1. Introduction
In practical image lossy compression systems, the framework based on transform–quantization–entropy coding is the most widely used [
1,
2,
3,
4,
5,
6]. However, methods that currently outperform JPEG2000 in compression efficiency typically come at the cost of increased computational complexity. The core of transform coding lies in the elimination of redundant correlations in image data, thus enhancing compression efficiency. Transformation methods in image compression can be divided into linear and non-linear transformations, with the latter commonly employed in deep learning-based image compression methods [
7,
8,
9,
10,
11]. The activation functions in the network architecture introduce non-linearity, thereby implementing non-linear transformations that extract complex features to achieve higher compression performance. However, deep learning-based image compression methods have higher computational complexity, which limits their application in scenarios where speed is a critical factor. Common linear transform methods include the Karhunen–Loève transform (KLT) [
12], Discrete Cosine Transform (DCT) [
13,
14], and Discrete Wavelet Transform (DWT) [
15,
16,
17,
18], with DCT and DWT serving as core transform techniques in the JPEG and JPEG2000 standards, respectively.
In terms of eliminating data correlations, the KLT, as an optimal linear orthogonal transform, can adaptively determine the optimal orthogonal basis based on the statistical properties of the data, minimizing the correlation between data in the new basis coordinate system. It achieves optimal compression in terms of the Mean Squared Error (MSE) [
12]. However, the high computational complexity of the KLT limits its use in practical applications.
In contrast, the basis functions of DCT, which are cosine functions, are fixed and independent of the statistical properties of the data, significantly reducing computational complexity. Moreover, DCT can achieve compression performance comparable to that of KLT in most cases, making it a widely used alternative in practical systems. However, as global basis functions, cosine functions span the entire dataset, limiting DCT’s ability to capture local features, such as image edges and textures. Therefore, when processing non-stationary signals, such as images, its redundancy reduction effectiveness is constrained.
To reduce the high computational and storage complexity of performing global DCT on large images, JPEG uses an 8 × 8 block-based DCT. However, under low bitrate conditions, information loss caused by truncated high-frequency components often leads to the blurring of the image and block artifacts.
The DWT employs wavelet functions as basis functions, with commonly used wavelet functions including Haar [
19], Daubechies [
20], Biorthogonal [
21], and Coiflet [
22]. Wavelet functions exhibit locality, being nonzero only in a limited region, which allows the DWT to be implemented through a weighted summation (convolution) method within local regions. As a result, the convolution-based DWT can operate directly on the entire image without the need for block-based processing, effectively avoiding block artifacts under low bitrate conditions. The DWT can simultaneously capture both global and local features of an image, making it more suitable for processing non-stationary signals.
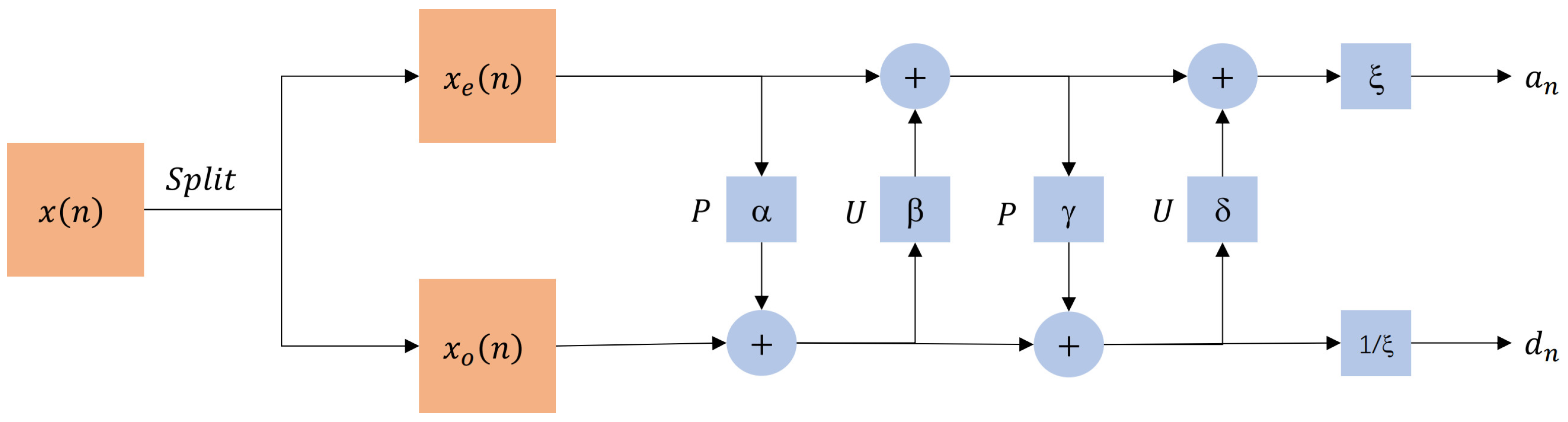
Furthermore, the DWT retains both time-domain and frequency-domain information and supports integer lossless transformations, making it more advantageous than the DCT in preserving image details. Its hierarchical decomposition mechanism allows images to be transmitted progressively at different resolution and quality levels, aligning more closely with human visual characteristics. Due to these properties, wavelet transforms are widely used in modern image compression techniques such as EZW (Embedded Zerotree Wavelet), SPIHT (Set Partitioning in Hierarchical Trees), and EBCOT (Embedded Block Coding with Optimal Truncation) [
23,
24,
25].
The Mallat algorithm is a fast DWT that achieves efficient multi-resolution decomposition [
26]. This algorithm implements DWT through convolution operations using FIR (Finite Impulse Response) filters. Introduced later, the lifting scheme decomposes the traditional filtering operations in the Mallat algorithm into a series of simple, complementary prediction and update steps, resulting in an efficient and reversible DWT, while also mitigating the boundary effects of convolution [
27,
28]. The lifting-based DWT is essentially an optimized version of the Mallat algorithm, and mathematically, they are equivalent. The lifting-based DWT is applied in JPEG2000 due to its computational simplicity and efficiency.
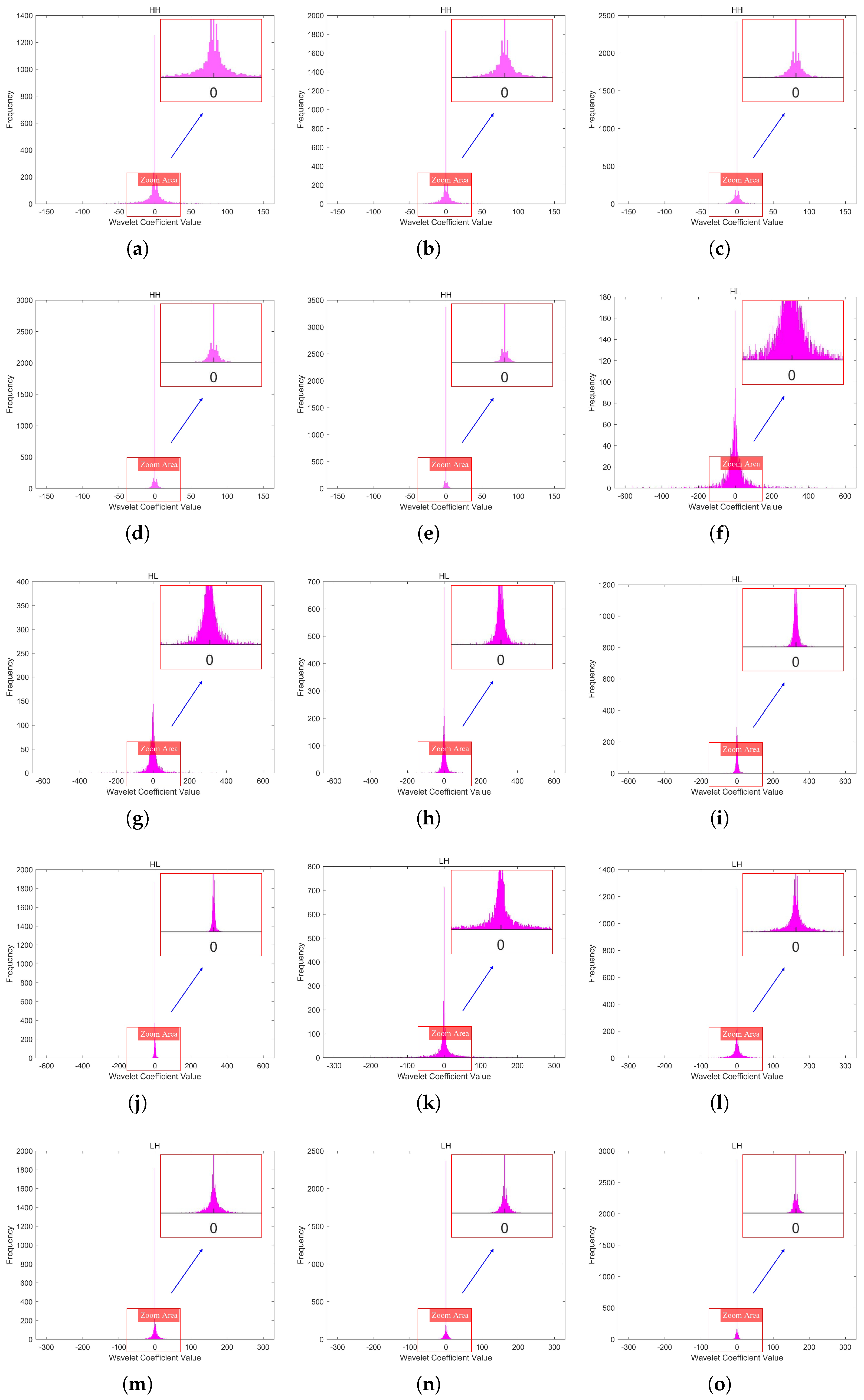
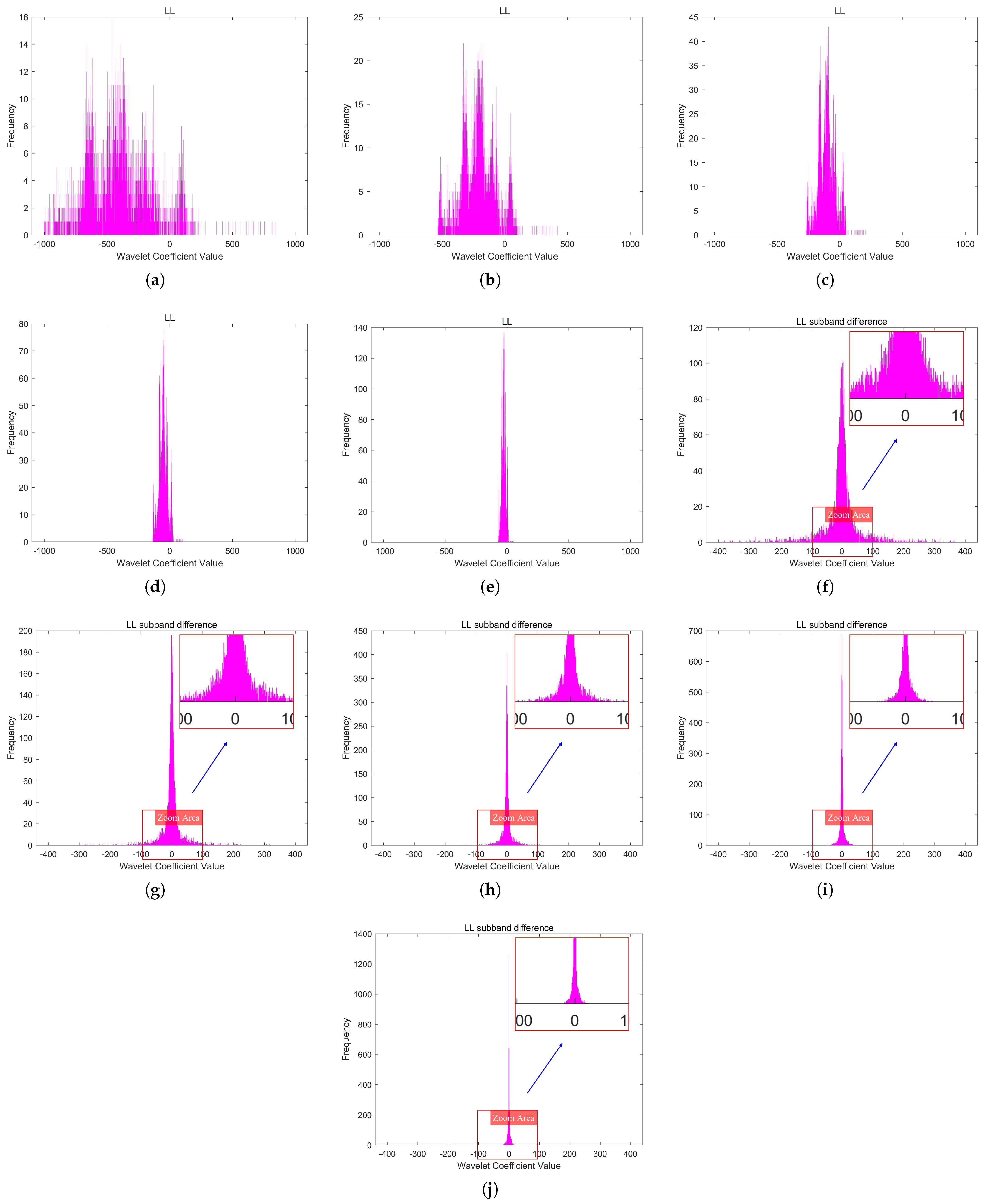
An n-level wavelet transform decomposition results in subbands, with the low-frequency subband (LL) containing most of the energy and serving as the approximation of the original image, while the high-frequency subbands (LH, HL, HH) contain less energy and represent the details of the image. Although the DWT offers advantages over the DCT, the decomposed subbands, especially the LL subband, may still contain spatial redundancy due to the retention of time-domain information.
Quantization schemes typically include vector quantization (VQ) and scalar quantization (SQ). In high bitrate scenarios, uniform scalar quantization (USQ) is widely used in practical coding systems due to its good rate-distortion performance and simplicity [
29]. JPEG uses an 8 × 8 DCT transformation, combined with USQ [
30,
31,
32,
33]. However, under low bitrate conditions, the quality of JPEG-compressed images degrades significantly due to the side effects introduced by quantization and block division. In contrast, JPEG2000 uses a lifting-based DWT to transform the entire image, avoiding block artifacts. JPEG2000 uses two wavelet transforms: the Le Gall 5/3 integer wavelet transform for lossless compression, and the Daubechies 9/7 fractional wavelet transform for lossy compression [
18]. In lossy compression, JPEG2000 uses dead-zone uniform scalar quantization (DUSQ) [
29,
34,
35] during the quantization stage. This method introduces larger quantization intervals near zero to discard insignificant information, thereby improving compression performance. Infrared line-scanning images, due to the high amount of redundant information they contain, exhibit sparsity in the coefficients of high-frequency subbands after DUSQ, with many coefficients being zero, and the few nonzero coefficients concentrated near zero.
Entropy coding is a key step in image compression, with common methods including arithmetic coding (AC) [
36,
37,
38,
39] and Huffman coding [
40,
41,
42,
43,
44]. JPEG2000 adopts MQ arithmetic coding [
45,
46], which uses a two-level lookup table with context (CX) and binary decisions (D) for adaptive probability estimation, achieving high compression efficiency. However, this method has high computational complexity. Despite optimizations such as parallel algorithms and hardware acceleration [
47,
48], its theoretical complexity is higher than that of Huffman coding. In contrast, Huffman coding is more efficient in terms of computational speed. In our previous work, we designed a coding method that could achieve O(1) complexity after the codebook was constructed [
49], making it highly suitable for high-speed compression applications.
However, Huffman coding only assigns integer-bit codes and does not consider the continuity of symbol distributions, resulting in low compression efficiency for sparse wavelet coefficients after quantization. Specifically, for high-frequency subbands with large numbers of consecutive zeros, the inaccuracy of Huffman coding with a minimum code length of one bit accumulates, reducing compression efficiency. Furthermore, due to the differences in statistical distributions across various wavelet subbands, traditional Huffman coding often requires frequent recalculation of statistics for constructing the codebook, thereby increasing complexity.
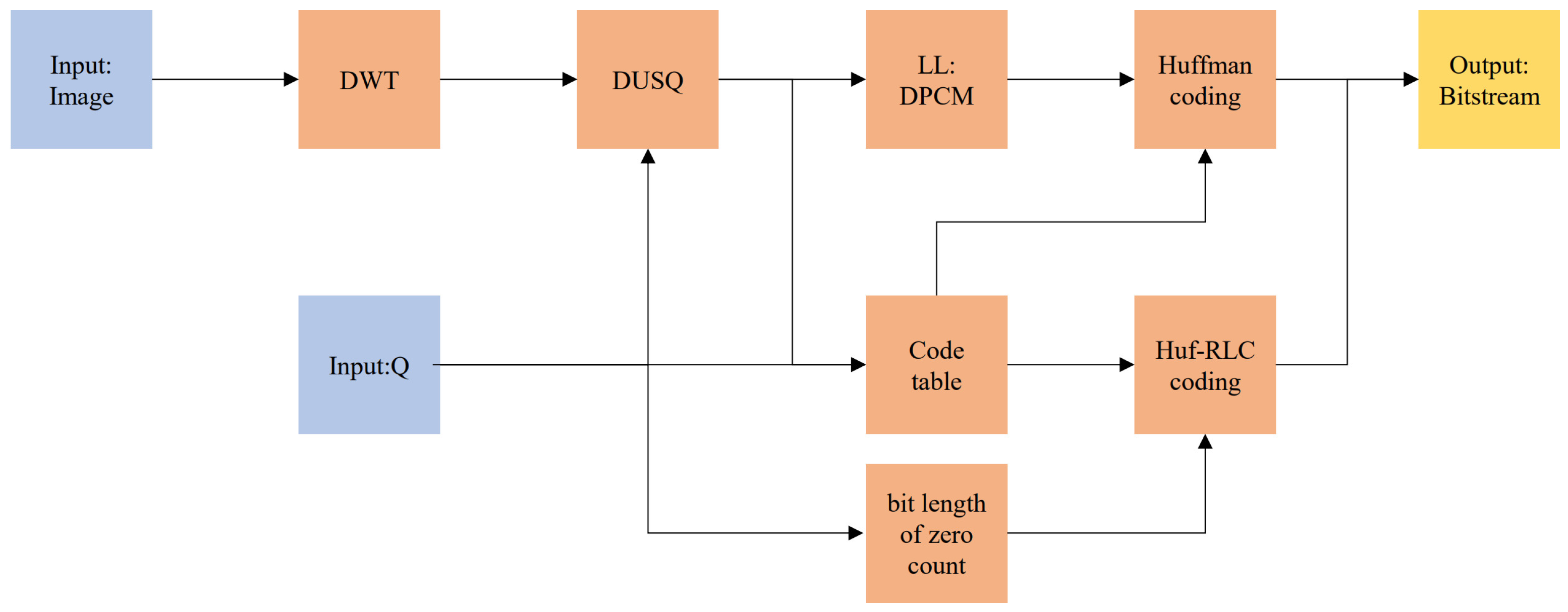
To address the remaining spatial redundancy in wavelet subbands and the inefficiencies of Huffman coding for quantized sparse wavelet coefficients, this paper proposes the following optimization strategies:
- 1.
Wavelet subband redundancy reduction via DPCM:
to address the spatial redundancy in wavelet subbands caused by the presence of temporal information, Differential Pulse Code Modulation (DPCM) is employed to reduce spatial redundancy.
- 2.
Wavelet coefficient probability modeling for Huffman coding:
A wavelet coefficient probability model-based Huffman coding scheme is proposed to eliminate the need for frequent symbol statistics and codebook reconstruction across wavelet subbands, thereby reducing computational complexity. Since quantized wavelet coefficients have varying statistical distributions across subbands and quantization levels, traditional Huffman coding requires frequent coefficient statistics and codebook construction, leading to high computational costs. The proposed method establishes a probabilistic model for quantized wavelet coefficients to effectively reduce complexity and improve compression speed.
- 3.
Run-length-enhanced Huffman coding:
Huffman coding of quantized sparse wavelet coefficients suffers from inefficient code length allocation and disregards symbol distribution continuity, leading to suboptimal compression efficiency. By integrating Run-Length Coding (RLC) into Huffman coding, symbol continuity is exploited to optimize the assignment of the shortest Huffman code, which is one bit, achieving an average code length of less than one bit in sparse scenarios, thus improving the efficiency of Huffman coding.
Experimental results demonstrate that the proposed method outperforms JPEG in terms of compression ratio and decoding speed, achieves higher compression speed compared to JPEG2000, and maintains image quality comparable to JPEG2000 at the same bitrate. Especially under low bitrate conditions, the proposed method maintains a small gap with JPEG2000, while JPEG shows significant blocking artifacts. Speed test results show that the proposed method achieves compression speeds 3.155 times faster than JPEG2000 and 2.049 times faster than JPEG, providing an ideal solution for lossy compression applications that require both compression speed and image quality.
3. Results
3.1. Selection of Optimal Run Length for Different Quantization Levels and Subbands
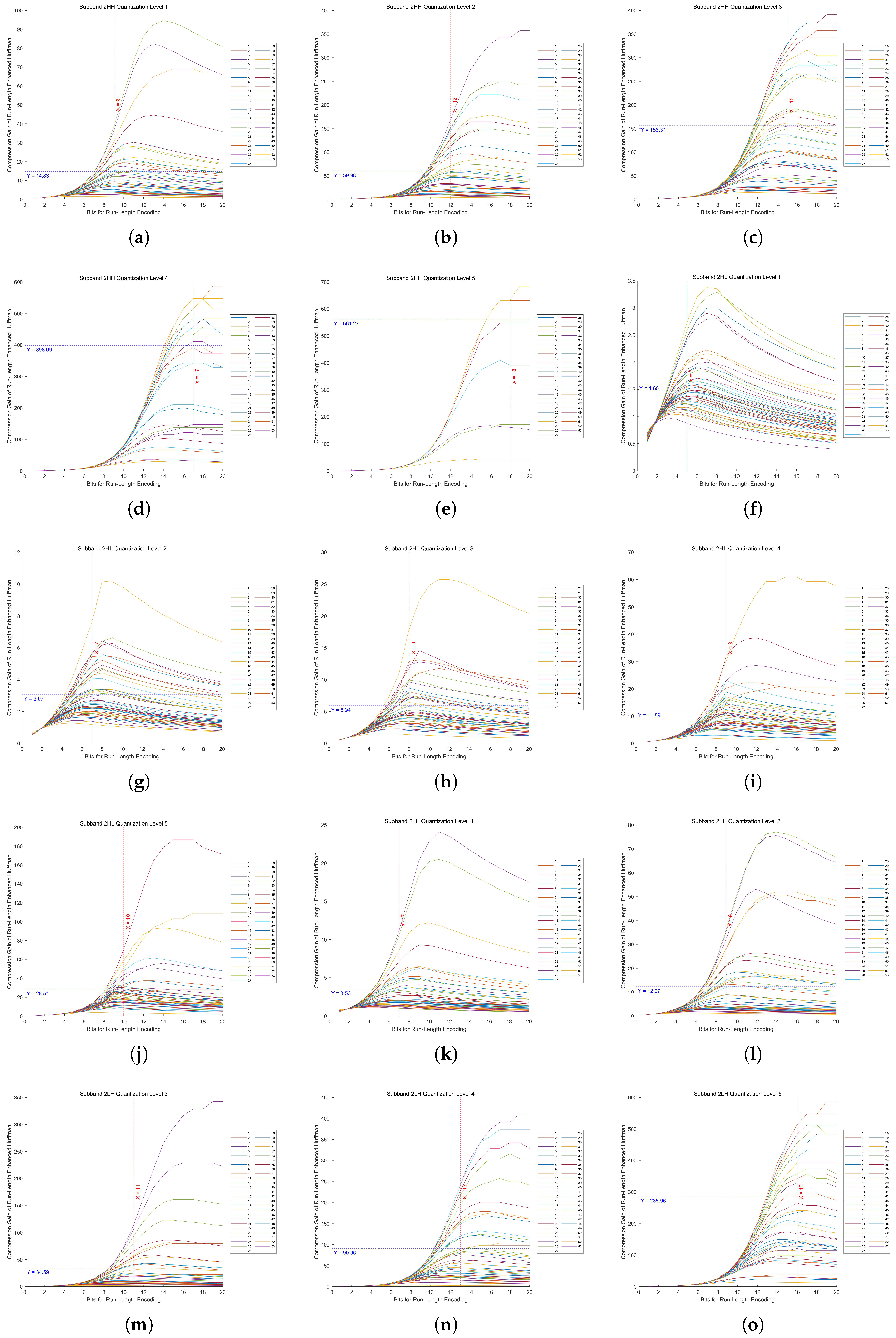
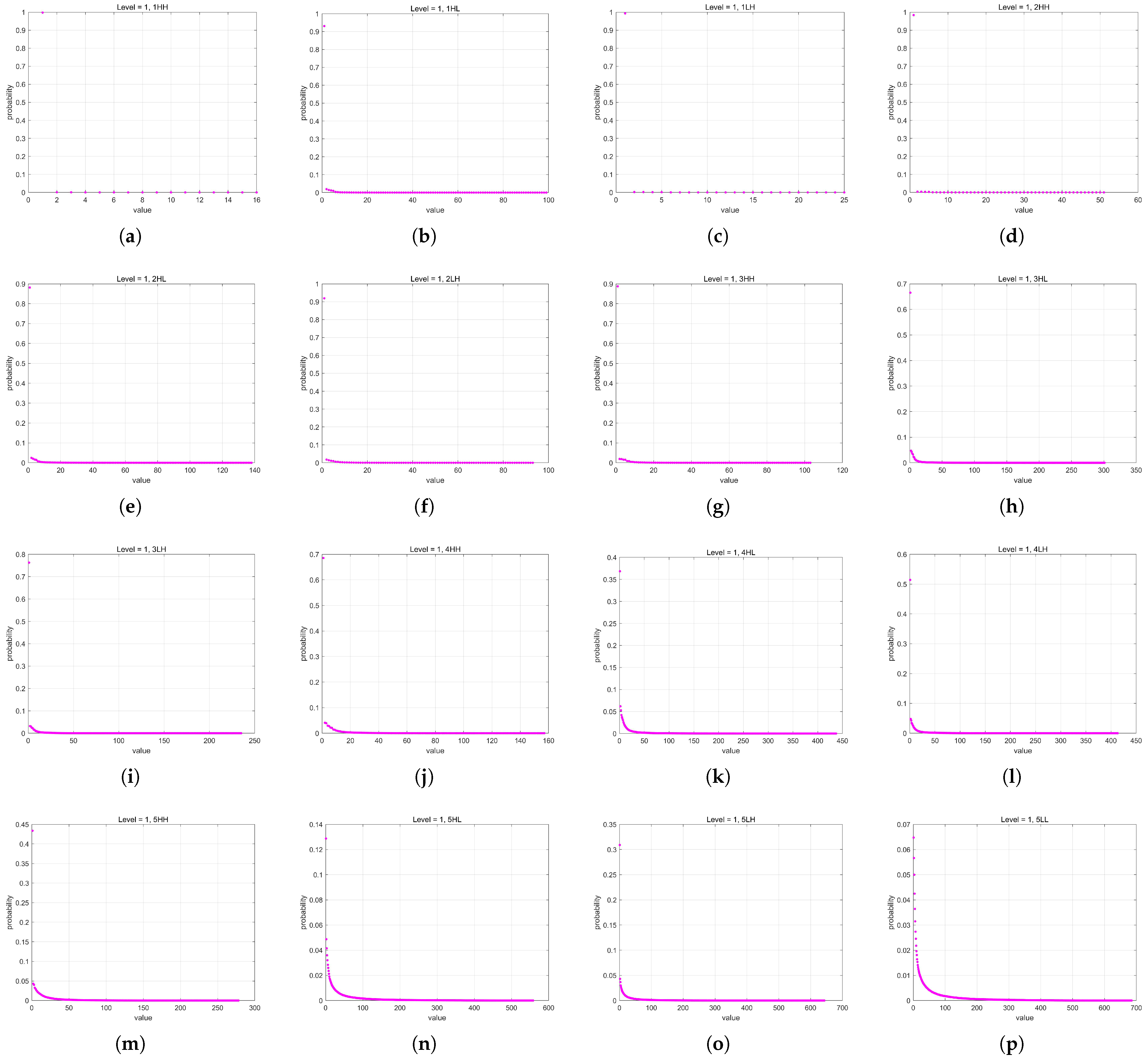
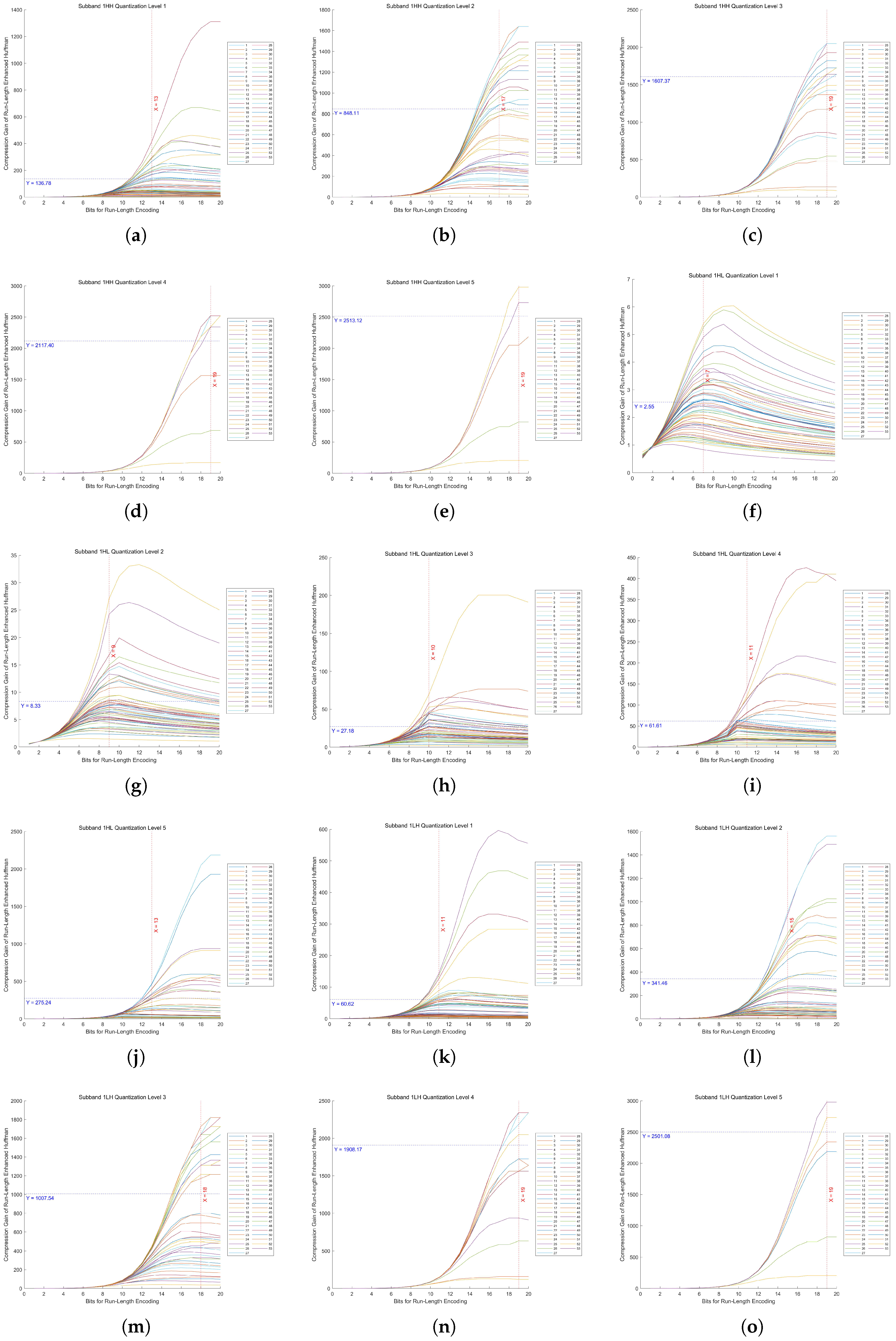
In Huf-RLC, the bit length used to record the number of consecutive zeros significantly impacts compression performance, especially when zeros occur with high probability. To determine the optimal bit length for encoding zero runs, experiments were conducted on five quantization levels of a five-level DWT across fifteen high-frequency subbands.
By evaluating 53 images, we measured the compression gain, defined as the ratio of the Huf-RLC compression ratio to the standard Huffman compression ratio, across bit lengths ranging from 1 to 20. The experimental results for the high-frequency subbands at decomposition level 1 in a five-level DWT, under quantization levels 1 to 5, are shown in
Figure 13. The results for decomposition levels 2 to 5 are presented in
Appendix A.2 in
Figure A1,
Figure A2,
Figure A3, and
Figure A4, respectively.
As proven in our theoretical analysis (
Appendix A.1), there exists a unique optimal bit length
for run-length encoding of zeros in quantized high-frequency wavelet subbands. From these figures, we can observe that the distribution of the 53 values of
is concentrated around a certain value, and the distribution may approximate a normal distribution. Therefore, using the mean as an estimate of the overall optimal value is a reasonable and effective approach.
In these figures, the x-axis represents the bit length used for encoding zero runs, while the y-axis denotes the compression gain. Five quantization levels were analyzed, with 53 curves corresponding to individual images. Each curve is annotated with the mean of all y-values at its maximum point, along with the rounded mean of the corresponding x-values. This rounded x-value represents the optimal bit length for recording the number of consecutive zeros.
Furthermore, Huf-RLC was applied to a subband only if the compression gain exceeded two (i.e., y > 2); otherwise, standard Huffman coding was used.
3.2. Comparison of Performance with JPEG and JPEG2000 at Different Bitrates
In lossy image compression, and are metrics used to evaluate the quality of compressed images. primarily measures pixel-wise errors, while focuses more on structure, brightness, and contrast, making it better at reflecting human visual perception.
is defined as follows:
where
is the maximum pixel value (255 for the eight-bit images in this paper). The original image
X is of size
, and the compressed image
Y is also of size
.
is defined as follows:
where
are the means of images
X and
Y (representing brightness).
are the variances (representing contrast).
is the covariance (representing structural information).
are stability constants to prevent division by zero.
(Bits Per Pixel) is a key metric for evaluating image compression quality and efficiency. It indicates the average number of bits assigned to each pixel in the compressed image and helps quantify the trade-off between compression ratio and image quality.
is defined as follows:
where
is the compressed image size (in bits).
Since the probability models was derived from 53 images, additional images were required to validate the generalizability of the algorithm, similar to the training and testing sets in deep learning. In this study, 53 images were used to construct the training set, while another 27 images were collected from different working scenarios of infrared line-scan detectors to form the test set.
In the experiment, 3 images were selected from the 53 images in the training set and 3 images from the 27 images in the test set to compare the performance of the proposed method, JPEG, and JPEG2000 at different bitrates. The specific bitrates were categorized into low bitrate under the first quantization level and high bitrate under the fifth quantization level. The experimental results are shown in
Figure 14, with detailed
,
, and
statistics provided in
Table 5.
JPEG2000 performed well under low bitrate conditions. The above test results and their averages showed that the proposed method maintained a of 40.05 dB and an of 0.9649 at a low bitrate ( approximately 0.0380). Compared to JPEG2000, the loss did not exceed 2.67 dB, and the loss did not exceed 0.008. However, JPEG, even at a relatively higher (approximately 0.0420), exhibited noticeable block effects, with a loss of 14.28 dB and an loss of 0.1165.
3.3. Rate-Distortion Curves and Compression Speed Evaluation
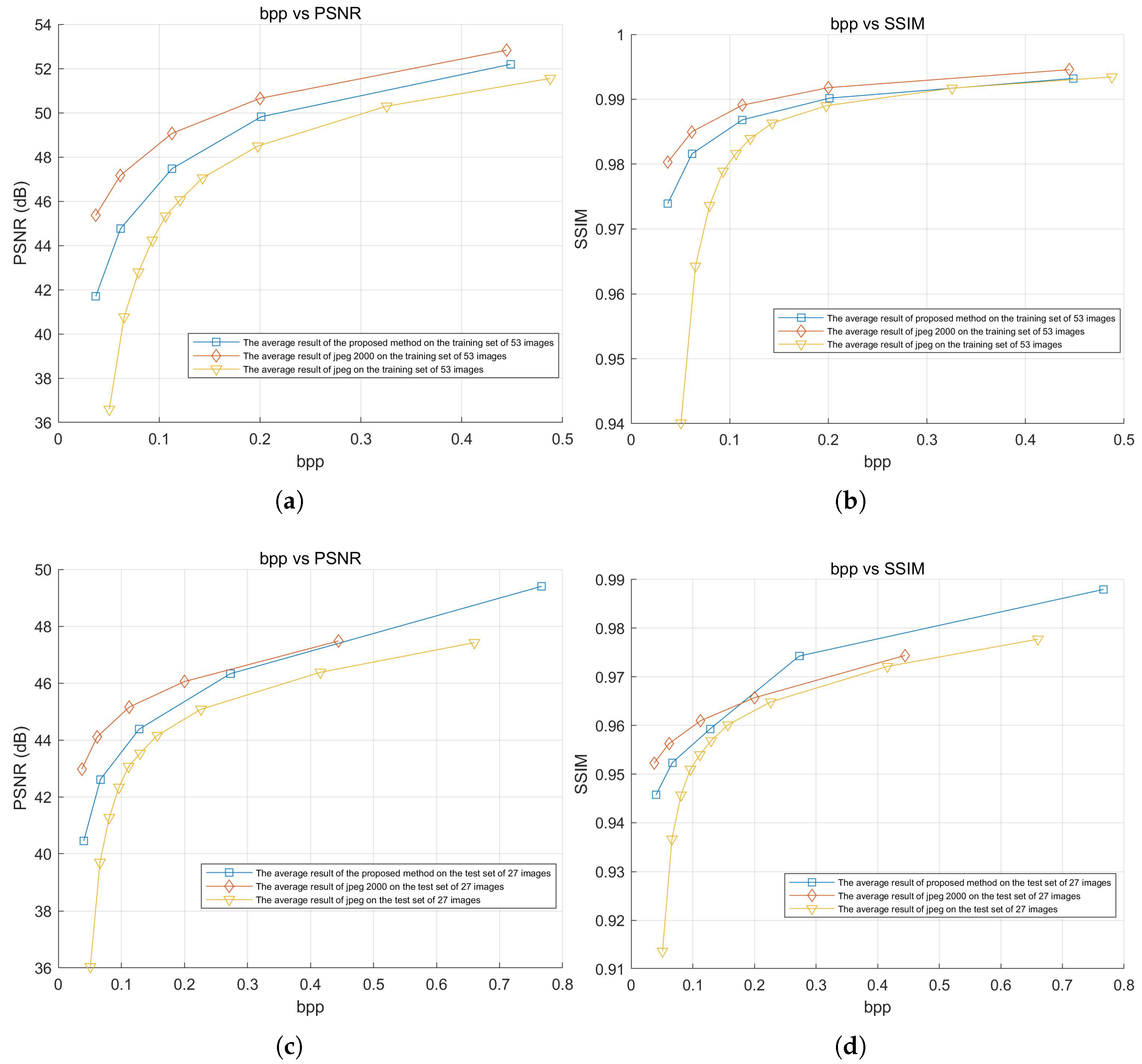
The experiment tested the compression efficiency of the proposed method, JPEG, and JPEG2000 on both the training and test sets. The average
and
results for all images in the dataset at different bitrates were used to plot the curves shown in
Figure 15. The average results of these curves, along with detailed numerical comparisons at specific points, are summarized in
Table 6. Additionally, the speed of the proposed method, JPEG, and JPEG2000 was also tested and is presented in
Table 7.
The experimental results show that, in terms of rate–distortion performance, the proposed method outperformed JPEG and was close to JPEG2000. In the average test results of the 53 training images, the loss compared to JPEG2000 was only −1.825 dB, and the loss was only −0.003, while the loss for JPEG reached −3.699 dB, and the loss was approximately −0.00985. In the average test results of the 27 test images, the loss compared to JPEG2000 was only −0.520 dB, and the improved by 0.002, while JPEG’s loss reached −2.257 dB, and the loss was approximately −0.00865.
Especially under low bitrate conditions, the proposed method still maintained a small gap with JPEG2000, while JPEG showed severe degradation. For the training set at a low bitrate, the loss compared to JPEG2000 was only −3.665 dB, with an loss of −0.00640, whereas JPEG showed a greater loss of −8.779 dB and an loss of approximately −0.04022. For the test set at a low bitrate, the loss compared to JPEG2000 was −2.522 dB, with an loss of −0.00652, while JPEG exhibited a higher loss of −6.934 dB, and an loss of approximately −0.03859.
JPEG2000 adopts MQ arithmetic coding, a context-based binary entropy encoder that operates at the bit level. It employs a two-level lookup table based on context labels (CX) and binary decisions (D) to adaptively estimate symbol probabilities. This fine-grained and highly adaptive coding allows the encoder to approach the theoretical entropy limit and achieve high compression efficiency. However, the computational complexity introduced by bit-level processing and context modeling may limit its suitability for real-time or resource-constrained scenarios. In contrast, the proposed Huf-RLC method performs symbol-level entropy coding using a much simpler structure. While this sacrifices some compression performance, it significantly reduces computational overhead and offers much faster encoding, making it more appropriate for speed-critical applications.
The speed test results showed that the proposed method achieved a speed of 28.944 MB/s, which was approximately 3.155 times faster than JPEG and 2.049 times faster than JPEG2000.
We implemented the DWT in the same manner as OpenJPEG, utilizing SIMD technology to ensure the efficiency of the DWT implementation. Despite this, the compression speed of our method outperformed OpenJPEG, primarily due to the advantages of our proposed entropy coding method, Huf-RLC. Notably, Huf-RLC was tested using a single core and a single thread, without any SIMD optimizations or acceleration techniques. This demonstrates the speed advantages of Huf-RLC, even in the absence of optimizations.
The image encoding time measurement procedure involved testing the encoding speed of each image individually, with the average encoding time calculated across all images. This was performed using a Windows batch script that processed each image one by one. The testing was conducted without any specific bulk encoding mechanism, ensuring that each image was encoded separately.
The above experimental results were conducted on an experimental platform with a 12th Gen Intel(R) Core(TM) i7-12700H, a 20-core CPU at 2.30 GHz, and 16 GB of RAM.
Deep learning-based compression methods that currently outperform JPEG2000 in terms of compression efficiency generally come with increased computational complexity. However, for applications where compression speed is critical, such as high-speed scenarios, our method offers a significant advantage due to faster encoding. As a result, comparisons with deep learning-based methods were not included in the experiments.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}