
A New Pallet-Positioning Method Based on a Lightweight Component Segmentation Network for AGV Toward Intelligent Warehousing


Abstract
1. Introduction
2. Related Works
2.1. Blurry Edge Segmentation and Slow Segmentation Speed
2.2. Small-Sample Semantic Segmentation
2.3. Generalization of the Segmentation Model
- Obtaining spatial detail information through a dual-branch attention network and optimizing the weights of deep features to solve the problem of inaccurate pallet edge segmentation.
- Extracting the middle-, low-, and high-level features of the dual-branch input image and fusing them to construct multi-scale images, which guide precise segmentation of unknown new classes using limited annotated images.
- Introducing residual structures and inverted residual structures in the backbone network to reduce redundancy in network parameters. During the image generation phase, a noise component is introduced, increasing data diversity and further enhancing the model’s generalization ability.
3. Methodology
3.1. Using the Segmentation Network to Achieve Pallet Positioning
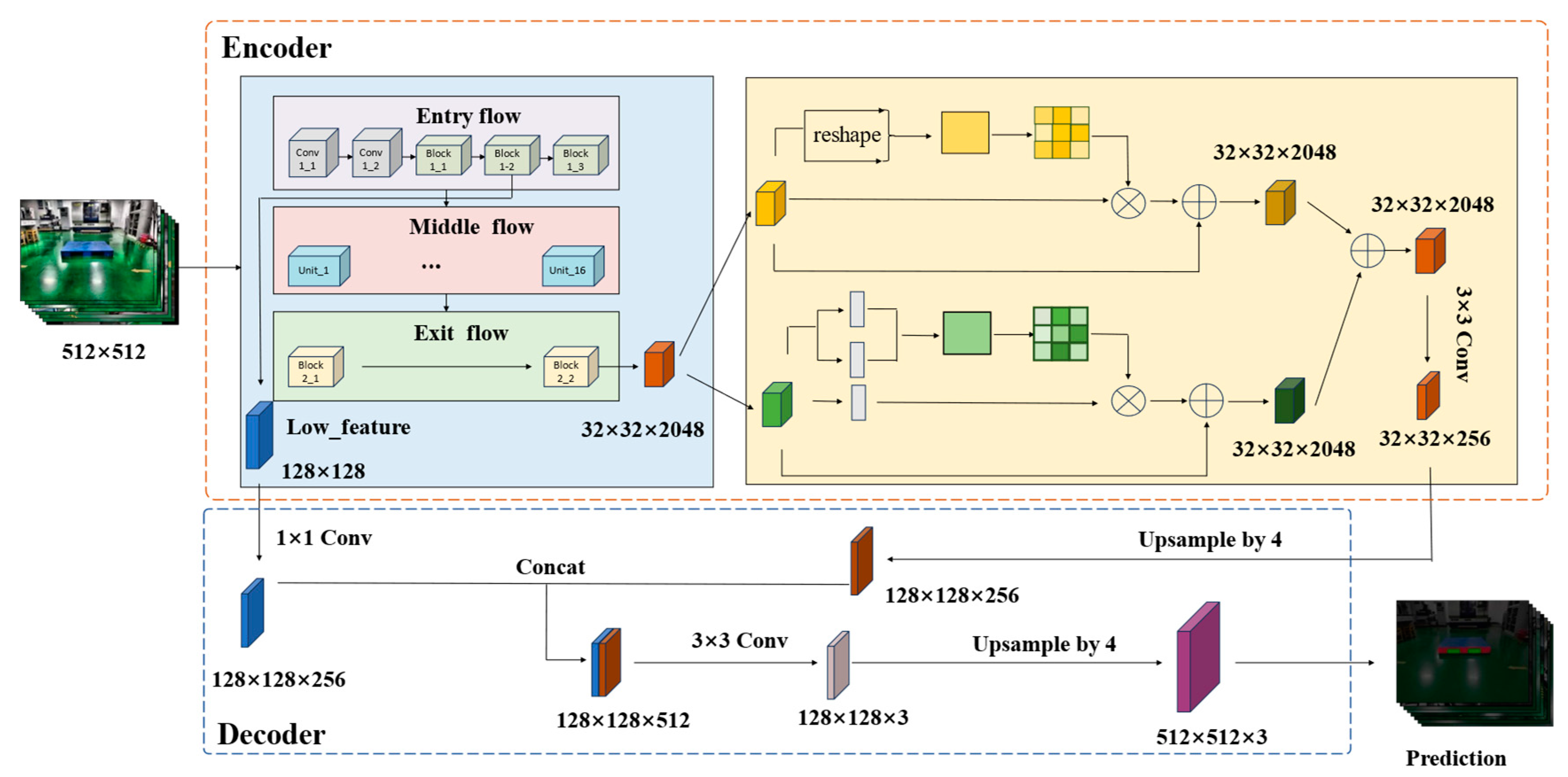
3.2. Basic Architecture of LCS-Net
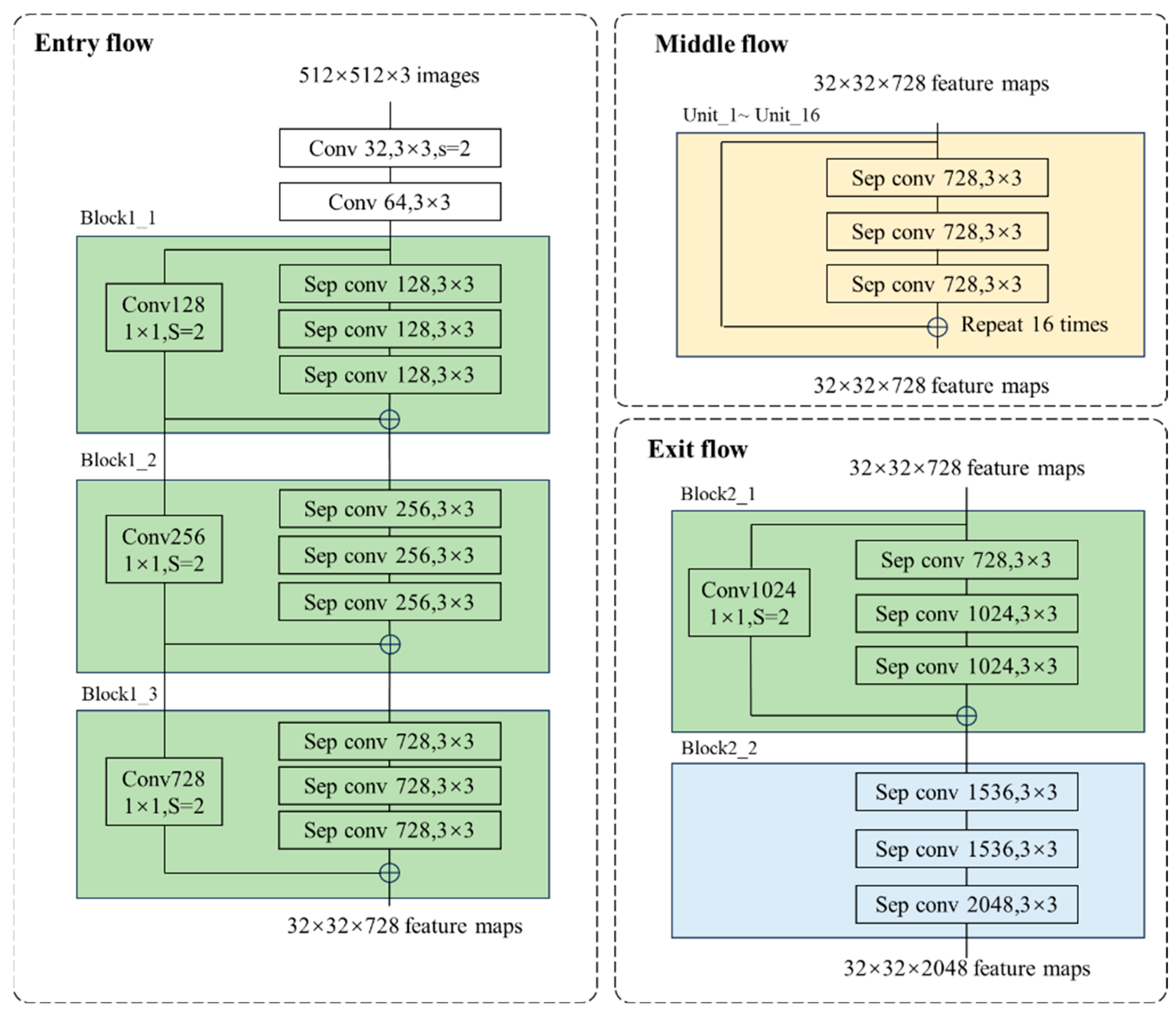
3.3. Optimization of Xception Network
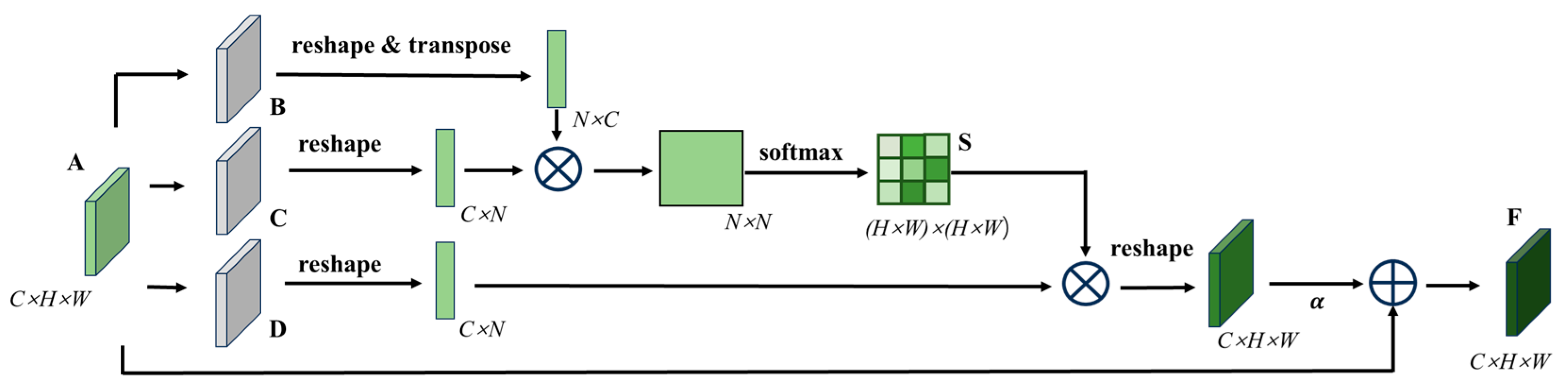
3.4. Dual-Branch Network Structure
3.5. Focal Loss Function
4. Ablation Experiment and Analysis
4.1. Datasets and Evaluation Criteria
4.1.1. Datasets Preparation and Processing
4.1.2. Performance Evaluation
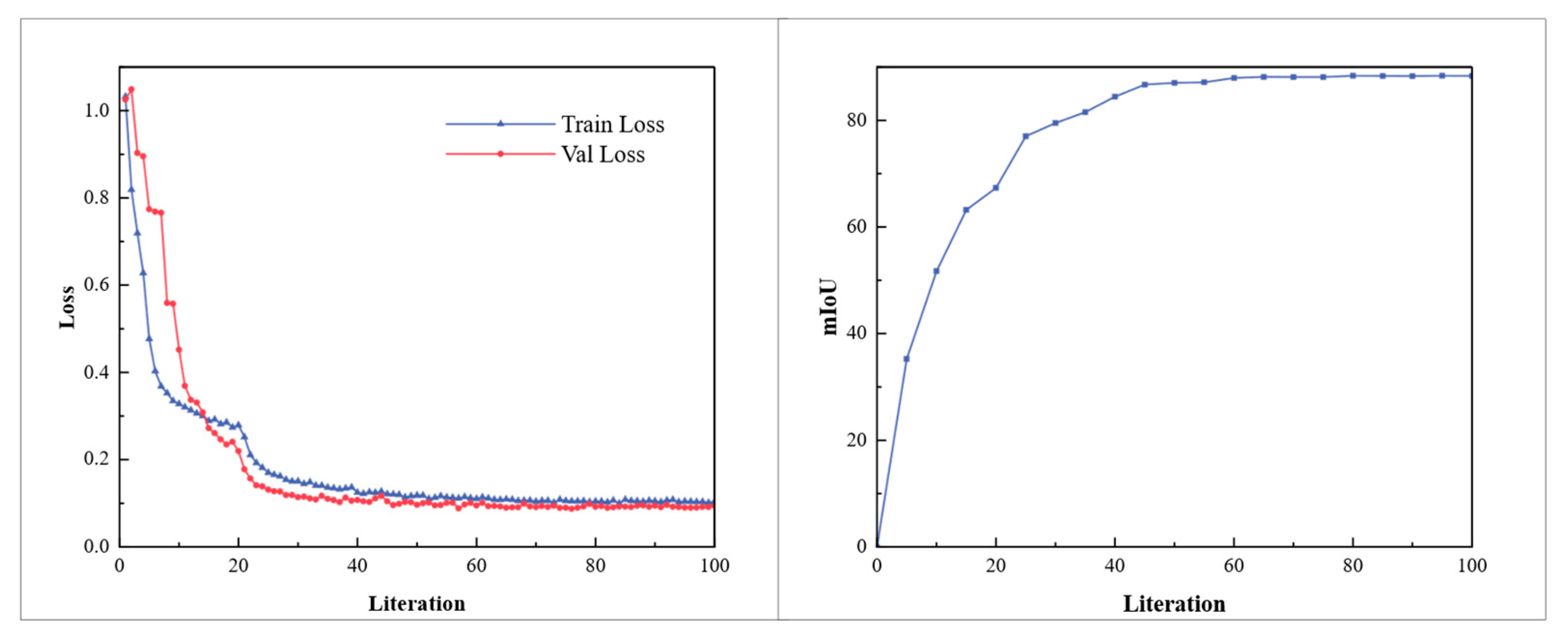
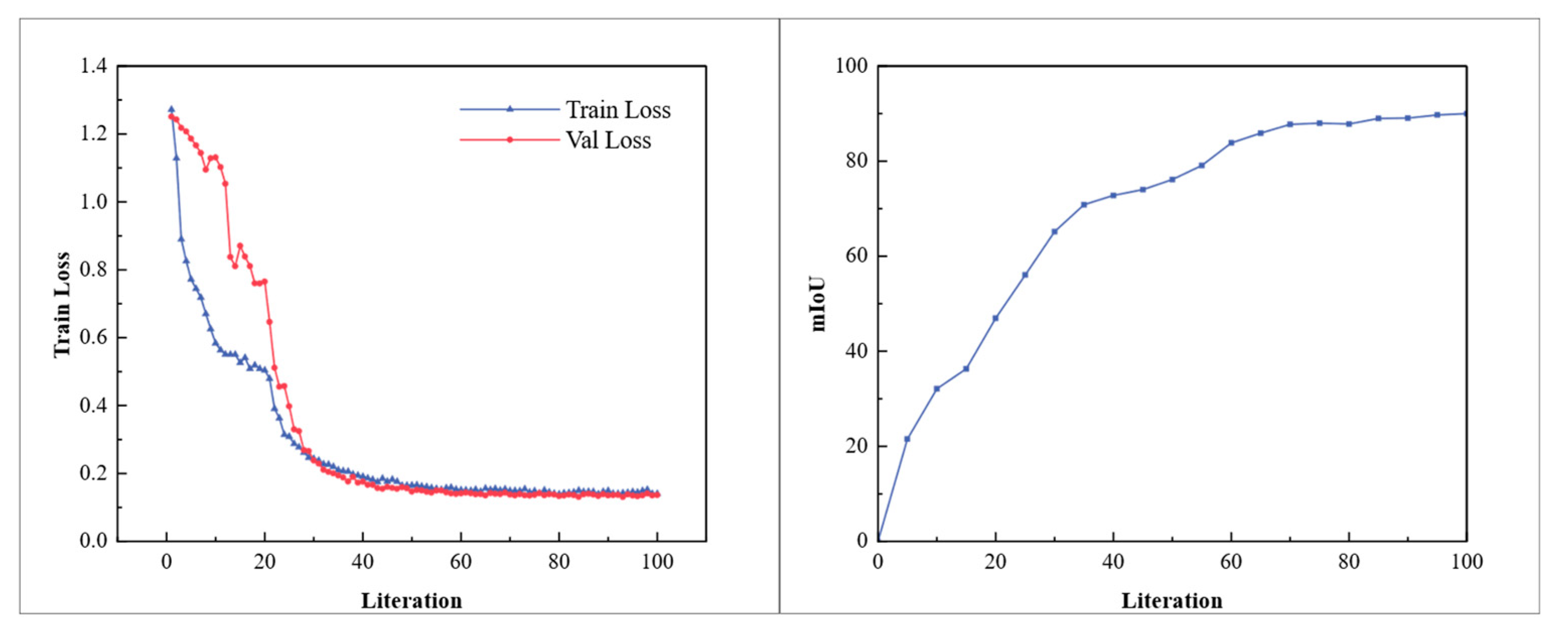
4.1.3. Implementation Details
4.2. Ablation Studies
4.2.1. Backbone Network Ablation Experiment
4.2.2. Evaluating the Impact of Attention Mechanisms
4.2.3. Single-Type Pallet Comparative Experiment
4.2.4. Multi-Type Pallet Comparative Experiment
4.3. Location of Pallet Based on LCS-Net
4.3.1. Positioning the Center Point of the Pallet Stringer Board
4.3.2. Evaluation Experiment of Pallet-Positioning Accuracy Under Different Distance
4.3.3. Evaluation Experiment of Pallet-Positioning Accuracy Under Different Offset Angles
4.3.4. Evaluation Experiment Result Analysis
4.4. Validation of Generalization Ability Across Different Environments
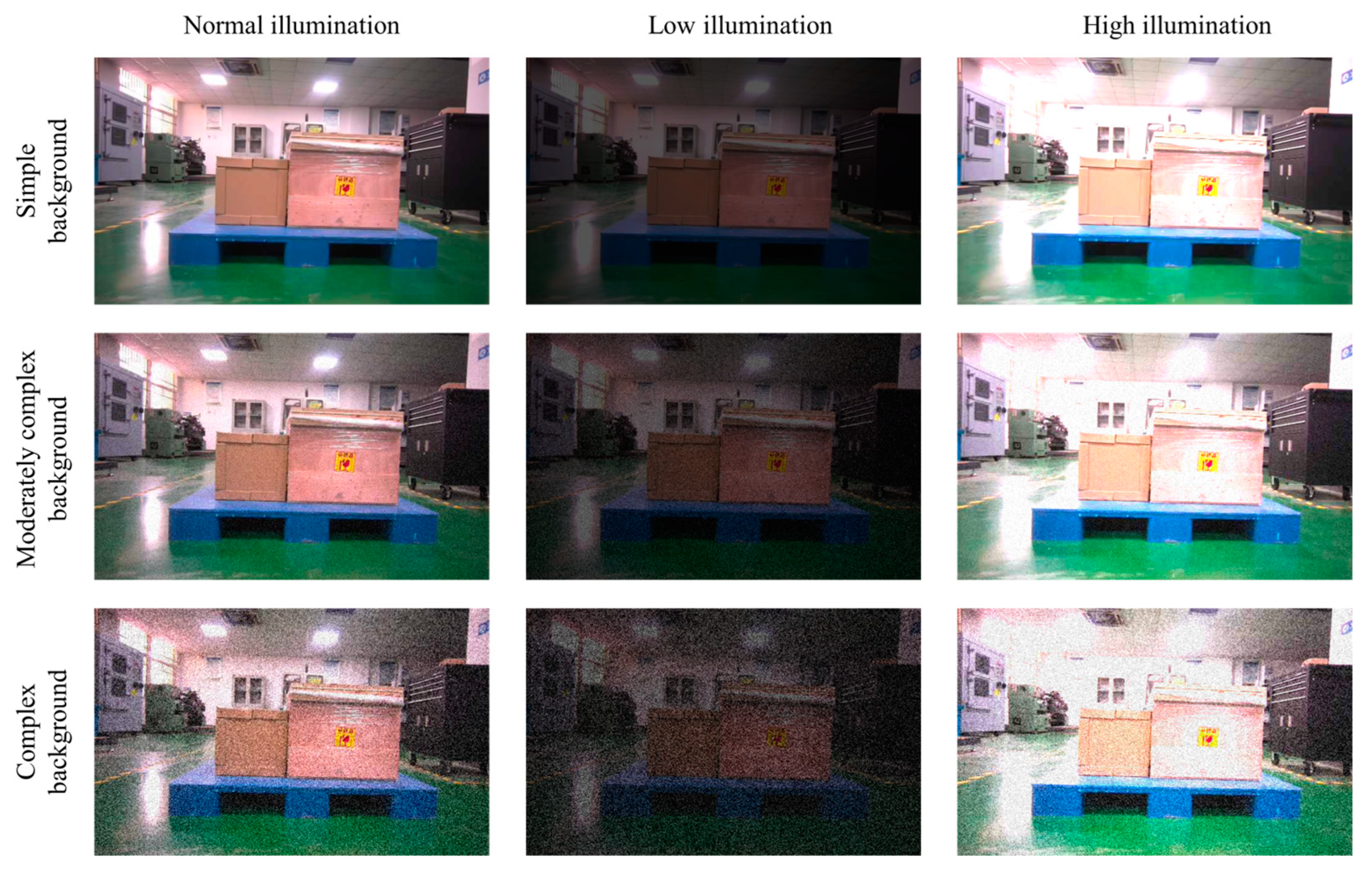
4.4.1. Illumination and Noise Joint Interference Experiment
4.4.2. Different Environments Result Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, B.-i.; Graves, R.J.; Heragu, S.S.; Onge, A.S. Intelligent agent modeling of an industrial warehousing problem. IIE Trans. 2002, 34, 601–612. [Google Scholar] [CrossRef]
- Zhao, Z.; Cheng, J.; Liang, J.; Liu, S.; Zhou, M.; Al-Turki, Y. Order picking optimization in smart warehouses with human-robot collaboration. IEEE Internet Things J. 2024, 11, 16314–16324. [Google Scholar] [CrossRef]
- Kubasakova, I.; Kubanova, J.; Benco, D.; Kadlecová, D. Implementation of Automated Guided Vehicles for the Automation of Selected Processes and Elimination of Collisions between Handling Equipment and Humans in the Warehouse. Sensors 2024, 24, 1029. [Google Scholar] [CrossRef] [PubMed]
- Solman, K.N. Analysis of interaction quality in human–machine systems: Applications for forklifts. Appl. Ergon. 2002, 33, 155–166. [Google Scholar] [CrossRef] [PubMed]
- Baglivo, L.; Biasi, N.; Biral, F.; Bellomo, N.; Bertolazzi, E.; Da Lio, M.; De Cecco, M. Autonomous pallet localization and picking for industrial forklifts: A robust range and look method. Meas. Sci. Technol. 2011, 22, 085502. [Google Scholar] [CrossRef]
- Seelinger, M.; Yoder, J.-D. Automatic visual guidance of a forklift engaging a pallet. Robot. Auton. Syst. 2006, 54, 1026–1038. [Google Scholar] [CrossRef]
- Lin, R.; Huang, H.; Li, M. An automated guided logistics robot for pallet transportation. Assem. Autom. 2021, 41, 45–54. [Google Scholar] [CrossRef]
- Mohamed, I.S.; Capitanelli, A.; Mastrogiovanni, F.; Rovetta, S.; Zaccaria, R. Detection, localisation and tracking of pallets using machine learning techniques and 2D range data. Neural Comput. Appl. 2020, 32, 8811–8828. [Google Scholar]
- Leng, J.; Wang, D.; Shen, W.; Li, X.; Liu, Q.; Chen, X. Digital twins-based smart manufacturing system design in Industry 4.0: A review. J. Manuf. Syst. 2021, 60, 119–137. [Google Scholar]
- Vu, V.-D.; Hoang, D.-D.; Tan, P.X.; Nguyen, V.-T.; Nguyen, T.-U.; Hoang, N.-A.; Phan, K.-T.; Tran, D.-T.; Vu, D.-Q.; Ngo, P.-Q. Occlusion-robust pallet pose estimation for warehouse automation. IEEE Access 2024, 12, 1927–1942. [Google Scholar] [CrossRef]
- Cai, W.; Song, Y.; Duan, H.; Xia, Z.; Wei, Z. Multi-feature fusion-guided multiscale bidirectional attention networks for logistics pallet segmentation. Comput. Model. Eng. Sci. 2022, 131, 1539–1555. [Google Scholar] [CrossRef]
- Chen, G.; Peng, R.; Wang, Z.; Zhao, W. Pallet Recognition and Localization Method for Vision Guided Forklift. In Proceedings of the 2012 8th International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, 21–23 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–4. [Google Scholar]
- Garibott, G.; Masciangelo, S.; Ilic, M.; Bassino, P. Robolift: A vision guided autonomous fork-lift for pallet handling. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS’96, Osaka, Japan, 8 November 1996; IEEE: Piscataway, NJ, USA, 1996; pp. 656–663. [Google Scholar]
- Carata, S.V.; Ghenescu, M.; Mihaescu, R. Real-Time Detection of Unrecognized Objects in Logistics Warehouses Using Semantic Segmentation. Mathematics 2023, 11, 2445. [Google Scholar] [CrossRef]
- Fang, D.; Han, J.; Shao, J.; Zhao, C. Pallet Detection and Localization Based on RGB Image and Point Cloud Data for Automated Forklift. In Proceedings of the 2024 7th International Conference on Advanced Algorithms and Control Engineering (ICAACE), Shanghai, China, 1–3 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 642–647. [Google Scholar]
- Bao, J.; Guo, D.; Li, J.; Zhang, J. The modelling and operations for the digital twin in the context of manufacturing. Enterp. Inf. Syst. 2019, 13, 534–556. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18, 2015. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 801–818. [Google Scholar]
- Lu, C.; Xia, M.; Qian, M.; Chen, B. Dual-branch network for cloud and cloud shadow segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410012. [Google Scholar] [CrossRef]
- Yang, Z. Semantic segmentation method based on improved DeeplabV3+. In Proceedings of the International Conference on Cloud Computing, Performance Computing, and Deep Learning (CCPCDL 2023), Huzhou, China, 17–19 February 2023; SPIE: Bellingham, WA, USA, 2023; pp. 32–37. [Google Scholar]
- Meng, J.; Zhang, L.; Cao, Y.; Zhang, L.; Song, Q. Research on optimization of image semantic segmentation algorithms based on Deeplab v3+. Laser Optoelectron. Prog. 2022, 59, 161–170. [Google Scholar]
- Hu, T.; Yang, P.; Zhang, C.; Yu, G.; Mu, Y.; Snoek, C.G. Attention-based multi-context guiding for few-shot semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019; AAAI: Palo Alto, CA, USA, 2019; pp. 8441–8448. [Google Scholar]
- Ding, H.; Zhang, H.; Jiang, X. Self-regularized prototypical network for few-shot semantic segmentation. Pattern Recognit. 2023, 133, 109018. [Google Scholar] [CrossRef]
- Antonelli, M.; Reinke, A.; Bakas, S.; Farahani, K.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B.; Ronneberger, O.; Summers, R.M. The medical segmentation decathlon. Nat. Commun. 2022, 13, 4128. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3146–3154. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 14–20 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Seattle, WA, USA, 14–19 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3–19. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss v2: Learning reliable localization quality estimation for dense object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Nashville, TN, USA, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 11632–11641. [Google Scholar]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive gradient methods with dynamic bound of learning rate. arXiv 2019, arXiv:1902.09843. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 8–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1251–1258. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Stringer Board IoU/% | Pallet Slots IoU/% | mIoU/% |
|---|---|---|---|
| Raw data | 64 | 59 | 74.15 |
| Enhanced data | 76 | 75 | 83.27 |
| Backbone | Model | mIoU/% | FPS |
|---|---|---|---|
| MobileNetv2 | DeepLabv3+ | 84.36 | 36.88 |
| Xception | DeepLabv3+ | 83.27 | 32.73 |
| Ours | DeepLabv3+ | 86.36 | 43.23 |
| Backbone | Attention Mechanism | mIoU/% | FPS |
|---|---|---|---|
| Xception | Baseline | 69.09 | 45.71 |
| Xception | Channel-Only | 75.95 | 43.89 |
| Xception | Position-Only | 73.48 | 44.25 |
| Xception | CBAM | 83.99 | 37.83 |
| Xception | Position and Channel | 87.37 | 43.57 |
| Method | mIoU/% | Stringer Board IoU/% | Pallet Slots IoU/% | mPA/% | FPS |
|---|---|---|---|---|---|
| U-Net | 77.87 | 66 | 69 | 96.49 | 34.89 |
| PSPNet | 72.09 | 64 | 67 | 87.59 | 45.88 |
| DeepLabv3+ | 83.27 | 76 | 75 | 90.12 | 32.73 |
| Fast-SCNN | 66.45 | 66 | 67 | 79.17 | 47.55 |
| SegFormer | 82.88 | 82 | 83 | 90.48 | 28.06 |
| Ours | 88.16 | 82 | 83 | 93.82 | 49.39 |
| Method | mIoU/% | Stringer Board IoU/% | Pallet Slots IoU/% | mPA/% | FPS |
|---|---|---|---|---|---|
| U-Net | 65.28 | 45 | 59 | 73.48 | 34.27 |
| PSPNet | 70.01 | 55 | 58 | 76.79 | 41.04 |
| Deeplabv3+ | 67.91 | 46 | 60 | 74.23 | 29.96 |
| Fast-SCNN | 66.45 | 66 | 67 | 79.17 | 43.43 |
| SegFormer | 78.44 | 72 | 73 | 83.79 | 26.84 |
| Ours | 78.02 | 63 | 73 | 84.64 | 39.79 |
| z/mm | Absolute Visual Positioning Error | |||
|---|---|---|---|---|
| x/mm | y/mm | z/mm | β/° | |
| 1000 | 2.76 | 1.42 | 0.95 | 0.57 |
| 1250 | 1.45 | 2.65 | 2.75 | 0.43 |
| 1500 | 1.87 | 4.11 | 4.81 | 0.97 |
| 1750 | 2.66 | 3.67 | 6.29 | 0.96 |
| 2000 | 3.98 | 4.74 | 3.79 | 1.15 |
| 2250 | 5.86 | 5.48 | 5.24 | 1.68 |
| 2500 | 4.86 | 7.59 | 9.43 | 1.18 |
| 2750 | 6.54 | 6.41 | 8.31 | 1.09 |
| 3000 | 9.19 | 7.51 | 12.15 | 0.51 |
| MAE | 4.35 | 5.02 | 5.75 | 0.86 |
| STD | 2.38 | 1.64 | 2.90 | 0.37 |
| β/° | Absolute Visual Positioning Error | |||
|---|---|---|---|---|
| x/mm | y/mm | z/mm | β/° | |
| −30 | 0.93 | 0.52 | 1.76 | 1.67 |
| −20 | 1.22 | 1.23 | 3.43 | 1.54 |
| −10 | 1.46 | 1.21 | 3.96 | 1.09 |
| 0 | 1.08 | 4.89 | 3.22 | 0.79 |
| 10 | 2.78 | 3.76 | 4.98 | 1.98 |
| 20 | 1.88 | 5.27 | 4.17 | 2.08 |
| 30 | 3.78 | 5.78 | 6.54 | 1.81 |
| MAE | 1.73 | 3.88 | 3.86 | 1.57 |
| STD | 0.98 | 1.97 | 1.17 | 0.41 |
| Illumination | Background | Absolute Visual Positioning Error | |||
|---|---|---|---|---|---|
| x/mm | y/mm | z/mm | β/° | ||
| Normal | Simple | 2.76 | 1.42 | 0.95 | 0.57 |
| Normal | Moderately complex | 2.98 | 2.53 | 1.04 | 0.65 |
| Normal | Complex | 3.45 | 2.67 | 1.20 | 0.72 |
| Low | Simple | 4.20 | 3.17 | 1.35 | 0.85 |
| Low | Moderately complex | 4.51 | 3.52 | 1.67 | 0.96 |
| Low | Complex | 5.10 | 4.27 | 1.70 | 1.10 |
| High | Simple | 3.10 | 1.51 | 1.10 | 0.65 |
| High | Moderately complex | 3.78 | 2.73 | 1.27 | 0.71 |
| High | Complex | 3.97 | 3.10 | 1.36 | 0.75 |
| MAE | 3.76 | 2.77 | 1.29 | 0.77 | |
| STD | 0.73 | 0.85 | 0.25 | 0.16 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, B.; Wang, S.; Lu, Y.; Yi, Y.; Jiang, D.; Qiao, M. A New Pallet-Positioning Method Based on a Lightweight Component Segmentation Network for AGV Toward Intelligent Warehousing. Sensors 2025, 25, 2333. https://doi.org/10.3390/s25072333
Wu B, Wang S, Lu Y, Yi Y, Jiang D, Qiao M. A New Pallet-Positioning Method Based on a Lightweight Component Segmentation Network for AGV Toward Intelligent Warehousing. Sensors. 2025; 25(7):2333. https://doi.org/10.3390/s25072333
Chicago/Turabian StyleWu, Bin, Shijie Wang, Yi Lu, Yang Yi, Di Jiang, and Mengmeng Qiao. 2025. "A New Pallet-Positioning Method Based on a Lightweight Component Segmentation Network for AGV Toward Intelligent Warehousing" Sensors 25, no. 7: 2333. https://doi.org/10.3390/s25072333
APA StyleWu, B., Wang, S., Lu, Y., Yi, Y., Jiang, D., & Qiao, M. (2025). A New Pallet-Positioning Method Based on a Lightweight Component Segmentation Network for AGV Toward Intelligent Warehousing. Sensors, 25(7), 2333. https://doi.org/10.3390/s25072333