1. Introduction
Rotary mechanisms are extensively utilized in a variety of functional machinery across industries such as agriculture, wind power, and transportation, where they play a crucial role in transmitting motion and converting torque. Bearings, as a vital component of these rotary mechanisms, have a direct impact on the efficient and stable operation of functional machinery. The real-time acquisition of bearing health status and the formulation of maintenance strategies in accordance with this status can effectively enhance the overall economy, safety, and stability of the machinery [
1].
Given the importance of bearing health assessment, various signal processing and diagnostic approaches have been developed over the years, including both traditional techniques based on time-domain or frequency-domain analysis and modern machine learning-based methods [
2]. Although traditional time-domain and frequency-domain signal processing methods (e.g., FFT-based spectral analysis) have been widely used in bearing fault diagnosis, these approaches rely heavily on handcrafted feature engineering and expert knowledge. Furthermore, they often struggle to capture complex, nonlinear fault patterns, especially under varying operational conditions or in noisy environments. In contrast, machine learning-based models, especially deep learning techniques, offer superior performance by automatically learning hierarchical features directly from raw or preprocessed data. This allows them to generalize better across different fault types and operating conditions [
3]. Deep learning-based fault diagnosis models are a vital means of perceiving bearing health. With the advancement of related software and hardware, the deployment of these models has become increasingly convenient, highlighting their efficiency and accuracy. Consequently, they are being widely applied in various fields for bearing fault diagnosis [
4,
5,
6]. The construction of deep learning-based fault diagnosis models relies on sufficiently large and balanced datasets. However, in industrial practice, bearings mostly operate normally, and faults, when they occur, typically affect machinery operation and are promptly addressed. The timing and location of bearing faults are influenced by surrounding components and loads, making them difficult to predict. This results in a scarcity of high-quality bearing fault samples and an imbalance in the quantity of different fault samples, leading to an imbalanced bearing fault dataset.
In recent years, GANs have been increasingly used to address the issue of imbalanced bearing fault data [
7,
8]. The reason for this is that GANs, through adversarial learning, can effectively learn the characteristics of real data and generate new data that closely resemble the real data [
9,
10]. Huang et al. [
11] enhanced their generative model by incorporating a data autoencoder at the input stage and optimizing the discriminator’s loss function, thereby generating one-dimensional signals with a probability distribution closely resembling real data, exhibiting heightened resilience to label noise and efficaciously supporting fault diagnosis in wind turbine gearbox bearings. Li et al. [
12] leveraged the GRU network’s prowess in time-series data handling, integrating a positional attention mechanism and a calibration technique for fault pulse probability distributions, thereby crafting a GAN generator that meticulously preserves temporal fault data integrity, yielding more precise and realistic fault signal synthesis. Luo et al. [
13] proposed the Enhanced Relative Generative Adversarial Network, a model featuring one-dimensional convolutional layers and spectral normalization layers to reconstruct its generator and discriminator, thereby improving the adaptability of network parameters to gradient penalty calculations, enhancing the ability to capture fault features, and reducing sensitivity to data quantity, allowing the generation of high-quality one-dimensional vibration signals to address the issue of imbalanced bearing fault data. Liu et al. [
14] utilized optimized CNNs within the GAN model to better learn data features and generate higher-quality one-dimensional vibration signals, thereby addressing the issue of data imbalance. Luo et al. [
15] proposed the DWGANGP model, which is designed to generate one-dimensional vibration signals that exhibit characteristics similar to the original samples.
The aforementioned literature employs the adversarial structure of GANs to learn features from the time domain of bearing fault vibration signals, generating fault data whose time-domain feature distribution closely resembles that of real samples, thereby addressing data imbalance issues. Simultaneously, the frequency domain of bearings also contains abundant fault information. Many scholars utilize GAN methods to generate data with similar frequency domain distributions, balancing the fault dataset and thus constructing fault diagnosis models. Zhang et al. [
16] proposed a Convolutional Block Attention Mechanism Conditional Regularized Least Squares Generative Adversarial Network (CBAM-CRLSGAN), which learns genuine fault features from frequency-domain samples procured via Fourier transform, thereby generating high-quality fault data utilized to establish a diagnostic model. Wang et al. [
17] proposed a deep convolutional conditional generative adversarial network (DCCGAN) model based on a CNN, which learns the feature distribution of real data from frequency-domain data obtained through Fourier transform, generating high-quality fault samples to address the issue of imbalanced data in rotating machinery fault diagnosis. Tao et al. [
18] utilize short-time Fourier transform (STFT) to convert the original 1-D vibration signals into 2-D time–frequency maps, and then train a CatGAN model to generate fake samples with a similar distribution to the real time–frequency maps. The ST-CatGAN method can effectively identify mixed fault conditions without manual labeling and demonstrates strong robustness. Wang et al. [
19] propose a semisupervised auxiliary classifier generative adversarial network (SACGAN) that also utilizes the STFT to convert one-dimensional time-domain vibration signals of bearings into two-dimensional time–frequency images, which serve as the input for the SACGAN to generate high-quality multi-mode fault samples. Liu et al. [
20] proposed the condition multidomain generative adversarial network (CMDGAN), which employs a self-adaptive feature extraction module to generate sample labels, utilizes binary discriminators for supervised adversarial training, and integrates time-domain and frequency-domain information to effectively capture the distribution features of limited original samples, resulting in generated samples that resemble the original samples in both the time and frequency domains. Liu et al. [
21] propose an improved multi-scale residual generative adversarial network (MsR-GAN), which extracts two-dimensional time–frequency features from the original vibration signals using frequency slice wavelet transform (FSWT) to generate high-quality time–frequency features for balancing the fault data distribution, and finally constructs a fault diagnosis model based on the balanced data. Zhao et al. [
22] employed an autoencoder to evaluate the similarity and filter the generated 2D images, which are obtained through the wavelet transform, thereby enhancing the diversity of GAN-generated samples and producing high-quality time–frequency samples that can effectively mitigate the issue of data imbalance in mechanical system fault diagnosis.
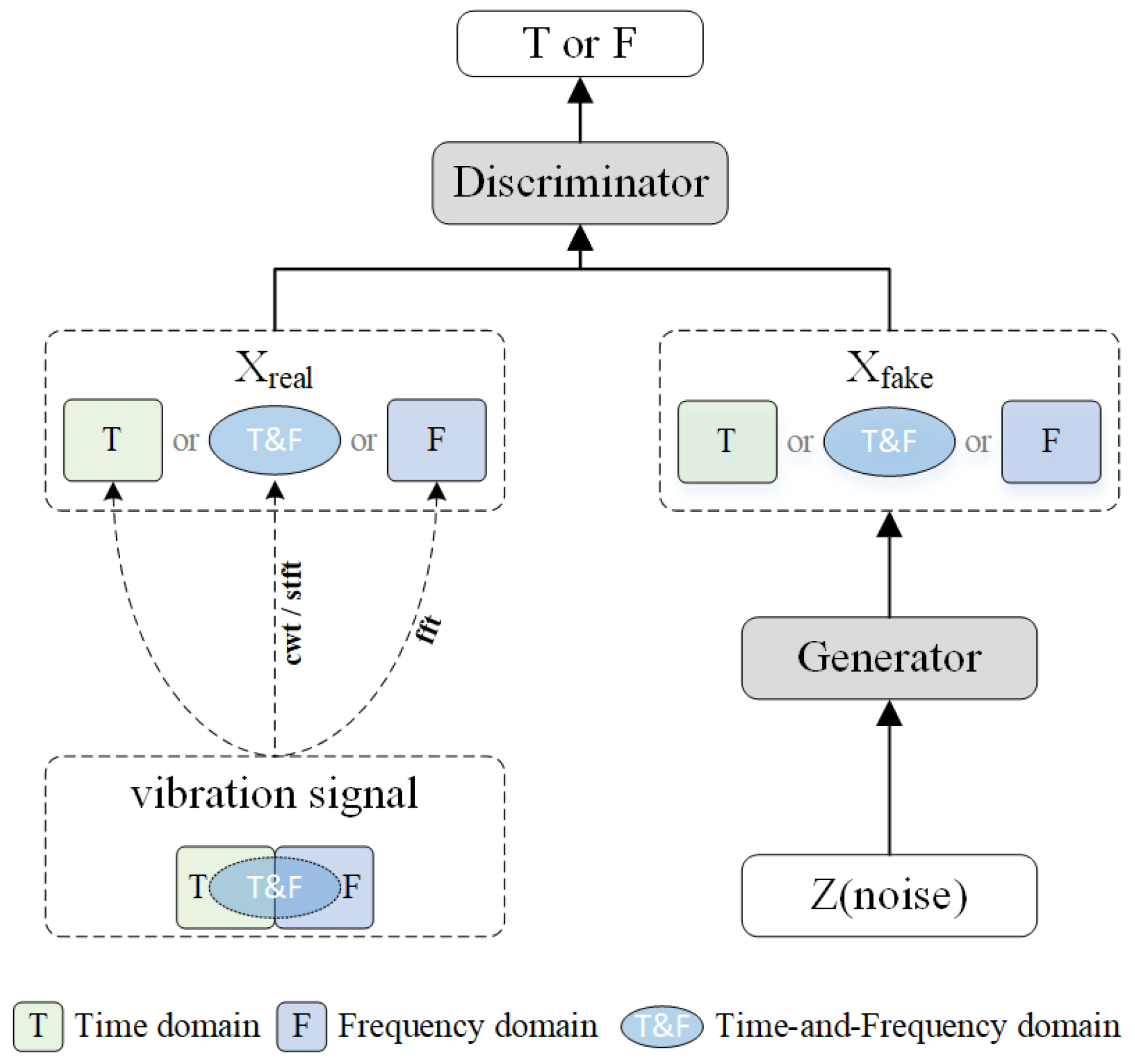
As highlighted by the literature review, the main optimization focus for addressing data imbalance with GANs lies in enhancing the model’s feature extraction capabilities and improving the stability of the training process [
23,
24]. The goal is to enable the GAN to generate samples that are more similar to the training set at the feature level, thus helping to balance the dataset. However, there has been limited exploration of the consistency of the frequency-domain information in the one-dimensional vibration signals generated by GANs and the time-domain information in the spectral maps when compared to the actual training samples. This oversight is largely due to the original design of GANs, which aims to generate samples similar to the training set at the feature level, naturally neglecting aspects not covered in the training data. As illustrated in
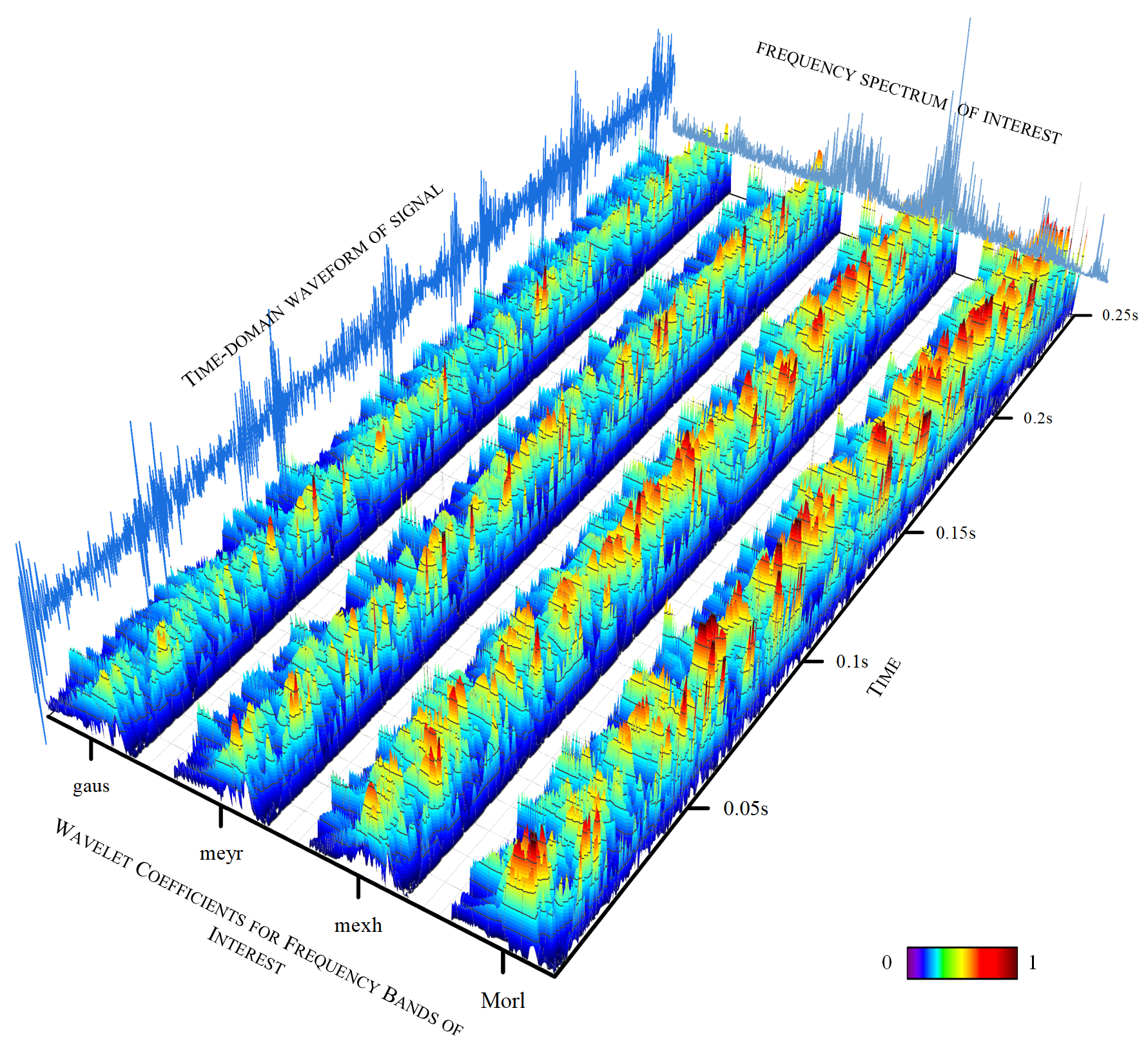
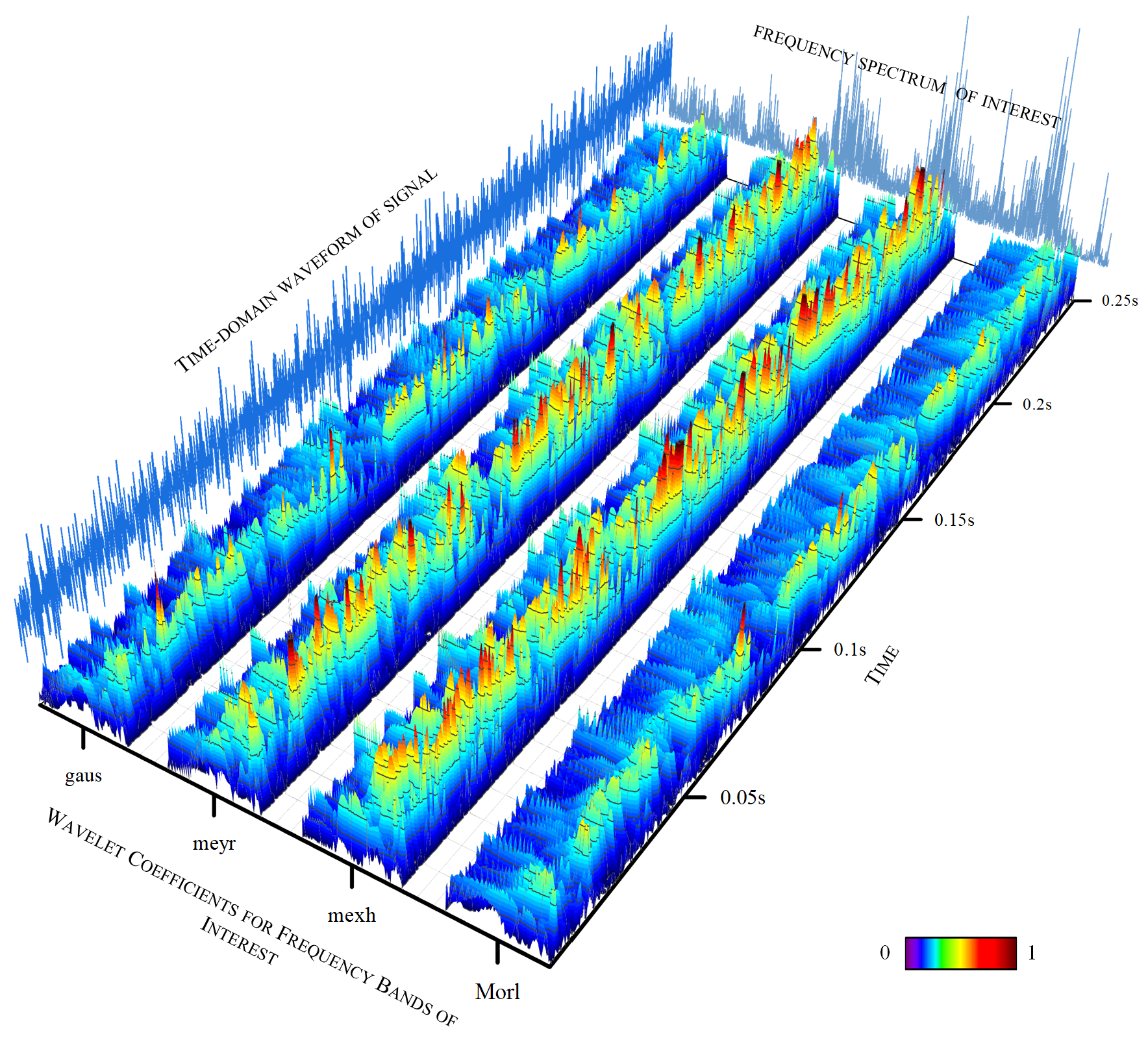
Figure 1, the vibration signals from faulty bearings typically contain three types of information: time-domain, frequency-domain (usually obtained through Fourier transform), and time–frequency domain (usually obtained through wavelet transform or short-time Fourier transform). However, due to the limitations of traditional GAN models, the generator can typically only utilize one type of information, such as if X_real is time-domain, making it nearly impossible for X_fake to generate frequency-domain data.
Although the time-domain and frequency-domain information in faulty bearing vibration signals contains rich fault characteristics, and using GAN networks to generate fault data can effectively address the imbalance in bearing fault data, when bearings are affected by surrounding components, resulting in a low signal-to-noise ratio, extracting comprehensive feature information from the fault data becomes crucial to significantly improve the performance of the fault diagnosis model [
25,
26]. If the samples used by the GAN contain only one type of information, even with an excellent feature extractor, discrepancies may still exist between the generated samples and the real training set. Consequently, the high-dimensional feature distribution extracted by a fault diagnosis model built on such a dataset may not align with the feature distribution based on real samples, potentially compromising the model’s accuracy. Therefore, to effectively mitigate the data imbalance issue in bearing fault diagnosis, the GAN model should fully utilize diverse types of data, which is a key strategy for improving the accuracy of the fault diagnosis model [
27,
28].
Like traditional GAN models, existing ensemble learning methods encounter comparable issues in the use of training set samples. These studies, [
29,
30,
31,
32], have employed ensemble learning approaches and incorporated feature extraction networks optimized through various methods, enabling fault diagnosis models based on ensemble learning to more effectively utilize the characteristic information embedded in the signals. However, these training set samples also use time-domain, frequency-domain, or partial time–frequency data from fault signals individually.
To fully exploit the fault feature information in both the time and frequency domains of bearing signals, and to address the accuracy issues of bearing fault diagnosis models affected by data imbalance, a novel method that integrates AWLT-GAN and ensemble learning is proposed. This method generates high-quality training samples via AWLT-GAN, enabling the ensemble learning-based fault diagnosis model to more effectively harness the fault information within the signals, thereby enhancing the precision of fault diagnosis. The main contributions of this paper can be summarized as follows:
AWLT-GAN combines the adaptive wavelet-like transform (AWLT) with generative adversarial networks (GANs) to enhance the learning of both time- and frequency-domain features in a single training iteration. This integration allows the model to generate synthetic fault data with higher fidelity and accuracy, particularly in imbalanced datasets. Compared to traditional GAN models, the AWLT-GAN introduces a novel dual-discriminator structure, which significantly improves the diagnostic performance by effectively capturing complex signal characteristics in both domains.
The adaptive wavelet-like transform neural network (AWLT) is specifically designed to overcome the limitations of conventional wavelet transforms in fault diagnosis. This network establishes a mapping between the time and frequency domains of the signal, allowing for the adaptive selection of wavelet basis functions based on the signal’s characteristics. This innovation ensures superior extraction of both time- and frequency-domain features in a single iteration, leading to more accurate and diverse fault data generation.
An advanced ensemble learning framework is introduced, combining 1D CNN models for time-domain feature extraction with 2D CNN models for frequency-domain analysis. This comprehensive approach leverages soft voting mechanisms to achieve more accurate fault diagnosis. By integrating both time- and frequency-domain data, the ensemble model provides superior classification performance compared to models that rely solely on one type of feature, thus improving the robustness of the diagnosis under varying operational conditions.
The main contents of this paper are as follows.
Section 2 describes the basic theory.
Section 3 gives the construction process of the proposed method.
Section 4,
Section 5 and
Section 6 show the results of the experiments and the comparison of the different methods.
Section 7 concludes the whole article.
3. Proposed Method
3.1. Adaptive Wavelet Transform
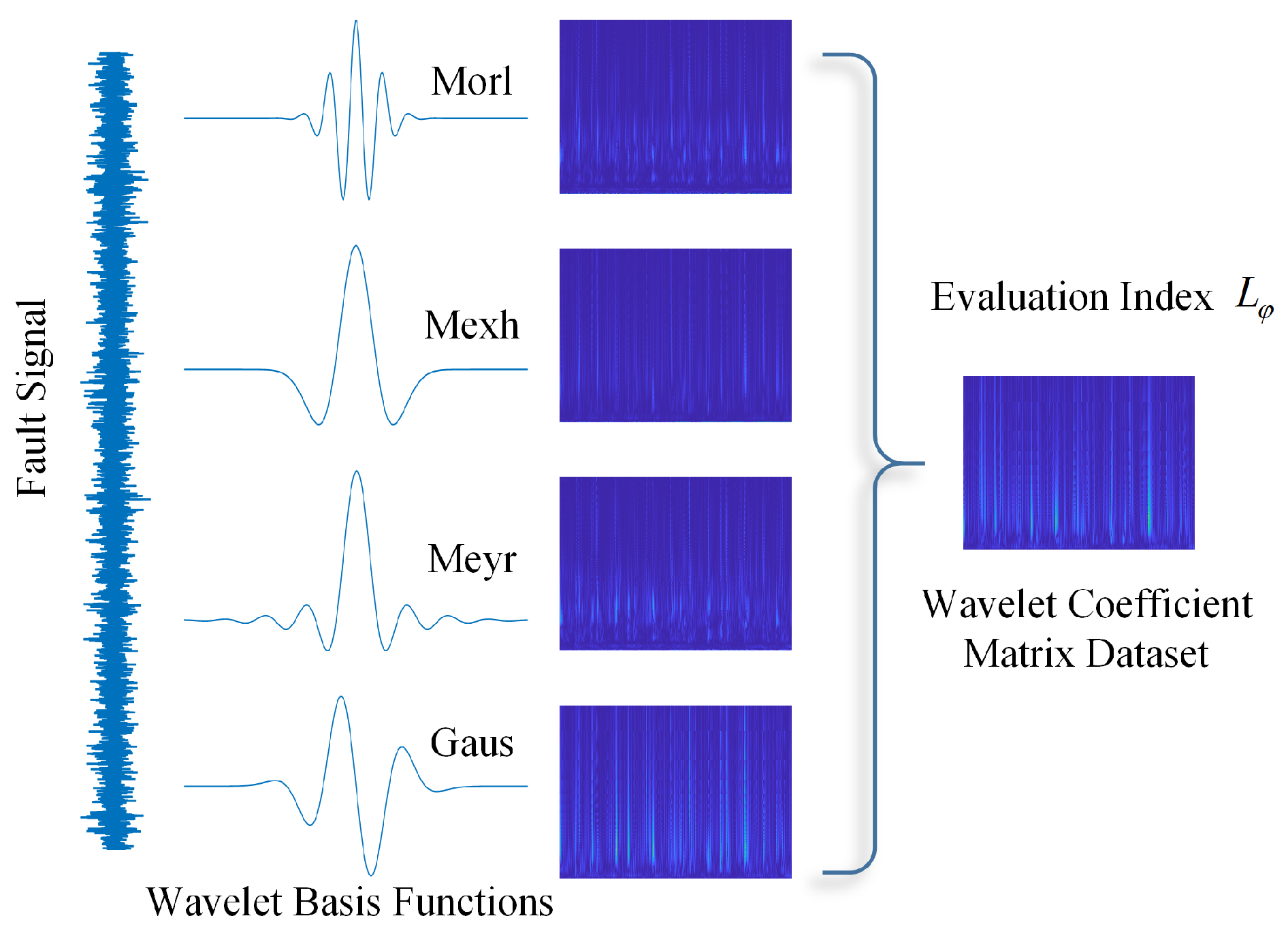
Wavelets come in various types of base functions, which provide engineers with flexibility and variability in signal analysis. For the same signal, wavelet spectra obtained using different base functions are different, and selecting an appropriate base function can highlight the feature information of interest in the signal. By providing an appropriate evaluation index for the wavelet transform results, the computer can quickly filter out suitable base functions, laying a data foundation for the construction of the wavelet neural network. To this end, an index for evaluating the quality of the wavelet transform results has been introduced. Based on this index, the wavelet basis function can be adaptively selected during the wavelet transform of the signal, yielding a wavelet coefficient matrix that best represents the fault characteristics of the signal. Subsequently, a more optimized dataset of wavelet coefficient matrices can be obtained. The specific method is illustrated in the
Figure 2.
Once the fault characteristics of interest are identified, the wavelet coefficient energy can be used as an indicator of the energy of the fault characteristics in the signal. The formula is as follows:
If the characteristic of interest is present in the signal and has a high similarity to the wavelet basis function, then after the wavelet transform, the energy indicator will be greater when the scale factor is a. Therefore, this can be used as one of the criteria for selecting the wavelet basis function.
If the energy measurement values are the same, due to the impact characteristics of bearing faults, a suitable wavelet basis function should have more concentrated energy in the time direction, i.e., its entropy value should be low. A selection criterion based on Multi-Scale Reverse Dispersion Entropy [
35] can be designed as follows:
where
c is the number of classes,
m is the embedding dimension,
is a dispersion pattern related to W, and
is the probabilities for each dispersion pattern. The specific settings can be referred to in [
35,
36,
37].
A suitable wavelet basis function should maximize
and
. Therefore, the objective function for selecting the wavelet basis function is
where
is the wavelet basis function and
A is the set of candidate wavelet basis functions. Based on the literature review, the candidate wavelet basis functions in this study are as follows: Morlet wavelet, Mexican Hat wavelet, Meyer wavelet, and Gaussian wavelet.
The joint optimization of
(Equation (
7)) ensures the selected basis simultaneously maximizes fault signature prominence in both time and frequency domains while avoiding artifacts from predefined basis mismatch (e.g., Morlet’s oscillations may dilute transient impacts). The implementation involves three steps: 1. Compute wavelet coefficients
for all candidate bases
. 2. Calculate
across scales
a. 3. Select the basis
. This process adaptively tailors the wavelet analysis to each signal’s unique fault characteristics, as visualized in
Figure 2.
Unlike traditional wavelet transforms that use a fixed basis function (e.g., Morlet), the adaptive mechanism in the AWLT dynamically selects the most informative basis based on energy and entropy metrics (Equation (
7)). This ensures the time–frequency representation aligns with fault characteristics, enhancing the generator’s ability to synthesize realistic vibration patterns under variable operating conditions.
3.2. Adaptive Wavelet-like Transform Neural Networks
The signal can be transformed using wavelet transform to obtain a wavelet coefficient matrix, which inherently represents the values of the inner product between the wavelet, varying with scale and translation factors, and the signal. This reflects the frequency distribution of the signal at different times. Given the wavelet coefficient matrix and the wavelet function, the signal can also be reconstructed using the inverse wavelet transform. Inspired by autoencoders (AEs), the wavelet transform and inverse transform can be viewed as two mappings, which can be replaced by multi-layer neural networks through iterative learning, resulting in a wavelet-like transform neural network. Neural networks excel at handling complex nonlinear relationships and can learn more complex mappings than traditional wavelet transforms through training, thus better adapting to the nonlinear characteristics in practical applications. Integrating wavelet-like transform neural networks into the GAN model can enhance the performance of the entire system, rather than focusing solely on the effect of a single step in the wavelet transform.
3.3. Adaptive Wavelet-like Transform Neural Network
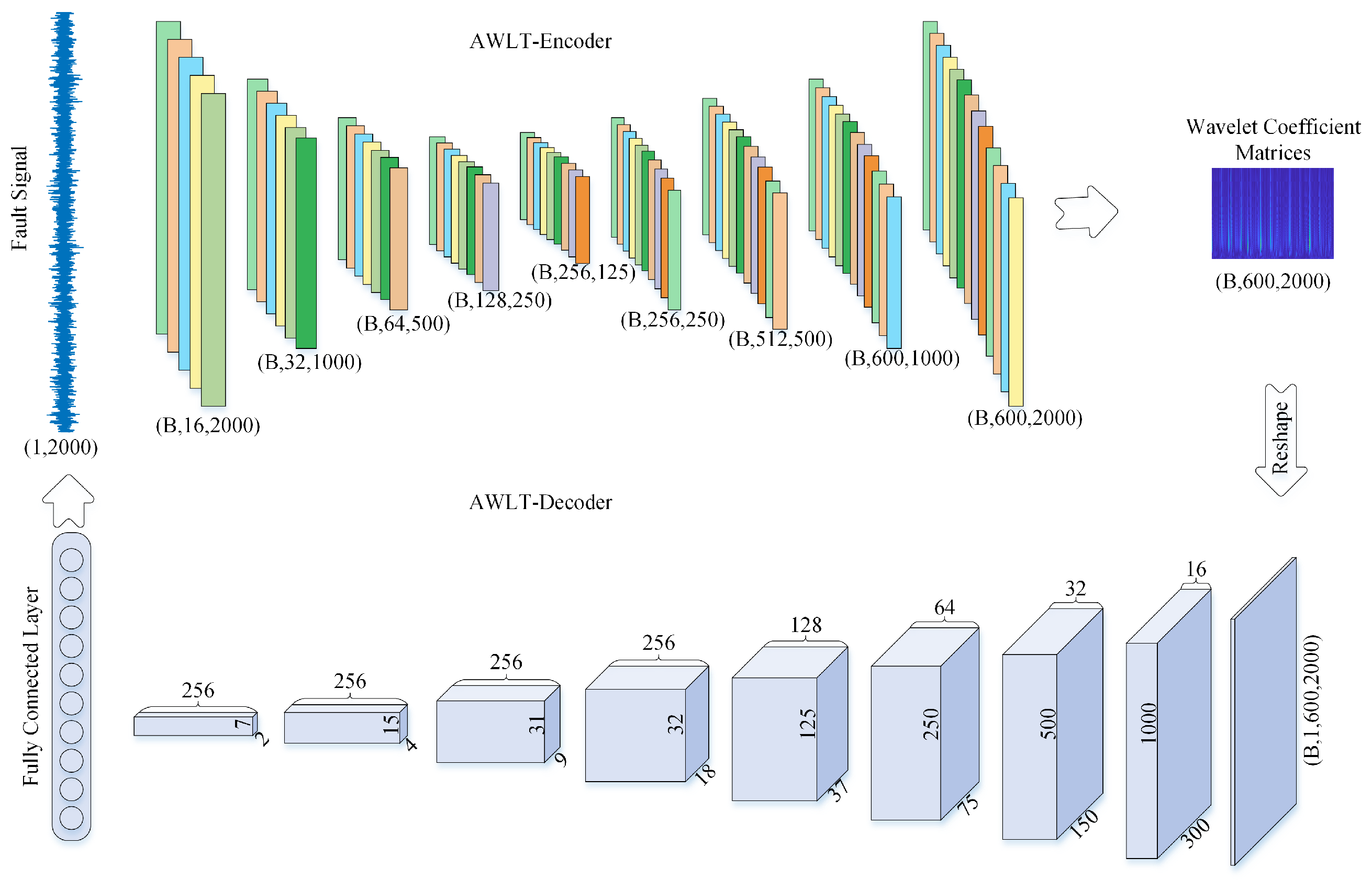
A one-dimensional vibration signal can be transformed into a two-dimensional wavelet coefficient matrix through wavelet transform, which captures time–frequency characteristics of the signal. Conversely, the inverse wavelet transform reconstructs the original signal from this matrix. The proposed adaptive wavelet-like transform neural network (AWLT) implements this bidirectional mapping via an encoder–decoder architecture, as illustrated in
Figure 3.
3.3.1. AWLT-Encoder: Time-to-Time–Frequency Mapping
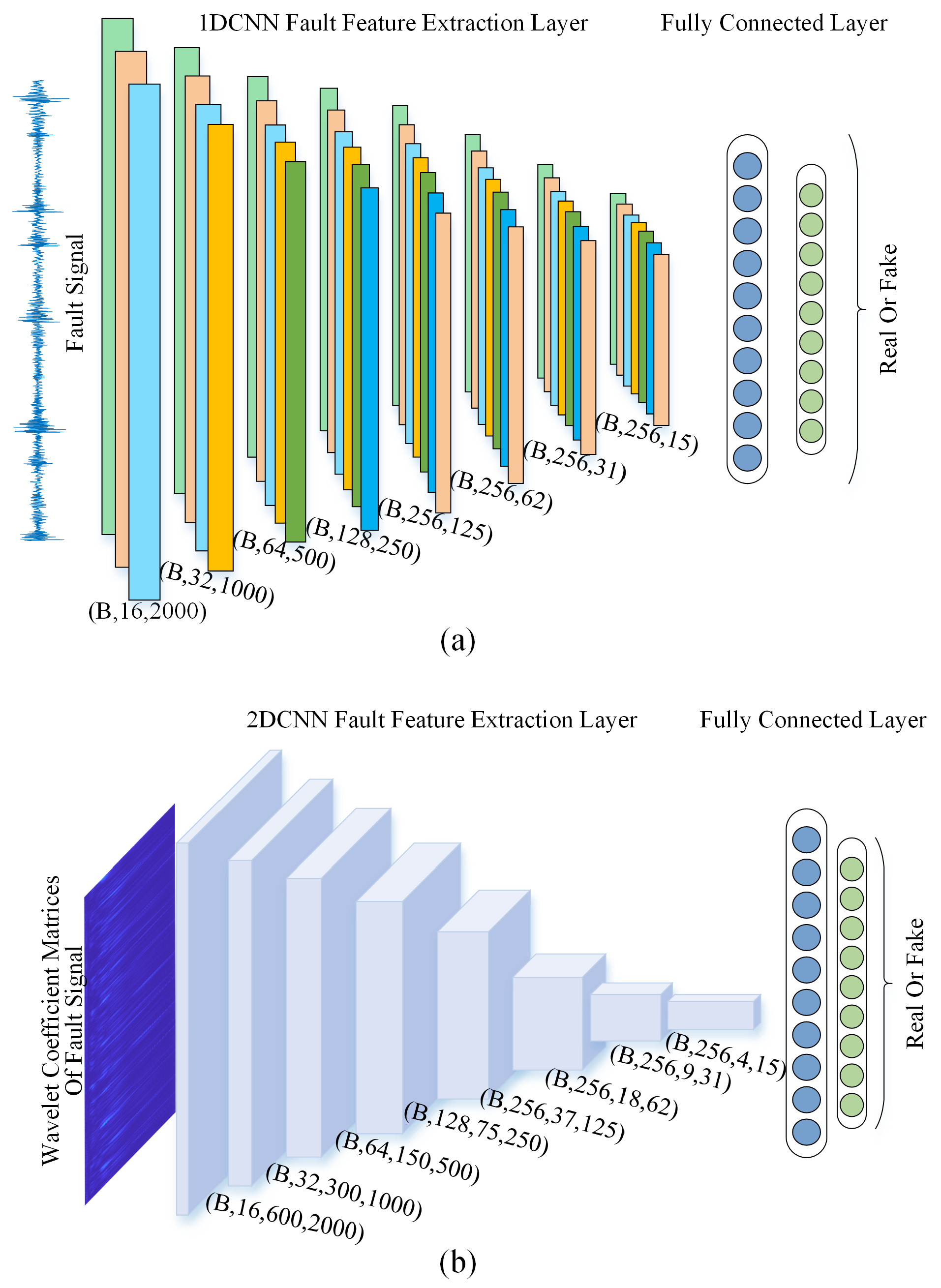
The encoder processes a fixed-length vibration signal of dimensions , where B denotes the batch size, through a hierarchical 1D convolutional network:
Input Layer: Raw signal .
Network Architecture: Hierarchical structure with downsampling and upsampling blocks. Detailed configurations are listed in
Table 1. (Note: transposed convolutions include output padding adjustments to align dimensions).
Output: A 2D wavelet coefficient matrix of dimensions .
The encoder is optimized by minimizing the Mean Squared Error (MSE) between predicted and reference wavelet coefficients (Equation (
8)).
3.3.2. AWLT-Decoder: Time–Frequency-to-Time Mapping
The decoder reconstructs the original signal from the wavelet coefficient matrix through an inverse mapping:
Input: Reshaped wavelet coefficients .
Feature Extraction Blocks: Eight 2D convolutional layers downsample the time–frequency representation. Detailed configurations are listed in
Table 2. (Note: Output dimensions are given in (Channels, Length) format. All convolutional layers use ReLU activation and Batch Normalization).
Reconstruction: The final feature map is flattened and passed through a fully connected layer to reconstruct the original signal with dimensions .
The decoder is trained using MSE loss between
and
, combined with
–
regularization terms (
) to enhance sparsity and prevent overfitting.
where
is the wavelet coefficient matrix generated by the encoder.
is the signal reconstructed by the decoder.
and
are the
regularization weights.
and
are the weights in the neural network.
3.4. Architecture of AWLT-GAN
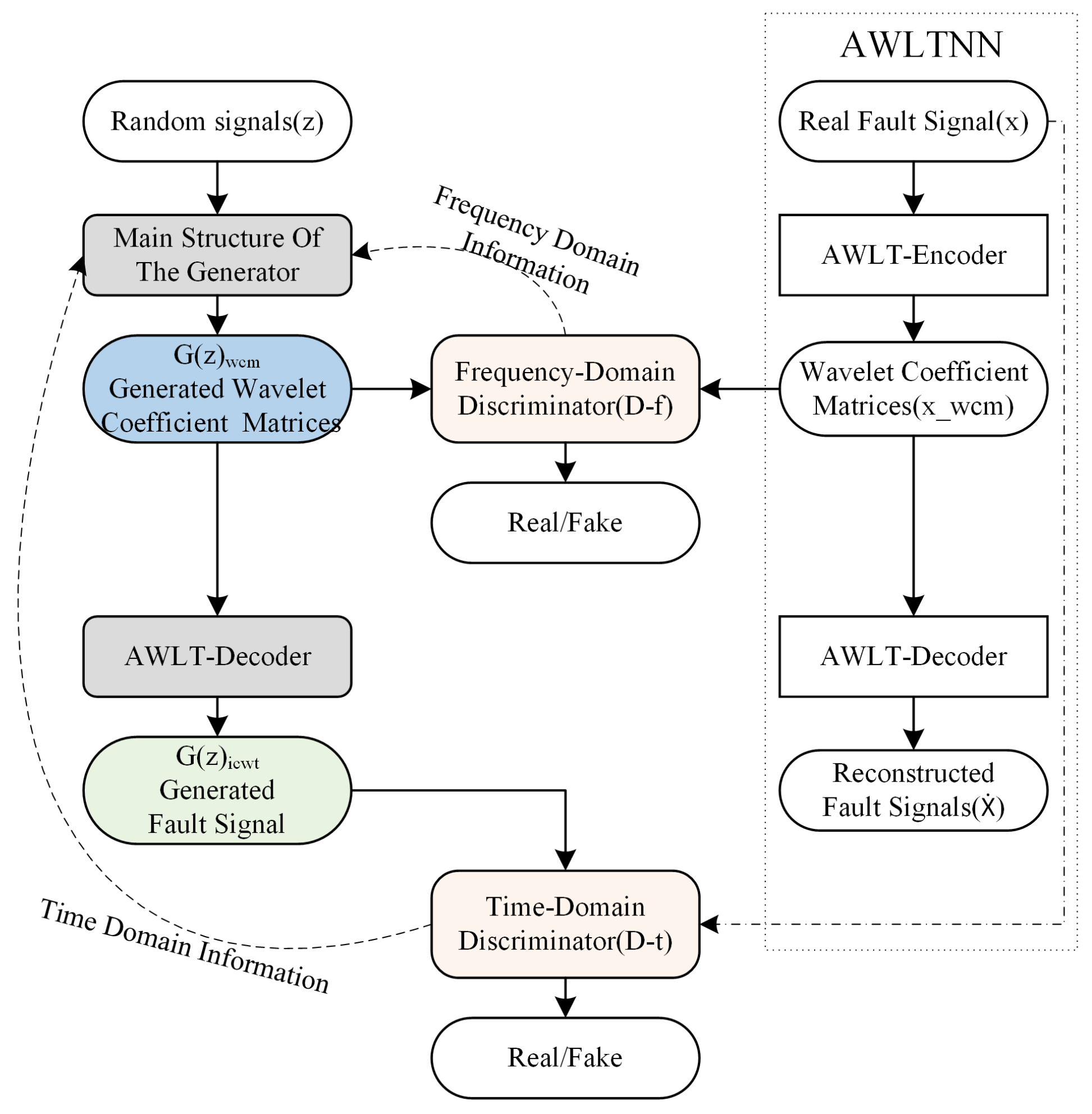
Typical GAN network structures usually include a generator and a discriminator. The differences between real data and generated data are computed by the discriminator, and the generator’s parameters are updated via backpropagation to learn the features of the real data. When the input to the discriminator is either real time-domain or frequency-domain data, the generator can only learn part of the real data’s features due to the limitations of the GAN model structure. By embedding an adaptive wavelet-like transform neural network into the generator of the GAN, the generator first generates a wavelet coefficient matrix, which is then converted into a vibration signal. Correspondingly, two discriminators are constructed so that in one iteration, the discriminator can evaluate both the local time–frequency feature wavelet coefficient matrix and the time-domain feature vibration signal. Through backpropagation, the generator’s parameters are simultaneously updated, enabling the generated signal to possess more complete tim- domain and frequency-domain attributes.
The structure of the AWLT-GAN is shown in
Figure 4. It includes two discriminators and one generator. The generator consists of two parts: the main generator and the adaptive wavelet-like decoding layer. The two discriminators are the frequency-domain discriminator
and the time-domain discriminator
. The frequency-domain discriminator’s role is to distinguish whether the wavelet coefficient matrix with frequency-domain characteristic information is transformed from a real signal or generated by the generator. The time-domain discriminator’s role is to distinguish whether the vibration signal with time-domain characteristic information is real or generated by the generator.
The generator of the AWLT-GAN is composed of two parts: the main structure of the generator is the same as the adaptive wavelet-like transform encoder, and the adaptive wavelet-like decoding layer structure is the same as the adaptive wavelet-like transform decoder. During training, the parameters of the wavelet-like decoding layer are fixed, and the parameters of the main structure are primarily updated. The loss function is as shown in Equation (
9).
where
is the probability distribution of the wavelet coefficient matrix
obtained through noise
z,
is the probability distribution of the vibration signal
generated by noise z,
is the discriminator function in the frequency domain, and
is the discriminator component in the time domain.
The constructed AWLT-GAN contains two discriminators with different functions: Time-Domain Discriminator (): processes raw vibration signals to evaluate time-domain authenticity. Frequency-Domain Discriminator (): analyzes wavelet coefficient matrices to assess time–frequency characteristics.
To stabilize adversarial training, both discriminators employ the Wasserstein distance with a gradient penalty term (Equations (
10) and (
11)), effectively mitigating gradient vanishing and mode collapse. The network architectures are illustrated in
Figure 5, with detailed layer configurations provided below.
where
p is the distribution of the sample
x,
is the gradient penalty term for the time-domain discriminator, and
denotes the uniform sampling of the time-domain generated samples and the real samples.
where
is the distribution of the wavelet coefficient matrix
obtained through wavelet transform of the sample
x,
is the gradient penalty term for the frequency-domain discriminator,
is the gradient penalty coefficient,
denotes the uniform sampling of the frequency-domain generated samples and the real samples,
is the gradient of the frequency-domain discriminator’s output results for
, and
is the L2 norm.
3.4.1. Time-Domain Discriminator ()
The discriminator takes a vibration signal of dimensions as input and processes it through a hierarchical 1D convolutional network:
3.4.2. Frequency-Domain Discriminator ()
The discriminator operates on wavelet coefficient matrices of dimensions , extracting joint time–frequency features:
The AWLT-GAN employs a dual-discriminator design to enforce fidelity in both time and frequency domains. The time-domain discriminator () evaluates the raw vibration signals, promoting accurate waveform reconstruction and temporal pattern learning. In contrast, the frequency-domain discriminator () analyzes the corresponding wavelet coefficient matrices (WCMs), guiding the generator to preserve time–frequency structures essential for fault characterization.
During training, the generator receives simultaneous feedback from both discriminators, and its parameters are updated accordingly in a joint optimization scheme. This strategy encourages the generation of signals that are not only realistic in the time domain but also maintain spectral integrity in the frequency domain. This dual-domain supervision enables AWLT-GAN to outperform conventional GANs with a single discriminator, especially in capturing complex fault signatures embedded in both domains.
3.5. Ensemble Learning Fault Diagnosis Model
Ensemble learning constructs several models with different characteristics and aggregates them according to a certain combination strategy, forming a model that has better generalization and accuracy than a single model. For time-domain vibration signals, one-dimensional convolution processes the signals by computing correlations in one dimension only, resulting in relatively low computation, faster processing, and more effective capture of contextual information along the time dimension, thus better extracting the time-domain features of the signal. For spectrograms obtained through wavelet transform, two-dimensional convolution can simultaneously capture both time and frequency information, comprehensively understanding the time–frequency characteristics of the signal and thus better extracting frequency-domain features.
To fully utilize both the time-domain and frequency-domain features of bearing fault signals and further enhance the effectiveness of the fault diagnosis model, this paper constructs two fault diagnosis models. The first model, based on one-dimensional convolution, primarily processes time-domain signals to extract time-domain features for fault diagnosis. Its feature extraction backbone is similar to the time domain discriminator of AWLT-GAN, utilizing one-dimensional convolutional modules, followed by two fully connected layers with a softmax activation function to output bearing fault types. To prevent overfitting, a dropout layer with a parameter set to 0.3 is added between the two fully connected layers. The second model, based on two-dimensional convolution, primarily processes the spectrograms obtained from the wavelet transform. Its feature extraction backbone is similar to the frequency-domain discriminator of AWLT-GAN, also using two-dimensional convolutional modules for feature extraction, with the remaining parts being similar to the first model. Finally, the two fault diagnosis models are combined through soft voting. In this study, an equal-weighted soft voting strategy was adopted, where the output probabilities of the time-domain and frequency-domain classifiers were averaged (i.e., weight = 0.5 for both). This simple and effective approach was chosen based on preliminary experiments, which showed no significant performance gain from weight tuning.
3.6. Workflow of Proposed Method
The workflow of the bearing fault diagnosis method based on AWLT-GAN and ensemble learning is shown in
Figure 6, which includes the following main steps:
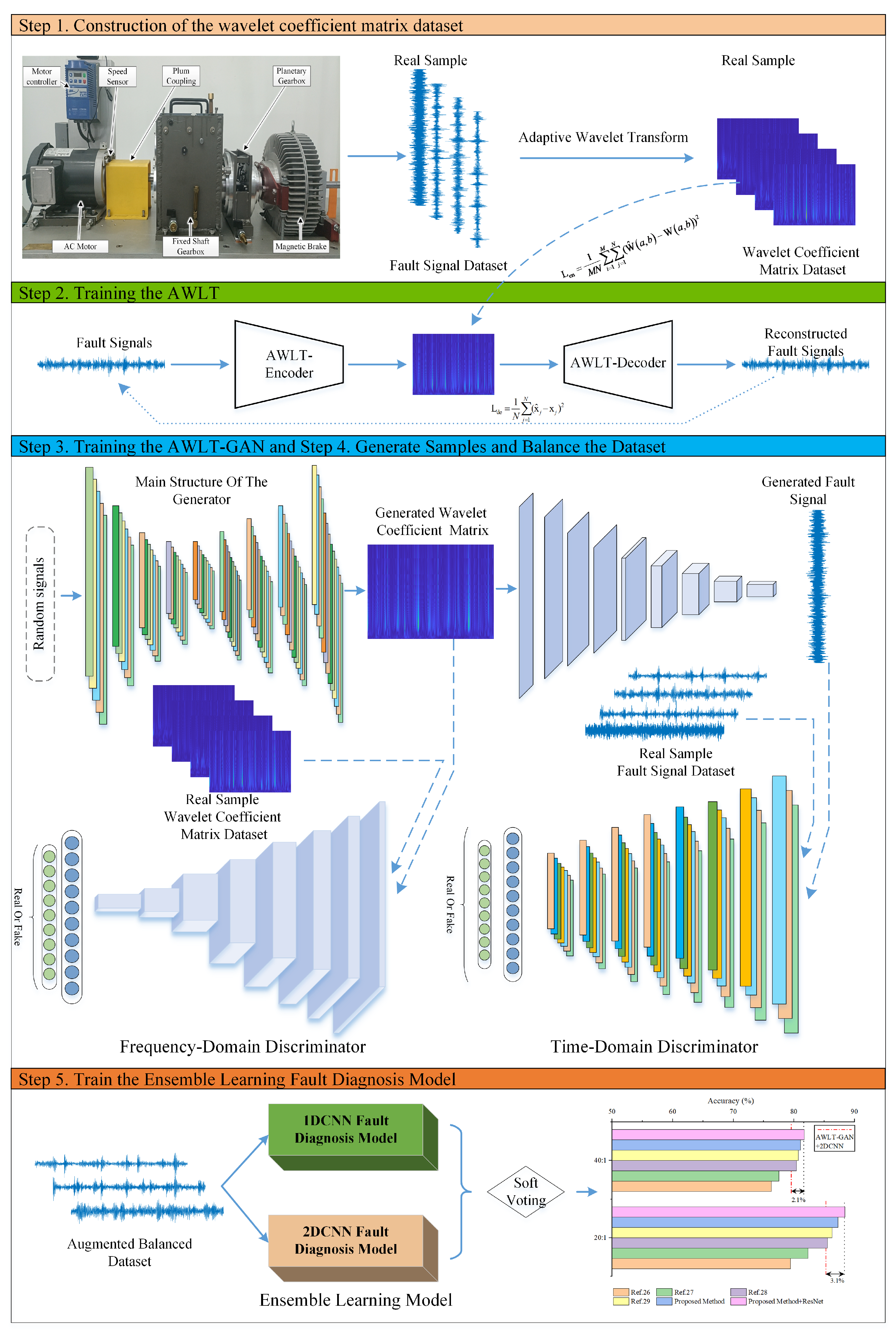
Step 1. Construction of the wavelet coefficient matrix dataset. Perform wavelet transform on the vibration signals using different wavelet basis functions, and select the wavelet coefficient matrix corresponding to the maximum as the output result of the current vibration signal’s wavelet transform.
Step 2. Training the AWLT. Use real data as input to train the encoder and decoder of the adaptive wavelet-like transform neural network, determining the network parameters.
Step 3. Training the AWLT-GAN. During training, fix the parameters of the generator’s decoding layer and only update the parameters of the main generator network. To avoid overfitting of the generator and ensure the quality of generated data, iterate the discriminator and generator at a 2:1 ratio within one training cycle.
Step 4. Generate Samples and Balance the Dataset. Use the trained AWLT-GAN network to generate bearing fault data, expanding and balancing the dataset.
Step 5. Train the ensemble learning fault diagnosis model. Use the balanced dataset to separately train the time-domain and frequency-domain fault diagnosis models, and then determine the bearing fault types through a soft voting method.
Figure 6.
Flowchart of proposed bearing fault diagnosis method using AWLT-GAN and ensemble learning.
Figure 6.
Flowchart of proposed bearing fault diagnosis method using AWLT-GAN and ensemble learning.
5. Experiment II: Imbalanced Fault Diagnosis
The aforementioned experiments indicate that AWLT-GAN can effectively improve the quality of generated data. However, it is important to note that these experiments were conducted with a certain amount of real data. In industrial practice, due to limitations in the installation environment of data collection hardware and the occasional and random nature of faults, only a limited amount of effective fault data can usually be collected. This results in a significant scale difference between normal and fault data, leading to imbalanced training dataset for fault diagnosis models and affecting the model’s accuracy. Common methods to address data imbalance include resampling and data augmentation. Among these, the GAN is widely used as an effective data augmentation method for handling the imbalance of bearing data.
To evaluate the performance of AWLT-GAN in dealing with imbalanced bearing data, a comparative experiment was set up. The experimental data settings are shown in
Table 10. The compared models include the following: the ADASYN model [
44] and DWGANGP model [
15], focused on learning time-domain information, the CBAM-CRLSGAN model [
16], focused on learning frequency-domain information, and the ST-CatGAN, Imp-DCGAN and FTGAN models [
18,
22,
27], focusing on both time–frequency-domain information (the structure of the CBAM module in the CBAM-CRLSGAN data generation model is referenced from paper [
45]). ST-CatGAN uses STFT for data preprocessing, while Imp-DCGAN uses CWT for data preprocessing. The FTGAN model also employs a dual discriminator structure, but it utilizes FFT for obtaining frequency-domain information. The construction of data generation models follows the methods in the relevant references, and the fault diagnosis models after data generation adopt the same 1DCNN or 2DCNN structure to evaluate the performance of different GAN generation methods in dealing with data imbalance. The experimental results are shown in
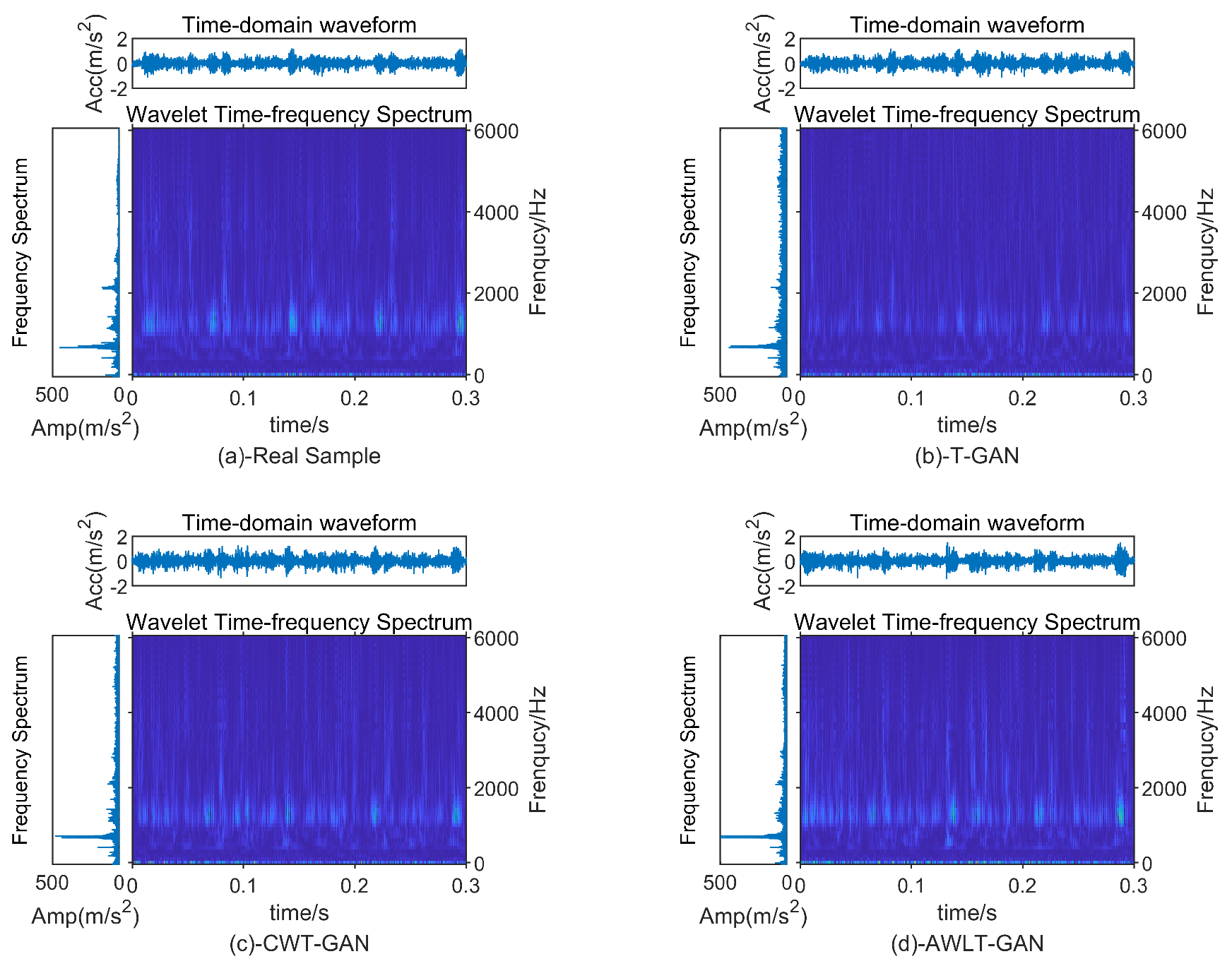
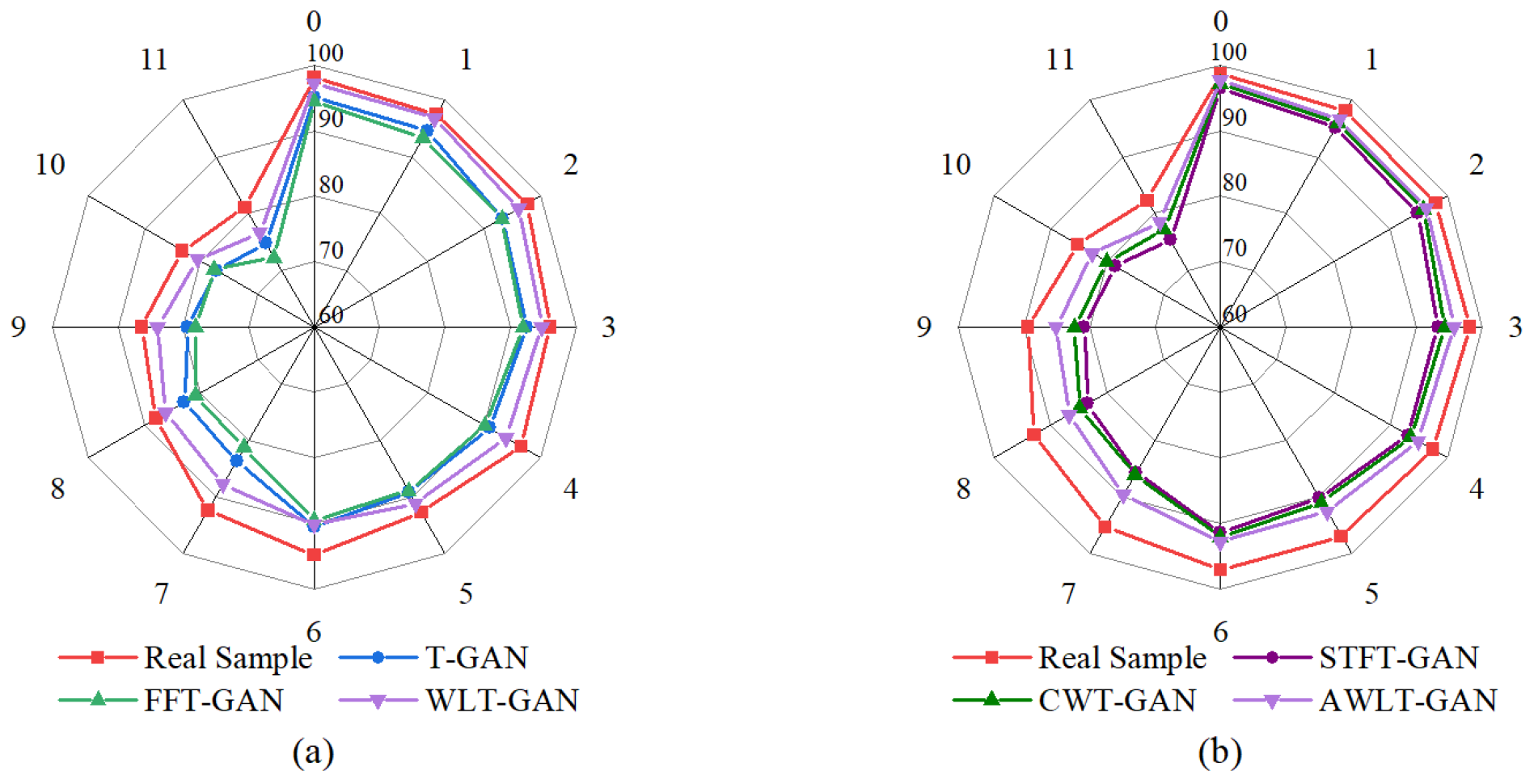
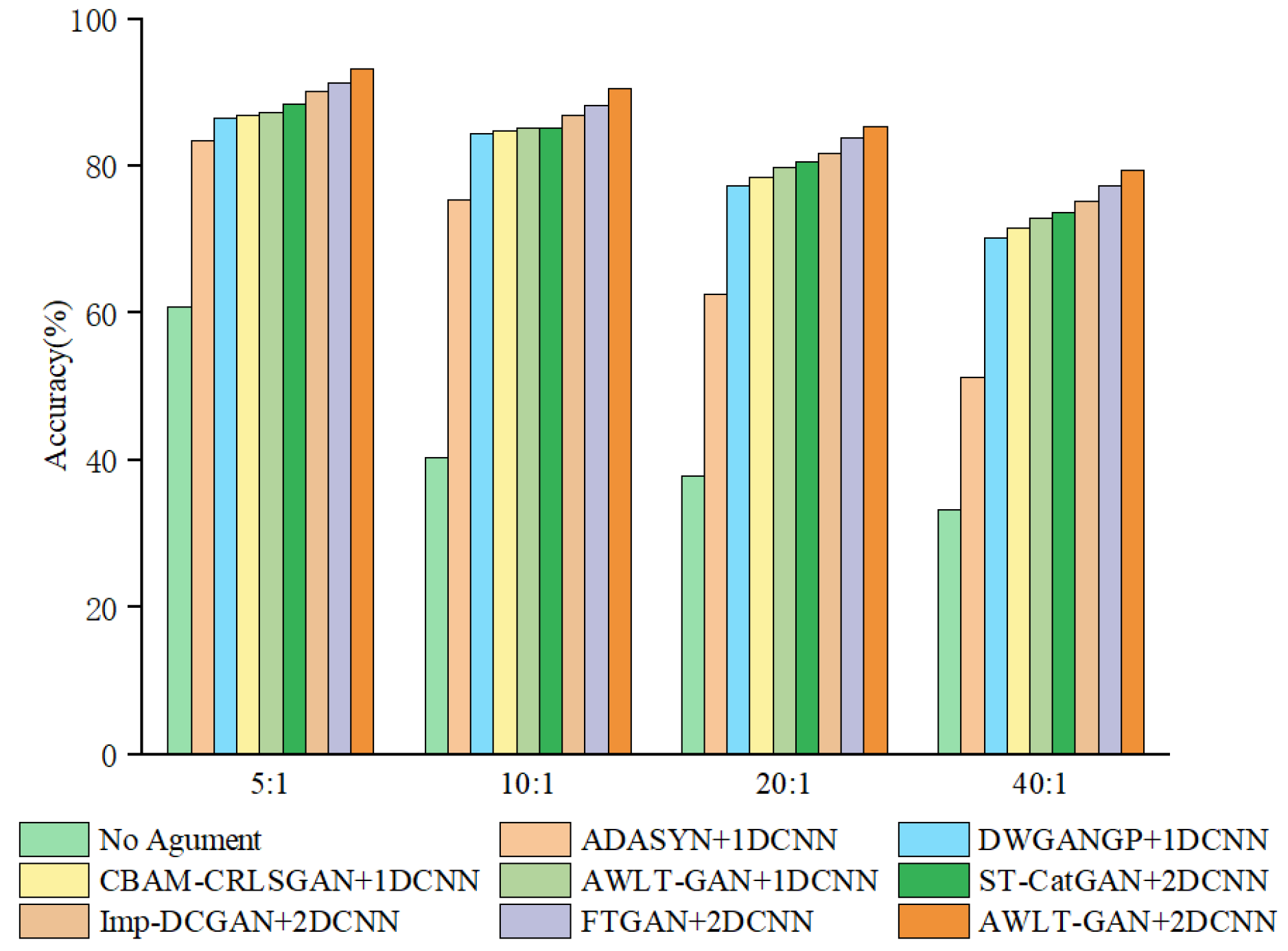
Figure 17.
From the experimental results, it can be seen that as the data imbalance ratio increases, the performance of all diagnostic models decreases to varying degrees. Using data augmentation techniques can make the generated data have high-dimensional features similar to real data and increase a certain degree of diversity, thereby improving the accuracy of diagnostic models. However, due to the limitations of the generation model structure, these models have different performances in extracting real data features. As the data imbalance ratio increases, the number of real samples available for the generation model to learn features decreases, leading to a reduction in the effective features learned by some models, thus reducing the quality of the generated data.
The classic resampling method ADASYN, due to its generated samples not being diverse enough and being sensitive to noise, achieved only a 51.3% fault recognition rate at a 40:1 imbalance ratio. GAN-based models can learn signal features from real data, utilizing adversarial methods and deep neural networks to give GANs stronger feature learning capabilities. Even at a 40:1 imbalance ratio, with only 10 real samples, the diagnostic accuracy still reached 70.5%, demonstrating the potential of GAN methods in handling imbalanced bearing data and constructing effective fault diagnosis models.
Observing the results, it can be found that compared to DWGANGP and CBAM-CRLSGAN, which learn only time-domain or frequency-domain features, the ST-CatGAN, Imp-DCGAN, and FTGAN models, which learn time–frequency attributes, exhibit higher fault recognition rates in the test set after balancing the bearing dataset. This result is partly due to the superior feature extraction capabilities of 2DCNN and partly because the optimized GAN models can learn more feature information contained in real samples. However, at a 40:1 imbalance ratio, the performance of fault diagnosis models significantly decreases compared to the 20:1 ratio. This decrease is mainly due to the reduced number of real sample data available for the GAN model to learn, limiting the GAN model’s generation capabilities, thus reducing the quality of generated samples and ultimately affecting the accuracy of the fault diagnosis models. The FTGAN model also performs well; however, due to using the FFT method, its ability to obtain frequency-domain information is weaker than that of the CWT method when processing complex signals. AWLT-GAN demonstrates excellent performance when applied to fault diagnosis models utilizing both one-dimensional and two-dimensional convolutional approaches. This is due to its dual-discriminator architecture, which can learn high-dimensional feature information from both the time and frequency domains in one training session, making the generated signals closer to real signals in terms of authenticity and diversity. At a 40:1 imbalance ratio, when the amount of real data is 10, the AWLT-GAN model still has an accuracy of 79.6%, a 5.7% decrease compared to the 20:1 ratio.
Table 11 presents the precision, recall, and F1-Score of different methods under an imbalance ratio of 20:1. The results demonstrate that the proposed method achieves the highest values across all three metrics, verifying its superiority in diagnostic performance. Additionally, the experimental results demonstrate that AWLT-GAN effectively captures essential features from small sample data and generates high-quality bearing fault data. These generated data significantly contribute to improving the accuracy and stability of the fault diagnosis models based on AWLT-GAN.
6. Experiment III: Imbalanced Fault Diagnosis Using Ensemble Learning
According to the experimental results in fault diagnosis with imbalanced data, for the same set of generated data, the recognition accuracy is lower when using one-dimensional convolution for feature extraction directly on the signal compared to using two-dimensional convolution after preprocessing the signal. This phenomenon is due to two reasons: firstly, the time–frequency domain after transformation contains more fault feature information, and secondly, there is a difference in the feature extraction capabilities between one-dimensional and two-dimensional convolution. However, while wavelet transform can provide time–frequency information, it does not fully reflect the time–frequency characteristics of real samples. Additionally, the smoothing process in wavelet transform may introduce pseudo-features, causing subtle features in the time domain of the original signal to become less apparent after transformation. According to the results of imbalanced fault diagnosis, at a 40:1 imbalance ratio, although the fault recognition accuracy reached 79.6%, there were still almost 20 fault recognition errors, indicating that there is still significant room for improvement in fault recognition accuracy.
At the same time, one-dimensional convolution kernels perform convolution operations in only one direction. When processing time-series data collected by vibration sensors, they can effectively extract the intrinsic features of the signal from the time-series data, making them suitable for feature extraction of one-dimensional bearing time-series signals. Two-dimensional convolution, on the other hand, extracts features in two spatial dimensions simultaneously when processing two-dimensional data, better capturing the spatial information in two-dimensional spectral data, making it suitable for feature extraction of two-dimensional spectrograms. However, the data generated by AWLT-GAN contain both time-domain and frequency-domain information of real data. Using these data alone cannot fully exploit the advantages of AWLT-GAN. To more effectively utilize the information of bearing data, this study constructed an ensemble learning fault diagnosis model aimed at further improving fault diagnosis accuracy.
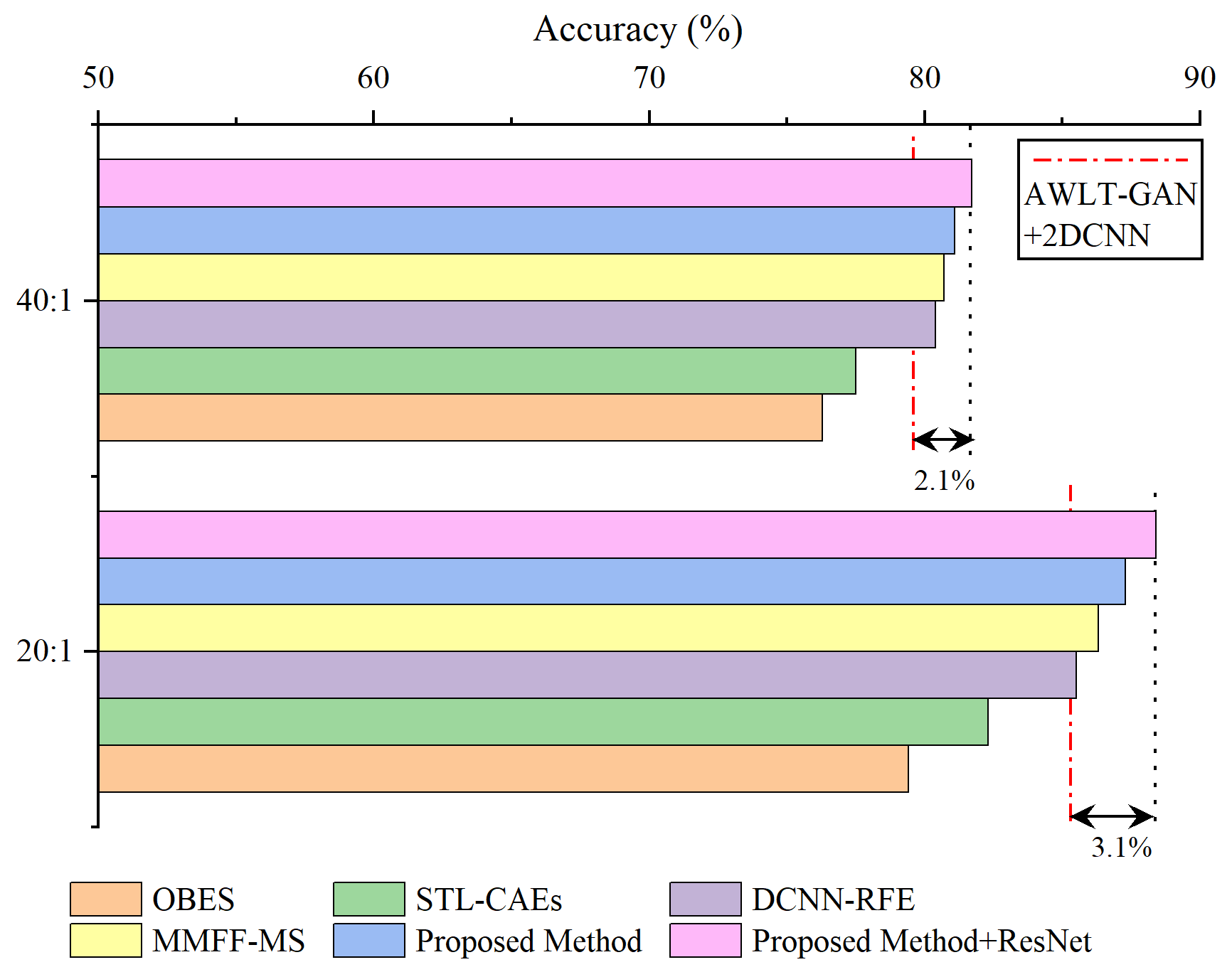
Based on the experiments in fault diagnosis with imbalanced data, datasets with imbalance ratios of 20:1 and 40:1 were selected, and the data generation models were used to balance the datasets. The comparison methods include OBES [
29] and STL-CAEs [
30], which utilize frequency-domain information, as well as DCNN-RFE [
31] and MMFF-MS [
32], which use time-frequency information. The ensemble learning method proposed in this paper is shown in
Figure 6: one-dimensional time-domain signals are directly input into the 1DCNN fault diagnosis model, two-dimensional frequency-domain data, obtained from wavelet transform to obtain spectrograms, are input into the 2DCNN fault diagnosis model, and soft voting is used to integrate the classification probabilities to determine the final classification. The results are shown in
Figure 18.
As shown in the results, the method MMFF-MS outperformed AWLT-GAN+2DCNN and other reference methods at imbalance ratios of 20:1 and 40:1. This superiority stems from two aspects: First, it extracts features from both the time domain and time-frequency domain, fully utilizing the features of the generated data. Second, it uses ResNet for feature extraction, which offers stronger capabilities than the network used in this paper. However, there are differences between MMFF-MS and the method proposed here. While MMFF-MS excels in feature extraction due to its use of ResNet for time-frequency information, the one-dimensional convolution-based method in this paper captures time-domain features more effectively. Additionally, MMFF-MS only extracts 28 features for classification, potentially underutilizing time-domain information. After optimizing our method by incorporating ResNet instead of 2DCNN, the ensemble learning approach in this paper achieved higher accuracy in fault classification compared to AWLT-GAN+2DCNN without ensemble learning. Specifically, at imbalance ratios of 20:1 and 40:1, the accuracy improved by 3.1% and 2.1%, respectively.
Compared to the method MMFF-MS, the method DCNN-RFE using ensemble learning focuses on repeatedly utilizing features from specific network layers, and its results also outperformed AWLT-GAN+2DCNN. However, due to the ineffective utilization of fault time-domain information, its fault diagnosis results were not as good as MMFF-MS and the method proposed in this paper. The methods OBES and STL-CAEs only used frequency-domain information, and although aided by ensemble learning methods, the improvement in fault diagnosis was not significant.
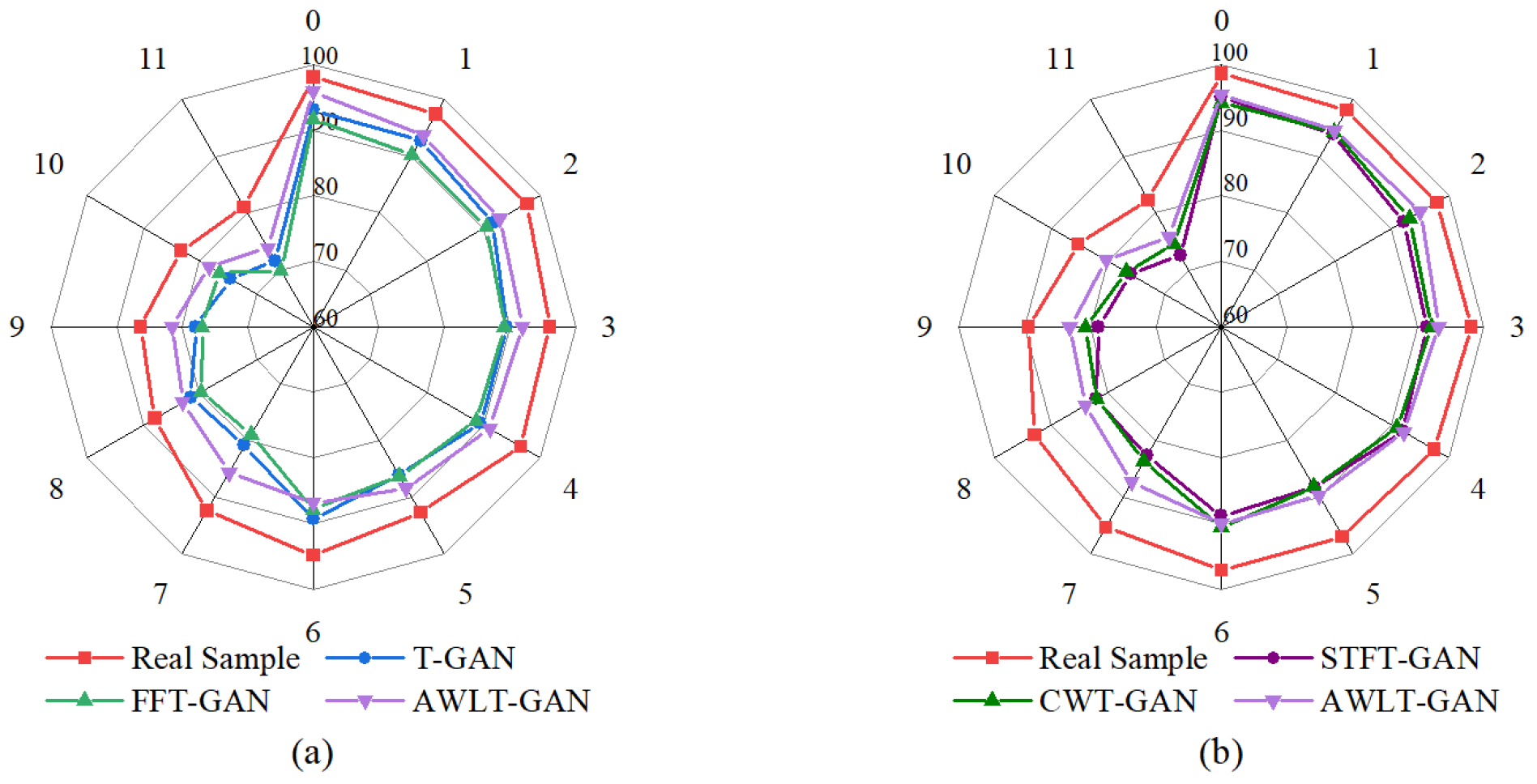
Overall, the ensemble learning method combining time-domain and frequency-domain classification results achieved higher fault recognition rates than models using time-domain or frequency-domain features alone, demonstrating the effectiveness of the ensemble learning method. To delve into the reasons behind the improved accuracy by integrated learning methods, we employed the AWLT-GAN approach to balance the dataset when the imbalance ratio reached 20:1. On this balanced dataset, we conducted three comparative experiments: the first using only time–frequency-domain information for fault diagnosis; the second using time-domain information alone for fault diagnosis; and the third applying an integrated learning method that utilizes both time–frequency information for fault diagnosis. The results are presented in
Figure 19.
Observing the accuracy for different conditions and fault types, it can be seen that when fault signal features are obvious, such as normal bearings and outer ring faults, both 1DCNN and 2DCNN achieve good classification results. However, when the bearing fault signals are significantly influenced by their characteristics and surrounding components, such as rolling element faults, the quality of generated signals also decreases, the fault features extracted by deep neural networks become less distinguishable, and the classification accuracy when using them alone is not high. Using the ensemble learning method can improve the fault recognition accuracy of fault diagnosis models, as the soft voting strategy can integrate the feature information from both the time domain and frequency domain in high-dimensional space, thereby enhancing fault recognition accuracy.
7. Conclusions
To effectively address the imbalance in bearing fault data and improve the accuracy of fault diagnosis models, this paper proposes the AWLT-GAN method to generate fault data by fully utilizing both the time-domain and frequency-domain information of bearing fault signals, thus solving the data imbalance problem. On this basis, ensemble learning methods are adopted to further enhance the accuracy of fault diagnosis.
Compared to other methods, the proposed approach offers the following advantages: (1) it fully utilizes the time-domain and frequency-domain information of bearing fault signals, significantly improving diagnostic accuracy; (2) the generated samples are closer to real signals in terms of authenticity and diversity, providing a practical solution to the imbalance in bearing data.
Overall, the experiments and results in this paper confirm that the proposed method can effectively generate high-quality bearing fault signals and address the issue of data imbalance. However, the ensemble learning experiments suggest that more efficient feature extraction strategies could further enhance the performance of fault diagnosis models, which will be an important direction for future research. In addition, due to the use of dual discriminators, the stability of the AWLT-GAN model requires further improvement. Moreover, the limited recognition performance on rolling element faults warrants deeper investigation.
Furthermore, although the validation experiments include multiple rotating speeds, all data were collected under a fixed external load, representing relatively stable operating conditions. The capability of the proposed method to enhance fault data under non-stationary scenarios—such as fluctuating loads and variable speeds—was not comprehensively explored in this study. Given that non-stationary conditions can significantly alter vibration signal characteristics and pose major challenges in real-world fault diagnosis tasks, future work will explore extending the application of the AWLT-GAN framework to more diverse operating conditions, including varying load levels and speed changes. This extension will enable a more thorough evaluation of the model’s robustness and generalization capability in realistic industrial environments.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}