
Fault Diagnosis Method of Rolling Bearing Based on 1D Multi-Channel Improved Convolutional Neural Network in Noisy Environment


 and
and
Abstract
1. Introduction
1.1. Related Work
1.2. Document Structure
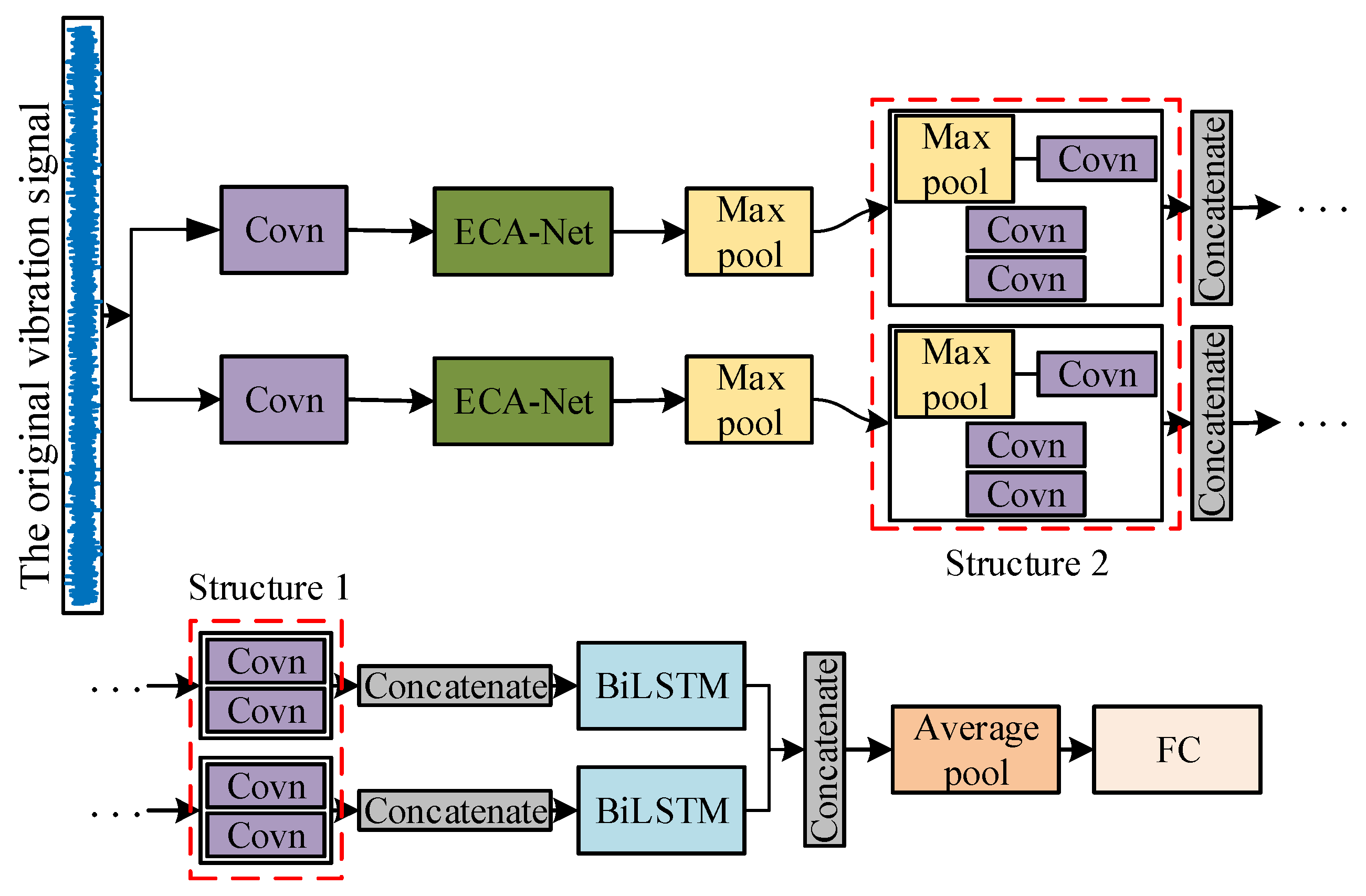
2. Design and Optimization of 1DMCICNN
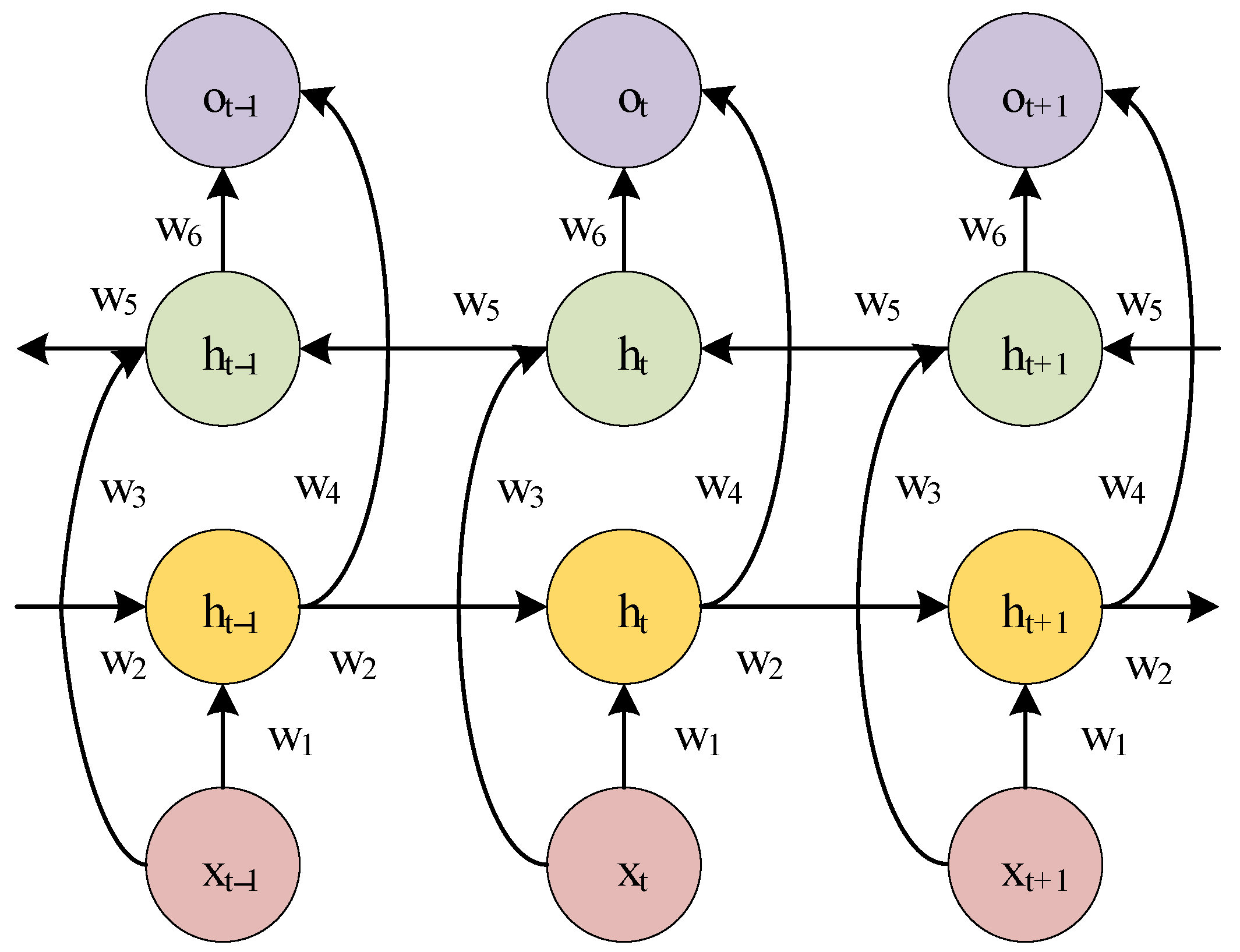
2.1. Bi-Directional Long Short-Term Memory Network
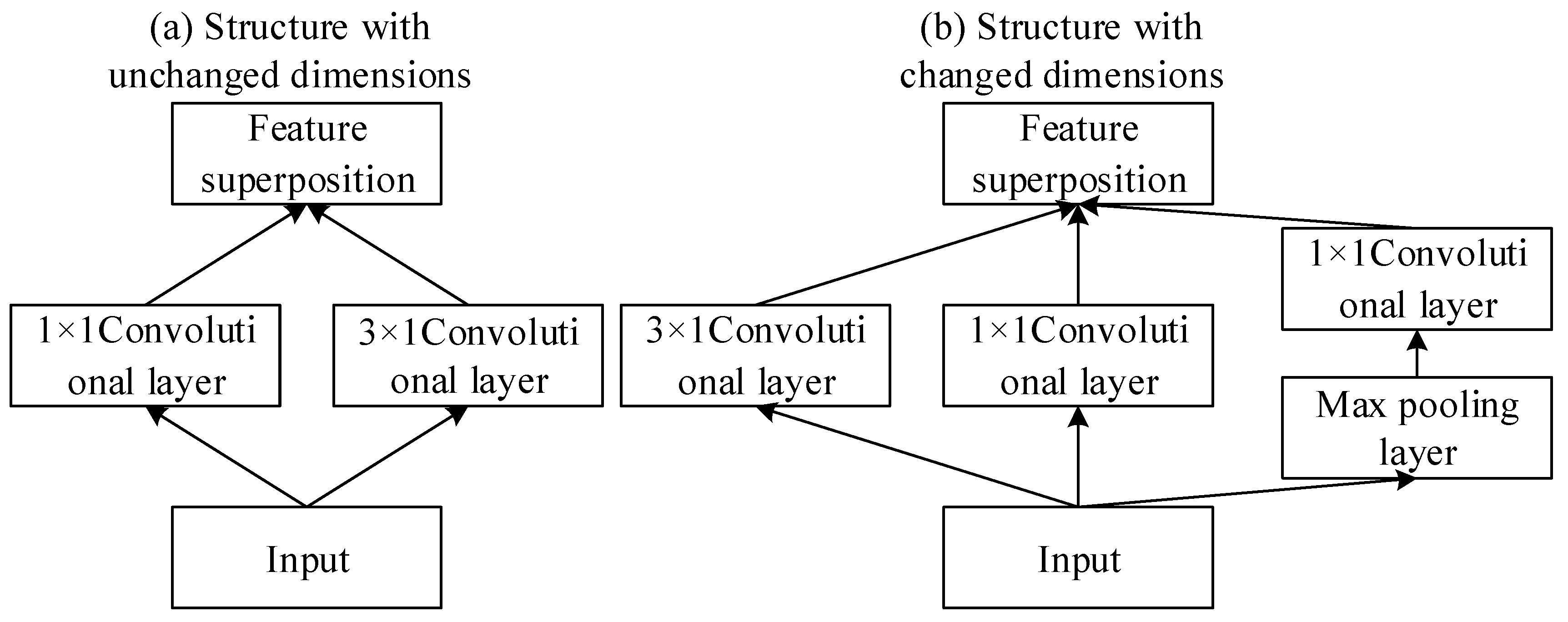
2.2. Locally Sparse Structure
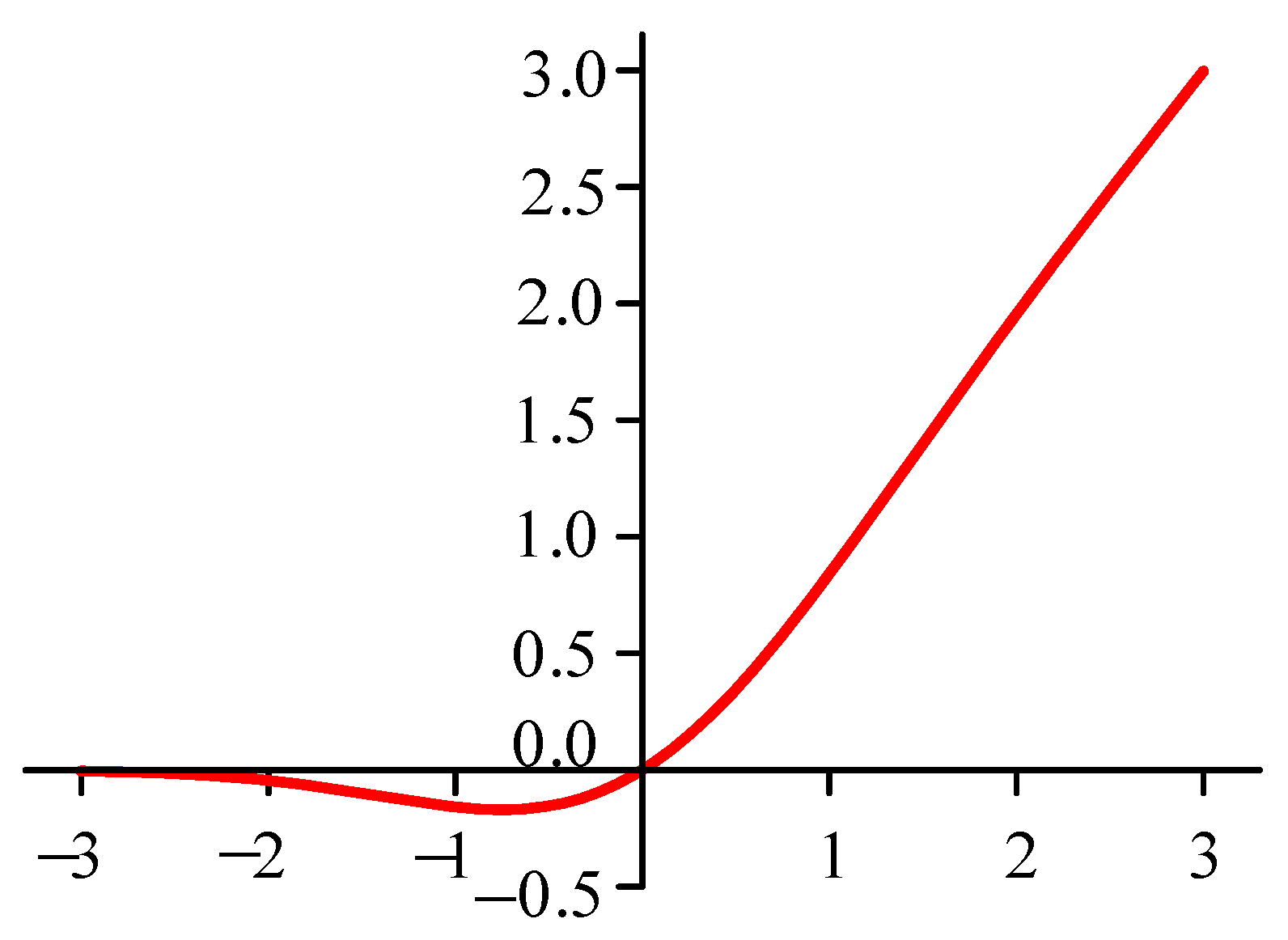
2.3. Optimization of Activation Function
2.4. Optimizer Selection
| Algorithm 1: Nadam, hyperparameter setting , , , |
| Conditions: Initial learning rate and retention stability constant |
| Conditions: Moment estimate decay rate and initialization |
| Conditions: Initialization of parameter |
| First , Second moment variable |
| Example Initialize the time step |
| If does not converge, perform the following operations: |
| End and return |
2.5. Sensors Used in the Experimental Platform
3. Structure and Diagnostic Flow of 1DMCICNN
3.1. DMCICNN Structure and Parameter Settings
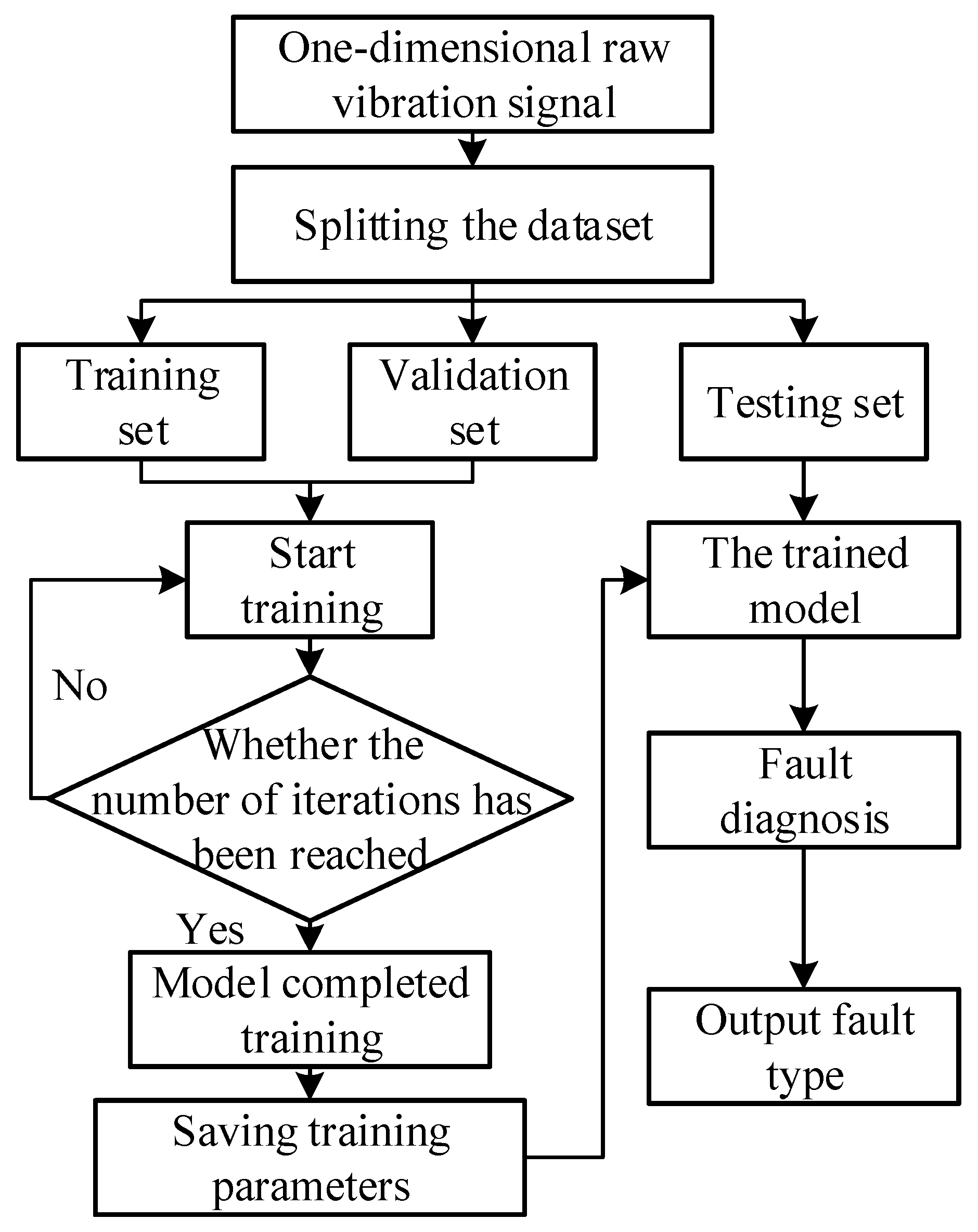
3.2. DMCICNN Fault Diagnosis Flow
4. Experimental Verification
4.1. Summary Description of a Dataset Containing Noise
4.2. Experimental Process Design
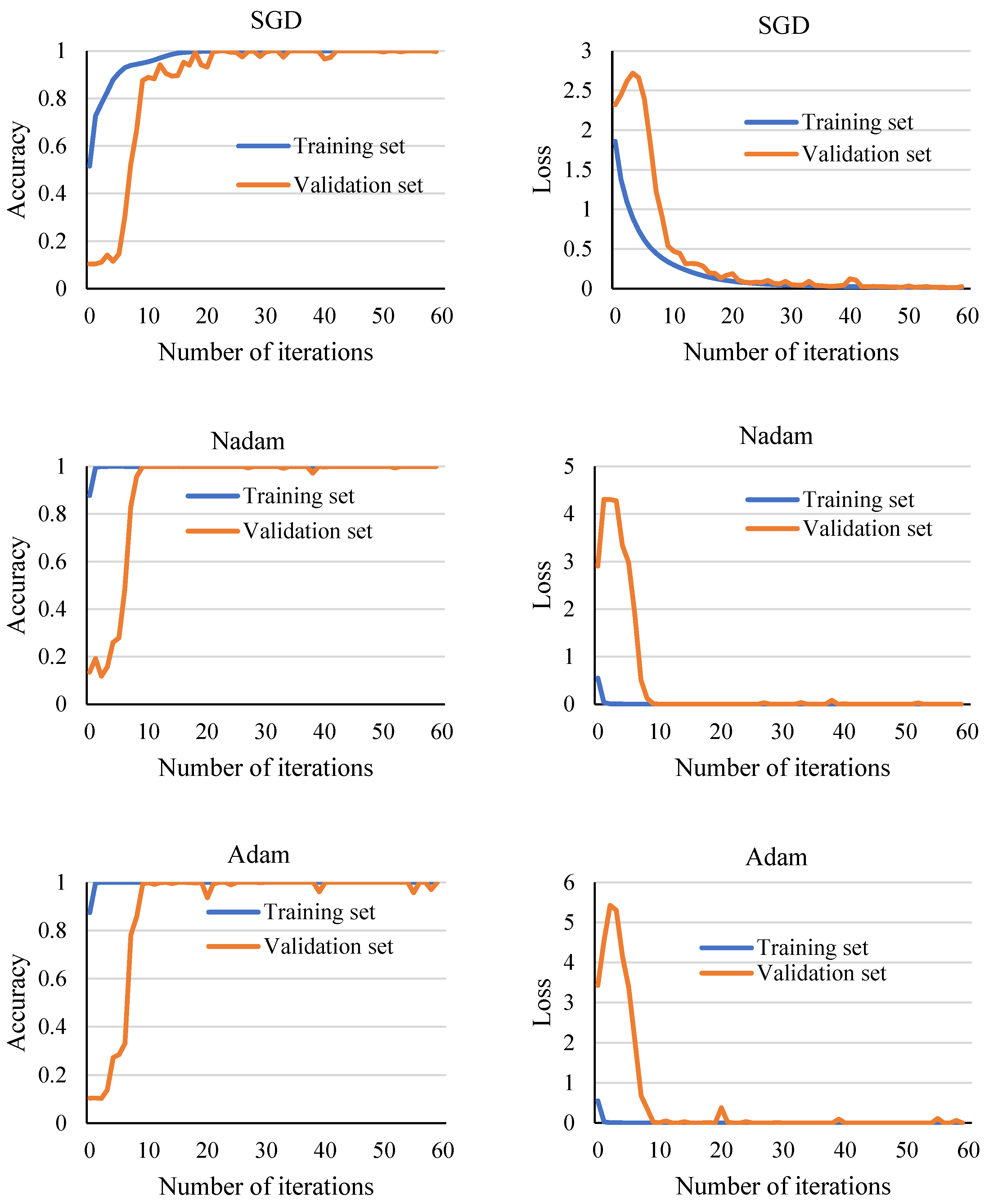
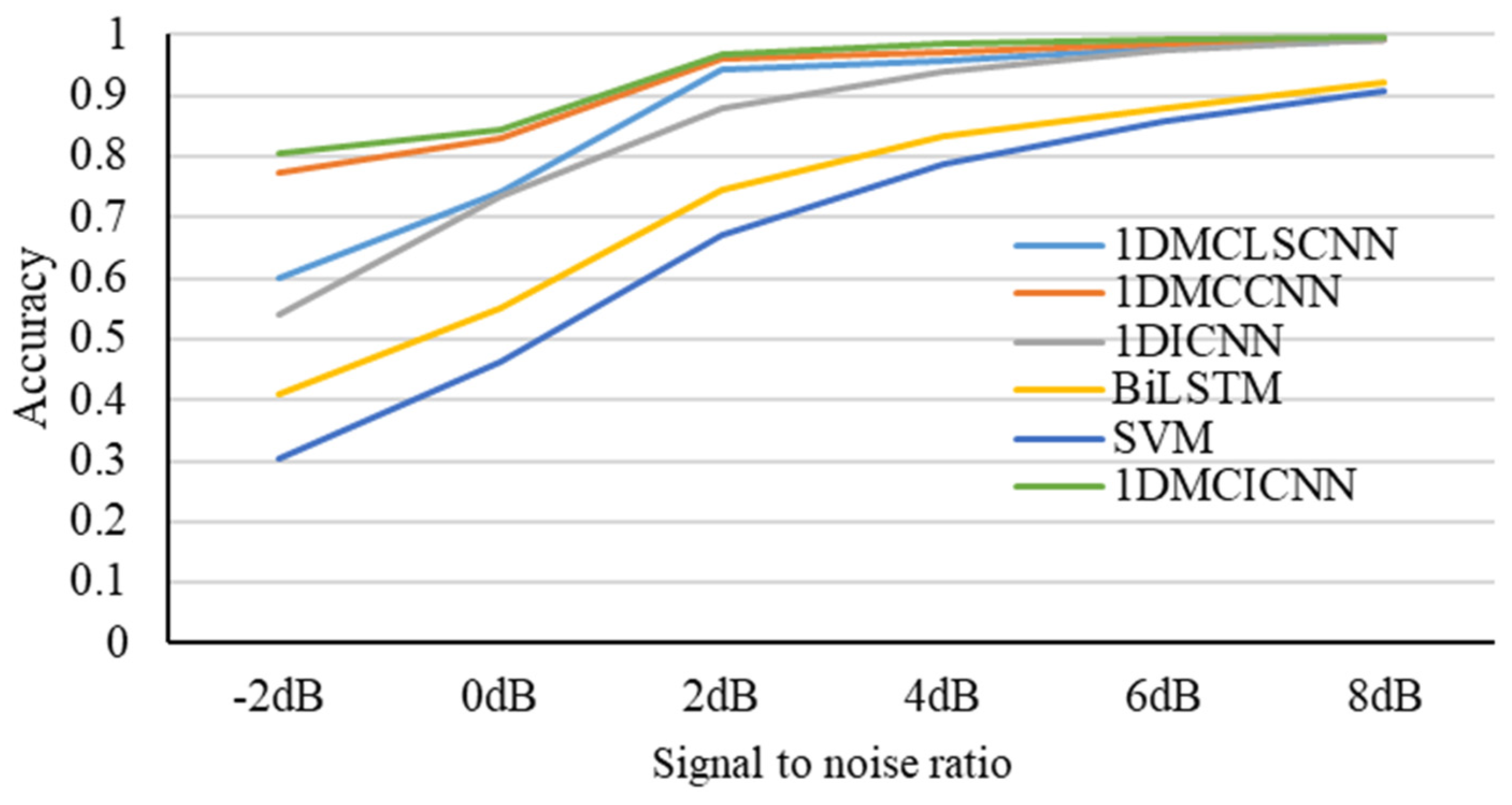
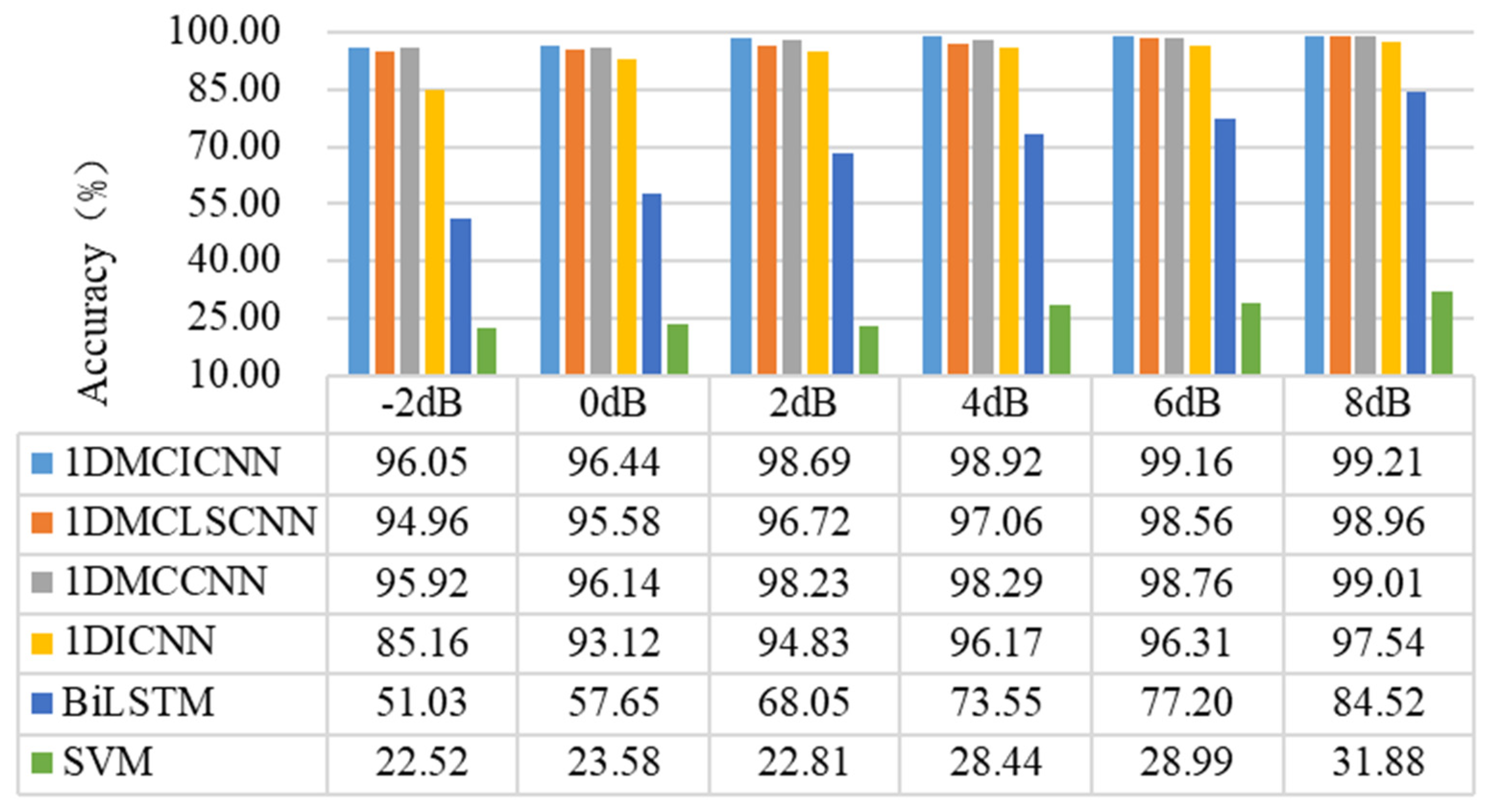
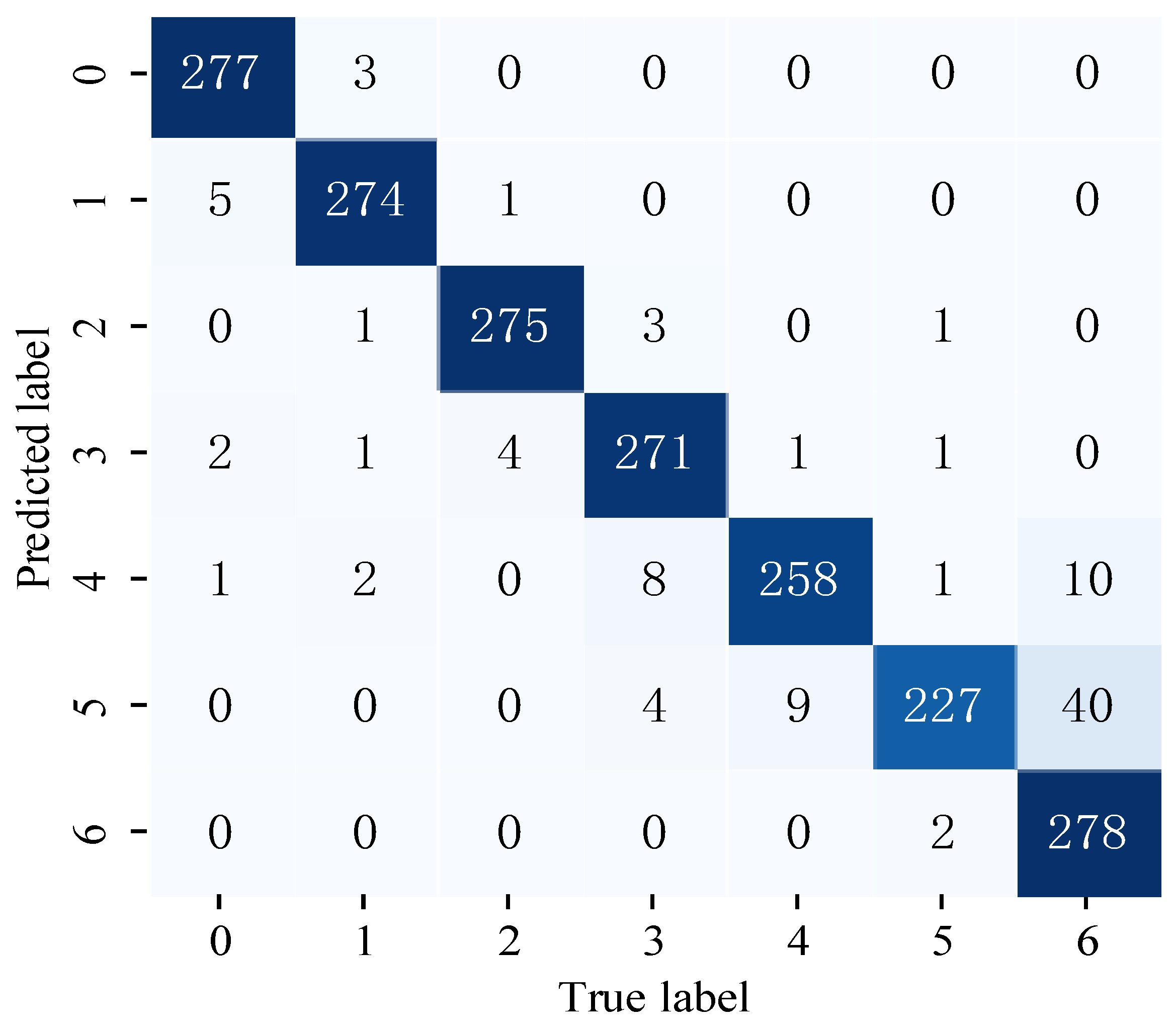
4.3. Experiment 1 Results and Analysis
4.4. Experiment 2 Results and Analysis
5. Evaluation
6. Conclusions
6.1. Conclusion of the Article
6.2. Directions for Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, J.; Luo, W.; Bai, M. Review of research on signal decomposition and fault diagnosis of rolling bearing based on vibration signal. Meas. Sci. Technol. 2024, 35, 092001. [Google Scholar] [CrossRef]
- Fang, Z.; Wu, Q.-E.; Wang, W.; Wu, S. Research on Improved Fault Detection Method of Rolling Bearing Based on Signal Feature Fusion Technology. Appl. Sci. 2023, 13, 12987. [Google Scholar] [CrossRef]
- Feng, Z.; Xing, P.; Li, G.; Zhang, L.; Lu, L.; He, X.; Zhang, H. A Hybrid Approach Based on the SR-HWPT-PDF for Identifying Early Fault Signals in Rolling Bearings. J. Mar. Sci. Eng. 2024, 12, 1857. [Google Scholar] [CrossRef]
- Gu, X.; Tian, Y.; Li, C.; Wei, Y.; Li, D. Improved SE-ResNet Acoustic-Vibration Fusion for Rolling Bearing Composite Fault Diagnosis. Appl. Sci. 2024, 14, 2182. [Google Scholar] [CrossRef]
- Guo, X. Fault Diagnosis of Rolling Bearings Based on Acoustics and Vibration Engineering. IEEE Access 2024, 12, 139632–139648. [Google Scholar] [CrossRef]
- Liu, X.; Yan, C.; Lv, M.; Li, S.; Wu, L. Multi-rolling element faults diagnosis of rolling bearing based on time-frequency analysis and multi-curves extraction. Meas. Sci. Technol. 2024, 35, 106113. [Google Scholar] [CrossRef]
- Ma, P.; Liang, W.; Zhang, H.; Wang, C.; Li, X. Multiscale permutation entropy based on natural visibility graph and its application to rolling bearing fault diagnosis. Struct. Health Monit.-Int. J. 2024, 24, 313–326. [Google Scholar] [CrossRef]
- Qin, L. Rolling Bearing Fault Detection Using Domain Adaptation-Based Anomaly Detection. Int. J. Artif. Intell. Tools 2024, 33, 2440003. [Google Scholar] [CrossRef]
- Shi, H.; Gan, C.; Zhang, X.; Meng, W.; Huang, C. A fault diagnosis method for rolling bearings based on RDDAN under multivariable working conditions. Meas. Sci. Technol. 2023, 34, 025003. [Google Scholar] [CrossRef]
- Yang, G.; Wang, Y.; Qin, D.; Zhu, R.; Han, Q. HMM-Based Method for Aircraft Environmental Control System Turbofan Rolling Bearing Fault Diagnosis. Shock Vib. 2024, 2024, 5582169. [Google Scholar] [CrossRef]
- Zhao, L.; Chi, X.; Li, P.; Ding, J. Incipient Fault Feature Enhancement of Rolling Bearings Based on CEEMDAN and MCKD. Appl. Sci. 2023, 13, 5688. [Google Scholar] [CrossRef]
- Zhong, C.; Wang, J.-S.; Liu, Y. Bi-LSTM fault diagnosis method for rolling bearings based on segmented interception AR spectrum analysis and information fusion. J. Intell. Fuzzy Syst. 2023, 44, 8493–8519. [Google Scholar] [CrossRef]
- Tang, S.N.; Yuan, S.Q.; Zhu, Y. Deep Learning-Based Intelligent Fault Diagnosis Methods Toward Rotating Machinery. IEEE Access 2020, 8, 9335–9346. [Google Scholar] [CrossRef]
- Toma, R.N.; Kim, J.M. Bearing Fault Classification of Induction Motors Using Discrete Wavelet Transform and Ensemble Machine Learning Algorithms. Appl. Sci. 2020, 10, 5251. [Google Scholar] [CrossRef]
- Cui, L.; Li, W.; Wang, X.; Liu, D. A novel quantitative diagnosis method for rolling bearing faults based on digital twin model. ISA Trans. 2024, 157, 381–391. [Google Scholar] [CrossRef]
- Pang, B.; Liu, Q.; Sun, Z.; Xu, Z.; Hao, Z.J.A.E.I. Time-frequency supervised contrastive learning via pseudo-labeling: An unsupervised domain adaptation network for rolling bearing fault diagnosis under time-varying speeds. Adv. Eng. Inform. 2024, 59, 102304. [Google Scholar] [CrossRef]
- Bai, R.; Meng, Z.; Xu, Q.; Fan, F. Fractional Fourier and time domain recurrence plot fusion combining convolutional neural network for bearing fault diagnosis under variable working conditions. Reliab. Eng. Syst. Saf. 2023, 232, 109076. [Google Scholar] [CrossRef]
- Li, Q. Measurement. New approach for bearing fault diagnosis based on fractional spatio-temporal sparse low rank matrix under multichannel time-varying speed condition. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar]
- Randall, R.B.; Antoni, J.; Chobsaard, S. The relationship between spectral correlation and envelope analysis in the diagnostics of bearing faults and other cyclostationary machine signals. Mech. Syst. Signal Process. 2001, 15, 945–962. [Google Scholar] [CrossRef]
- Cardona-Morales, O.; Avendaño, L.; Castellanos-Dominguez, G. Nonlinear model for condition monitoring of non-stationary vibration signals in ship driveline application. Mech. Syst. Signal Process. 2014, 44, 134–148. [Google Scholar] [CrossRef]
- D’Elia, G. Fault Detection in Rotating Machines by Vibration Signal Processing Techniques. Ph.D. Thesis, Alma Mater Studiorum Università di Bologna, Bologna, Italy, 2008. [Google Scholar]
- Mustafa, D.; Yicheng, Z.; Minjie, G.; Jonas, H.; Jürgen, F. Motor current based misalignment diagnosis on linear axes with short-time Fourier transform (STFT). Procedia CIRP 2022, 106, 239–243. [Google Scholar] [CrossRef]
- Sifuzzaman, M.; Islam, M.R.; Ali, M. Application of wavelet transform and its advantages compared to Fourier transform. J. Phys. Sci. 2009, 13, 121–134. [Google Scholar]
- Amarouayache, I.I.E.; Saadi, M.N.; Guersi, N.; Boutasseta, N. Bearing fault diagnostics using EEMD processing and convolutional neural network methods. Int. J. Adv. Manuf. Technol. 2020, 107, 4077–4095. [Google Scholar] [CrossRef]
- Zhang, M.; Han, Y.; Wang, C.; Yang, P.; Wang, C.; Zalhaf, A.S. Ultra-short-term photovoltaic power prediction based on similar day clustering and temporal convolutional network with bidirectional long short-term memory model: A case study using DKASC data. Appl. Energy 2024, 375, 124085. [Google Scholar] [CrossRef]
- Zhang, X.; He, W.; Cui, Q.; Bai, T.; Li, B.; Li, J.; Li, X. WavLoadNet: Dynamic Load Identification for Aeronautical Structures Based on Convolution Neural Network and Wavelet Transform. Appl. Sci. 2024, 14, 1928. [Google Scholar] [CrossRef]
- Yan, R.; Liu, Y.; Gao, R.X. Permutation entropy: A nonlinear statistical measure for status characterization of rotary machines. Mech. Syst. Signal Process. 2012, 29, 474–484. [Google Scholar] [CrossRef]
- Kanai, R.A.; Desavale, R.G.; Chavan, S.P. Experimental-Based Fault Diagnosis of Rolling Bearings Using Artificial Neural Network. J. Tribol. -Trans. ASME 2016, 138, 031103. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Zhang, F.; Li, W.; Lv, S.; Jiang, M.; Jia, L. Accuracy-improved bearing fault diagnosis method based on AVMD theory and AWPSO-ELM model. Measurement 2021, 181, 109666. [Google Scholar] [CrossRef]
- Wang, Z.Y.; Yao, L.G.; Cai, Y.W. Rolling bearing fault diagnosis using generalized refined composite multiscale sample entropy and optimized support vector machine. Measurement 2020, 156, 107574. [Google Scholar] [CrossRef]
- Zhang, S.C.; Li, X.L.; Zong, M.; Zhu, X.F.; Wang, R.L. Efficient kNN Classification With Different Numbers of Nearest Neighbors. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1774–1785. [Google Scholar] [CrossRef]
- Deng, W.; Yao, R.; Zhao, H.M.; Yang, X.H.; Li, G.Y. A novel intelligent diagnosis method using optimal LS-SVM with improved PSO algorithm. Soft Comput. 2019, 23, 2445–2462. [Google Scholar] [CrossRef]
- Kumbhar, S.G.; Desavale, R.G.; Dharwadkar, N.V. Fault size diagnosis of rolling element bearing using artificial neural network and dimension theory. Neural Comput. Appl. 2021, 33, 16079–16093. [Google Scholar] [CrossRef]
- Lu, J.T.; Qian, W.W.; Li, S.M.; Cui, R.Q. Enhanced K-Nearest Neighbor for Intelligent Fault Diagnosis of Rotating Machinery. Appl. Sci. 2021, 11, 919. [Google Scholar] [CrossRef]
- Shinde, P.V.; Desavale, R.G.; Jadhav, P.M.; Sawant, S.H. A multi fault classification in a rotor-bearing system using machine learning approach. J. Braz. Soc. Mech. Sci. Eng. 2023, 45, 121. [Google Scholar] [CrossRef]
- Ding, Y.; Cao, Y.; Jia, M.; Ding, P.; Zhao, X.; Lee, C.-G. Deep temporal-spectral domain adaptation for bearing fault diagnosis. Knowl.-Based Syst. 2024, 299, 111999. [Google Scholar]
- Khan, A.S.; Akram, M.U.; Khattak, M.K.; Jawed, S. Deep Learning Based Approaches for Intelligent Industrial Machineryhealth Management & Fault Diagnosis in Resource-Constrain edenvironments. 2025; preprint. [Google Scholar] [CrossRef]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nat. Med. 2019, 25, 65–69. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.; van Ginneken, B.; Sanchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.Q.; Chen, Z.H.; Mao, K.Z.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, M.; Ouyang, T.; Che, F. A wind turbine bearing fault diagnosis method based on fused depth features in time–frequency domain. Energy Rep. 2022, 8, 12727–12739. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Zhang, C.; Tan, K.C.; Li, H.Z.; Hong, G.S. A Cost-Sensitive Deep Belief Network for Imbalanced Classification. IEEE Trans. NEURAL Netw. Learn. Syst. 2019, 30, 109–122. [Google Scholar] [CrossRef] [PubMed]
- Shao, S.Y.; Wang, P.; Yan, R.Q. Generative adversarial networks for data augmentation in machine fault diagnosis. Comput. Ind. 2019, 106, 85–93. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Gryllias, K.; Li, W.H. Mechanical fault diagnosis using Convolutional Neural Networks and Extreme Learning Machine. Mech. Syst. Signal Process. 2019, 133, 106272. [Google Scholar] [CrossRef]
- Gong, W.F.; Chen, H.; Zhang, Z.H.; Zhang, M.L.; Wang, R.H.; Guan, C.; Wang, Q. A Novel Deep Learning Method for Intelligent Fault Diagnosis of Rotating Machinery Based on Improved CNN-SVM and Multichannel Data Fusion. Sensors 2019, 19, 1693. [Google Scholar] [CrossRef]
- Jiang, G.Q.; He, H.B.; Yan, J.; Xie, P. Multiscale Convolutional Neural Networks for Fault Diagnosis of Wind Turbine Gearbox. IEEE Trans. Ind. Electron. 2019, 66, 3196–3207. [Google Scholar] [CrossRef]
- Sharada, K.; Jeevanandam, P.; Mohanavel, V.; Naik, B.R.; Kannan, S. Synergizing Deep Belief Networks and Multi-Layer Perceptrons for Advanced Facial Expression Identification: A Leap in Deep Learning Applications. In Proceedings of the 2024 IEEE 9th International Conference for Convergence in Technology (I2CT), Pune, India, 5–7 April 2024; pp. 1–6. [Google Scholar]
- Qin, B.; Luo, Q.; Li, Z.; Zhang, C.; Wang, H.; Liu, W. Data Screening Based on Correlation Energy Fluctuation Coefficient and Deep Learning for Fault Diagnosis of Rolling Bearings. Energies 2022, 15, 2707. [Google Scholar] [CrossRef]
- Deng, W.; Liu, H.L.; Xu, J.J.; Zhao, H.M.; Song, Y.J. An Improved Quantum-Inspired Differential Evolution Algorithm for Deep Belief Network. IEEE Trans. Instrum. Meas. 2020, 69, 7319–7327. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, C.; Jiang, X. Imbalanced fault diagnosis of rolling bearing using improved MsR-GAN and feature enhancement-driven CapsNet. Mech. Syst. Signal Process. 2022, 168, 108664. [Google Scholar] [CrossRef]
- Mao, W.T.; Liu, Y.M.; Ding, L.; Li, Y. Imbalanced Fault Diagnosis of Rolling Bearing Based on Generative Adversarial Network: A Comparative Study. IEEE Access 2019, 7, 9515–9530. [Google Scholar] [CrossRef]
- Zhou, F.N.; Yang, S.; Fujita, H.; Chen, D.M.; Wen, C.L. Deep learning fault diagnosis method based on global optimization GAN for unbalanced data. Knowl.-Based Syst. 2020, 187, 104837. [Google Scholar] [CrossRef]
- Liu, J.; Xu, Y.; Pan, G. Vibration. A combined acoustic and dynamic model of a defective ball bearing. J. Sound Vib. 2021, 501, 116029. [Google Scholar] [CrossRef]
- Shi, H.; Hou, M.; Wu, Y.; Guo, J.; Feng, D. Leader-following Consensus of First-order Multi-agent Systems with Dynamic Hybrid Quantizer. Int. J. Control Autom. Syst. 2020, 18, 2765–2773. [Google Scholar] [CrossRef]
- Shi, H.; Li, Y.; Bai, X.; Wang, Z.; Zou, D.; Bao, Z.; Wang, Z. Investigation of the orbit-spinning behaviors of the outer ring in a full ceramic ball bearing-steel pedestal system in wide temperature ranges. Mech. Syst. Signal Process. 2021, 149, 107317. [Google Scholar]
- Li, Z.; Li, Y.; Sun, Q.; Qi, B. Bearing Fault Diagnosis Method Based on Convolutional Neural Network and Knowledge Graph. Entropy 2022, 24, 1589. [Google Scholar] [CrossRef]
- Kong, L.; Wang, T.; Wang, P.; Zhou, Y. Research on bearing fault diagnosis method under variable operating conditions based on MWDCNN. Proc. J. Phys. Conf. Ser. 2022, 2173, 012088. [Google Scholar]
- Albanese, L.; Barra, A.; Bianco, P.; Durante, F.; Pallara, D. Hebbian learning from first principles. J. Math. Phys. 2024, 65, 113302. [Google Scholar]
- Shao, Y.; Wang, J.; Sun, H.; Yu, H.; Xing, L.; Zhao, Q.; Zhang, L. An Improved BGE-Adam Optimization Algorithm Based on Entropy Weighting and Adaptive Gradient Strategy. Symmetry 2024, 16, 623. [Google Scholar] [CrossRef]
- Martins, A.; Fonseca, I.; Farinha, J.T.; Reis, J.; Cardoso, A.J.M. Prediction maintenance based on vibration analysis and deep learning—A case study of a drying press supported on a Hidden Markov Model. Appl. Soft Comput. 2024, 163, 111885. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Kernel Size | Step Size | Input Size | Output Size | Number of Convolution Kernels | |
|---|---|---|---|---|---|---|
| Input 1 | - | - | 2048 × 1 | 2048 × 1 | - | |
| Input 2 | - | - | 2048 × 1 | 2048 × 1 | - | |
| Covn 1-1 | 64 | 16 | 2048 × 1 | 128 × 32 | 32 | |
| ECA-Net | - | - | 128 × 32 | 128 × 32 | - | |
| Max pool 1-2 | 2 | 2 | 128 × 32 | 64 × 32 | - | |
| Covn 2-1 | 128 | 16 | 2048 × 1 | 128 × 32 | 32 | |
| ECA-Net | - | - | 128 × 32 | 128 × 32 | ||
| Max pool 2-2 | 2 | 2 | 128 × 32 | 64 × 32 | - | |
| Max pool | 2 | 1 | 64 × 32 | 64 × 32 | - | |
| Covn | 1 | 2 | 64 × 32 | 32 × 32 | 32 | |
| Covn | 3 | 2 | 64 × 32 | 32 × 16 | 16 | |
| Covn | 1 | 2 | 64 × 32 | 32 × 64 | 64 | |
| Concatenate 1 | - | - | - | 32 × 112 | - | |
| Covn | 3 | 1 | 32 × 112 | 16 × 64 | 64 | |
| Covn | 1 | 1 | 32 × 112 | 16 × 32 | 32 | |
| Concatenate 2 | - | - | - | 16 × 96 | - | |
| BiLSTM 1-5 | 16 × 96 | 16 × 32 | - | |||
| Max pool | 2 | 1 | 64 × 32 | 64 × 32 | - | |
| Covn | 1 | 2 | 64 × 32 | 32 × 32 | 32 | |
| Covn | 3 | 2 | 64 × 32 | 32 × 32 | 32 | |
| Covn | 1 | 2 | 64 × 32 | 32 × 64 | 64 | |
| Concatenate 3 | - | - | - | 32 × 128 | - | |
| Covn | 3 | 1 | 32 × 128 | 16 × 64 | 64 | |
| Covn | 1 | 1 | 32 × 128 | 16 × 32 | 32 | |
| Concatenate 4 | - | - | - | 16 × 96 | - | |
| BiLSTM 2-5 | - | - | 16 × 96 | 16 × 32 | - | |
| Concatenate 7 | - | - | - | 16 × 64 | - | |
| Average pool | - | - | 16 × 64 | 64 | - | |
| FC | - | - | 64 | 10 | - | |
| Type of Fault | Load (lb) | Rotational Speed (Hz) | Sampling Frequency (Hz) |
|---|---|---|---|
| Normal | 270 | 25 | 97,656 |
| Inner loop | 0/50/10/1150/200/250/300 | 25 | 48,848 |
| Outer ring | 25/50/10/1150/200/250/300 | 25 | 48,828 |
| Data Sources | Bearing Type | Dataset | Fault Size (Inch)/Load (lb) | Fault Type | Label | Sample Size |
|---|---|---|---|---|---|---|
| CWRU | SKF6205 | I | - | Normal | 0 | 2400 |
| 0.007/0.014/0.021 | Rolling element | 1/2/3 | 7200 | |||
| 0.007/0.014/0.021 | Inner ring | 4/5/6 | 7200 | |||
| 0.007/0.014/0.021 | Outer ring | 7/8/9 | 7200 | |||
| J | - | Normal | 0 | 2400 | ||
| 0.007/0.014/0.021 | Rolling element | 1/2/3 | 7200 | |||
| 0.007/0.014/0.021 | Inner ring | 4/5/6 | 7200 | |||
| 0.007/0.014/0.021 | Outer ring | 7/8/9 | 7200 | |||
| K | - | Normal | 0 | 2400 | ||
| 0.007/0.014/0.021 | Rolling element | 1/2/3 | 7200 | |||
| 0.007/0.014/0.021 | Inner ring | 4/5/6 | 7200 | |||
| 0.007/0.014/0.021 | Outer ring | 7/8/9 | 7200 | |||
| L | - | Normal | 0 | 2400 | ||
| 0.007/0.014/0.021 | Rolling element | 1/2/3 | 7200 | |||
| 0.007/0.014/0.021 | Inner ring | 4/5/6 | 7200 | |||
| 0.007/0.014/0.021 | Outer ring | 7/8/9 | 7200 | |||
| MFPT | NICE | M | 0/50/100/150/ 200/250/30 | Inner ring | 0/1/2/3/4/5/6 | 19,600 |
| Dataset | Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| −2 dB | 0 dB | 2 dB | 4 dB | 6 dB | 8 dB | |
| I | 80.63 | 84.39 | 96.91 | 98.66 | 99.29 | 99.63 |
| J | 81.08 | 83.10 | 95.60 | 99.47 | 99.60 | 99.93 |
| K | 79.08 | 84.90 | 95.44 | 99.10 | 99.83 | 99.87 |
| L | 80.15 | 85.20 | 95.91 | 99.55 | 99.79 | 99.97 |
| Average value | 80.24 | 84.40 | 95.97 | 99.20 | 99.63 | 99.85 |
| Number of Parameters | 1DMCCNN | 1DMCICNN |
|---|---|---|
| Total number of parameters | 231,248 | 102,720 |
| Number of trainable parameters | 230,352 | 101,728 |
| Number of non-trainable parameters | 896 | 992 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Ping, D.; Wang, L.; Zhang, W.; Wu, J.; Ma, X.; Xu, Q.; Lu, Z. Fault Diagnosis Method of Rolling Bearing Based on 1D Multi-Channel Improved Convolutional Neural Network in Noisy Environment. Sensors 2025, 25, 2286. https://doi.org/10.3390/s25072286
Guo H, Ping D, Wang L, Zhang W, Wu J, Ma X, Xu Q, Lu Z. Fault Diagnosis Method of Rolling Bearing Based on 1D Multi-Channel Improved Convolutional Neural Network in Noisy Environment. Sensors. 2025; 25(7):2286. https://doi.org/10.3390/s25072286
Chicago/Turabian StyleGuo, Huijuan, Dongzhi Ping, Lijun Wang, Weijie Zhang, Junfeng Wu, Xiao Ma, Qiang Xu, and Zhongyu Lu. 2025. "Fault Diagnosis Method of Rolling Bearing Based on 1D Multi-Channel Improved Convolutional Neural Network in Noisy Environment" Sensors 25, no. 7: 2286. https://doi.org/10.3390/s25072286
APA StyleGuo, H., Ping, D., Wang, L., Zhang, W., Wu, J., Ma, X., Xu, Q., & Lu, Z. (2025). Fault Diagnosis Method of Rolling Bearing Based on 1D Multi-Channel Improved Convolutional Neural Network in Noisy Environment. Sensors, 25(7), 2286. https://doi.org/10.3390/s25072286