
MMG-Based Motion Segmentation and Recognition of Upper Limb Rehabilitation Using the YOLOv5s-SE


Abstract
1. Introduction
2. Materials and Methods
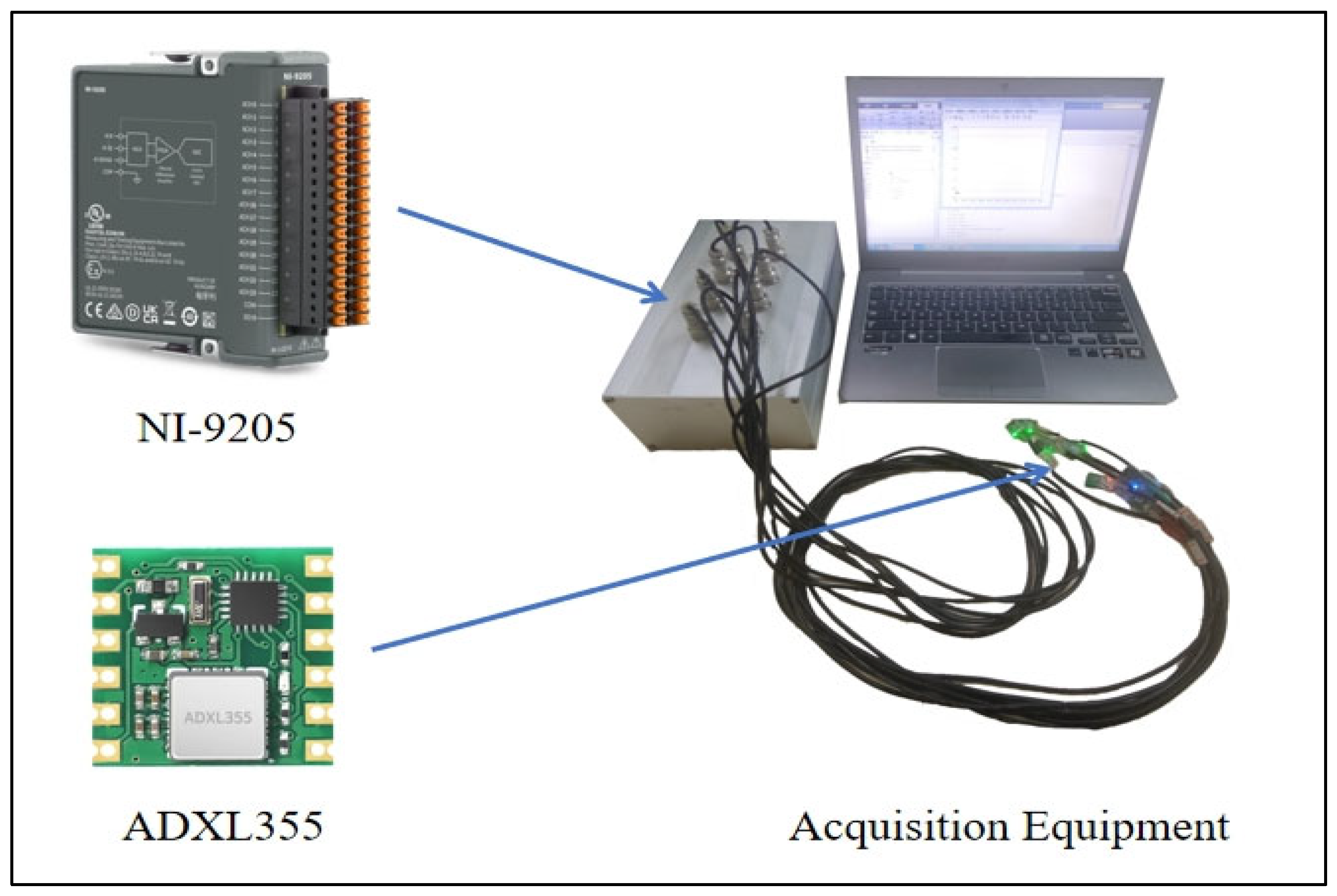
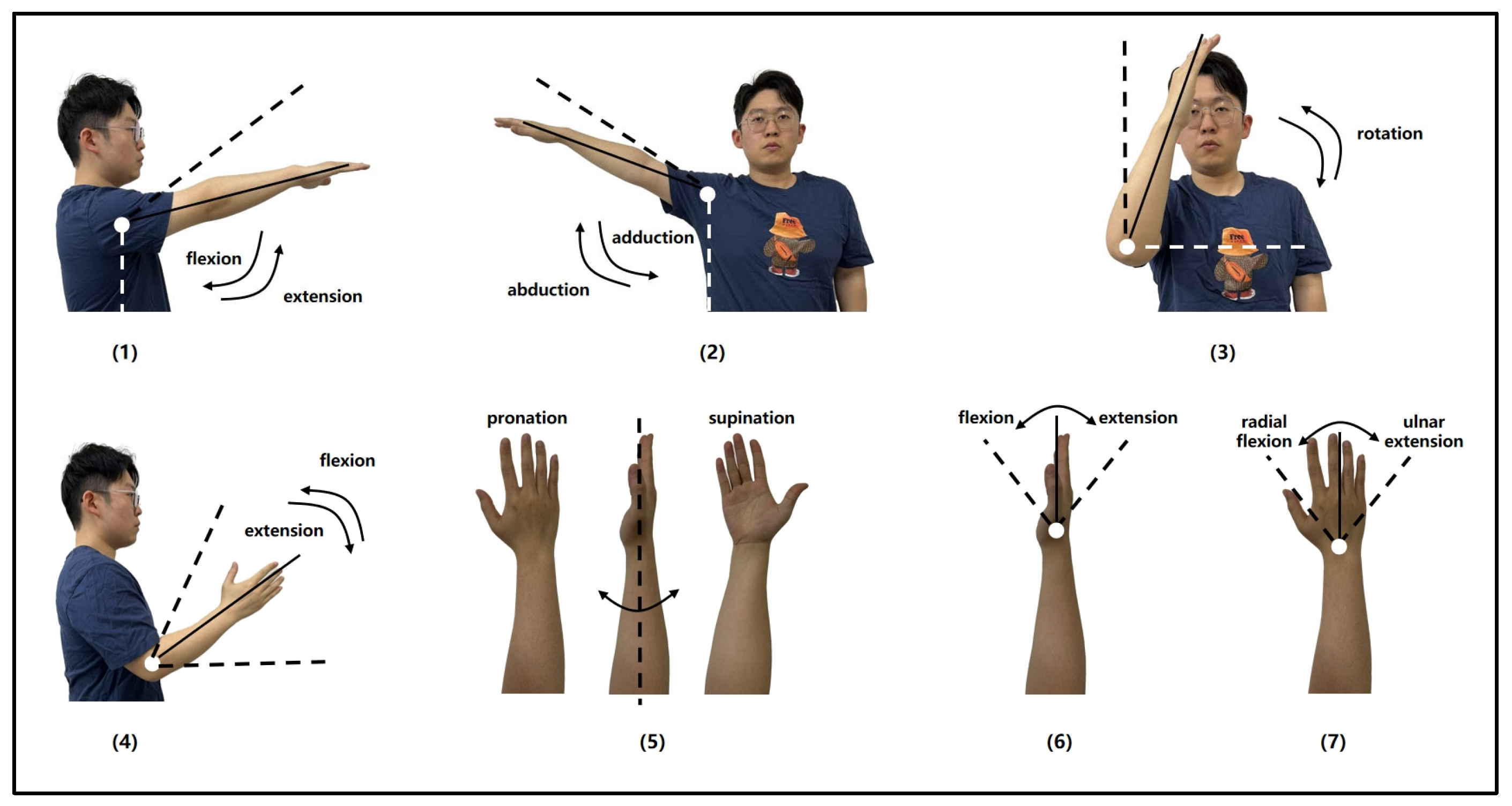
2.1. Experimental Program
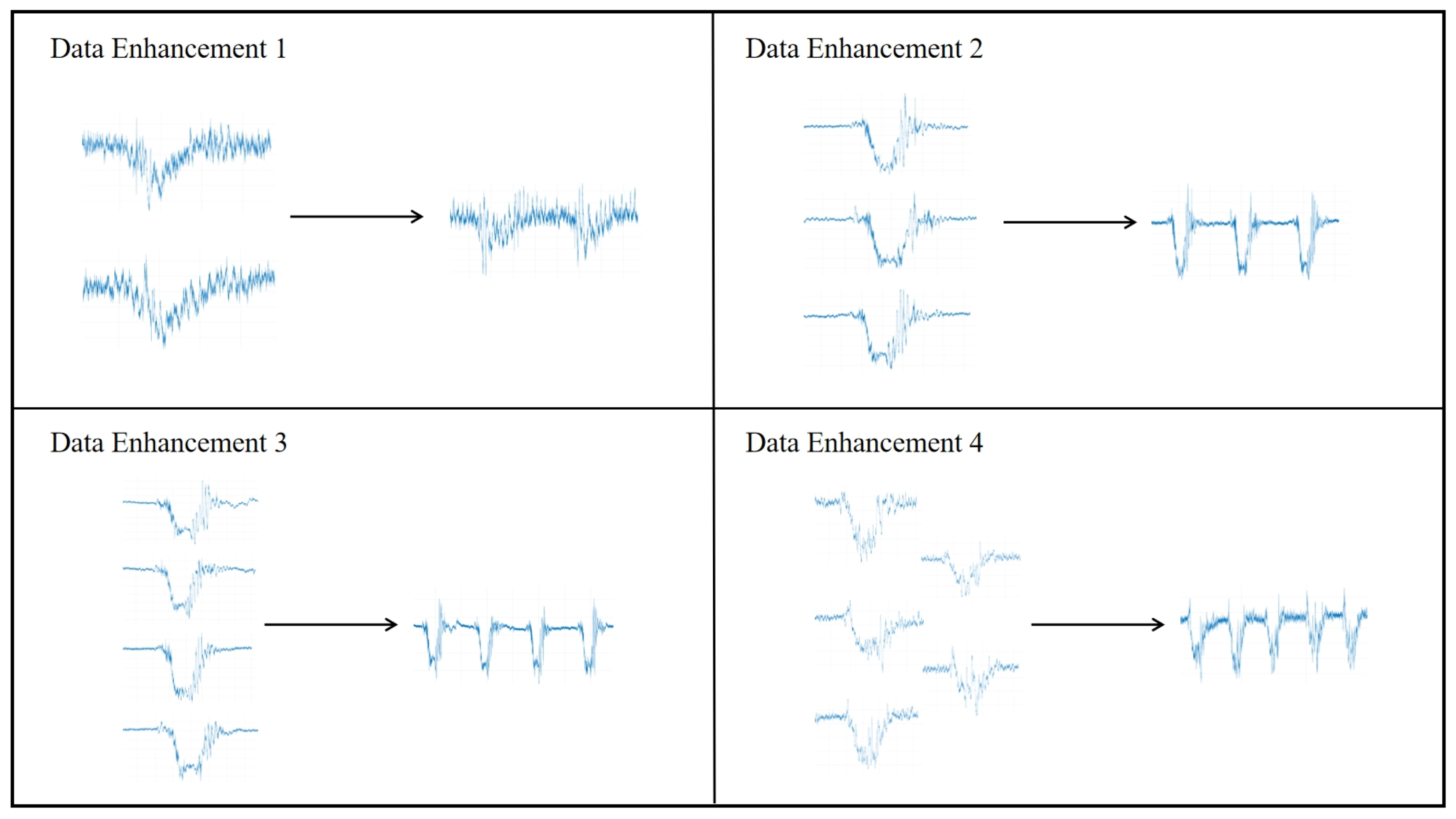
2.2. Data Processing
2.3. YOLOv5-SE Target Detection Model
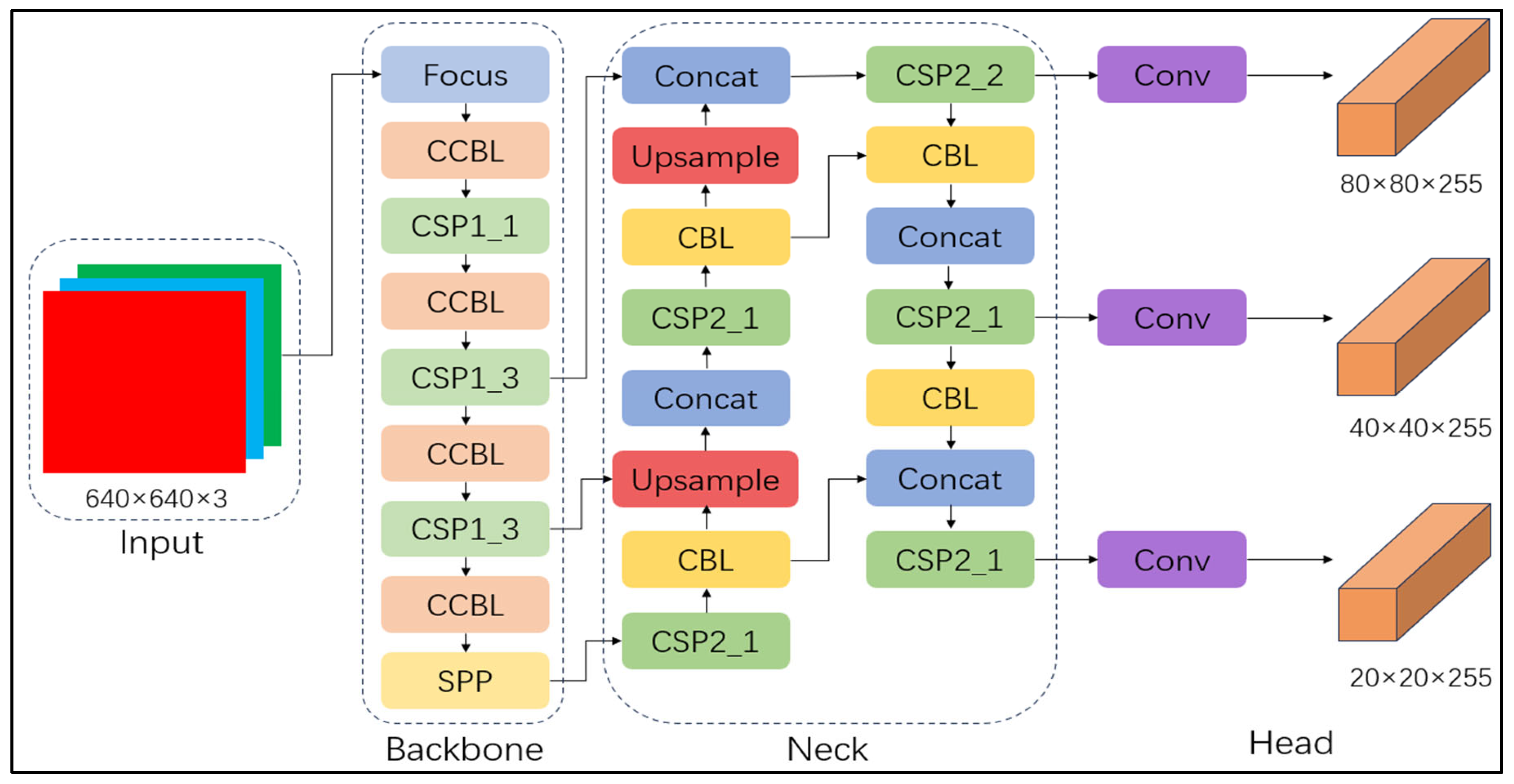
2.3.1. Network Structure of YOLOv5
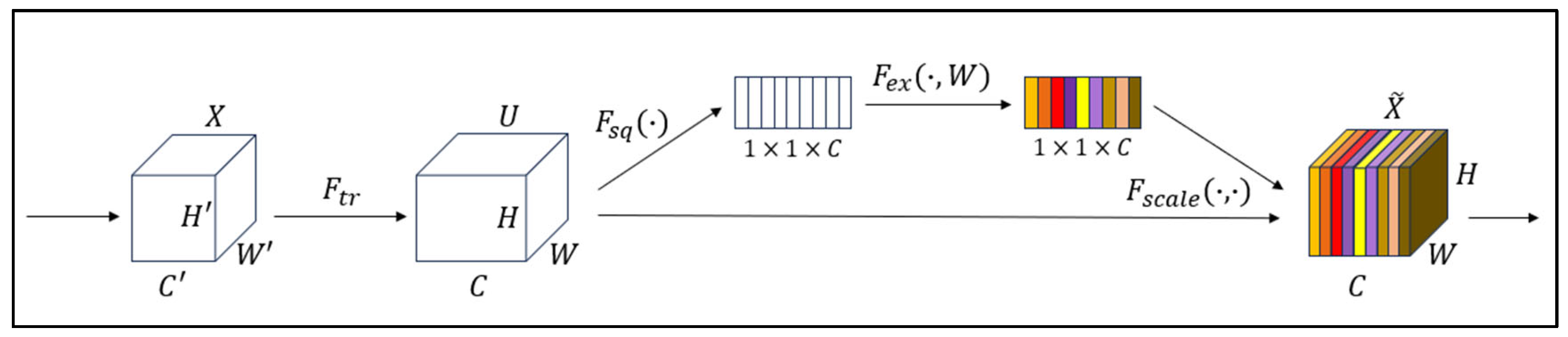
2.3.2. SE Attention Mechanism Module
2.4. Model Performance Evaluation
3. Results
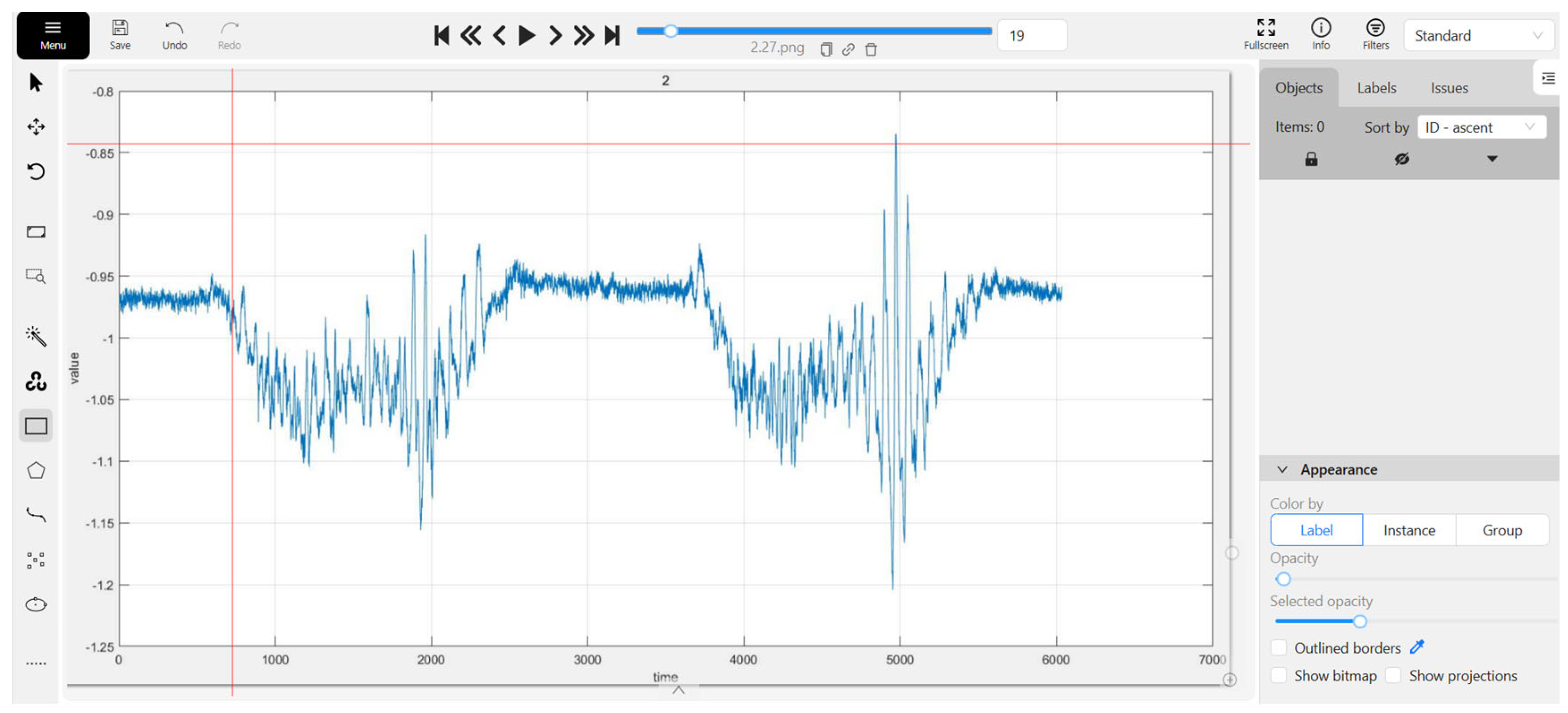
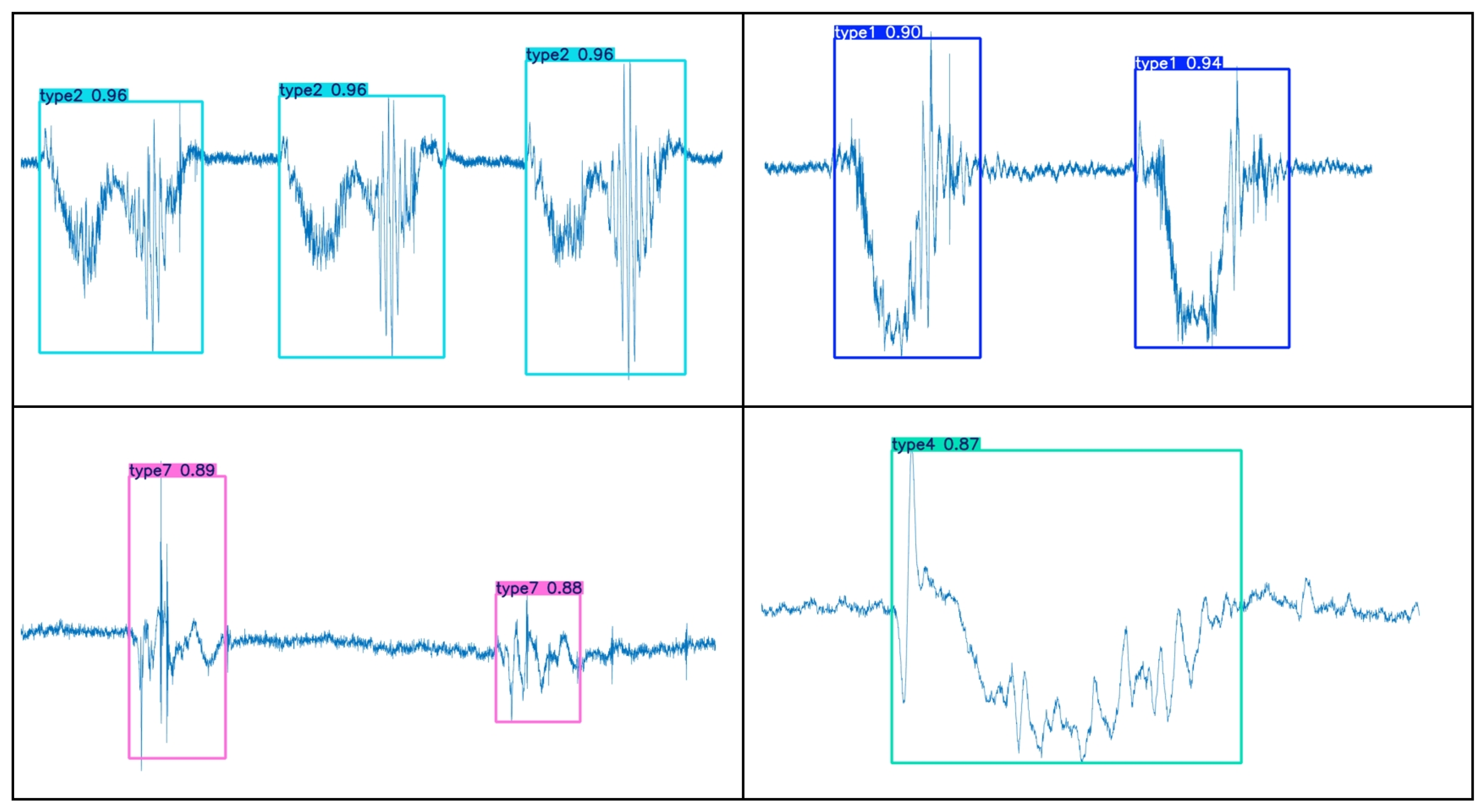
3.1. Motion Segmentation Image
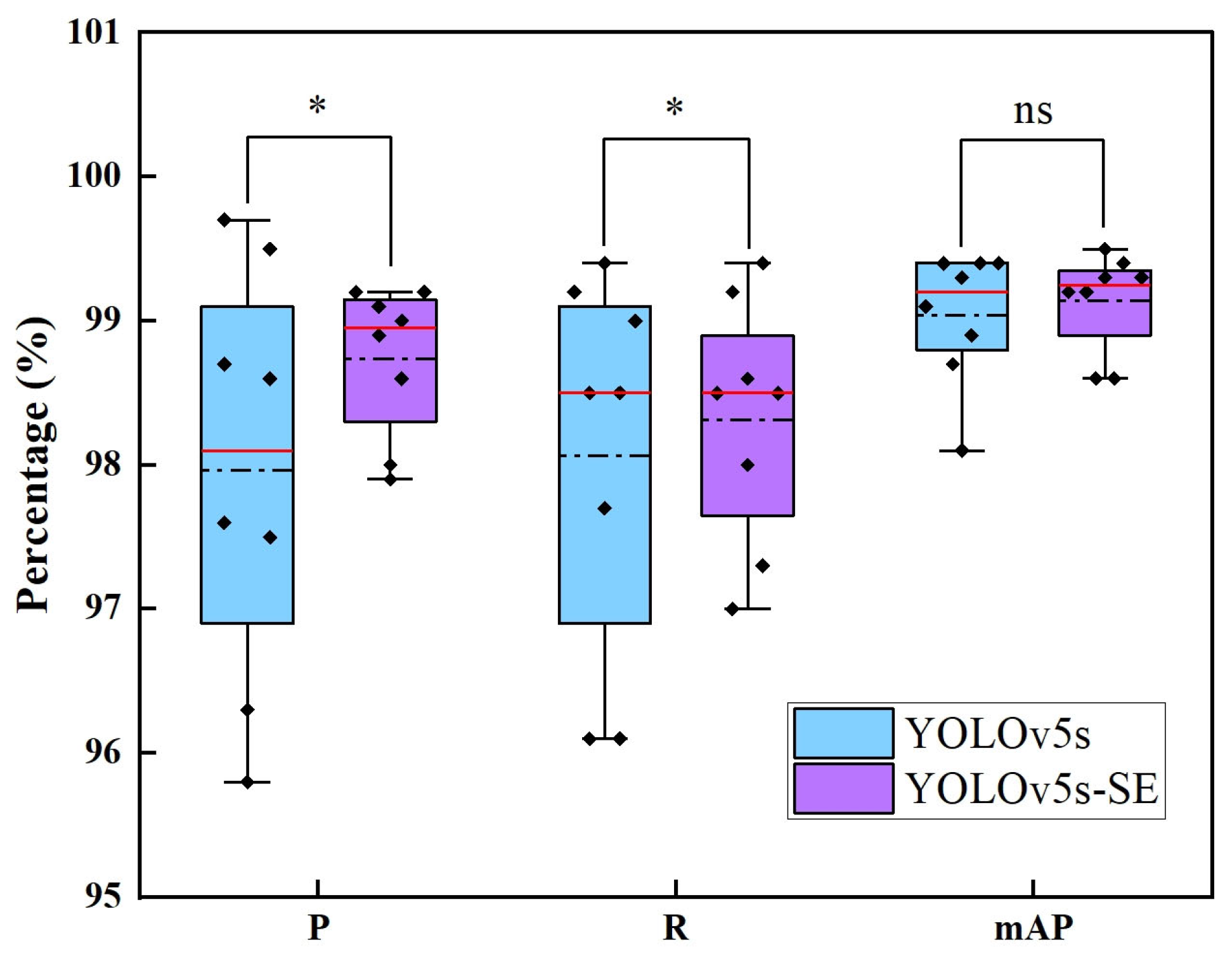
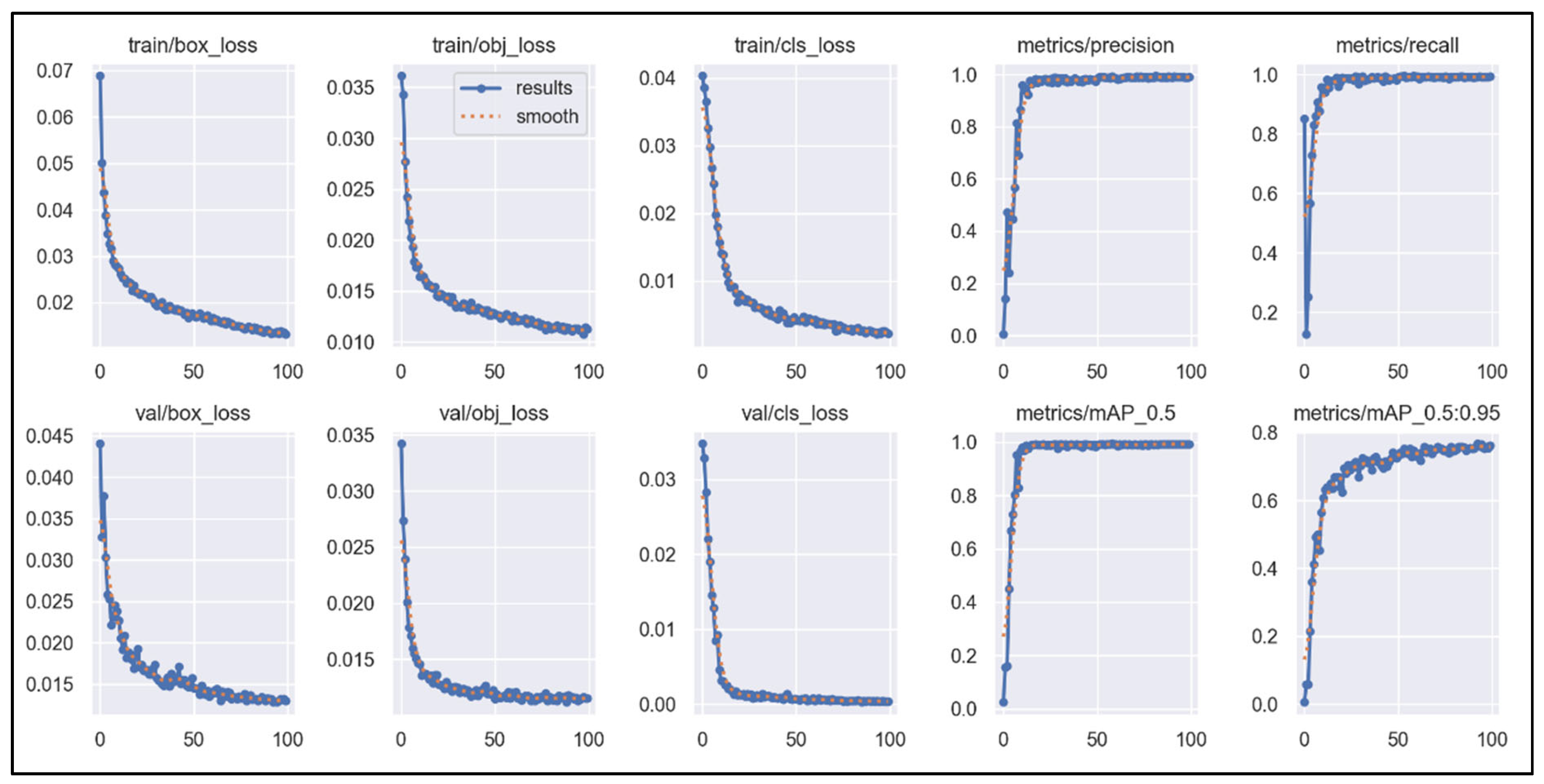
3.2. The Model Performance of YOLOv5s and YOLOv5s-SE
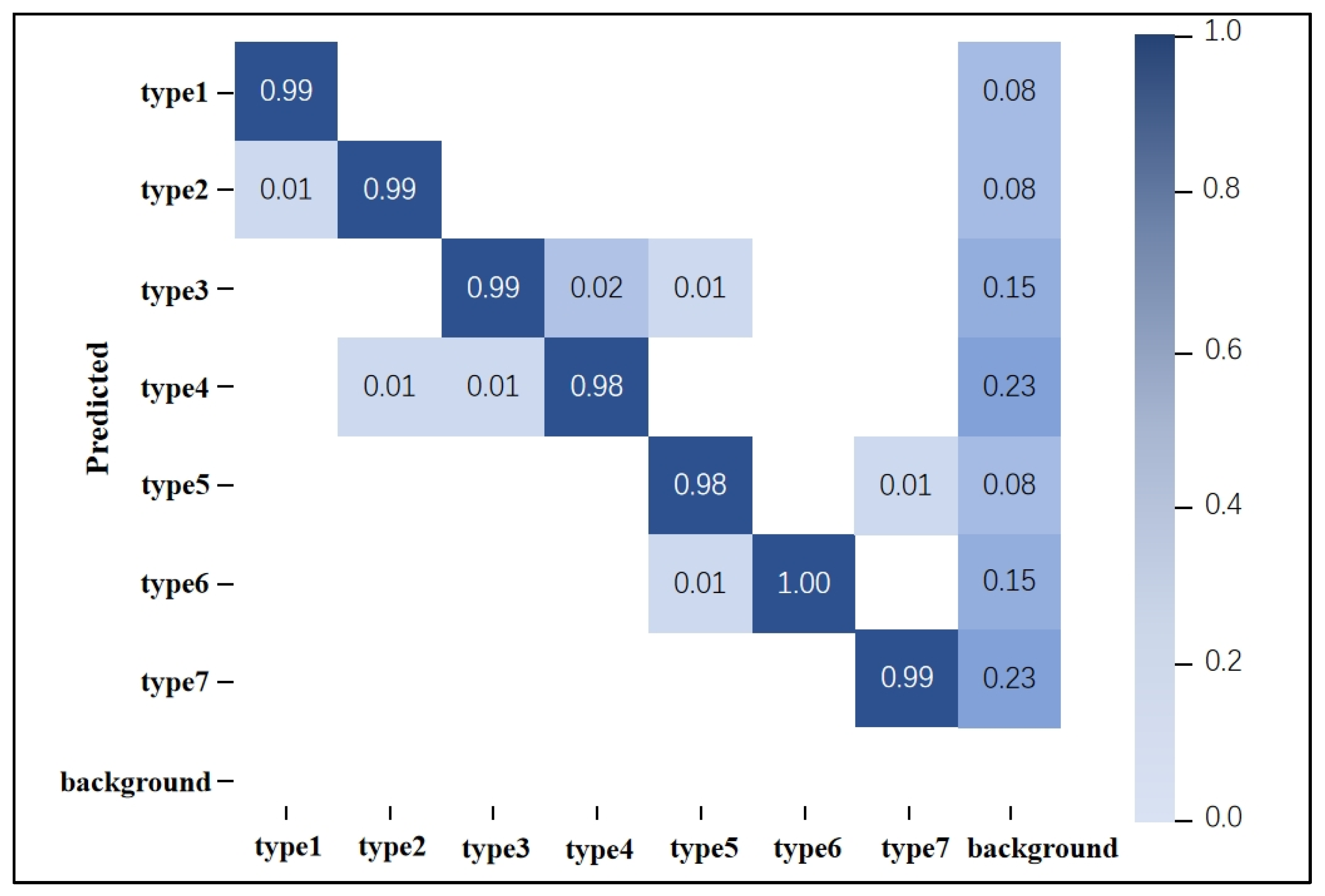
3.3. Motion Pattern Recognition Accuracy Results
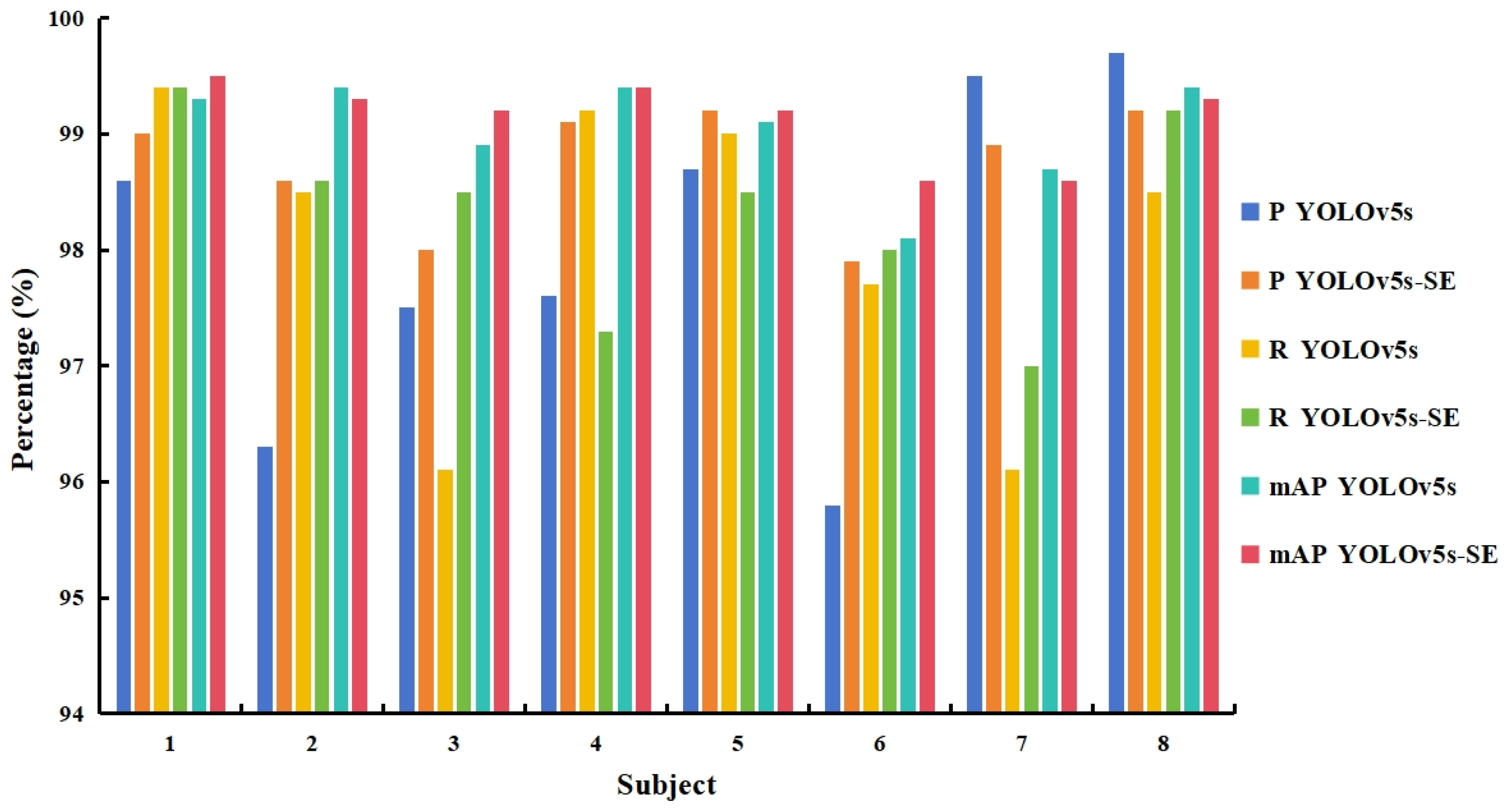
3.4. Model Robustness of YOLOv5s
3.5. Summary
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, H.; Xiong, A. Advances and Disturbances in sEMG-Based Intentions and Movements Recognition: A Review. IEEE Sens. J. 2021, 21, 13019–13028. [Google Scholar] [CrossRef]
- Rodgers, H.; Bosomworth, H.; Krebs, H.I.; van Wijck, F.; Howel, D.; Wilson, N.; Aird, L.; Alvarado, N.; Andole, S.; Cohen, D.L.; et al. Robot assisted training for the upper limb after stroke (RATULS): A multicentre randomised controlled trial. Lancet 2019, 394, 51–62. [Google Scholar] [CrossRef] [PubMed]
- Sammali, E.; Alia, C.; Vegliante, G.; Colombo, V.; Giordano, N.; Pischiutta, F.; Boncoraglio, G.B.; Barilani, M.; Lazzari, L.; Caleo, M.; et al. Intravenous infusion of human bone marrow mesenchymal stromal cells promotes functional recovery and neuroplasticity after ischemic stroke in mice. Sci. Rep. 2017, 7, 6962. [Google Scholar] [CrossRef]
- Miao, Q.; Fu, X.; Chen, Y.F. Sensing equivalent kinematics enables robot-assisted mirror rehabilitation training via a broaden learning system. Front. Bioeng. Biotechnol. 2024, 12, 1484265. [Google Scholar] [CrossRef]
- Curiel, R.C.; Nakamura, T.; Kuzuoka, H.; Kanaya, T.; Prahm, C.; Matsumoto, K. Virtual Reality Self Co-Embodiment: An Alternative to Mirror Therapy for Post-Stroke Upper Limb Rehabilitation. IEEE Trans. Vis. Comput. Graph. 2024, 30, 2390–2399. [Google Scholar] [CrossRef]
- Sardari, S.; Sharifzadeh, S.; Daneshkhah, A.; Nakisa, B.; Loke, S.W.; Palade, V.; Duncan, M.J. Artificial Intelligence for skeleton-based physical rehabilitation action evaluation: A systematic review. Comput. Biol. Med. 2023, 158, 106835. [Google Scholar] [CrossRef]
- Lin, W.; Zeng, H.; Zhu, J.; Hsia, C.-H.; Hou, J.; Ma, K.-K. Unsupervised video-based action recognition using two-stream generative adversarial network. Neural Comput. Appl. 2023, 36, 5077–5091. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, C.; Li, X.; Zhang, Z.-Q.; Yuan, X.; Li, H. Research on Multimodal Fusion Recognition Method of Upper Limb Motion Patterns. IEEE Trans. Instrum. Meas. 2023, 72, 4008312. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Yu, H.; Yang, X.; Lu, W. Learning Effective Spatial–Temporal Features for sEMG Armband-Based Gesture Recognition. IEEE Internet Things J. 2020, 7, 6979–6992. [Google Scholar] [CrossRef]
- Cao, G.; Zhang, Y.; Zhang, H.; Zhao, T.; Xia, C. A Hybrid Recognition Method via Kelm with Cpso for Mmg-Based Upper-Limb Movements Classification. J. Mech. Med. Biol. 2023, 24, 2360084. [Google Scholar] [CrossRef]
- Shen, C.; Pei, Z.; Chen, W.; Wang, J.; Zhang, J.; Chen, Z. Toward Generalization of sEMG-Based Pattern Recognition: A Novel Feature Extraction for Gesture Recognition. IEEE Trans. Instrum. Meas. 2022, 71, 2501412. [Google Scholar] [CrossRef]
- Bi, L.; Feleke, A.G.; Guan, C. A review on EMG-based motor intention prediction of continuous human upper limb motion for human-robot collaboration. Biomed. Signal Process. Control 2019, 51, 113–127. [Google Scholar] [CrossRef]
- Zhang, Y.; Cao, G.; Zhao, T.; Zhang, H.; Zhang, J.; Xia, C. A Pilot Study of Mechanomyography-Based Hand Movements Recognition Emphasizing on the Influence of Fabrics Between Sensor and Skin. J. Mech. Med. Biol. 2020, 20, 2050054. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, M.; Xia, C.; Zhou, J.; Cao, G.; Wu, Q. Mechanomyography Signal Pattern Recognition of Knee and Ankle Movements Using Swarm Intelligence Algorithm-Based Feature Selection Methods. Sensors 2023, 23, 6939. [Google Scholar] [CrossRef]
- Zhang, Y.; Xia, C.; Cao, G.; Zhao, T.; Zhao, Y. Pattern recognition of hand movements based on multi-channel mechanomyography in the condition of one-time collection and sensor doffing and donning. Biomed. Signal Process. Control 2024, 91, 106078. [Google Scholar] [CrossRef]
- Xie, C.; Wang, D.; Wu, H.; Gao, L. A long short-term memory neural network model for knee joint acceleration estimation using mechanomyography signals. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420968702. [Google Scholar] [CrossRef]
- Jo, M.; Ahn, S.; Kim, J.; Koo, B.; Jeong, Y.; Kim, S.; Kim, Y. Mechanomyography for the Measurement of Muscle Fatigue Caused by Repeated Functional Electrical Stimulation. Int. J. Precis. Eng. Manuf. 2018, 19, 1405–1410. [Google Scholar] [CrossRef]
- Ibitoye, M.O.; Hamzaid, N.A.; Hasnan, N.; Abdul Wahab, A.K.; Islam, M.A.; Kean, V.S.; Davis, G.M. Torque and mechanomyogram relationships during electrically-evoked isometric quadriceps contractions in persons with spinal cord injury. Med. Eng. Phys. 2016, 38, 767–775. [Google Scholar] [CrossRef]
- Liu, M.-K.; Lin, Y.-T.; Qiu, Z.-W.; Kuo, C.-K.; Wu, C.-K. Hand Gesture Recognition by a MMG-Based Wearable Device. IEEE Sens. J. 2020, 20, 14703–14712. [Google Scholar] [CrossRef]
- Szumilas, M.; Wladzinski, M.; Wildner, K. A Coupled Piezoelectric Sensor for MMG-Based Human-Machine Interfaces. Sensors 2021, 21, 8380. [Google Scholar] [CrossRef]
- Meagher, C.; Franco, E.; Turk, R.; Wilson, S.; Steadman, N.; McNicholas, L.; Vaidyanathan, R.; Burridge, J.; Stokes, M. New advances in mechanomyography sensor technology and signal processing: Validity and intrarater reliability of recordings from muscle. J. Rehabil. Assist. Technol. Eng. 2020, 7, 2055668320916116. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Xia, C. A preliminary study of classification of upper limb motions and forces based on mechanomyography. Med. Eng. Phys. 2020, 81, 97–104. [Google Scholar] [CrossRef] [PubMed]
- Yan, Z.; Zhang, B.; Wang, D. An FPGA-Based YOLOv5 Accelerator for Real-Time Industrial Vision Applications. Micromachines 2024, 15, 1164. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Yu, H. Weight analysis for various prohibitory sign detection and recognition using deep learning. Multimed. Tools Appl. 2020, 79, 32897–32915. [Google Scholar] [CrossRef]
- Liu, C.; Wu, Y.; Liu, J.; Sun, Z.; Xu, H. Insulator Faults Detection in Aerial Images from High-Voltage Transmission Lines Based on Deep Learning Model. Appl. Sci. 2021, 11, 4647. [Google Scholar] [CrossRef]
- Bu, D.; Guo, S.; Li, H. sEMG-Based Motion Recognition of Upper Limb Rehabilitation Using the Improved Yolo-v4 Algorithm. Life 2022, 12, 64. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Sirisha, U.; Praveen, S.P.; Srinivasu, P.N.; Barsocchi, P.; Bhoi, A.K. Statistical Analysis of Design Aspects of Various YOLO-Based Deep Learning Models for Object Detection. Int. J. Comput. Intell. Syst. 2023, 16, 126. [Google Scholar] [CrossRef]
- Xue, M.; Chen, M.; Peng, D.; Guo, Y.; Chen, H. One Spatio-Temporal Sharpening Attention Mechanism for Light-Weight YOLO Models Based on Sharpening Spatial Attention. Sensors 2021, 21, 7949. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Sun, Z.; Xu, R.; Zheng, X.; Zhang, L.; Zhang, Y. A forest fire detection method based on improved YOLOv5. Signal Image Video Process. 2024, 19, 136. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P (%) | R (%) | mAP (%) |
|---|---|---|---|
| YOLOv5s | 97.9 | 98.0 | 99.0 |
| YOLOv5s-SE | 98.7 | 98.3 | 99.1 |
| Metric | Model | Average Value | Variance | p-Value |
|---|---|---|---|---|
| P | YOLOv5s | 97.9% | 1.26 | 0.016 (p < 0.05) |
| YOLOv5s-SE | 98.7% | 0.45 | ||
| R | YOLOv5s | 98.0% | 1.40 | 0.039 (p < 0.05) |
| YOLOv5s-SE | 98.3% | 0.72 | ||
| mAP | YOLOv5s | 99.0% | 0.30 | 0.313 (p > 0.05) |
| YOLOv5s-SE | 99.1% | 0.29 |
| Model | P (%) | R (%) | mAP (%) |
|---|---|---|---|
| YOLOv5s | 77.3 | 80.0 | 88.6 |
| YOLOv5s-SE | 83.8 | 85.8 | 89.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, G.; Jia, S.; Wu, Q.; Xia, C. MMG-Based Motion Segmentation and Recognition of Upper Limb Rehabilitation Using the YOLOv5s-SE. Sensors 2025, 25, 2257. https://doi.org/10.3390/s25072257
Cao G, Jia S, Wu Q, Xia C. MMG-Based Motion Segmentation and Recognition of Upper Limb Rehabilitation Using the YOLOv5s-SE. Sensors. 2025; 25(7):2257. https://doi.org/10.3390/s25072257
Chicago/Turabian StyleCao, Gangsheng, Shen Jia, Qing Wu, and Chunming Xia. 2025. "MMG-Based Motion Segmentation and Recognition of Upper Limb Rehabilitation Using the YOLOv5s-SE" Sensors 25, no. 7: 2257. https://doi.org/10.3390/s25072257
APA StyleCao, G., Jia, S., Wu, Q., & Xia, C. (2025). MMG-Based Motion Segmentation and Recognition of Upper Limb Rehabilitation Using the YOLOv5s-SE. Sensors, 25(7), 2257. https://doi.org/10.3390/s25072257