
Electrocardiographic Discrimination of Long QT Syndrome Genotypes: A Comparative Analysis and Machine Learning Approach



Abstract
1. Introduction
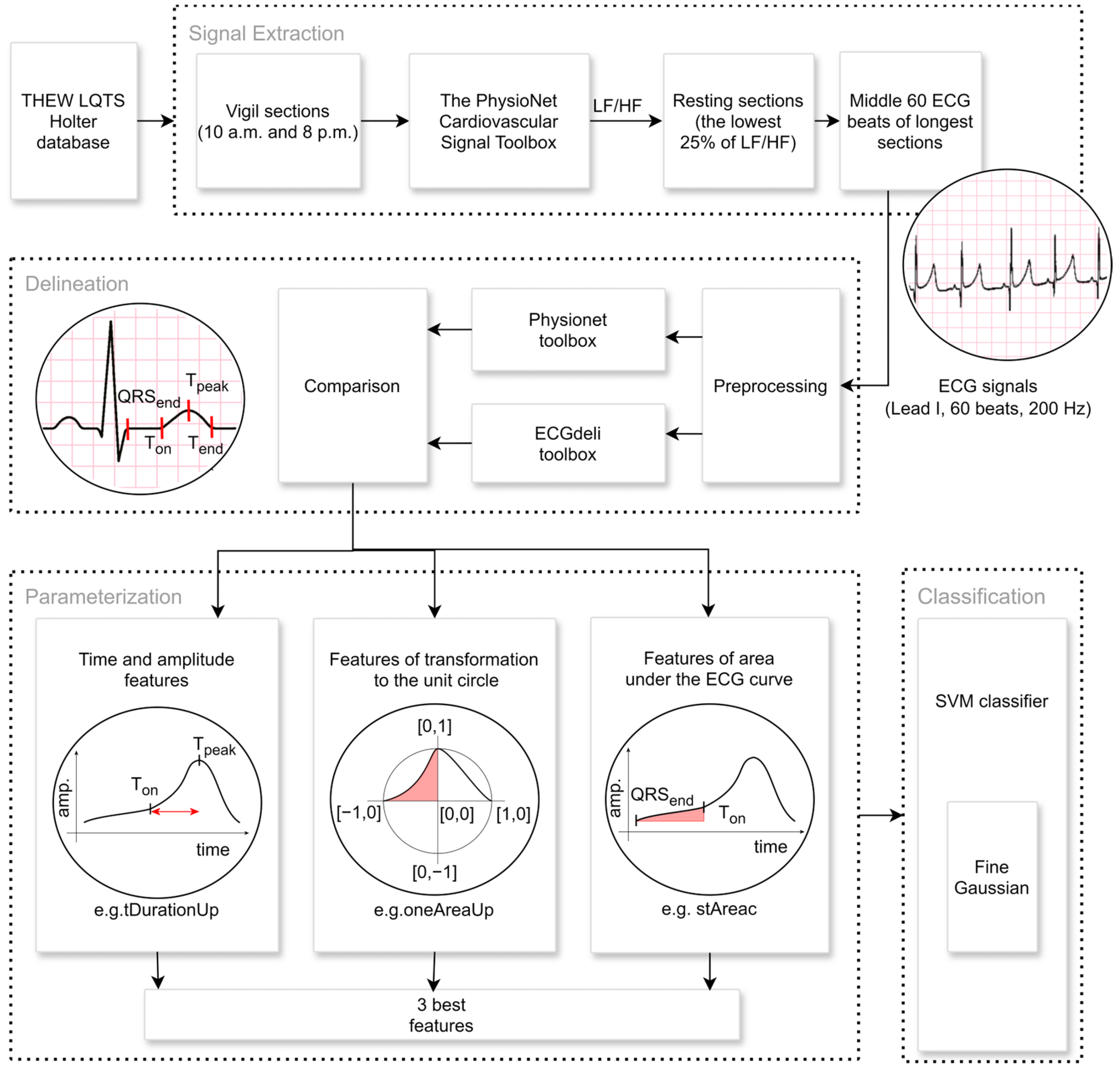
2. Materials and Methods
2.1. Data Acquisition and Study Population
2.1.1. Inclusion Criteria
2.1.2. Data Processing and Selection
2.1.3. Dataset Characterization and Preparation
2.1.4. Control Group Selection
2.2. Extraction of Signal Parts
2.3. Feature Extraction
- tDuration: The time duration between the T-wave’s beginning (Ton) and the end (Tend) (Figure 2).
- tDurationUp: The time duration between the T-wave’s beginning (Ton) and peak (Tpeak) (Figure 2).
- tDurationDown: The time duration between the peak (Tpeak) and the end (Tend) of the T-wave (Figure 2).
- stRise-perc: It is calculated as (Amplitude (Ton) − Amplitude (QRSend))/(Amplitude (Tpeak) − Amplitude (QRSend)).
- stDuration: The time duration of the ST segment is calculated as the time difference between QRSend and the Ton.
- st-rrRatio: The parameter is calculated as a ratio between the stDuration and the duration of the RR interval.
- tAreaUpc: The area under (in the case of positive T-wave) or above (in the case of negative T-wave) the ECG signal is time-limited by the beginning (Ton) and peak (Tpeak) of the T-wave. The ECG amplitude values are shifted so that the Ton amplitude equals zero. The ECG values, which are lower than the amplitude of Ton, are considered zero values in the case of a positive T-wave (or higher in the case of a negative T-wave). The integral is calculated using the rectangle method that starts at the peak point. The parameter assumes values greater than zero for positive T-waves and values lower than zero for negative T-waves.
- tAreaDownc: The area is calculated analogically as a tAreaUpc, just as the border values are used as Tpeak and the end (Tend) of the T-wave. The parameter also assumes values greater than zero for positive T-waves and values lower than zero for negative T-waves.
- tAreac: It is counted as a sum of the parameters tAreaUpc and tAreaDownc mentioned above.
- tAreacUpDownRatio: It is counted as the tAreaUpc divided by tAreaDownc.
- stAreac: The area under (in the case of a rising ST segment) or above (in the case of a decreasing ST segment) the time-limited ECG signal bordered by the QRS offset (QRSend) and the beginning of the T-wave (Ton). The ECG amplitude values are shifted so that the QRSend amplitude equals zero. ECG values lower than QRSend amplitude are considered zero values. The integral is calculated using the rectangle method that starts at the peak point. The parameter assumes values greater than zero for the rising ST segments and values lower than zero for the decreasing ST.
- oneAreaUp: The T-wave is transformed to the unit circle, where the point of the ECG signal [Time(Tpeak), Amplitude(Ton)] corresponds to the point [0,0] of the unit circle, [Time(Tpeak), Amplitude(Tpeak)] to the point [0,1], [Time(Ton), Amplitude(Ton)] to [−1,0]. Then, the area of the transformed T-wave is calculated analogously to tAreaUpc. The parameter’s value is always positive (Figure 2).
- oneAreaDdown: The T-wave is transformed into the unit circle, where the point of the ECG signal [Time(Tpeak), Amplitude(Tend)] corresponds to the point [0,0] of the unit circle, [Time(Tpeak), Amplitude(Tpeak)] to the point [0,1], [Time(Tend), Amplitude(Tend)] to [1,0]. Then, the area of the transformed T-wave is calculated analogously to tAreaDownc. The value of the parameter is always positive (Figure 2).
- ratioUpDown-perc: The value is counted as the ratio oneAreaUp/oneAreaDown.
- oneSTTAreaUp: The T-wave is transformed into the unit circle, where the point of the ECG signal [Time(Tpeak), Amplitude(QRSend)] corresponds to the point [0,0] of the unit circle, [Time(Tpeak), Amplitude(Tpeak)] to the point [0,1], [Time(QRSend), and Amplitude(QRSend)] to [−1,0]. Then, the area of the transformed T-wave is calculated analogously to tAreaUpc. The parameter’s value is always positive.
- ratioSTTUpDown-perc: The value is counted as the ratio oneSTTAreaUp/oneAreaDown.
- tAreacPerSec: The parameter is counted as a tAreac/tDuration. The ratio eliminates the influence of the variation in the RR interval.
- tAreacUpPerSec: The parameter is counted as a tAreacUp/tDurationUp. The ratio eliminates the influence of the variation in the RR interval.
- tAreacDownPerSec: The parameter is counted as tAreacDown/tDuratioDown. The ratio eliminates the influence of the variation in the RR interval.
- stAreacPerSec: The parameter is calculated as stAreac/stDuration.
2.4. Statistical Analysis
2.4.1. Discrimination Analysis
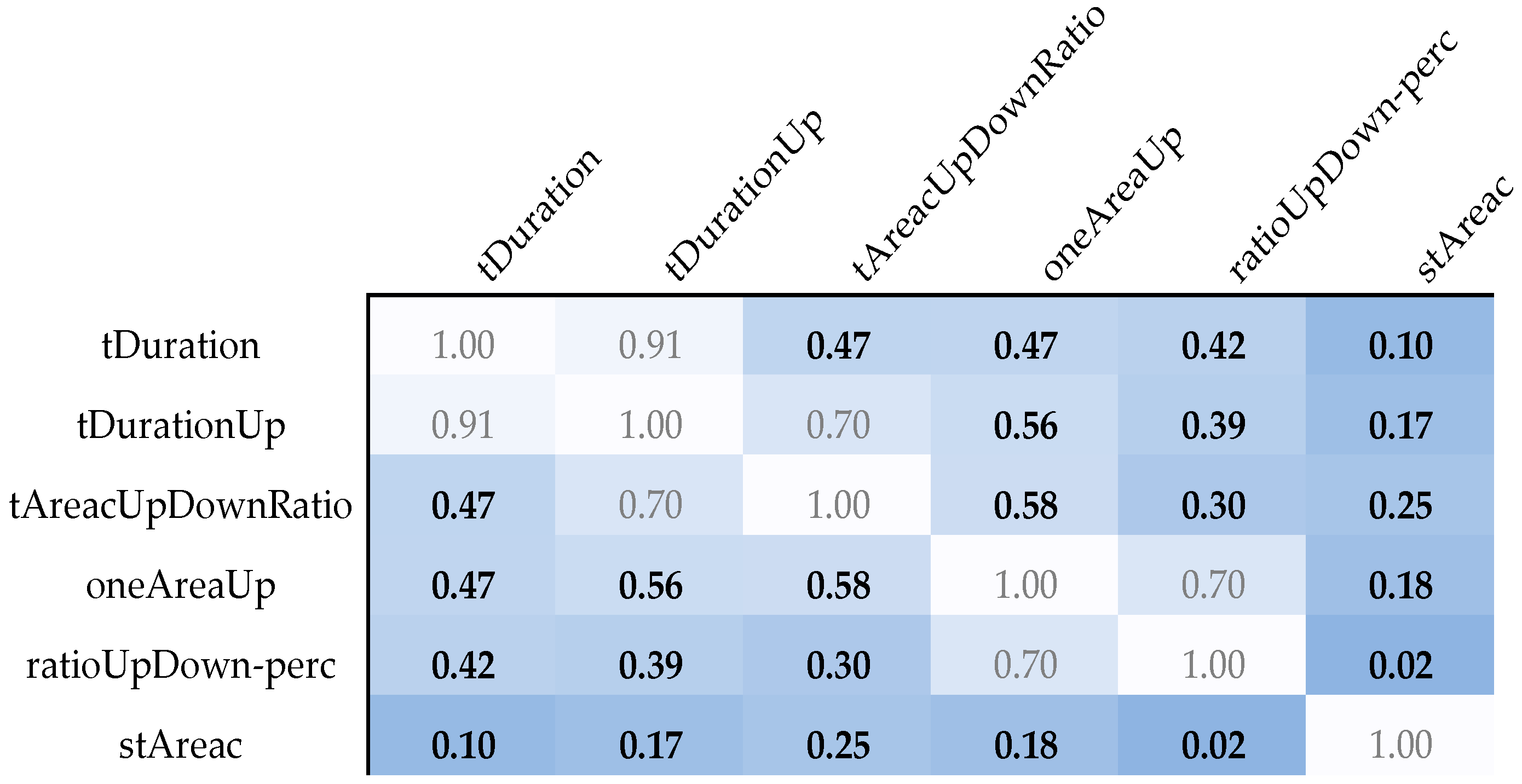
2.4.2. Correlation Analysis
2.4.3. Feature Selection
2.5. Classification Model
Classifier Performance Measurements
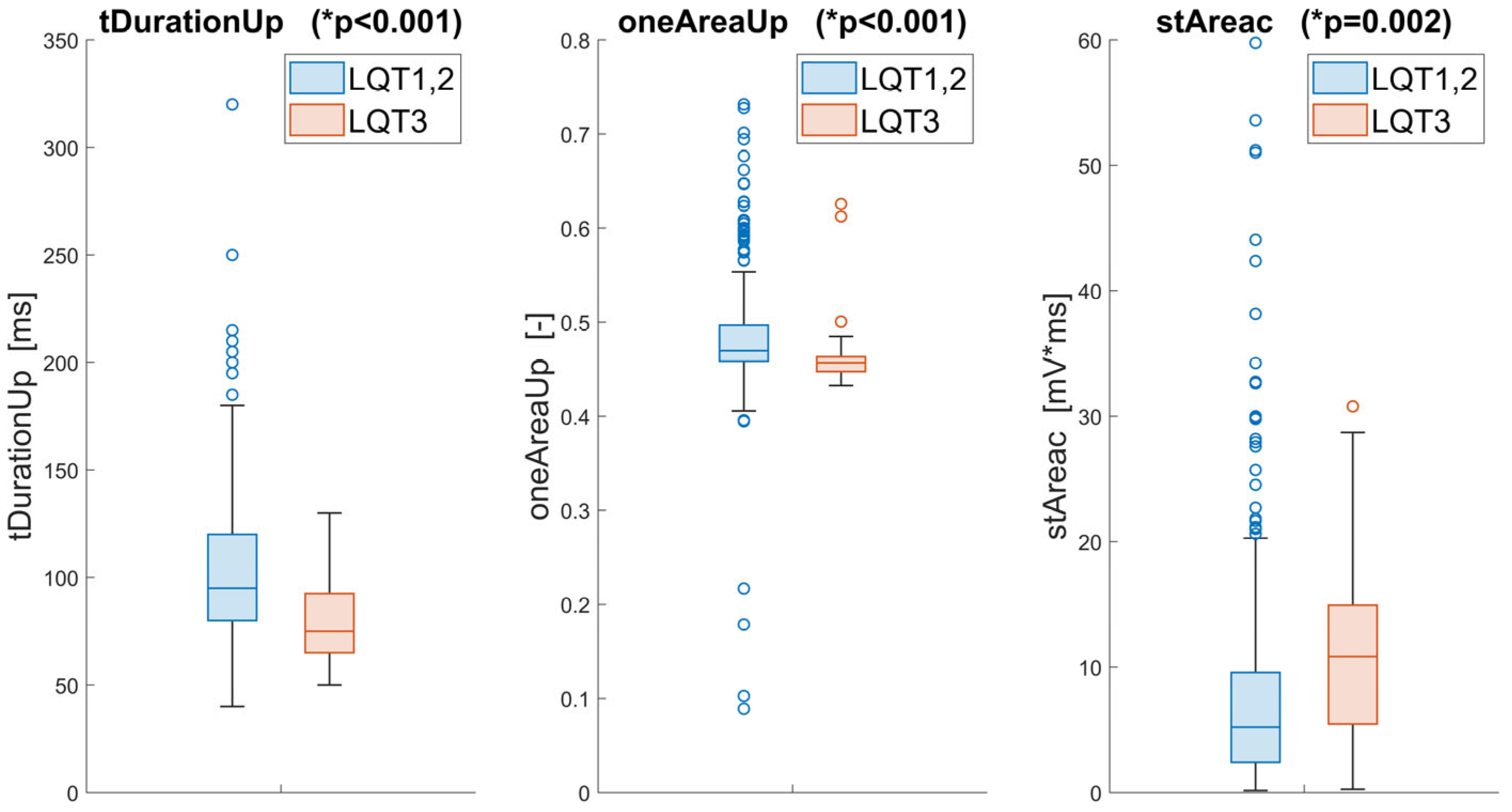
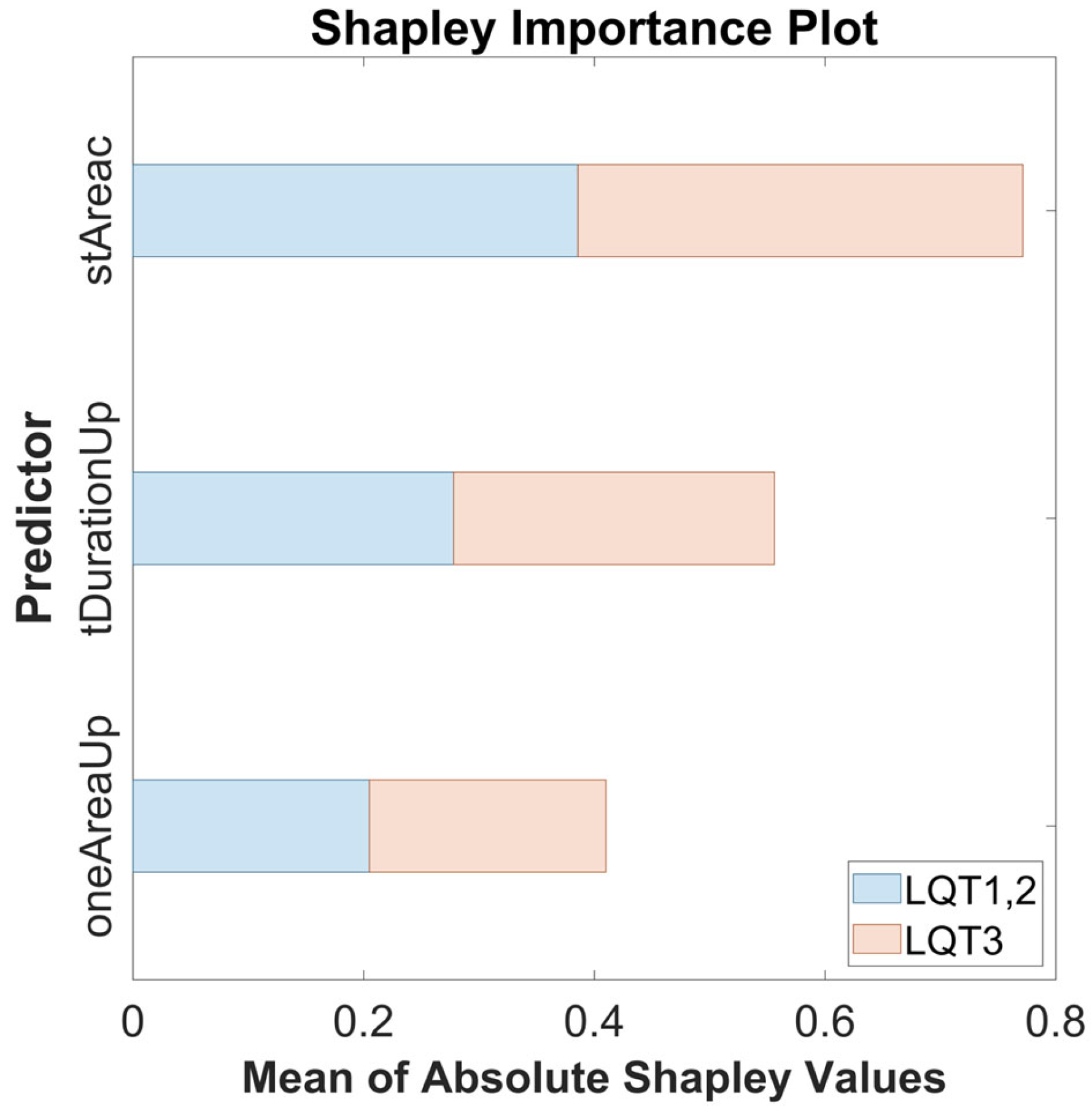
3. Results
4. Discussion
Limitations—Reflective Considerations on Methodological Constraints
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AUC | Area under the receiver operating characteristic curve |
| C | Box Constraints |
| CNN | Convolutional Neural Networks |
| ECG | Electrocardiogram |
| HF | High frequency |
| HRV | Heart rate variability |
| LF | Low frequency |
| LQTS | Long QT syndrome |
| LSTM | Long-Short-Term Memory |
| KS | Kernel Scale |
| ROC | Receiver operating characteristic |
| SHAP | Shapley Additive Explanations |
| SVM | Support Vector Machine |
| TdP | Torsades de pointes |
| THEW | Telemetric and Holter ECG Warehouse |
References
- Schwartz, P.J.; Priori, S.G.; Spazzolini, C.; Moss, A.J.; Vincent, G.M.; Napolitano, C.; Denjoy, I.; Guicheney, P.; Breithardt, G.; Keating, M.T.; et al. Genotype-Phenotype Correlation in the Long-QT Syndrome. Circulation 2001, 103, 89–95. [Google Scholar] [CrossRef] [PubMed]
- Abrams, D.J.; MacRae, C.A. Long QT Syndrome. Circulation 2014, 129, 1524–1529. [Google Scholar] [CrossRef] [PubMed]
- Rohatgi, R.K.; Sugrue, A.; Bos, J.M.; Cannon, B.C.; Asirvatham, S.J.; Moir, C.; Owen, H.J.; Bos, K.M.; Kruisselbrink, T.; Ackerman, M.J. Contemporary Outcomes in Patients With Long QT Syndrome. J. Am. Coll. Cardiol. 2017, 70, 453–462. [Google Scholar] [CrossRef]
- Goldenberg, I.; Moss, A.J. Long QT Syndrome. J. Am. Coll. Cardiol. 2008, 51, 2291–2300. [Google Scholar] [CrossRef]
- Schwartz, P.J.; Crotti, L.; Insolia, R. Long-QT Syndrome. Circ. Arrhythmia Electrophysiol. 2012, 5, 868–877. [Google Scholar] [CrossRef]
- Zareba, W.; Cygankiewicz, I. Long QT Syndrome and Short QT Syndrome. Prog. Cardiovasc. Dis. 2008, 51, 264–278. [Google Scholar] [CrossRef]
- Khositseth, A.; Tester, D.J.; Will, M.L.; Bell, C.M.; Ackerman, M.J. Identification of a Common Genetic Substrate Underlying Postpartum Cardiac Events in Congenital Long QT Syndrome. Heart Rhythm 2004, 1, 60–64. [Google Scholar] [CrossRef]
- Moss, A.J.; Robinson, J.L.; Gessman, L.; Gillespie, R.; Zareba, W.; Schwartz, P.J.; Vincent, G.M.; Benhorin, J.; Heilbron, E.L.; Towbin, J.A.; et al. Comparison of Clinical and Genetic Variables of Cardiac Events Associated with Loud Noise Versus Swimming Among Subjects with the Long QT Syndrome. Am. J. Cardiol. 1999, 84, 876–879. [Google Scholar] [CrossRef]
- Shimizu, W.; Antzelevitch, C. Differential Effects of Beta-Adrenergic Agonists and Antagonists in LQT1, LQT2 and LQT3 Models of the Long QT Syndrome. J. Am. Coll. Cardiol. 2000, 35, 778–786. [Google Scholar] [CrossRef]
- Tardo, D.T.; Peck, M.; Subbiah, R.N.; Vandenberg, J.I.; Hill, A.P. The Diagnostic Role of T Wave Morphology Biomarkers in Congenital and Acquired Long QT Syndrome: A Systematic Review. Ann. Noninvasive Electrocardiol. 2023, 28, e13015. [Google Scholar] [CrossRef]
- Bos, J.M.; Attia, Z.I.; Albert, D.E.; Noseworthy, P.A.; Friedman, P.A.; Ackerman, M.J. Use of Artificial Intelligence and Deep Neural Networks in Evaluation of Patients with Electrocardiographically Concealed Long QT Syndrome from the Surface 12-Lead Electrocardiogram. JAMA Cardiol. 2021, 6, 532–538. [Google Scholar] [CrossRef] [PubMed]
- Gima, K.; Rudy, Y. Ionic Current Basis of Electrocardiographic Waveforms: A Model Study. Circ. Res. 2002, 90, 889–896. [Google Scholar] [CrossRef] [PubMed]
- Shimizu, W.; Antzelevitch, C. Cellular Basis for the ECG Features of the LQT1 Form of the Long-QT Syndrome. Circulation 1998, 98, 2314–2322. [Google Scholar] [CrossRef] [PubMed]
- Shimizu, W.; Antzelevitch, C. Sodium Channel Block with Mexiletine Is Effective in Reducing Dispersion of Repolarization and Preventing Torsade de Pointes in LQT2 and LQT3 Models of the Long-QT Syndrome. Circulation 1997, 96, 2038–2047. [Google Scholar] [CrossRef]
- Zhang, L.; Timothy, K.W.; Vincent, G.M.; Lehmann, M.H.; Fox, J.; Giuli, L.C.; Shen, J.; Splawski, I.; Priori, S.G.; Compton, S.J.; et al. Spectrum of ST-T–Wave Patterns and Repolarization Parameters in Congenital Long-QT Syndrome. Circulation 2000, 102, 2849–2855. [Google Scholar] [CrossRef]
- Couderc, J.-P. A Unique Digital Electrocardiographic Repository for the Development of Quantitative Electrocardiography and Cardiac Safety: The Telemetric and Holter ECG Warehouse (THEW). J. Electrocardiol. 2010, 43, 595–600. [Google Scholar] [CrossRef]
- Malik, M.; Bigger, J.T.; Camm, A.J.; Kleiger, R.E.; Malliani, A.; Moss, A.J.; Schwartz, P.J. Heart Rate Variability: Standards of Measurement, Physiological Interpretation, and Clinical Use. Eur. Heart J. 1996, 17, 354–381. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.-K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation 2000, 101, e215–e220. [Google Scholar]
- Vest, A.N.; Poian, G.D.; Li, Q.; Liu, C.; Nemati, S.; Shah, A.J.; Clifford, G.D. An Open Source Benchmarked Toolbox for Cardiovascular Waveform and Interval Analysis. Physiol. Meas. 2018, 39, 105004. [Google Scholar] [CrossRef]
- Pilia, N.; Nagel, C.; Lenis, G.; Becker, S.; Dössel, O.; Loewe, A. ECGdeli—An Open Source ECG Delineation Toolbox for MATLAB. SoftwareX 2021, 13, 100639. [Google Scholar] [CrossRef]
- Jiang, R.; Cheung, C.C.; Garcia-Montero, M.; Davies, B.; Cao, J.; Redfearn, D.; Laksman, Z.M.; Grondin, S.; Atallah, J.; Escudero, C.A.; et al. Deep Learning–Augmented ECG Analysis for Screening and Genotype Prediction of Congenital Long QT Syndrome. JAMA Cardiol. 2024, 9, 377–384. [Google Scholar] [CrossRef] [PubMed]
- Andrew, A.M. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods by Nello Christianini and John Shawe-Taylor, Cambridge University Press, Cambridge, 2000, Xiii+189 pp., ISBN 0-521-78019-5 (Hbk, £27.50). Robotica 2000, 18, 687–689. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS): Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: San Francisco, CA, USA, 2017; Volume 30. [Google Scholar]
- Immanuel, S.A.; Sadrieh, A.; Baumert, M.; Couderc, J.P.; Zareba, W.; Hill, A.P.; Vandenberg, J.I. T-Wave Morphology Can Distinguish Healthy Controls from LQTS Patients. Physiol. Meas. 2016, 37, 1456. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Dataset | Testing Dataset | |||||
|---|---|---|---|---|---|---|
| LQTS Groups | LQT1 | LQT2 | LQT3 | LQT1 | LQT2 | LQT3 |
| Number of signals | 137 | 58 | 21 | 68 | 28 | 10 |
| Weights | 1 | 1 | 9.3 | 1 | 1 | 9.6 |
| Balanced number of signals | 137 | 58 | 195 | 68 | 28 | 96 |
| Predictor | LQT1,2 | LQT3 |
|---|---|---|
| tDurationUp | 0.29 | 0.29 |
| oneAreaUp | 0.22 | 0.22 |
| stAreac | 0.41 | 0.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Srutova, M.; Kremen, V.; Lhotska, L. Electrocardiographic Discrimination of Long QT Syndrome Genotypes: A Comparative Analysis and Machine Learning Approach. Sensors 2025, 25, 2253. https://doi.org/10.3390/s25072253
Srutova M, Kremen V, Lhotska L. Electrocardiographic Discrimination of Long QT Syndrome Genotypes: A Comparative Analysis and Machine Learning Approach. Sensors. 2025; 25(7):2253. https://doi.org/10.3390/s25072253
Chicago/Turabian StyleSrutova, Martina, Vaclav Kremen, and Lenka Lhotska. 2025. "Electrocardiographic Discrimination of Long QT Syndrome Genotypes: A Comparative Analysis and Machine Learning Approach" Sensors 25, no. 7: 2253. https://doi.org/10.3390/s25072253
APA StyleSrutova, M., Kremen, V., & Lhotska, L. (2025). Electrocardiographic Discrimination of Long QT Syndrome Genotypes: A Comparative Analysis and Machine Learning Approach. Sensors, 25(7), 2253. https://doi.org/10.3390/s25072253