
SF-DETR: A Scale-Frequency Detection Transformer for Drone-View Object Detection


Abstract
1. Introduction
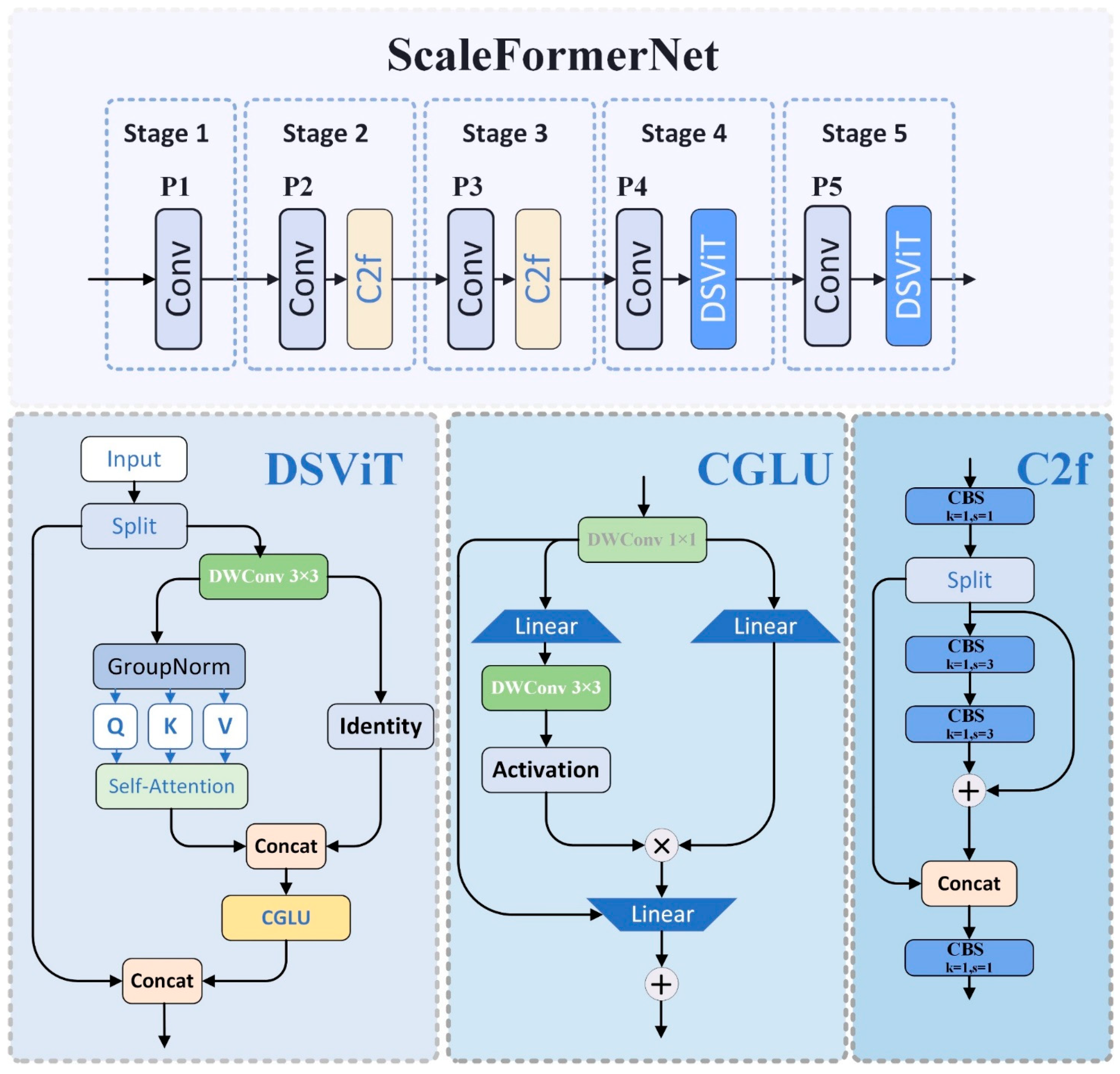
- We introduce a dual-stream vision transformer (DSViT) that enables parallel processing, where one stream preserves original features via identity connections at deeper layers (P4 and P5), while the other refines feature representations. Unlike existing single-stream architectures or CNN–Transformer hybrids, our DSViT preserves both the original and refined feature representations, achieving 1.9% higher with 31.8% fewer parameters compared with RT-DETR.
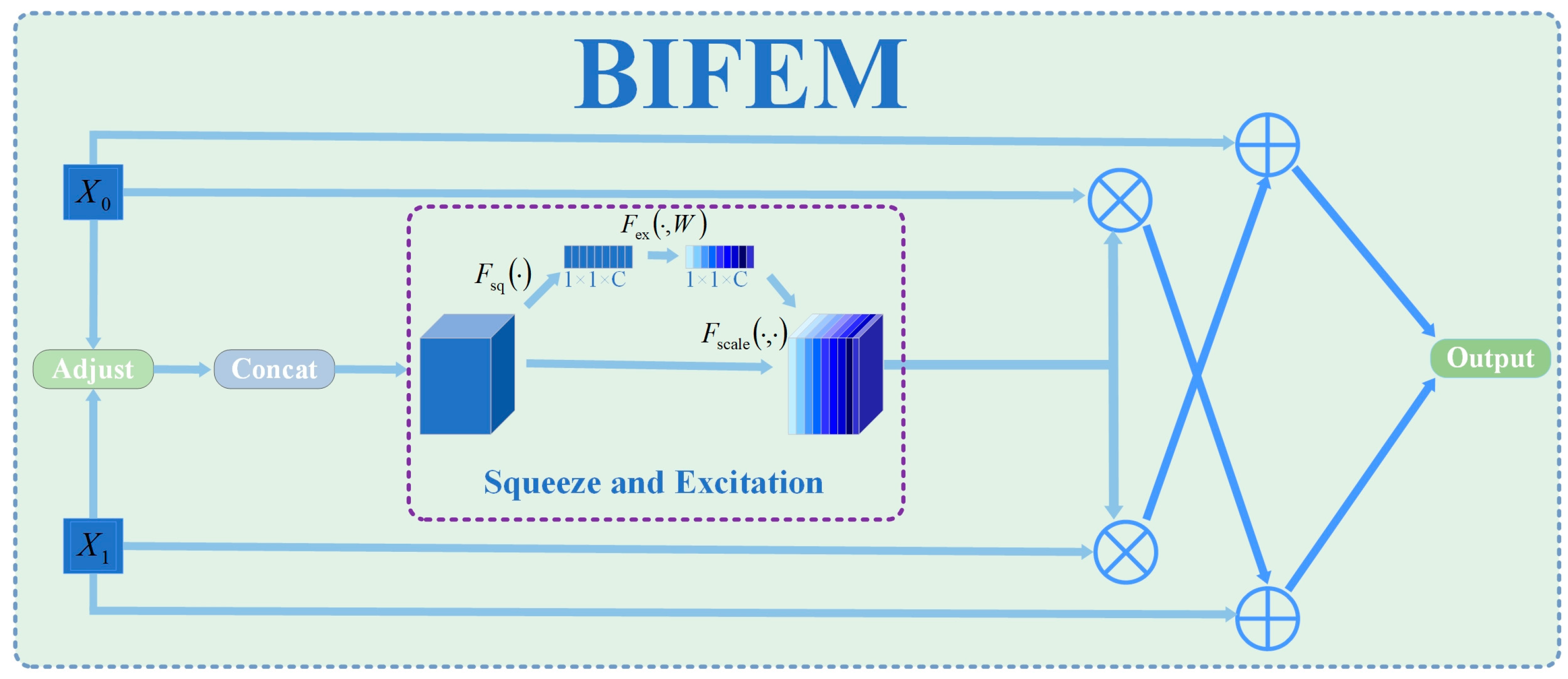
- We propose a Bilateral Interactive Feature Enhancement Mechanism (BIFEM) that facilitates bidirectional information flow between hierarchical features using attention-based channels. While previous methods use unidirectional feature fusion or static fusion strategies, BIFEM dynamically links fine-grained spatial details with high-level contextual information through dual attention paths, improving localization accuracy for small objects in dense clusters by 8.3% compared with single-direction approaches.
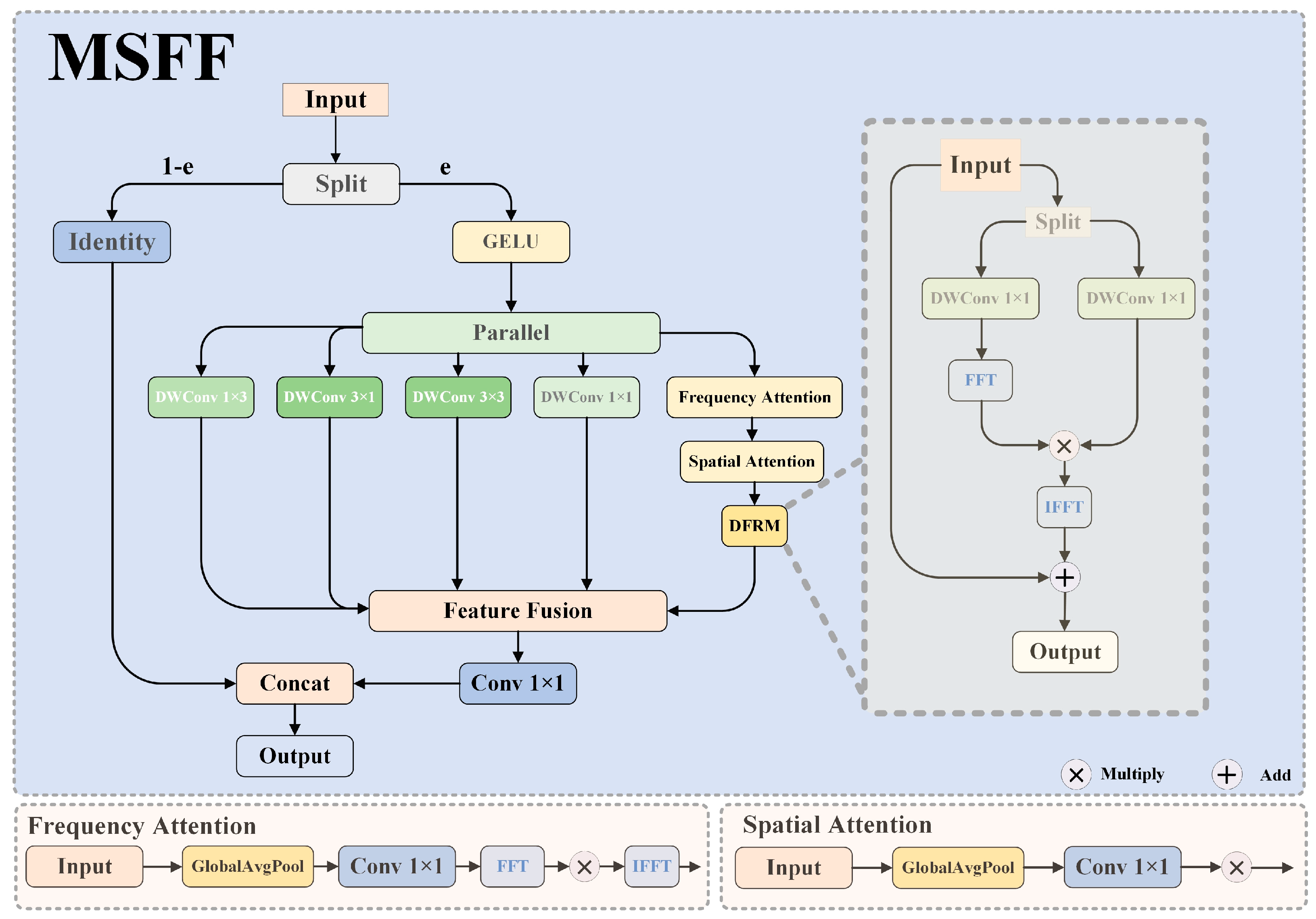
- We develop a novel Multi-Scale Frequency Fusion (MSFF) module that uniquely integrates spatial and frequency–domain processing via parallel branches. Unlike conventional spatial-only approaches or computationally intensive frequency analysis methods, MSFF efficiently extracts the high-frequency components crucial for small object details while maintaining real-time performance, enhancing scale-adaptive features with only 2.4% additional computational cost while improving detection accuracy by 1.7%.
- Extensive experiments on VisDrone2019 and HIT-UAV demonstrate significant improvements in the detection of small objects, complex urban scenes, and varying flight conditions. SF-DETR achieves 51.0% on VisDrone2019 and 86.5% on HIT-UAV, surpassing existing methods in aerial object detection.
2. Related Work
2.1. Object Detection in Aerial Images
2.2. Advanced Deep Learning Paradigms for Small-Object Detection
2.3. Next-Generation Transformers for Small-Object Detection
2.4. Multi-Scale Feature Fusion for Drone Small-Object Detection
3. Methodology
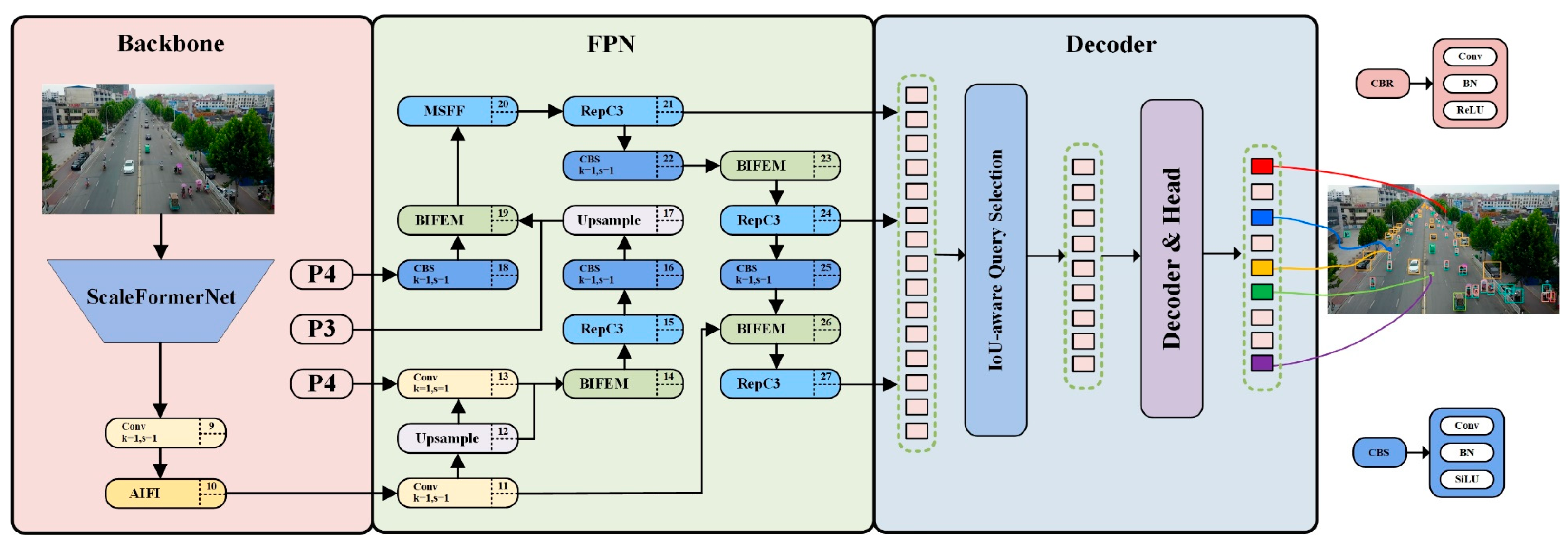
3.1. Overview of SF-DETR
3.2. ScaleFormerNet
3.3. Bilateral Interactive Feature Enhancement Module
3.4. Multi-Scale Frequency-Fused Feature Enhancement Network
4. Experiments
4.1. Datasets
4.2. Experiment Settings
4.3. Ablation Studies
4.4. Comparison with State-of-the-Art Methods
4.5. Extended Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mohamed, N.; Al-Jaroodi, J.; Jawhar, I.; Idries, A.; Mohammed, F. Unmanned aerial vehicles applications in future smart cities. Technol. Forecast. Soc. Chang. 2020, 153, 119293. [Google Scholar] [CrossRef]
- MarketsandMarkets. Unmanned Aerial Vehicles (UAV) Market by Type, Application, and Geography–Global Forecast to 2026. Available online: https://www.marketsandmarkets.com/Market-Reports/unmanned-aerial-vehicles-uav-market-662.html (accessed on 26 March 2025).
- Giordano, S.; Le Bris, A.; Mallet, C. Fully automatic analysis of archival aerial images current status and challenges. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, United Arab Emirates, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 12 December 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Jocher, G. YOLO11. 2024. Available online: https://github.com/ultralytics/ultralytics/tree/main (accessed on 26 March 2025).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision—ECCV 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Li, K.; Wang, G.; Cheng, G.; Meng, L.; Han, J. Enhanced attention networks for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7813–7824. [Google Scholar]
- Li, F.; Li, S.; Zhu, C.; Lan, X.; Chang, H. Cost-effective class-imbalance aware CNN for vehicle localization and categorization in high resolution aerial images. Remote Sens. 2017, 9, 494. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- International Civil Aviation Organization. Standards and Recommended Practices for Unmanned Aircraft Systems; Doc 10019 AN/507; ICAO: Montréal, QC, Canada, 2023. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 213–226. [Google Scholar]
- Suo, J.; Wang, T.; Zhang, X.; Chen, H.; Zhou, W.; Shi, W. HIT-UAV: A high-altitude infrared thermal dataset for Unmanned Aerial Vehicle-based object detection. Sci. Data 2023, 10, 227. [Google Scholar] [CrossRef] [PubMed]
- An, R.; Gong, P.; Wang, H.; Feng, X.; Xiao, P.; Chen, Q.; Zhang, Q.; Chen, C.; Yan, P. A modified PSO algorithm for remote sensing image template matching. Photogramm. Eng. Remote Sens. 2010, 76, 379–389. [Google Scholar] [CrossRef]
- Kumar, A.; Joshi, A.; Kumar, A.; Mittal, A.; Gangodkar, D.R. Template matching application in geo-referencing of remote sensing temporal image. Int. J. Signal Process. Image Process. Pattern Recognit. 2014, 7, 201–210. [Google Scholar] [CrossRef]
- Konstantinidis, D.; Stathaki, T.; Argyriou, V.; Grammalidis, N. Building detection using enhanced HOG–LBP features and region refinement processes. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 888–905. [Google Scholar] [CrossRef]
- Dawood, M.; Cappelle, C.; El Najjar, M.E.; Khalil, M.; Pomorski, D. Harris, SIFT and SURF features comparison for vehicle localization based on virtual 3D model and camera. In Proceedings of the 3rd International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 15–18 October 2012; pp. 307–312. [Google Scholar]
- Hadrović, E.; Osmanković, D.; Velagić, J. Aerial image mosaicing approach based on feature matching. In Proceedings of the 2017 International Symposium ELMAR, Zadar, Croatia, 18–20 September 2017; pp. 177–180. [Google Scholar]
- Romero, J.D.; Lado, M.J.; Mendez, A.J. A background modeling and foreground detection algorithm using scaling coefficients defined with a color model called lightness-red-green-blue. IEEE Trans. Image Process. 2017, 27, 1243–1258. [Google Scholar] [CrossRef]
- Shen, H.; Li, S.; Zhu, C.; Chang, H.; Zhang, J. Moving object detection in aerial video based on spatiotemporal saliency. Chin. J. Aeronaut. 2013, 26, 1211–1217. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef]
- Cazzato, D.; Cimarelli, C.; Sanchez-Lopez, J.L.; Voos, H.; Leo, M. A survey of computer vision methods for 2d object detection from unmanned aerial vehicles. J. Imaging 2020, 6, 78. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Li, S.; Zhang, R.; Wang, J.; Chen, Y. Adaptive Scale Selection Network for UAV Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar]
- Li, H.; Wang, Y.; Chen, X.; Liu, Y. Multi-Granularity Feature Enhancement for Small Object Detection in Aerial Images. Remote Sens. 2023, 15, 1023–1038. [Google Scholar]
- Wang, Z.; Liu, Y.; Zhang, Q.; Li, X. Dynamic Attention Network for Small Object Detection in Complex Scenes. IEEE/CAA J. Autom. Sin. 2023, 10, 456–469. [Google Scholar]
- Zhang, R.; Chen, J.; Wu, X.; Liu, M. Context-Guided Feature Aggregation for UAV Object Detection. IEEE Trans. Image Process. 2023, 32, 678–691. [Google Scholar]
- Chen, L.; Wang, H.; Zhang, Y.; Liu, S. Scale-Balanced Network: Bridging Scale Gaps in Aerial Detection. ISPRS J. Photogramm. Remote Sens. 2024, 197, 83–97. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional DETR for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3651–3660. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. DAB-DETR: Dynamic anchor boxes are better queries for DETR. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- Liu, Y.; Wang, J.; Chen, Y.; Li, S. RT-DETR: DETRs Beat YOLOs on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Cui, W.; Li, C.; Wang, X.; Zhang, Y. Efficient DETR with Cross-Level Dense Query. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9576–9591. [Google Scholar]
- Wang, H.; Zhang, L.; Yang, Y.; Liu, Y. Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment. IEEE Trans. Image Process. 2024, 33, 123–137. [Google Scholar]
- Yang, Z.; Liu, S.; Chen, H.; Wang, J. Small Object Detection via Coarse-to-Fine Knowledge Distillation. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 2789–2803. [Google Scholar]
- Zhang, P.; Li, X.; Wang, Y.; Chen, L. Task-aligned DETR: Better Architectures for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1456–1465. [Google Scholar]
- Chen, Z.; Ji, H.; Zhang, Y.; Liu, W.; Zhu, Z. Hybrid receptive field network for small object detection on drone view. Chin. J. Aeronaut. 2025, 38, 103127. [Google Scholar]
- Fu, Q.; Zheng, Q.; Yu, F. LMANet: A Lighter and More Accurate Multi-object Detection Network for UAV Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar]
- Li, Y.; Li, Q.; Pan, J.; Zhou, Y.; Zhu, H.; Wei, H.; Liu, C. SOD-YOLO: Small-object-detection algorithm based on improved YOLOv8 for UAV images. Remote Sens. 2024, 16, 3057. [Google Scholar] [CrossRef]
- Du, S.; Pan, W.; Li, N.; Dai, S.; Xu, B.; Liu, H.; Xu, C.; Li, X. TSD-YOLO: Small traffic sign detection based on improved YOLO v8. IET Image Process. 2024, 18, 2884–2898. [Google Scholar] [CrossRef]
- Han, Z.; Jia, D.; Zhang, L.; Li, J.; Cheng, P. FNI-DETR: Real-time DETR with far and near feature interaction for small object detection. Eng. Res. Express 2025, 7, 015204. [Google Scholar]
- Yang, M.; Xu, R.; Yang, C.; Wu, H.; Wang, A. Hybrid-DETR: A Differentiated Module-Based Model for Object Detection in Remote Sensing Images. Electronics 2024, 13, 5014. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, H.; Yang, J.; Ma, X.; Chen, J. AMFEF-DETR: An end-to-end adaptive multi-scale feature extraction and fusion object detection network based on UAV aerial images. Drones 2024, 8, 523. [Google Scholar] [CrossRef]
- Wang, S.; Jiang, H.; Li, Z.; Yang, J.; Ma, X.; Chen, J.; Tang, X. PHSI-RTDETR: A Lightweight Infrared Small Target Detection Algorithm Based on UAV Aerial Photography. Drones 2024, 8, 240. [Google Scholar] [CrossRef]
- Xu, K.; Song, C.; Xie, Y.; Pan, L.; Gan, X.; Huang, G. RMT-YOLOv9s: An Infrared Small Target Detection Method Based on UAV Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 7002205. [Google Scholar]
- Yan, B.; Wei, Y.; Liu, S.; Huang, W.; Feng, R.; Chen, X. A review of current studies on the unmanned aerial vehicle-based moving target tracking methods. Def. Technol. 2025, in press. [Google Scholar]
- Alhafnawi, M.; Salameh, H.A.B.; Masadeh, A.E.; Al-Obiedollah, H.; Ayyash, M.; El-Khazali, R.; Elgala, H. A survey of indoor and outdoor UAV-based target tracking systems: Current status, challenges, technologies, and future directions. IEEE Access 2023, 11, 68324–68339. [Google Scholar]
- Sun, N.; Zhao, J.; Shi, Q.; Liu, C.; Liu, P. Moving target tracking by unmanned aerial vehicle: A survey and taxonomy. IEEE Trans. Ind. Inform. 2024, 20, 7056–7068. [Google Scholar] [CrossRef]
- Li, B.; Liu, W.; Xie, W.; Zhang, N.; Zhang, Y. Adaptive digital twin for UAV-assisted integrated sensing, communication, and computation networks. IEEE Trans. Green Commun. Netw. 2023, 7, 1996–2009. [Google Scholar]
- Peng, S.; Li, B.; Liu, L.; Fei, Z.; Niyato, D. Trajectory Design and Resource Allocation for Multi-UAV-Assisted Sensing, Communication, and Edge Computing Integration. IEEE Trans. Commun. 2024. [Google Scholar] [CrossRef]
- Shi, D. Transnext: Robust foveal visual perception for vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashvile, TN, USA, 16–22 June 2024; pp. 17773–17783. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- Glenn, J. YOLOv5. 2020. Available online: https://github.com/ultralytics/ultralytics/tree/main (accessed on 26 March 2025).
- Glenn, J. YOLOv8. 2023. Available online: https://github.com/ultralytics/ultralytics/tree/main (accessed on 26 March 2025).
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high-quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Configuration | Types | Value |
|---|---|---|---|
| GPU | RTX 3090 | Learning rate | 1 × 10−4 |
| CPU | 13600K | Batch size | 8 |
| CUDA | 11.8 | Optimizer | SGD |
| Model | Precision | Recall | FPS | Param (M) | Flops (G) | ||
|---|---|---|---|---|---|---|---|
| RTDETR-r18 | 60.8 | 45.1 | 47.0 | 28.7 | 60.2 | 19.8 | 57.0 |
| +SFN | 62.4 | 46.9 | 48.9 | 30.1 | 55.4 | 13.5 | 50.1 |
| +BIFEM | 62.1 | 46.5 | 47.9 | 29.1 | 53.2 | 19.9 | 57.0 |
| +MSFF | 63.0 | 47.2 | 48.7 | 29.8 | 54.6 | 20.2 | 58.6 |
| +SFN+BIFEM | 62.8 | 47.6 | 49.4 | 30.4 | 46.1 | 13.6 | 50.0 |
| +BIFEM+MSFF | 63.1 | 48.1 | 50.1 | 30.7 | 48.5 | 20.3 | 58.9 |
| + SFN+MSFF | 62.7 | 47.4 | 48.9 | 29.8 | 45.5 | 14.7 | 53.6 |
| +SFN+BIFEM+ MSFF | 63.3 | 49.9 | 51.0 | 31.8 | 42.5 | 14.7 | 55.7 |
| Model | (%) | (%) | Precision (%) | Recall (%) | FPS | Param (M) | Flops (G) |
|---|---|---|---|---|---|---|---|
| Faster-RCNN | 41.3 | 25.1 | 51.7 | 40.5 | 13.1 | 42.0 | 180 |
| CenterNet [52] | 32.2 | 18.4 | 42.8 | 32.9 | 38.9 | 11.1 | 14.4 |
| RTMDet [53] | 43.1 | 26.3 | 55.7 | 41.2 | 37.7 | 52.3 | 80.0 |
| TOOD [54] | 41.9 | 25.5 | 55.2 | 40.1 | 34.9 | 32.0 | 199 |
| DETR | 26.2 | 14.7 | 35.2 | 28.4 | 25.1 | 42.2 | 86.2 |
| YOLOv5m [55] | 42.3 | 25.4 | 54.0 | 40.9 | 75.3 | 25.0 | 64.4 |
| YOLOv8m [56] | 43.0 | 26.0 | 53.7 | 42.4 | 87.8 | 25.8 | 79.1 |
| YOLOv9m [57] | 44.8 | 27.1 | 54.9 | 43.8 | 54.2 | 20.0 | 78.0 |
| YOLOv10m [58] | 44.2 | 26.9 | 55.5 | 41.9 | 67.9 | 16.4 | 64.0 |
| YOLO11m | 44.6 | 27.3 | 55.5 | 43.3 | 69.1 | 20.0 | 67.7 |
| RTDETR-r18 | 47.0 | 28.7 | 60.8 | 45.1 | 60.2 | 19.8 | 57.0 |
| PHSI-RTDETR | 47.1 | 28.7 | 60.8 | 45.6 | 39.9 | 14.0 | 47.5 |
| FECI-RTDETR | 47.2 | 28.8 | 60.1 | 45.6 | 40.5 | 14.9 | 46.1 |
| SF-DETR | 51.0 | 31.8 | 63.3 | 49.9 | 42.5 | 14.7 | 55.7 |
| Model | (%) | (%) | Precision (%) | Recall (%) | FPS | Param (M) | Flops (G) |
|---|---|---|---|---|---|---|---|
| Faster-RCNN | 70.2 | 40.1 | 79.7 | 67.7 | 23.0 | 42.1 | 180 |
| Cascade-RCNN [59] | 77.8 | 49.9 | 77.9 | 75.6 | 11.3 | 72.0 | 270 |
| Tood | 79.3 | 51.1 | 79.3 | 74.2 | 22.7 | 43.0 | 195 |
| DETR | 76.2 | 48.4 | 78.5 | 70.1 | 26.6 | 42.2 | 86.2 |
| YOLOv5m | 75.4 | 48.1 | 81.6 | 71.3 | 76.7 | 25.0 | 64.4 |
| YOLOv8m | 79.9 | 51.0 | 82.1 | 76.5 | 92.3 | 25.8 | 79.1 |
| YOLOv9m | 84.1 | 56.2 | 83.1 | 80.5 | 58.9 | 20.1 | 78.0 |
| YOLOv10m | 77.7 | 47.4 | 85.8 | 70.6 | 66.1 | 16.4 | 64.0 |
| YOLO11m | 78.9 | 50.7 | 77.4 | 75.4 | 67.4 | 20.0 | 67.7 |
| RTDETR-r18 | 80.0 | 50.8 | 86.5 | 76.9 | 61.1 | 19.9 | 57.3 |
| PHSI-RTDETR | 82.6 | 51.6 | 89.9 | 76.1 | 36.2 | 13.9 | 47.5 |
| FECI-RTDETR | 84.2 | 53.7 | 86.5 | 80.3 | 41.1 | 14.9 | 46.1 |
| SF-DETR | 86.5 | 57.5 | 86.9 | 79.1 | 45.2 | 14.7 | 55.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Gao, J. SF-DETR: A Scale-Frequency Detection Transformer for Drone-View Object Detection. Sensors 2025, 25, 2190. https://doi.org/10.3390/s25072190
Wang H, Gao J. SF-DETR: A Scale-Frequency Detection Transformer for Drone-View Object Detection. Sensors. 2025; 25(7):2190. https://doi.org/10.3390/s25072190
Chicago/Turabian StyleWang, Haotong, and Junwei Gao. 2025. "SF-DETR: A Scale-Frequency Detection Transformer for Drone-View Object Detection" Sensors 25, no. 7: 2190. https://doi.org/10.3390/s25072190
APA StyleWang, H., & Gao, J. (2025). SF-DETR: A Scale-Frequency Detection Transformer for Drone-View Object Detection. Sensors, 25(7), 2190. https://doi.org/10.3390/s25072190