
A Hybrid Deep Learning and Improved SVM Framework for Real-Time Railroad Construction Personnel Detection with Multi-Scale Feature Optimization

 ,
,
Abstract
1. Introduction
2. Literature Review
3. Image Processing and Algorithm Design
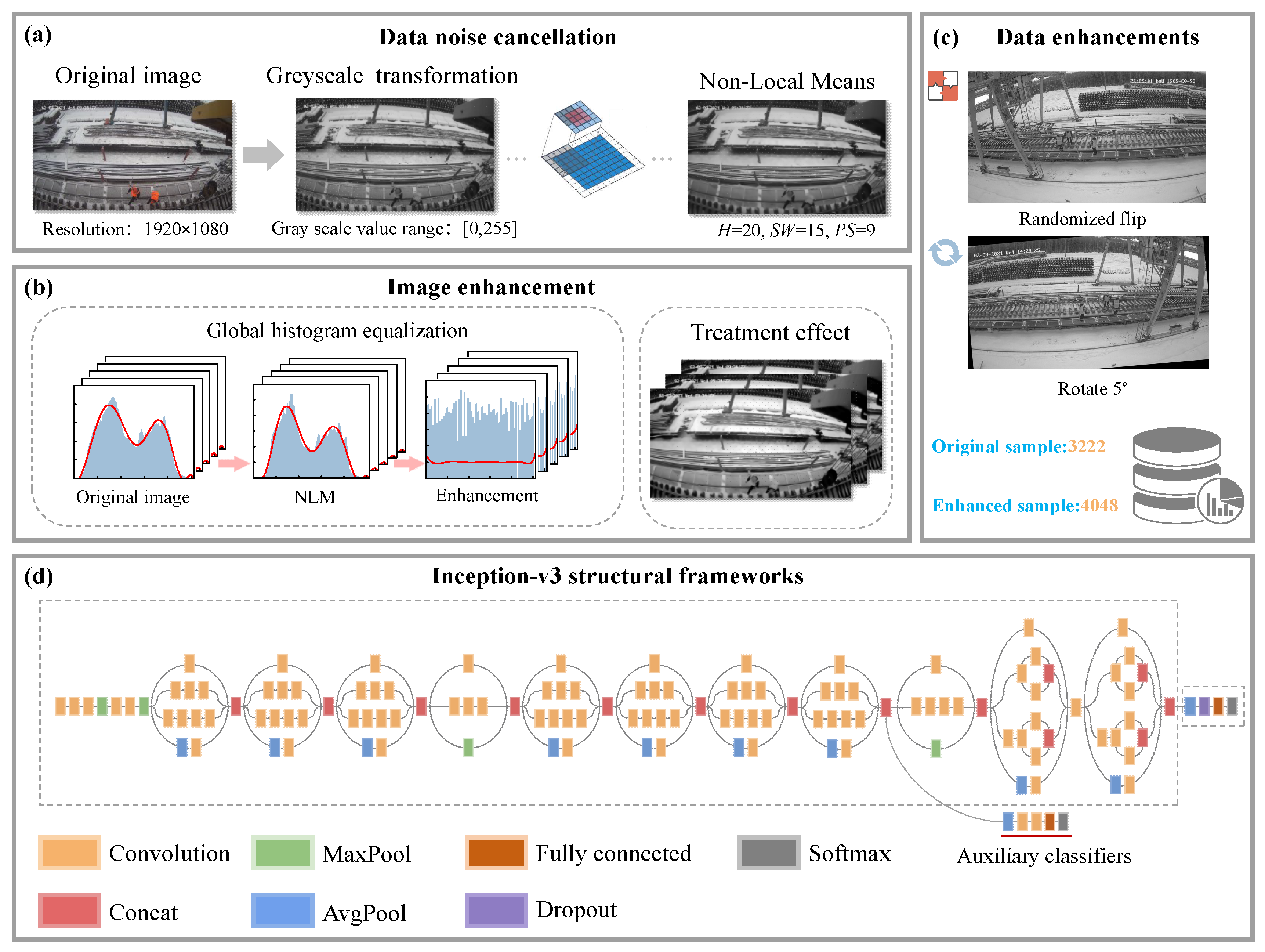
3.1. Image Collection and Processing
3.1.1. Image Noise Reduction
3.1.2. Image Enhancement
3.1.3. Data Enhancement
3.2. Algorithm Design
3.2.1. Algorithm Design Ideas
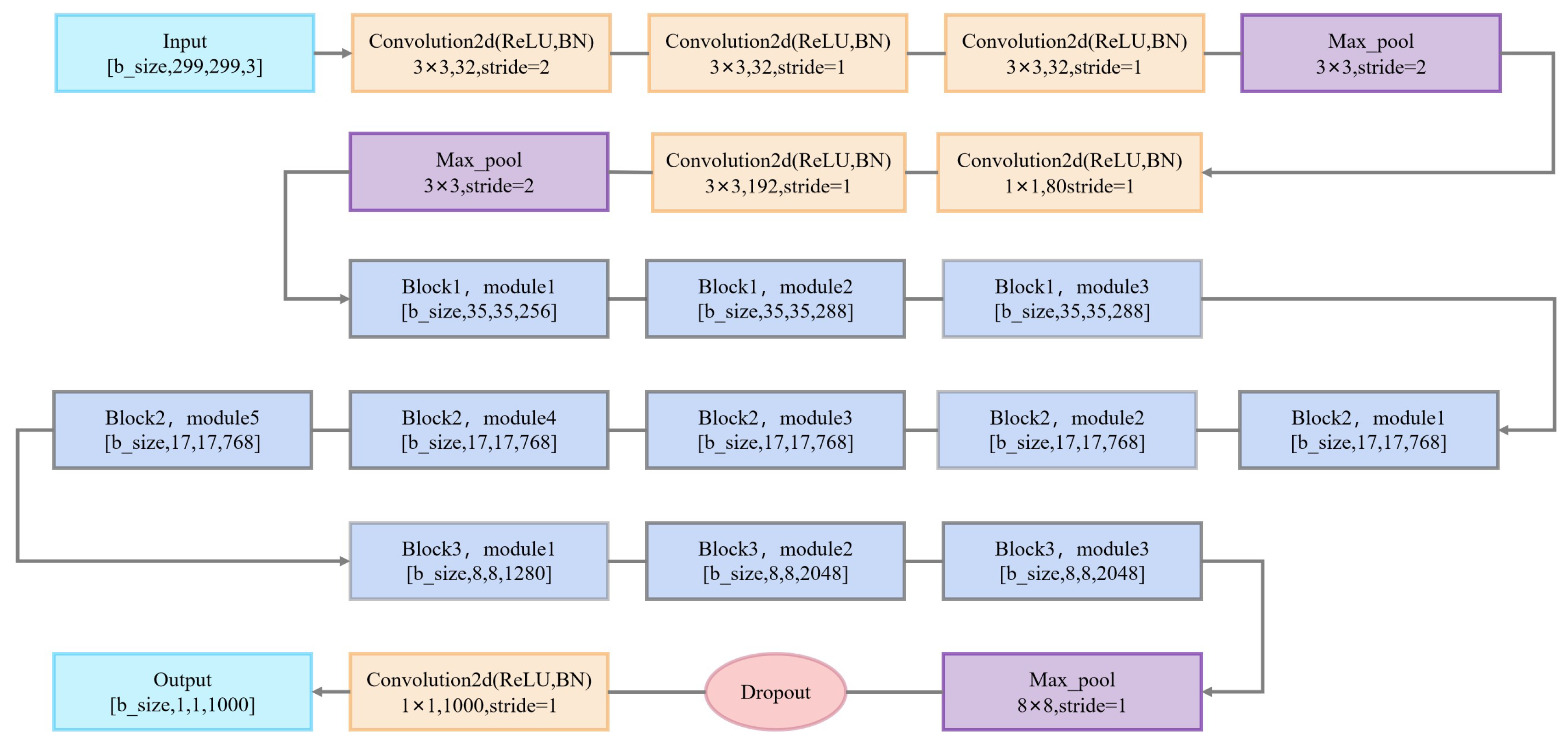
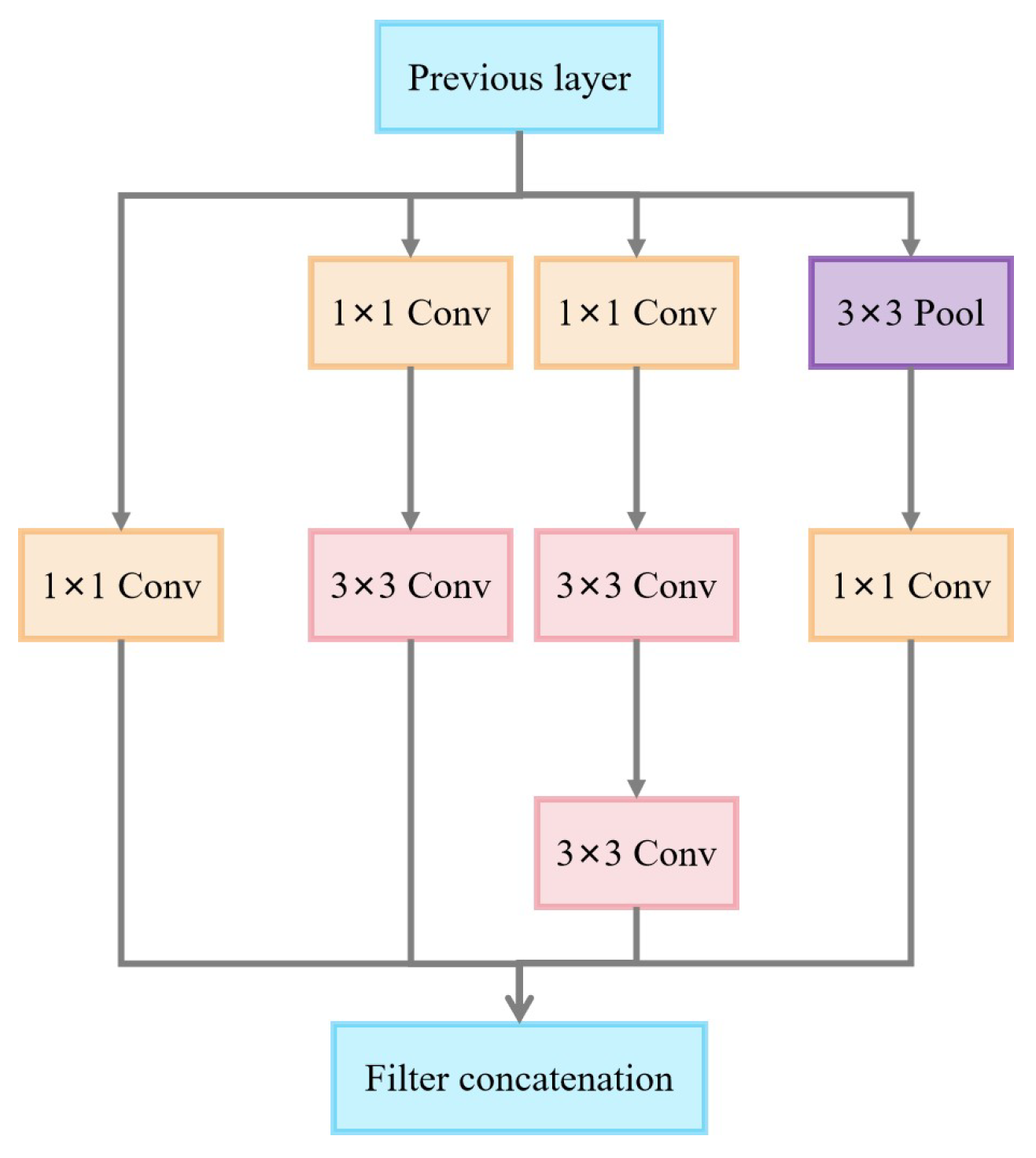
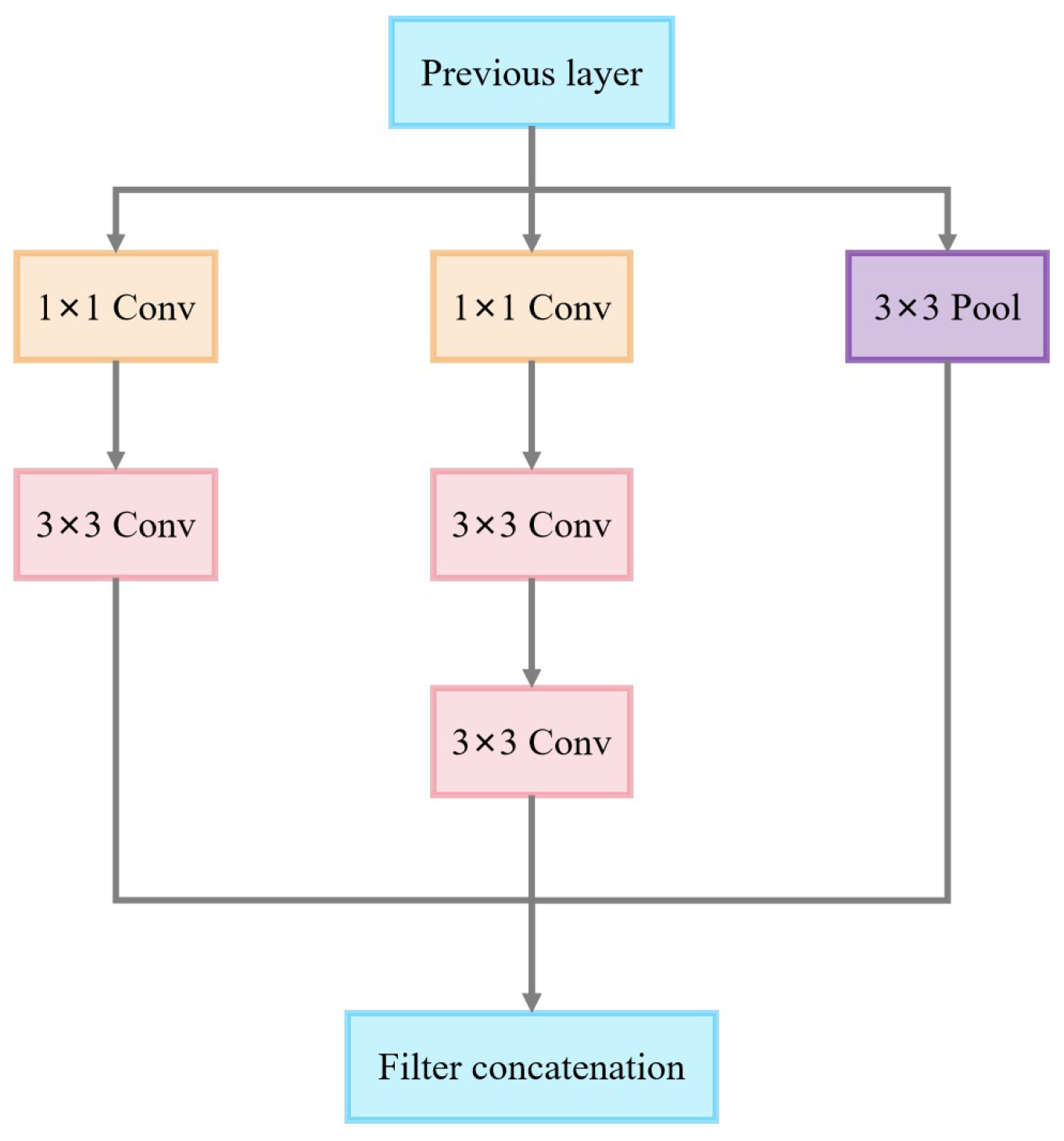
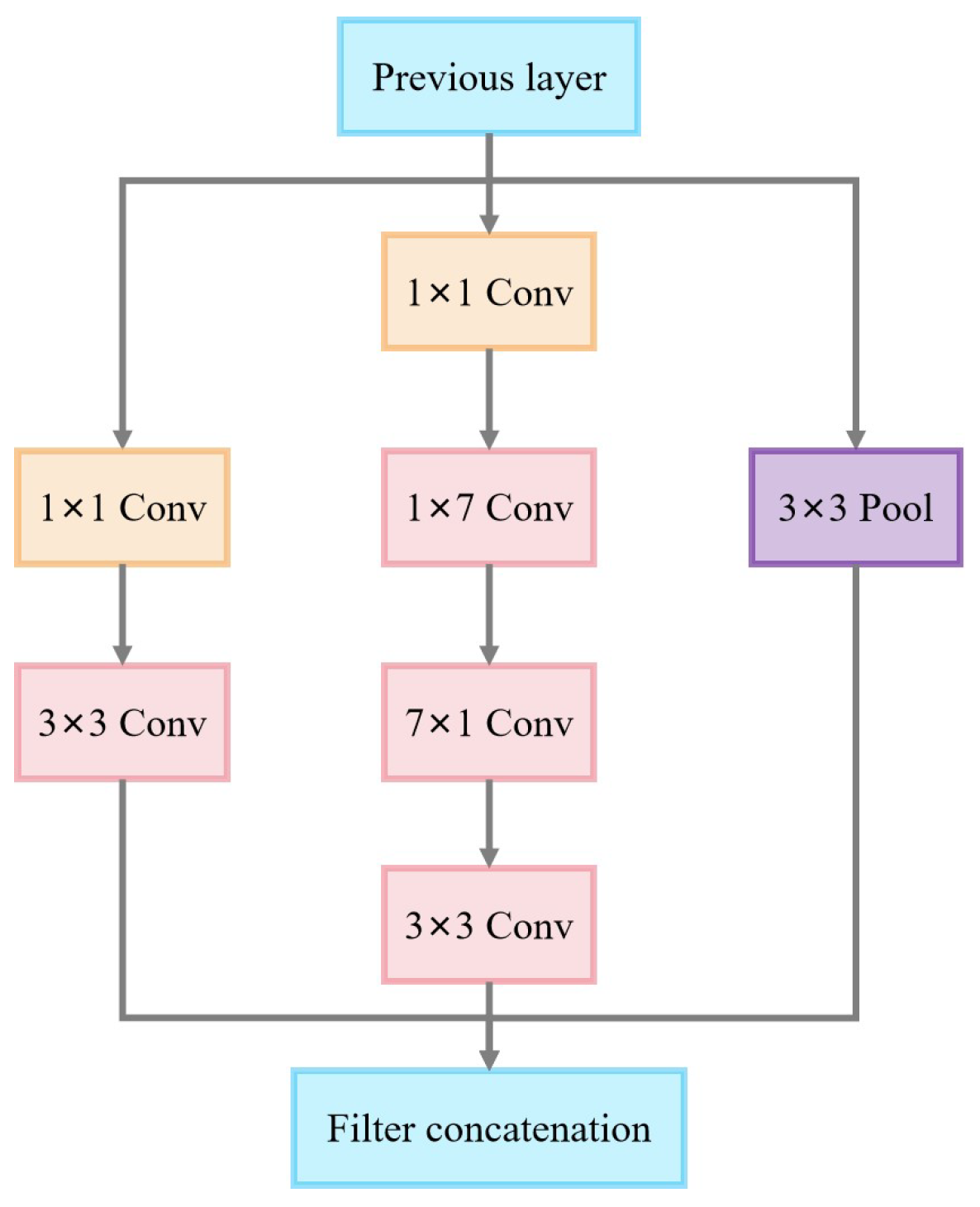
3.2.2. Inception v3 Model
3.2.3. Efficient Linear Support Vector Machines
- When the sample points do not satisfy the constraints, i.e., they are outside the feasible solution region, . At this point, is set to infinity; then, is also infinite.
- When the sample points satisfy the constraints, i.e., they are inside the feasible solution region, . At this point, is the function itself.
4. Experimentation and Analysis
4.1. Experimental Procedure
4.1.1. Parameter Calibration
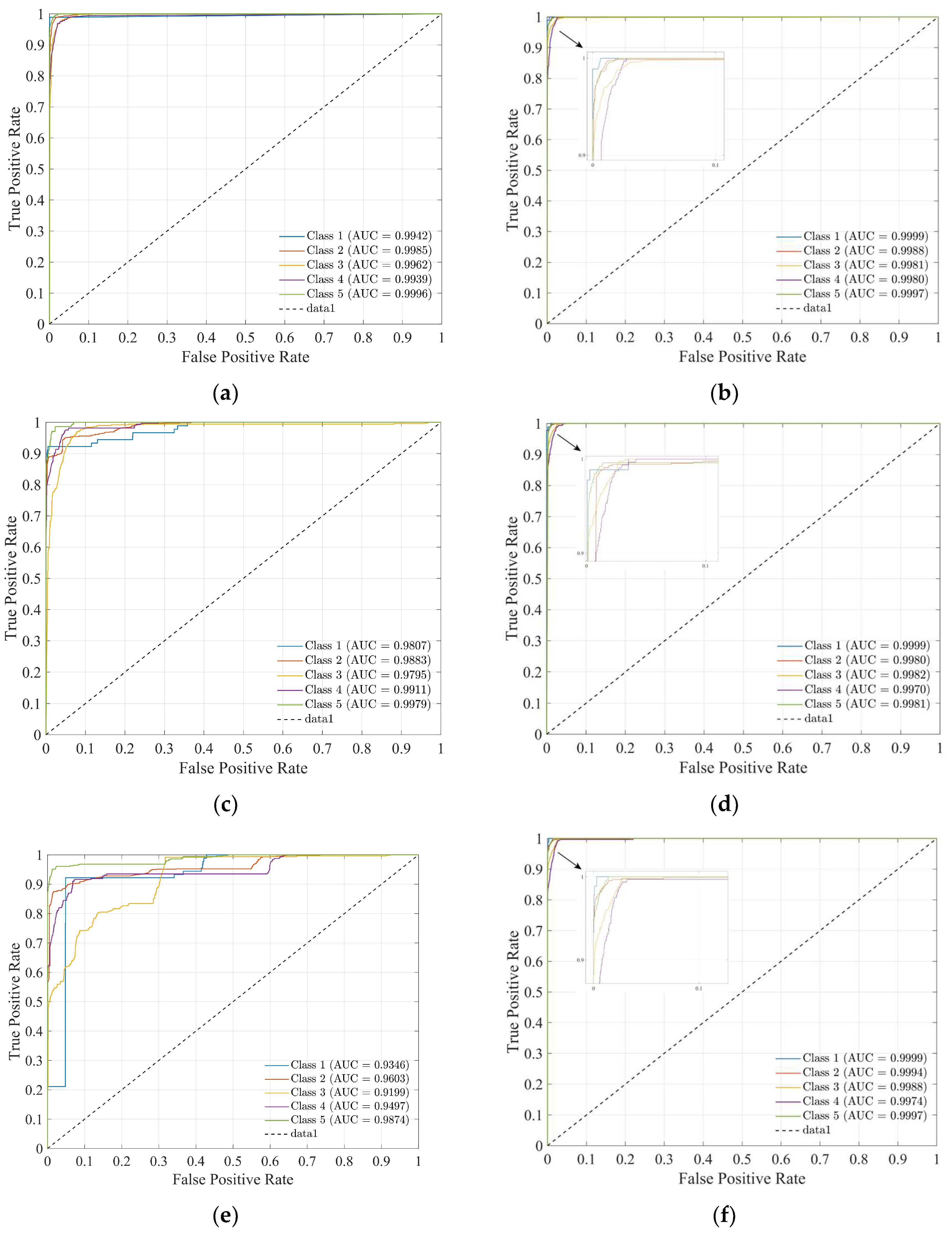
4.1.2. Results
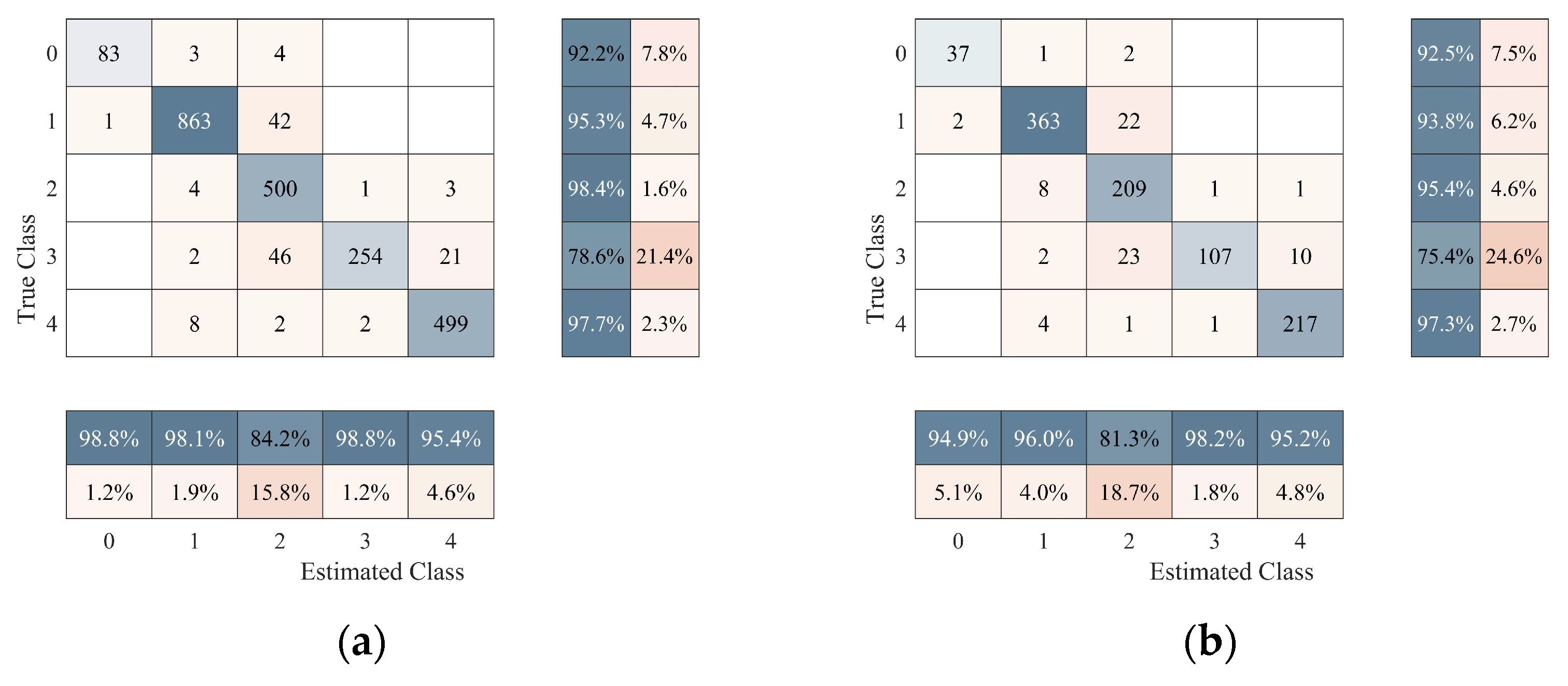
4.1.3. Analysis of Differences in Classification
4.2. Experiments and Discussions
Performance Evaluation
5. Discussion
6. Conclusions
- (1)
- By combining deep learning and traditional machine learning methods, the ISVM algorithm improves the accuracy of the Inception v3 model by 6.3%, and the accuracy, precision, recall, and F1 score indicators are improved by 11.43%, 13.70%, 15.27%, and 17.12%, respectively, compared to the average of the comparison models. The prediction accuracy is improved in short-term prediction.
- (2)
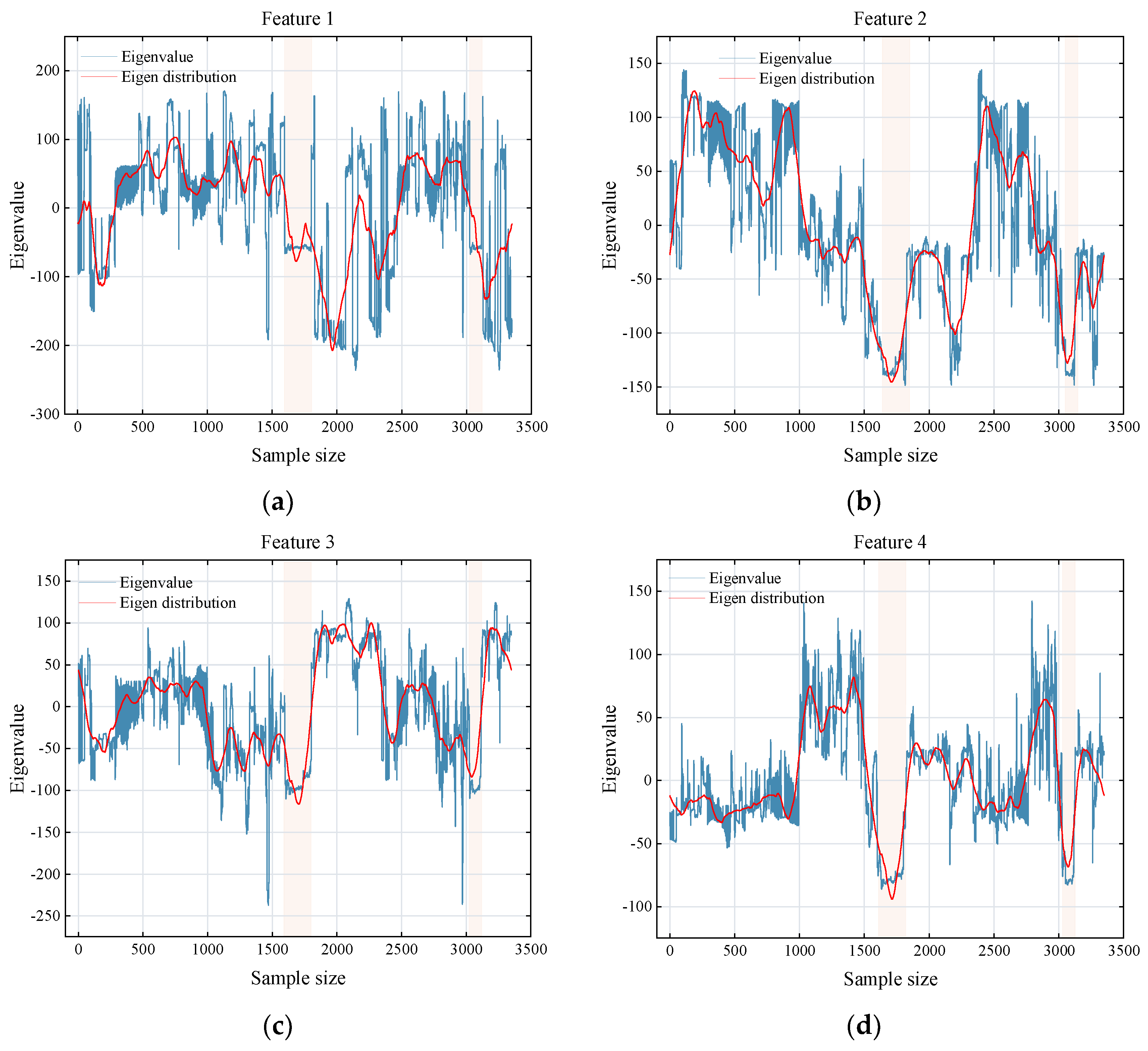
- This experiment uses principal component analysis to reduce the dimensionality of the features of the AvgPool layer of the Inception v3 network. The experimental results show that the features are basically independent of each other, and there is no obvious problem of multiple collinearity. However, the recognition accuracy of some categories is relatively low, which is caused by the uneven distribution of the sample size of various categories in the scene and the low degree of feature differentiation.
- (3)
- This experiment tests the performance of 25 classifiers on the validation set. The results show that introducing PCA dimensionality reduction improves the prediction speed of most classifiers, but it also increases training time. Among them, the efficient linear SVM shows a 1.9% improvement in accuracy and a 2405.49 obs/s improvement in prediction speed. Notably, the efficient linear SVM, with or without dimensionality reduction, demonstrates strong adaptability, particularly when handling high-dimensional features, and exhibits better robustness and generalization ability. Additionally, the bagging tree classifier performs particularly well in terms of prediction speed and is suitable for large-scale real-time detection tasks. These results suggest that selecting an appropriate classifier is crucial for enhancing the overall performance of the detection system.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, C.F.; Cai, C.X. Challenges and Countermeasures for Construction Safety during the Sichuan-Tibet Railway Project. Engineering 2019, 5, 833–838. [Google Scholar] [CrossRef]
- Zhu, C.D.; Zhu, J.Q.; Bu, T.X.; Gao, X.F. Monitoring and Identification of Road Construction Safety Factors via UAV. Sensors 2022, 22, 8797. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.J.; Liu, X.H.; Li, H.X.; Lu, F.; Gu, X.H.; Qin, K. Research on Unsupervised Low-Light Railway Fastener Image Enhancement Method Based on Contrastive Learning GAN. Sensors 2024, 24, 3794. [Google Scholar] [CrossRef] [PubMed]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1437–1451. [Google Scholar] [CrossRef]
- Kapoor, R.; Goel, R.; Sharma, A. An intelligent railway surveillance framework based on recognition of object and railway track using deep learning. Multimed. Tools Appl. 2022, 81, 21083–21109. [Google Scholar] [CrossRef]
- Arimura, K.; Hagita, N. Feature space design for statistical image recognition with image screening. IEICE Trans. Inf. Syst. 1998, 81, 88–93. [Google Scholar]
- Vaser, R.; Adusumalli, S.; Leng, S.N.; Šikić, M.; Ng, P.C. SIFT missense predictions for genomes. Nat. Protoc. 2015, 11, 1–9. [Google Scholar] [CrossRef]
- Li, H.; Yang, X.; Zhai, H.; Liu, Y.; Bao, H.; Zhang, G. Vox-Surf: Voxel-Based Implicit Surface Representation. IEEE Trans. Vis. Comput. Graph. 2024, 30, 1743–1755. [Google Scholar] [CrossRef]
- Ayalew, A.M.; Salau, A.O.; Abeje, B.T.; Enyew, B. Detection and classification of COVID-19 disease from X-ray images using convolutional neural networks and histogram of oriented gradients. Biomed. Signal Process. Control 2022, 74, 103530. [Google Scholar] [CrossRef]
- Ikenoyama, Y.; Hirasawa, T.; Ishioka, M.; Namikawa, K.; Yoshimizu, S.; Horiuchi, Y.; Ishiyama, A.; Yoshio, T.; Tsuchida, T.; Takeuchi, Y.; et al. Detecting early gastric cancer: Comparison between the diagnostic ability of convolutional neural networks and endoscopists. Dig. Endosc. 2020, 33, 141–150. [Google Scholar] [CrossRef]
- Saini, A.; Singh, D.; Álvarez, M.A. FishTwoMask R-CNN: Two-stage Mask R-CNN approach for detection of fishplates in high-altitude railroad track drone images. Multimed. Tools Appl. 2023, 83, 10367–10392. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Zhang, H.; Tian, L.; Wang, Z.; Xu, Y.; Cheng, P.; Bai, K.; Chen, B. Multiscale Visual-Attribute Co-Attention for Zero-Shot Image Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 6003–6014. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, Z.; Lu, X. Physical flexibility detection under complex backgrounds using ED-Former. Vis. Comput. 2024, 40, 523–534. [Google Scholar] [CrossRef]
- Huang, L.; Lu, K.; Song, G.; Wang, L.; Liu, S.; Liu, Y.; Li, H. Teach-DETR: Better Training DETR With Teachers. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15759–15771. [Google Scholar] [CrossRef]
- Amel, O.; Siebert, X.; Mahmoudi, S.A. Comparison Analysis of Multimodal Fusion for Dangerous Action Recognition in Railway Construction Sites. Electronics 2024, 13, 2294. [Google Scholar] [CrossRef]
- Ying, W.; Zhang, L.; Luo, S.; Yao, C.; Ying, F. Simulation of computer image recognition technology based on image feature extraction. Soft Comput. 2023, 27, 10167–10176. [Google Scholar] [CrossRef]
- Yang, O. Improved locating algorithm of railway tunnel personnel based on collaborative information fusion in Internet of Things. Trans. Inst. Meas. Control 2017, 39, 446–454. [Google Scholar] [CrossRef]
- Cao, Z.; Qin, Y.; Xie, Z.; Liu, Q.; Zhang, E.; Wu, Z.; Yu, Z. An effective railway intrusion detection method using dynamic intrusion region and lightweight neural network. Measurement 2022, 191, 110564. [Google Scholar] [CrossRef]
- Alves dos Santos, J.L.; Carvalho de Araújo, R.C.; Lima Filho, A.C.; Belo, F.A.; Gomes de Lima, J.A. Telemetric system for monitoring and automation of railroad networks. Transp. Plan. Technol. 2011, 34, 593–603. [Google Scholar] [CrossRef]
- Zhang, X.; Fu, Q.; Li, Y.; Han, Z.; Jiang, N.; Li, C. A Dynamic Detection Method for Railway Slope Falling Rocks Based on the Gaussian Mixture Model Segmentation Algorithm. Appl. Sci. 2024, 14, 4454. [Google Scholar] [CrossRef]
- Duan, Y.; Qiu, S.; Jin, W.; Lu, T.; Li, X. High-Speed rail tunnel panoramic inspection image recognition technology based on improved YOLOv5. Sensors 2023, 23, 5986. [Google Scholar] [CrossRef]
- Xu, F.; Xu, Z.; Lu, Z.; Peng, C.; Yan, S. Detection and Recognition of Tilted Characters on Railroad Wagon Wheelsets Based on Deep Learning. Sensors 2023, 23, 7716. [Google Scholar] [CrossRef]
- Wang, Y.Y. Condition Monitoring of Substation Equipment Based on Machine Vision. Front. Energy Res. 2022, 10, 908999. [Google Scholar] [CrossRef]
- Gibert, X.; Patel, V.M.; Chellappa, R. Deep multitask learning for railway track inspection. IEEE Trans. Intell. Transp. Syst. 2016, 18, 153–164. [Google Scholar] [CrossRef]
- Aydin, I.; Sevi, M.; Salur, M.U.; Akin, E. Defect classification of railway fasteners using image preprocessing and alightweight convolutional neural network. Turk. J. Electr. Eng. Comput. Sci. 2022, 30, 891–907. [Google Scholar] [CrossRef]
- Tan, P.; Li, X.; Wu, Z.; Ding, J.; Ma, J.; Chen, Y.; Fang, Y.; Ning, Y. Multialgorithm fusion image processing for high-speed railway dropper failure–defect detection. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 4466–4478. [Google Scholar] [CrossRef]
- Zhang, S.; Chang, Y.; Wang, S.; Li, Y.; Gu, T. An improved lightweight YOLOv5 algorithm for detecting railway catenary hanging string. IEEE Access 2023, 11, 114061–114070. [Google Scholar] [CrossRef]
- Wei, X.; Jiang, S.; Li, Y.; Li, C.; Jia, L.; Li, Y. Defect detection of pantograph slide based on deep learning and image processing technology. IEEE Trans. Intell. Transp. Syst. 2019, 21, 947–958. [Google Scholar] [CrossRef]
- Nogueira, K.; Machado, G.L.S.; Gama, P.H.T.; da Silva, C.C.V.; Balaniuk, R.; dos Santos, J.A. Facing erosion identification in railway lines using pixel-wise deep-based approaches. Remote Sens. 2020, 12, 739. [Google Scholar] [CrossRef]
- Espinosa, F.; García, J.J.; Hernández, Á.; Mazo, M.; Ureña, J.; Jiménez, J.; Fernández, I.; Perez, C.L.; García García, J.C. Advanced monitoring of rail breakage in double-track railway lines by means of PCA techniques. Appl. Soft Comput. 2018, 63, 1–13. [Google Scholar] [CrossRef]
- Guo, W.J.; Yu, Z.Y.; Chui, H.C.; Chen, X.M. Development of DMPS-EMAT for Long-Distance Monitoring of Broken Rail. Sensors 2023, 23, 5583. [Google Scholar] [CrossRef]
- Wang, W.S.; Sun, Q.Q.; Zhao, Z.Y.; Fang, Z.Y.; Tay, J.S.; See, K.Y.; Zheng, Y.J. Novel Coil Transducer Induced Thermoacoustic Detection of Rail Internal Defects Towards Intelligent Processing. IEEE Trans. Ind. Electron. 2024, 71, 2100–2111. [Google Scholar] [CrossRef]
- Cheng, Z.; Han, Z.; Han, Q.; Chen, C.; Liu, J. A novel linetype recognition algorithm based on track geometry detection data. Meas. Sci. Technol. 2024, 36, 015024. [Google Scholar] [CrossRef]
- Yue, Y.; Liu, H.; Lin, C.; Meng, X.; Liu, C.; Zhang, X.; Cui, J.; Du, Y. Automatic recognition of defects behind railway tunnel linings in GPR images using transfer learning. Measurement 2024, 224, 113903. [Google Scholar] [CrossRef]
- Min, Y.; Li, Y. Self-Supervised railway surface defect detection with defect removal variational autoencoders. Energies 2022, 15, 3592. [Google Scholar] [CrossRef]
- Zhuang, Y.; Liu, R.K.; Tang, Y.J. Heterogeneity-Oriented ensemble learning for rail monitoring based on vehicle-body vibration. Comput.—Aided Civ. Infrastruct. Eng. 2023, 39, 1766–1794. [Google Scholar] [CrossRef]
- Kim, H.; Lee, S.; Han, S. Railroad surface defect segmentation using a modified fully convolutional network. KSII Trans. Internet Inf. Syst. 2020, 14, 4763–4775. [Google Scholar]
- Rampriya, R.S.; Jenefa, A.; Prathiba, S.B.; Sabarinathan, L.; Julus, L.J.; Selvaraj, A.K.; Rodrigues, J.J.P.C. Fault Detection and Semantic Segmentation on Railway Track Using Deep Fusion Model. IEEE Access 2024, 12, 136183–136201. [Google Scholar] [CrossRef]
- Qiu, L.; Zhu, M.; Park, J.; Jiang, Y. Non-Interrupting Rail Track Geometry Measurement System Using UAV and LiDAR. arXiv 2024, arXiv:2410.10832v2. [Google Scholar]
- Mohammadi, A.A.; Wang, Z.; Teng, H. Mechanical and metallurgical assessment of a submerged arc welded surfaced rail. Int. J. Transp. Sci. Technol. 2024. [Google Scholar] [CrossRef]
- Jia, L.; Park, J.; Zhu, M.; Jiang, Y.; Teng, H. Evaluation of On-Vehicle Bone-Conduct Acoustic Emission Detection for Rail Defects. J. Transp. Technol. 2025, 15, 95–121. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Algorithm Used | Algorithm Model | Application Domain | Model Fusion | |
|---|---|---|---|---|---|
| Yes | No | ||||
| Ying [17] | Convolutional Neural Networks with Support Vector Machines | Deep learning | Construction safety | √ | |
| Liu [18] | Genetic Algorithm Optimization of BP Neural Networks | Deep learning | Construction safety | √ | |
| Yang [19] | Background Difference Method | Information fusion model | Construction safety | √ | |
| Nogueira K [30] | Dynamically Expanded Convolutional Networks | Deep learning | Rail monitoring | √ | |
| Cao [20] | Lightweight Neural Networks | Deep learning | Construction safety | √ | |
| Zhang [28] | YOLOv5 Neural Network | Target detection algorithms | Construction safety | √ | |
| Kapoor R [32] | Deep Classifier Network | Deep learning | Rail monitoring | √ | |
| Cheng [35] | NLRA | Pattern recognition | Rail monitoring | √ | |
| Xu [23] | Convolutional Recurrent Neural Network | Deep learning | Equipment Monitoring | √ | |
| Aydin [26] | LCNN | Machine learning | Equipment Monitoring | √ | |
| Yue [36] | YOLOP | Target detection algorithms | Rail monitoring | √ | |
| Gibert [25] | Artificial Neural Network | Deep learning | Equipment Monitoring | √ | |
| Tan [27] | Faster R-CNN | Target detection algorithms | Equipment Monitoring | √ | |
| Min [41] | DR-VAE | Unsupervised learning | Rail monitoring | √ | |
| Kim [38] | Fully Convolutional Network | Deep learning | Rail monitoring | √ | |
| Rampriya [44] | Deep Residual U-Net | Machine learning | Rail monitoring | √ | |
| Wei [29] | PDDNet | Deep learning | Equipment Monitoring | √ | |
| Zhuang [42] | A Data-Driven Approach | Deep learning | Rail monitoring | √ | |
| Guo [37] | Finite Element Analysis (FEA) | Finite element simulation model | Rail monitoring | √ | |
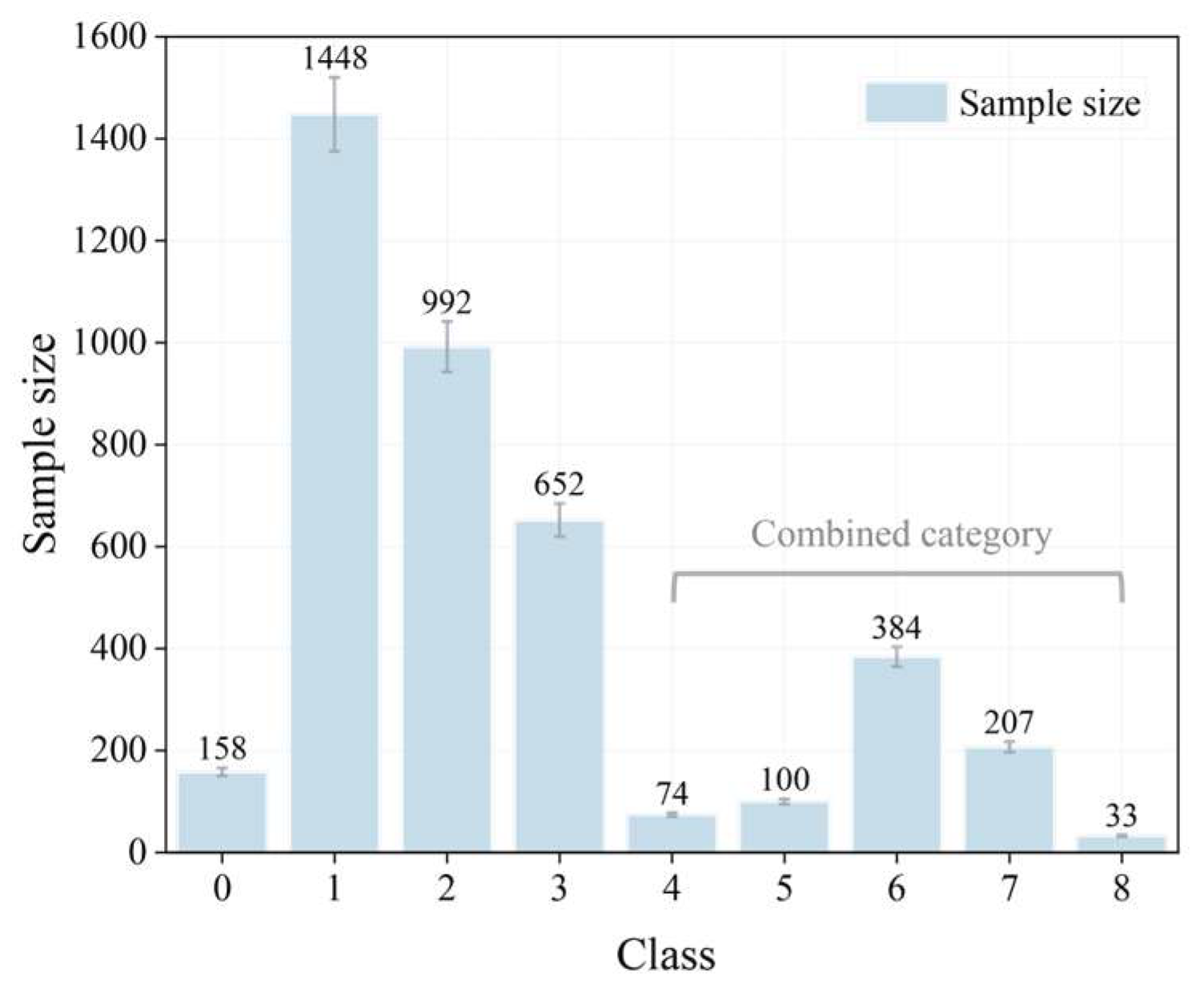
| Category | Training Set | Test Set | Validation Set | Total |
|---|---|---|---|---|
| 0 | 90 | 40 | 28 | 158 |
| 1 | 906 | 387 | 155 | 1448 |
| 2 | 508 | 219 | 265 | 992 |
| 3 | 323 | 142 | 187 | 652 |
| 4 | 511 | 223 | 64 | 798 |
| Total | 2338 | 1011 | 699 | 4048 |
| Algorithm | Parameter Meaning | Setting Value |
|---|---|---|
| NLM | Image resolution | 1920 × 1080 |
| Convert image type | Grey | |
| Search window size | 15 | |
| Image block size | 9 | |
| Smoothing parameters | 21 | |
| Histogram Equalization | Number of bins in the histogram | 256 |
| Contrast enhancement factor | 0 | |
| Brightness enhancement factor | 0 | |
| gamma correction factor | 1 | |
| Inception v3 | Input size | 299 × 299 × 3 |
| Learning rate | 0.001 | |
| Maximum number of iterations | 500 | |
| Validation frequency | 50 | |
| Batch size | 32 | |
| Dropout ratio | 0.2 | |
| Weight decay | 0.0001 | |
| Optimizer | SGD | |
| Activation function | ReLU | |
| Efficient Linear SVM | K-fold cross validation | 5 |
| Test set ratio | 0.3 | |
| Regularization parameters | 10 | |
| Penalty factor | 10 | |
| Tolerance | 0.001 | |
| Maximum number of iterations | 1000 | |
| Loss function | Modified Huber loss | |
| Kernel function | Linear kernel function |
| Algorithm | Training Set | Test Set | Training Time (s) |
|---|---|---|---|
| Inception v3 | 87.21% | 87.17% | 184 |
| Inception v2 | 85.73% | 84.82% | 169 |
| Inception v1 | 84.59% | 84.48% | 153 |
| ISVM | 93.56% | 93.47% | 196 |
| Model Type | Presuppose | Accuracy (Verification) | Total Cost (Validation) | Predicted Speed (obs/s) | Training Time (Seconds) |
|---|---|---|---|---|---|
| Efficient Logistic Regression | Efficient Logistic Regression | 0.923 ± 0.02 | 60 | 1882.77 | 14.94 |
| Efficient Linear SVM | Efficient Linear SVM | 0.923 ± 0.03 | 65 | 2275.27 | 11.36 |
| Plain Bayes | Kernel Plain Bayes | 0.851 ± 0.04 | 178 | 31.16 | 309.71 |
| Tree | Fine Tree | 0.905 ± 0.02 | 90 | 1669.01 | 25.88 |
| Medium Tree | 0.905 ± 0.02 | 90 | 1536 | 22.09 | |
| Coarse Tree | 0.915 ± 0.03 | 73 | 1669.66 | 20.59 | |
| SVM | Linear SVM | 0.910 ± 0.03 | 65 | 1449.27 | 38.45 |
| Quadratic SVM | 0.912 ± 0.01 | 62 | 1230.5 | 36.99 | |
| Cubic SVM | 0.919 ± 0.01 | 67 | 1199.04 | 36.21 | |
| Fine Gaussian SVM | 0.916 ± 0.03 | 71 | 802.68 | 34.93 | |
| Medium Gaussian SVM | 0.918 ± 0.03 | 69 | 1129.29 | 34.27 | |
| Rough Gaussian SVM | 0.876 ± 0.03 | 137 | 964.36 | 32.89 | |
| KNN | Fine KNN | 0.904 ± 0.03 | 92 | 657.78 | 31.79 |
| Medium KNN | 0.898 ± 0.02 | 102 | 657.33 | 30.55 | |
| Coarse KNN | 0.791 ± 0.05 | 277 | 754.07 | 29.85 | |
| Cosine KNN | 0.898 ± 0.03 | 102 | 582.59 | 28.62 | |
| Cubic KNN | 0.905 ± 0.03 | 90 | 183.64 | 85.69 | |
| Weighted KNN | 0.889 ± 0.03 | 99 | 1109.51 | 27.56 | |
| Integration | Lifting Trees | 0.907 ± 0.03 | 87 | 2034.68 | 86.82 |
| Bagging tree | 0.918 ± 0.03 | 78 | 2542.56 | 95.14 | |
| Subspace discriminant | 0.917 ± 0.02 | 71 | 393.49 | 63.4 | |
| Subspace KNN | 0.909 ± 0.03 | 83 | 167.54 | 70.2 | |
| RUSBoosted tree | 0.909 ± 0.03 | 82 | 1297.62 | 54.28 | |
| Kernel | SVM Kernel | 0.902 ± 0.01 | 62 | 607.04 | 207.76 |
| logistic regression kernel | 0.919 ± 0.03 | 66 | 297.83 | 129.09 |
| Model Type | Presuppose | Accuracy (Verification) | Total Cost (Validation) | Predicted Speed (obs/s) | Training Time (Seconds) |
|---|---|---|---|---|---|
| Efficient Logistic Regression | Efficient Logistic Regression | 0.942 ± 0.02 | 62 | 4819.49 | 622.89 |
| Efficient Linear SVM | Efficient Linear SVM | 0.944 ± 0.03 | 59 | 4680.76 | 603.23 |
| Plain Bayes | Kernel Plain Bayes | 0.922 ± 0.01 | 79 | 854.23 | 621.10 |
| Tree | Fine Tree | 0.929 ± 0.01 | 84 | 1947.13 | 18.20 |
| Medium Tree | 0.931 ± 0.02 | 81 | 1870.18 | 627.04 | |
| Coarse Tree | 0.862 ± 0.05 | 193 | 1857.38 | 625.21 | |
| SVM | Linear SVM | 0.935 ± 0.01 | 73 | 1731.71 | 620.14 |
| Quadratic SVM | 0.939 ± 0.02 | 68 | 1440.99 | 619.46 | |
| Cubic SVM | 0.911 ± 0.03 | 64 | 1478.08 | 618.66 | |
| Fine Gaussian SVM | 0.938 ± 0.01 | 69 | 1704.47 | 617.73 | |
| Medium Gaussian SVM | 0.918 ± 0.01 | 101 | 1501.79 | 616.86 | |
| Rough Gaussian SVM | 0.868 ± 0.05 | 1002 | 1560.30 | 615.82 | |
| KNN | Fine KNN | 0.931 ± 0.01 | 80 | 2077.37 | 619.01 |
| Medium KNN | 0.935 ± 0.01 | 73 | 1945.83 | 618.41 | |
| Coarse KNN | 0.893 ± 0.03 | 142 | 1644.69 | 617.92 | |
| Cosine KNN | 0.939 ± 0.02 | 67 | 1918.58 | 617.27 | |
| Cubic KNN | 0.935 ± 0.02 | 74 | 3323.83 | 616.66 | |
| Weighted KNN | 0.932 ± 0.03 | 78 | 3952.22 | 615.85 | |
| Integration | Lifting Trees | 0.915 ± 0.02 | 74 | 2085.90 | 615.13 |
| Bagging Tree | 0.940 ± 0.01 | 82 | 5038.28 | 613.99 | |
| Subspace Discriminant | 0.933 ± 0.02 | 68 | 1001.08 | 631.19 | |
| Subspace KNN | 0.934 ± 0.02 | 75 | 766.98 | 18.01 | |
| RUSBoosted Tree | 0.939 ± 0.03 | 68 | 1408.36 | 17.35 | |
| Kernel | SVM Kernel | 0.935 ± 0.03 | 73 | 2483.67 | 23.54 |
| Logistic Regression Kernel | 0.922 ± 0.03 | 63 | 2021.97 | 19.30 |
| Model | Accuracy Rate (%) | Precision Rate (%) | Recall Rate (%) | F1 Score (%) | Param (M) |
|---|---|---|---|---|---|
| AlexNet | 74.11 | 81.84 | 60.18 | 56.24 | 58.30 |
| ResNet-50 | 76.39 | 79.89 | 77.31 | 77.39 | 23.50 |
| DenseNet-201 | 83.83 | 81.80 | 73.32 | 73.39 | 18.10 |
| MobileOne-S2 | 73.25 | 71.64 | 63.62 | 62.64 | 4.80 |
| MobileOne-S4 | 86.54 | 85.32 | 83.55 | 83.51 | 18.30 |
| Vision Transformer | 89.28 | 88.57 | 89.42 | 88.14 | 86.00 |
| EdgeNeXt-XS | 79.35 | 78.97 | 73.37 | 71.25 | 5.30 |
| Inception v3 | 87.31 | 86.87 | 85.83 | 85.81 | 25.00 |
| Inception v4 | 86.46 | 85.34 | 87.21 | 87.18 | 42.68 |
| ISVM (Ours) | 93.27 | 95.95 | 92.36 | 93.30 | 26.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Xiong, H.; Zhou, S.; Wang, X.; Lou, B.; Ning, L.; Hu, Q.; Tang, Y.; Gu, G. A Hybrid Deep Learning and Improved SVM Framework for Real-Time Railroad Construction Personnel Detection with Multi-Scale Feature Optimization. Sensors 2025, 25, 2061. https://doi.org/10.3390/s25072061
Chen J, Xiong H, Zhou S, Wang X, Lou B, Ning L, Hu Q, Tang Y, Gu G. A Hybrid Deep Learning and Improved SVM Framework for Real-Time Railroad Construction Personnel Detection with Multi-Scale Feature Optimization. Sensors. 2025; 25(7):2061. https://doi.org/10.3390/s25072061
Chicago/Turabian StyleChen, Jianqiu, Huan Xiong, Shixuan Zhou, Xiang Wang, Benxiao Lou, Longtang Ning, Qingwei Hu, Yang Tang, and Guobin Gu. 2025. "A Hybrid Deep Learning and Improved SVM Framework for Real-Time Railroad Construction Personnel Detection with Multi-Scale Feature Optimization" Sensors 25, no. 7: 2061. https://doi.org/10.3390/s25072061
APA StyleChen, J., Xiong, H., Zhou, S., Wang, X., Lou, B., Ning, L., Hu, Q., Tang, Y., & Gu, G. (2025). A Hybrid Deep Learning and Improved SVM Framework for Real-Time Railroad Construction Personnel Detection with Multi-Scale Feature Optimization. Sensors, 25(7), 2061. https://doi.org/10.3390/s25072061