1. Introduction
Land cover classification (LCC) using remote sensing images aims to generate schematic maps from satellite and drone imagery [
1]. This process involves creating a numerical representation based on available data for specific land cover (LC) types, such as forests, grasslands, pastures, water bodies, buildings, polluted areas, and mining zones [
2,
3]. By applying a computational classification method, the LC type in each different region of an image can be accurately identified. With the expansion of imaging and remote sensing drones and satellites, along with the increased accuracy and range of wavelengths acquired by sensors, LCC using remote sensing imagery has seen significant growth [
4,
5]. LCC has widespread applications across various fields, such as ecology, geography, climatology, and mapping [
4,
5]. Monitoring environmental changes using satellite imagery allows for detecting anomalies and changes, such as the degradation of natural resources [
6]. This allows managers and planners to assess pollution and climate change with exceptional speed and precision. With the rapid growth of artificial intelligence, particularly in Computer Vision, supervised and semi-supervised methods for satellite image segmentation and classification have significantly improved in versatility and accuracy [
7,
8]. However, due to the complexity of specific patterns and the demand for highly detailed classifications, existing methods still require further refinement and enhancement [
8].
Unlike traditional segmentation approaches, deep learning-based methods can identify more diverse areas and complex patterns. However, they require significantly more input data and larger training samples, more advanced hardware, and longer training times [
5,
9]. In the most recent studies, the combined use of expert knowledge in satellite image interpretation and artificial intelligence capabilities has improved the accuracy and generalizability of these methods [
10,
11]. Semantic segmentation, inspired by the functioning of the human mind, is one of the most accurate and advanced methods for segmenting satellite images. It leverages the capabilities of artificial intelligence to achieve more precise classifications. In a semantic segmentation, the input image is divided into multiple subsections, and each subsection is analyzed individually. The results are then processed, and, using a part-to-whole approach, the final segmentation of the entire image is achieved [
4]. Semantic segmentation has shown highly satisfactory results across various fields, particularly satellite imagery. Given that modern sensors acquire a broader range of wavelengths compared to standard Red, Green, and Blue (RGB) images, using the entire frequency bands of satellite and drone sensors can enhance the segmentation quality and significantly improve the detection accuracy. In such scenarios, multispectral satellite images enhance the quality and efficiency of segmentation, particularly under varying weather conditions. For example, using near-infrared (NIR) bands helps distinguish vigorous vegetation, identify regions experiencing water stress, and monitor seasonal plant changes [
12].
Various semantic LCC methods based on supervised deep learning techniques or semi-supervised approaches using transformers have been proposed [
1,
2,
4,
5]. However, based on our knowledge, no method has yet been introduced that combines expert knowledge with an intelligent approach for LCC synergistic semantic segmentation in a hybrid manner. In such cases, traditional methods and expert knowledge can correct some errors in the deep learning output, allowing the simultaneous benefit of both approaches. The present study proposes a hybrid approach combining a pre-trained Deeplab v3+ [
13] segmentation network and a post-processing step using a dictionary containing spectral ensembles of various LC types for synergistic semantic segmentation. The innovations of the proposed method can be summarized as follows:
Simultaneous use of the Deeplab v3+ model with a dictionary-based method for semantic segmentation;
Building of a spectral dictionary for different LC types, which also covers seasonal changes;
Hierarchical application of deep learning-based synergistic semantic segmentation, followed by result refinement using the dictionary-based method;
Integration of deep learning and dictionary-driven methods to improve the learning speed and the output accuracy simultaneously.
This article is organized into five additional sections.
Section 2 reviews the existing literature related to LCC.
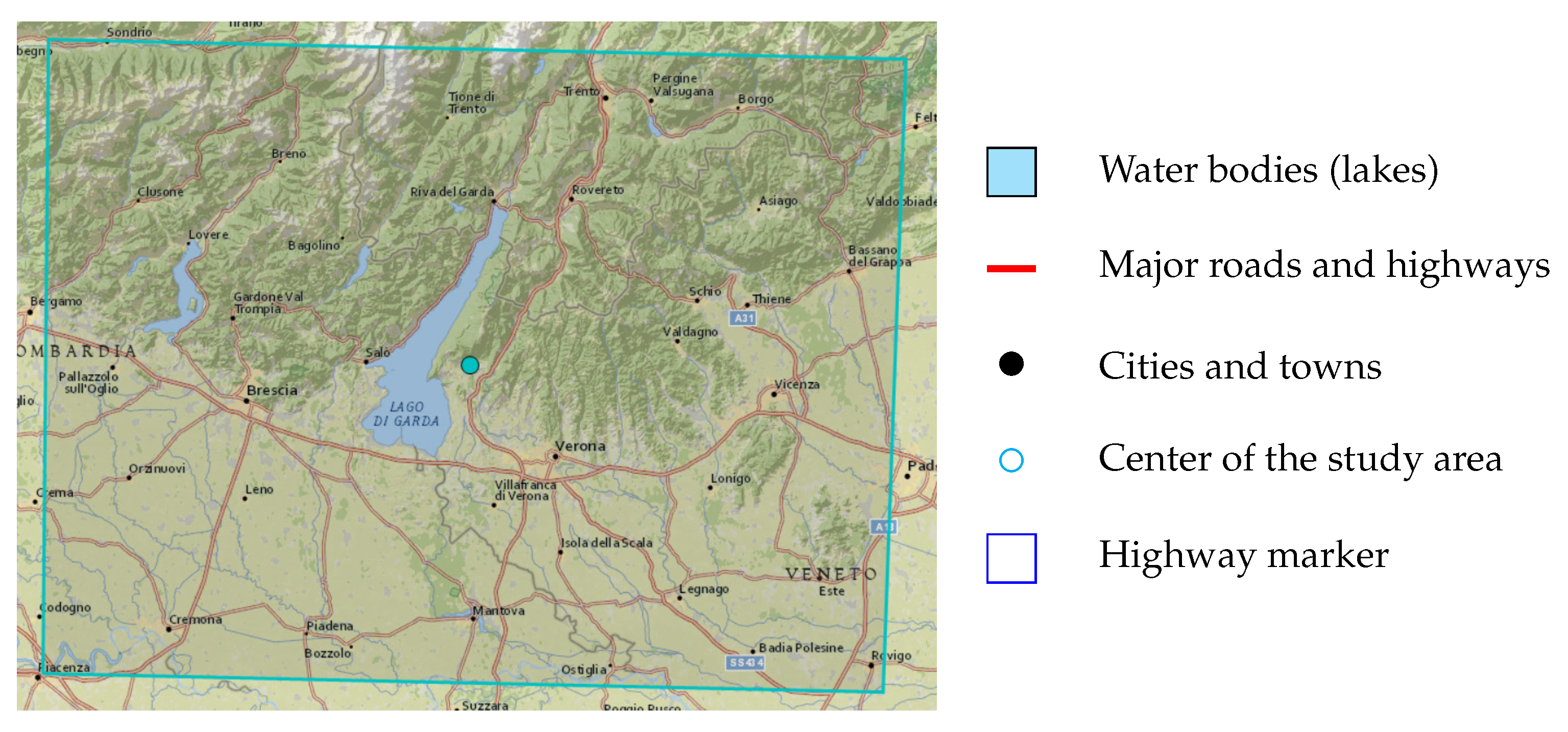
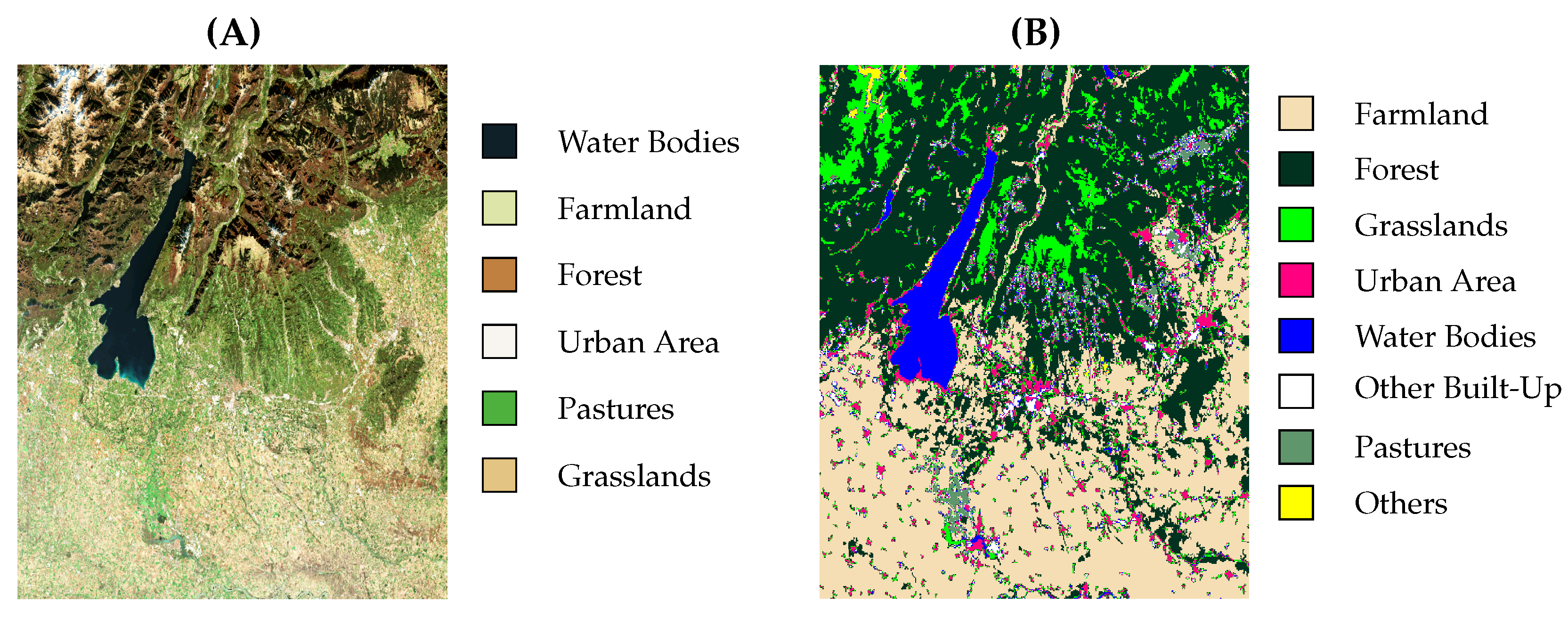
Section 3 explains the studied area and the used dataset in detail.
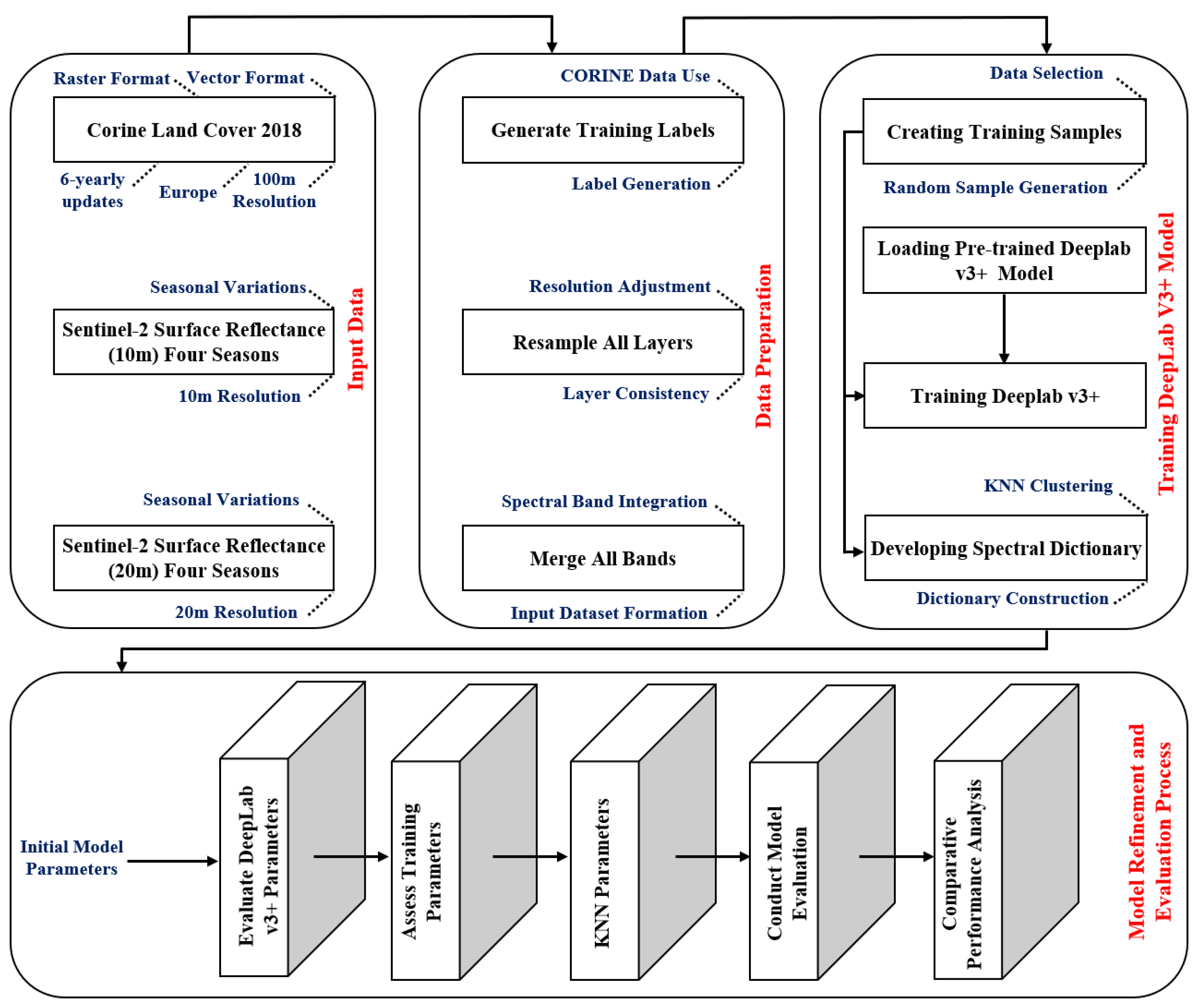
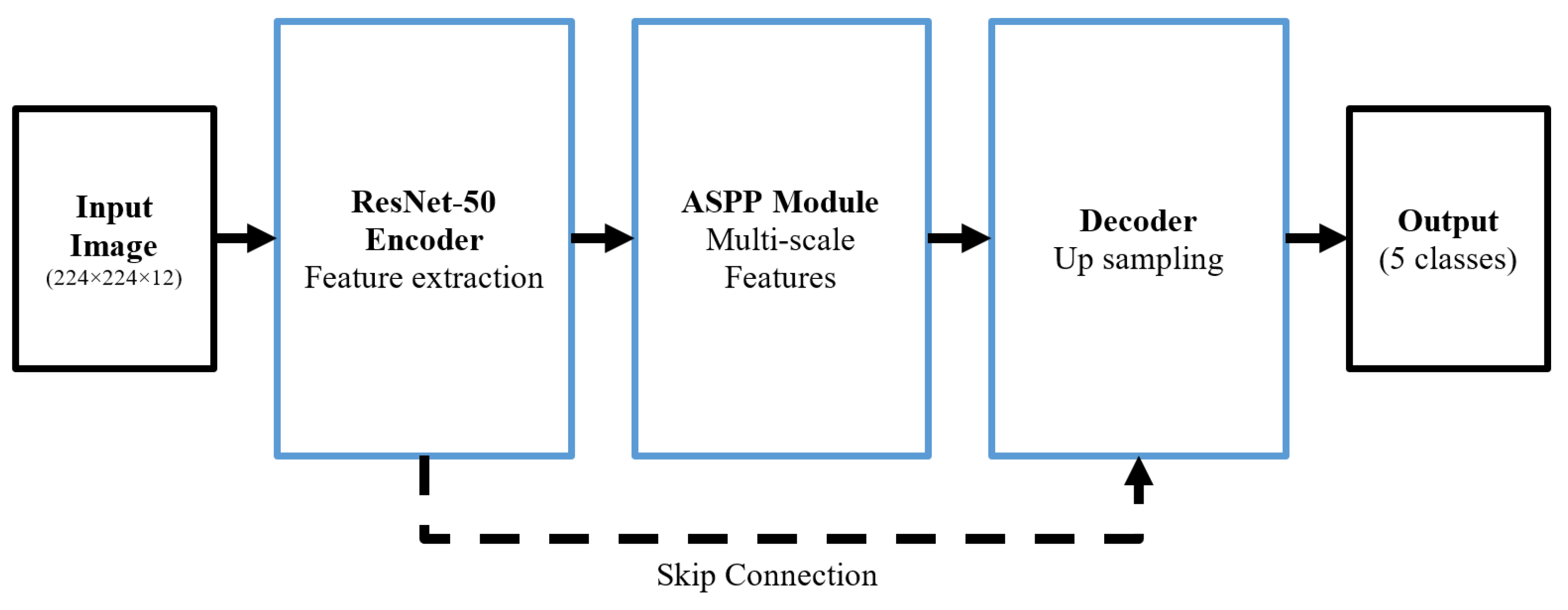
Section 4 outlines the methodology and theoretical aspects employed in the proposed approach.
Section 5 presents and discusses the obtained results. Finally,
Section 6 concludes this article and suggests potential future research directions.
2. Literature Review
In recent years, the rapid development of artificial intelligence systems and the increasing availability of satellite imagery have significantly boosted progress in LCC. Some of the latest studies and advancements in this field focus on using multispectral satellite images. Levering et al. (2021) [
14] proposed an approach combining LCC with landscape esthetic assessment using Sentinel-2 imagery across the United Kingdom. Their ScenicNet architecture employs a ResNet-50 [
15] backbone for feature extraction, coupled with a semantic bottleneck that enables interpretable multi-task learning through class-specific modes. The semantic segmentation methodology leverages a multi-label classification approach rather than pixel-wise segmentation using 10 m resolution bands from the Sentinel-2 satellite. Baudoux et al. (2021) [
16] introduced a framework for translating between different LC maps through a context-aware semantic segmentation approach that simultaneously handles spatial and nomenclature transitions. Their method employs an asymmetric U-Net architecture enhanced with positional encoding to capture local and global geographical context—a crucial consideration for large-scale LC mapping.
Walsh et al. (2021) [
17] introduced a synergistic approach to land cover classification by employing a Resnet-50 Convolutional Neural Network (CNN) architecture for feature extraction and classification, adapted through transfer learning to serve as a segmentation algorithm. The segmentation process uses a U-Net architecture, which excels in pixel-level classification, which is essential for generating detailed land cover maps. The classifier was retrained on Sentinel-2 satellite imagery. Dabija et al. (2021) [
18] conducted a comparative study on LCC using support vector machines (SVMs) and random forest (RF) algorithms, leveraging Sentinel-2 and Landsat 8 multispectral satellite images. The research used multi-temporal feature extraction to analyze seasonal variations and implemented pixel-based classification with iterative accuracy assessment for robust model evaluation. Baudoux et al. (2021) [
19] proposed a novel map translation framework that directly infers CORINE land cover (CLC) maps from existing national-scale products, avoiding the need for new satellite imagery. Their approach leverages a CNN with asymmetrical architecture and positional encoding to harmonize spatial and semantic discrepancies between high-resolution source maps, mainly OSO, and the coarser CLC target. Rousset et al. (2021) [
20] evaluated deep learning techniques for LCC using multispectral satellite imagery. The study used a custom dataset of five regions in New Caledonia, incorporating five LC classes with features derived from raw RGB and NIR bands. The study compared pixel-wise and semantic segmentation methodologies, employing CNNs, mainly DenseNet and DeepLabV3+, alongside a gradient-boosted decision tree classifier, XGBoost. DenseNet and DeepLabV3+ achieved the highest accuracy.
Martini et al. (2021) [
21] proposed a novel methodology integrating domain-adversarial training with self-attention-based Transformer encoders to enhance LCC accuracy across geographic regions and leveraging multispectral, multi-temporal Sentinel-2 imagery. The study extracted temporal correlations using 10 spectral bands and 45 temporal steps. The model employs domain-adversarial neural networks (DANNs) to bridge domain discrepancies, with classification achieved via a Transformer encoder and multi-layer perceptron heads for LC prediction and domain alignment. Xie and Niculescu (2021) [
22] investigated LCC changes over 11 years using SPOT-5 and Sentinel-2 satellite images. They analyzed deep learning and machine learning classifiers, including SVM, RF, and CNN, with the CNN achieving superior accuracy. Šćepanović et al. (2021) [
23] explored semantic segmentation for wide-area LC mapping using Sentinel-1 C-band synthetic aperture radar (SAR) imagery, leveraging its resilience to cloud cover and low-light conditions. They used CORINE LC maps as reference data, focusing on five aggregated classes, and employed seven state-of-the-art segmentation architectures, including U-Net, DeepLabV3+, PSPNet, and FC-DenseNet, pre-trained on ImageNet and fine-tuned for SAR.
Yuan et al. (2022) [
24] proposed SITS-Former, a pre-trained spatial–spectral–temporal representation model designed for LCC from Sentinel-2 satellite time series. The methodology employs a Transformer encoder backbone, pre-trained through a self-supervised learning task of missing-data imputation to capture high-level spatial and temporal dependencies. Sengan et al. (2022) [
25] proposed a hybrid learning model, RAVNet, for efficient LCC using multispectral satellite imagery. The model integrates residual attention mechanisms with the VNet framework to blend low-level and high-level feature maps, enhancing spatial and contextual information extraction. Paris et al. (2022) [
26] developed a scalable, high-performance, unsupervised system for producing high-resolution LC maps. Their methodology employs a tile-based, parallelizable approach using Sentinel-2 imagery. The feature extraction step incorporates robust spectral indices, while the classification step relies on an ensemble of SVMs with Gaussian radial basis functions. The segmentation step is achieved through K-means clustering to refine “weak” training sets extracted from coarse LC map units.
Zaabar et al. (2022) [
27] suggested an integrated framework combining CNNs and object-based image analysis (OBIA) for LCC mapping in coastal areas. Using Sentinel-2 and Pléiades imagery, their methodology leverages CNNs to extract high-level spectral features through convolutional, pooling, and hidden layers, subsequently applying OBIA for segmentation and classification of LCC categories. The study also compared traditional machine learning classifiers, including RF and SVM, highlighting the superior accuracy of the OBIA-CNN integration. Efthimiou et al. (2022) [
28] developed a high-resolution LCC approach to address the spatial and temporal limitations of the CORINE dataset. By integrating the land parcel identification system (LPIS) with multispectral Sentinel-2 imagery, the approach employs object-oriented segmentation and harmonization of datasets to enhance agricultural classification. Giffard-Roisin et al. (2022) [
29] presented an innovative approach for LCC in the Alps using temporal coherence matrices derived from Sentinel-1 SAR data. The approach employs a one-year coherence matrix as input, capturing temporal and spatial patterns essential for segmentation. The features are extracted by treating the matrix as image-like data, enabling multi-scale texture analysis. The classification is performed using an SVM and CNN across six classes. Soni et al. (2022) [
30] presented an urban LCC classification framework leveraging Sentinel-2 multispectral imagery to address challenges posed by high-density urbanization in South-West Delhi. Employing SVM, artificial neural networks (ANNs), and maximum likelihood classification (MLC) approaches, the study compared their performance using kappa coefficients and overall accuracy (OA) metrics.
Matcı and Avdan (2022) [
31] proposed a methodology for the automatic labeling of LC classes using Sentinel-2 multispectral imagery, focusing on regions in Turkey and Greece. The classification spans five major categories, leveraging a pre-constructed spectral database alongside Corine LC data to validate and refine labels. This study highlights the potential of spectral-index-based models in addressing challenges in LCC, offering a scalable solution with enhanced spatial detail critical for ecological monitoring and resource management in remote sensing applications. Daniele la Cecilia et al. (2023) [
32] introduced the open field and protected agriculture classifier (OPAC), a pixel-based model leveraging Sentinel-2 L2A imagery for LCC, addressing the unique challenges of mapping heterogeneous agricultural landscapes. Employing the RF algorithm, OPAC extracts features from a 13-dimensional vector of spectral bands to classify nine LC types.
Matei and Koßmann (2023) [
33] introduced a robust Self-Supervised Learning (SSL) framework for addressing the challenges of season-invariant LCC using remote sensing data. The methodology leverages SeasoNet [
34], comprising multispectral Sentinel-2 imagery with high-resolution segmentation labels, and employs MoCo-v2 for SSL pre-training with ResNet-50 and DeepLabV3 architectures. Feature extraction involves contrastive learning, incorporating novel seasonal augmentations and combinations with traditional artificial augmentations. Duarte and Fonte (2023) [
35] proposed a framework to classify non-residential built-up areas by integrating national census data with Sentinel-2 satellite imagery through a supervised CNN segmentation model. The study employed census datasets combined with built-up data to automatically generate training masks, enabling segmentation using a modified U-Net architecture with densely connected layers to address class imbalances. Sentinel-2’s 10 m spatial resolution bands are used for feature extraction to differentiate residential and non-residential land uses.
Kramarczyk and Hejmanowska (2023) [
36] employed a U-Net neural network architecture to classify Sentinel-2 multispectral satellite images for LCC in rural areas, addressing challenges in distinguishing agricultural and quarry land. The model leverages multi-temporal Sentinel-2 data to extract features across ten spectral bands, enabling detailed monitoring of LC transitions and soil conditions. Demir and Musaoglu (2023) [
37] proposed a semantic segmentation framework leveraging deep learning for CORINE LCC using Sentinel-2 imagery. The methodology involves dataset pre-processing, U-Net architecture enhanced with ResNet50 and ResNet101 backbones, and transfer learning for robust feature extraction. This approach employs multi-temporal Sentinel-2 data, including RGB and NRG bands, facilitating seasonal variability assessments. Zamanoglu et al. (2023) [
38] suggested a hybrid semantic segmentation approach combining DeepLabV3 and ResNet34 architectures for LCC using the LandCover AI dataset. The model leverages ResNet34 for robust feature extraction and employs DeepLabV3 to handle multi-scale contextual information. Cecili et al. (2023) [
39] explored CNNs for LC mapping, leveraging Sentinel-2 multispectral imagery. The study evaluated DenseNet121, ResNet50, and VGG16 models using single-date and multi-temporal datasets, ultimately identifying VGG16 as the most effective classifier.
Tzepkenlis et al. (2023) [
40] presented a novel approach to LCC using a modified U-TAE model for Sentinel imagery composites processed via Google Earth Engine. Their methodology simplifies the input data by employing temporal median composites of Sentinel-1, Sentinel-2, and ALOS elevation data, reducing noise from atmospheric effects. Feature extraction leverages a channel attention mechanism within the U-TAE model, diverging from traditional temporal attention strategies. Cuypers et al. (2023) [
41] proposed an integrative approach for LCC mapping by leveraging very high-resolution (VHR) optical imagery and multi-temporal Sentinel-2 satellite data within a geographic object-based image analysis (GEOBIA) framework. The methodology incorporated RF classifiers, augmented with simple non-iterative clustering (SNIC) for segmentation, and extracted features such as gray-level co-occurrence matrix (GLCM) textures and temporal indices, such as the phase and amplitude of spectral indices. Arrechea-Castillo et al. (2023) [
42] proposed a robust, computationally efficient approach for multi-class LCC classification using Sentinel-2 imagery and a simplified CNN based on the LeNet architecture. Their model used 27 features derived from pre-processed spectral bands, a digital elevation model (DEM) and 16 radiometric indices. Fagua et al. (2023) [
43] developed a high-resolution LCC framework tailored to tropical regions using temporal metrics derived from Sentinel-1 SAR and Sentinel-2 multispectral data. The study integrated SAR backscatter coefficients and multispectral indices with visual pixel classifications and field survey data. Five machine learning classifiers were evaluated, with RF achieving the best performance.
Gharbia (2023) [
44] introduced an automated framework for extracting water regions using Faster R-CNN, a region-based CNN designed for object detection. This method integrates CNN-based feature extraction with a region proposal network (RPN) to achieve precise classification and localization of water features. The approach was evaluated using Sentinel-2 and Landsat-8 (OLI) datasets, with Sentinel-2 leading to the highest accuracy. Kavran et al. (2023) [
45] introduced a spatiotemporal approach for LCC using multispectral Sentinel-2 satellite images processed through a graph neural network (GNN). The methodology integrated superpixel segmentation with graph-based representation, where segmented land regions across sequential images were modeled as directed graphs. Feature extraction was conducted using EfficientNetV2-S, while node classification relied on the GraphSAGE algorithm with LSTM-based aggregation. Carneiro et al. (2023) [
46] proposed a transfer learning framework using small 3D CNNs for LCC. Their method used semantic segmentation with a slide-window approach, using pre-trained models fine-tuned on Sentinel-2 imagery, with bands at 10 m and 20 m resolutions. Feature extraction incorporated spectral–spatial characteristics via small CNNs and ResNext50 as the backbone for specific segmentation tasks.
Çelik and Gazioğlu (2024) [
47] employed a modified VGG16 CNN using transfer learning for the semantic segmentation of coastal LC using Sentinel-2A multispectral imagery. Their methodology used Google Earth Engine for large-scale data pre-processing and incorporated spectral band combinations, notably emphasizing the NIR band, to enhance classification accuracy across five coastal classes. Feature extraction relied on the fine-tuned later layers of VGG16, while classification employed the CNN’s architecture with adjustments for improved generalizability. Pešek et al. (2024) [
48] proposed a CNN-based framework for semantic segmentation of urban green areas using Sentinel-2 multispectral imagery. The study evaluated four CNN architectures, FCN, U-Net, SegNet, and DeepLabv3+, and compared them to an RF baseline. This work underscores CNNs’ potential in addressing LCC challenges, particularly for urban environments with limited high-resolution datasets. Perez-Guerra et al. (2024) [
49] explored deep learning-based semantic segmentation techniques for LCC using Sentinel-2 multispectral images. The study employed U-Net, U-Net++, and PSPNet architectures, integrating feature extraction through ResNet and ResNeXt backbones, pre-trained on ImageNet. Vo Quang et al. (2024) [
50] used CNNs to identify degraded forests using Sentinel-2 multispectral imagery. The study used U-Net, SegNet, and ResNet-UNet models, with U-Net demonstrating superior performance.
Kalaivani et al. (2024) [
51] presented a comprehensive approach to LC segmentation using a blend of state-of-the-art deep learning architectures, including U-Net++, DeepLabV3+, InceptionV4, MobileNetV2, and ResNet152. While the research underscores the effectiveness of combining high-performing models for segmentation, its reliance on existing datasets may limit adaptability to unexplored geographic regions, reflecting broader challenges in scalable LCC from multispectral satellite imagery. Marko Pavlovic et al. (2024) [
52] proposed a two-stage deep learning pipeline for estimating soil organic carbon (SOC) using Sentinel-2 satellite imagery, emphasizing LCC as a precursor to SOC prediction. The methodology employs the U-Net architecture for image segmentation to extract spatial features from multispectral images, subsequently using these as input for machine learning models such as Extremely Randomized Trees, which achieved superior performance. Suraj Sawant and Ghosh (2024) [
53] used a tailored semantic segmentation approach to address the challenges of LCC using Sentinel-2 imagery. Their methodology involved training five state-of-the-art deep CNNs, including UNet, FPN, and LinkNet architectures optimized for pixel-wise classification of seven LCC classes.
Sharma et al. (2024) [
54] introduced Sen4Map, a benchmark dataset built for detailed land cover mapping using Sentinel-2 satellite data. Feature extraction incorporates Sentinel-2 bands at 10 m and 20 m resolutions, excluding bands primarily used for atmospheric corrections. Four classifiers, including RF and temporal vision transformers, were benchmarked for broad land cover categorization and detailed crop classification, emphasizing temporal harmonization. Lasko et al. (2024) [
55] proposed a scalable LCC methodology for Sentinel-2 imagery across seven diverse global sites. The framework integrates binary masks derived from spectral, textural, and ancillary geospatial data layers and optimizes thresholds regionally and globally to generate nine-class, six-class, and five-class models. The segmentation approach combined adaptive thresholding with decision functions, ensuring compatibility across heterogeneous landscapes. Some studies used vision transformers [
24,
56] and self-supervised learning approaches [
33,
34] to improve LCC methods. However, these methods did not use traditional post-processing techniques to correct errors in segmentation output.
Based on the reviewed studies, while deep learning and some machine learning methods have shown good performance in LCC, there are still various challenges. One of the main challenges is the need to have a large amount of training data to improve accuracy and generalizability. The aforementioned studies are all trained on local and regional data, restricting the models’ generalizability. Additionally, they must be trained for various times of the year to operate independently of temporal factors in vegetation or forest classification. In some applications, such as mining, spectral information databases are available; however, spectral data for other types of coverage remain quite limited. This study introduces a combined deep learning and multispectral analysis approach for LCC.
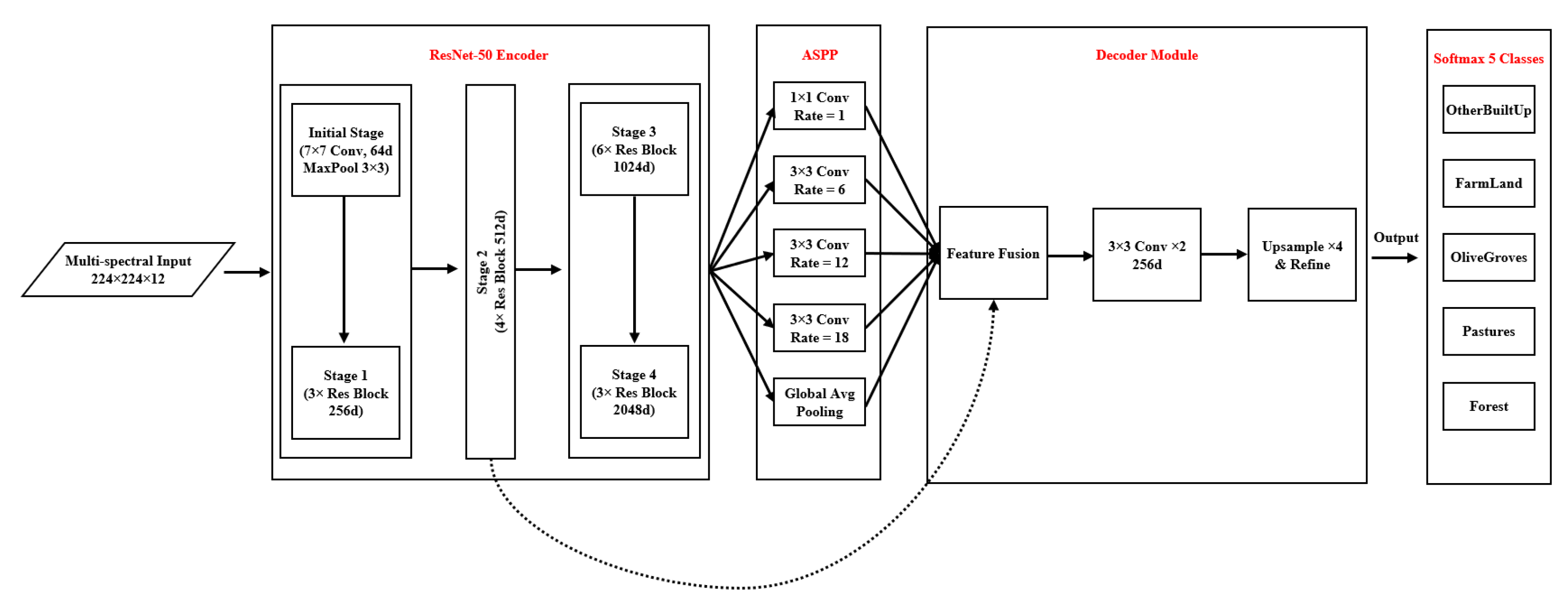
In the current study, a deep learning LCC model is used for segmentation, and then a K-medoids post-processing step is used to improve the segmentation result. The post-processing step uses an assumption of continuity in adjacent regions to fix errors. By combining the strengths of both deep learning and K-medoids, the proposed approach aims to achieve better performance. Leveraging transfer learning significantly reduces the number of samples required for training the deep learning model. Additionally, dictionary-based multispectral analysis is incorporated to enhance the accuracy of the synergistic semantic segmentation, so the proposed method effectively addresses the limitations of previous techniques to a notable extent.
6. Conclusions
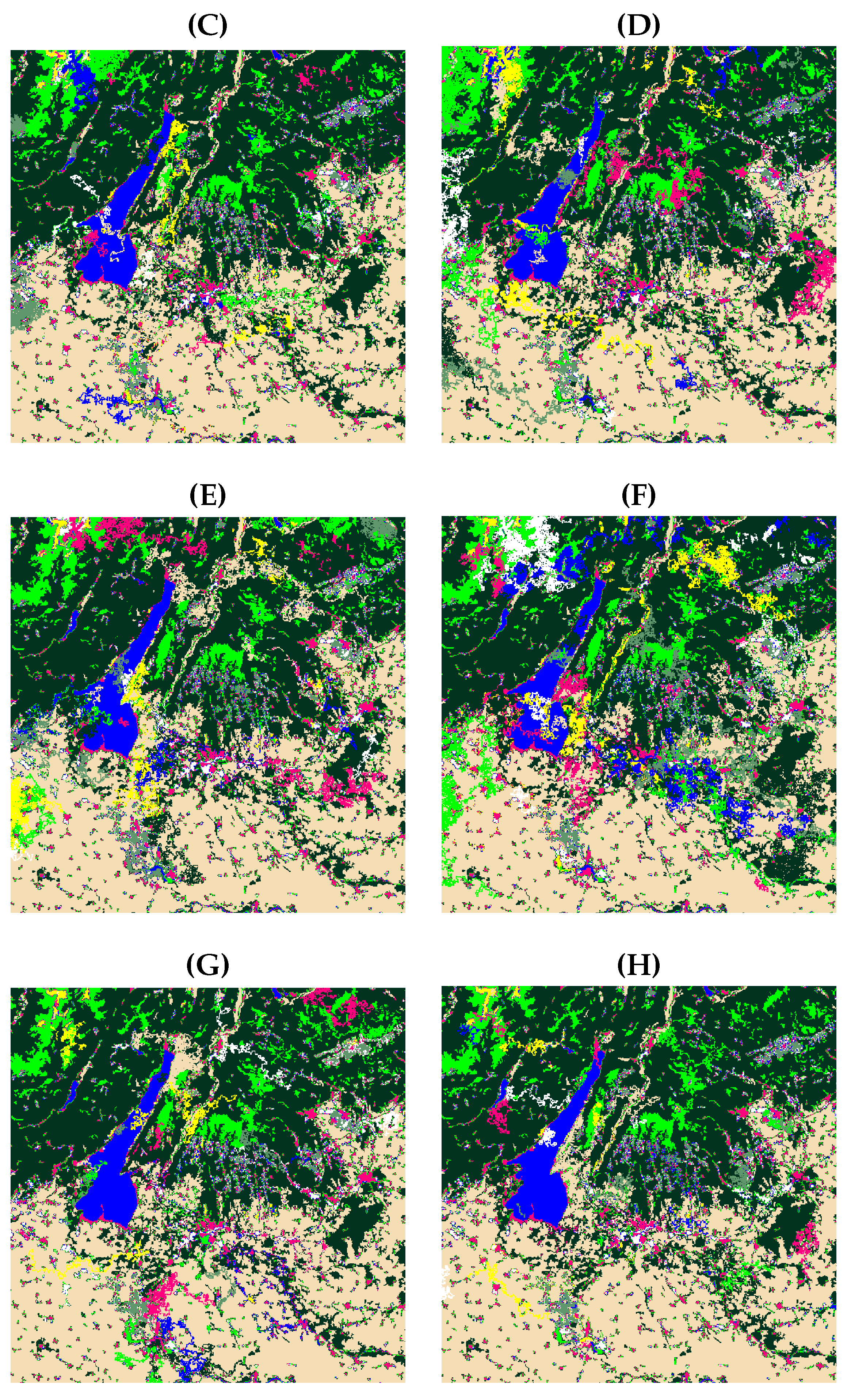
This study introduced a synergistic semantic segmentation system integrating the DeepLab v3+ deep neural network with a post-processing step. The chosen classes included Pastures, Urban Areas, Other Built-Up Areas, Water Bodies, Grasslands, Forests, Farmland, and Others. Transfer learning was used with DeepLab v3+ pre-trained segmentation networks to optimize the training process and reduce computational demands. In the post-processing step, a dictionary-based K-medoid clustering approach was used. In the K-medoid clustering, spectral codewords were first derived for each class using training data. These spectral codewords, which cover seasonal variations in classes such as Forests and Pastures, were then used to refine the DeepLab v3+ output. The proposed post-processing approach, which involves dictionary training and subsequent use of spectral codewords for performance enhancement, achieved a 1.5% improvement in weighted OA and a 5.7% increase in the weighted MCC compared to the DeepLab v3+ network. It also outperformed selected state-of-the-art semantic segmentation networks, with over a 1.5% in weighted OA and more than a 6% improvement in the weighted MCC.
The main advantages of the proposed method are the ability to analyze vegetation classes based on the data acquisition timing and the addition of a post-processing approach to reduce errors. The two main limitations of the proposed method are computational complexity and inefficiency in cases where deep learning makes errors within a specific region. The second limitation is because of the assumption that errors appear as isolated points within a correct texture. If this assumption is incorrect, the post-processing approach will not check them.
The proposed LCC method has many applications in environmental monitoring, urban expansion tracking, agricultural land management, urban expansion tracking, and water resource management. For example, by segmenting forest areas, the model can track changes in natural landscapes over time and assess patterns of degradation and land use changes caused by human activity. Future work could focus on generalizing the derived codewords for different vegetation types across various regions and creating a spectral dictionary of vegetation classes that can be standardly used in multispectral satellites. Moreover, the post-processing approach could be refined using statistical analysis to define more precise error probability patterns. Another interesting topic is the use of domain adaptation techniques, e.g., feature normalization and fine-tuning, to improve the transferability of the model to different sensors.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}