
Secondary Operation Risk Assessment Method Integrating Graph Convolutional Networks and Semantic Embeddings


Abstract
1. Introduction
- The proposed model innovatively combines semantic embeddings generated by RoBERTa with structural embeddings extracted by a GCN. Unlike traditional methods that focus on either semantic or structural information, this hybrid model leverages both to improve evaluation accuracy.
- This paper constructs a structured knowledge graph for secondary operation scenarios in the power industry and utilizes a GCN to extract structural information from graph nodes, providing reliable support for risk assessment.
- This paper employs the K-means clustering similarity search algorithm to significantly reduce computational complexity. Additionally, a multi-node weighted evaluation method is introduced to comprehensively consider the risk scores of multiple similar nodes, further enhancing the precision and reliability of the assessment results.
- We evaluate the proposed model on power datasets. Compared to the other models, our model achieves the best results in terms of accuracy, recall, and F1 score. Furthermore, an ablation study evaluates the effectiveness of combining semantic and structural embeddings, as well as the similarity measurement mechanism.
2. Related Work
3. Methodology
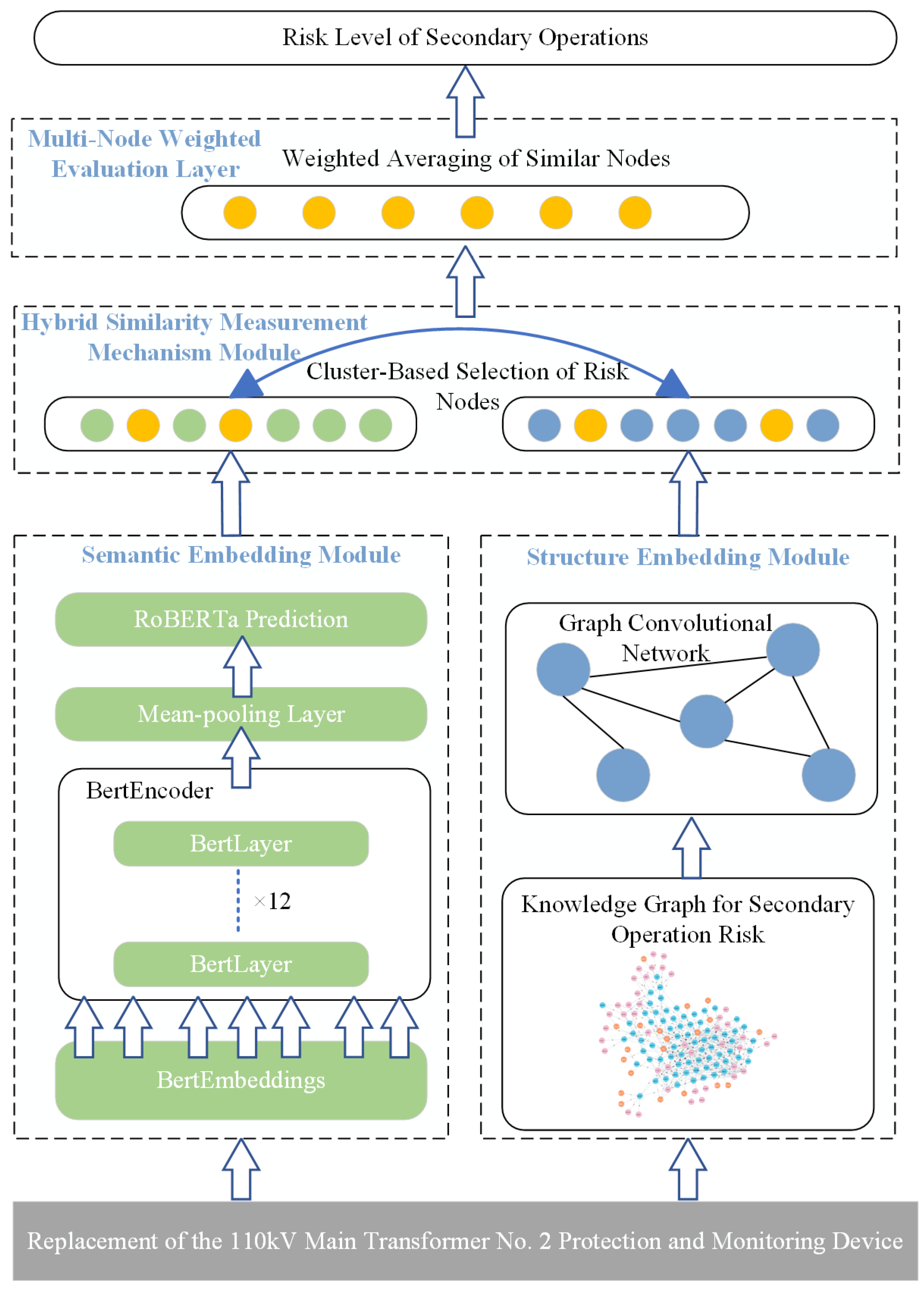
3.1. Model Architecture
3.2. Knowledge Graph Construction
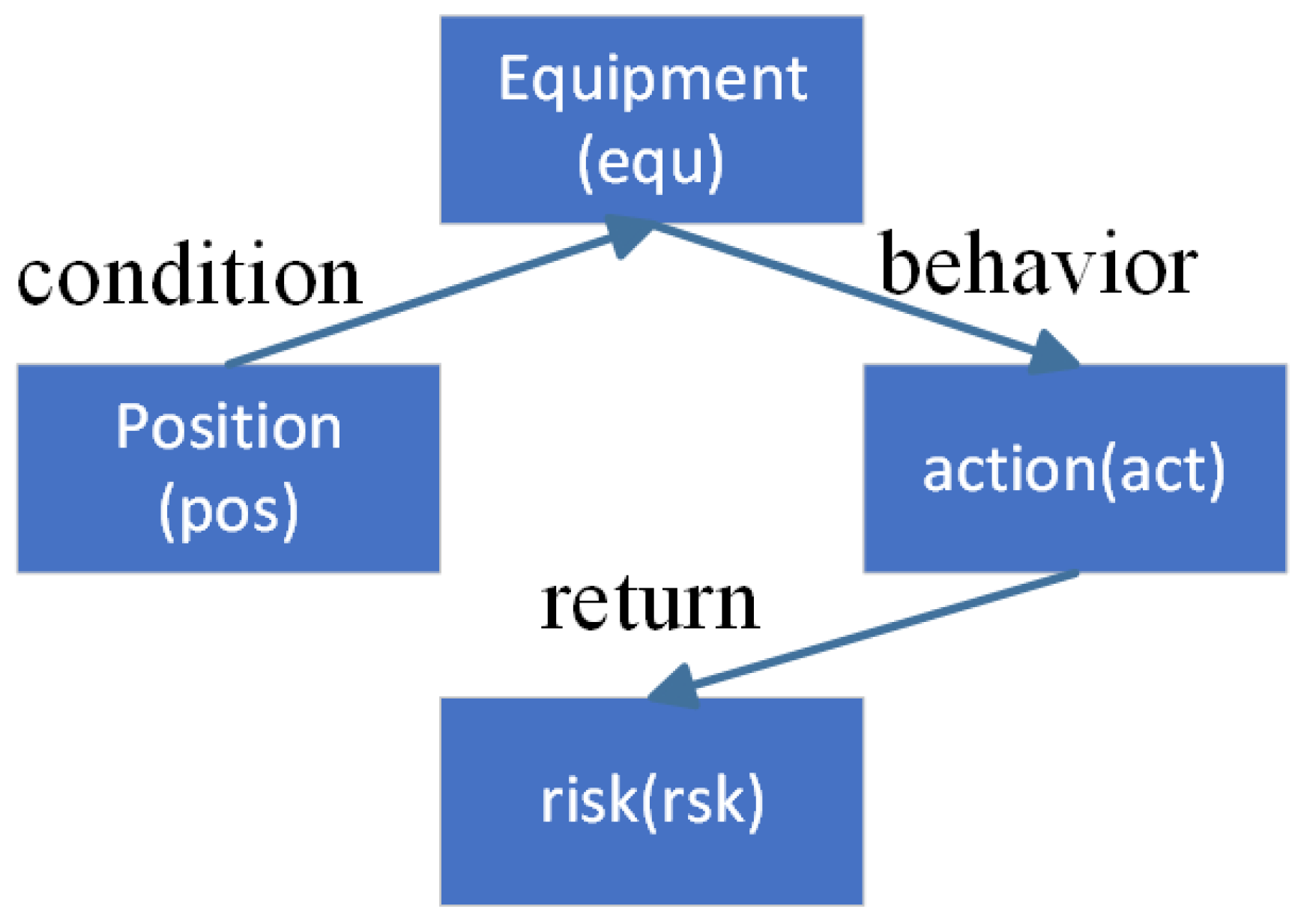
3.2.1. Data Acquisition and Ontology Construction
- Current and Voltage Sensors: These sensors are used to monitor real-time changes in current and voltage on busbars, especially during retrofitting or testing processes. They can accurately capture fluctuations caused by line switching or equipment commissioning, providing critical data for early anomaly detection.
- Fault Location Sensors: During equipment retrofitting, testing the response performance of protection devices may be necessary. Fault location sensors generate and capture fault signals to verify whether the protection devices are functioning correctly, ensuring system stability.
- Environmental Monitoring Sensors: In scenarios where primary equipment remains in service, there may be heightened risks of electromagnetic interference and thermal effects. Environmental monitoring sensors, such as electromagnetic radiation sensors and temperature–humidity sensors, provide real-time surveillance of the working environment, assess its safety, and support risk mitigation efforts.
- Grounding Resistance Sensors: These sensors are used to check whether the grounding status of out-of-service equipment meets safety standards. By accurately measuring grounding resistance, they help to prevent safety hazards caused by poor grounding.
- Data Filtering: Cleaning the text corpus to remove irrelevant data and unnecessary characters that do not contain entity relationships, retaining only content relevant to knowledge extraction;
- Sentence Segmentation: Splitting longer sentences into reasonable segments to ensure that each segment has an appropriate length and contains at least one entity relationship pair. This helps the model to better recognize entity relationships and improves extraction efficiency;
- Data Annotation: The Label Studio annotation tool is used to mark entities in the text according to the BIO format. During this process, entities and relationships in the preprocessed text are precisely labeled, enabling the model to learn the structure and associations of domain-specific knowledge during training.
3.2.2. Knowledge Extraction
3.2.3. Knowledge Fusion
3.2.4. Knowledge Storage
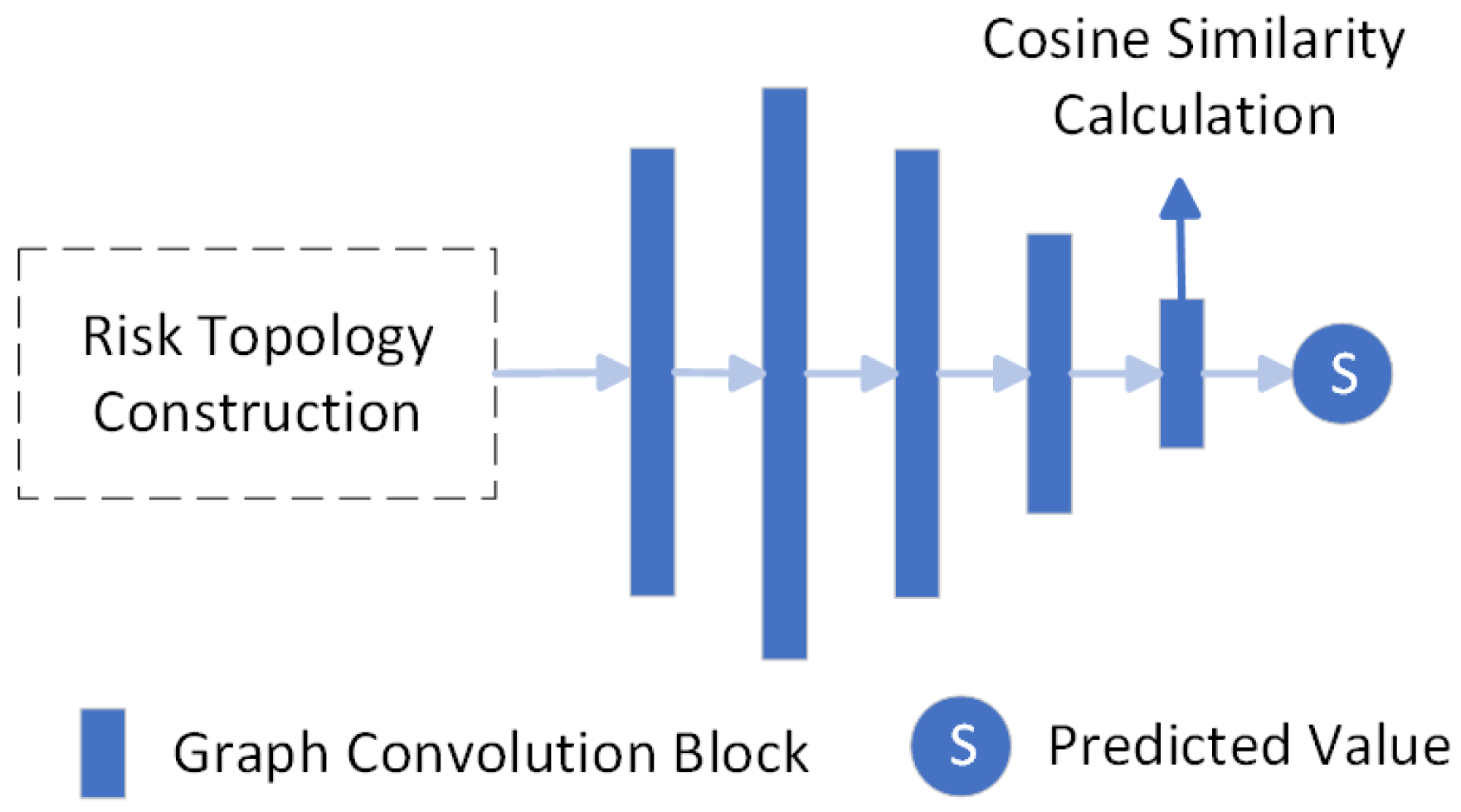
3.3. GCN Structural Embedding Generation
3.4. RoBERTa Semantic Embedding Fusion
3.5. Similarity Measurement Mechanism
4. Results
4.1. Datasets and Parameter Settings
4.2. Experimental Environment and Evaluation Metrics
4.3. Results Analysis
5. Conclusions
- Building a dynamic knowledge graph update mechanism and using online learning to integrate new equipment parameters and operation and maintenance records in real time.
- Developing a lightweight graph neural network architecture and adapting edge computing devices to achieve on-site risk assessment.
- Exploring multi-agent collaborative evaluation models and optimizing the semantic embedding space in combination with expert experience feedback.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ju, P.; Zhou, X.; Chen, W.; Yu, Y.; Qin, C.; Li, R.; Wang, C.; Dong, X.; Liu, J.; Wen, J. A Review of Research on “Smart Grid+”. Electr. Power Autom. Equip. 2018, 38, 2–11. [Google Scholar]
- Zhang, Y.; Wang, A.; Zhang, H. A Review of Smart Grid Development in China. Power Syst. Prot. Control 2021, 49, 180–187. [Google Scholar]
- Zhang, H.; Zhang, B. Reliability Evaluation Method for Secondary Safety Measures in Substation Secondary Equipment Maintenance Based on Maintenance Strategies. Hebei Electr. Power Technol. 2024, 43, 43–49. [Google Scholar]
- Zhao, W.; Fan, G.; Wu, X.; Wang, Y.; Bai, J.; Zhao, L. Research and Application of Substation Secondary Safety Ticket Generation Technology Based on Self-Learning Technology. Electr. Meas. Instrum. 2024, 61, 151–157. [Google Scholar]
- Fan, W.; Zhu, H.; Feng, X.; Dong, J.; Gao, X.; Hu, Y. A Secondary Safety Measure Verification Method for Smart Substations Based on Signal Simulation. Electr. Power Autom. Equip. 2020, 40, 1–10. [Google Scholar]
- Hu, L. Fault Analysis and Research of Power Systems Based on Expert Systems. J. Change Inst. Technol. 2014, 27, 33–37. [Google Scholar]
- Wu, M.; Huang, X.; Zhu, Y.; Jiang, W. Risk Assessment of Cable Lines Based on the Analytic Hierarchy Process. J. Xi’an Polytech. Univ. 2019, 33, 637–642. [Google Scholar]
- Zhao, J. Analysis of Violation Identification Factors and Research on Risk Assessment System for Distribution Network Operations. Master’s Thesis, Hunan University, Changsha, China, 2023. [Google Scholar]
- Qi, D.; Yan, W.; Yan, Y.; Peng, J.; Guo, B. Research Status and Development of Event Knowledge Graph for Power Dispatching. J. Electron. Inf. Technol. 2025, 47, 1–11. [Google Scholar]
- Tian, J.; Song, H.; Chen, L.; Sheng, G.; Jiang, X. A Method for Entity Recognition in Equipment Fault Texts for Knowledge Graph Construction. Power Syst. Technol. 2022, 46, 3913–3922. [Google Scholar] [CrossRef]
- Jiang, C.; Wang, Y.; Chen, M.; Li, C.; Wang, Y.; Ma, G. Transformer Fault Identification Based on Kbert Text Clustering Model. High Volt. Eng. 2022, 48, 2991–3000. [Google Scholar] [CrossRef]
- Kun, L.; Baoxian, Z.; Yiying, Z.; Yiping, L.; Bo, Z.; Xiankun, Z. PF2RM: A Power Fault Retrieval and Recommendation Model Based on Knowledge Graph. Energies 2022, 15, 1810. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-BERT: Enabling Language Representation with Knowledge Graph. Proc. AAAI Conf. Artif. Intell. 2020, 34, 2901–2908. [Google Scholar] [CrossRef]
- Delobelle, P.; Winters, T.; Berendt, B. Robbert: A dutch roberta-based language model. arXiv 2020, arXiv:2001.06286. [Google Scholar]
- Chen, Y.; Lin, D.; Meng, Q.; Liang, Z.; Tan, Z. Named entity identification in the power dispatch domain based on RoBERTa-attention-FL model. Energies 2023, 16, 4654. [Google Scholar] [CrossRef]
- Lin, L.; Chen, Q.; Jin, L.; Wang, L. Research and Application of Fault Knowledge Representation for Substation Alarm Information Based on Knowledge Graph. Power Syst. Prot. Control 2022, 50, 90–99. [Google Scholar]
- Yang, X.; Peng, G.; Li, Z.; Lv, Y.; Liu, S.; Li, C. APT Attack Entity Recognition and Alignment Based on BERT and BiLSTM-CRF. J. Commun. 2022, 43, 58–70. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A temporal graph convolutional network for traffic prediction. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3848–3858. [Google Scholar] [CrossRef]
- Yu, S.Y.; Malawade, A.V.; Muthirayan, D.; Khargonekar, P.P.; Al Faruque, M.A. Scene-graph augmented data-driven risk assessment of autonomous vehicle decisions. IEEE Trans. Intell. Transp. Syst. 2021, 23, 7941–7951. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Y.; Gou, C. Learning from interaction-enhanced scene graph for pedestrian collision risk assessment. IEEE Trans. Intell. Veh. 2023, 8, 4237–4248. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Hamerly, G.; Elkan, C. Learning the K in K-Means. Adv. Neural Inf. Process. Syst. 2003, 16. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Voltage Level | High-Risk Operation Content | Risk Level |
|---|---|---|---|
| 1 | 220 kV | Primary equipment area: Replacement of 220 kV terminal box, cable laying, and wiring; Replacement of 220 kV control panel, switchgear testing | III |
| 2 | 35 kV or Below | Transformer row device modification | IV |
| 3 | 110 kV | Main transformer protection: Control equipment replacement, voltage regulator modification | IV |
| 4 | 1000 kV | First set of quasi-station equipment inspection for pressure control and circuit breaker | III |
| Token | Label |
|---|---|
| 110 KV | B-pos |
| 2nd | O |
| main transformer | B-equ |
| protection | I-equ |
| measurement | I-equ |
| installation | I-equ |
| replacement | B-act |
| Parameter Name | Parameter Value |
|---|---|
| Learning Rate | 1 × 105 |
| Batch Size | 8 |
| Epoch | 10 |
| BERT Pre-trained Model | BERT-base-Chinese |
| BERT Dimension | 768 |
| P | R | F1 | |
|---|---|---|---|
| BiLSTM | 0.766 | 0.801 | 0.785 |
| BiLSTM-CRF | 0.815 | 0.828 | 0.830 |
| BERT-CRF | 0.881 | 0.866 | 0.885 |
| BERT-BiLSTM-CRF | 0.898 | 0.885 | 0.890 |
| Model | P | R | F1 |
|---|---|---|---|
| Ranking SVM_EL | 0.724 | 0.716 | 0.711 |
| C-DSSM | 0.807 | 0.816 | 0.808 |
| BERT | 0.811 | 0.825 | 0.822 |
| RoBERTa | 0.823 | 0.826 | 0.828 |
| SBERT | 0.834 | 0.837 | 0.834 |
| ERNIE | 0.843 | 0.841 | 0.839 |
| GraphSAGE | 0.763 | 0.755 | 0.760 |
| GAT | 0.845 | 0.838 | 0.841 |
| Ours | 0.879 | 0.863 | 0.868 |
| Semantic Embedding | Structural Embedding | Similarity Measurement Mechanism | P | R | F1 |
|---|---|---|---|---|---|
| ✓ | 0.815 | 0.825 | 0.830 | ||
| ✓ | 0.763 | 0.755 | 0.760 | ||
| ✓ | ✓ | 0.854 | 0.835 | 0.846 | |
| ✓ | ✓ | 0.798 | 0.785 | 0.774 | |
| ✓ | ✓ | ✓ | 0.879 | 0.863 | 0.868 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, P.; Li, Y.; Xu, P.; Li, P.; Zhao, Z.; Li, G. Secondary Operation Risk Assessment Method Integrating Graph Convolutional Networks and Semantic Embeddings. Sensors 2025, 25, 1934. https://doi.org/10.3390/s25061934
Zhu P, Li Y, Xu P, Li P, Zhao Z, Li G. Secondary Operation Risk Assessment Method Integrating Graph Convolutional Networks and Semantic Embeddings. Sensors. 2025; 25(6):1934. https://doi.org/10.3390/s25061934
Chicago/Turabian StyleZhu, Pengyu, Youwei Li, Peidong Xu, Ping Li, Zhenbing Zhao, and Gang Li. 2025. "Secondary Operation Risk Assessment Method Integrating Graph Convolutional Networks and Semantic Embeddings" Sensors 25, no. 6: 1934. https://doi.org/10.3390/s25061934
APA StyleZhu, P., Li, Y., Xu, P., Li, P., Zhao, Z., & Li, G. (2025). Secondary Operation Risk Assessment Method Integrating Graph Convolutional Networks and Semantic Embeddings. Sensors, 25(6), 1934. https://doi.org/10.3390/s25061934