
Multi-Feature Unsupervised Domain Adaptation (M-FUDA) Applied to Cross Unaligned Domain-Specific Distributions in Device-Free Human Activity Classification



Abstract
1. Introduction
- ✓
- Multi-source M-FUDA outperforms all the baseline methods for most of the transfer learning tasks performed on three publicly available CSI datasets utilized for creating cross-user, cross-environment, and/or cross-atmospheric conditions using device-free HAR.
- ✓
- The proposed model is applied to a multi-source unsupervised domain adaptation (MUDA) setup and contrasted against a single-source unsupervised domain adaptation (SUDA) setup designed with all the underlined sources combined in a single-source vs target setting. The proposed model produces promising results, surpassing traditional domain adaptation methods for device-free sensing. Our findings suggest that aligning multiple domain-invariant representations with domain-specific classifiers near class boundaries improves generalization. This alignment is particularly effective for each pair of source and target domains. As a result, the model performs well across various domain-shifting tasks.
- ✓
- Empirical evaluation of various distance minimization approaches on one of the selected CSI datasets for each pair of source and target distributions indicates the suitability of maximum mean discrepancy (MMD) over others.
- ✓
- Extensive evaluation shows that the predictive outputs of classifiers from different CSI sources capture target samples far from the support of underlying sources with the involvement of discrepancy and contrastive semantic alignment losses. This shows the role of proposed alignment losses in reducing the gap between the classifiers.
2. Related Work
3. Preliminaries
3.1. Channel State Information (CSI)
3.2. Wasserstein Distance
3.3. Correlation Alignment
3.4. Maximum Mean Discrepancy and Its Variants
4. Problem Definition
5. Materials and Methods
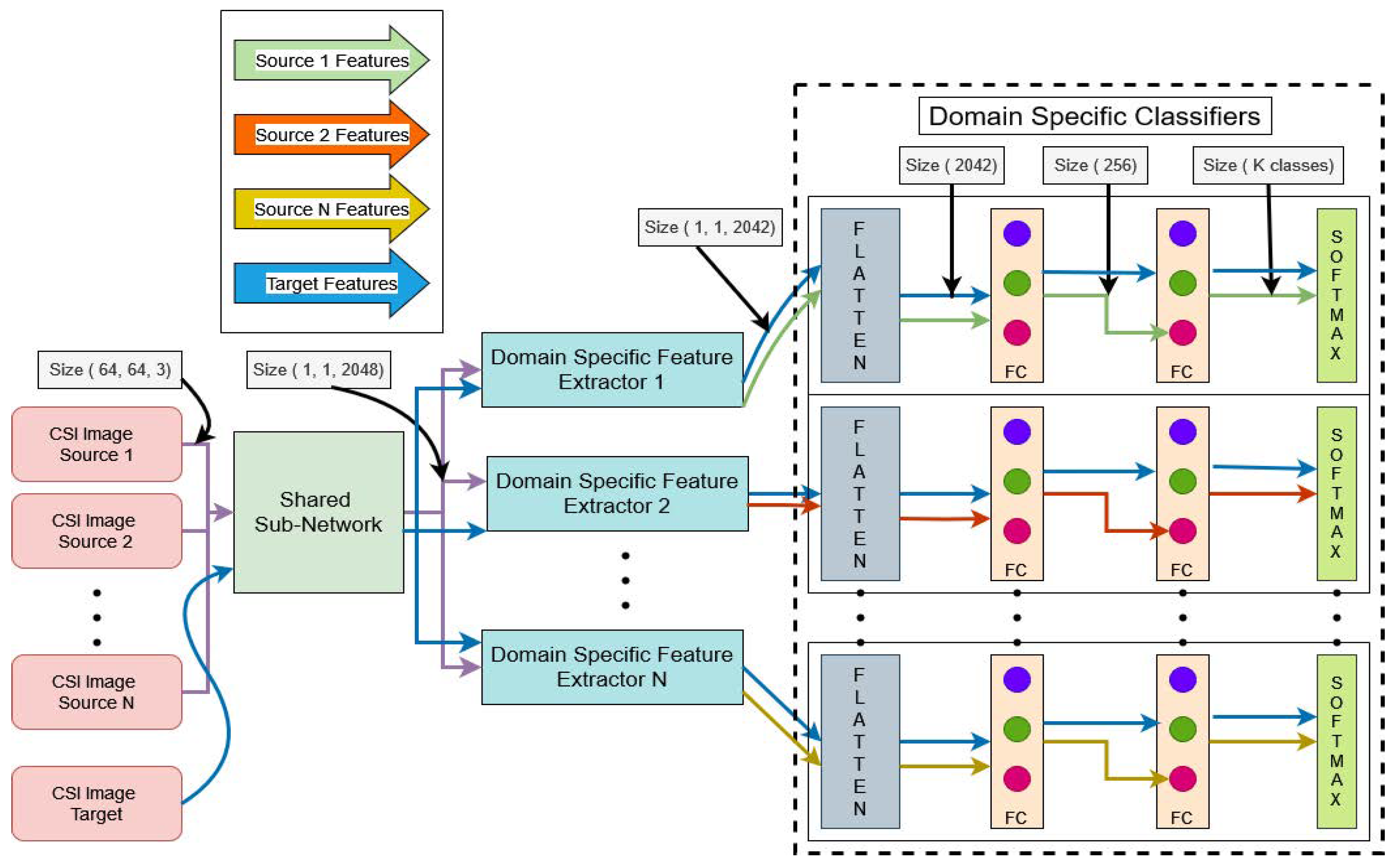
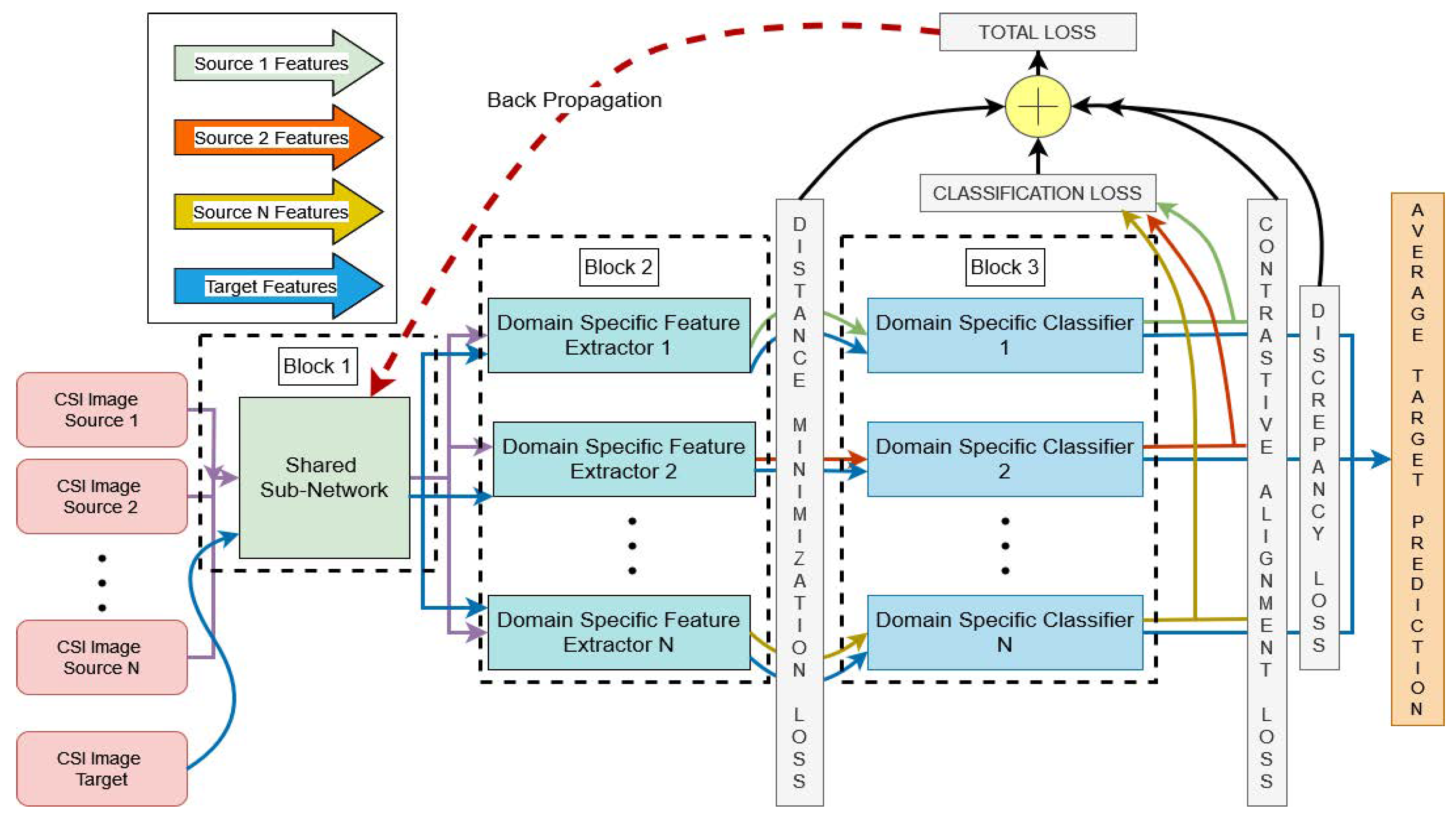
5.1. Proposed Method
5.2. Overview
5.3. Domain Invariant Feature Alignment
5.4. Domain-Specific Feature Alignment
5.5. Domain-Specific Classifier Alignment
5.6. Contrastive Semantic Alignment
| Algorithm 1: Multi-Source M-FUDA Training |
|
 |
6. Experimental Results
6.1. Datasets
6.2. Configuration and Hyperparameter Tuning
6.2.1. Domain-Specific Feature Extractors
6.2.2. Domain-Specific Classifiers
6.2.3. Grid Search for Optimal Configuration
6.2.4. Learning Rate Strategy and Optimization
6.2.5. Optimization Algorithms
- Adaptive Moment Estimation (Adam): Known for its adaptive learning rate capabilities.
- Adaptive Gradient Algorithm (Adagrad): Effective for sparse data scenarios.
- Adam with Weight Decay (AdamW): Combines Adam’s efficiency with weight decay for better regularization.
- Stochastic Gradient Descent (SGD) with momentum (0.9): Provides stability and faster convergence by dampening oscillations.
6.2.6. Early Stopping and Data Splits
6.3. Comparison Techniques and Evaluation Metrics
7. Results and Discussion
7.1. Experiments with Varying Users
7.2. Experiments with Varying Users and Environments
7.3. Experiments with Varying Atmospheric Conditions
7.4. Computational Complexity
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, G.; Lai, A. A Survey on Still Image based Human Action Recognition. Pattern Recognit. 2014, 47, 3343–3361. [Google Scholar] [CrossRef]
- Anuradha, K.; Sairam, N. Spatio-temporal based approaches for human action recognition in static and dynamic background: A survey. Indian J. Sci. Technol. 2016, 9, 1–12. [Google Scholar] [CrossRef]
- Ke, S.R.; Thuc, H.L.U.; Lee, Y.J.; Hwang, J.N.; Yoo, J.H.; Choi, K.H. A review on video-based human activity recognition. Computers 2013, 2, 88–131. [Google Scholar] [CrossRef]
- Hassan, M.M.; Huda, S.; Uddin, M.Z.; Almogren, A.; Alrubaian, M. Human activity recognition from body sensor data using deep learning. J. Med. Syst. 2018, 42, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Webber, M.; Rojas, R.F. Human activity recognition with accelerometer and gyroscope: A data fusion approach. IEEE Sens. J. 2021, 21, 16979–16989. [Google Scholar] [CrossRef]
- Yang, P.; Yang, C.; Lanfranchi, V.; Ciravegna, F. Activity graph based convolutional neural network for human activity recognition using acceleration and gyroscope data. IEEE Trans. Ind. Inform. 2022, 18, 6619–6630. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. ACM Comput. Surv. (CSUR) 2021, 54, 77. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Al-Qaness, M.A.; Abd Elaziz, M.; Kim, S.; Ewees, A.A.; Abbasi, A.A.; Alhaj, Y.A.; Hawbani, A. Channel state information from pure communication to sense and track human motion: A survey. Sensors 2019, 19, 3329. [Google Scholar] [CrossRef]
- Abdelnasser, H.; Harras, K.A.; Youssef, M. UbiBreathe: A ubiquitous non-invasive WiFi-based breathing estimator. In Proceedings of the 16th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Paderborn, Germany, 5–8 July 2015; pp. 277–286. [Google Scholar]
- Wang, P.; Guo, B.; Xin, T.; Wang, Z.; Yu, Z. TinySense: Multi-user respiration detection using Wi-Fi CSI signals. In Proceedings of the 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom), Dalian, China, 12–15 October 2017; pp. 1–6. [Google Scholar]
- Liu, J.; Wang, Y.; Chen, Y.; Yang, J.; Chen, X.; Cheng, J. Tracking vital signs during sleep leveraging off-the-shelf Wi-Fi. In Proceedings of the 16th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Paderborn, Germany, 5–8 July 2015; pp. 267–276. [Google Scholar]
- Boudlal, H.; Serrhini, M.; Tahiri, A. A monitoring system for elderly people using Wi-Fi sensing with channel state information. Int. J. Interact. Mob. Technol. 2023, 17, 112. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, K.; Ni, L.M. Wifall: Device-free fall detection by wireless networks. IEEE Trans. Mob. Comput. 2016, 16, 581–594. [Google Scholar] [CrossRef]
- Chu, Y.; Cumanan, K.; Sankarpandi, S.K.; Smith, S.; Dobre, O.A. Deep learning-based fall detection using Wi-Fi channel state information. IEEE Access 2023, 11, 83763–83780. [Google Scholar] [CrossRef]
- Abdelnasser, H.; Youssef, M.; Harras, K.A. Wigest: A ubiquitous Wi-Fi-based gesture recognition system. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Kowloon, Hong Kong, 26 April–1 May 2015; pp. 1472–1480. [Google Scholar]
- Adib, F.; Katabi, D. See through walls with Wi-Fi! In Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM, Hong Kong, China, 12–16 August 2013; pp. 75–86. [Google Scholar]
- Chen, Y.; Dong, W.; Gao, Y.; Liu, X.; Gu, T. Rapid: A multimodal and device-free approach using noise estimation for robust person identification. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 41. [Google Scholar] [CrossRef]
- Cheng, L.; Wang, J. How can I guard my AP? Non-intrusive user identification for mobile devices using WiFi signals. In Proceedings of the 17th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Paderborn, Germany, 4–8 July 2016; pp. 91–100. [Google Scholar]
- Arshad, S.; Feng, C.; Liu, Y.; Hu, Y.; Yu, R.; Zhou, S.; Li, H. Wi-chase: A WiFi based human activity recognition system for sensorless environments. In Proceedings of the 2017 IEEE 18th International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), Macau, China, 12–15 June 2017; pp. 1–6. [Google Scholar]
- Feng, C.; Arshad, S.; Liu, Y. Mais: Multiple activity identification system using channel state information of wifi signals. In Proceedings of the 12th International Conference on Wireless Algorithms, Systems, and Applications: WASA 2017, Guilin, China, 19–21 June 2017; Proceedings 12. Springer International Publishing: Cham, Switzerland, 2017; pp. 419–432. [Google Scholar]
- Gao, Q.; Wang, J.; Ma, X.; Feng, X.; Wang, H. CSI-based device-free wireless localization and activity recognition using radio image features. IEEE Trans. Veh. Technol. 2017, 66, 10346–10356. [Google Scholar] [CrossRef]
- Won, M.; Zhang, S.; Son, S.H. WiTraffic: Low-cost and non-intrusive traffic monitoring system using Wi-Fi. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–9. [Google Scholar]
- Zhu, Y.; Yao, Y.; Zhao, B.Y.; Zheng, H. Object recognition and navigation using a single networking device. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, Niagara Falls, NY, USA, 19–23 June 2017; pp. 265–277. [Google Scholar]
- Zhang, X.; Ruby, R.; Long, J.; Wang, L.; Ming, Z.; Wu, K. WiHumidity: A novel CSI-based humidity measurement system. In Proceedings of the First International Conference on Smart Computing and Communication: SmartCom 2016, Shenzhen, China, 17–19 December 2017; Proceedings 1. Springer International Publishing: Cham, Switzerland, 2017; pp. 537–547. [Google Scholar]
- Zinys, A.; van Berlo, B.; Meratnia, N. A domain-independent generative adversarial network for activity recognition using WiFi CSI data. Sensors 2021, 21, 7852. [Google Scholar] [CrossRef] [PubMed]
- Tse, D.; Viswanath, P. Fundamentals of Wireless Communication; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Kumar, R.; Sinwar, D.; Singh, V. Analysis of QoS aware traffic template in n78 band using proportional fair scheduling in 5G NR. Telecommun. Syst. 2024, 87, 17–32. [Google Scholar] [CrossRef]
- Chen, C.; Zhou, G.; Lin, Y. Cross-domain Wi-Fi sensing with channel state information: A survey. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar]
- Shi, Z.; Zhang, J.A.; Xu, R.; Cheng, Q.; Pearce, A. Towards environment-independent human activity recognition using deep learning and enhanced CSI. In Proceedings of the GLOBECOM 2020-2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Wang, X.; Yang, C.; Mao, S. Resilient respiration rate monitoring with realtime bimodal CSI data. IEEE Sens. J. 2020, 20, 10187–10198. [Google Scholar] [CrossRef]
- Ma, Y.; Zhou, G.; Wang, S. Wi-Fi sensing with channel state information: A survey. ACM Comput. Surv. (CSUR) 2019, 52, 46. [Google Scholar]
- Huang, J.; Liu, B.; Chen, C.; Jin, H.; Liu, Z.; Zhang, C.; Yu, N. Towards anti-interference human activity recognition based on Wi-Fi subcarrier correlation selection. IEEE Trans. Veh. Technol. 2020, 69, 6739–6754. [Google Scholar] [CrossRef]
- Ahmed, H.F.T.; Ahmad, H.; Aravind, C.V. Device free human gesture recognition using Wi-Fi CSI: A survey. Eng. Appl. Artif. Intell. 2020, 87, 103281. [Google Scholar] [CrossRef]
- Shalaby, E.; ElShennawy, N.; Sarhan, A. Utilizing deep learning models in CSI-based human activity recognition. Neural Comput. Appl. 2022, 34, 5993–6010. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. Wi-Fi CSI based passive human activity recognition using attention based BLSTM. IEEE Trans. Mob. Comput. 2018, 18, 2714–2724. [Google Scholar] [CrossRef]
- Khan, D.A.; Razak, S.; Raj, B.; Singh, R. Human behaviour recognition using Wi-Fi channel state information. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7625–7629. [Google Scholar]
- Zhuravchak, A.; Kapshii, O.; Pournaras, E. Human activity recognition based on Wi-Fi CSI data- A deep neural network approach. Procedia Comput. Sci. 2022, 198, 59–66. [Google Scholar] [CrossRef]
- Zou, H.; Yang, J.; Zhou, Y.; Spanos, C.J. Joint adversarial domain adaptation for resilient WiFi-enabled device-free gesture recognition. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 202–207. [Google Scholar]
- Brinke, J.K.; Meratnia, N. Scaling activity recognition using channel state information through convolutional neural networks and transfer learning. In Proceedings of the First International Workshop on Challenges in Artificial Intelligence and Machine Learning for Internet of Things, New York, NY, USA, 10–13 November 2019; pp. 56–62. [Google Scholar]
- Yin, G.; Zhang, J.; Shen, G.; Chen, Y. FewSense, towards a scalable and cross-domain Wi-Fi sensing system using few-shot learning. IEEE Trans. Mob. Comput. 2022, 23, 453–468. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 63. [Google Scholar] [CrossRef]
- Song, Y.; Wang, T.; Cai, P.; Mondal, S.K.; Sahoo, J.P. A comprehensive survey of few-shot learning: Evolution, applications, challenges, and opportunities. ACM Comput. Surv. 2023, 55, 1–40. [Google Scholar] [CrossRef]
- Hu, P.; Tang, C.; Yin, K.; Zhang, X. Wigr: A practical Wi-Fi-based gesture recognition system with a lightweight few-shot network. Appl. Sci. 2021, 11, 3329. [Google Scholar] [CrossRef]
- Ma, X.; Zhao, Y.; Zhang, L.; Gao, Q.; Pan, M.; Wang, J. Practical device-free gesture recognition using Wi-Fi signals based on metalearning. IEEE Trans. Ind. Inform. 2019, 16, 228–237. [Google Scholar] [CrossRef]
- Moshiri, P.F.; Nabati, M.; Shahbazian, R.; Ghorashi, S.A. CSI-based human activity recognition using convolutional neural networks. In Proceedings of the 2021 11th International Conference on Computer Engineering and Knowledge (ICCKE), Mashhad, Iran, 28–29 October 2021; pp. 7–12. [Google Scholar]
- Yousefi, S.; Narui, H.; Dayal, S.; Ermon, S.; Valaee, S. A survey on behavior recognition using Wi-Fi channel state information. IEEE Commun. Mag. 2017, 55, 98–104. [Google Scholar] [CrossRef]
- Moshiri, P.F.; Shahbazian, R.; Nabati, M.; Ghorashi, S.A. A CSI-based human activity recognition using deep learning. Sensors 2021, 21, 7225. [Google Scholar] [CrossRef]
- Hassan, M.; Kelsey, T.; Rahman, F. Adversarial AI applied to cross-user inter-domain and intra-domain adaptation in human activity recognition using wireless signals. PLoS ONE 2024, 19, e0298888. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Jiao, W. Imgfi: A high accuracy and lightweight human activity recognition framework using CSI image. IEEE Sens. J. 2023, 23, 21966–21977. [Google Scholar] [CrossRef]
- Wang, Z.; Oates, T. Imaging time-series to improve classification and imputation. arXiv 2015, arXiv:1506.00327. [Google Scholar]
- Eckmann, J.P.; Kamphorst, S.O.; Ruelle, D. Recurrence plots of dynamical systems. World Sci. Ser. Nonlinear Sci. Ser. A 1995, 16, 441–446. [Google Scholar]
- Lee, H.; Ahn, C.R.; Choi, N. Fine-grained occupant activity monitoring with Wi-Fi channel state information: Practical implementation of multiple receiver settings. Adv. Eng. Inform. 2020, 46, 101147. [Google Scholar] [CrossRef]
- Sharma, L.; Chao, C.H.; Wu, S.L.; Li, M.C. High accuracy Wi-Fi-based human activity classification system with time-frequency diagram CNN method for different places. Sensors 2021, 21, 3797. [Google Scholar] [CrossRef]
- Sundararajan, D. Discrete Wavelet Transform: A Signal Processing Approach; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Gray, R.M.; Goodman, J.W. Fourier Transforms: An Introduction for Engineers; Springer Science+Business Media: New York, NY, USA, 2012; Volume 322. [Google Scholar]
- Anand, R.; Shanthi, T.; Nithish, M.S.; Lakshman, S. Face recognition and classification using GoogleNET architecture. Soft Comput. Probl. Solving 2018, 1, 261–269. [Google Scholar]
- Zhang, H.; Zhou, Z.; Gong, W. Wi-adaptor: Fine-grained domain adaptation in Wi-Fi-based activity recognition. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Chen, X.; Li, H.; Zhou, C.; Liu, X.; Wu, D.; Dudek, G. Fidora: Robust WiFi-based indoor localization via unsupervised domain adaptation. IEEE Internet Things J. 2022, 9, 9872–9888. [Google Scholar] [CrossRef]
- Yang, J.; Chen, X.; Zou, H.; Wang, D.; Xie, L. Autofi: Toward automatic Wi-Fi human sensing via geometric self-supervised learning. IEEE Internet Things J. 2022, 10, 7416–7425. [Google Scholar] [CrossRef]
- Chen, X.; Li, H.; Zhou, C.; Liu, X.; Wu, D.; Dudek, G. Fido: Ubiquitous fine-grained Wi-Fi based localization for unlabeled users via domain adaptation. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 23–33. [Google Scholar]
- Al-qaness, M.A.A.; Li, F. WiGeR: WiFi-based gesture recognition system. ISPRS Int. J. Geo-Inf. 2016, 5, 92. [Google Scholar] [CrossRef]
- Tian, Z.; Wang, J.; Yang, X.; Zhou, M. WiCatch: A Wi-Fi based hand gesture recognition system. IEEE Access 2018, 6, 16911–16923. [Google Scholar] [CrossRef]
- Ma, Y.; Zhou, G.; Wang, S.; Zhao, H.; Jung, W. SignFi: Sign language recognition using Wi-Fi. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–21. [Google Scholar] [CrossRef]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. ICML Deep Learn. Workshop 2015, 2, 1–30. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, D. Aligning domain-specific distribution and classifier for cross-domain classification from multiple sources. Proc. AAAI Conf. Artif. Intell. 2019, 33, 5989–5996. [Google Scholar] [CrossRef]
- Xu, R.; Chen, Z.; Zuo, W.; Yan, J.; Lin, L. Deep cocktail network: Multi-source unsupervised domain adaptation with category shift. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3964–3973. [Google Scholar]
- Kolouri, S.; Nadjahi, K.; Simsekli, U.; Badeau, R.; Rohde, G. Generalized sliced Wasserstein distances. Adv. Neural Inf. Process. Syst. 2019, 32, 261–272. [Google Scholar]
- Courty, N.; Flamary, R.; Tuia, D.; Rakotomamonjy, A. Optimal transport for domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1853–1865. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10, 15–16 October 2016; Proceedings, Part III 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 443–450. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. Proc. AAAI Conf. Artif. Intell. 2016, 30, 10306. [Google Scholar] [CrossRef]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Li, X.; Yuan, P.; Su, K.; Li, D.; Xie, Z.; Kong, X. Innovative integration of multi-scale residual networks and MK-MMD for enhanced feature representation in fault diagnosis. Meas. Sci. Technol. 2024, 35, 086108. [Google Scholar] [CrossRef]
- Xia, P.; Niu, H.; Li, Z.; Li, B. Enhancing backdoor attacks with multi-level MMD regularization. IEEE Trans. Dependable Secur. Comput. 2022, 20, 1675–1686. [Google Scholar] [CrossRef]
- Wang, W.; Li, B.; Yang, S.; Sun, J.; Ding, Z.; Chen, J.; Dong, X.; Wang, Z.; Li, H. A unified joint maximum mean discrepancy for domain adaptation. arXiv 2021, arXiv:2101.09979. [Google Scholar]
- Motiian, S.; Piccirilli, M.; Adjeroh, D.A.; Doretto, G. Unified deep supervised domain adaptation and generalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5715–5725. [Google Scholar]
- Zhang, J.; Tang, Z.; Li, M.; Fang, D.; Nurmi, P.; Wang, Z. CrossSense: Towards cross-site and large-scale Wi-Fi sensing. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 305–320. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Baha’A, A.; Almazari, M.M.; Alazrai, R.; Daoud, M.I. A dataset for Wi-Fi-based human activity recognition in line-of-sight and non-line-of-sight indoor environments. Data Brief 2020, 33, 106534. [Google Scholar]
- Gringoli, F.; Schulz, M.; Link, J.; Hollick, M. Free your CSI: A channel state information extraction platform for modern Wi-Fi chipsets. In Proceedings of the 13th International Workshop on Wireless Network Testbeds, Experimental Evaluation & Characterization, Los Cabos, Mexico, 25 October 2019; pp. 21–28. [Google Scholar]
- Portnoff, M. Time-frequency representation of digital signals and systems based on short-time Fourier analysis. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 55–69. [Google Scholar] [CrossRef]
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Tool release: Gathering 802.11 n traces with channel state information. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 53. [Google Scholar] [CrossRef]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3723–3732. [Google Scholar]
- Han, Y.; Liu, X.; Sheng, Z.; Ren, Y.; Han, X.; You, J.; Liu, R.; Luo, Z. Wasserstein loss-based deep object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 998–999. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | No. of Features | No. of Samples | Antenna Pairs | No. of Users | No. of Environments | Atmospheric Impacts | Activities |
|---|---|---|---|---|---|---|---|
| Parisafm | 52 | 420 | 1 | 3 | 1 | Disregarded | (0) bending, (1) falling, (2) lie down, (3) running, (4) sit down, (5) stand up, and (6) walking |
| Alsaify | 90 | 3240 | 3 | 6 | 3 | Disregarded | (0) sit still on a chair, (1) falling down, (2) lie down, (3) stand still, (4) walking from the transmitter to the receiver, and (5) pick a pen from the ground |
| Brinke and Meratnia | 270 | 5400 | 6 | 2 | 1 | Considered | (0) clapping, (1) falling, (2) nothing, (3) walking |
| Micro-F1 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Source Domains | Target Domain | Proposed Methods | ||||||
| Variants of Multi-Source M-FUDA | ||||||||
| Sourrce 1 | Source 2 | Source 3 | Target 1 | (Disc) | (Disc + CCSA) | (Disc + CCSA + JMMD) | (Disc + CCSA + MK-MMD) | (Disc + CCSA + MMD) |
| S1 | S2 | S1 + S2 | S3 | 0.74 | 0.85 | 0.69 | 0.86 | 0.86 |
| S2 | S3 | S2 + S3 | S1 | 0.62 | 0.67 | 0.67 | 0.83 | 0.73 |
| S1 | S3 | S1 + S3 | S2 | 0.75 | 0.84 | 0.69 | 0.79 | 0.84 |
| Average | 0.70 | 0.78 | 0.68 | 0.83 | 0.81 | |||
| Macro-F1 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Source Domains | Target Domain | Proposed Methods | ||||||
| Variants of Multi-Source M-FUDA | ||||||||
| Sourrce 1 | Source 2 | Source 3 | Target 1 | (Disc) | (Disc + CCSA) | (Disc + CCSA + JMMD) | (Disc + CCSA + MK-MMD) | (Disc + CCSA + MMD) |
| S1 | S2 | S1 + S2 | S3 | 0.73 | 0.81 | 0.66 | 0.86 | 0.83 |
| S2 | S3 | S2 + S3 | S1 | 0.61 | 0.65 | 0.66 | 0.82 | 0.74 |
| S1 | S3 | S1 + S3 | S2 | 0.75 | 0.83 | 0.70 | 0.80 | 0.85 |
| Average | 0.69 | 0.76 | 0.67 | 0.83 | 0.81 | |||
| Micro-F1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Source Domains | Target Domain | Proposed Multi-Source Models | Combined-Source Models | ||||||
| Source 1 | Source 2 | Source 3 | Target 1 | M-FUDA (MMD) | M-FUDA (MK-MMD) | M-FUDA (MMD) | CORAL [72] | Wasserstein [89] | MCD [59,88] |
| S1 | S2 | S1 + S2 | S3 | 0.86 | 0.86 | 0.81 | 0.83 | 0.83 | 0.78 |
| S2 | S3 | S2 + S3 | S1 | 0.73 | 0.83 | 0.64 | 0.62 | 0.62 | 0.59 |
| S1 | S3 | S1 + S3 | S2 | 0.84 | 0.79 | 0.88 | 0.66 | 0.66 | 0.77 |
| Average | 0.81 | 0.83 | 0.78 | 0.70 | 0.70 | 0.71 | |||
| Macro-F1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Source Domains | Target Domain | Proposed Multi-Source Models | Combined-Source Models | ||||||
| Source 1 | Source 2 | Source 3 | Target 1 | M-FUDA (MMD) | M-FUDA (MK-MMD) | M-FUDA (MMD) | CORAL [72] | Wasserstein [89] | MCD [59,88] |
| S1 | S2 | S1 + S2 | S3 | 0.83 | 0.86 | 0.78 | 0.81 | 0.82 | 0.76 |
| S2 | S3 | S2 + S3 | S1 | 0.74 | 0.82 | 0.66 | 0.63 | 0.59 | 0.59 |
| S1 | S3 | S1 + S3 | S2 | 0.85 | 0.80 | 0.88 | 0.69 | 0.69 | 0.74 |
| Average | 0.81 | 0.83 | 0.77 | 0.71 | 0.70 | 0.70 | |||
| Micro-F1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Source Domains | Target Domain | Proposed Multi-Source Models | Combined-Source Models | ||||||
| Source 1 | Source 2 | Source 3 | Target 1 | M-FUDA (MMD) | M-FUDA (MK-MMD) | M-FUDA (MMD) | CORAL [72] | Wasserstein [89] | MCD [59,88] |
| E1(S1) | E1(S2) | E1(S3) | E2(S12) | 0.69 | 0.65 | 0.67 | 0.62 | 0.62 | 0.67 |
| E1(S1) | E1 (S2) | E1(S3) | E3(S21) | 0.72 | 0.74 | 0.72 | 0.70 | 0.69 | 0.75 |
| E2(S11) | E2(S12) | E2(S13) | E1(S3) | 0.71 | 0.69 | 0.57 | 0.53 | 0.50 | 0.59 |
| E2(S11) | E2(S12) | E2(S13) | E3(S21) | 0.81 | 0.81 | 0.73 | 0.68 | 0.63 | 0.71 |
| E2(S11) | E2(S12) | E2(S13) | E3(S23) | 0.81 | 0.77 | 0.73 | 0.7 | 0.68 | 0.74 |
| E3(S21) | E3(S22) | E3(S23) | E1(S1) | 0.74 | 0.68 | 0.69 | 0.64 | 0.63 | 0.80 |
| E3(S21) | E3(S22) | E3(S23) | E1(S2) | 0.90 | 0.88 | 0.84 | 0.75 | 0.72 | 0.85 |
| E3(S21) | E3(S22) | E3(S23) | E1(S3) | 0.72 | 0.74 | 0.71 | 0.68 | 0.65 | 0.73 |
| E3(S21) | E3(S22) | E3(S23) | E2(S11) | 0.70 | 0.71 | 0.67 | 0.72 | 0.71 | 0.74 |
| E3(S21) | E3(S22) | E3(S23) | E2(S12) | 0.80 | 0.79 | 0.77 | 0.66 | 0.60 | 0.75 |
| E3(S21) | E3(S22) | E3(S23) | E2(S13) | 0.73 | 0.70 | 0.71 | 0.65 | 0.62 | 0.70 |
| Average | 0.76 | 0.74 | 0.71 | 0.67 | 0.64 | 0.73 | |||
| Macro-F1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Source Domains | Target Domain | Proposed Multi-Source Models | Combined-Source Models | ||||||
| Source 1 | Source 2 | Source 3 | Target 1 | M-FUDA (MMD) | M-FUDA (MK-MMD) | M-FUDA (MMD) | CORAL [72] | Wasserstein [89] | MCD [59,88] |
| E1(S1) | E1(S2) | E1(S3) | E2(S12) | 0.70 | 0.67 | 0.67 | 0.63 | 0.61 | 0.68 |
| E1(S1) | E1 (S2) | E1(S3) | E3(S21) | 0.68 | 0.71 | 0.72 | 0.69 | 0.68 | 0.74 |
| E2(S11) | E2(S12) | E2(S13) | E1(S3) | 0.68 | 0.65 | 0.54 | 0.52 | 0.50 | 0.55 |
| E2(S11) | E2(S12) | E2(S13) | E3(S21) | 0.81 | 0.81 | 0.73 | 0.69 | 0.62 | 0.70 |
| E2(S11) | E2(S12) | E2(S13) | E3(S23) | 0.81 | 0.78 | 0.74 | 0.7 | 0.67 | 0.73 |
| E3(S21) | E3(S22) | E3(S23) | E1(S1) | 0.72 | 0.66 | 0.66 | 0.62 | 0.61 | 0.78 |
| E3(S21) | E3(S22) | E3(S23) | E1(S2) | 0.90 | 0.86 | 0.83 | 0.75 | 0.73 | 0.85 |
| E3(S21) | E3(S22) | E3(S23) | E1(S3) | 0.69 | 0.72 | 0.68 | 0.67 | 0.64 | 0.71 |
| E3(S21) | E3(S22) | E3(S23) | E2(S11) | 0.71 | 0.72 | 0.68 | 0.72 | 0.70 | 0.75 |
| E3(S21) | E3(S22) | E3(S23) | E2(S12) | 0.81 | 0.79 | 0.78 | 0.65 | 0.59 | 0.76 |
| E3(S21) | E3(S22) | E3(S23) | E2(S13) | 0.75 | 0.72 | 0.72 | 0.64 | 0.62 | 0.71 |
| Average | 0.75 | 0.74 | 0.70 | 0.66 | 0.63 | 0.72 | |||
| Micro-F1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Source Domains | Target Domain | Proposed Multi-Source Models | Combined-Source Models | ||||||
| Source 1 | Source 2 | Source 3 | Target 1 | M-FUDA (MMD) | M-FUDA (MK-MMD) | M-FUDA (MMD) | CORAL [72] | Wasserstein [89] | MCD [59,88] |
| D6(S1) | D7(S1) | D8(S2) | D8(S1) | 0.70 | 0.68 | 0.69 | 0.57 | 0.58 | 0.68 |
| D7(S1) | D8(S1) | D6(S2) | D6(S1) | 0.78 | 0.75 | 0.80 | 0.71 | 0.68 | 0.89 |
| D6(S1) | D8(S1) | D7(S2) | D7(S1) | 0.76 | 0.73 | 0.75 | 0.68 | 0.66 | 0.70 |
| D6(S2) | D7(S2) | D8(S1) | D8(S2) | 0.67 | 0.66 | 0.63 | 0.58 | 0.60 | 0.62 |
| D7(S2) | D8(S2) | D6(S1) | D6(S2) | 0.74 | 0.67 | 0.74 | 0.67 | 0.65 | 0.73 |
| D6(S2) | D8(S2) | D7(S1) | D7(S2) | 0.75 | 0.72 | 0.73 | 0.69 | 0.67 | 0.72 |
| Average | 0.73 | 0.70 | 0.72 | 0.65 | 0.64 | 0.72 | |||
| Macro-F1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Source Domains | Target Domain | Proposed Multi-Source Models | Combined-Source Models | ||||||
| Source 1 | Source 2 | Source 3 | Target 1 | M-FUDA (MMD) | M-FUDA (MK-MMD) | M-FUDA (MMD) | CORAL [72] | Wasserstein [89] | MCD [59,88] |
| D6(S1) | D7(S1) | D8(S2) | D8(S1) | 0.70 | 0.67 | 0.68 | 0.56 | 0.57 | 0.68 |
| D7(S1) | D8(S1) | D6(S2) | D6(S1) | 0.78 | 0.75 | 0.80 | 0.69 | 0.67 | 0.89 |
| D6(S1) | D8(S1) | D7(S2) | D7(S1) | 0.76 | 0.72 | 0.75 | 0.68 | 0.66 | 0.70 |
| D6(S2) | D7(S2) | D8(S1) | D8(S2) | 0.67 | 0.64 | 0.62 | 0.58 | 0.60 | 0.62 |
| D7(S2) | D8(S2) | D6(S1) | D6(S2) | 0.74 | 0.67 | 0.74 | 0.68 | 0.65 | 0.72 |
| D6(S2) | D8(S2) | D7(S1) | D7(S2) | 0.74 | 0.71 | 0.73 | 0.67 | 0.66 | 0.72 |
| Average | 0.73 | 0.70 | 0.72 | 0.64 | 0.64 | 0.72 | |||
| Training Time (seconds) | ||||||
|---|---|---|---|---|---|---|
| Cross-Domain Tasks | Proposed Multi-Source Models | Combined-Source Models | ||||
| M-FUDA (MMD) | M-FUDA (MK-MMD) | M-FUDA (MMD) | CORAL [72] | Wasserstein [89] | MCD [59,88] | |
| Cross-User | 521.97 | 632.49 | 370.29 | 324.26 | 312.34 | 353.91 |
| Cross-User + Cross-Environment | 504.23 | 615.13 | 430.47 | 409.12 | 395.56 | 426.89 |
| Cross-Atmospheric | 441.38 | 532.65 | 367.98 | 347.36 | 325.14 | 320.91 |
| Average | 489.19 | 593.42 | 389.58 | 360.25 | 344.35 | 367.24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, M.; Kelsey, T. Multi-Feature Unsupervised Domain Adaptation (M-FUDA) Applied to Cross Unaligned Domain-Specific Distributions in Device-Free Human Activity Classification. Sensors 2025, 25, 1876. https://doi.org/10.3390/s25061876
Hassan M, Kelsey T. Multi-Feature Unsupervised Domain Adaptation (M-FUDA) Applied to Cross Unaligned Domain-Specific Distributions in Device-Free Human Activity Classification. Sensors. 2025; 25(6):1876. https://doi.org/10.3390/s25061876
Chicago/Turabian StyleHassan, Muhammad, and Tom Kelsey. 2025. "Multi-Feature Unsupervised Domain Adaptation (M-FUDA) Applied to Cross Unaligned Domain-Specific Distributions in Device-Free Human Activity Classification" Sensors 25, no. 6: 1876. https://doi.org/10.3390/s25061876
APA StyleHassan, M., & Kelsey, T. (2025). Multi-Feature Unsupervised Domain Adaptation (M-FUDA) Applied to Cross Unaligned Domain-Specific Distributions in Device-Free Human Activity Classification. Sensors, 25(6), 1876. https://doi.org/10.3390/s25061876