
An Adaptive Obstacle Avoidance Model for Autonomous Robots Based on Dual-Coupling Grouped Aggregation and Transformer Optimization


Abstract
1. Introduction
- (1)
- Transformer-based dual-coupling grouped aggregation strategy:
- (2)
- Harris hawk optimization for enhanced transformer framework
- (3)
- Intelligent obstacle avoidance in 3D real-world scenarios:
2. Related Work
- (1)
- Vision-Based Transformer Applications in Obstacle Avoidance
- (2)
- Grouped Aggregation Strategy in Robotic Object Detection
- (3)
- Metaheuristic Optimization for Transformer Frameworks
- (4)
- The Application of the APF Method in Obstacle Avoidance
- (5)
- Simulation Platforms for Robotic Obstacle Avoidance Validation
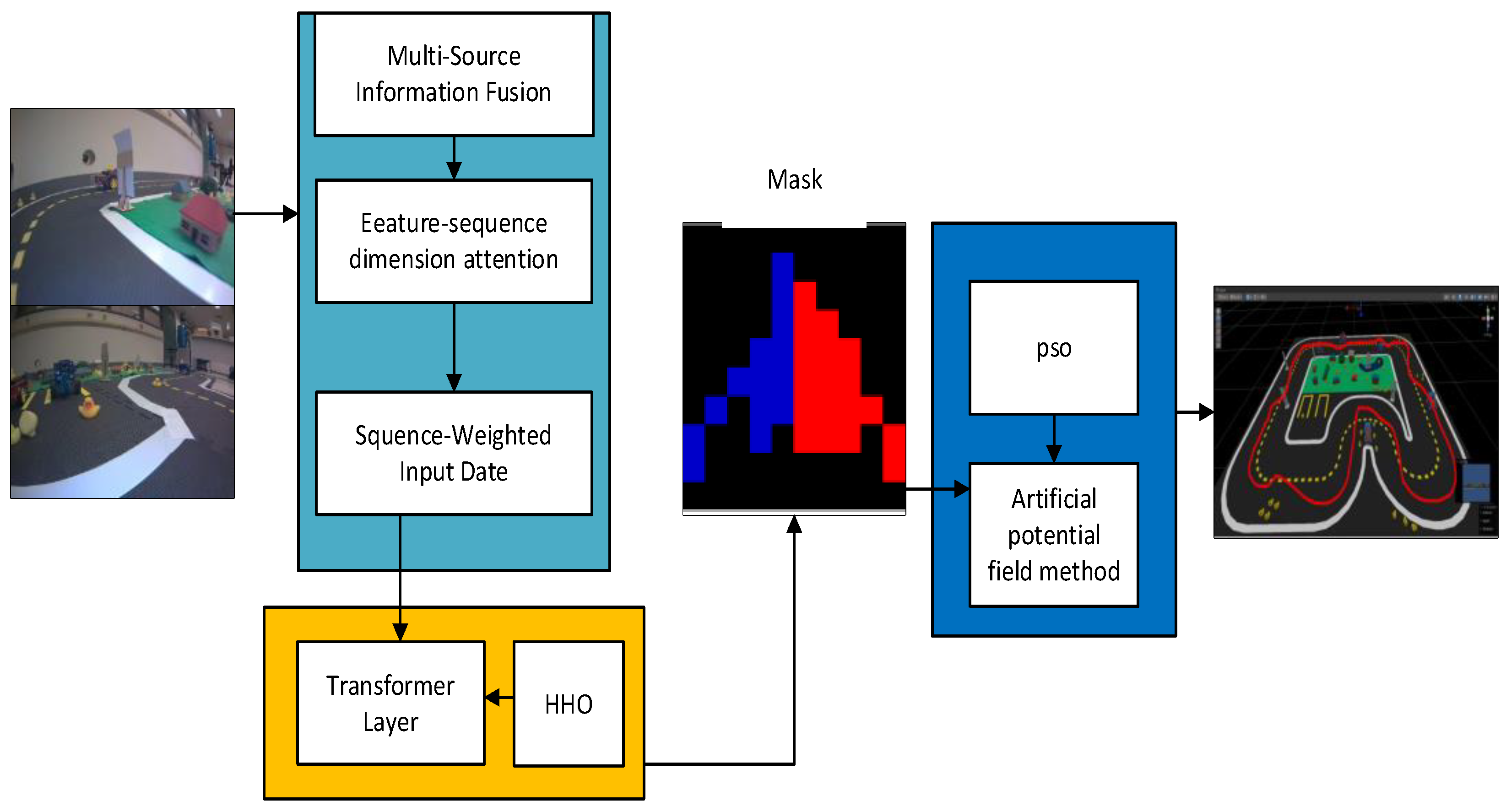
3. Methods
- (1)
- Data collection:
- (2)
- Image segmentation using GAS-H-Trans:
- (3)
- Obstacle avoidance execution:
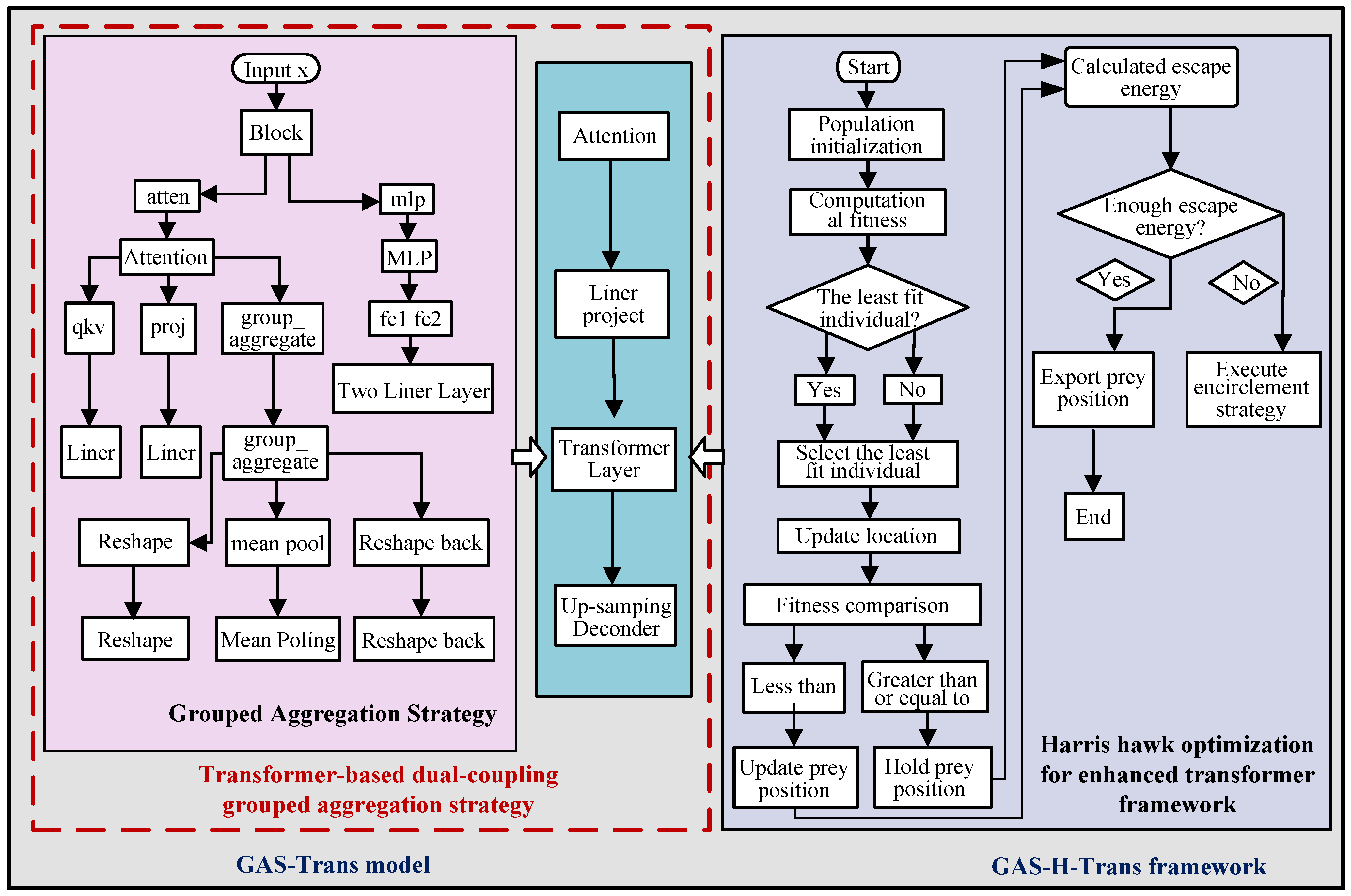
3.1. Overview of GAS-H-Trans Model
3.2. GAS-Trans Model
- Step 1: Attention Mechanism with Grouped Aggregation
- Step 2: Transformer Layers for Segmentation
- Step 3: Output Processing
3.3. HHO-Optimized GAS-H-Trans Model
| Algorithm 1 GAS-H-Trans Algorithm |
| 1. Input: X (a tensor with shape (batch_size, channels, height, width)) 2. Output: Y (the segmentation mask tensor with shape (batch_size, num_classes, height, width)) 3. Start 4. Initialize model parameters: patch_size, embed_dim, num_heads, num_classes, depth (to be optimized), group_size 5. Initialize HHO parameters: hho_iter, hho_pop_size, hho_alpha, hho_beta, hho_gamma 6. Initialize the population of Harris Hawks with random solutions for depth. 7. Evaluate the fitness of each Harris Hawk in the population. 8. While not converged and iteration < hho_iter do For each Harris Hawk in the population do Update the Harris Hawk’s position Update the Harris Hawk’s leader position Update the step size for each Harris Hawk Evaluate the new fitness scores for the updated positions Update the best solution found so far Select the best depth value for the VisionTransformer model. Create PatchEmbed module to embed the image patches into a higher dimension. Initialize the classification token and position encoding. 9. Create the VisionTransformer model with the optimized depth. 10. Preprocess the input image X: - x = transformer.patch_embed(X) # Embed the image patches - x = transformer.prepare_tokens(x) # Add classification token and position encoding 11. Forward pass through the VisionTransformer model: - For each block in the transformer: - Apply multi-head attention (Equation (2)): - Compute queries (Q), keys (K), and values (V): - Q, K, V = self.norm1(x) # Learnable weight matrices as in Equation (3) - Compute attention outputs for each head: - For each head i: - head_i = Attention(Q, K, V) # Equation (3) - Combine multi-head outputs: - attention = Concat(head_1, head_2, …, head_h) W^O # Equation (2) - Apply MLP to further process features (Equation (4)): - mlp_output = GELU(X W_1 + b_1) W_2 + b_2 - Add residual connections and layer normalization (Equations (5) and (6)): - residual = x + Dropout(attention) - z = LayerNorm(residual) - residual = z + Dropout(mlp_output) - z = LayerNorm(residual) - Perform group aggregation with probability group_aggregate_prob (Equation (1)): - Calculate number of patches per group: per_group = int(sqrt(num_patches/(group_size^2))) - Reshape x for group aggregation: x_reshaped = x.view(batch_size, group_size, group_size, per_group, per_group, embed_dim) - Perform aggregation operation: x = mean(x_reshaped) # Equation (1) 12. Apply the classification head to obtain the segmentation mask: - y = transformer.head(z) 13. If necessary, upsample the segmentation mask to match the original image size: - y = upsample(y, original_height, original_width) 14. Return the segmentation mask Y 15. End |
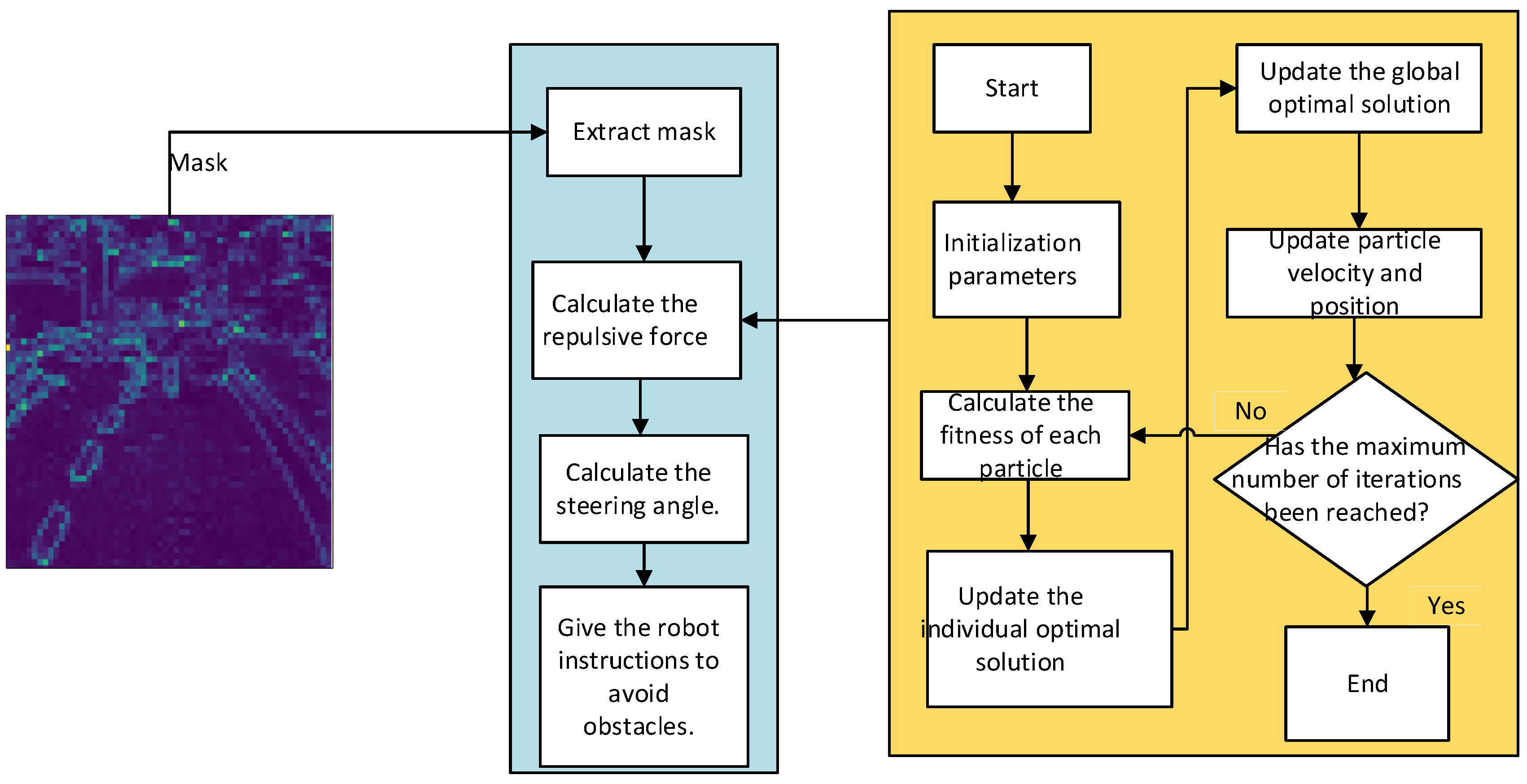
3.4. PSO-Optimized Artificial Potential Field
| Algorithm 2 PSO Optimized Artificial Potential Field for Robot Navigation |
| 1. Input: pred (2D array): Segmentation map with shape (height, width) robot_position (array): Initial position of the robot [x, y] target_position (array): Target position [x, y] 2. Output: trajectory (list of arrays): Path taken by the robot to reach the target 3. Start 4. Initialize parameters: attractive_weight (float): Weight for the attractive field repulsive_weight (float): Weight for the repulsive field repulsive_range (int): Range of the repulsive field num_particles (int): Number of particles in PSO num_iterations (int): Number of iterations in PSO w (float): Inertia weight in PSO c1 (float): Cognitive (individual) learning factor in PSO c2 (float): Social (global) learning factor in PSO 5. Define attractive_field(robot_pos, target_pos): Return attractive_weight * (target_pos robot_pos) 6. Define repulsive_field_pso(robot_pos, obstacle_map, repulsive_range, num_particles, num_iterations, w, c1, c2): Initialize particles and velocities Evaluate the initial fitness of particles For iteration = 1 to num_iterations: For each particle: Calculate repulsive force Evaluate fitness score Update personal best position and score Update global best position and score Update velocities and positions of particles Return global best position as an optimized repulsive force 7. Define artificial_potential_field(robot_pos, target_pos, obstacle_map, repulsive_range, num_particles, num_iterations, w, c1, c2): Calculate attractive force Calculate repulsive force using PSO Return total force (attractive + repulsive) 8. Define simulate_robot_motion(robot_pos, target_pos, obstacle_map, repulsive_range, num_particles, num_iterations, w, c1, c2, steps): Initialize trajectory with robot_pos For step = 1 to steps: Calculate total force Update robot position Append new position to trajectory If robot reaches target, break Return trajectory 9. Main program: Call simulate_robot_motion to get trajectory 10. Visualization: Plot segmentation map Plot trajectory Mark target and start positions 11. End |
3.5. Evaluation Metrics
- (1)
- Evaluation Metrics for the Performance of the GAS-H-Trans Model
- (2)
- Obstacle Avoidance Success Rate
4. Results
4.1. Dataset Description
4.1.1. Duckiebot Dataset
4.1.2. KITTI Dataset
4.1.3. ImageNet Dataset
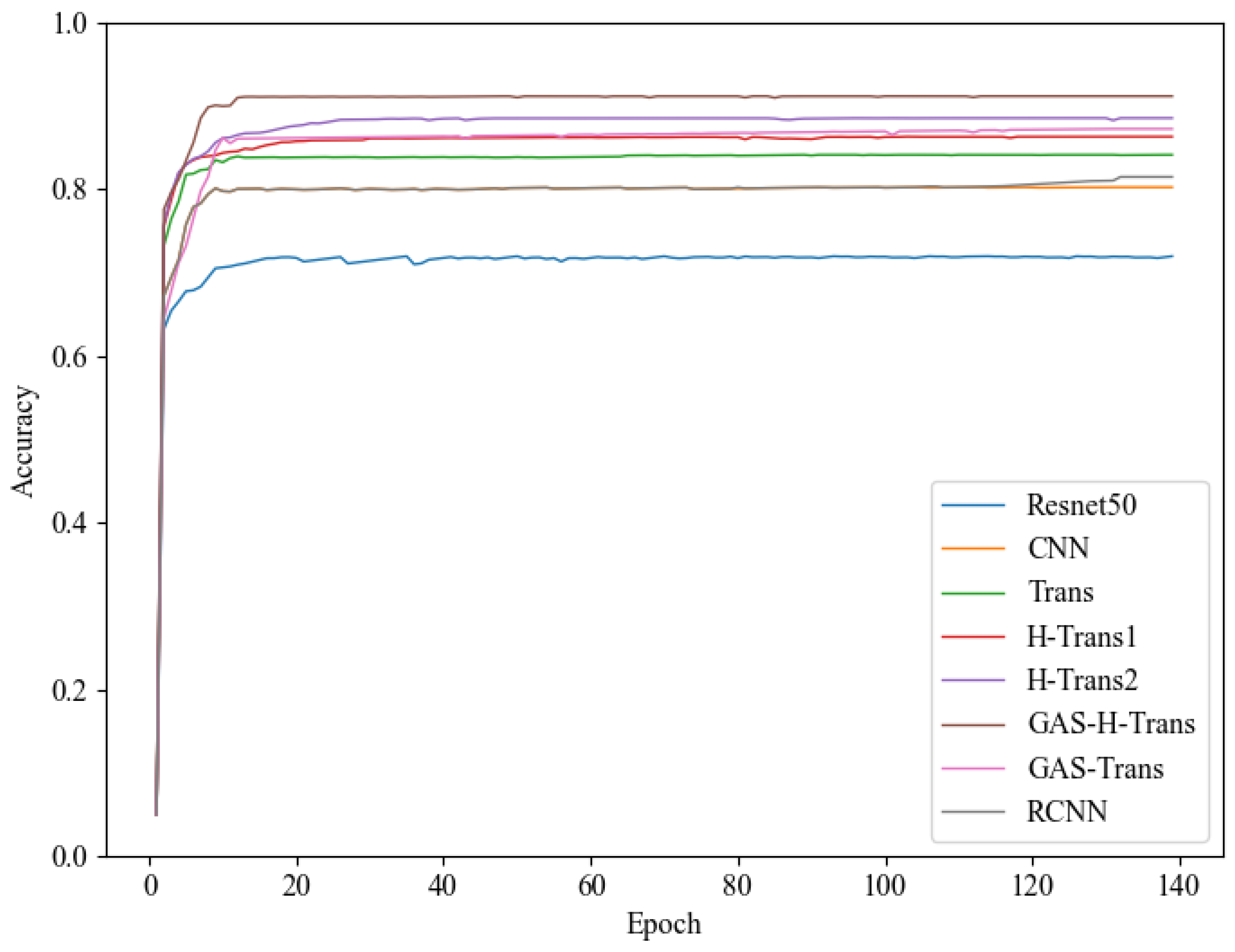
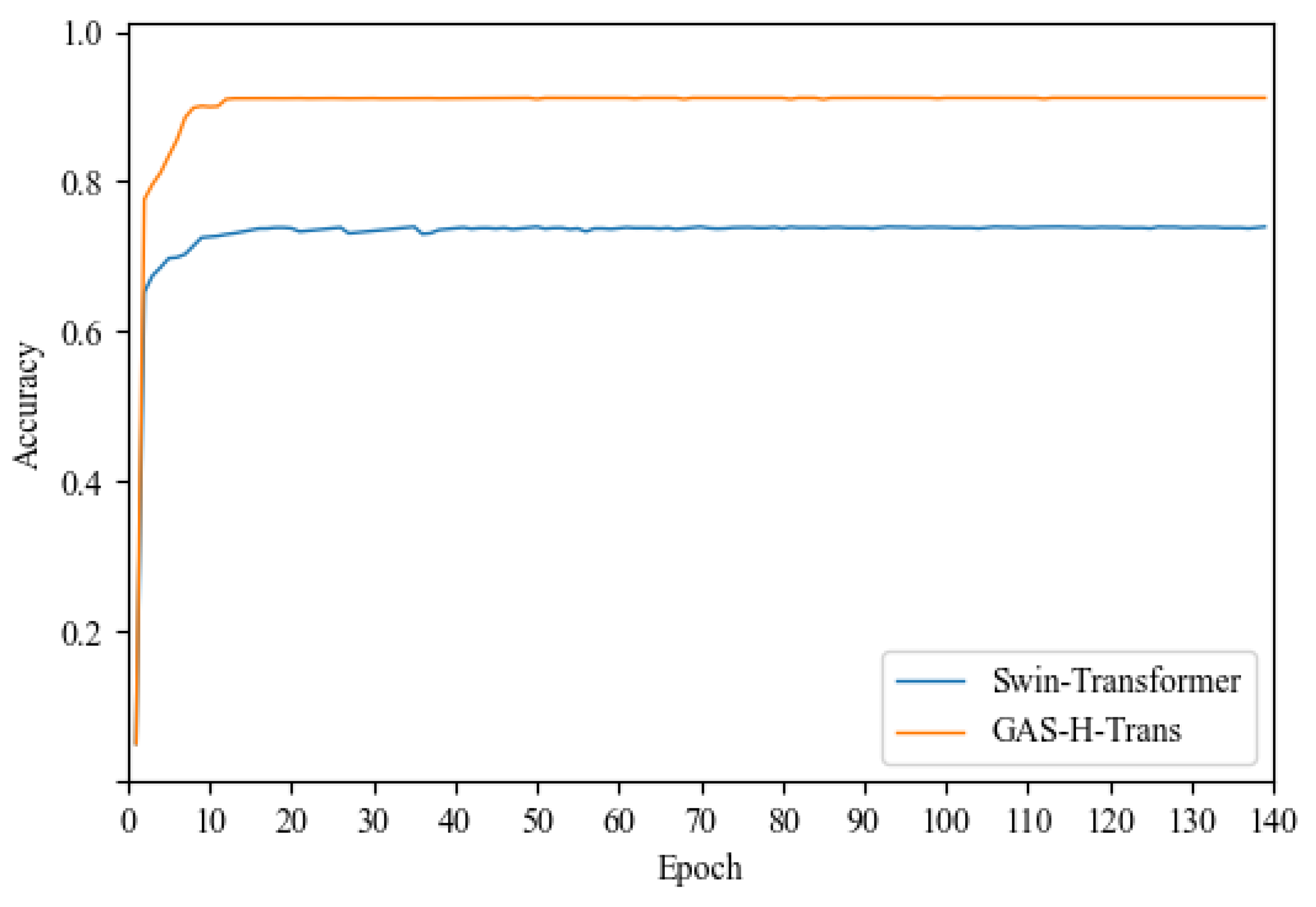
4.2. Performance Comparison of GAS-H-Trans with Baseline Models
- (1)
- Comparison with CNN and ResNet50:
- (2)
- Comparison with Transformer and optimized variants:
4.3. Effectiveness of the Dual-Coupling Grouped Aggregation Strategy
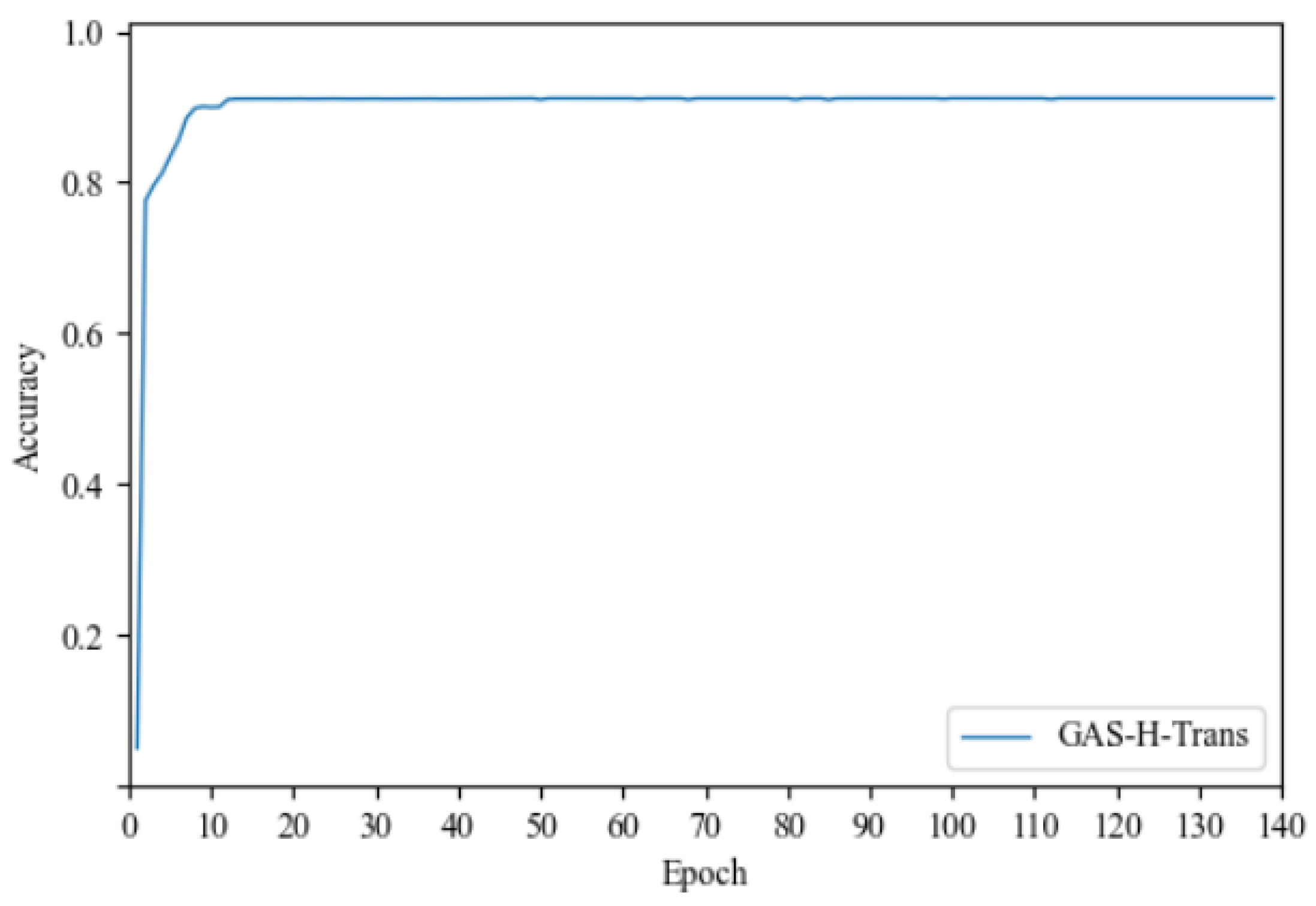
4.4. Generalization Testing of GAS-H-Trans
4.5. Effectiveness of GAS-H-Trans in Virtual Robot Obstacle Avoidance
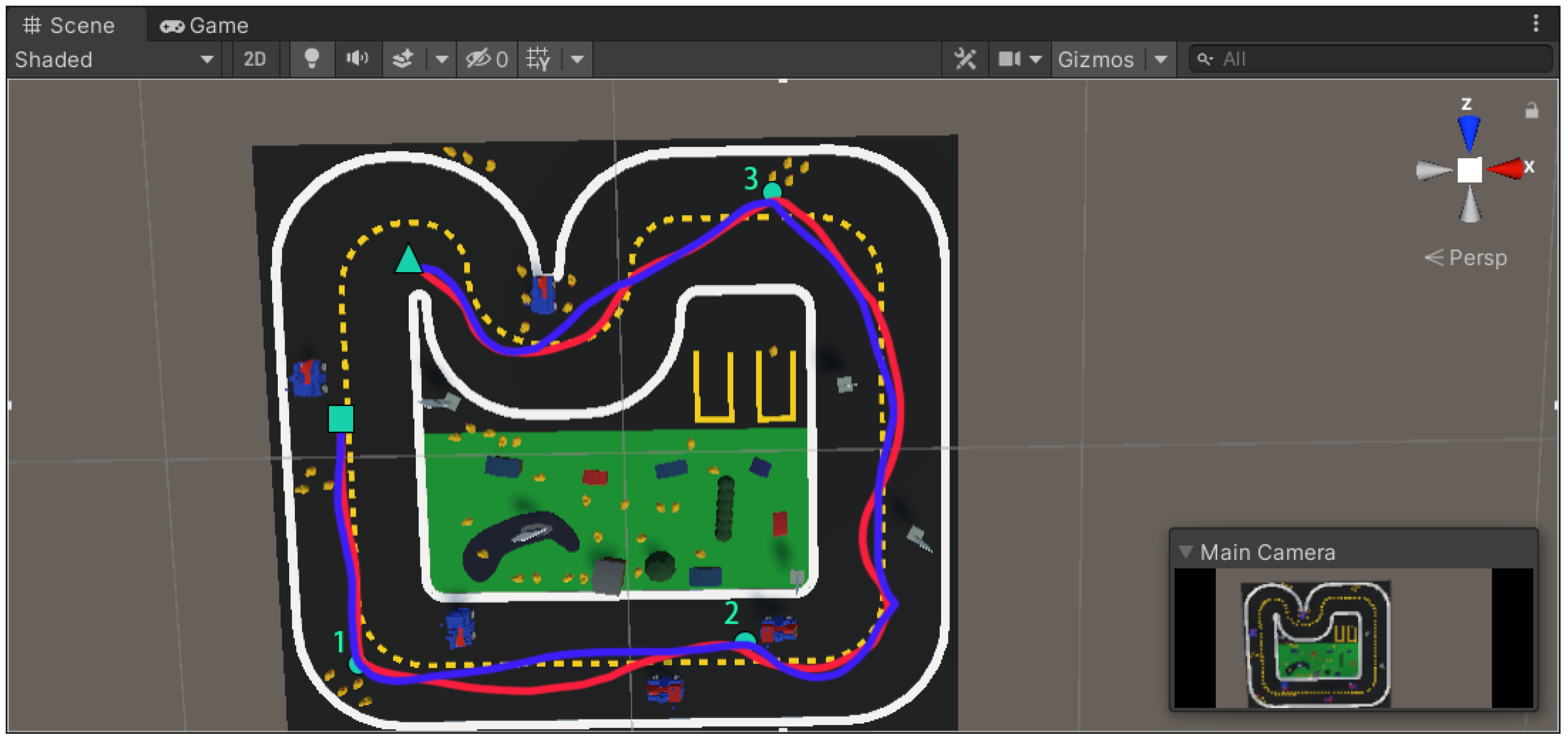
4.5.1. Validation of GAS-H-Trans Model for Image Segmentation in a Virtual Environment
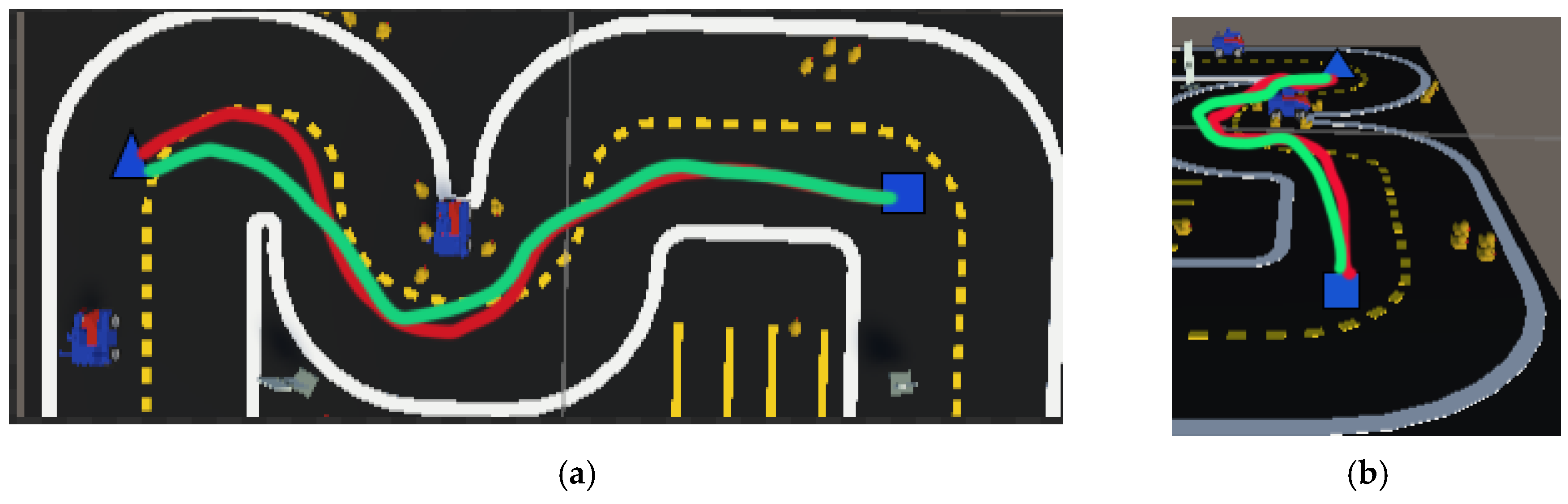
4.5.2. Validation of Autonomous Robot Obstacle Avoidance in Virtual Environments with PSO-Optimized APF
- (1)
- Obstacle Avoidance Strategy for Autonomous Robots in Virtual Environments
- (1)
- Image segmentation: The pre-trained GAS-H-Trans model performs semantic segmentation on images captured by the onboard camera of the robot, rather than being derived from a bird’s-eye view (2D map). It identifies lane markings, obstacles, and other environmental features, providing a structured representation of the environment that improves the accuracy of obstacle recognition and path planning;
- (2)
- Potential field calculation: Based on the segmentation results, the potential field is calculated. The goal position generates an attractive potential, and the obstacles generate a repulsive potential. Unlike traditional sensor-based approaches, this method derives the potential field from vision-based segmentation, ensuring a more detailed and adaptive representation of the environment;
- (3)
- Potential field mapping: The segmentation results are mapped into two potential field masks that represent the left and right sides of the robot, forming a structured spatial representation. These masks correspond to the spatial distribution of virtual forces and are used to simulate the gradient variations of the potential function. They are then transformed into a structured motion-planning coordinate system. Finally, the resultant force synthesized from these potential fields dynamically adjusts the robot’s movement direction, ensuring flexibility and stability in path planning;
- (4)
- Controller design: A potential field-based controller is designed. Using the PSO optimization algorithm to optimize the attractive and repulsive gain coefficients within the APF, the controller calculates a repulsive potential to push the robot away from the side with more obstacles. This controller effectively converts vision-based potential field information into real-world navigation commands, ensuring stability by adapting to dynamic changes in the environment. By incorporating optimization techniques, the controller prevents local minima issues and enhances global path stability;
- (5)
- Obstacle avoidance execution: The robot adjusts its movement based on the controller’s output, successfully performing obstacle avoidance in an autonomous robot operating environment. The control signals, though derived from image-based potential field calculations, are ultimately transformed into robot motion commands in the real-world coordinate system. The robot’s control decisions, including velocity and steering adjustments, are based on the computed potential field forces, enabling precise and adaptive obstacle avoidance.
- (1)
- Obstacle identification through segmentation:
- (2)
- Relative positioning within the robot’s field of view:
- (3)
- APF estimation of distance-based forces:
- (2)
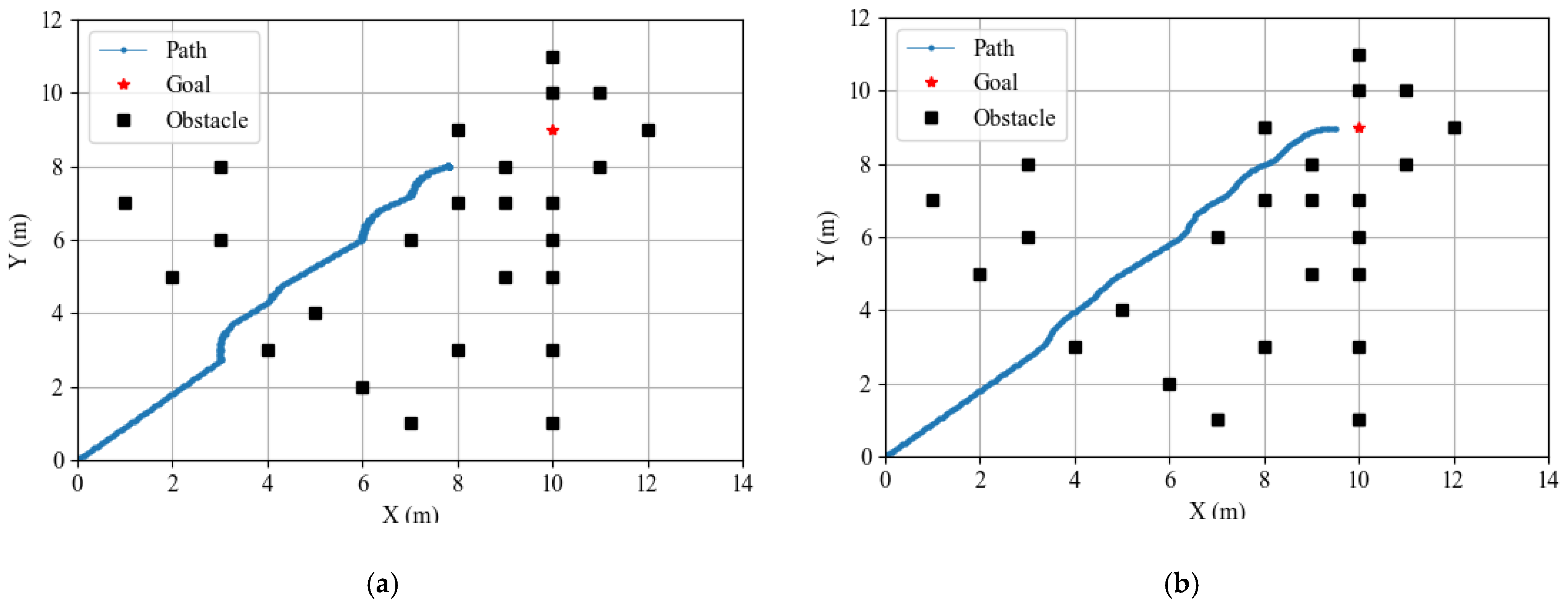
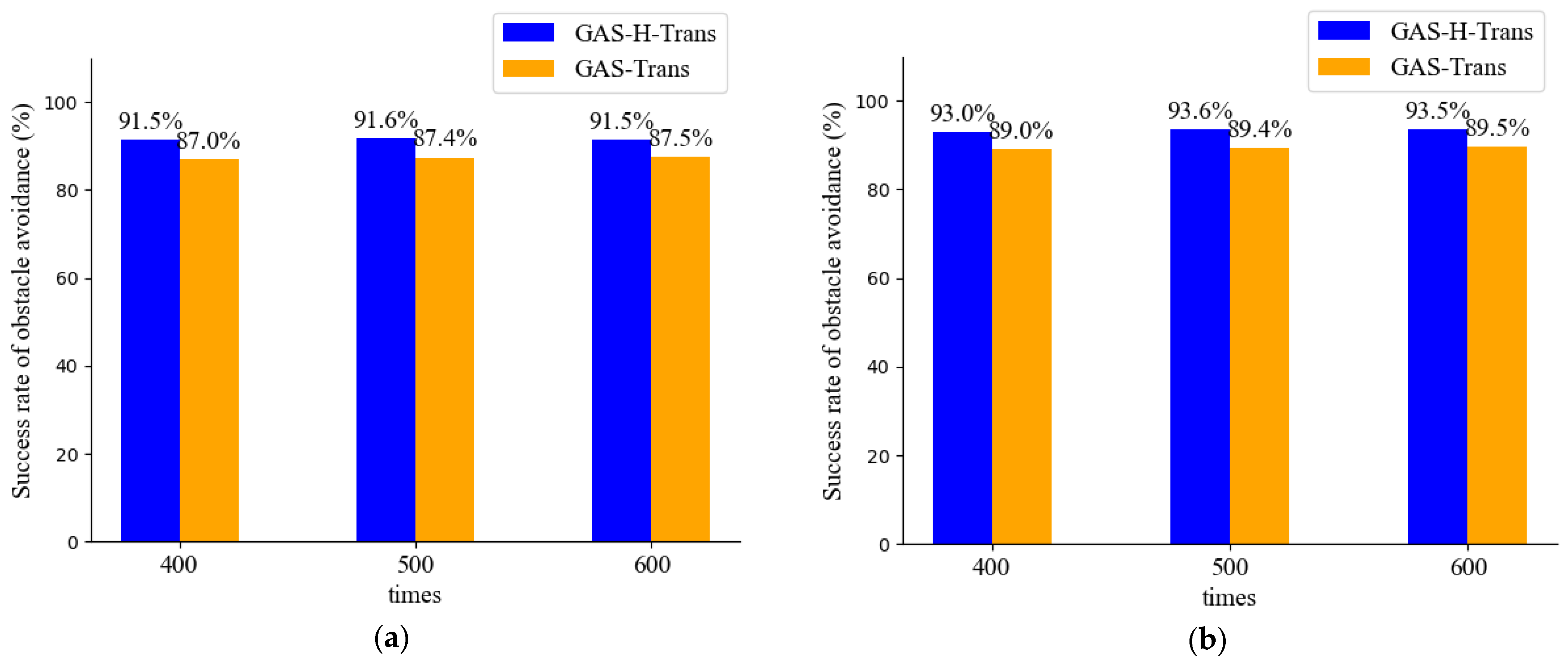
- Obstacle Avoidance Improvement Using the PSO-Optimized APF Method
4.5.3. Obstacle Avoidance Performance of Autonomous Robots in Virtual Environments
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, L.; Liu, H.; Cai, H. Enhanced visual SLAM for construction robots by efficient integration of dynamic object segmentation and scene semantics. Adv. Eng. Inform. 2024, 59, 102313. [Google Scholar] [CrossRef]
- Sadeghi Esfahlani, S.; Sanaei, A.; Ghorabian, M.; Shirvani, H. The Deep Convolutional Neural Network Role in the Autonomous Navigation of Mobile Robots (SROBO). Remote Sens. 2022, 14, 3324. [Google Scholar] [CrossRef]
- Kok, V.; Olusanya, M.; Ezugwu, A. A Few-Shot Learning-Based Reward Estimation for Mapless Navigation of Mobile Robots Using a Siamese Convolutional Neural Network. Appl. Sci. 2022, 12, 5323. [Google Scholar] [CrossRef]
- Wang, H.; Tan, A.H.; Nejat, G. NavFormer: A Transformer Architecture for Robot Target-Driven Navigation in Unknown and Dynamic Environments. IEEE Robot. Autom. Lett. 2024, 9, 6808–6815. [Google Scholar] [CrossRef]
- Sun, L.; Ding, G.; Qiu, Y.; Yoshiyasu, Y.; Kanehiro, F. TransFusionOdom: Transformer-Based LiDAR-Inertial Fusion Odometry Estimation. IEEE Sens. J. 2023, 23, 22064–22079. [Google Scholar] [CrossRef]
- Pandey, A.; Pandey, S.; Parhi, D. Mobile robot navigation and obstacle avoidance techniques: A review. Int. Rob. Auto J. 2017, 2, 00022. [Google Scholar] [CrossRef]
- Wang, H.; Ding, L.; Dong, S.; Shi, S.; Li, A.; Li, J.; Li, Z.; Wang, L. CaGroup3D: Class-Aware Grouping for 3D Object Detection on Point Clouds. Adv. Neural Inf. Process. Syst. 2022, 35, 29975–29988. [Google Scholar]
- Xu, S.; Wan, R.; Ye, M.; Zou, X.; Cao, T. Sparse Cross-Scale Attention Network for Efficient LiDAR Panoptic Segmentation. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2920–2928. [Google Scholar] [CrossRef]
- Zhu, B.; Jiang, Z.; Zhou, X.; Li, Z.; Yu, G. Class-Balanced Grouping and Sampling for Point Cloud 3D Object Detection. arXiv 2019, arXiv:1908.09492. [Google Scholar]
- Hoshino, S.; Kubota, Y.; Yoshida, Y. Motion Planner Based on CNN with LSTM Through Mediated Perception for Obstacle Avoidance. SICE J. Control. Meas. Syst. Integr. 2024, 17, 19–30. [Google Scholar] [CrossRef]
- Zheng, H.; Sun, Y.; Zhang, G.; Zhang, L.; Zhang, W. Research on Real-Time Obstacle Avoidance Method for AUV Based on Combination of ViT-DPFN and MPC. IEEE Trans. Instrum. Meas. 2024, 73, 1–15. [Google Scholar] [CrossRef]
- Chitta, K.; Prakash, A.; Jaeger, B.; Yu, Z.; Renz, K.; Geiger, A. TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12878–12895. [Google Scholar] [CrossRef]
- Ren, H.; Qureshi, A.H. Robot Active Neural Sensing and Planning in Unknown Cluttered Environments. IEEE Trans. Robot. 2023, 39, 2738–2750. [Google Scholar] [CrossRef]
- Lin, C.; Cheng, Y.; Wang, X.; Yuan, J.; Wang, G. Transformer-Based Dual-Channel Self-Attention for UUV Autonomous Collision Avoidance. IEEE Trans. Intell. Veh. 2023, 8, 2319–2331. [Google Scholar] [CrossRef]
- Fan, L.; Yuan, J.; Niu, X.; Zha, K.; Ma, W. RockSeg: A Novel Semantic Segmentation Network Based on a Hybrid Framework Combining a Convolutional Neural Network and Transformer for Deep Space Rock Images. Remote Sens. 2023, 15, 3935. [Google Scholar] [CrossRef]
- Jing, L.; Chen, Y.; Tian, Y. Coarse-to-fine semantic segmentation from image-level labels. IEEE Trans. Image Process. 2019, 29, 225–236. [Google Scholar] [CrossRef]
- Cai, S.; Wakaki, R.; Nobuhara, S.; Nishino, K. Rgb Road Scene Material Segmentation. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022. [Google Scholar]
- Zhang, T.; Hu, X.; Xiao, J.; Zhang, G. TveNet: Transformer-Based Visual Exploration Network for Mobile Robot in Unseen Environment. IEEE Access 2022, 10, 62056–62072. [Google Scholar] [CrossRef]
- Shao, Q.; Gong, L.; Ma, K.; Liu, H.; Zheng, Y. Attentive CT Lesion Detection Using Deep Pyramid Inference with Multi-Scale Booster. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2019; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar]
- Tang, X.; Xu, W.; Li, K.; Han, M.; Ma, Z.; Wang, R. PIAENet: Pyramid Integration and Attention Enhanced Network for Object Detection. Inf. Sci. 2024, 670, 120576. [Google Scholar] [CrossRef]
- Zha, W.; Hu, L.; Sun, Y.; Li, Y. ENGD-BiFPN: A Remote Sensing Object Detection Model Based on Grouped Deformable Convolution for Power Transmission Towers. Multimed. Tools Appl. 2023, 82, 45585–45604. [Google Scholar] [CrossRef]
- Cai, H.; Rahman, M.M.; Akhtar, M.S.; Li, J.; Wu, J.; Fang, Z. AgileIR: Memory-Efficient Group Shifted Windows Attention for Agile Image Restoration. arXiv 2024, arXiv:2409.06206. [Google Scholar]
- Gao, J.; Ji, X.; Chen, G.; Guo, R. Main-Sub Transformer with Spectral-Spatial Separable Convolution for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 2747–2762. [Google Scholar] [CrossRef]
- Yao, C.; Ma, G.; Sun, Z.; Luo, J.; Ren, G.; Xu, S. Weighting Factors Optimization for FCS-MPC in PMSM Drives Using Aggregated Residual Network. IEEE Trans. Power Electron. 2023, 39, 1292–1307. [Google Scholar] [CrossRef]
- Jiang, B.; Wu, H.; Xia, Q.; Li, G.; Xiao, H.; Zhao, Y. NKDFF-CNN: A Convolutional Neural Network with Narrow Kernel and Dual-View Feature Fusion for Multitype Gesture Recognition Based on sEMG. Digit. Signal Process. 2024, 156, 104772. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Hong, Y.-Y.; Pula, R.A. Diagnosis of Photovoltaic Faults Using Digital Twin and PSO-Optimized Shifted Window Transformer. Appl. Soft Comput. 2024, 150, 111092. [Google Scholar] [CrossRef]
- Kumar, S.S.; Kumar, R.V.; Ranjith, V.G.; Jeevakala, S.; Varun, S. Grey Wolf Optimized SwinUNet Based Transformer Framework for Liver Segmentation from CT Images. Comput. Electr. Eng. 2024, 117, 109248. [Google Scholar] [CrossRef]
- Toren, M. Optimization of Transformer Parameters at Distribution and Power Levels with Hybrid Grey Wolf-Whale Optimization Algorithm. Eng. Sci. Technol. Int. J. 2023, 43, 101439. [Google Scholar] [CrossRef]
- Mulla, N.; Gharpure, P. Genetic Algorithm Optimized Topic-Aware Transformer-Based Framework for Conversational Question Generation. Procedia Comput. Sci. 2023, 230, 914–922. [Google Scholar] [CrossRef]
- Zhu, Q.; Yan, Y.; Xing, Z. Robot Path Planning Based on Artificial Potential Field Approach with Simulated Annealing. In Proceedings of the Sixth International Conference on Intelligent Systems Design and Applications, Jian, China, 16–18 October 2006. [Google Scholar]
- Li, M.; Quan, L.; Li, Q.; Li, D.; Li, Z.; Ding, W. UAV Obstacle Avoidance Path Planning Based on Improved Artificial Potential Field Method. In Proceedings of the 2024 International Conference on Advanced Control Systems and Automation Technologies (ACSAT), Nanjing, China, 15–17 November 2024. [Google Scholar]
- Zhai, L.; Liu, C.; Zhang, X.; Wang, C. Local Trajectory Planning for Obstacle Avoidance of Unmanned Tracked Vehicles Based on Artificial Potential Field Method. IEEE Access 2024, 12, 19665–19681. [Google Scholar] [CrossRef]
- Song, S.; Zhu, J.; Zhang, P.; Song, X.; Mei, B. Research on Multivessel Collision Avoidance Decision Based on Improved Artificial Potential Field Algorithm. In Proceedings of the Ninth International Conference on Electromechanical Control Technology and Transportation (ICECTT 2024), Guilin, China, 24–26 May 2024; Volume 13251. [Google Scholar]
- Liu, Z.; Li, W.; Li, B.; Gao, S.; Ouyang, M.; Wang, T. Multi-Robots Formation and Obstacle Avoidance Algorithm Based on Leader-Follower and Artificial Potential Field Method. In CCF Conference on Computer Supported Cooperative Work and Social Computing; Springer Nature: Singapore, 2023. [Google Scholar]
- Li, C.; Zheng, P.; Zhou, P.; Yin, Y.; Lee, C.K.; Wang, L. Unleashing Mixed-Reality Capability in Deep Reinforcement Learning-Based Robot Motion Generation Towards Safe Human–Robot Collaboration. J. Manuf. Syst. 2024, 74, 411–421. [Google Scholar] [CrossRef]
- Ha, V.T.; Vinh, V.Q. Experimental Research on Avoidance Obstacle Control for Mobile Robots Using Q-Learning (QL) and Deep Q-Learning (DQL) Algorithms in Dynamic Environments. Actuators 2024, 13, 26. [Google Scholar] [CrossRef]
- Fernandez-Chaves, D.; Ruiz-Sarmiento, J.R.; Jaenal, A.; Petkov, N.; Gonzalez-Jimenez, J. Robot@ VirtualHome, an Ecosystem of Virtual Environments and Tools for Realistic Indoor Robotic Simulation. Expert Syst. Appl. 2022, 208, 117970. [Google Scholar] [CrossRef]
- Tao, M.; Feng, N.; Duan, F.; Meng, Z.; Liu, Y.; Zhong, H.; Wang, Y. Simulation Study on Mobile Robot Obstacle Avoidance and Path Planning Based on Unity3D. Int. Core J. Eng. 2024, 10, 238–242. [Google Scholar]
- Udomsil, R.; Sangpet, T.; Sapsaman, T. Environment Generation from Real Map to Investigate Path Planning and Obstacle Avoidance Algorithm for Electric Vehicle. In Proceedings of the 2019 Research, Invention, and Innovation Congress (RI2C), Bangkok, Thailand, 11–13 December 2019. [Google Scholar]
- Javaid, M.; Haleem, A.; Suman, R. Digital Twin Applications Toward Industry 4.0: A Review. Cogn. Robot. 2023, 3, 71–92. [Google Scholar] [CrossRef]
- Guffanti, D.; Brunete, A.; Hernando, M. Development and Validation of a ROS-Based Mobile Robotic Platform for Human Gait Analysis Applications. Robot. Auton. Syst. 2021, 145, 103869. [Google Scholar] [CrossRef]
- Zhang, C.; Tian, L.M.; Guo, L.; Wang, Y. A Method for Constructing Virtual-Real Interaction Scenes for Mobile Robots Based on ROS-Unity. Artif. Intell. Robot. Res. 2020, 9, 217. [Google Scholar]
- Rohmer, E.; Singh, S.P.N.; Freese, M. V-REP: A Versatile and Scalable Robot Simulation Framework. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Aflaki, S.C. Teaching a Virtual Duckietown Agent to Stop. Bachelor’s Thesis, University of Amsterdam, Amsterdam, The Netherlands, April 2021; pp. 10–23. [Google Scholar]
- Broere, A.R. Monocular Navigation for a Duckiebot Using a High-Resolution Encoder-Decoder Architecture. Bachelor’s Thesis, University of Amsterdam, Amsterdam, The Netherlands, 2023; pp. 4–13. [Google Scholar]
- Paull, L.; Tani, J.; Ahn, H.; Alonso-Mora, J.; Carlone, L.; Cap, M.; Chen, Y.F.; Choi, C.; Dusek, J.; Fang, Y.; et al. Duckietown: An open, inexpensive and flexible platform for autonomy education and research. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1497–1504. [Google Scholar]
- Raman, S.S.; Pelgrim, M.H.; Buchsbaum, D.; Serre, T. Categorizing the visual environment and analyzing the visual attention of dogs. arXiv 2023, arXiv:2311.11988. [Google Scholar]
- Wang, Y.; Lu, C.; Lian, H.; Zhao, Y.; Schuller, B.W.; Zong, Y.; Zheng, W. Speech Swin-Transformer: Exploring a Hierarchical Transformer with Shifted Windows for Speech Emotion Recognition. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Configuration Parameter | Structural Parameters |
|---|---|---|
| CNN | Batch size: 16 | (Conv2d, BatchNorm2d) × 3 + Conv2d |
| Optimizer: SGD | ||
| Loss Function: Binary Cross-Entropy | Dense | |
| Resent50 | Batch size: 50 | (Conv2d + BatchNorm2d + Activation) × 3 + Shortcut Connection |
| Optimizer: Adam | ||
| Loss Function: Cross-Entropy Loss | Dense | |
| Mask R-CNN | Batch size: 50 | (Conv2d + BatchNorm2d + ReLU) × 3 + Shortcut Connection |
| Optimizer: Adam | ||
| Loss Function: Cross-Entropy Loss+Smooth L1 Loss+Average Binary Cross-Entropy Loss | Dense | |
| Trans | Batch size: 16 | Patch Embedding + (Block with Attention + MLP) × Depth + Classification Head |
| Optimizer: Adam | ||
| GAS-H-Trans | Batch size: 16 | (Linear, BatchNorm) × 3 + Softmax |
| Optimizer: Adam |
| Model | Parameter | mIoU | F1 | Accuracy |
|---|---|---|---|---|
| CNN | 1.6 M | 63.4% | 74.3% | 71.8% |
| CNN [16] | - | 47.7% | - | - |
| Resent50 | 7.1 M | 74.7% | 84.4% | 80.4% |
| Resent50 [15] | - | 78.97% | - | - |
| Mask R-CNN | 75.1% | 84.8% | 81.5% | |
| Mask R-CNN [48] | - | 60% | 68% | 74% |
| Trans | 5.8 M | 81.2% | 89.1% | 86.5% |
| GAS-Trans | 5.7 M | 82.4% | 90% | 87.2% |
| H-trans1 | 9.8 M | 83.7% | 90.9% | 88.9% |
| H-trans2 | 9.8 M | 84.5% | 91.4% | 89.5% |
| GAS-H-Trans | 9.8 M | 85.2% | 91.9% | 91.3% |
| Model | Parameter | mIoU | F1 | Accuracy |
|---|---|---|---|---|
| GAS-H-Trans | 9.8 M | 85.2% | 91.9% | 91.3% |
| Swin-transformer | 9.2 M | 67.1% | 77.2% | 73.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Y.; Bai, Y.; Chen, Q. An Adaptive Obstacle Avoidance Model for Autonomous Robots Based on Dual-Coupling Grouped Aggregation and Transformer Optimization. Sensors 2025, 25, 1839. https://doi.org/10.3390/s25061839
Tang Y, Bai Y, Chen Q. An Adaptive Obstacle Avoidance Model for Autonomous Robots Based on Dual-Coupling Grouped Aggregation and Transformer Optimization. Sensors. 2025; 25(6):1839. https://doi.org/10.3390/s25061839
Chicago/Turabian StyleTang, Yuhu, Ying Bai, and Qiang Chen. 2025. "An Adaptive Obstacle Avoidance Model for Autonomous Robots Based on Dual-Coupling Grouped Aggregation and Transformer Optimization" Sensors 25, no. 6: 1839. https://doi.org/10.3390/s25061839
APA StyleTang, Y., Bai, Y., & Chen, Q. (2025). An Adaptive Obstacle Avoidance Model for Autonomous Robots Based on Dual-Coupling Grouped Aggregation and Transformer Optimization. Sensors, 25(6), 1839. https://doi.org/10.3390/s25061839