1. Introduction
With the continuous advancement of computing, robotics, and automation technologies, the automation level in steel coil packaging lines has been steadily increasing. Currently, most processes in advanced steel coil packaging production lines overseas are fully automated. However, only a small number of foreign steel companies have automated the installation of the inner corner of steel coils [
1,
2,
3]. Moreover, high costs remain a significant challenge. The primary issue lies in the absence of a reliable steel coil end face position detection system, which hinders accurate detection and adjustment of both the steel coil end face and inner corner positions. Therefore, the development of a high-precision, robust position detection system is crucial.
With the widespread application of machine vision and image processing technologies, the efficiency and accuracy of visual inspection have been significantly enhanced [
4,
5,
6]. Currently, target position detection methods are classified into two categories: conventional position detection techniques and machine vision-based methods [
7]. The traditional methods typically rely on manually defined rules, manual feature extraction, or geometric modeling to process and analyze input data [
8,
9], and perform target detection by scanning all positions in the image using a sliding window technique. For example, Bochang Zou proposed a novel approach for sphere characterization, which enables the recognition of spherical objects by extracting and fitting their contour features [
10]. Similarly, Zhu et al. introduced a large component assembly method based on key assembly features, which uses a laser tracker to measure assembly points and a multi-objective particle swarm optimization algorithm to compute the target’s positional attitude [
11]. While the traditional position extraction methods based on image features offer high efficiency and stability, they face significant challenges in detecting steel coil end face targets in complex environments. These challenges include difficulties in processing nonlinear data, long processing cycles, and low accuracy, all of which hinder their ability to meet practical requirements. Hasib Zunair and A. Ben Hamza proposed an improved biomedical image segmentation network, Sharp U-Net. The model performs well in multimodal medical image segmentation tasks such as lung CT, endoscopic images, skin lesions and COVID-19 CT, significantly improving accuracy, accelerating convergence, and improving robustness, providing new ideas for segmentation in industrial inspection scenarios. network optimization in industrial inspection scenarios. However, the method still suffers from under-segmentation in low contrast or complex backgrounds, and its generalization ability and real-time performance in the field of machine vision are yet to be further verified [
12]. Yang Liu et al. proposed a deep learning-based mineral image segmentation method, which improves the segmentation of adhering and overlapping particles by integrating morphological erosion operations with an encoder-decoder network architecture. Experimental results demonstrate that MobileNet-based PSPNet and DeepLab models achieve excellent performance in complex industrial environments, reaching a pixel accuracy of 95.8% and an intersection-over-union (IoU) of 95.0%. This method effectively enhances segmentation accuracy; however, it still faces challenges such as sensitivity to erosion parameters, high computational cost, and inadequate segmentation of small particles. Therefore, further improvements are needed to enhance the method’s versatility and real-time performance in practical applications [
13].
Machine vision-based position detection methods primarily involve target detection through feature extraction, such as texture and color, from images. For example, Zhao et al. applied a charge-coupled device (CCD) attitude sensor for position recognition and extraction during the docking of the Shenzhou VIII spacecraft [
14]. Xu and Zhang et al. proposed a cooperative target attitude measurement method based on binocular stereo vision and validated the algorithm’s effectiveness through a simulation system to meet the measurement requirements for tracking, approaching, and maintaining relative position [
15,
16]. Liu et al. designed a binocular vision-based missile assembly position recognition method to guide the docking mechanism in adjusting the compartment’s position using compartment features to complete the docking process [
17]. Qian et al. proposed a collaborative spacecraft attitude measurement method based on three-view vision, which improves feature point localization accuracy, enhances system reliability, and addresses the challenge of measuring positional attitude parameters during the rendezvous and docking process [
18].
Traditional machine vision position extraction methods face several challenges in steel coil end face inspection. First, the complex background and the interweaving of edge and mounting hole contours make image background segmentation difficult. Second, due to variations in packaging requirements and field environments, the steel coil end face images exhibit significant differences, necessitating the design of complex segmentation algorithms and intricate solution processes. Furthermore, traditional methods lack accurate positioning of contour regions and automatic feature extraction, which limits their portability and reusability. As a result, traditional target detection algorithms are increasingly being replaced by deep-learning algorithms. These deep-learning techniques have become the mainstream in target detection due to their ability to automatically learn features and classifiers, offering stronger robustness and adaptability [
19,
20].
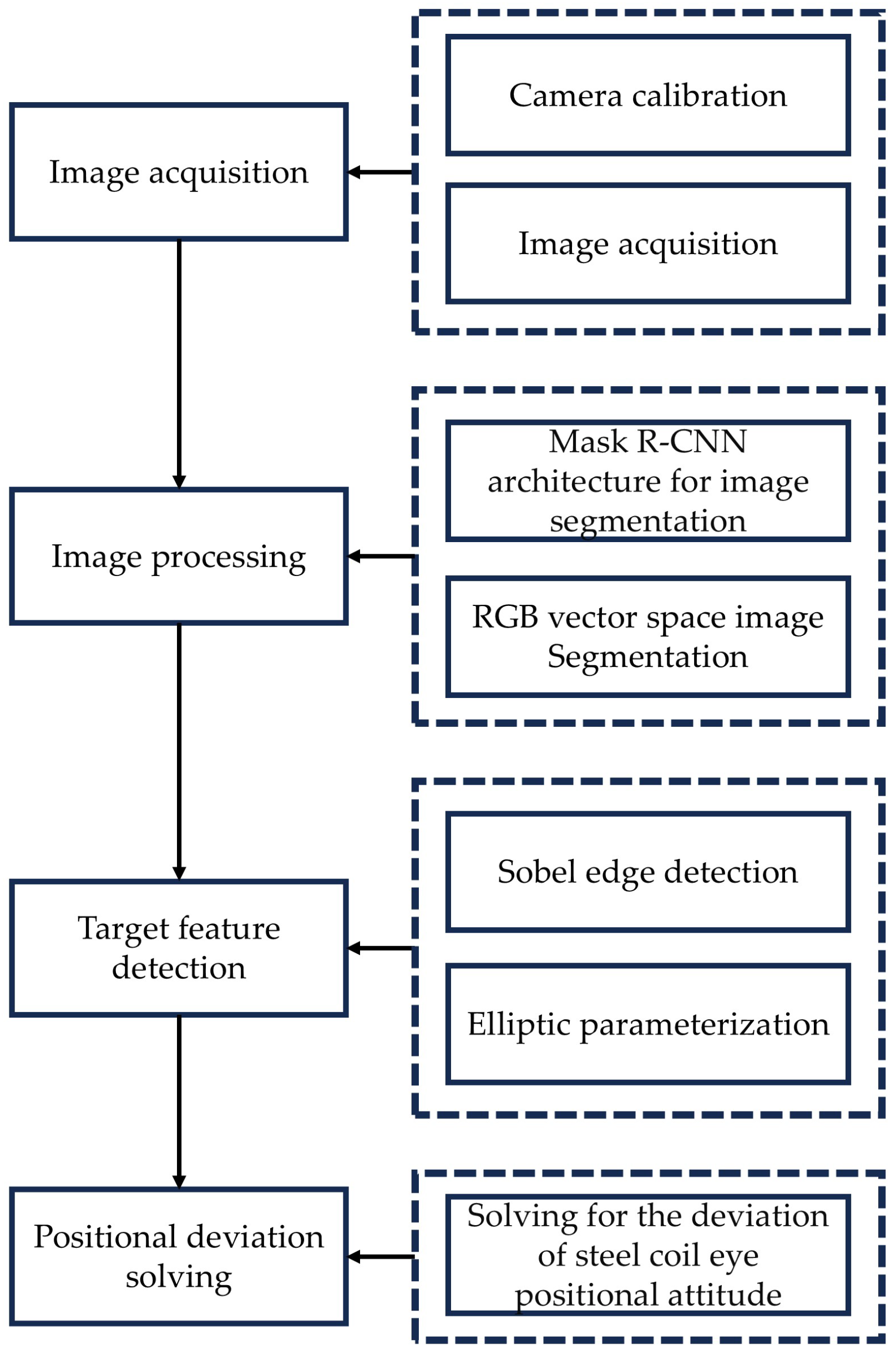
This paper introduces a novel method for detecting positional deviations in the steel coil end face, leveraging deep learning and binocular vision technologies, integrated with an inner corner guard butt joint installation scheme. The core of this approach is to transform the parameter information of the steel coil’s roll eye from the image coordinate system to a 3D spatial pose in the world coordinate system. This transformation is accomplished through a series of steps involving image segmentation, feature extraction, and coordinate transformation techniques. Initially, the relationships between the four major coordinate systems of the camera are established based on visual sensing principles [
21]. Subsequently, the Mask R-CNN architecture, combined with the RGB vector space segmentation method, is employed for image segmentation [
22], producing a binarized image. Following this, the least-squares method is applied to extract elliptic parameters from the rolled eye parameters after performing Sobel edge detection. Finally, by integrating the camera’s intrinsic parameters [
23], the extracted elliptic parameter feature information, and the geometric positional relationship between the camera and the steel coil, the roll eye’s positional attitude is accurately determined.
3. Image Acquisition and Processing
First, the camera is calibrated using specific parameters. This study employs Zhang Zhengyou’s plane calibration method to conduct camera calibration experiments. The calibration process, illustrated in
Figure 4, involves the following steps: initially, the calibration plate is positioned at various attitudes; subsequently, corner points are detected; and finally, the calibration results are derived through computational analysis.
Due to the abrupt change in gray level at the junction of black and white squares, the Harris operator detects this sudden gray level variation around pixel points, identifying them as characteristic corner points. Consequently, the camera extracts the corner point image, as depicted in
Figure 5.
The extracted corner points are utilized to fit and derive the camera’s parameter matrix. In the equations, the parameters for the left and right cameras are distinguished by the subscripts l and r, respectively.
The internal reference matrices for Camera 1 and Camera 2 are as follows:
The rotation and translation matrices between the two cameras are:
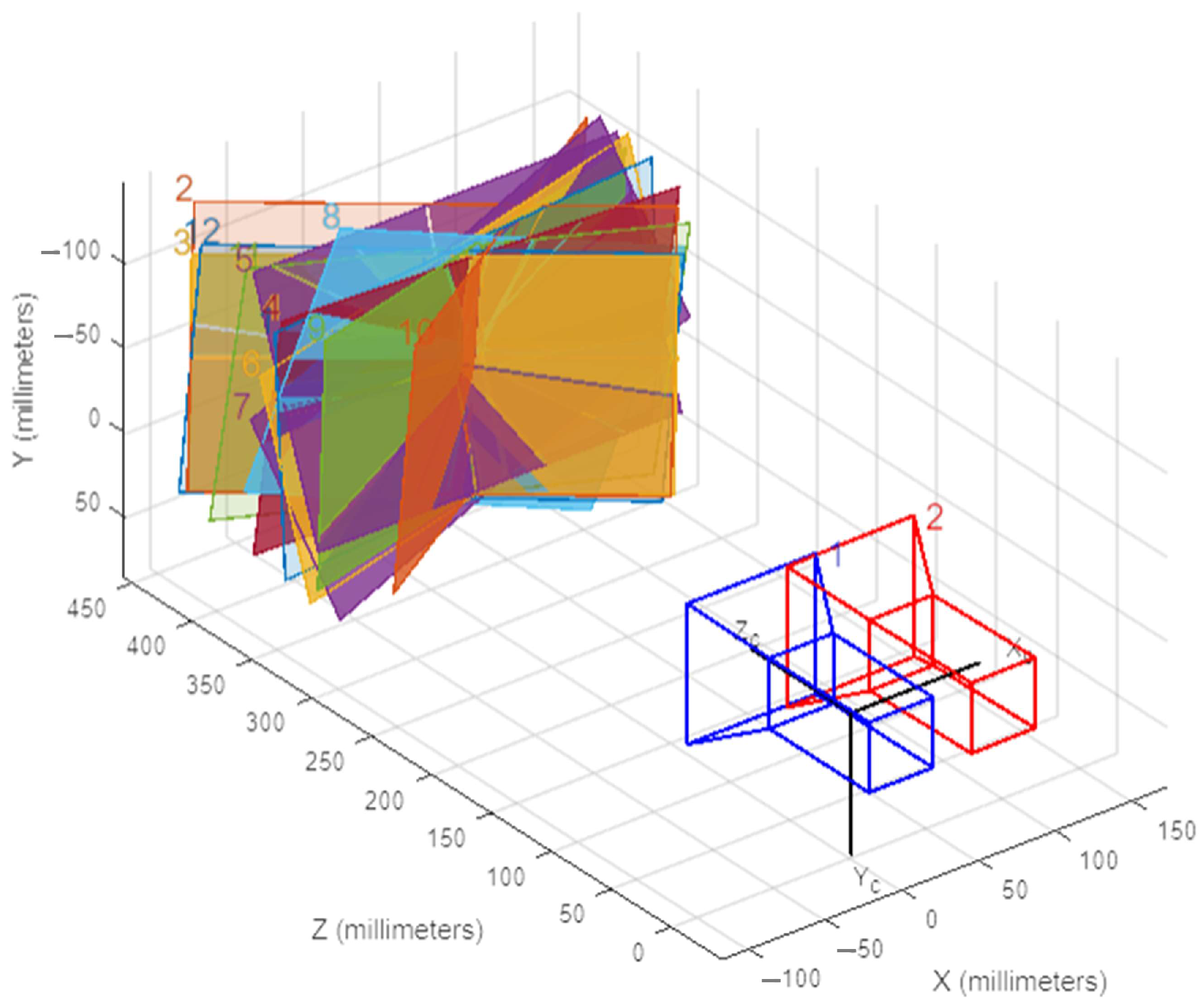
The camera 3D positional view in
Figure 6.
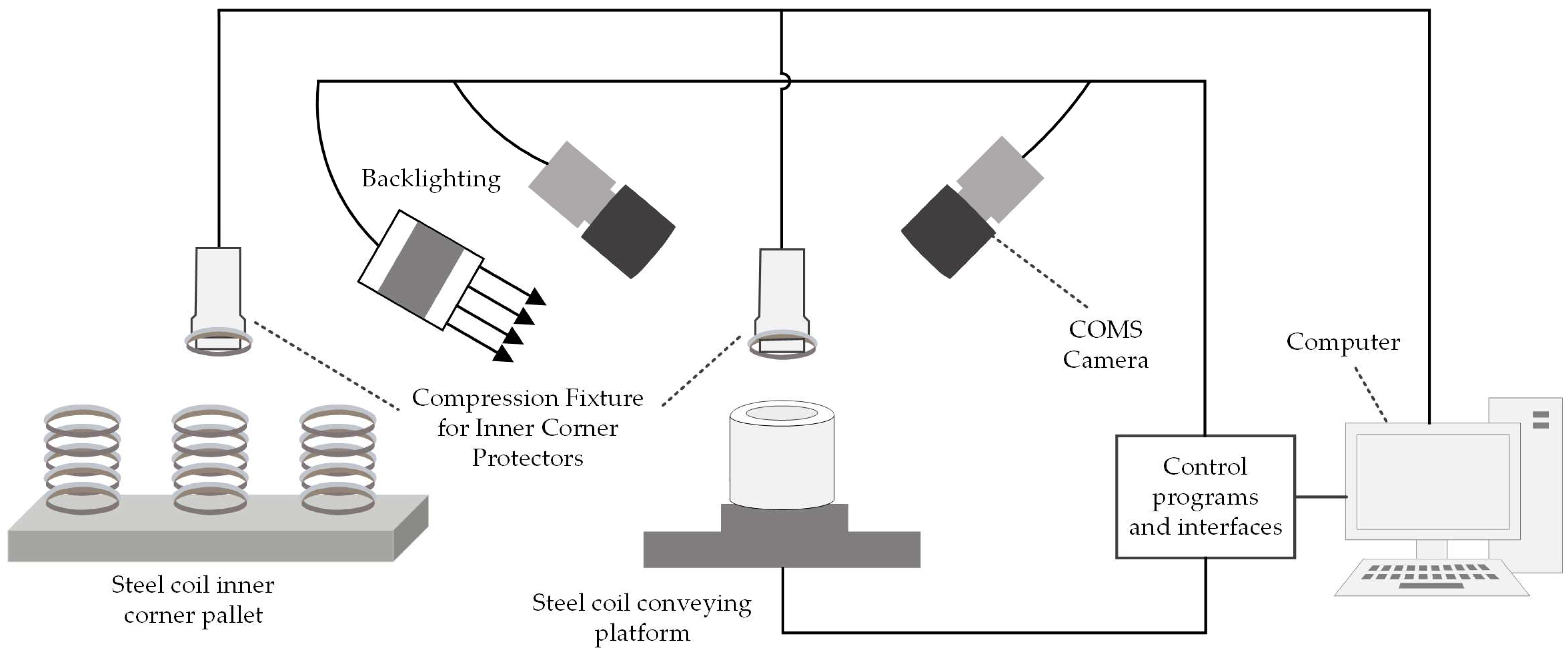
During the image acquisition process, various internal and external objective parameters such as lens characteristics and lighting conditions can introduce interference into the image. Additionally, the side of the steel coil features numerous small contours, which, due to the camera’s robust image capture capability, are likely to be captured in detail. This can easily lead to image misjudgment, necessitating image pre-processing. In this study, the image pre-processing steps employed are erosion, median filtering, and histogram equalization.
3.1. Visual Imaging Principle
Visual sensors primarily capture information about objects in three-dimensional space by analyzing the target’s light intensity data, the spatial distribution of light intensity, and color identification. This information is subsequently converted into two-dimensional image plane projection data [
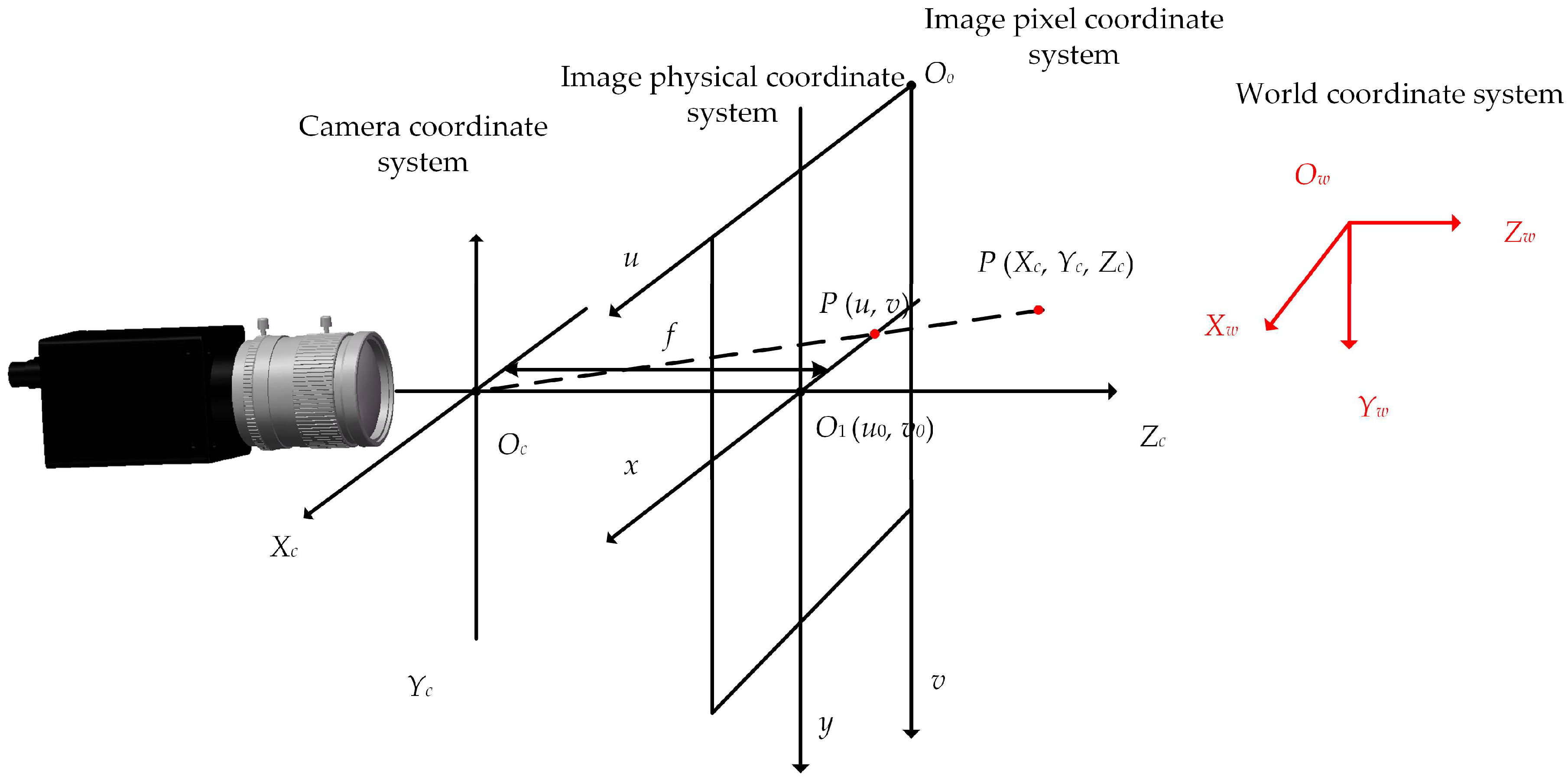
24]. In this study, a CMOS camera (IMX298) was utilized to capture images of the steel coil’s end face. By leveraging camera imaging principles and coordinate translation transformations, the flatness of the end face and the precise coordinates of its mounting holes are accurately determined.
A spatial coordinate system was established to derive the camera’s imaging model. The machine vision system encompasses four primary coordinate systems: the world coordinate system, which represents the absolute coordinates of three-dimensional points in the scene as (
Xw,
Yw,
Zw); the camera coordinate system, which describes the relative position of objects within the camera, with the three-dimensional coordinates of a scene point P denoted as (
Xc,
Yc,
Zc); the image physical coordinate system, whose origin
O1 (
u0,
y0) is situated at the center of the image plane, with the x-axis and y-axis aligned parallel to the
u-axis and
v-axis of the image pixel coordinate system; and the image pixel coordinate system, which delineates the coordinates of image pixels, with the coordinates of scene point P expressed as (
u,
v) [
25].
The relationship between the coordinate systems is shown in
Figure 7.
The transformation relationship between the image coordinate system and the image physical coordinate system can be expressed as:
It can be represented in the form of its chi-square coordinate matrix as:
The relationship between the camera coordinate system and the world coordinate system can be represented by a rotation matrix
R and a translation matrix
T, which is expressed as its sub-matrix:
where
R is an orthogonal unit rotation matrix of size 3 × 3 and
T is a 3D translation matrix of size 3 × 1. (
Xc,
Yc,
Zc) are the coordinates of the point in the camera coordinate system, (
Xw,
Yw,
Zw) are the coordinates of the point in the world coordinate system.
For any point
P (
Xc,
Yc,
Zc) in the camera coordinate system, the physical coordinate system (
x,
y) in the image plane is:
This can be expressed in terms of the matrix:
From the linear camera imaging model [
26], we derive the relationship between coordinate points (
Xw,
Yw,
Zw) win the world coordinate system and their projection points (
u,
v) in the image pixel coordinate system, as shown in Equation (10).
In the formula, M, [R T] are referred to as the “inner parameter matrix” and “outer parameter matrix” of the camera, respectively. M is completely determined by the internal parameters (ku), (kv), (ks), (u0), (v0), while [R T] depends on the relative positions of the camera coordinate system and the world coordinate system, thus termed the “outer parameter matrix”. Additionally, (Z1) represents the transformation scale factor.
3.2. Image Segmentation
To reduce the computational load and complexity of subsequent image processing while enhancing the portability and reusability of target region extraction for steel coils, this paper employs a deep-learning approach. Specifically, it utilizes the Mask R-CNN feature extraction algorithm within the deep-learning framework to identify and extract the target region of steel coil corner guards, thereby obtaining a mask color image of the mounting holes. The image segmented by the Mask R-CNN architecture was further refined using the RGB vector space image segmentation method to produce a binarized image of the steel roll eyes.
Figure 8 illustrates sample images of steel coils with varying packaging processes, qualities, and sizes.
3.2.1. Mask R-CNN Algorithm
The architecture of Mask R-CNN comprises several key components: feature extraction, the candidate region network (RPN), the region of interest (ROI) alignment module, and three output branches. Feature extraction employs ResNet integrated with Feature Pyramid Network (FPN) to generate a multi-scale feature map. The RPN generates candidate frames through 1 × 1 convolution and selects high-quality frames for the ROI alignment module. This module aligns the feature maps and candidate frames to the same dimensions, which are then fed into a fully connected layer to produce classification and bounding box regression results. Additionally, the mask branch enhances resolution via deconvolution to obtain a pixel-level mask of the target, thereby facilitating both detection and segmentation tasks.
A total of 100 images were initially captured, each with a resolution of 800 × 800 pixels. Some samples from the dataset are illustrated in
Figure 9.
To enhance the model’s generalization ability and reduce data similarity, we employed various data augmentation techniques. These included geometric transformations such as image translation, flipping, and affine transformations, as well as pixel-level transformations like adjusting brightness, contrast, and adding Gaussian noise. After augmenting the dataset, we further filtered out images with excessive similarity, ultimately retaining 1560 images, which suffices for neural network training requirements. This dataset was then randomly divided into training and test sets at an 8:2 ratio.
Using the Image Labeler in MATLAB 2019a, we established two categories: “Circle” and “Background”. This tool was employed to perform pixel-level labeling of the image data, resulting in segmented labeled maps of the mounting holes. The labeling outcomes are depicted in
Figure 10.
- 2.
Network Training
Prior to training the deep-learning network, it is essential to configure the network parameters. The specific parameter settings are as follows: the initial learning rate is set to 0.001, with a segmented learning rate decay strategy, reducing the rate every 1 epoch by a factor of 0.95. The momentum contribution from the previous step is set to 0.9, the maximum number of epochs is 10, and the mini-batch size is 1. The training is conducted in a GPU-enabled environment. During the training of the Mask R-CNN network, the loss change curves are optimized by calculating the discrepancies between predicted and labeled values, followed by backpropagation to refine the model. The loss change curve is illustrated in
Figure 11.
The horizontal axis of the graph denotes the number of training iterations, while the vertical axis represents the total loss value. As depicted, the loss value stabilized upon reaching 577 iterations, highlighting the model’s robustness. The Mask R-CNN model’s losses encompass boundary regression loss, classification loss, mask loss, RPN foreground/background classification loss, and RPN boundary regression loss. With increasing iterations, each loss component exhibited a similar trend. Notably, at 577 iterations, the total loss reduced to 0.8 and the mask loss to 0.2, signifying enhanced model fitting to the data.
- 3.
Experimental results
The images in the test set were evaluated using the trained target detection network, with the results displayed in
Figure 12. The mounting area of the steel coil was effectively segmented from the background, demonstrating accurate recognition. The mask fit for the test set was high, indicating excellent performance.
3.2.2. RGB Vector Space Image Segmentation
Following the image segmentation by the Mask R-CNN architecture, the image must be converted into a binary format as required. This involves identifying the target color vectors a= (aR, aG, aB), and measuring the similarity within the color space using the Euclidean distance. Specifically, we set the color vector z = (zR, zG, zB) for any point in the RGB color space.
When the distance between the color vector and the target vector is less than a predefined threshold D0, the vector z is deemed similar to a. In other words, z is considered a point within the color region of interest, with the Euclidean distance between them denoted as D(z, a).
The set of points that satisfy
D(
z,
a) ≤
D0 at this point is a solid sphere with center a and radius
D0. The extraction of the color region of interest can be equated to a linear programming in the RGB color space with a threshold segmentation expression for the pixel
z-points:
where
f (
zR,
zG,
zB) is the threshold segmentation objective function,
f (
zR,
zG,
zB) =
zG − (
zR + zB)/2;
P(
z) is the Logical values in
z-point color space, 0 or 1;
D0 is the region of interest segmentation threshold, selected as 30 in this paper.
In this study, the
G (green) spectral component values in the installation area are significantly higher than those of the
R (red) and
B (blue) spectral components, the objective function
f (
zR,
zG,
zB) =
zG − (
zR + zB)/2 represents the difference between the
G (green) component and the mean of the
R (red) and
B (blue) components at point
z;
P(
z) is the logical value of the color space at point
z. The color space partitioning is illustrated in
Figure 13.
The shaded portion of
Figure 12 represents the plane defined by the equation
f (
zR,
zG,
zB) =
zG − (
zR + zB)/2 −
D0 = 0, the region encompassing this segmentation plane and the lower-left section of the area is the target color region. If a pixel’s color vector falls within this region, its logical value is
P(
z) = 1, indicating that it will appear as a white region after binarization, signifying the region of interest. Conversely, if the color vector lies outside this region, the logical value is 0, and post-segmentation binarization, this part of the pixel point forms the black background region.
The final result of the segmentation of the rolled eyes is shown in
Figure 14.
4. Target Feature Extraction
The pixel
f (
x,
y) value corresponds to the specific pixel point within the image. Upon undergoing the aforementioned image segmentation process, the image is transformed into an ellipsoidal binary image representing the installation area.
To determine the positional state of the mounting end face, edge detection of the mounting holes is essential for extracting the ellipse parameters during horizontal, vertical deviation, yaw angle, and pitch angle positional identification. The results of the edge detection for the mounting holes are illustrated in
Figure 15.
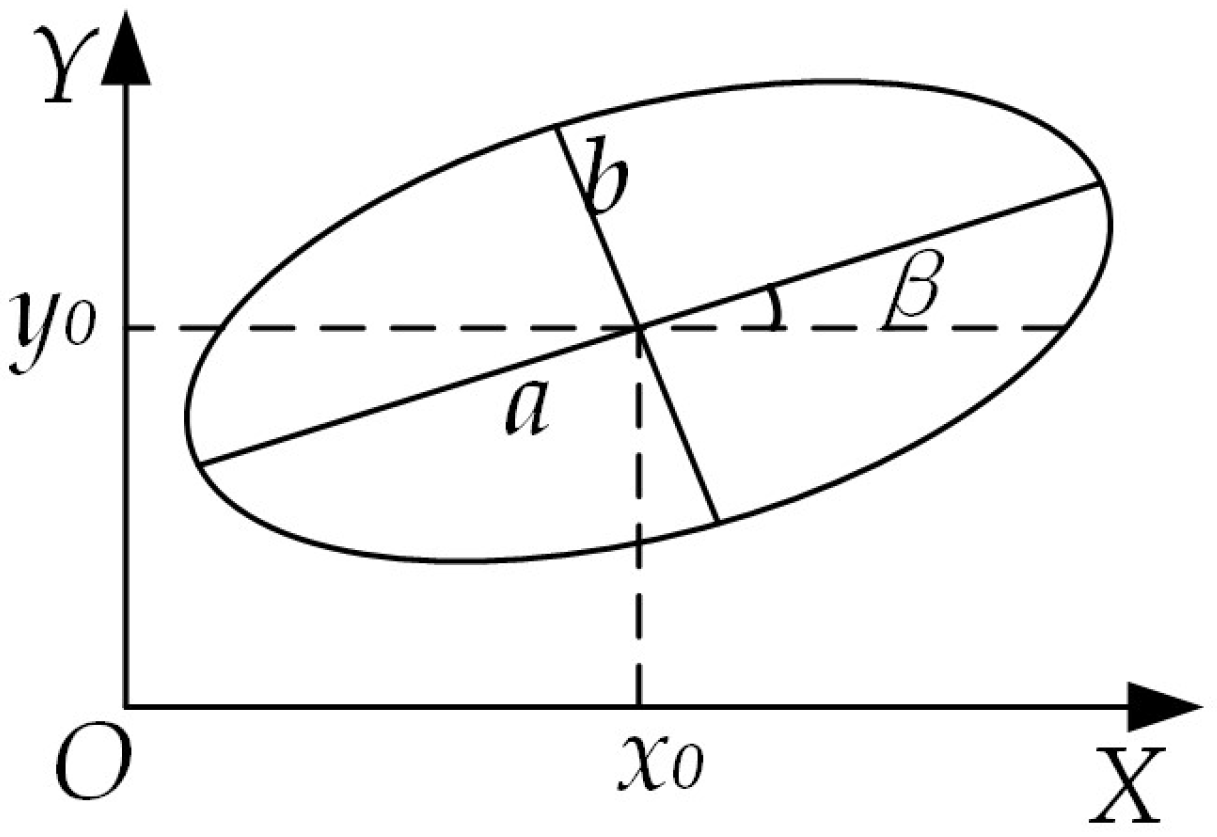
When the mounting end face of the steel coil is not parallel to the mounting end face of the inner corner protector, the image of the mounting hole edge captured by the binocular camera will appear as an ellipse due to angular projection. Building on the image segmented using the Mask R-CNN architecture and the image processed via the RGB vector space method, the Sobel edge extraction algorithm is then applied to obtain a series of pixel points along the ellipse. Finally, ellipse parameter fitting is performed to derive the ellipse parameters. The schematic diagram of the ellipse’s right-angled coordinates is presented in
Figure 16.
The figure (x0, y0) illustrates the coordinates of the ellipse’s center. Here, (a) denotes the semi-major axis (half-length axis) of the ellipse, (b) signifies the semi-minor axis (half-short axis), and (β) represents the angle between the major axis of the ellipse and the horizontal axis, with counterclockwise direction considered positive.
The parametric equation of the ellipse can be expressed as:
The general form of the equation representing the curve of an ellipse is expressed as follows:
When the six parameters
A,
B,
C,
D,
E, and F are scaled uniformly, the represented ellipse remains unchanged. To prevent overlapping and zero solutions, the constraint
A +
C = 1 is imposed. Additionally, it is essential to ensure the discriminant condition: Δ =
B2 − 4
AC < 0. Consequently, the corresponding parameters of the ellipse are determined.
According to the principle of least squares, the pixel points are substituted into the normalized sum of the general formula, which serves as the objective function for ellipse fitting:
where (
xi,
yi) represent the coordinates of the extracted edge pixel points.
According to the Extreme Value Theorem, there exists a point at which the objective function attains its minimum value:
Substituting
A +
C into Equation (16) for partial derivatives gives the parameters
B,
C,
D,
E,
F. Then, using the constraint
A +
C = 1, determine
A. By substituting these values, the coordinates of the ellipse’s center, the semi-major axis, and the semi-minor axis can be derived. A sample of the ellipse parameter solution is illustrated in
Figure 17. The center coordinates are (504.2759, 335.078), the deviation angle is −35.7533°, the major axis is 116.8405, and the minor axis is 182.3455, the elliptic parametric equation is:
5. Positional Deviation Solving
Any coordinate in the camera coordinate system can be transformed into a coordinate in the world coordinate system through a series of four coordinate transformations. The schematic of the coordinate transformation is shown in
Figure 18. First, translate the coordinate system
O −
X’Y’Z’ so that point
O’ coincides with point
O, with the translation matrix denoted as (
T). Next, rotate the system by angles (
θx), (
θz), and (
θy), align the camera coordinate system with the world coordinate system. The coordinates of any object point
P(
xi,
yi,
zi) in the camera coordinate system can then be transformed into the world coordinate system by leveraging the left and right camera linear imaging models.
The translation matrix is:
This results in the determination of the camera’s external reference matrix [
R T]:
The relationship between the left and right camera pixel coordinate systems and the world coordinate system is as follows:
The collation results in a mapping from the left and right camera pixel coordinate systems to the world coordinate system:
By substituting the camera parameters, the coordinates of the spatial point P in the world coordinate system can be estimated using the coordinates of the pixel points in the left and right cameras via Equation (27). In this equation, the parameters of the left and right cameras are denoted by the subscripts l and r, respectively.
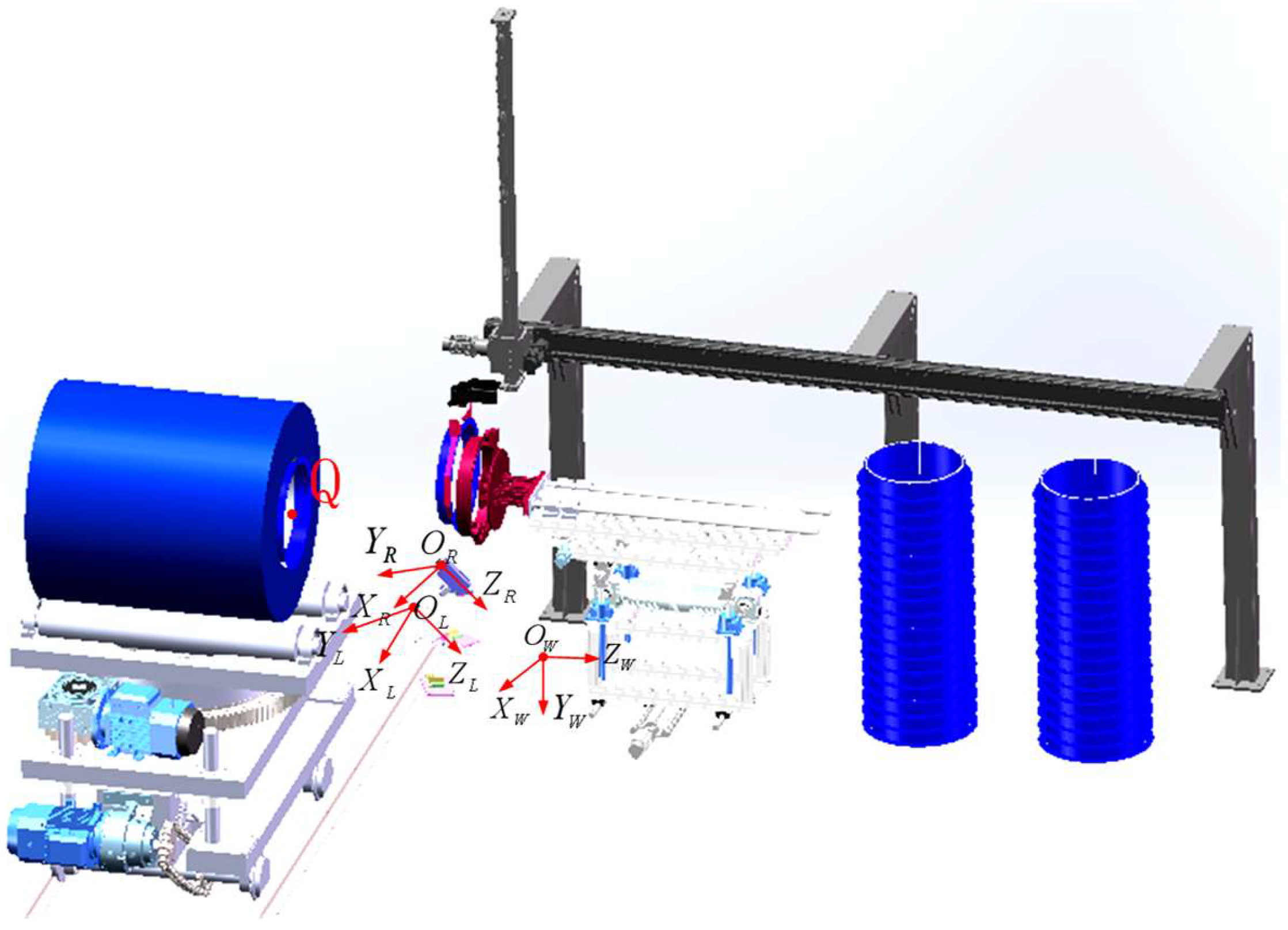
To obtain the three-dimensional coordinates of
Q of the end face of the steel coil in the world coordinate system, a world coordinate system
Ow −
XwYwZw with the same orientation as depicted in
Section 2 is established, with left camera coordinate system
OL −
XLYLZL and right camera coordinate system
OR −
XRYRZR, as shown in
Figure 19.
The attitude angle of the left camera relative to the world coordinate system is defined as (60°, 30°, 30°). Based on the principle of coordinate system translation, the linear imaging models of the left and right cameras can be interconnected to derive the translation matrix
TL, rotation matrix (
ML), and external reference matrix (
MLw) from the left camera coordinate system
OL −
XLYLZL to the world coordinate system
Ow −
XwYwZw.
The external reference matrix from the right camera coordinate system
OR −
XRYRZR to the world coordinate system
Ow −
XwYwZw is (
MRw), which can be obtained from the external reference matrix of the left camera (
MLw) and the translation matrices (
T) and rotation matrices (
R) between the two cameras, and the translation and rotation matrices between the two cameras are obtained from the camera parameter calibration:
The coordinates of the center of the curling eye within the image coordinate systems of the left and right cameras, following target feature extraction, are as follows (
uL,
vL), (
uR,
vR). The coordinates of the center of the eye roll within the world coordinate system are as follows: (
Xw, Yw, Zw).
where (
MLw), (
MRw) are the camera external reference matrices, and (
Ml), (
Mr) are derived from the camera calibration test described in
Section 2.
The mapping relationship between the pixel coordinate systems of the left and right cameras and the world coordinate system, as delineated in Equation (27), elucidates the correlation between the coordinates of the center of the rolled eye within the image coordinate systems of the left and right cameras and the coordinates of the world coordinate system.
Based on the relative positions of the camera coordinate system and the world coordinate system, it is evident that the end face of the steel roll is inclined at an angle to the lens, resulting in the circular mounting hole being imaged as an ellipse within the camera’s field of view. Based on the relative positions of the camera coordinate system and the world coordinate system, it is evident that the end face of the steel roll is inclined at an angle to the lens, resulting in the circular mounting hole being imaged as an ellipse within the camera’s field of view. As illustrated in
Figure 20a, when the end face of the steel coil and the end face of the corner guard are parallel, the angle between the long axis of the ellipse and the horizontal axis is denoted as (
θz), as derived from the camera’s external reference matrix. Conversely, when the end faces of the steel coil and the corner guard are not parallel, the angle between the long axis of the ellipse and the horizontal axis is represented by (
β), with the counterclockwise direction being defined as the positive direction. The camera captures the image and, following image segmentation, yields an elliptical image. Based on the principles of elliptical projection, the length of the long axis corresponds to the pixel length of the roll eye’s diameter, while the length of the short axis represents the projection of the roll eye’s radius in the vertical direction relative to the camera’s shooting direction [
27]. As depicted in
Figure 20b, the angle between the camera’s optical axis and the center axis of the steel coil is denoted as (
α), the angle between the center of the steel coil and the Z-axis is represented by (
γ), and the angle between the camera’s optical axis and the
Z-axis is (
θx). These angles can be derived based on the mathematical relationships illustrated in
Figure 20:
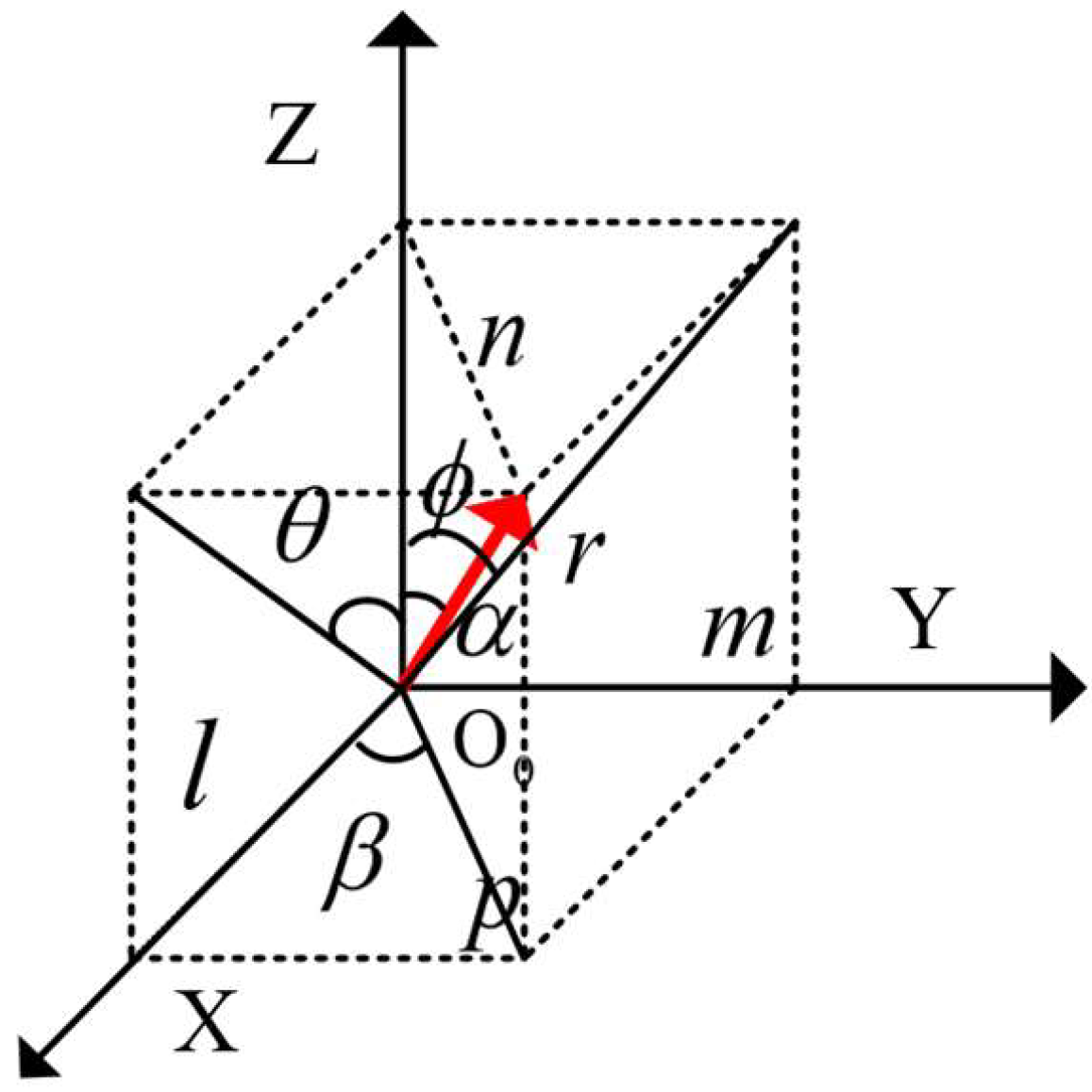
As illustrated in
Figure 21, to establish the positional coordinate system, the direction of each coordinate axis was aligned with that of the preceding world coordinate system. The arrow in the figure denotes the direction of the steel coil’s axis, with the angle between this axis and the
Z-axis being (α). The angle of inclination of the ellipse’s long axis is (
β), and the pitch angle (
θ) and the deflection angle (
φ) are as indicated in the figure. Let the length of the axis be (
r), with its projections on the
x,
y, and
z axes being (
l), (
m), and (
n), respectively. The relationship between the pitch angle (
θ) and the deflection angle (
φ) with respect to (
α) and (
β) is as follows:
7. Conclusions
This paper presents a novel scheme for the precise measurement of the positional parameters of the roll eye of a steel coil using visual detection technology. Initially, the transformation relationships between four coordinate systems were derived based on the camera imaging principle. This enabled the determination of the internal and external parameter matrices, which were then rotated to achieve camera calibration, ensuring high-precision image acquisition. Subsequently, image segmentation was performed using a Mask R-CNN network, complemented by spatial vector segmentation in the RGB color space. This approach accurately extracted the steel coil roll-eye region from complex scenes, effectively addressing the challenge of target region recognition amidst intricate backgrounds. Furthermore, the ellipse parameter extraction technique was integrated with the least-squares method to construct a chi-square equation from the elliptic curve equation. This facilitated the determination of the ellipse’s inclination and center position within the image coordinate system. By combining the camera imaging principle with the linear imaging models of the left and right cameras, the scheme successfully resolved the issue of accurately measuring the positional attitude parameters of the steel coil roll eyes.
The experiments demonstrated that the system design effectively addressed the technical challenges in image processing related to the detection of the positional attitude of steel coil roll eyes. The mask image obtained through the Mask R-CNN-based image segmentation technique exhibited high fidelity, resulting in minimal errors in both ellipse parameter solving and overall visual detection. Specifically, the error in ellipse parameter extraction in the u-direction of the coordinate system was 0.49, while in the v-direction, it was 0.47. The maximum error in the deflection angle was 0.45°. In the actual steel coil roll eye positional pose detection experiments, the maximum deviations for the pitch angle, deflection angle, and center coordinates were 2.17°, 2.24°, 3.53 mm, 4.05 mm, and 4.67 mm, respectively, meeting the accuracy requirements for automatic docking installation. In summary, the proposed machine vision-based steel coil eye position detection method significantly enhances the precision of steel coil eye position detection and provides robust technical support for the automated installation process of steel coils.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}