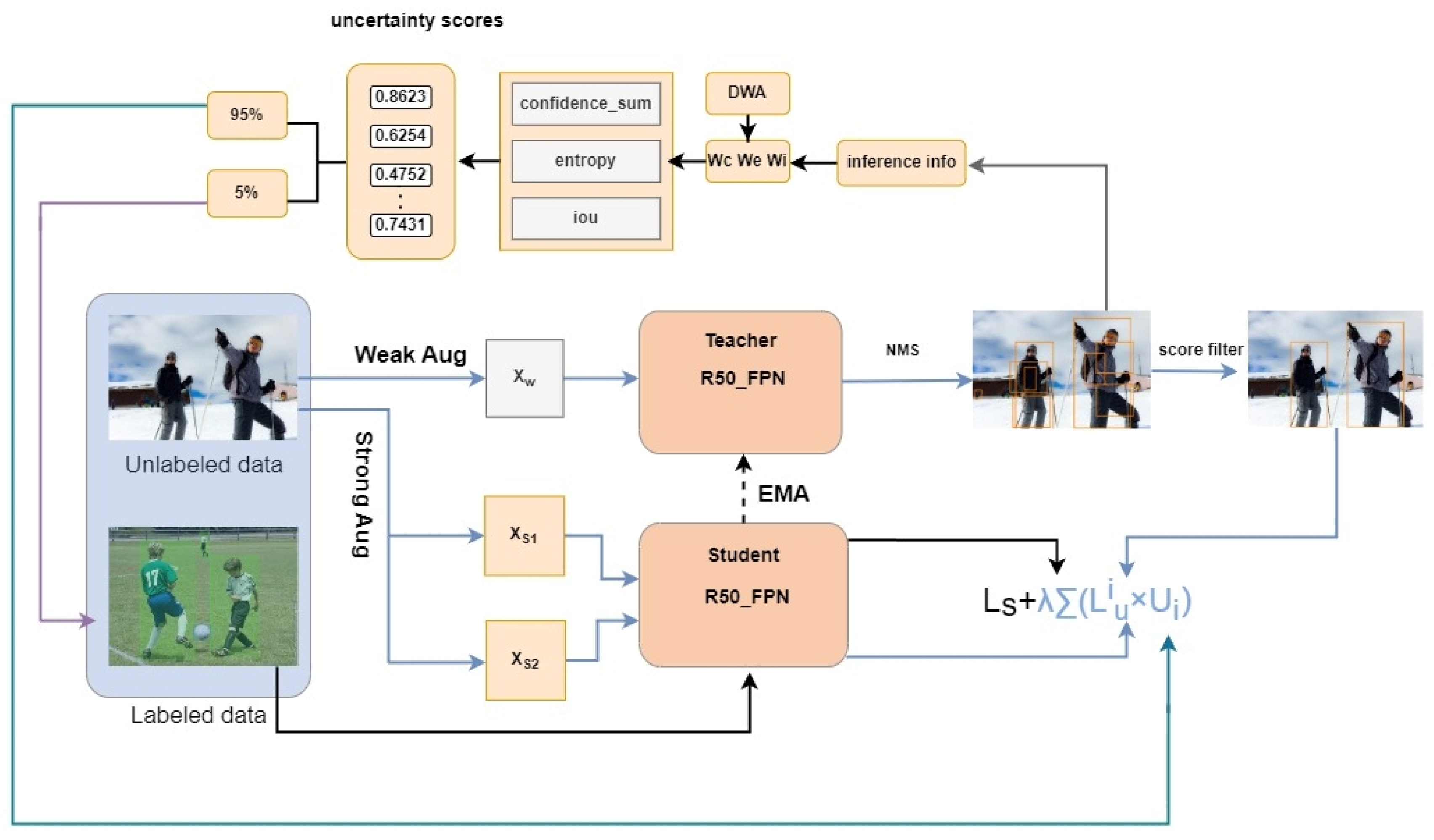
3.2.1. Multi-Metric and Dynamic Weighting Strategy
In order to improve the ability of SSOD to select the most valuable samples from unlabeled data
, a dynamically adjusted active learning framework is proposed. The framework adopts the uncertainty-driven sampling strategy widely used in AL [
26,
27]. Specifically, the detection results of each unlabeled sample
are evaluated through the trained model to calculate the uncertainty of the sample. To this end, three core indicators (
,
, and
) are introduced in this paper to quantify the uncertainty of the detection results. Building on this foundation, a dynamic weight adjustment (DWA) strategy is proposed, allowing the weight of each metric to adapt dynamically based on sample characteristics. Therefore, the unlabeled data samples are sorted in descending order according to the uncertainty scores, and a portion of the samples with the highest scores are selected for manual labeling. Next, the specific implementation of the indicator calculation and DWA strategy will be introduced in detail.
Next, the specific implementation of indicator calculation and weight adjustment strategy will be introduced in detail.
First, the confidence level reflects the degree of confidence of the model in its predictions. It is necessary to calculate the sum of the confidence scores of each detected object (bounding box). This indicator is calculated as follows:
where
is the confidence score of the
i-th bounding box predicted by the TN, and
N is the number of bounding boxes. Since the bounding boxes left at the end are those left after a series of post-processing (including NMS), the higher the confidence score, the more certain the model is that the detection result is correct. Since the bounding boxes left at the end are those left after a series of post-processing (including NMS), the higher the confidence score, the more certain the model is that the detection result is correct.
Secondly, uncertainty reflects the uncertainty of the model when making classifications. Generally, the larger the classification entropy of an image, the flatter the model’s prediction distribution (i.e., the model’s probability estimates for multiple categories are similar), and the higher the uncertainty. Then, samples with high classification entropy indicate that the model is more uncertain about these samples. This indicator calculates the classification entropy for each detected bounding box and then calculates the sum of the classification entropies of all bounding boxes. The calculation method is as follows:
where
is the confidence score of the
i-th bounding box predicted by the TN, and
N is the number of bounding boxes.
Finally, the bounding box overlap (IoU) measures the degree of overlap between two bounding boxes. For each image, we compute the IoU between each pair of detected bounding boxes. Then, the average of these IoUs is calculated. A high IoU average value indicates that the detected bounding boxes overlap heavily with each other, which may mean that the model is not localizing well enough on that image.
For each pair of bounding boxes, we first calculate their IoU, which is the ratio of the intersection area to the union area, as follows:
Among them,
A and
B are two bounding boxes. On this basis, the average contribution of IOU of all bounding box pairs is calculated:
where Io
U(
,
) is the IoU between the
i-th and
j-th bounding boxes,
N is the number of bounding boxes, and
M is the number of bounding box pairs.
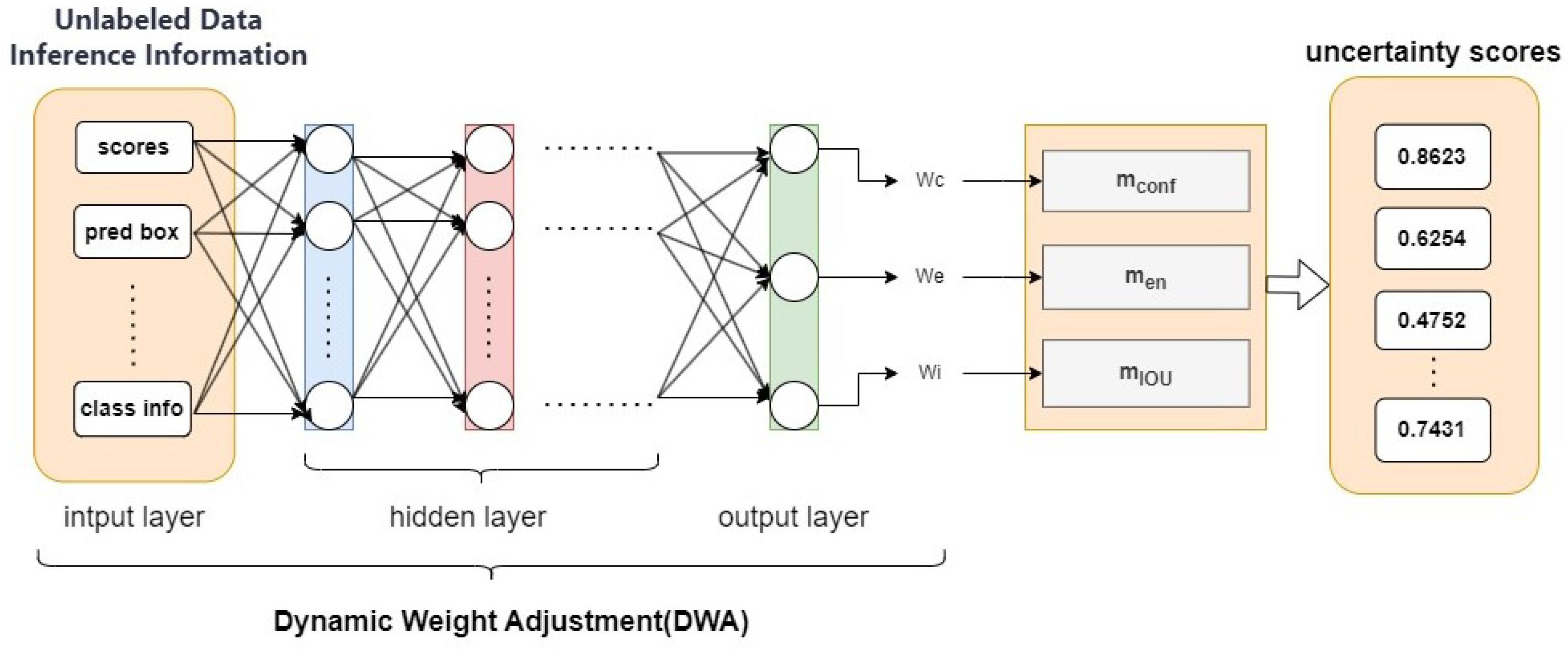
To address the heterogeneous emphasis of uncertainty measurements across diverse image samples, this paper proposes a DWA Network based on model performance distribution to adaptively optimize uncertainty metric weights for different samples. The core insight lies in the recognition that a single uncertainty metric fails to comprehensively capture sample informativeness. For instance, while classification entropy reflects prediction uncertainty, it lacks sensitivity to spatial distribution characteristics (e.g., Intersection over Union, IOU). By integrating multiple metrics (including confidence scores, classification entropy, and IOU) with a dynamic weighting mechanism, our approach enables holistic uncertainty assessment. This multi-metric synthesis effectively models sample complexity, thereby enhancing sample selection precision. As illustrated in
Figure 2, the DWA network processes inference information from the teacher model (TDN) for unlabeled samples (confidence, classification entropy, IOU, etc.), employs hidden layers to extract inter-feature relationships and patterns, thereby capturing category complexity and model prediction status. The network ultimately outputs a weight vector that dynamically modulates category-specific weights during training. This mechanism adaptively prioritizes categories with higher classification difficulty or lower confidence based on real-time model performance, thereby optimizing overall model efficacy through focused learning of critical categories.
The integrated loss function proposed in this study comprises two complementary components: category prediction loss and weighted loss. The category prediction loss quantifies prediction errors for each class through focal loss, while the weighted loss dynamically recalibrates class-specific contributions by incorporating adaptive weighting coefficients derived from model performance. This dual-component design empowers the network to autonomously optimize weight assignments through gradient-driven learning guided by real-time model behavior. Specifically, categories exhibiting lower confidence scores or higher error rates are automatically assigned elevated weighting values, thereby amplifying their influence during backpropagation to prioritize underperforming categories in the training process. Such loss formulation strategically directs optimization focus toward challenging samples, effectively enhancing the model’s discriminative capability on hard-to-classify categories through performance-aware gradient modulation and targeted parameter refinement.
Category prediction loss: the focal loss used in this paper is shown in Equation (
4), which is used to measure the prediction error of the model for each category.
Weighted loss: The loss of each category is adjusted according to the weight of the category, reflecting the attention paid to different categories. For example, the weight of the category can be dynamically adjusted according to its classification entropy or error rate, and the weight of the low-confidence category is increased, and vice versa.
Among them, is the weight of each category predicted by the neural network, and is the loss of the corresponding category.
By dynamically adjusting the weights, the DWA network can focus more attention on categories or samples where the model performs poorly during training. This mechanism can accelerate the optimization of model performance, especially when the categories are unbalanced or some categories are difficult to classify.
Finally, the uncertainty score of the unlabeled sample is a comprehensive score after the weighted average of the three indicators, and its formula is as follows:
Among them,
,
,
are weight coefficients, which are optimized through the DWA network in
Figure 2 as (
,
,
) = DWA (scores, pred box, …, class info) with trainable hidden layers. This allows weights to be calculated based on the current sample performance distribution to dynamically focus on different sample evaluation priorities.
The above three indicators can represent the uncertainty score of an image after adaptive weighted fusion. Compared with fixed weighting, the weights generated for us by the dynamically adjusted weight network based on the model performance distribution can better focus on the indicators emphasized by each unlabeled sample and generate a more valuable uncertainty score for the network.
3.2.2. Pattern Mining for Full Unlabeled Data
In order to further explore the learnable modes of unlabeled samples, this paper proposes a novel sample loss calculation method to fully utilize the remaining unlabeled samples during training, thereby improving the learning efficiency of semi-supervised object detectors. According to the existing active learning framework, the training value of unlabeled samples is measured by calculating the uncertainty score. Theoretically, the higher the uncertainty score
, the greater the potential of the sample to improve model performance. However, previous studies [
26,
27] focused solely on selecting unlabeled samples with high uncertainty scores for manual annotation. This strategy has certain limitations in terms of optimization efficiency: although many low-scoring samples have small individual contributions, their information accumulation still has a significant effect on model training due to their large number, resulting in the problem of insufficient utilization of unlabeled data.
Based on the above analysis, this paper designs an improved sample loss function (Formula (16)) from a new perspective, aiming to directly integrate the uncertainty score of unlabeled samples into the loss calculation. The core idea is that no matter how high or low the uncertainty score is, every unlabeled sample has potential value in training. By adjusting the sample loss weight
during training, even samples with low uncertainty scores can have a positive impact on model learning. This method can make full use of the potential contribution of the remaining low-scoring samples, thereby realizing pattern mining of full unlabeled data and significantly improving training efficiency and model performance.
Among them, is the unsupervised loss of each unlabeled image, N is the number of images in the unlabeled data, and is the weight assigned to each unlabeled image.
The core of the method proposed in this paper is to optimize the loss function so that the uncertainty score of unlabeled samples is involved in the calculation of the total loss. During the training process, the unlabeled data are first predicted by the existing model, and the uncertainty score of each sample is calculated. Specifically, the calculation of the uncertainty score is consistent with the above method. Combining indicators such as confidence, classification entropy, and bounding box overlap (as shown in Formulas (10)–(13)), an uncertainty score
is calculated for each unlabeled sample using Formula (15). This score is also the weight value assigned to the loss. For ease of calculation, we use the sigmoid activation function to normalize the uncertainty score to between 0 and 1.
where
is a set containing the uncertainty scores of unlabeled samples.
In this way, the uncertainty score is normalized into a weight between 0 and 1. Based on this, an improved total loss function of the SSOD network is proposed:
where
is the supervised loss of labeled data,
is the unsupervised loss of each unlabeled image,
N is the number of unlabeled data images,
is the weight obtained by normalizing the detection value score of each unlabeled image, and
is an adjustment parameter used to balance the contribution of labeled data and unlabeled data to the total loss.
The improved loss function explicitly links the detection value of unlabeled samples with their loss by introducing the weight factor . High-uncertainty samples will contribute more to the total loss and thus receive more attention, while low-uncertainty samples will also participate in model training with a smaller weight, thus ensuring the full utilization of unlabeled data.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}