
YOLO-WAD for Small-Defect Detection Boost in Photovoltaic Modules


Abstract
1. Introduction
- (1)
- Inconsistency between different feature scales is still a difficult problem, especially in multi-scale target detection, meaning that how to effectively fuse different levels of features still needs further research;
- (2)
- Small targets occupy fewer pixels in an image, their feature expression ability is weak, and they are easily overwhelmed by background information, leading to a decrease in detection accuracy;
- (3)
- In practical industrial applications, defect detection systems need to have high real-time performance, while some existing deep learning models still have room for improvement in terms of computational efficiency and real-time performance.
- (1)
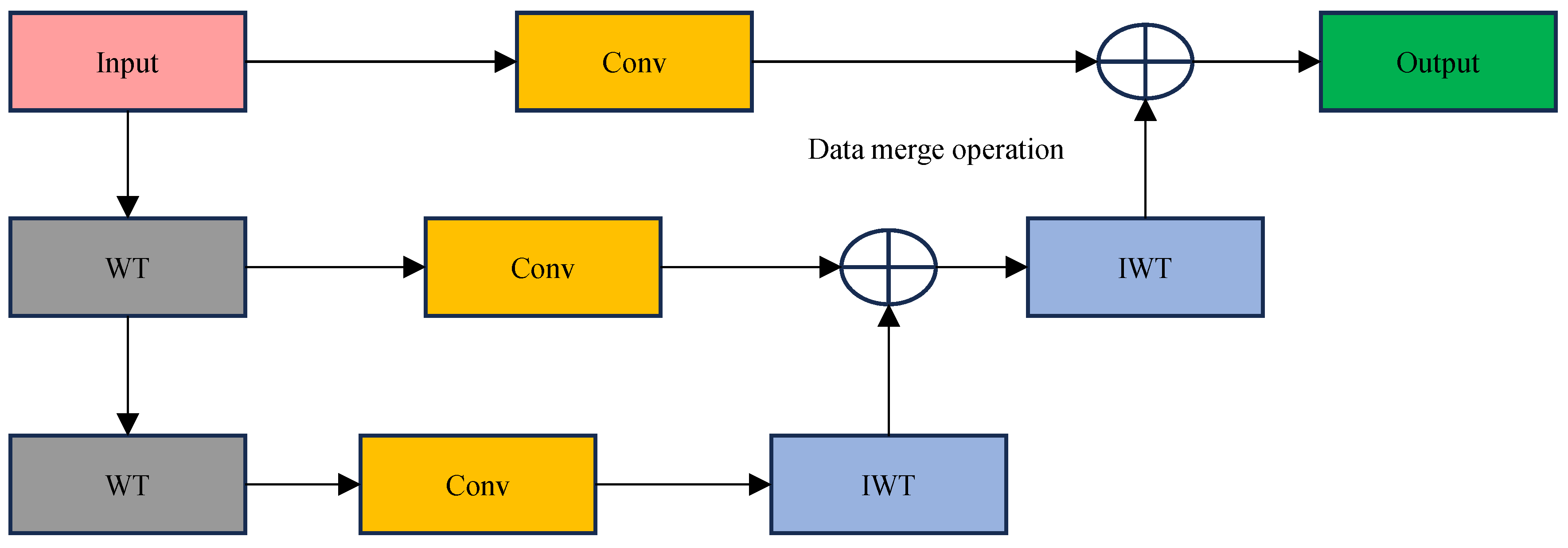
- Instead of C2f, we use C2f-WTConv in the backbone part, and the main purpose of WTConv is to improve the accuracy of small-target detection for PV modules by processing different frequency bands of the input data, using the wavelet transform, expanding the convolutional sensory field through a multi-frequency response, and performing small-kernel convolution operations in different frequency ranges.
- (2)
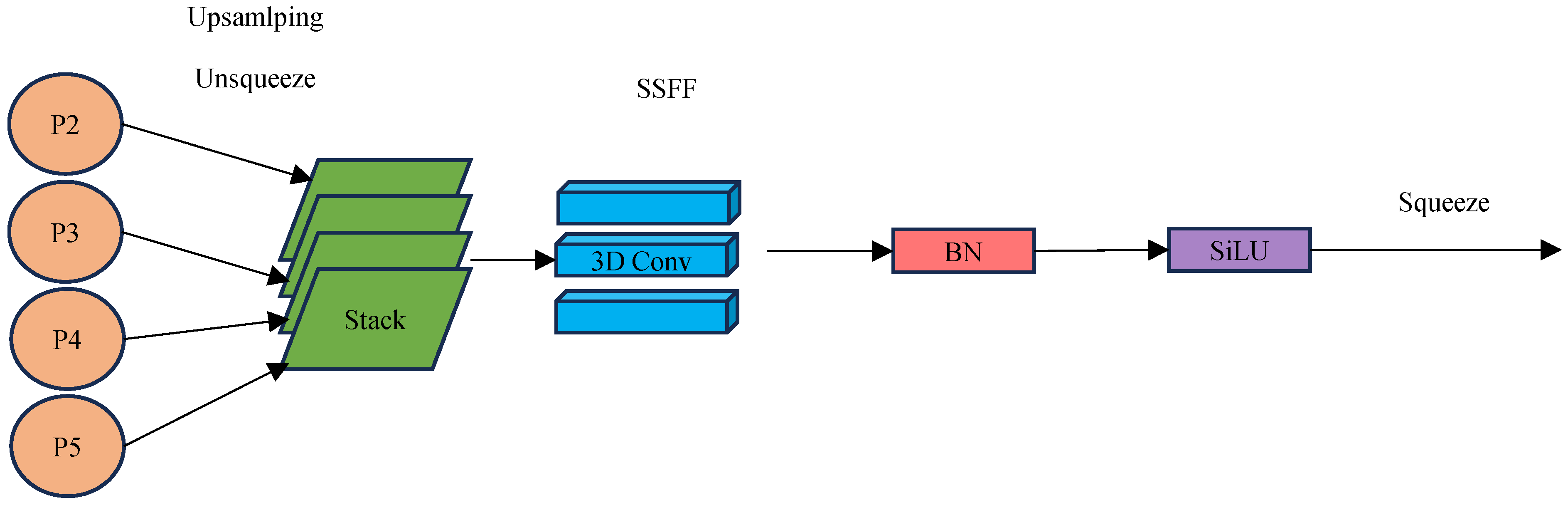
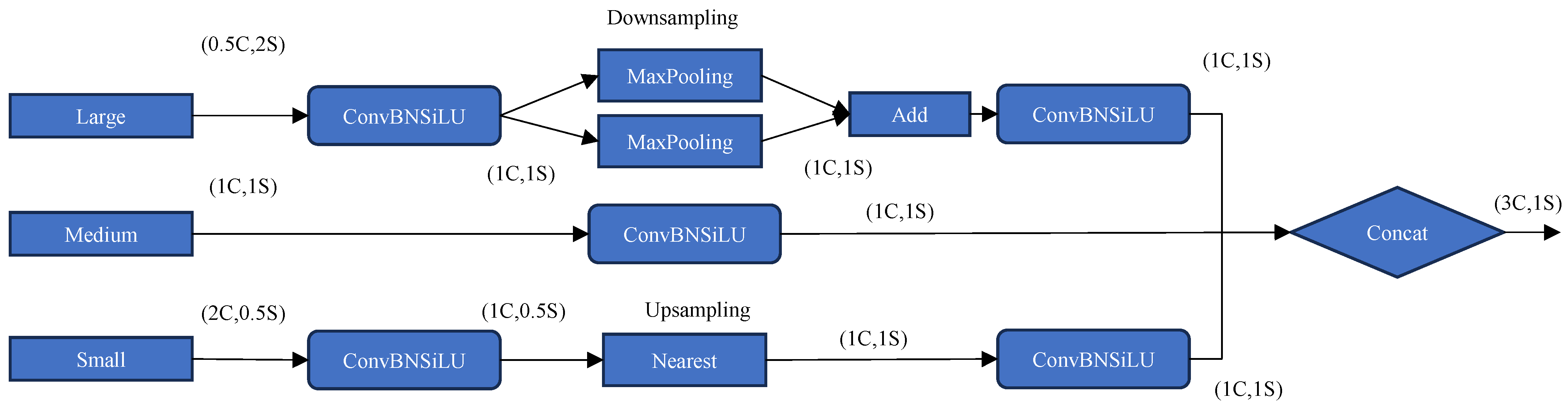
- We apply an attention scale sequence fusion (ASF) structure to the neck layer, which further strengthens the ability of the model to recognize the details of small objects. By merging spatial and multi-scale features, the ASF structure efficiently fuses the output characteristics of different layers (P2, P3, P4, and P5) extracted from the backbone network. This efficient feature fusion strategy enhances the model’s ability to detect small objects and improves the overall feature representation of the model.
- (3)
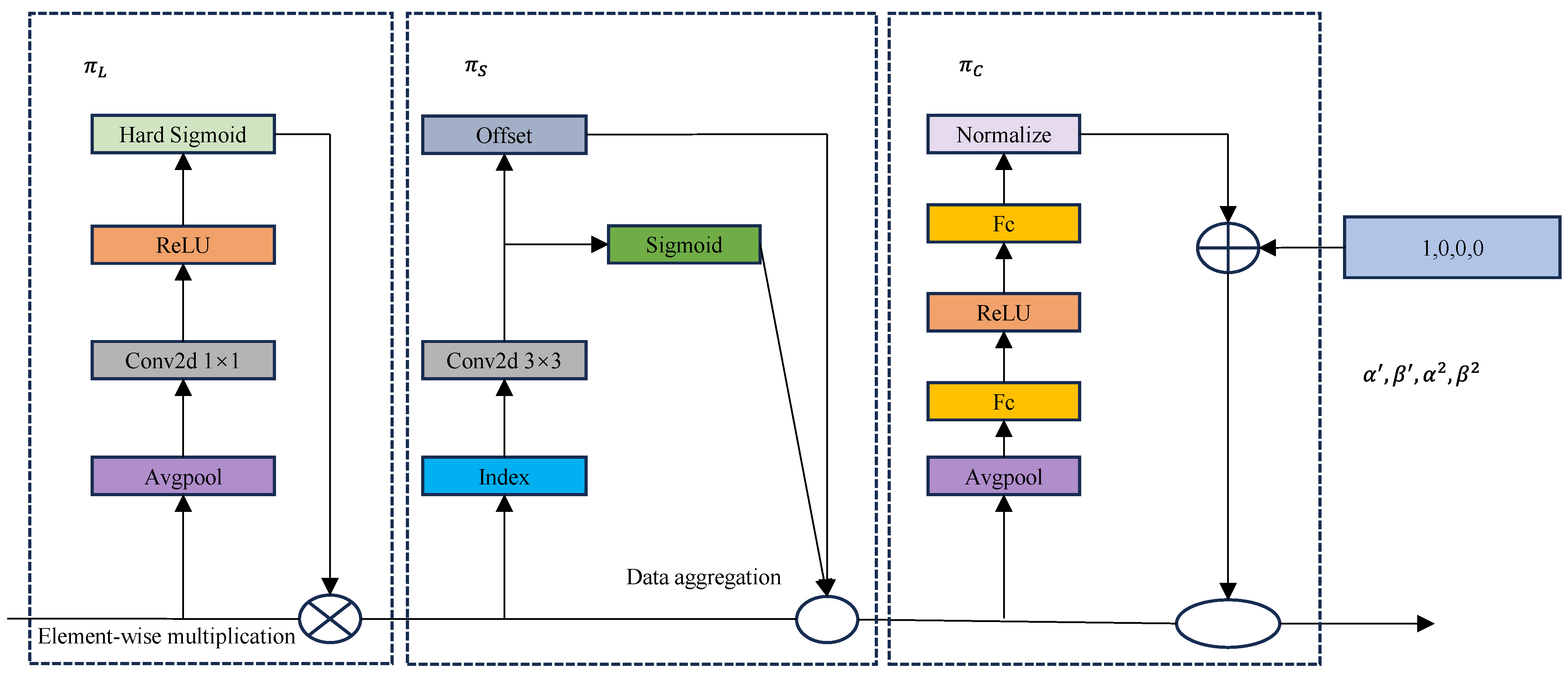
- In the detection head part, we introduce the dynamic head framework DyHead, which combines the object detection head with the attention mechanism to enhance the model’s ability to classify and localize objects and better detect the absence of small targets, thus improving the detection accuracy.
- (4)
- We integrate the C2f-EMA structure into the network using an efficient multi-scale attention module embedded into C2f. This enhancement improves feature extraction by redistributing feature weights, prioritizing relevant features and spatial details across image channels. As a result, it enhances the network’s ability to detect targets of different sizes.
2. YOLO-WAD Algorithm
2.1. YOLO-WAD Structure
2.2. Wavelet Transform Convolution (WTConv)
2.3. Attentional Scale Sequence Fusion (ASF)
2.4. Dynamic Detection Head
2.5. Embedding Efficient Multi-Scale Attention Mechanisms in C2f
3. Results
3.1. Experimental Environment
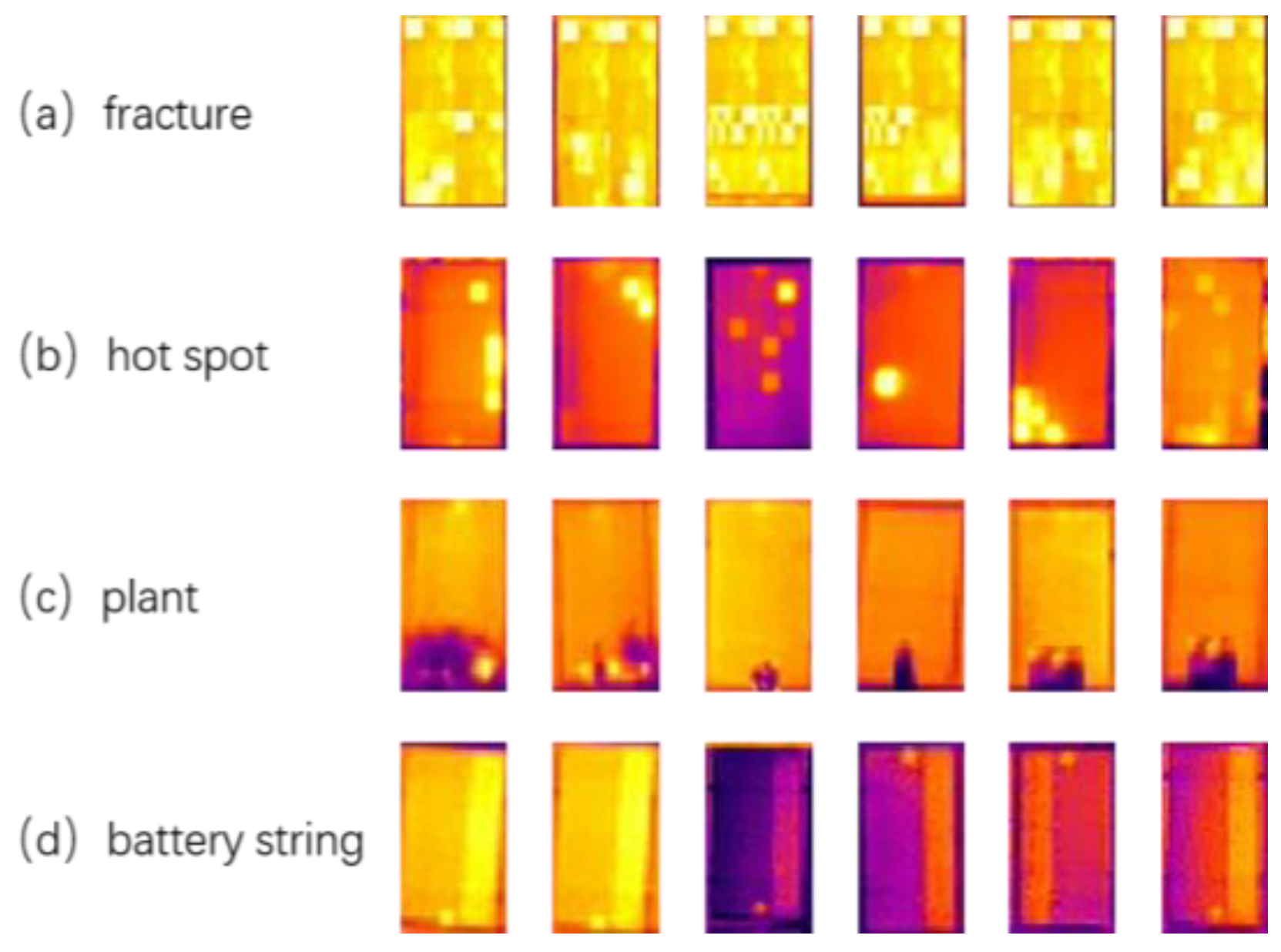
3.2. Datasets
3.3. Evaluation Indicators
3.4. Experimental Results and Analysis
3.4.1. Comparison with Other Algorithms
3.4.2. Visualization and Analysis
3.4.3. Ablation Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Full name |
| C2f | CSP bottleneck with two convolutions |
| WTConv | Wavelet transform convolution |
| ASF | Attentional scale sequence fusion |
| EMA | Efficient multi-scale attention mechanism |
| DyHead | Dynamic head |
| TFE | Temporal feature extraction |
| SSFF | Spatial-scale feature fusion |
| BN | Batch normalization |
| PV | Photovoltaic |
| SiLU | Sigmoid-weighted linear unit |
| C2f-EMA | CSP bottleneck with two convolutions–efficient multi-scale attention |
| C2f-WTConv | CSP bottleneck with two convolutions–wavelet transform convolution |
References
- Zhao, S.; Chen, H.; Wang, C.; Zhang, Z. SSN: Shift suppression network for endogenous shift of photovoltaic defect detection. IEEE Trans. Ind. Inform. 2023, 20, 4685–4697. [Google Scholar] [CrossRef]
- Tsai, D.M.; Wu, S.C.; Chiu, W.Y. Defect detection in solar modules using ICA basis images. IEEE Trans. Ind. Inform. 2012, 9, 122–131. [Google Scholar] [CrossRef]
- Dhimish, M.; d’Alessandro, V.; Daliento, S. Investigating the impact of cracks on solar cells performance: Analysis based on nonuniform and uniform crack distributions. IEEE Trans. Ind. Inform. 2021, 18, 1684–1693. [Google Scholar] [CrossRef]
- Lu, C.; Zong, Y.; Zheng, W.; Li, Y.; Tang, C.; Schuller, B.W. Domain invariant feature learning for speaker-independent speech emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2217–2230. [Google Scholar] [CrossRef]
- Tsai, D.M.; Molina, D.E.R. Morphology-based defect detection in machined surfaces with circular tool-mark patterns. Measurement 2019, 134, 209–217. [Google Scholar] [CrossRef]
- Peli, T.; Malah, D. A study of edge detection algorithms. Comput. Graph. Image Process. 1982, 20, 1–21. [Google Scholar] [CrossRef]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3588–3597. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet convolutions for large receptive fields. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2025; pp. 363–380. [Google Scholar]
- Kang, M.; Ting, C.M.; Ting, F.F.; Phan, R.C.W. ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 2024, 147, 105057. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Wang, H.; Yang, H.; Chen, H.; Wang, J.; Zhou, X.; Xu, Y. A Remote Sensing Image Target Detection Algorithm Based on Improved YOLOv8. Appl. Sci. 2024, 14, 1557. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar]
- Gannett, P.M.; Ye, J.; Ding, M.; Powell, J.; Zhang, Y.; Darian, E.; Daft, J.; Shi, X. Activation of AP-1 through the MAP kinase pathway: A potential mechanism of the carcinogenic effect of arenediazonium ions. Chem. Res. Toxicol. 2000, 13, 1020–1027. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2025; pp. 1–21. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 1–6. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Precision | Recall | mAP@0.5 | Fracture | Hot Spot | Plant | Battery String |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 91.38 | 84.96 | 91.57 | 99.2 | 75.38 | 92.2 | 99.5 |
| YOLOv9s | 85.38 | 89.44 | 92.7 | 99.4 | 78.1 | 93.7 | 99.5 |
| YOLOv10n | 90.7 | 88.14 | 91.5 | 99.3 | 76.8 | 90.5 | 99.5 |
| YOLOv11 | 89.89 | 88.41 | 91.6 | 99.3 | 75.2 | 92.4 | 99.5 |
| RT-DETR-l | 76.6 | 76.7 | 81.4 | 97.5 | 64.6 | 86.7 | 76.7 |
| RT-DETR-x | 79 | 76.5 | 81.4 | 98.5 | 61.9 | 86.7 | 78.4 |
| RT-DETR-Resnet50 | 82.4 | 82.5 | 86 | 99.2 | 68.5 | 88 | 88.4 |
| RT-DETR-Resnet101 | 86.5 | 81 | 87.5 | 98.8 | 71 | 87.6 | 92.7 |
| YOLO-WAD (ours) | 93.4 | 92.7 | 95.6 | 99.7 | 86.3 | 97.5 | 99.5 |
| C2f-WTConv | ASF | C2f-EMA | DyHead | Precision (%) | Recall (%) | mAP@0.5 (%) | Hot Spot (%) |
|---|---|---|---|---|---|---|---|
| 90.7 | 88.14 | 91.5 | 76.8 | ||||
| ✓ | 91.8 | 89.4 | 92.7 | 80.2 | |||
| ✓ | 92.2 | 90.2 | 93.0 | 81.7 | |||
| ✓ | 91.9 | 91.3 | 93.3 | 82.1 | |||
| ✓ | 92.4 | 90.5 | 93.4 | 81.8 | |||
| ✓ | ✓ | 92.8 | 91.6 | 94.3 | 82.6 | ||
| ✓ | ✓ | ✓ | 93.1 | 92.3 | 95.2 | 84.7 | |
| ✓ | ✓ | ✓ | ✓ | 93.4 | 92.7 | 95.6 | 86.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Yun, W.; Xie, G.; Zhao, Z. YOLO-WAD for Small-Defect Detection Boost in Photovoltaic Modules. Sensors 2025, 25, 1755. https://doi.org/10.3390/s25061755
Wang Y, Yun W, Xie G, Zhao Z. YOLO-WAD for Small-Defect Detection Boost in Photovoltaic Modules. Sensors. 2025; 25(6):1755. https://doi.org/10.3390/s25061755
Chicago/Turabian StyleWang, Yin, Wang Yun, Gang Xie, and Zhicheng Zhao. 2025. "YOLO-WAD for Small-Defect Detection Boost in Photovoltaic Modules" Sensors 25, no. 6: 1755. https://doi.org/10.3390/s25061755
APA StyleWang, Y., Yun, W., Xie, G., & Zhao, Z. (2025). YOLO-WAD for Small-Defect Detection Boost in Photovoltaic Modules. Sensors, 25(6), 1755. https://doi.org/10.3390/s25061755