1. Introduction
Over the past few decades, many countries have experienced a significant increase in the proportion of elderly individuals, reflecting the global trend of population aging [
1]. According to data from the World Health Organization, the global population aged 60 years and older is projected to reach approximately 2 billion by 2050 [
2]. China’s elderly population aged 60 years and above had reached 212 million by the end of 2014, and is expected to reach 358 million by 2030, accounting for more than 25.3% of the total national population [
3]. This presents severe challenges in enhancing the quality of life of the elderly and addressing their health and well-being. The monitoring of daily activities and habits of elderly people is crucial for assessing their overall health status, monitoring disease development, and providing personalized care services [
4,
5]. However, the provision of continuous private care has obvious effects on the independence and psychological status of the elderly, and it also imposes a financial burden on families and society.
Traditional monitoring methods, such as video surveillance and routine health check-ups, provide extensive coverage, but also present the challenges of privacy concerns device maintenance, and data processing [
6,
7]. Acoustic scene recognition (ASR), a promising alternative to address these challenges [
8], can accurately detect and classify different acoustic scenes by analyzing ambient sound data in real time, thereby ensuring comprehensive monitoring of the surroundings of elderly individuals [
9]. This approach enhances real-time safety monitoring while also delivering detailed scene insights, reducing the dependence on visual data and addressing privacy concerns more effectively [
10,
11].
With advances in artificial intelligence technology, machine and deep learning have been extensively applied in the field of ASR [
12,
13]. Traditional machine learning algorithms, such as support vector machine (SVM), random forest (RF), decision trees, and k-nearest neighbors (k-NN), have been utilized in this domain [
14,
15]. For instance, various feature extraction algorithms, such as Mel-frequency cepstral coefficient (MFCC), Gammatone Cepstral Coefficients (GTCCs), and Naive Bayes (NB), were compared with machine learning algorithms for acoustic event detection across five different acoustic environments [
16]. The results indicated that most algorithm combinations performed well, with the GTCC and k-NN combination achieving the best performance. Lei and Mak [
17] designed an energy-efficient sound event detector that utilized sound event partitioning (SEP) techniques and employed SVM for classification. Abidin et al. [
18] proposed an acoustic scene classification method that combines local binary patterns (LBPs) with RF. They first applied the constant-Q transform (CQT) to audio signals by dividing the spectrum into multiple sub-bands to capture local spectral features. The LBP was then used to extract these time–frequency features, and RF was employed for classification, achieving a classification accuracy of 85.0%. Although these methods, which rely on manually extracted features to classify acoustic scenes, have demonstrated good performance in certain tasks, their ability to capture complex patterns and high-dimensional features in sound data remains limited.
Deep learning algorithms, particularly convolutional neural networks (CNNs), automated feature extraction, and end-to-end learning, enable networks to extract hierarchical features from raw sound data and capture local patterns and textures in audio signals. This significantly enhances the recognition accuracy [
19,
20]. Vivek et al. [
21] designed a sound classification system using an automatic hearing aid switching algorithm, thereby enabling traditional hearing aids to adapt to varying sound environments. This system utilized features such as MFCC, Mel spectrogram, and chroma, and trained a CNN to classify five sound categories with high accuracy and efficiency while incurring low memory cost. Zhu et al. [
22] proposed a deep CNN architecture for environmental sound classification that processes raw audio waveforms and employs a parallel CNN to capture features at different temporal scales. The architecture also incorporates direct connections between layers to improve information flow and mitigate the vanishing gradient problem. Basbug and Sert [
23] integrated the spatial pyramid pooling (SPP) method within CNN convolutional layers to aggregate local features, using MFCC, Mel energy, and spectrograms as input features. The results showed that the CNN-SPP architecture with spectrogram features improved classification accuracy. Furthermore, Tripathi and Mishra [
24] introduced a novel model for environmental sound classification, incorporating an attention mechanism that focuses on semantically relevant frames in spectrograms and learning spatiotemporal relationships within the signal. This study on the ESC-10 and DCASE 2019 Task-1(A) datasets demonstrated improvements of 11.50% and 19.50%, respectively, over baseline models. These discussions highlight that applying deep learning techniques can provide a theoretical foundation and technological support for ASR in elderly monitoring, thereby offering more precise safety surveillance.
Additionally, with the advancement of Internet of Things (IoT) technologies and improvement in the computational power and storage resources of edge devices, it is feasible to deploy deep learning models on these devices [
25,
26]. Acoustic scene changes can be detected efficiently by performing real-time inferences on edge devices, thereby providing more accurate and timely monitoring services. This approach reduces the dependency on cloud computing, thus lowering data transmission latency and enhancing data security. Strantzalis et al. [
27] designed an edge AI system and developed various CNN models, which, after quantization and compression, were deployed on microcontroller units (MCUs) for real-time validation, achieving the detection of different sound signals. Hou et al. [
28] introduced an innovative, compact, and low-power intelligent microsystem that leverages a CNN algorithm for sound-event recognition. With an average accuracy of over 92.50%, this system is well-suited for applications in home IoT and acoustic environment monitoring, particularly for enhancing safety. Yuh and Kang [
29] developed a real-time sound monitoring system targeting elderly home care using a 2D CNN classifier; they deployed the system in real-world settings, achieving an accuracy of 95.55%. Chavdar et al. [
30] employed a CNN to design a real-time remote acoustic monitoring system for assisted living scenarios, which was implemented on miniature MCUs and demonstrated effective detection performance.
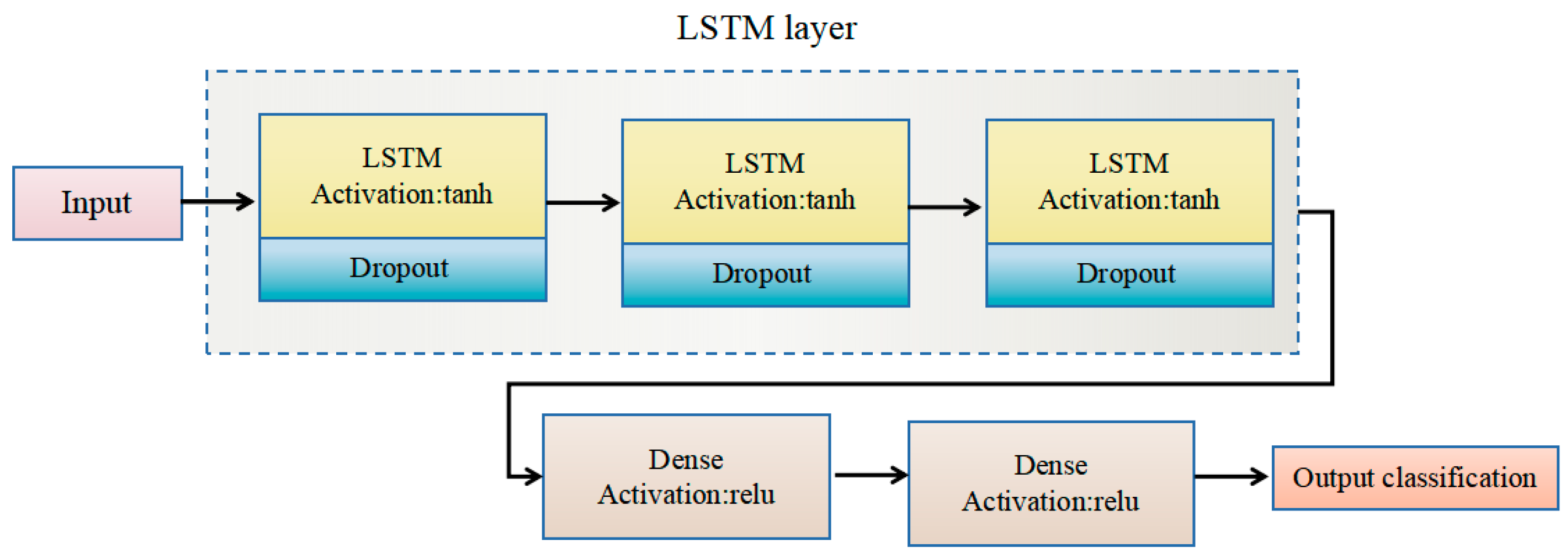
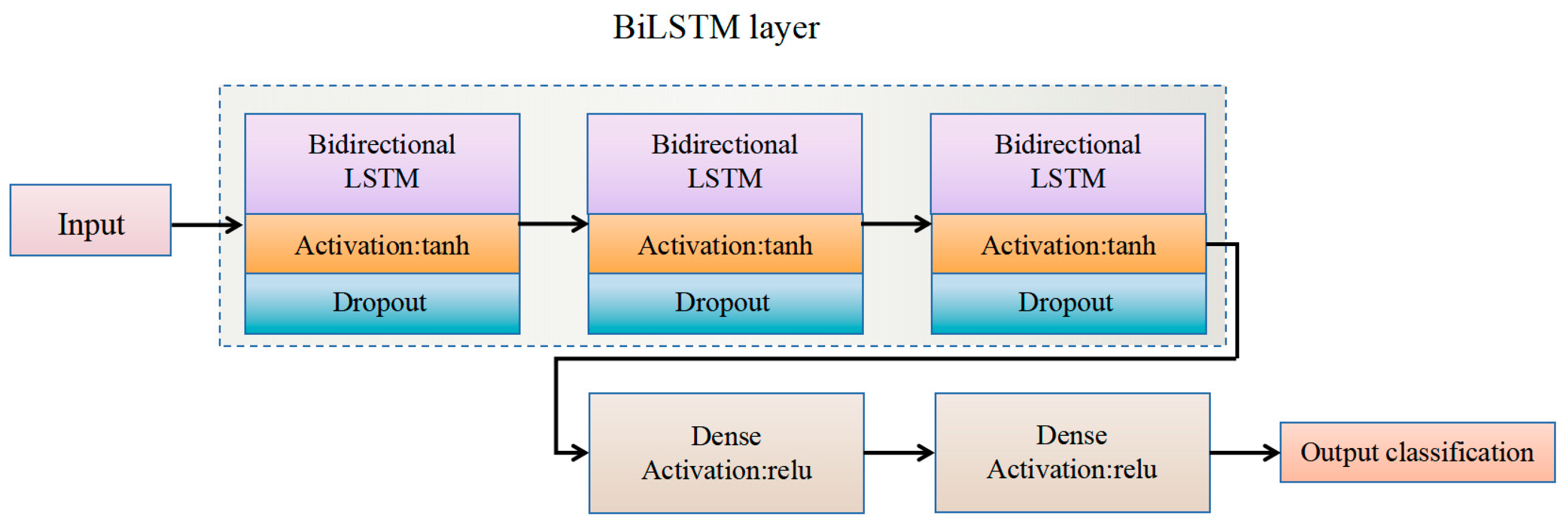
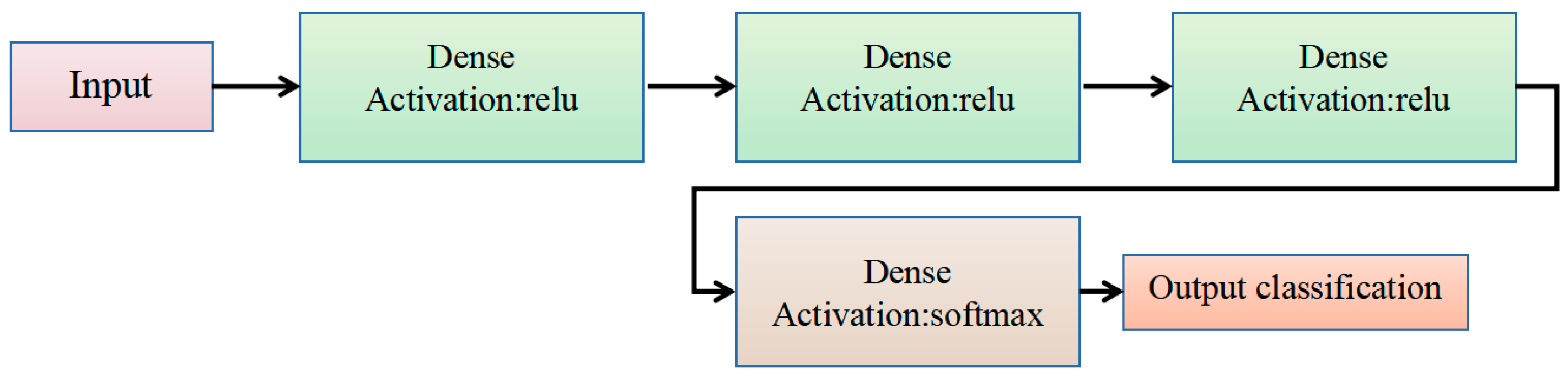
This paper presents the design and implementation of an ASR system for elderly individuals that combines edge computing with deep learning technology. The system consists of edge devices equipped with multiple microphones, a wearable lanyard, and a small power supply, ensuring that the system is integrated into daily activities of the elderly and does not disrupt their routine. The edge devices are responsible for executing real-time audio processing and feature extraction to capture relevant acoustic features and performs real-time inference and recognition through algorithms. We developed four different deep learning models (CNN, long short-term memory (LSTM), bidirectional LSTM (BiLSTM), and deep neural network (DNN)) to analyze various acoustic features, enabling high-precision and real-time ASR. To optimize the deployment of models on edge devices, model quantization techniques were employed to effectively reduce computational complexity and memory usage. Additionally, the system is suitable for everyday wear, enhancing portability, and by processing data locally, it maximizes energy efficiency, reduces latency, and improves data security.
The contributions of this study are as follows:
- (1)
By processing data locally at the edge and performing real-time audio analysis and recognition, this approach enhances system responsiveness while also strengthening security and privacy, which is crucial for sensitive applications such as elderly care.
- (2)
We developed four deep learning models and applied model quantization techniques to reduce their complexity and memory usage, making them more efficient for deployment.
- (3)
The wearable design, featuring lightweight components, ensures ease of use of the system for the elderly, enabling its seamless integration into their daily activities while continuously providing ASR.
The remainder of the paper is organized as follows:
Section 2 reviews related work.
Section 3 presents the overall system architecture and foundational design of the system components.
Section 4 discusses the data collection and preprocessing.
Section 5 and
Section 6 present the model construction methods and an analysis of the results, respectively. Finally,
Section 7 summarizes our research findings and outlines future directions.
2. Related Work
Edge computing technology shifts data processing capabilities closer to the data source, thereby reducing the load of data transmission and enhancing real-time processing capabilities. This distributed computing architecture minimizes communication with the cloud and effectively addresses latency issues. Islam et al. [
31] deployed an LSTM model on edge devices to build an ECI-TeleCaring system that enables real-time activity prediction and location awareness, thereby improving the quality of elderly care. Huang et al. [
32] arranged smart sensors in the daily living spaces of the elderly; the system can recognize activities such as cooking, coughing, snoring, talking, listening to music, and walking, thereby offering benefits for home care. Gupta et al. [
33] proposed a predictive model that combines edge computing and a CNN to develop an IoT-based health model. This system can provide timely health assistance to doctors and patients with an accuracy rate of 99.23%. Lian et al. [
34] used inaudible acoustic sensing through home audio devices to detect fall incidents, analyzing actions via Doppler shifts and extracting features for classification. After dimensionality reduction and clustering, a hidden Markov model was used for training. Their system exhibited high performance and environmental adaptability.
ASR plays a pivotal role in monitoring systems. Advancements in deep learning have enhanced the detection of key sound events in daily life, thereby providing more efficient and reliable solutions for elderly care. For example, Shin [
35] adapted the pre-trained YAMNet model for sound event detection in home care environments and developed a Y-MCC method based on the Matthews correlation coefficient (MCC) to generate new class mappings and improve event classification. Their experimental results demonstrated the excellent performance of the Y-MCC system across multiple datasets, particularly in SINS, ESC-50, and TUT-SED 2016. Kim et al. [
36] developed a deep learning-based sound recognition model for effectively distinguishing emergency sounds in single-person households, thereby effectively detecting emergencies and enhancing personal safety and well-being. Pandya and Ghayvat [
37] proposed an LSTM-CNN-based environmental acoustic event detection and classification system that achieved a classification accuracy of 77% under various noise conditions using a customized dataset.
Li et al. [
38] developed an integrated learning auditory health monitoring system that detects everyday sounds and emergency events, such as falls, for elderly individuals at home, achieving an accuracy rate of 94.17% while also reducing privacy intrusion and enhancing monitoring efficiency. Ghayvat and Pandya [
39] proposed an acoustic system designed to detect and recognize specific acoustic events in daily life. This system can process background sounds related to daily activities, enabling preventive health monitoring and incorporating audio signal processing and deep learning algorithms.
Although the real-time processing of large audio data on local devices reduces the latency associated with data transmission and significantly enhances responsiveness and reliability, the complexity of deep learning models often results in high computational and storage costs. This makes the direct deployment of resource-constrained edge devices challenging. Researchers have begun to adopt model quantization techniques, such as 8-bit post-training quantization (PTQ) and quantization-aware training (QAT), that reduce the computational complexity of models, thereby reducing their memory requirements and storage footprints [
40]. Varam et al. [
41] achieved a reduction in model size while maintaining good performance through float-16 quantization (F16) and QAT. Moreover, quantization techniques significantly improve energy efficiency, particularly under the low-power requirements of edge devices.
8. Summary and Conclusions
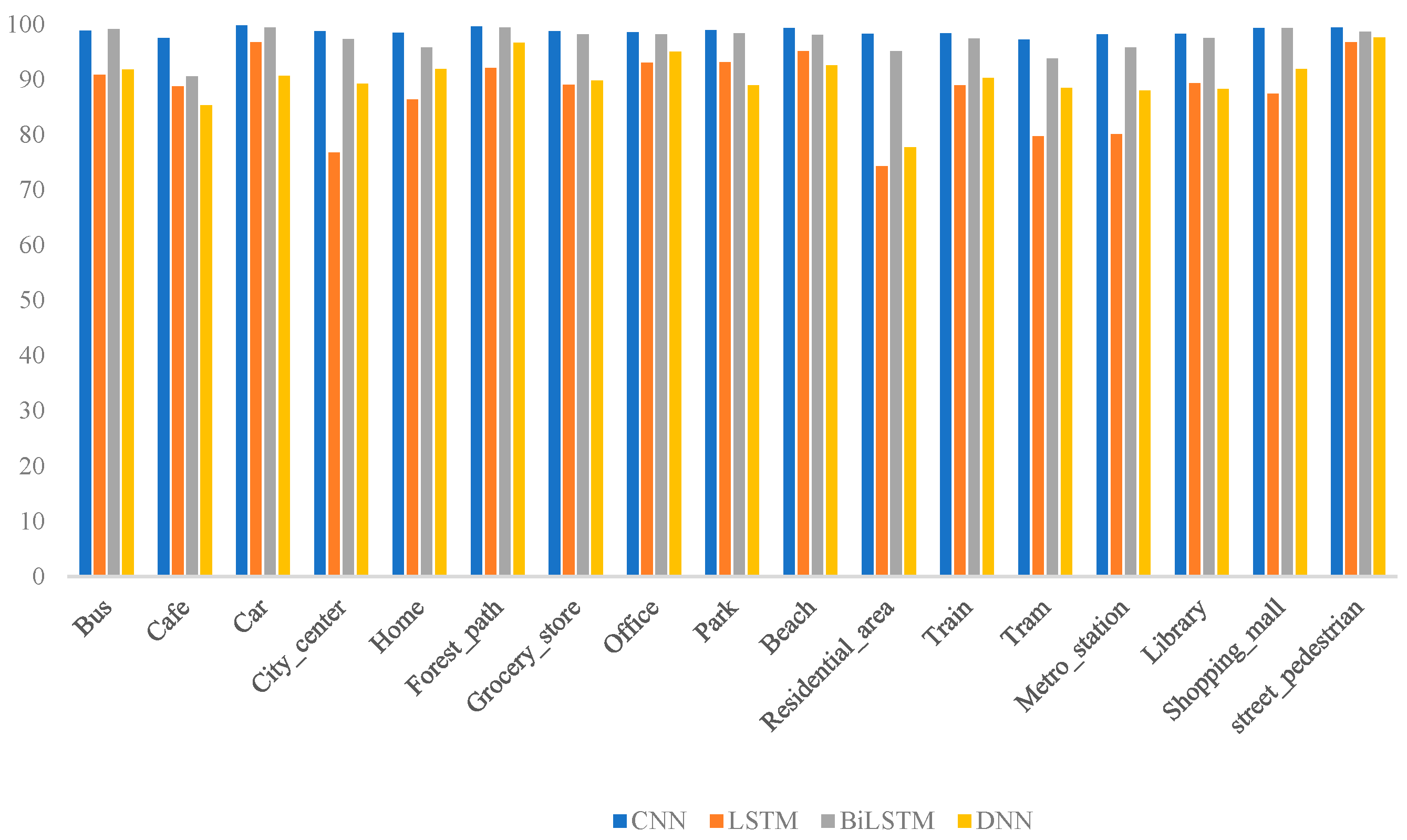
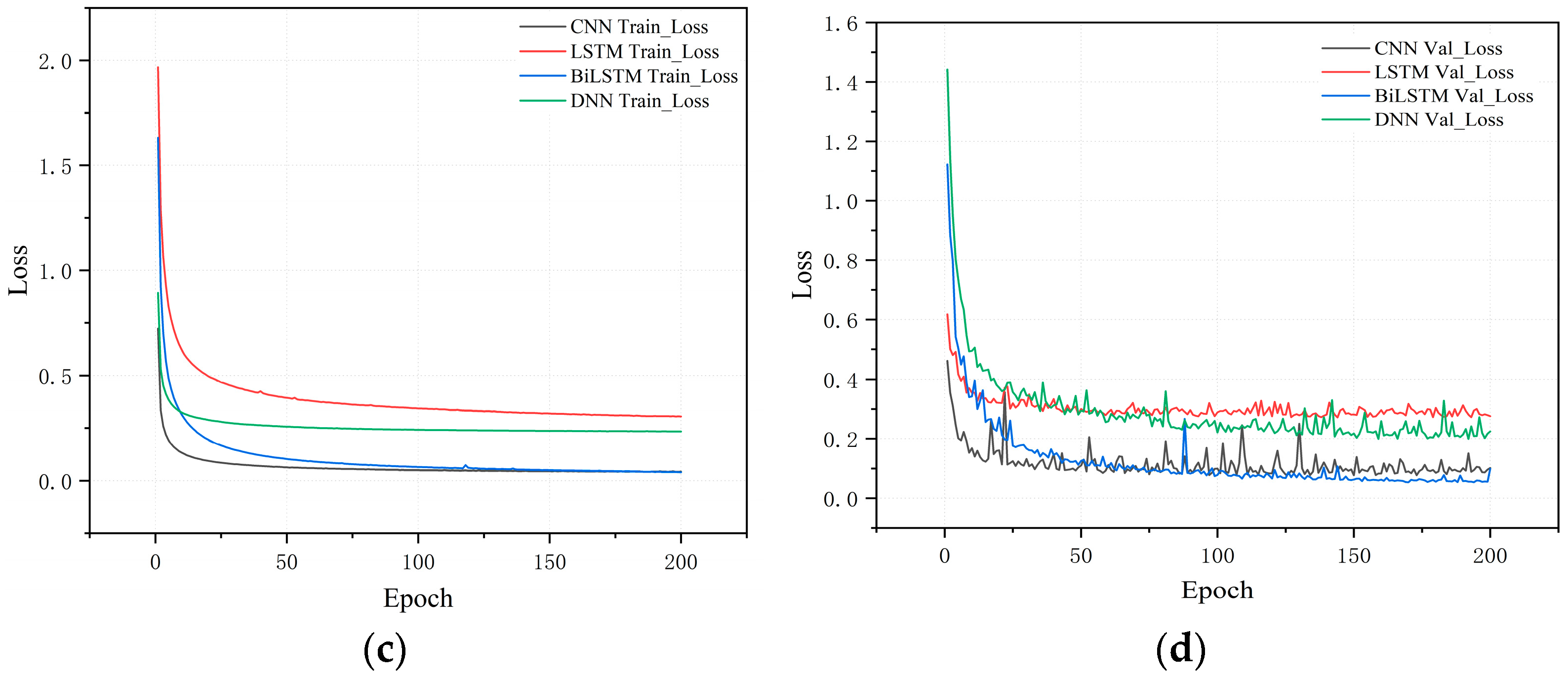
In this work, we designed an acoustic scene recognition (ASR) system aimed at monitoring the daily activities of elderly individuals. By processing real-time audio signals, the system promptly identifies key acoustic features in the daily environment, enabling accurate and timely scene recognition. This approach addresses the critical need for effective real-time monitoring in elderly care. To enhance the system’s deployment on edge devices, we developed several deep learning models and employed model quantization techniques, significantly reducing computational complexity and memory consumption. Experimental results demonstrated that, among the models trained and tested on the same dataset, the CNN model outperformed others, achieving an accuracy of 98.5% while maintaining low computational requirements. This enables the system to provide high-precision real-time monitoring with minimal power consumption, thus improving the overall efficiency of elderly care systems. However, it is important to note that the performance advantages of the CNN model are specific to the dataset and experimental conditions used in this study and should not be generalized to all environments or applications.
Building on this foundation, the system’s stability was tested across different participants, with real-world evaluations confirming its robustness in reliably identifying acoustic environments across various scenarios. Furthermore, the user-friendly smartphone application effectively addresses the care needs of the elderly by providing practical, accessible real-time environmental monitoring and personalized health management.
However, several challenges remain unaddressed. In unpredictable settings, the sensitivity of the system to environmental noise can affect detection accuracy. Future work could focus on developing optimized, lightweight deep learning algorithms to enhance model accuracy in complex and noisy environments. Additionally, implementing an event-triggered mechanism can help reduce overall power consumption by ensuring that the system is activated only upon detecting specific events. Finally, ongoing data collection from diverse real-world acoustic environments will further expand the dataset, enhancing the system’s generalization capabilities across various soundscapes and improving its robustness and adaptability.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}