
Time Series Remote Sensing Image Classification with a Data-Driven Active Deep Learning Approach


Abstract
1. Introduction
- We proposed an AL framework based on representativeness and uncertainty for TSRSI classification. This framework selects key time series samples with richer information for annotation to address the problem of limited labeled time series samples and to save on labeling efforts.
- We have designed a selector named time series loss prediction module in the AL framework. The selector is a data-driven one that can automatically learn features and patterns from a large amount of data and capture deep temporal dependencies, which gives it higher generalization performance compared to model-driven methods.
- Our experiments were conducted on three datasets, MUDS [41], DynamicEarthNet [42], and PASTIS [43]. The data in these three datasets cover a wide range and are strongly geographically representative. The proposed method performs excellently on these three datasets. Experiments have demonstrated that our method can be applied to a variety of geographical environments.
2. Related Work
2.1. Model-Driven AL Methods
- (1)
- Model-Driven AL with Uncertainty: Uncertainty-based AL methods hold that the most ambiguous samples with high uncertainty for the present model are the most effective in improving its accuracy if they are added to the training set. Some uncertainty-based AL methods aim to find samples located on the classification boundaries. For instance, ref. [44] proposes a breaking-ties AL method for a Bayesian approach. Ref. [45] introduces an entropy-based AL method to Logistic Regression. Ref. [46] presents a spatial batch-mode AL method based on margin distance to select uncertainty samples for a binary SVM classifier. A Maximum Confidence Uncertainty is applied in [47], which can find highly informative samples and automatically balance the training distribution.
- (2)
- Model-Driven AL with Representativeness: Since the unlabeled samples are always redundant, representativeness-based AL methods demonstrate that if representative samples are selected, the training set can be enriched. Many AL studies [48,49] regard representativeness as an important selection criterion when selecting samples. For example, a K-center-greedy method is introduced [50] into Core-Set to choose representative samples. Additionally, Liu et al. [31] employ sparse representation by dictionary learning to seek representative samples. These methods can help the target classifier grasp the data distribution.
- (3)
- Model-Driven AL with Model Influences: Model-driven AL methods with model influences select samples that have a significant impact on the model parameters of the target model. The model influences can be measured by Fisher Information [51,52,53], Expected-Gradient-Length (EGL), etc. The paper [54] applies Fisher information to analyze the objectives in the context of AL asymptotically, aiming to provide theoretical support and insights for optimizing the performance of AL algorithms. The first EGL strategy was proposed in [55] to select samples with a high magnitude gradient.
2.2. Data-Driven AL Methods
- (1)
- Data-Driven AL Methods with Uncertainty: The difference from the model-driven uncertainty-based AL methods is that uncertainty in data-driven AL methods is usually measured by automatic feature learning, such as hidden layers. Loss learning [56], discriminate learning [57], and adversarial learning [58] are all data-driven AL methods with uncertainty. Among them, [56] proposes a novel AL method that attaches a small parametric module called the loss prediction module to a target network to predict the target losses of unlabeled samples. Here, the target loss is an embodiment of uncertainty. An adversarial uncertainty-based AL method is proposed in [59] to query valuable samples. VAAL [60] learns a latent space using a variational autoencoder (VAE) and an adversarial network trained to discriminate between unlabeled and labeled data, which combines discriminate learning and adversarial learning to select uncertainty samples.
- (2)
- Data-Driven AL Methods with Reinforcement Learning: AL methods with reinforcement learning empower software-defined agents to actively explore and figure out the most optimal actions within a virtual environment. This streamlines the sample selection process for AL and injects a dynamic, self-learning mechanism. In [61], a reinforced pool-based deep AL approach to select informative samples for annotation is proposed, which can dynamically select valuable samples for annotation and adaptively optimize classification strategies.
- (3)
- Data-Driven AL Methods with Data Augmentation: Unlike other methods, which select real samples from the unlabeled dataset, data augmentation-based AL methods aim to generate some samples with rich information. GAAL [62] introduces the GANs into AL, which integrates the ideas of data augmentation and uncertainty to generate and select valuable samples, respectively. The BGAL [63] first performs the operation of selecting samples, then generates samples with rich information and adds them to the candidate dataset.
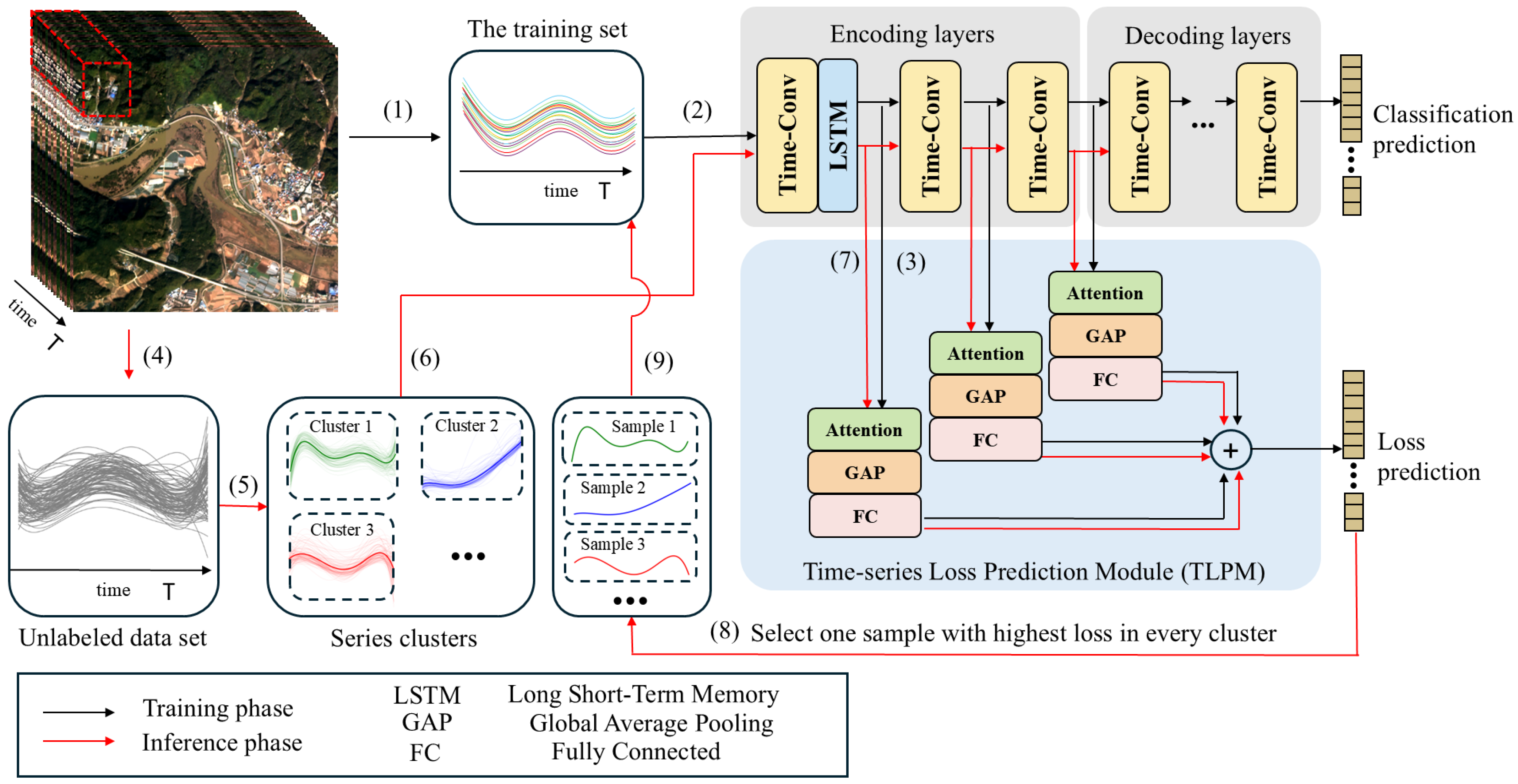
3. Methods
3.1. LSTM-Based Temporal Classifier
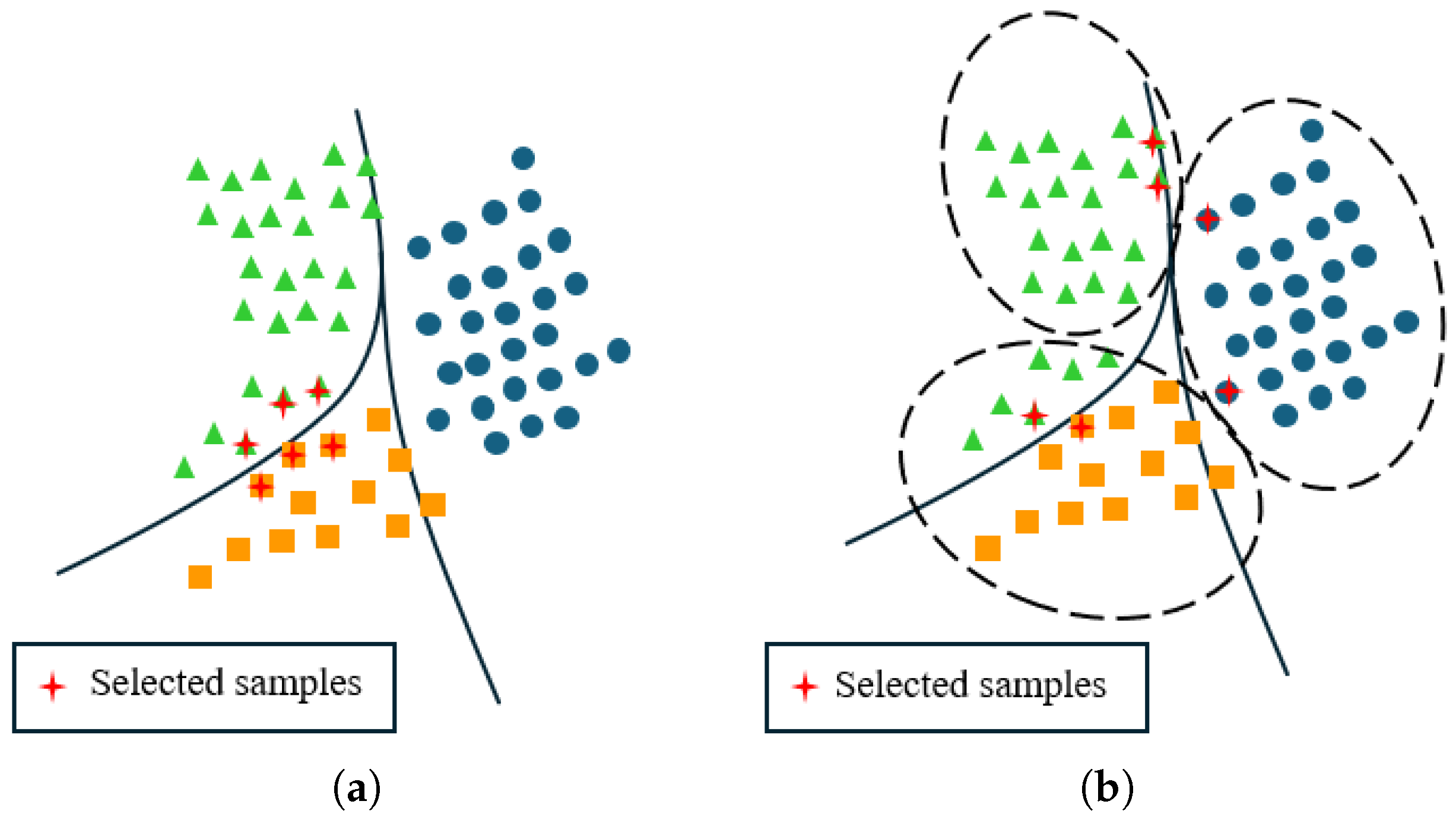
3.2. Select Samples Based on Representativeness and Uncertainty
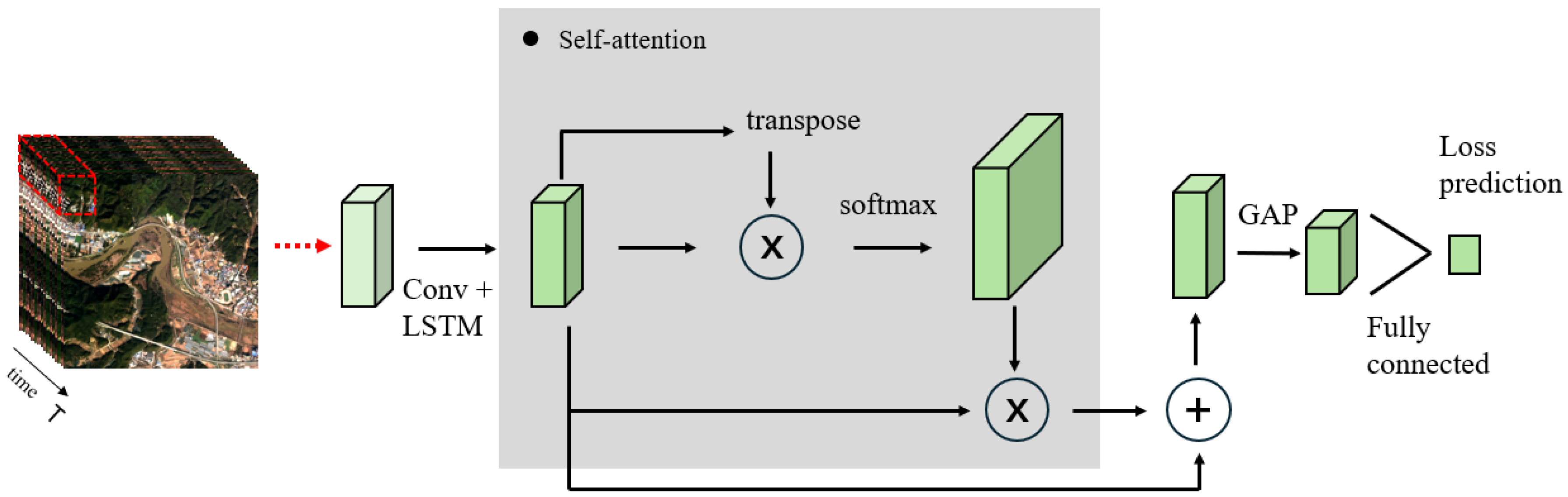
3.3. Loss Function of Our Network Architecture
| Algorithm 1: Algorithm for selecting time series samples |
 |
4. Experiments and Results
4.1. Dataset Details
4.2. Competitive Approaches
4.3. Experimental Settings and Implementation Details
4.4. The Training Settings on Datasets
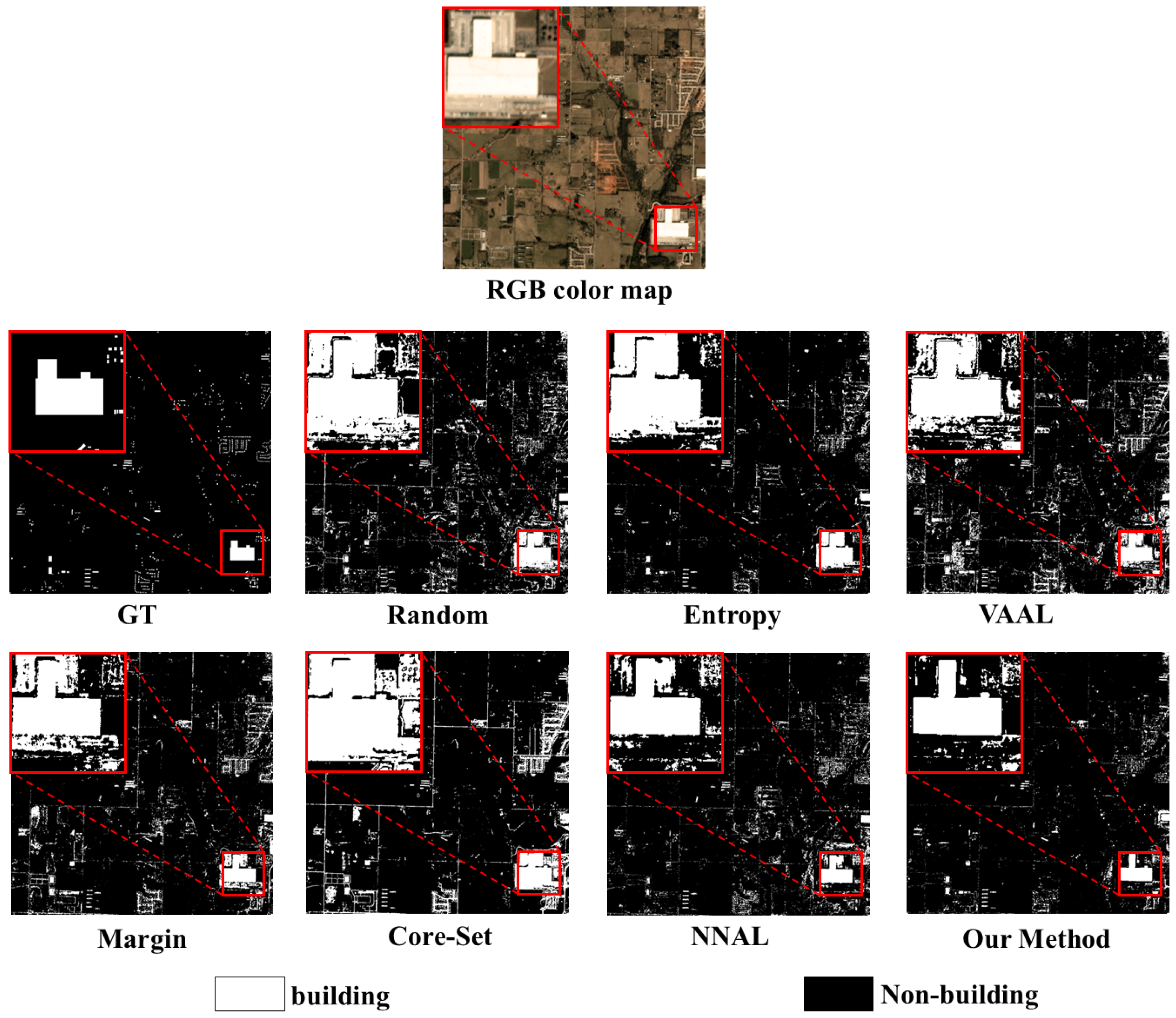
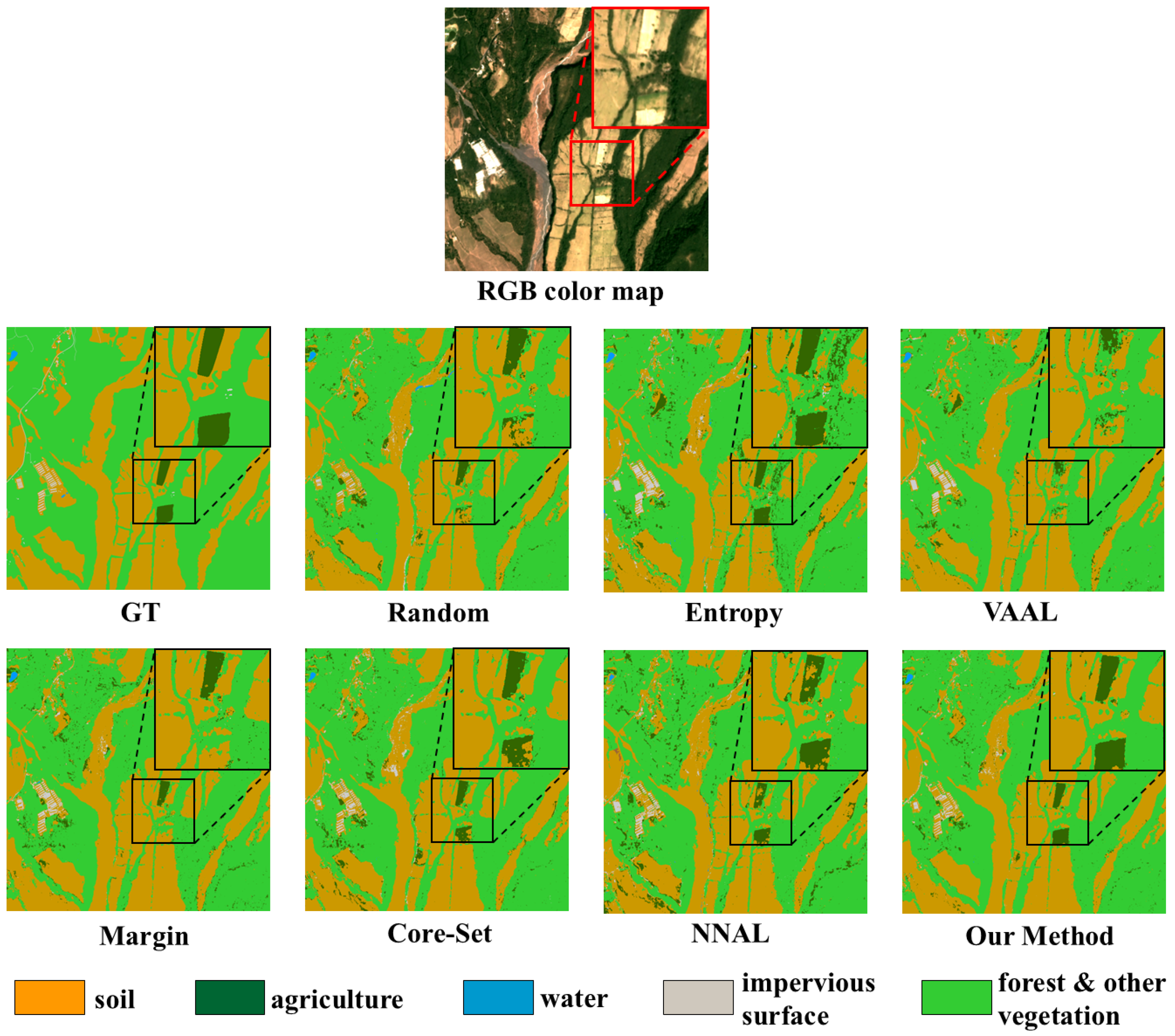
4.5. Effectiveness Verification
4.6. Computational Cost
5. Discussion
5.1. Experiments with Different Initial Training Sets
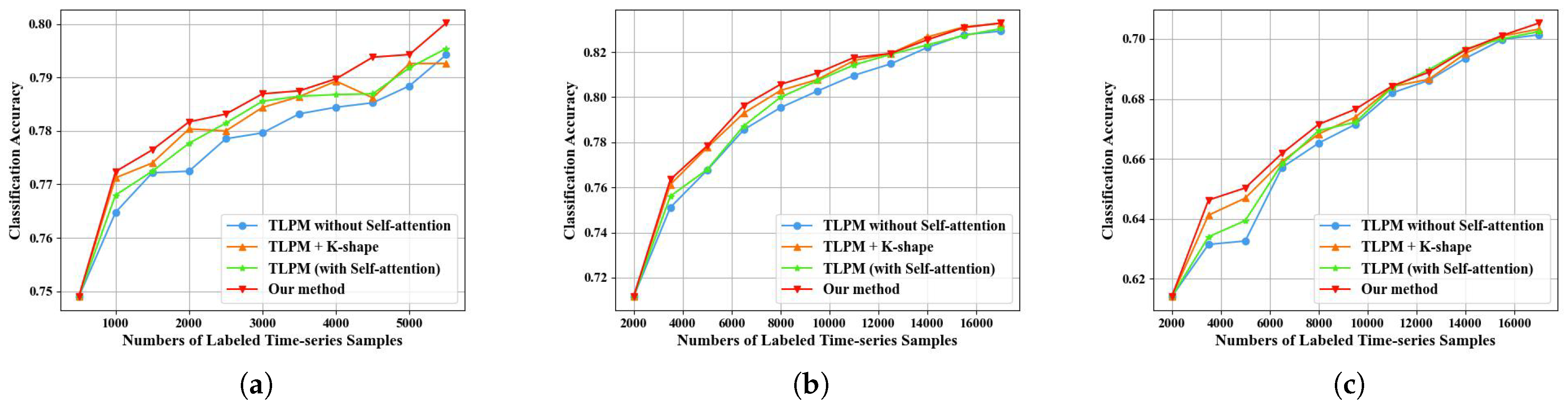
5.2. Ablation Study
5.3. Experiments with Different Temporal Lengths
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TSRSI | Time-series remote sensing image |
| AL | Active learning |
| TLPM | Time-series loss prediction module |
| LSTM | Long Short-Term Memory |
| GAP | Global average pooling |
| FC | Fully connected |
| MUDS | Multi-temporal urban development spacenet dataset |
| DynamicEarthNet | Daily multi-Spectral satellite dataset |
| VAAL | Variational adversarial active learning |
| NNAL | Nearest Neighbor-based Active Learning |
| BANet | Burned areas neural network |
| GT | Ground truth |
References
- Liu, M.; Liu, P.; Zhao, L.; Ma, Y.; Chen, L.; Xu, M. Fast semantic segmentation for remote sensing images with an improved Short-Term Dense-Connection (STDC) network. Int. J. Digit. Earth 2024, 17, 2356122. [Google Scholar] [CrossRef]
- Holder, C.J.; Shafique, M. On efficient real-time semantic segmentation: A survey. arXiv 2022, arXiv:2206.08605. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 12077–12090. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef]
- Luo, F.; Zhou, T.; Liu, J.; Guo, T.; Gong, X.; Ren, J. Multiscale diff-changed feature fusion network for hyperspectral image change detection. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Feng, Y.; Jiang, J.; Xu, H.; Zheng, J. Change detection on remote sensing images using dual-branch multilevel intertemporal network. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Lv, Z.Y.; Huang, H.T.; Li, X.; Zhao, M.; Benediktsson, J.; Sun, W.; Falco, N. Land cover change detection with heterogeneous remote sensing images: Review, progress, and perspective. Proc. IEEE 2022, 110, 1976–1991. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure transformer network for remote sensing image change detection. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Sarpong, K.; Jackson, J.K.; Effah, D.; Addo, D.; Banaamwini, S.; Awrangjeb, M.; Agbeshi, R.; Mantebea, J.; Qin, Z. Classification from sky: A robust remote sensing time series image classification using spatial encoder and multi-fast channel attention. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 10405–10422. [Google Scholar] [CrossRef]
- Yuan, Y.; Lin, L.; Liu, Q.; Hang, R.; Zhou, Z. SITS-Former: A pre-trained spatio-spectral-temporal representation model for Sentinel-2 time series classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102651. [Google Scholar] [CrossRef]
- Qin, H.; Wang, J.; Mao, X.; Zhao, Z.; Gao, X.; Lu, W. An improved faster R-CNN method for landslide detection in remote sensing images. J. Geovisualiz. Spat. Anal. 2024, 8, 2. [Google Scholar] [CrossRef]
- Li, X.; Feng, M.; Ran, Y.; Su, Y.; Liu, F.; Huang, C.; Shen, H.; Xiao, Q.; Su, J.; Yuan, S.; et al. Big Data in Earth system science and progress towards a digital twin. Nat. Rev. Earth Environ. 2023, 4, 319–332. [Google Scholar] [CrossRef]
- Navnath, N.N.; Chandrasekaran, K.; Stateczny, A.; Sundaram, V.; Panneer, P. Spatiotemporal assessment of satellite image time series for land cover classification using deep learning techniques: A case study of Reunion Island, France. Remote Sens. 2022, 14, 5232. [Google Scholar] [CrossRef]
- Dou, P.; Shen, H.; Li, Z.; Guan, X. Time series remote sensing image classification framework using combination of deep learning and multiple classifiers system. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102477. [Google Scholar] [CrossRef]
- Pelletier, C.; Webb, G.I.; Petitjean, F. Temporal convolutional neural network for the classification of satellite image time series. Remote Sens. 2019, 11, 523. [Google Scholar] [CrossRef]
- Ienco, D.; Gaetano, R.; Dupaquier, C.; Maurel, P. Land cover classification via multitemporal spatial data by deep recurrent neural networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1685–1689. [Google Scholar] [CrossRef]
- Pinto, M.M.; Libonati, R.; Trigo, R.M.; Trigo, I.; DaCamara, C. A deep learning approach for mapping and dating burned areas using temporal sequences of satellite images. Isprs J. Photogramm. Remote. Sens. 2020, 160, 260–274. [Google Scholar] [CrossRef]
- Yan, J.; Liu, J.; Wang, L.; Liang, D.; Cao, Q.; Zhang, W.; Peng, J. Land-cover classification with time-series remote sensing images by complete extraction of multiscale timing dependence. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 1953–1967. [Google Scholar] [CrossRef]
- He, D.; Shi, Q.; Xue, J.; Atkinson, P.; Liu, X. Very fine spatial resolution urban land cover mapping using an explicable sub-pixel mapping network based on learnable spatial correlation. Remote. Sens. Environ. 2023, 299, 113884. [Google Scholar] [CrossRef]
- Tang, P.; Du, P.; Xia, J.; Zhang, P.; Zhang, W. Channel attention-based temporal convolutional network for satellite image time series classification. IEEE Geosci. Remote. Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Dou, P.; Huang, C.; Han, W.; Hou, J.; Zhang, Y. Time series remote sensing image classification using feature relationship learning. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Junaid, M.; Sun, J.; Iqbal, A.; Sohail, M.; Zafar, S.; Khan, A. Mapping lulc dynamics and its potential implication on forest cover in malam jabba region with landsat time series imagery and random forest classification. Sustainability 2023, 15, 1858. [Google Scholar] [CrossRef]
- Mirończuk, M.M.; Protasiewicz, J. A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 2018, 106, 36–54. [Google Scholar] [CrossRef]
- Mohammed, A.; Kora, R. An effective ensemble deep learning framework for text classification. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 8825–8837. [Google Scholar] [CrossRef]
- Umer, M.; Sadiq, S.; Missen, M.M.S.; Hameed, Z.; Aslam, Z.; Siddique, M.; NAPPI, M. Scientific papers citation analysis using textual features and SMOTE resampling techniques. Pattern Recognit. Lett. 2021, 150, 250–257. [Google Scholar] [CrossRef]
- Li, Z.; Guo, Q.; Pan, Y.; Ding, W.; Yu, J.; Zhang, Y.; Liu, W.; Chen, H.; Wang, H.; Xie, Y. Multi-level correlation mining framework with self-supervised label generation for multimodal sentiment analysis. Inf. Fusion 2023, 99, 101891. [Google Scholar] [CrossRef]
- Jin, H.; Stehman, S.V.; Mountrakis, G. Assessing the impact of training sample selection on accuracy of an urban classification: A case study in Denver, Colorado. Int. J. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Muñoz-Marí, J. A survey of active learning algorithms for supervised remote sensing image classification. IEEE J. Sel. Top. Signal Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Foody, G.M. Sample size determination for image classification accuracy assessment and comparison. Int. J. Remote Sens. 2009, 30, 5273–5291. [Google Scholar] [CrossRef]
- Niazmardi, S.; Homayouni, S.; Safari, A. A computationally efficient multi-domain active learning method for crop mapping using satellite image time-series. Int. J. Remote Sens. 2019, 40, 6383–6394. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, H.; Eom, K.B. Active deep learning for classification of hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 712–724. [Google Scholar] [CrossRef]
- Lei, Z.; Zeng, Y.; Liu, P.; Su, X. Active deep learning for hyperspectral image classification with uncertainty learning. IEEE Geosci. Remote. Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Bortiew, A.; Patra, S.; Bruzzone, L. Active learning for hyperspectral image classification using kernel sparse representation classifiers. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Hou, W.; Chen, N.; Peng, J.; Sun, W. A Prototype and Active Learning Network for Small-Sample Hyperspectral Image Classification. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Gikunda, P.; Jouandeau, N. Homogeneous transfer active learning for time series classification. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–16 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 778–784. [Google Scholar]
- Koyuncu, F.S.; İn kaya, T. An Active Learning Approach Using Clustering-Based Initialization for Time Series Classification. In Proceedings of the International Symposium on Intelligent Manufacturing and Service Systems, Istanbul, Turkey, 26–28 May 2023; Springer Nature Singapore: Singapore, 2023; pp. 224–235. [Google Scholar]
- He, G.; Li, Y.; Zhao, W. An uncertainty and density based active semi-supervised learning scheme for positive unlabeled multivariate time series classification. Knowl.-Based Syst. 2017, 124, 80–92. [Google Scholar] [CrossRef]
- Gweon, H.; Yu, H. A nearest neighbor-based active learning method and its application to time series classification. Pattern Recognit. Lett. 2021, 146, 230–236. [Google Scholar] [CrossRef]
- Peng, F.; Luo, Q.; Ni, L.M. ACTS: An active learning method for time series classification. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 175–178. [Google Scholar]
- Liu, P.; Wang, L.; Ranjan, R.; He, G.; Zhao, L. A survey on active deep learning: From model-driven to data-driven. ACM Comput. Surv. (CSUR) 2022, 54, 1–34. [Google Scholar] [CrossRef]
- Van Etten, A.; Hogan, D.; Manso, J.M.; Shermeyer, J.; Weir, N.; Lewis, R. The multi-temporal urban development spacenet dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6398–6407. [Google Scholar]
- Toker, A.; Kondmann, L.; Weber, M.; Eisenberger, M.; Camero, A.; Hu, J.; Hoderlein, A.; Şenaras, C.; Davis, T.; Cremers, D.; et al. Dynamicearthnet: Daily multi-spectral satellite dataset for semantic change segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21158–21167. [Google Scholar]
- Garnot, V.S.F.; Landrieu, L. Panoptic segmentation of satellite image time series with convolutional temporal attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4872–4881. [Google Scholar]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Hyperspectral image segmentation using a new Bayesian approach with active learning. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3947–3960. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Semisupervised hyperspectral image segmentation using multinomial logistic regression with active learning. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4085–4098. [Google Scholar] [CrossRef]
- Shi, Q.; Du, B.; Zhang, L. Spatial coherence-based batch-mode active learning for remote sensing image classification. IEEE Trans. Image Process. 2015, 24, 2037–2050. [Google Scholar]
- Růžička, V.; D’Aronco, S.; Wegner, J.D.; Schindler, K. Deep active learning in remote sensing for data efficient change detection. arXiv 2020, arXiv:2008.11201. [Google Scholar]
- Du, B.; Wang, Z.; Zhang, L.; Zhang, L.; Liu, W.; Shen, J.; Tao, D. Exploring representativeness and informativeness for active learning. IEEE Trans. Cybern. 2015, 47, 14–26. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.J.; Jin, R.; Zhou, Z.H. Active learning by querying informative and representative examples. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 23. [Google Scholar]
- Sener, O.; Savarese, S. Active learning for convolutional neural networks: A core-set approach. arXiv 2017, arXiv:1708.00489. [Google Scholar]
- Settles, B.; Craven, M.; Ray, S. Multiple-instance active learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; Curran Associates: Red Hook, NY, USA; Volume 20. [Google Scholar]
- Hoi, S.C.H.; Jin, R.; Lyu, M.R. Batch mode active learning with applications to text categorization and image retrieval. IEEE Trans. Knowl. Data Eng. 2009, 21, 1233–1248. [Google Scholar] [CrossRef]
- Chaudhuri, K.; Kakade, S.M.; Netrapalli, P.; Sanghavi, S. Convergence rates of active learning for maximum likelihood estimation. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, BC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Sourati, J.; Akcakaya, M.; Leen, T.K.; Erdogmus, D.; Dy, J. Asymptotic analysis of objectives based on fisher information in active learning. J. Mach. Learn. Res. 2017, 18, 1–41. [Google Scholar]
- Zhang, Y.; Lease, M.; Wallace, B. Active discriminative text representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Yoo, D.; Kweon, I.S. Learning loss for active learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 93–102. [Google Scholar]
- Mottaghi, A.; Yeung, S. Adversarial representation active learning. arXiv 2019, arXiv:1912.09720. [Google Scholar]
- Gissin, D.; Shalev-Shwartz, S. Discriminative active learning. arXiv 2019, arXiv:1907.06347. [Google Scholar]
- Di, X.; Xue, Z.; Zhang, M. Active learning-driven siamese network for hyperspectral image classification. Remote. Sens. 2023, 15, 752. [Google Scholar] [CrossRef]
- Sinha, S.; Ebrahimi, S.; Darrell, T. Variational adversarial active learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5972–5981. [Google Scholar]
- Patel, U.; Patel, V. Active learning-based hyperspectral image classification: A reinforcement learning approach. J. Supercomput. 2024, 80, 2461–2486. [Google Scholar] [CrossRef]
- Zhu, J.J.; Bento, J. Generative adversarial active learning. arXiv 2017, arXiv:1702.07956. [Google Scholar]
- Tran, T.; Do, T.T.; Reid, I.; Carneiro, G. Bayesian generative active deep learning. In Proceedings of the PMLR International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6295–6304. [Google Scholar]
- Paparrizos, J.; Gravano, L. k-shape: Efficient and accurate clustering of time series. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 31 May–4 June 2015; pp. 1855–1870. [Google Scholar]
- Lin, M. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wu, B.; Zhang, M.; Zeng, H.; Tian, F.; Potgieter, A.B.; Qin, X.; Yan, N.; Chang, S.; Zhao, Y.; Dong, Q. Challenges and opportunities in remote sensing-based crop monitoring: A review. Natl. Sci. Rev. 2023, 10, nwac290. [Google Scholar] [CrossRef] [PubMed]
- Mani, J.K.; Varghese, A.O. Remote sensing and GIS in agriculture and forest resource monitoring. In Geospatial Technologies in Land Resources Mapping, Monitoring and Management; Springer: Cham, Switzerland, 2018; pp. 377–400. [Google Scholar]
- Sousa, J.C.G.; Ribeiro, A.R.; Barbosa, M.O.; Pereira, M.F.R.; Silva, A.M.T. A review on environmental monitoring of water organic pollutants identified by EU guidelines. J. Hazard. Mater. 2018, 344, 146–162. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | DynamicEarthNet | MUDS | PASTIS |
|---|---|---|---|
| Resolution (m) | 3 | 4 | 10 |
| Sensor | Planet Labs | Planet Labs | Sentinel-2 |
| Bands | 4 | 4 | 10 |
| Temporal length | 2 years | 2 years | more than 2 years |
| Sample frequency | monthly | monthly | irregular |
| Categories | 7 | 2 | 19 |
| Dataset | MUDS | DynamicEarthNet | PASTIS |
|---|---|---|---|
| Random | 0.5897 | 0.7440 | 0.6022 |
| Entropy | 0.6257 | 0.7731 | 0.6119 |
| VAAL | 0.5139 | 0.6949 | 0.5937 |
| Margin | 0.5856 | 0.7614 | 0.6041 |
| Core-set | 0.5590 | 0.7470 | 0.5887 |
| NNAL | 0.5539 | 0.7595 | 0.5641 |
| Our method | 0.6663 | 0.7845 | 0.6231 |
| AL Methods | MUDS | DynamicEarthNet | PASTIS | |||
|---|---|---|---|---|---|---|
| Training | Sampling | Training | Sampling | Training | Sampling | |
| Random | 123.25 | 0.28 | 179.21 | 0.78 | 198.95 | 0.72 |
| Entropy | 125.15 | 3.28 | 183.73 | 4.13 | 194.44 | 6.81 |
| VAAL | 285.69 | 8.70 | 450.84 | 9.73 | 682.36 | 11.43 |
| Margin | 125.75 | 2.63 | 180.86 | 4.22 | 195.23 | 5.98 |
| Core-set | 129.50 | 31.26 | 178.25 | 42.02 | 192.73 | 245.33 |
| NNAL | 126.05 | 124.25 | 181.27 | 83.67 | 197.92 | 215.09 |
| Our | 197.49 | 315.46 | 223.47 | 342.96 | 281.83 | 387.13 |
| Temporal Length | DynamicEarthNet | MUDS | PASTIS |
|---|---|---|---|
| 12 | 79.37% | 79.34% | 70.80% |
| 16 | 80.86% | 79.96% | 71.64% |
| 20 | 81.96% | 81.35% | 71.82% |
| 24 | 84.61% | 84.78% | 72.57% |
| 30 | - | - | 74.02% |
| 36 | - | - | 75.54% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, G.; Liu, P.; Chen, Z.; Chen, L.; Ma, Y.; Zhao, L. Time Series Remote Sensing Image Classification with a Data-Driven Active Deep Learning Approach. Sensors 2025, 25, 1718. https://doi.org/10.3390/s25061718
Xie G, Liu P, Chen Z, Chen L, Ma Y, Zhao L. Time Series Remote Sensing Image Classification with a Data-Driven Active Deep Learning Approach. Sensors. 2025; 25(6):1718. https://doi.org/10.3390/s25061718
Chicago/Turabian StyleXie, Gaoliang, Peng Liu, Zugang Chen, Lajiao Chen, Yan Ma, and Lingjun Zhao. 2025. "Time Series Remote Sensing Image Classification with a Data-Driven Active Deep Learning Approach" Sensors 25, no. 6: 1718. https://doi.org/10.3390/s25061718
APA StyleXie, G., Liu, P., Chen, Z., Chen, L., Ma, Y., & Zhao, L. (2025). Time Series Remote Sensing Image Classification with a Data-Driven Active Deep Learning Approach. Sensors, 25(6), 1718. https://doi.org/10.3390/s25061718