
A Texture Reconstructive Downsampling for Multi-Scale Object Detection in UAV Remote-Sensing Images

Abstract
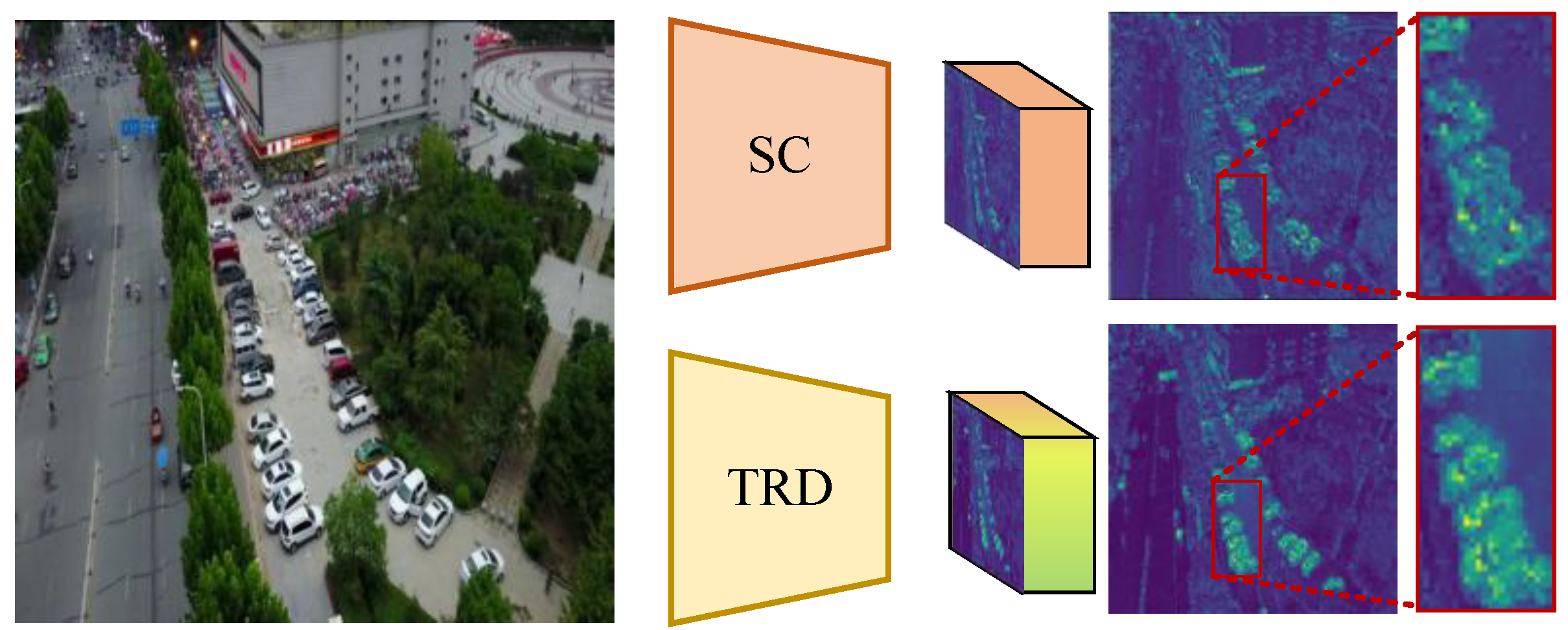
1. Introduction
- We propose an inverse projection-based sample residual learning structure that computes the projection error to guide the reconstruction of the downsampled ideal feature maps by cascading the upsampling and downsampling operators.
- The proposed TRD method mitigates the inherent trade-off between resolution reduction and information loss. It effectively improves the multi-scale object-detection accuracy in UAV remote-sensing images.
- Extensive experiments are conducted with the TRD on VisDrone-DET and NWPU VHR-10 datasets, showing that TRD can improve the multi-scale detection performance of the model compared to the baseline with little additional cost.
2. Related Work
2.1. Object Detection in UAV Remote-Sensing Images
2.2. Downsampling in CNNs
2.3. Back-Projection in CNNs
3. Method
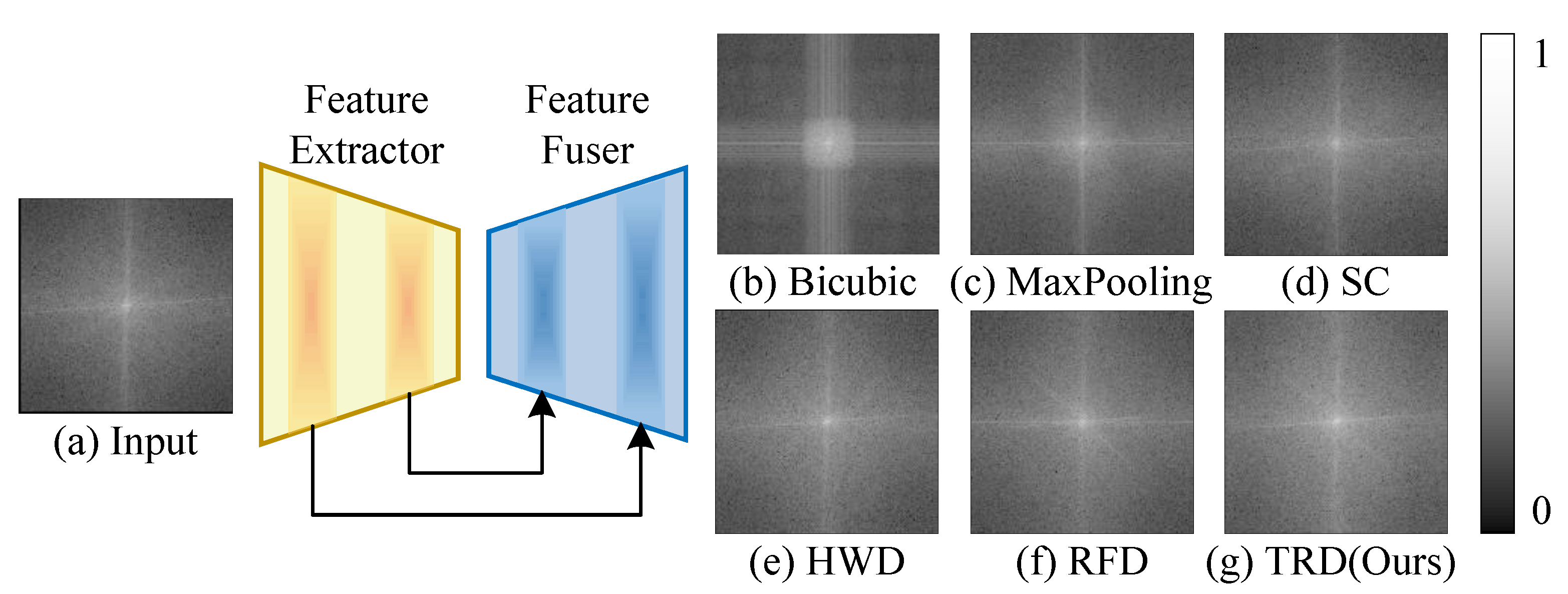
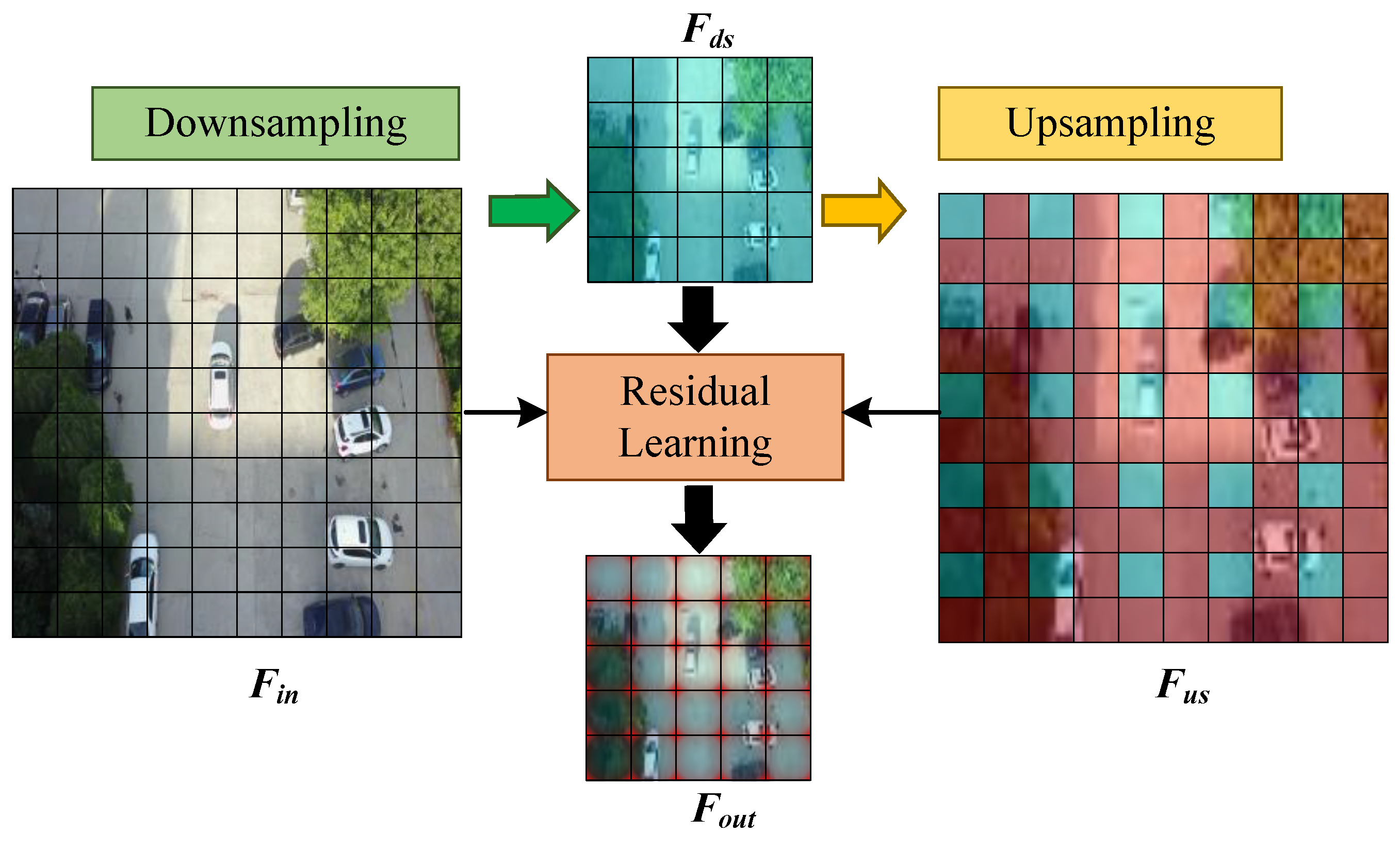
3.1. Overview of Additive TRD
3.2. Sample Residual Learning Structure
3.3. Texture Reconstructive Downsampling
4. Experiments
4.1. Experiment Setting
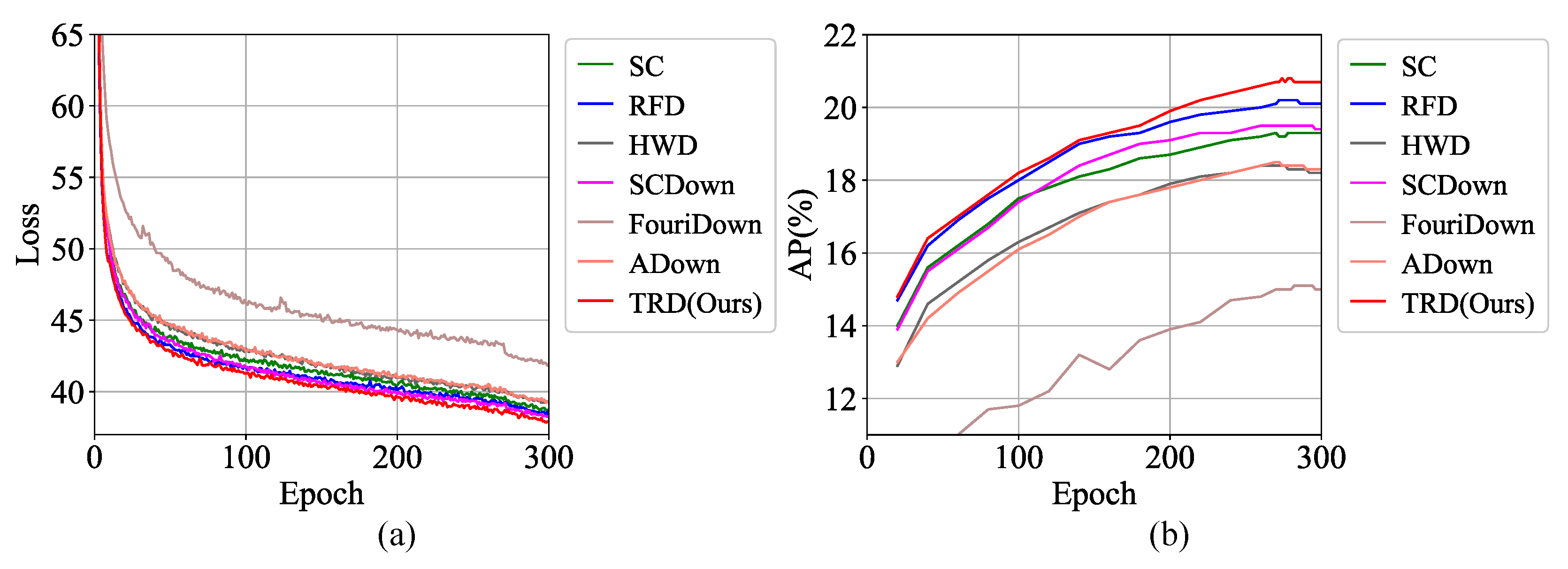
4.2. Overall Performance of TRD
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gu, J.; Su, T.; Wang, Q.; Du, X.; Guizani, M. Multiple moving targets surveillance based on a cooperative network for multi-UAV. IEEE Commun. Mag. 2018, 56, 82–89. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, J.; Huang, D. UFPMP-Det: Toward accurate and efficient object detection on drone imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 1026–1033. [Google Scholar]
- Zhang, J.; Yang, X.; He, W.; Ren, J.; Zhang, Q.; Zhao, Y.; Bai, R.; He, X.; Liu, J. Scale Optimization Using Evolutionary Reinforcement Learning for Object Detection on Drone Imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 410–418. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Farhadi, A.; Redmon, J. YOLOv3: An incremental improvement. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, USA, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Ge, Z. YOLOX: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Lv, H.; Zheng, X.; Xie, X.; Chen, X.; Xiong, H. The UAV Benchmark: Compact Detection of Vehicles in Urban Scenarios. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. (J-STARS) 2024, 17, 14836–14847. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, USA, 8–13 December 2014; Volume 27, pp. 1–9. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Stergiou, A.; Poppe, R. Adapool: Exponential adaptive pooling for information-retaining downsampling. IEEE Trans. Image Process. (TIP) 2022, 32, 251–266. [Google Scholar] [CrossRef]
- Li, Q.; Yuan, Y.; Jia, X.; Wang, Q. Dual-stage approach toward hyperspectral image super-resolution. IEEE Trans. Image Process. (TIP) 2022, 31, 7252–7263. [Google Scholar] [CrossRef]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2021, 44, 7380–7399. [Google Scholar] [CrossRef]
- Xiong, X.; He, M.; Li, T.; Zheng, G.; Xu, W.; Fan, X.; Zhang, Y. Adaptive Feature Fusion and Improved Attention Mechanism Based Small Object Detection for UAV Target Tracking. IEEE Internet Things J. (IoT) 2024, 11, 21239–21249. [Google Scholar] [CrossRef]
- Zhou, L.; Zhao, S.; Wan, Z.; Liu, Y.; Wang, Y.; Zuo, X. MFEFNet: A Multi-Scale Feature Information Extraction and Fusion Network for Multi-Scale Object Detection in UAV Aerial Images. Drones 2024, 8, 186. [Google Scholar] [CrossRef]
- Jiang, L.; Yuan, B.; Du, J.; Chen, B.; Xie, H.; Tian, J.; Yuan, Z. MFFSODNet: Multi-Scale Feature Fusion Small Object Detection Network for UAV Aerial Images. IEEE Trans. Instrum. Meas. 2024, 73, 3381272. [Google Scholar] [CrossRef]
- Xian, R.; Xiong, X.; Peng, H.; Wang, J.; de Arellano Marrero, A.R.; Yang, Q. Feature fusion method based on spiking neural convolutional network for edge detection. Pattern Recogn. (PR) 2024, 147, 110112. [Google Scholar] [CrossRef]
- Ren, H.; Xia, M.; Weng, L.; Hu, K.; Lin, H. Dual attention-guided multiscale feature aggregation network for remote sensing image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. (J-STARS) 2024, 17, 4899–4916. [Google Scholar] [CrossRef]
- Xie, J.; Nie, J.; Ding, B.; Yu, M.; Cao, J. Cross-modal Local Calibration and Global Context Modeling Network for RGB-Infrared Remote Sensing Object Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. (J-STARS) 2023, 16, 8933–8942. [Google Scholar] [CrossRef]
- Lin, X.; Ozaydin, B.; Vidit, V.; El Helou, M.; Süsstrunk, S. DSR: Towards Drone Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 361–377. [Google Scholar]
- Bhowmik, A.; Wang, Y.; Baka, N.; Oswald, M.R.; Snoek, C.G. Detecting Objects with Context-Likelihood Graphs and Graph Refinement. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 6524–6533. [Google Scholar]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605415. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25, pp. 84–90. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Xu, G.; Liao, W.; Zhang, X.; Li, C.; He, X.; Wu, X. Haar wavelet downsampling: A simple but effective downsampling module for semantic segmentation. Pattern Recogn. (PR) 2023, 143, 109819. [Google Scholar] [CrossRef]
- Williams, T.; Li, R. Wavelet pooling for convolutional neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–12. [Google Scholar]
- Stergiou, A.; Poppe, R.; Kalliatakis, G. Refining activation downsampling with SoftPool. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10357–10366. [Google Scholar]
- Lu, W.; Chen, S.B.; Tang, J.; Ding, C.H.; Luo, B. A Robust Feature Downsampling Module for Remote-Sensing Visual Tasks. IEEE Trans. Geosci. Remote Sens. (TGRS) 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Hesse, R.; Schaub-Meyer, S.; Roth, S. Content-daptive downsampling in convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, USA, 18–22 June 2023; pp. 4544–4553. [Google Scholar]
- Wang, J.; Cui, Y.; Li, Y.; Ren, W.; Cao, X. Omnidirectional Image Super-resolution via Bi-projection Fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, USA, 20–27 February 2024; Volume 38, pp. 5454–5462. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Recurrent back-projection network for video super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3897–3906. [Google Scholar]
- Liu, Z.S.; Wang, L.W.; Li, C.T.; Siu, W.C. Hierarchical back projection network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1–10. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Wang, L.W.; Liu, Z.S.; Siu, W.C.; Lun, D.P. Lightening network for low-light image enhancement. IEEE Trans. Image Process. (TIP) 2020, 29, 7984–7996. [Google Scholar] [CrossRef]
- Zhu, J.; Tang, H.; Cheng, Z.Q.; He, J.Y.; Luo, B.; Qiu, S.; Li, S.; Lu, H. DCPT: Darkness clue-prompted tracking in nighttime uavs. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 7381–7388. [Google Scholar]
- Park, J.Y.; Park, C.W.; Eom, I.K. ULBPNet: Low-light image enhancement using U-shaped lightening back-projection. Knowl.-Based Syst. 2023, 281, 111099. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, J.; Cao, S.; Zhu, M.; Sun, J.; Hao, Z.; Jiang, X. SRBPSwin: Single-Image Super-Resolution for Remote Sensing Images Using a Global Residual Multi-Attention Hybrid Back-Projection Network Based on the Swin Transformer. Remote Sens. 2024, 16, 2252. [Google Scholar] [CrossRef]
- Zhang, X.; Wan, F.; Liu, C.; Ji, X.; Ye, Q. Learning to Match Anchors for Visual Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2022, 44, 3096–3109. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Chai, L.; Jin, L. Scale decoupled pyramid for object detection in aerial images. IEEE Trans. Geosci. Remote Sens. (TGRS) 2023, 61, 3298852. [Google Scholar] [CrossRef]
- Yang, Y.; Zang, B.; Li, N.; Zhao, B.; Li, B.; Lang, Y. Reducing False Detections in Aerial Images by Exploiting the Context Information and Centroid Relationship. IEEE Trans. Instrum. Meas. (TIM) 2022, 71, 3187724. [Google Scholar] [CrossRef]
- Yang, Y.; Zang, B.; Song, C.; Li, B.; Lang, Y.; Zhang, W.; Huo, P. Small Object Detection in Remote Sensing Images Based on Redundant Feature Removal and Progressive Regression. IEEE Trans. Geosci. Remote Sens. (TGRS) 2024, 62, 3417960. [Google Scholar] [CrossRef]
- Chen, L.; Liu, C.; Li, W.; Xu, Q.; Deng, H. DTSSNet: Dynamic Training Sample Selection Network for UAV Object Detection. IEEE Trans. Geosci. Remote Sens. (TGRS) 2024, 62, 3348555. [Google Scholar] [CrossRef]
- Huang, S.; Lin, C.; Jiang, X.; Qu, Z. BRSTD: Bio-Inspired Remote Sensing Tiny Object Detection. IEEE Trans. Geosci. Remote Sens. (TGRS) 2024, 62, 3470900. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Z.; Wang, N. QueryDet: Cascaded sparse query for accelerating high-resolution small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 13668–13677. [Google Scholar]
- Bolya, D.; Hoffman, J. Token merging for fast stable diffusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, USA, 18–22 June 2023; pp. 4599–4603. [Google Scholar]
- Xu, C.; Wang, J.; Yang, W.; Yu, H.; Yu, L. RFLA: Gaussian receptive field based label assignment for tiny object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 526–543. [Google Scholar]
- Tang, S.; Zhang, S.; Fang, Y. HIC-YOLOv5: Improved YOLOv5 For Small Object Detection. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 6614–6619. [Google Scholar]
- Du, B.; Huang, Y.; Chen, J.; Huang, D. Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, USA, 18–22 June 2023; pp. 13435–13444. [Google Scholar]
- Ross, T.Y.; Dollár, G. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Liu, C.; Dong, Y.; Zhang, Y.; Li, X. Confidence-Driven Region Mixing for Optical Remote Sensing Domain Adaptation Object Detection. IEEE Trans. Geosci. Remote Sens. (TGRS) 2024, 62, 3417610. [Google Scholar] [CrossRef]
- Zhu, Q.; Huang, J.; Zheng, N.; Gao, H.; Li, C.; Xu, Y.; Zhao, F. FouriDown: Factoring down-sampling into shuffling and superposing. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 10–15 December 2024; Volume 36. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Venue | AP (%) | AP50 (%) | AP75 (%) | APS (%) | APM (%) | APL (%) |
|---|---|---|---|---|---|---|---|
| FreeAnchor [45] | TPAMI2022 | 20.0 | 33.6 | 20.9 | 11.4 | 30.0 | 36.7 |
| SDPNet [46] | TGRS2023 | 30.2 | 52.5 | 30.6 | - | - | - |
| CCOD [47] | TIM2022 | 20.9 | 35.8 | 21.1 | 12.3 | 31.3 | 35.1 |
| FPSOD [48] | TGRS2024 | 23.1 | 38.0 | 24.1 | 15.1 | 34.2 | 36.8 |
| DTSSNet [49] | TGRS2024 | 25.5 | 41.1 | 26.9 | 18.6 | 34.3 | 41.2 |
| BRSTD [50] | TGRS2024 | 27.3 | 45.9 | - | - | - | - |
| QueryDet [51] | CVPR2022 | 28.3 | 48.1 | 28.8 | - | - | - |
| ToMe [52] | CVPR2023 | 27.8 | 46.9 | 28.5 | - | - | - |
| RFLA [53] | ECCV2022 | 27.4 | 45.3 | - | - | - | - |
| HIC-YOLOv5 [54] | ICRA2024 | 25.9 | 44.3 | - | - | - | - |
| YOLOv5-X | Ultralytics2022 | 22.6 | 38.6 | 21.8 | 13.9 | 32.4 | 42.6 |
| CEASC [55] | CVPR2023 | 20.8 | 35.0 | 31.5 | - | - | - |
| YOLOv7 [11] | CVPR2023 | 27.8 | 49.2 | 27.5 | 18.6 | 38.8 | 47.8 |
| YOLOv8-X | Ultralytics2023 | 28.0 | 45.4 | 26.8 | 16.7 | 38.9 | 45.5 |
| YOLOv5-X w/TRD (Ours) | - | 24.5 | 40.9 | 24.8 | 15.2 | 36.2 | 42.7 |
| YOLOv8-X w/TRD (Ours) | - | 31.0 | 49.5 | 32.3 | 19.8 | 45.7 | 59.4 |
| Method | Backbone | Category (%) | AP (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AI | SH | ST | BD | TC | BC | GTF | HA | BR | VE | |||
| RetinaNet [56] | ResNet-50 | 58.4 | 46.8 | 53.1 | 55.2 | 49.4 | 43.2 | 23.5 | 32.5 | 17.1 | 45.5 | 42.5 |
| Faster R-CNN [5] | ResNet-50 | 63.9 | 54.7 | 60.3 | 58.5 | 61.3 | 64.1 | 35.6 | 41.3 | 33.5 | 59.6 | 53.3 |
| RTMDet * | CSPNeXt | 65.2 | 55.4 | 55.1 | 72.0 | 68.1 | 63.2 | 80.2 | 60.0 | 43.7 | 55.7 | 61.8 |
| YOLOv5 * | Darknet | 61.9 | 47.9 | 41.2 | 69.9 | 60.4 | 51.4 | 78.3 | 48.5 | 44.3 | 47.8 | 55.2 |
| YOLOX [12] | Darknet | 62.1 | 52.0 | 45.9 | 60.5 | 55.9 | 57.2 | 24.7 | 47.4 | 30.4 | 51.6 | 48.8 |
| YOLOv7 [11] | Darknet | 59.4 | 53.3 | 44.3 | 61.9 | 55.5 | 55.6 | 32.6 | 51.0 | 39.6 | 49.6 | 50.3 |
| YOLOv8 * | Darknet | 65.9 | 52.5 | 49.0 | 71.5 | 66.5 | 53.3 | 81.2 | 57.1 | 45.3 | 48.6 | 59.1 |
| CR-Mixing [57] | Darknet | 75.9 | 15.7 | 50.4 | 85.2 | 91.1 | 65.7 | 76.5 | 26.0 | 12.9 | 43.8 | 54.3 |
| YOLOv5 w/TRD | Darknet | 60.6 | 51.4 | 41.7 | 71.2 | 63.3 | 50.9 | 82.4 | 57.9 | 42.3 | 47.5 | 56.9 |
| YOLOv8 w/TRD | Darknet | 63.8 | 55.9 | 49.6 | 73.8 | 68.8 | 62.0 | 83.6 | 60.3 | 46.6 | 57.1 | 62.2 |
| RTMDet w/TRD | CSPNeXt | 66.7 | 55.7 | 55.6 | 74.1 | 72.1 | 70.0 | 83.4 | 58.4 | 43.8 | 60.2 | 64.0 |
| Model | DSL | AP (%) | AP50 (%) | AP75 (%) | APS (%) | APM (%) | APL (%) | #Param (M) | GFLOPs |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8-N | SC | 19.3 | 33.0 | 19.3 | 10.4 | 29.3 | 42.1 | 3.0 | 4.1 |
| TRD | 20.8 (+1.5) | 35.2 (+2.2) | 21.0 (+1.7) | 11.7 (+1.3) | 31.8 (+2.5) | 44.8 (+2.7) | 3.2 (+0.2) | 4.6 (+0.5) | |
| YOLOv8-S | SC | 23.6 | 40.0 | 21.8 | 12.7 | 33.4 | 42.0 | 11.2 | 14.4 |
| TRD | 24.9 (+1.3) | 41.0 (+1.0) | 25.5 (+3.7) | 14.8 (+2.1) | 37.5 (+4.1) | 45.6 (+3.6) | 12.0 (+0.8) | 16.3 (+1.9) | |
| YOLOv8-M | SC | 25.6 | 42.6 | 24.0 | 14.8 | 35.5 | 41.8 | 25.9 | 39.6 |
| TRD | 28.2 (+2.6) | 45.8 (+3.2) | 29.3 (+5.3) | 17.5 (+2.7) | 42.3 (+6.8) | 55.9 (+14.1) | 27.2 (+1.3) | 43.6 (+4.0) | |
| YOLOv8-L | SC | 27.1 | 44.1 | 24.8 | 15.3 | 36.0 | 44.7 | 43.7 | 82.7 |
| TRD | 30.3 (+3.2) | 48.6 (+4.5) | 31.5 (+6.7) | 19.8 (+4.5) | 44.8 (+8.8) | 56.0 (+11.3) | 45.3 (+1.6) | 89.4 (6.6) | |
| YOLOv8-X | SC | 28.0 | 45.4 | 26.8 | 16.7 | 38.9 | 45.5 | 68.2 | 132.1 |
| TRD | 31.0 (+3.0) | 49.5 (+4.1) | 32.3 (+5.5) | 19.8 (+3.1) | 45.7 (+6.8) | 59.4 (+13.9) | 70.8 (+2.5) | 139.4 (+7.3) |
| Method | Venue | AP (%) | AP50 (%) | AP75 (%) | #Param (M) | GFLOPs |
|---|---|---|---|---|---|---|
| SC * | - | 19.3 | 33.0 | 19.3 | 3.0 | 4.1 |
| RFD [35] * | TGRS2023 | 20.2 | 34.6 | 20.0 | 3.5 | 6.3 |
| HWD [32] * | PR2023 | 18.4 | 32.1 | 18.1 | 2.8 | 3.8 |
| SCDown [14] * | ARXIV2024 | 19.5 | 33.4 | 19.2 | 2.7 | 3.8 |
| FouriDown [58] * | NeurIPS2024 | 15.1 | 26.6 | 14.6 | 2.7 | 3.7 |
| ADown [13] * | ECCV2024 | 18.5 | 31.8 | 18.2 | 2.7 | 3.7 |
| TRD | - | 20.8 | 35.2 | 21.0 | 3.2 | 4.6 |
| AP (%) | AP50 (%) | AP75 (%) | APS (%) | APM (%) | APL (%) | #Param (M) | GFLOPs | |||
|---|---|---|---|---|---|---|---|---|---|---|
| ✔ | × | × | 19.3 | 33.0 | 19.3 | 10.4 | 29.5 | 42.3 | 3.0 | 4.1 |
| ✔ | ✔ | × | 20.3 | 34.6 | 20.4 | 11.1 | 31.1 | 44.2 | 3.1 | 4.3 |
| ✔ | ✔ | ✔ | 20.8 | 35.2 | 21.0 | 11.7 | 31.8 | 44.8 | 3.2 | 4.6 |
| Method | AP (%) | AP50 (%) | AP75 (%) | APS (%) | APM (%) | APL (%) | #Param (M) | GFLOPs |
|---|---|---|---|---|---|---|---|---|
| SC (baseline) | 23.6 | 40.0 | 21.8 | 12.7 | 33.4 | 42.0 | 11.2 | 14.4 |
| TRD w/MaxPooling | 24.7 | 40.8 | 25.1 | 14.6 | 37.2 | 45.7 | 12.0 | 16.3 |
| TRD w/AveragePooling | 24.9 | 41.0 | 25.5 | 14.8 | 37.5 | 45.6 | 12.0 | 16.3 |
| TRD w/SC (K = 1) | 24.9 | 41.0 | 25.4 | 14.9 | 37.4 | 45.7 | 12.4 | 16.8 |
| TRD w/SC (K = 3) | 25.5 | 42.0 | 26.0 | 15.5 | 38.3 | 46.1 | 15.2 | 21.0 |
| TRD w/SC (K = 5) | 25.8 | 42.2 | 26.5 | 15.5 | 38.6 | 48.3 | 20.8 | 29.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, W.; Xiong, B.; Chen, J.; Ou, Q.; Yu, L. A Texture Reconstructive Downsampling for Multi-Scale Object Detection in UAV Remote-Sensing Images. Sensors 2025, 25, 1569. https://doi.org/10.3390/s25051569
Zheng W, Xiong B, Chen J, Ou Q, Yu L. A Texture Reconstructive Downsampling for Multi-Scale Object Detection in UAV Remote-Sensing Images. Sensors. 2025; 25(5):1569. https://doi.org/10.3390/s25051569
Chicago/Turabian StyleZheng, Wenhao, Bangshu Xiong, Jiujiu Chen, Qiaofeng Ou, and Lei Yu. 2025. "A Texture Reconstructive Downsampling for Multi-Scale Object Detection in UAV Remote-Sensing Images" Sensors 25, no. 5: 1569. https://doi.org/10.3390/s25051569
APA StyleZheng, W., Xiong, B., Chen, J., Ou, Q., & Yu, L. (2025). A Texture Reconstructive Downsampling for Multi-Scale Object Detection in UAV Remote-Sensing Images. Sensors, 25(5), 1569. https://doi.org/10.3390/s25051569