
A Survey of Robotic Monocular Pose Estimation

Abstract
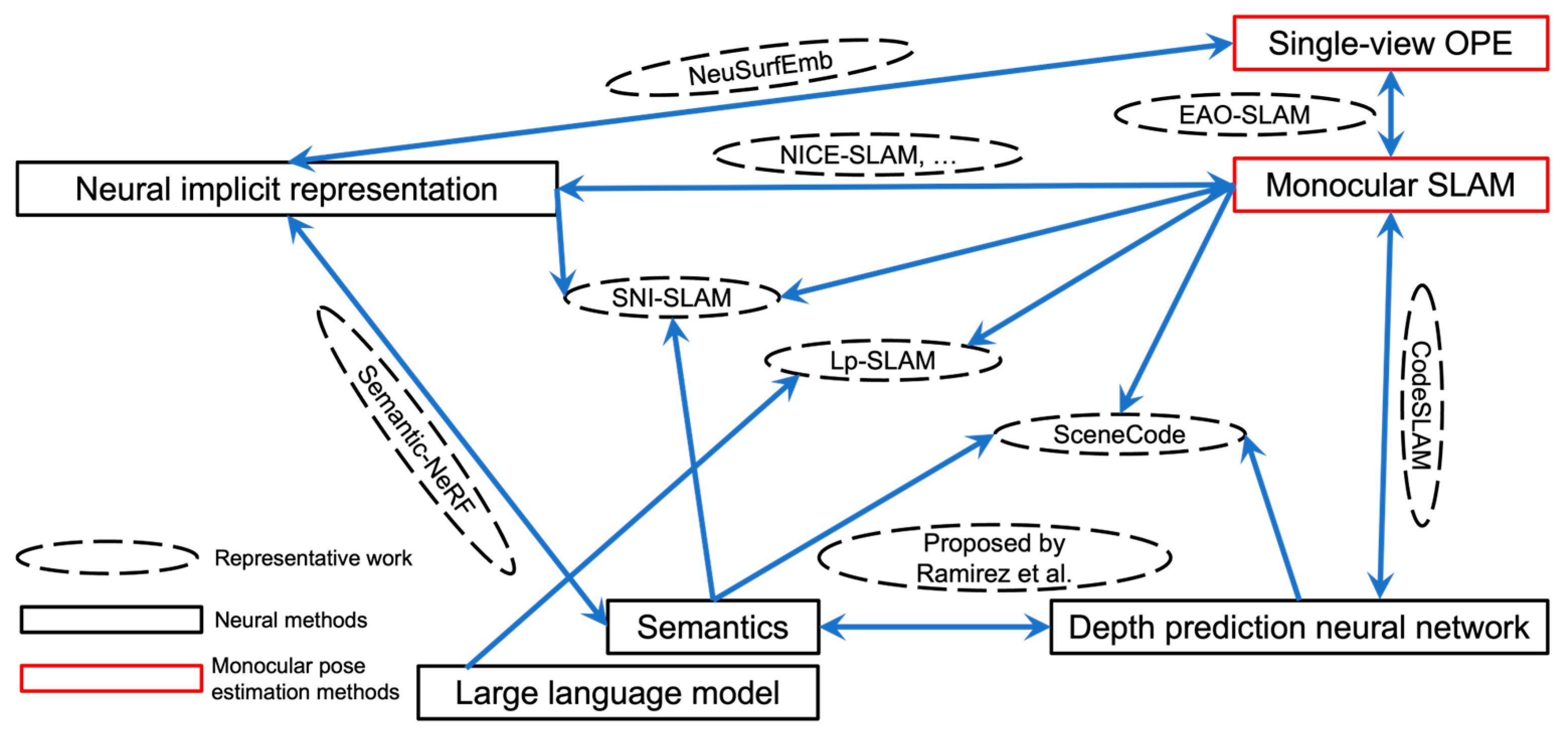
1. Introduction
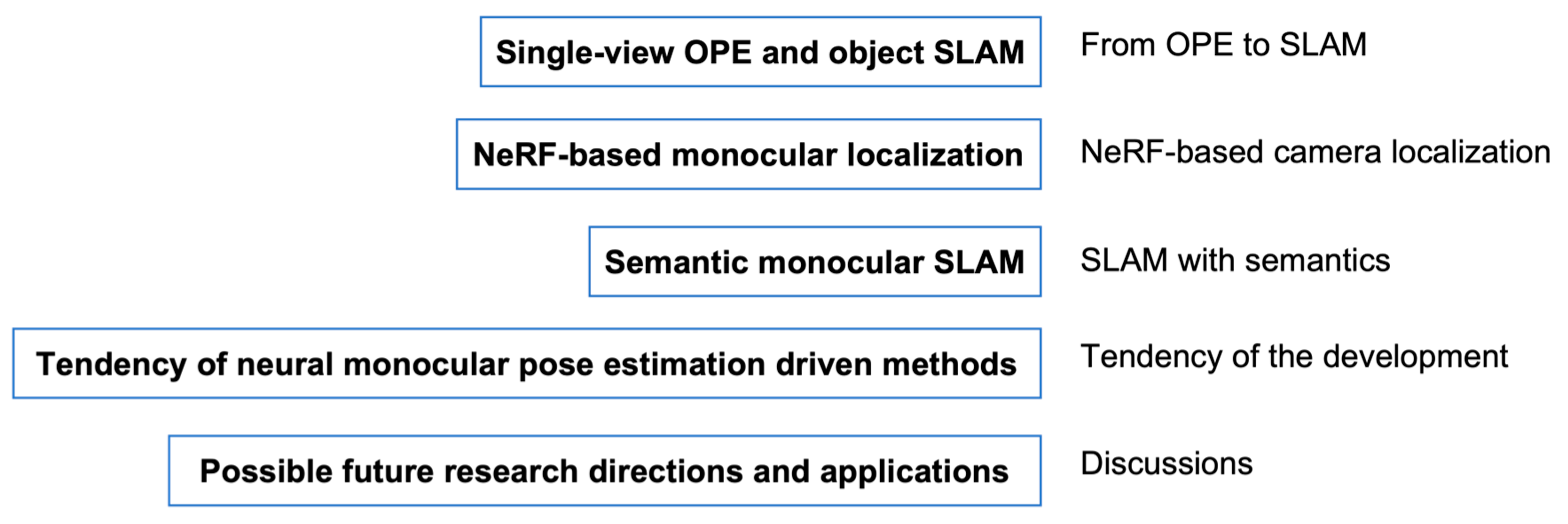
2. Single-View OPE and Object SLAM
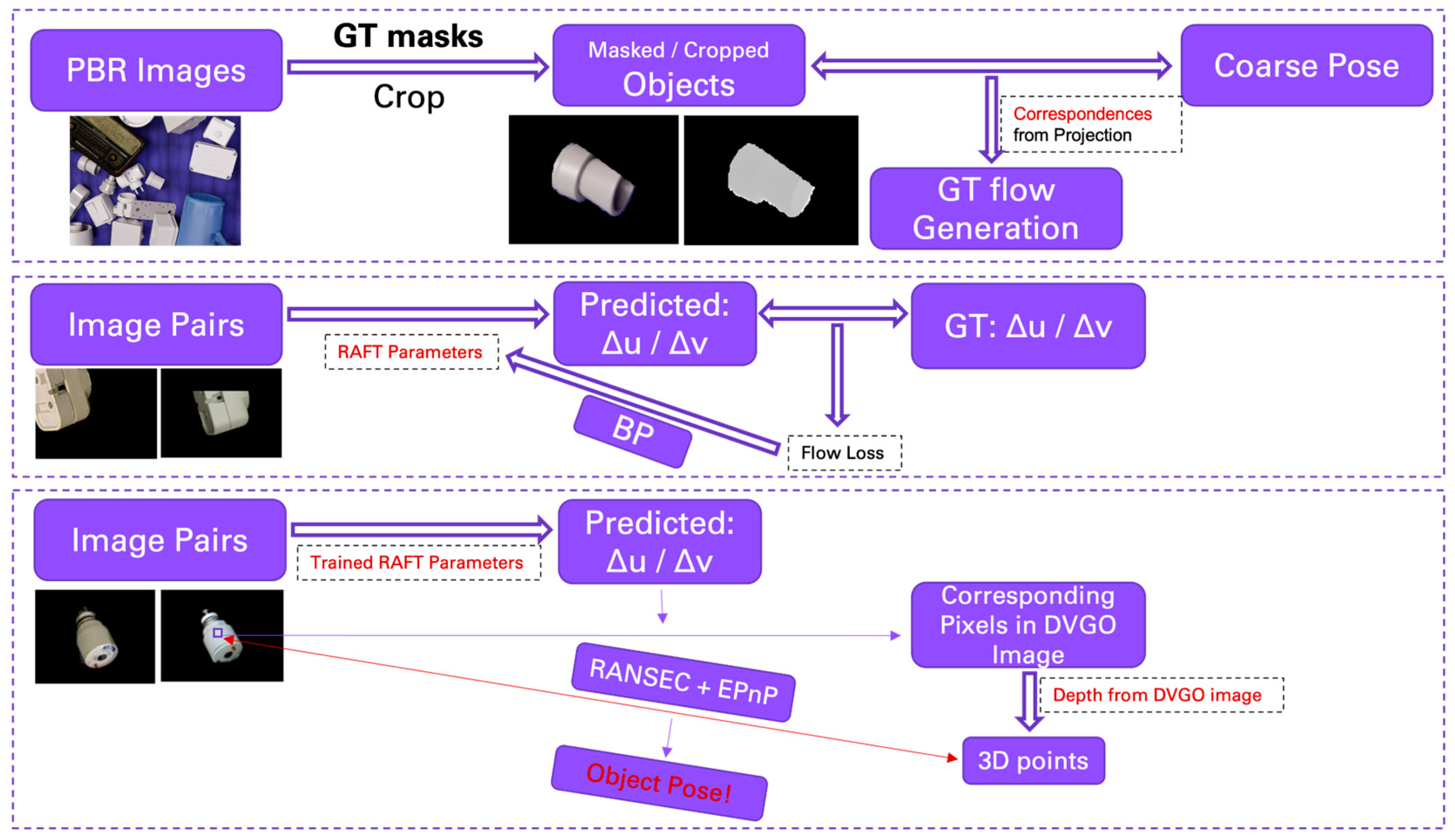
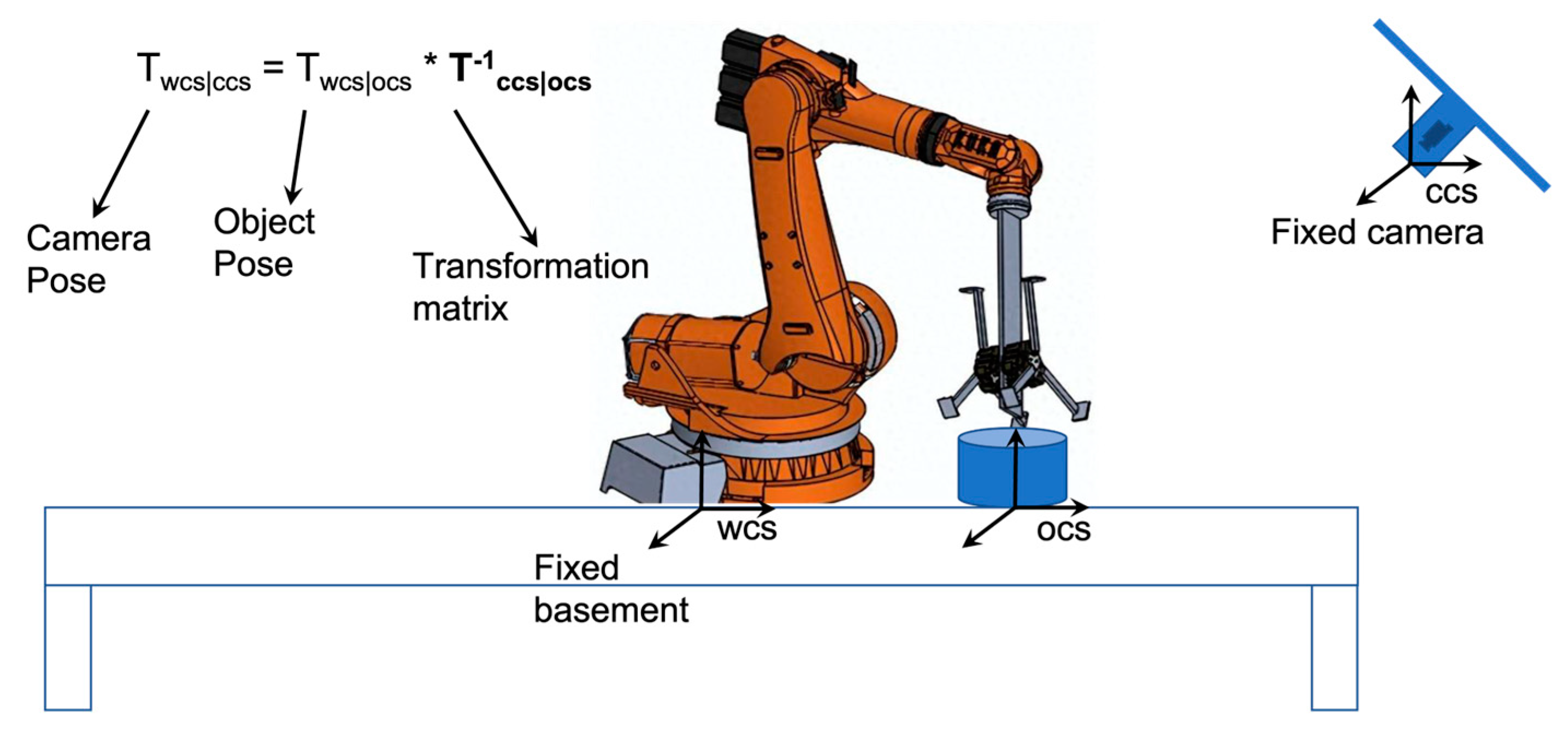
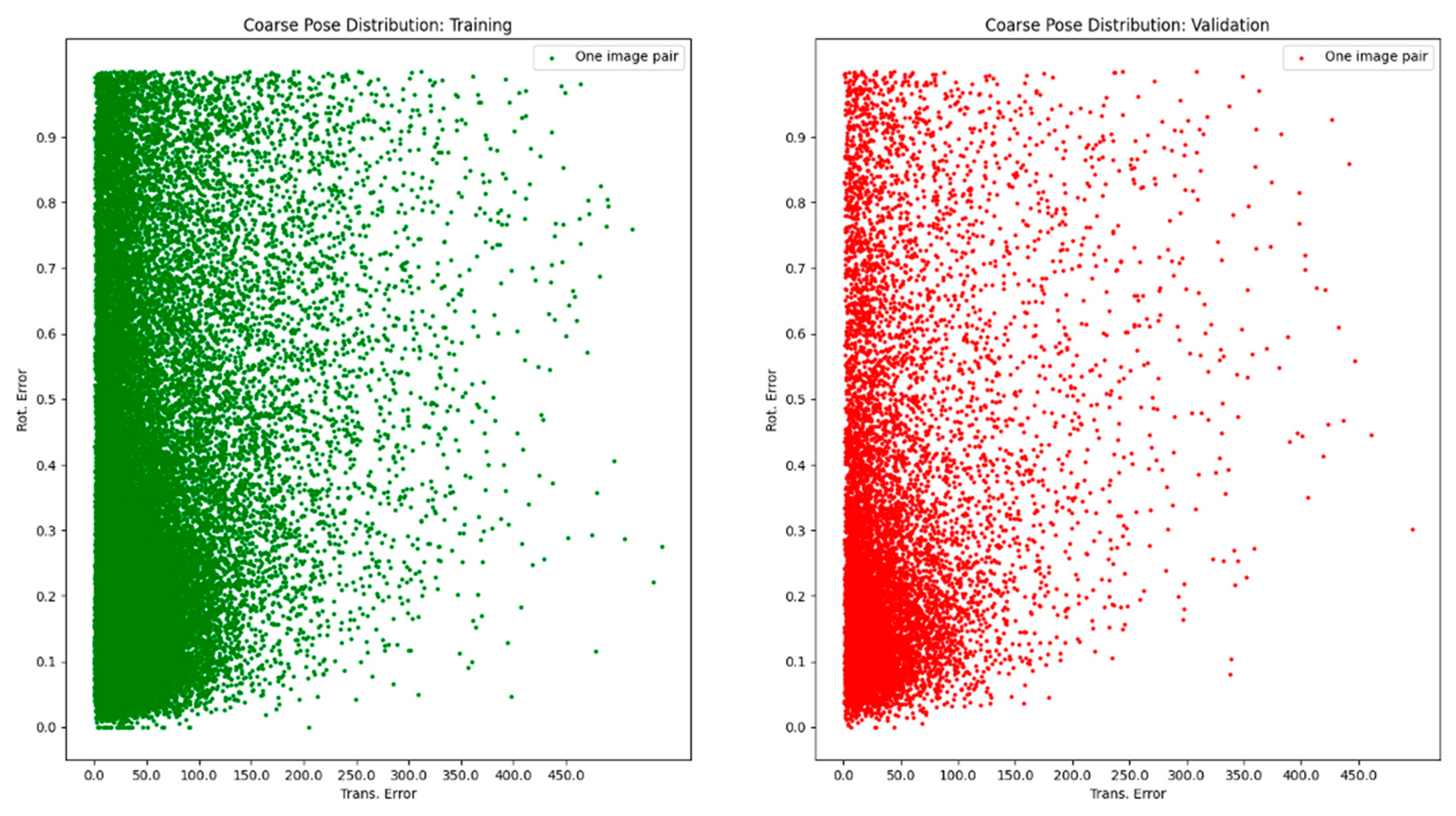
2.1. Single-View OPE
2.2. Object SLAM and OPE Plugging
3. NeRF-Based Monocular Localization
4. Semantic Monocular SLAM
4.1. Traditional Semantic Monocular SLAM
4.2. NeRF-Based Semantic Monocular SLAM
5. Tendency of Neural Monocular Pose Estimation Driven Methods
6. Possible Future Research Directions and Applications
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A Survey on Evaluation of Large Language Models. ACM Trans. Intel. Syst. Technol. 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Tawhid, M.; Ludher, A.S.; Hashim, H.A. Stochastic Observer for SLAM on the Lie Group. In Proceedings of the Modeling, Estimation and Control Conference (MECC), Austin, TX, USA, 24–27 October 2021. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Hashim, H.A.; Eltoukhy, A.E.E. Nonlinear Filter for Simultaneous Localization and Mapping on a Matrix Lie Group Using IMU and Feature Measurements. IEEE Trans. Syst. Man. Cybern. Syst. 2022, 52, 2098–2109. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, F. BALM: Bundle Adjustment for Lidar Mapping. IEEE Robot. Autom. Lett. 2021, 6, 3184–3191. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. Commun. ACM 2022, 65, 99–106. [Google Scholar] [CrossRef]
- Tosi, F.; Zhang, Y.; Gong, Z.; Sandström, E.; Mattoccia, S.; Oswald, M.R.; Poggi, M. How NeRFs and 3D Gaussian Splatting are Reshaping SLAM: A Survey. arXiv 2024, arXiv:2402.13255v2. [Google Scholar]
- Guan, J.; Hao, Y.; Wu, Q.; Li, S.; Fang, Y. A Survey of 6DoF Object Pose Estimation Methods for Different Application Scenarios. Sensors 2024, 24, 1076. [Google Scholar] [CrossRef]
- Hodan, T.; Michel, F.; Brachmann, E.; Kehl, W.; GlentBuch, A.; Kraft, D.; Drost, B.; Vidal, J.; Ihrke, S.; Zabulis, X.; et al. BOP: Benchmark for 6D Object Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, Y.; Speierer, S.; Jakob, W.; Fua, P.; Salzmann, M. Wide-Depth-Range 6D Object Pose Estimation in Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Hodan, T.; Haluza, P.; Obdržálek, Š.; Matas, J.; Lourakis, M.; Zabulis, X. T-LESS: An RGB-D Dataset for 6D Pose Estimation of Texture-less Objects. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 880–888. [Google Scholar]
- Labbé, Y.; Carpentier, J.; Aubry, M.; Sivic, J. CosyPose: Consistent Multi-view Multi-object 6D Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. DeepIM: Deep Iterative Matching for 6D Pose Estimation. Int. J. Comput. Vis. 2020, 128, 657–678. [Google Scholar] [CrossRef]
- Yen-Chen, L.; Florence, P.; Barron, J.T.; Rodriguez, A.; Isola, P.; Lin, T.Y. iNeRF: Inverting Neural Radiance Fields for Pose Estimation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Lipson, L.; Teed, Z.; Goyal, A.; Deng, J. Coupled Iterative Refinement for 6D Multi-Object Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Teed, Z.; Deng, J. RAFT: Recurrent all-pairs field transforms for optical flow. In Proceedings of the IEEE Conference on European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Moon, S.; Son, H.; Hur, D.; Kim, S. GenFlow: Generalizable Recurrent Flow for 6D Pose Refinement of Novel Objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Sun, C.; Sun, M.; Chen, H.T. Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Fridovich-Keil, S.; Yu, A.; Tancik, M.; Chen, Q.; Recht, B.; Kanazawa, A. Plenoxels: Radiance Fields without Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Chen, A.; Xu, Z.; Geiger, A.; Yu, J.; Su, H. TensoRF: Tensorial Radiance Fields. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. 2022, 41, 102:1–102:12. [Google Scholar] [CrossRef]
- Wilson, W.J.; Hulls, C.W.; Bell, G.S. Relative end-effector control using cartesian position based visual servoing. IEEE Trans. Robot. Autom. 1996, 12, 684–696. [Google Scholar] [CrossRef]
- Milano, F.; Chung, J.J.; Blum, H.; Siegwart, R.; Ott, L. NeuSurfEmb: A Complete Pipeline for Dense Correspondence-based 6D Object Pose Estimation without CAD Models. arXiv 2024, arXiv:2407.12207v1. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D Object Pose Estimation Using 3D Object Coordinates. In Proceedings of the IEEE Conference on European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Bohg, J.; Morales, A.; Asfour, T.; Kragic, D. Data-Driven Grasp Synthesis—A Survey. IEEE Trans. Robot. 2014, 30, 289–309. [Google Scholar] [CrossRef]
- Ichnowski, J.; Avigal, Y.; Kerr, J.; Goldberg, K. Dex-NeRF: Using a Neural Radiance Field to Grasp Transparent Objects. In Proceedings of the Conference on Robot Learning (CoRL), London, UK, 8–11 November 2021. [Google Scholar]
- Mahler, J.; Pokorny, F.T.; Hou, B.; Roderick, M.; Laskey, M.; Aubry, M.; Kohlhoff, K.; Kröger, T.; Kuffner, J.; Goldberg, K. Dex-Net 1.0: A cloud-based network of 3D objects for robust grasp planning using a Multi-Armed Bandit model with correlated rewards. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.; Davison, A.J. SLAM++: Simultaneous Localisation and Mapping at the Level of Objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality(ISMAR), Basel, Switzerland, 26–29 October 2011. [Google Scholar]
- Yang, S.; Scherer, S. CubeSLAM: Monocular 3-D Object SLAM. IEEE Trans. Robot. 2019, 35, 925–938. [Google Scholar] [CrossRef]
- Lin, Y.; Müller, T.; Tremblay, J.; Wen, B.; Tyree, S.; Evans, A.; Vela, P.A.; Birchfield, S. Parallel Inversion of Neural Radiance Fields for Robust Pose Estimation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Lin, C.H.; Ma, W.C.; Torralba, A.; Lucey, S. BARF: Bundle-Adjusting Neural Radiance Fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Jang, W.; Agapito, L. CodeNeRF: Disentangled Neural Radiance Fields for Object Categories. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Wang, Z.; Wu, S.; Xie, W.; Chen, M.; Prisacariu, V.A. NeRF—Neural Radiance Fields Without Known Camera Parameters. arXiv 2021, arXiv:2102.07064. [Google Scholar]
- Sucar, E.; Liu, S.; Ortiz, J.; Davison, A.J. iMAP: Implicit Mapping and Positioning in Real-Time. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Zhuge, Y.; Luo, H.; Chen, R.; Chen, Y.; Yan, J.; Jiang, Z. ONeK-SLAM: A Robust Object-level Dense SLAM Based on Joint Neural Radiance Fields and Keypoints. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Castle, R.O.; Gawley, D.J.; Klein, G.; Murray, D.W. Towards simultaneous recognition, localization and mapping for hand-held and wearable cameras. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Rome, Italy, 10–14 April 2007. [Google Scholar]
- Civera, J.; Gálvez-López, D.; Riazuelo, L.; Tardós, J.D.; Montiel, J.M.M. Towards semantic SLAM using a monocular camera. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011. [Google Scholar]
- Bao, S.Y.; Savarese, S. Semantic structure from motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011. [Google Scholar]
- Dame, A.; Prisacariu, V.A.; Ren, C.Y.; Reid, I. Dense Reconstruction Using 3D Object Shape Priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Fioraio, N.; Di Stefano, L. Joint Detection, Tracking and Mapping by Semantic Bundle Adjustment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Li, C.; Xiao, H.; Tateno, K.; Tombari, F.; Navab, N.; Hager, G.D. Incremental scene understanding on dense SLAM. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016. [Google Scholar]
- Bowman, S.L.; Atanasov, N.; Daniilidis, K.; Pappas, G.J. Probabilistic Data Association for Semantic SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Moon, T.K. The expectation-maximization algorithm. IEEE Signal Process Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Toft, C.; Olsson, C.; Kahl, F. Long-Term 3D Localization and Pose from Semantic Labellings. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lianos, K.N.; Schonberger, J.L.; Pollefeys, M.; Sattler, T. VSO: Visual Semantic Odometry. In Proceedings of the IEEE European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Whelan, T.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J.; Leutenegger, S. ElasticFusion: Real-Time Dense SLAM and Light Source Estimation. In Proceedings of the Conference on Robotics—Science and Systems (RSS), Rome, Italy, 12–16 July 2015. [Google Scholar]
- Tosi, F.; Aleotti, F.; Ramirez, P.Z.; Poggi, M.; Salti, S.; Stefano, L.D.; Mattoccia, S. Distilled Semantics for Comprehensive Scene Understanding from Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Sagar, A.S.M.S.; Chen, Y.; Xie, Y.K.; Kim, H.S. MSA R-CNN: A comprehensive approach to remote sensing object detection and scene understanding. Expert. Syst. Appl. 2024, 241, 122788. [Google Scholar] [CrossRef]
- Ma, P.; Bai, Y.; Zhu, J.; Wang, C.; Peng, C. DSOD: DSO in Dynamic Environments. IEEE Access 2019, 7, 178300–178309. [Google Scholar] [CrossRef]
- Bao, Y.; Yang, Z.; Pan, Y.; Huan, R. Semantic-Direct Visual Odometry. IEEE Robot. Autom. Lett. 2022, 7, 6718–6725. [Google Scholar] [CrossRef]
- Fernandez-Cortizas, M.; Bavle, H.; Perez-Saura, D.; Sanchez-Lopez, J.L.; Campoy, P.; Voos, H. Multi S-Graphs: An Efficient Distributed Semantic-Relational Collaborative SLAM. IEEE Robot. Autom. Lett. 2024, 49, 6004–6011. [Google Scholar] [CrossRef]
- Zhu, S.; Wang, G.; Blum, H.; Liu, J.; Song, L.; Pollefeys, M.; Wang, H. SNI-SLAM: Semantic Neural Implicit SLAM. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Li, M.; Liu, S.; Zhou, H.; Zhu, G.; Cheng, N.; Deng, T.; Wang, H. SGS-SLAM: Semantic Gaussian Splatting For Neural Dense SLAM. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 Sepetember–4 October 2024. [Google Scholar]
- Ming, Y.; Yang, X.; Wang, W.; Chen, Z.; Feng, J.; Xing, Y.; Zhang, G. Benchmarking neural radiance fields for autonomous robots: An overview. Eng. Appl. Artif. Intel. 2025, 140, 109685. [Google Scholar] [CrossRef]
- Ramirez, P.Z.; Poggi, M.; Tosi, F.; Mattoccia, S.; Di Stefano, L. Geometry Meets Semantics for Semi-supervised Monocular Depth Estimation. In Proceedings of the Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018. [Google Scholar]
- Bloesch, M.; Czarnowski, J.; Clark, R.; Leutenegger, S.; Davison, A.J. CodeSLAM—Learning a Compact, Optimisable Representation for Dense Visual SLAM. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhi, S.; Bloesch, M.; Leutenegger, S.; Davison, A.J. Scenecode: Monocular dense semantic reconstruction using learned encoded scene representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, BC, Canada, 16–20 June 2019. [Google Scholar]
- Zhi, S.; Laidlow, T.; Leutenegger, S.; Davison, A.J. In-Place Scene Labelling and Understanding with Implicit Scene Representation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Wu, Y.; Zhang, Y.; Zhu, D.; Feng, Y.; Coleman, S.; Kerr, D. EAO-SLAM: Monocular Semi-Dense Object SLAM Based on Ensemble Data Association. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021. [Google Scholar]
- Wu, Y.; Zhang, Y.; Zhu, D.; Deng, Z.; Sun, W.; Chen, X.; Zhang, J. An Object SLAM Framework for Association, Mapping, and High-Level Tasks. IEEE Trans. Robot. 2023, 39, 2912–2932. [Google Scholar] [CrossRef]
- Zhang, W.; Guo, Y.; Niu, L.; Li, P.; Wan, Z.; Shao, F.; Nian, C.; Ud Din Farrukh, F.; Zhang, D.; Zhang, C.; et al. Lp-slam: Language-perceptive RGB-D SLAM framework exploiting large language model. Complex Int. Ell. Syst. 2024, 10, 5391–5409. [Google Scholar] [CrossRef]
- Amaduzzi, A.; Ramirez, P.Z.; Lisanti, G.; Salti, S.; Di Stefano, L. LLaNA: Large Language and NeRF Assistant. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 9–15 December 2024. [Google Scholar]
- Bosché, F.; Ahmed, M.; Turkan, Y.; Haas, C.T.; Haas, R. The value of integrating Scan-to-BIM and Scan-vs-BIM techniques for construction monitoring using laser scanning and BIM: The case of cylindrical MEP components. Autom. Constr. 2015, 49, 201–213. [Google Scholar] [CrossRef]
- Asadi, K.; Ramshankar, H.; Noghabaei, M.; Han, K. Real-Time Image Localization and Registration with BIM Using Perspective Alignment for Indoor Monitoring of Construction. J. Comput Civil Eng. 2019, 33, 04019031. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Domain | Subdomain | Promising Methods |
|---|---|---|
| Mechanical Engineering | Intelligent Manufacturing | SLAM + OPE |
| Civil Engineering | Intelligent Construction | SLAM + OPE driven BIM |
| Automatic Driving | Perception | SLAM + OPE |
| Real Robots | Real Perception | SLAM + OPE |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; Song, G.; Ai, Q. A Survey of Robotic Monocular Pose Estimation. Sensors 2025, 25, 1519. https://doi.org/10.3390/s25051519
Zhang K, Song G, Ai Q. A Survey of Robotic Monocular Pose Estimation. Sensors. 2025; 25(5):1519. https://doi.org/10.3390/s25051519
Chicago/Turabian StyleZhang, Kun, Guozheng Song, and Qinglin Ai. 2025. "A Survey of Robotic Monocular Pose Estimation" Sensors 25, no. 5: 1519. https://doi.org/10.3390/s25051519
APA StyleZhang, K., Song, G., & Ai, Q. (2025). A Survey of Robotic Monocular Pose Estimation. Sensors, 25(5), 1519. https://doi.org/10.3390/s25051519