

An Efficient and Low-Complexity Transformer-Based Deep Learning Framework for High-Dynamic-Range Image Reconstruction



Abstract

1. Introduction
- We propose a new high-quality HDR reconstruction architecture based on Transformers that has a lower computational cost than current state-of-the-art methodologies.
- We introduce the use of CBAM blocks to enhance input features in the self-attention mechanisms of the Transformer architecture for HDR reconstruction.
- Exhaustive experiments are conducted to demonstrate the effectiveness of the proposed HDR reconstruction. Two main aspects are explored: the computational cost required and the quality of the HDR output image, considering both quantitative and qualitative comparisons.
2. Related Works
3. Proposed Method
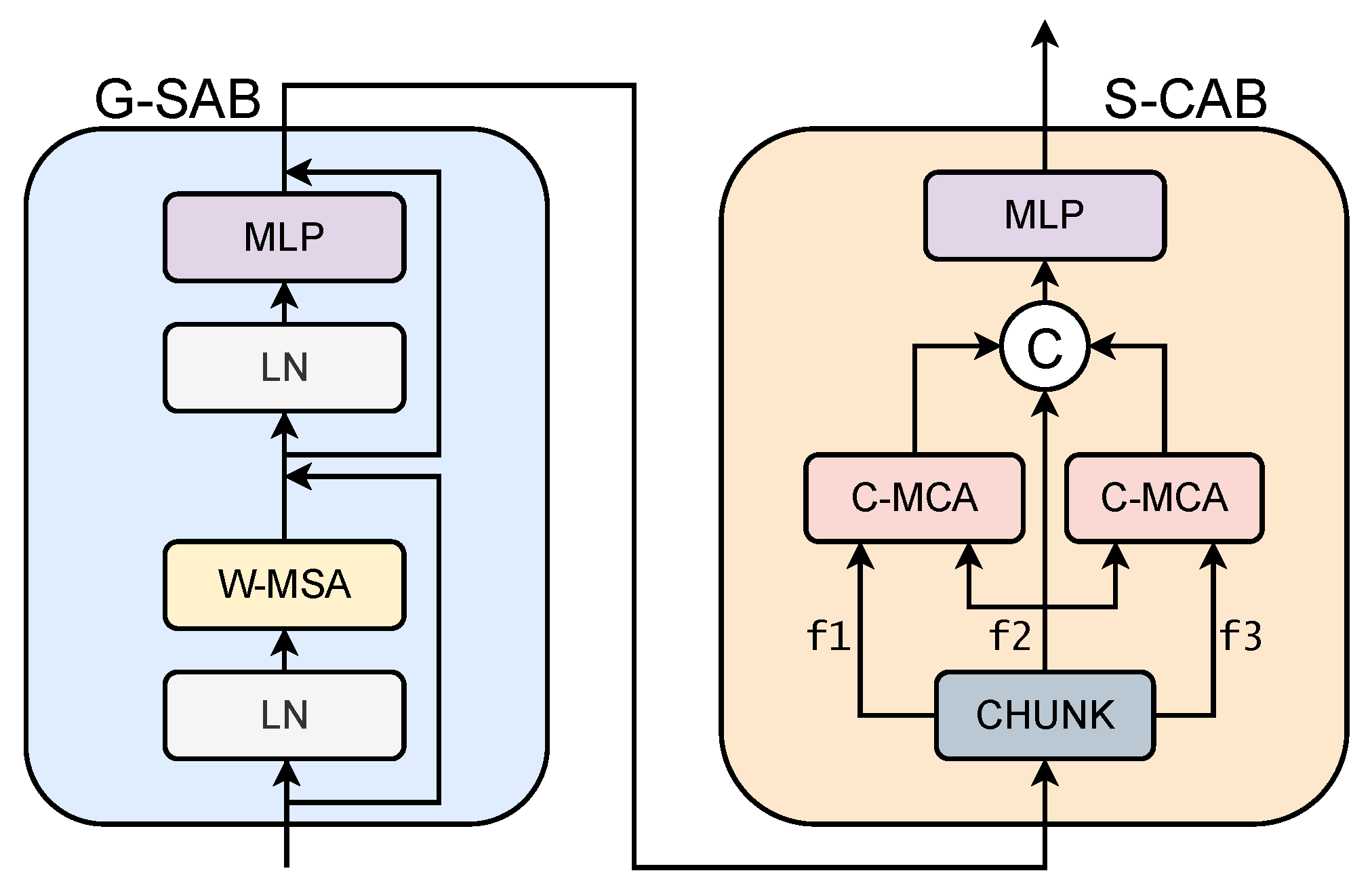
3.1. Overall Architecture
3.2. Feature Extraction
3.2.1. CBAM
3.2.2. Feature Concatenation
3.3. Feature Refinement
3.3.1. G-SAB
3.3.2. S-CAB
3.3.3. Skip Connection
3.4. Loss Function
4. Experiments and Results
4.1. Implementation Details
4.1.1. Datasets
4.1.2. Experimental Setup
4.1.3. Evaluation Metrics
4.2. Evaluation and Comparison
4.2.1. Quantitative Analysis
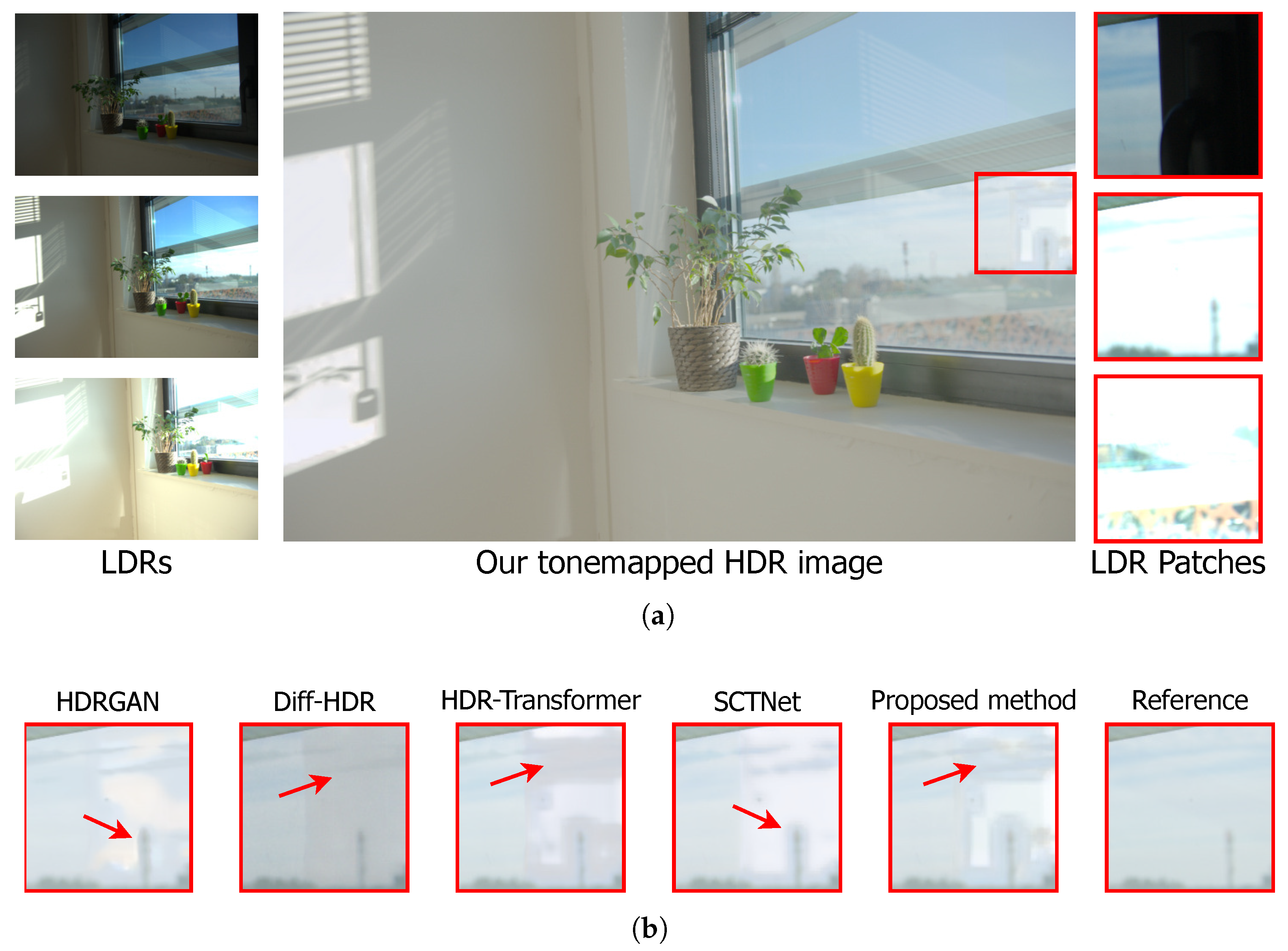
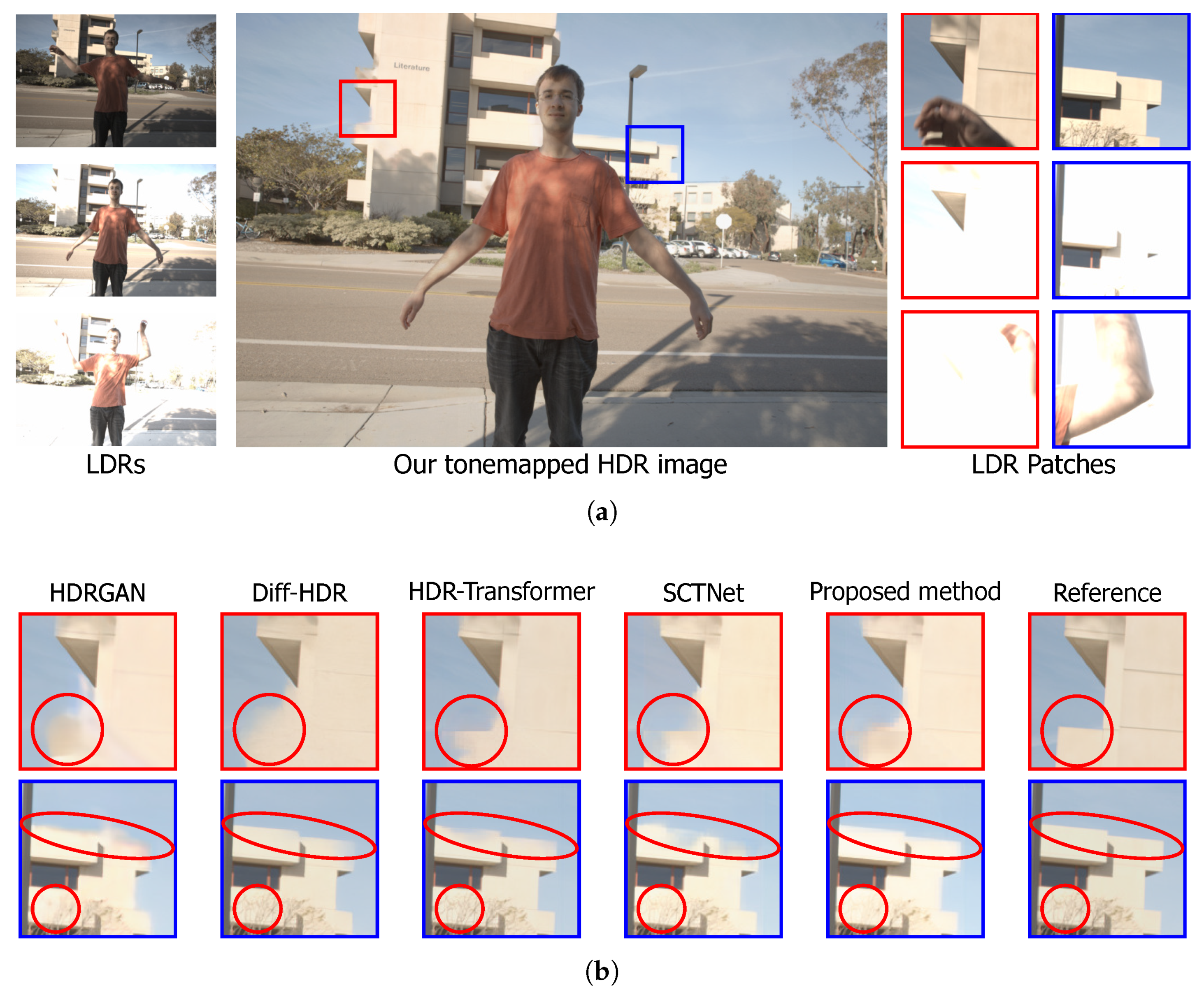
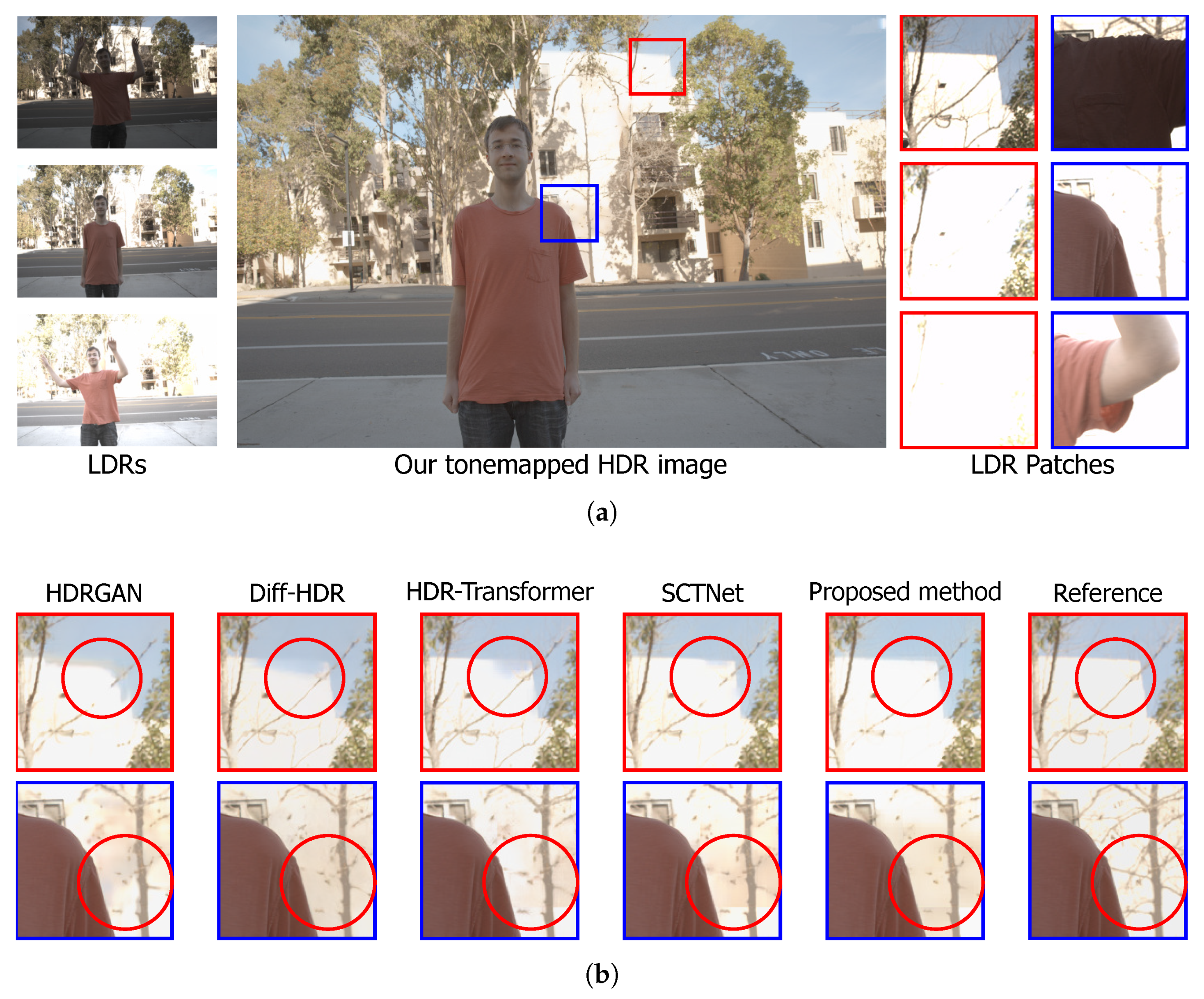
4.2.2. Qualitative Analysis
4.2.3. Comparison of Computational Cost
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mann, S.; Picard, R. On being ’undigital’ with digital cameras: Extending Dynamic Range by Combining Differently Exposed Pictures. In Proceedings of the IS&T’s 48th Annual Conference: Society for Imaging Science and Technology, Washington, DC, USA, 7–11 May 1995; pp. 422–428. [Google Scholar]
- Chaurasiya, R.K.; Ramakrishnan, K. High dynamic range imaging. In Proceedings of the 2013 International Conference on Communication Systems and Network Technologies, Gwalior, India, 6–8 April 2013; pp. 83–89. [Google Scholar]
- Nayar, S.K.; Mitsunaga, T. High dynamic range imaging: Spatially varying pixel exposures. In Proceedings of the IEEE/CVPR Conference on Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 15 June 2000; Volume 1, pp. 472–479. [Google Scholar]
- Tumblin, J.; Agrawal, A.; Raskar, R. Why I want a gradient camera. In Proceedings of the IEEE/CVPR Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 103–110. [Google Scholar]
- Heo, Y.S.; Lee, K.M.; Lee, S.U.; Moon, Y.; Cha, J. Ghost-free high dynamic range imaging. In Computer Vision—ACCV 2010, 10th Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010, Revised Selected Papers, Part IV; Springer: Berlin/Heidelberg, Germany, 2010; pp. 486–500. [Google Scholar]
- Yan, Q.; Sun, J.; Li, H.; Zhu, Y.; Zhang, Y. High dynamic range imaging by sparse representation. Neurocomputing 2017, 269, 160–169. [Google Scholar] [CrossRef]
- Gallo, O.; Gelfandz, N.; Chen, W.C.; Tico, M.; Pulli, K. Artifact-free high dynamic range imaging. In Proceedings of the 2009 IEEE International Conference on Computational Photography (ICCP), San Francisco, CA, USA, 16–17 April 2009; pp. 1–7. [Google Scholar]
- Grosch, T. Fast and robust high dynamic range image generation with camera and object movement. In Proceedings of the 11th international Workshop Vision, Modeling, and Visualization, Aanchen, Germany, 22–24 November 2006; pp. 277–284. [Google Scholar]
- Ward, G. Fast, robust image registration for compositing high dynamic range photographs from hand-held exposures. J. Graph. Tools 2003, 8, 17–30. [Google Scholar] [CrossRef]
- Tomaszewska, A.; Mantiuk, R. Image Registration for Multi-Exposure High Dynamic Range Image Acquisition. In Proceedings of the WSCG 15th International Conference in Central Europe on Computer Graphics, Visualization and Computer Vision, Bory, Czech Republic, 29 January–1 February 2007; pp. 49–56. [Google Scholar]
- Bogoni, L. Extending dynamic range of monochrome and color images through fusion. In Proceedings of the 15th International Conference on Pattern Recognition (ICPR-2000), Barcelona, Spain, 3–7 September 2000; Voume 3, pp. 7–12. [Google Scholar]
- Zimmer, H.; Bruhn, A.; Weickert, J. Freehand HDR imaging of moving scenes with simultaneous resolution enhancement. Comput. Graph. Forum 2011, 30, 405–414. [Google Scholar] [CrossRef]
- Sen, P.; Kalantari, N.K.; Yaesoubi, M.; Darabi, S.; Goldman, D.B.; Shechtman, E. Robust patch-based HDR reconstruction of dynamic scenes. ACM Trans. Graph. 2012, 31, 203. [Google Scholar] [CrossRef]
- Hu, J.; Gallo, O.; Pulli, K.; Sun, X. HDR deghosting: How to deal with saturation? In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1163–1170. [Google Scholar]
- Zheng, J.; Li, Z.; Zhu, Z.; Wu, S.; Rahardja, S. Hybrid patching for a sequence of differently exposed images with moving objects. IEEE Trans. Image Process. 2013, 22, 5190–5201. [Google Scholar] [CrossRef]
- Banterle, F.; Ledda, P.; Debattista, K.; Chalmers, A. Inverse tone mapping. In Proceedings of the 4th International Conference on Computer Graphics and Interactive Techniques in Australasia and Southeast Asia, Kuala Lumpur, Malaysia, 29 November–2 December 2006; pp. 349–356. [Google Scholar]
- Chen, X.; Liu, Y.; Zhang, Z.; Qiao, Y.; Dong, C. Hdrunet: Single image HDR reconstruction with denoising and dequantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 354–363. [Google Scholar]
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. In Seminal Graphics Papers: Pushing the Boundaries; Association for Computing Machinery: New York, NY, USA, 2023; Volume 2, pp. 643–652. [Google Scholar]
- Liu, M.; Rehman, S.; Tang, X.; Gu, K.; Fan, Q.; Chen, D.; Ma, W. Methodologies for improving HDR efficiency. Front. Genet. 2019, 9, 691. [Google Scholar] [CrossRef]
- Karađuzović-Hadžiabdić, K.; Telalović, J.H.; Mantiuk, R.K. Assessment of multi-exposure HDR image deghosting methods. Comput. Graph. 2017, 63, 1–17. [Google Scholar] [CrossRef]
- Catley-Chandar, S.; Tanay, T.; Vandroux, L.; Leonardis, A.; Slabaugh, G.; Pérez-Pellitero, E. Flexhdr: Modeling alignment and exposure uncertainties for flexible HDR imaging. IEEE Trans. Image Process. 2022, 31, 5923–5935. [Google Scholar] [CrossRef]
- Peng, F.; Zhang, M.; Lai, S.; Tan, H.; Yan, S. Deep HDR reconstruction of dynamic scenes. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 347–351. [Google Scholar]
- Nemoto, H.; Korshunov, P.; Hanhart, P.; Ebrahimi, T. Visual attention in LDR and HDR images. In Proceedings of the 9th International Workshop on Video Processing and Quality Metrics for Consumer Electronics (VPQM), Chandler, AZ, USA, 5–6 February 2015; pp. 1–6. [Google Scholar]
- Yoon, H.; Uddin, S.N.; Jung, Y.J. Multi-scale attention-guided non-local network for HDR image reconstruction. Sensors 2022, 22, 7044. [Google Scholar] [CrossRef]
- Deng, Y.; Liu, Q.; Ikenaga, T. Multi-scale contextual attention based HDR reconstruction of dynamic scenes. In Proceedings of the Twelfth International Conference on Digital Image Processing (ICDIP 2020), Osaka, Japan, 19–22 May 2020; Volume 11519, pp. 413–419. [Google Scholar]
- KS, G.R.; Biswas, A.; Patel, M.S.; Prasad, B.P. Deep multi-stage learning for HDR with large object motions. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4714–4718. [Google Scholar]
- Liu, Z.; Lin, W.; Li, X.; Rao, Q.; Jiang, T.; Han, M.; Fan, H.; Sun, J.; Liu, S. ADNet: Attention-guided deformable convolutional network for high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 463–470. [Google Scholar]
- Kong, L.; Li, B.; Xiong, Y.; Zhang, H.; Gu, H.; Chen, J. SAFNet: Selective Alignment Fusion Network for Efficient HDR Imaging. In Computer Vision—ECCV 2024, 18th European Conference, Milan, Italy, 29 September–4 October 2024, Proceedings, Part XXVI; Springer: Cham, Switzerland, 2025; pp. 256–273. [Google Scholar]
- Yan, Q.; Hu, T.; Sun, Y.; Tang, H.; Zhu, Y.; Dong, W.; Van Gool, L.; Zhang, Y. Towards high-quality HDR deghosting with conditional diffusion models. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 4011–4026. [Google Scholar] [CrossRef]
- Niu, Y.; Wu, J.; Liu, W.; Guo, W.; Lau, R.W. Hdr-gan: Hdr image reconstruction from multi-exposed ldr images with large motions. IEEE Trans. Image Process. 2021, 30, 3885–3896. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Wang, Y.; Zeng, B.; Liu, S. Ghost-free high dynamic range imaging with context-aware transformer. In Computer Vision—ECCV, 17th European Conference, Tel Aviv, Israel, 23–27 October 2022, Proceedings, Part XIX; Springer: Cham, Switzerland, 2022; pp. 344–360. [Google Scholar]
- Tel, S.; Wu, Z.; Zhang, Y.; Heyrman, B.; Demonceaux, C.; Timofte, R.; Ginhac, D. Alignment-free HDR deghosting with semantics consistent transformer. In Proceeding of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 12790–12799. [Google Scholar]
- Hittawe, M.M.; Harrou, F.; Togou, M.A.; Sun, Y.; Knio, O. Time-series weather prediction in the Red sea using ensemble transformers. Appl. Soft Comput. 2024, 164, 111926. [Google Scholar] [CrossRef]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Jagalingam, P.; Hegde, A.V. A review of quality metrics for fused image. Aquat. Procedia 2015, 4, 133–142. [Google Scholar] [CrossRef]
- Pérez-Pellitero, E.; Catley-Chandar, S.; Shaw, R.; Leonardis, A.; Timofte, R.; Zhang, Z.; Liu, C.; Peng, Y.; Lin, Y.; Yu, G.; et al. NTIRE 2022 challenge on high dynamic range imaging: Methods and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 1009–1023. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Kalantari, N.K.; Ramamoorthi, R. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph. 2017, 36, 144. [Google Scholar] [CrossRef]
- Paul, N.; Chung, C. Application of HDR algorithms to solve direct sunlight problems when autonomous vehicles using machine vision systems are driving into sun. Comput. Ind. 2018, 98, 192–196. [Google Scholar] [CrossRef]
- Kim, J.; Zhu, Z.; Bau, T.; Liu, C. DCDR-UNet: Deformable Convolution Based Detail Restoration via U-shape Network for Single Image HDR Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 5909–5918. [Google Scholar]
- Tursun, O.T.; Akyüz, A.O.; Erdem, A.; Erdem, E. The state of the art in HDR deghosting: A survey and evaluation. Comput. Graph. Forum 2015, 34, 683–707. [Google Scholar] [CrossRef]
- Zhang, X.; Hu, T.; He, J.; Yan, Q. Efficient content reconstruction for high dynamic range imaging. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 7660–7664. [Google Scholar]
- Tel, S.; Heyrman, B.; Ginhac, D. CEN-HDR: Computationally efficient neural network for real-time high dynamic range imaging. In Computer Vision—ECCV Workshops, Tel Aviv, Israel, 23–27 October 2022, Proceedings, Part II; Springer: Cham, Switzerland, 2022; pp. 378–394. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Kim, J.; Kim, M.H. Joint demosaicing and deghosting of time-varying exposures for single-shot HDR imaging. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12292–12301. [Google Scholar]
- Zhou, F.; Fu, Z.; Zhang, D. High dynamic range imaging with context-aware transformer. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar]
- Chen, R.; Zheng, B.; Zhang, H.; Chen, Q.; Yan, C.; Slabaugh, G.; Yuan, S. Improving dynamic HDR imaging with fusion transformer. AAAI Conf. Artif. Intell. 2023, 37, 340–349. [Google Scholar] [CrossRef]
- Liu, X.; Li, A.; Wu, Z.; Du, Y.; Zhang, L.; Zhang, Y.; Timofte, R.; Zhu, C. PASTA: Towards Flexible and Efficient HDR Imaging Via Progressively Aggregated Spatio-Temporal Aligment. arXiv 2024, arXiv:2403.10376. [Google Scholar]
- Yan, Q.; Chen, W.; Zhang, S.; Zhu, Y.; Sun, J.; Zhang, Y. A unified HDR imaging method with pixel and patch level. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22211–22220. [Google Scholar]
- Chi, Y.; Zhang, X.; Chan, S.H. Hdr imaging with spatially varying signal-to-noise ratios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5724–5734. [Google Scholar]
- Yan, Q.; Zhang, S.; Chen, W.; Tang, H.; Zhu, Y.; Sun, J.; Van Gool, L.; Zhang, Y. Smae: Few-shot learning for HDR deghosting with saturation-aware masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5775–5784. [Google Scholar]
- Wu, S.; Xu, J.; Tai, Y.W.; Tang, C.K. Deep High Dynamic Range Imaging with Large Foreground Motions. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 120–135. [Google Scholar]
- Yan, Q.; Zhang, L.; Liu, Y.; Zhu, Y.; Sun, J.; Shi, Q.; Zhang, Y. Deep HDR imaging via a non-local network. IEEE Trans. Image Process. 2020, 29, 4308–4322. [Google Scholar] [CrossRef] [PubMed]
- Yan, Q.; Gong, D.; Shi, Q.; Hengel, A.v.d.; Shen, C.; Reid, I.; Zhang, Y. Attention-guided network for ghost-free high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1751–1760. [Google Scholar]
- Chen, J.; Yang, Z.; Chan, T.N.; Li, H.; Hou, J.; Chau, L.P. Attention-guided progressive neural texture fusion for high dynamic range image restoration. IEEE Trans. Image Process. 2022, 31, 2661–2672. [Google Scholar] [CrossRef] [PubMed]
- Song, J.W.; Park, Y.I.; Kong, K.; Kwak, J.; Kang, S.J. Selective transhdr: Transformer-based selective HDR imaging using ghost region mask. In Computer Vision—ECCV, 17th European Conference, Tel Aviv, Israel, 23–27 October 2022, Proceedings, Part XVII; Springer: Cham, Switzerland, 2022; pp. 288–304. [Google Scholar]
- Jam, J.; Kendrick, C.; Drouard, V.; Walker, K.; Hsu, G.S.; Yap, M.H. R-mnet: A perceptual adversarial network for image inpainting. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 2714–2723. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Mantiuk, R.; Kim, K.J.; Rempel, A.G.; Heidrich, W. HDR-VDP-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions. ACM Trans. Graph. (TOG) 2011, 30, 1–14. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | -PSNR ↑ | l-PSNR ↑ | -SSIM ↑ | l-SSIM ↑ | HDR-VDP-2 ↑ |
|---|---|---|---|---|---|
| HDR-GAN [30] | 40.32 | 44.35 | 0.9833 | 0.9913 | 67.89 |
| Diff-HDR [29] | 42.33 | 46.79 | 0.9849 | 0.9948 | 68.91 |
| HDR-Transformer [31] | 42.39 | 46.35 | 0.9844 | 0.9948 | 69.23 |
| SCTNet [32] | 42.55 | 47.51 | 0.9850 | 0.9952 | 70.66 |
| Proposed method | 43.16 | 47.46 | 0.9876 | 0.9956 | 69.76 |
| Method | -PSNR ↑ | l-PSNR ↑ | -SSIM ↑ | l-SSIM ↑ | HDR-VDP-2 ↑ |
|---|---|---|---|---|---|
| HDR-GAN [30] | 43.92 | 41.57 | 0.9905 | 0.9865 | 65.45 |
| Diff-HDR [29] | 44.11 | 41.73 | 0.9911 | 0.9885 | 65.52 |
| HDR-Transformer [31] | 44.32 | 42.18 | 0.9916 | 0.9884 | 66.03 |
| SCTNet [32] | 44.49 | 42.29 | 0.9924 | 0.9887 | 66.65 |
| Proposed method | 44.10 | 42.07 | 0.9917 | 0.9886 | 67.79 |
| Method | Par. (M) ↓ | MAC (G) ↓ | Size (MB) ↓ | Inf. (s) ↓ |
|---|---|---|---|---|
| HDR-GAN [30] | 2.63 | 778.61 | 10.6 | 0.19 |
| Diff-HDR [29] | 75.13 | — | 289.0 | 178.16 |
| HDR-Transformer [31] | 1.22 | 981.81 | 53.4 | 7.61 |
| SCTNet [32] | 0.99 | 255.54 | 28.0 | 6.28 |
| Proposed method | 0.29 | 84.95 | 7.9 | 2.19 |
| Base | CBAM | SCT | Skip c. | -PSNR ↑ | l-PSNR ↑ | -SSIM ↑ | l-SSIM ↑ |
|---|---|---|---|---|---|---|---|
| ✔ | ✘ | ✘ | ✘ | 27.05 | 28.68 | 0.9518 | 0.9440 |
| ✔ | ✔ | ✘ | ✘ | 36.16 | 36.30 | 0.9818 | 0.9777 |
| ✔ | ✔ | ✔ | ✘ | 44.03 | 41.97 | 0.9915 | 0.9880 |
| ✔ | ✔ | ✔ | ✔ | 44.10 | 42.07 | 0.9917 | 0.9886 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopez-Cabrejos, J.; Paixão, T.; Alvarez, A.B.; Luque, D.B. An Efficient and Low-Complexity Transformer-Based Deep Learning Framework for High-Dynamic-Range Image Reconstruction. Sensors 2025, 25, 1497. https://doi.org/10.3390/s25051497
Lopez-Cabrejos J, Paixão T, Alvarez AB, Luque DB. An Efficient and Low-Complexity Transformer-Based Deep Learning Framework for High-Dynamic-Range Image Reconstruction. Sensors. 2025; 25(5):1497. https://doi.org/10.3390/s25051497
Chicago/Turabian StyleLopez-Cabrejos, Josue, Thuanne Paixão, Ana Beatriz Alvarez, and Diodomiro Baldomero Luque. 2025. "An Efficient and Low-Complexity Transformer-Based Deep Learning Framework for High-Dynamic-Range Image Reconstruction" Sensors 25, no. 5: 1497. https://doi.org/10.3390/s25051497
APA StyleLopez-Cabrejos, J., Paixão, T., Alvarez, A. B., & Luque, D. B. (2025). An Efficient and Low-Complexity Transformer-Based Deep Learning Framework for High-Dynamic-Range Image Reconstruction. Sensors, 25(5), 1497. https://doi.org/10.3390/s25051497