
Intelligent Detection Algorithm for Concrete Bridge Defects Based on SATH–YOLO Model


Abstract
1. Introduction
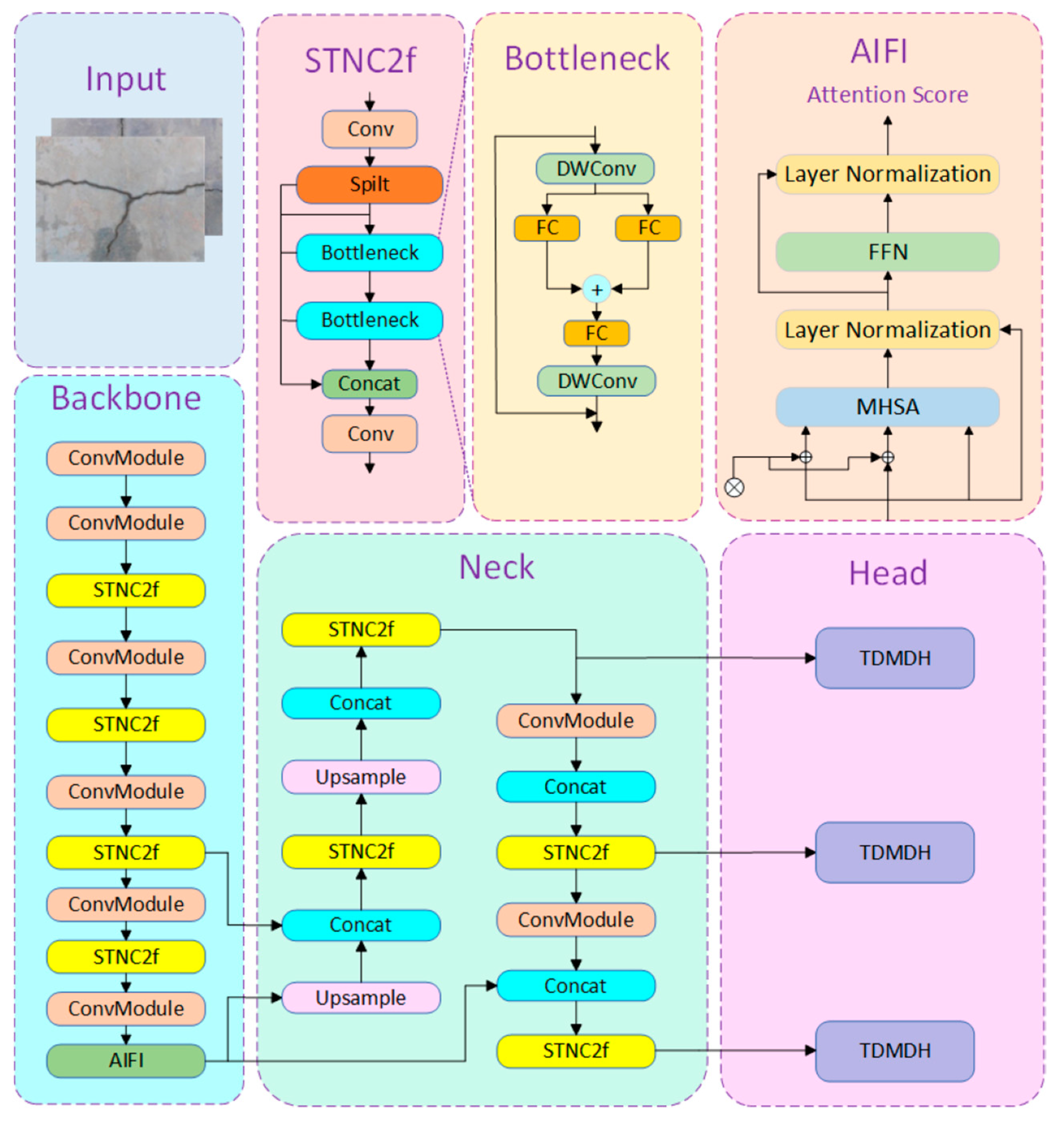
2. SATH–YOLO Algorithm Framework
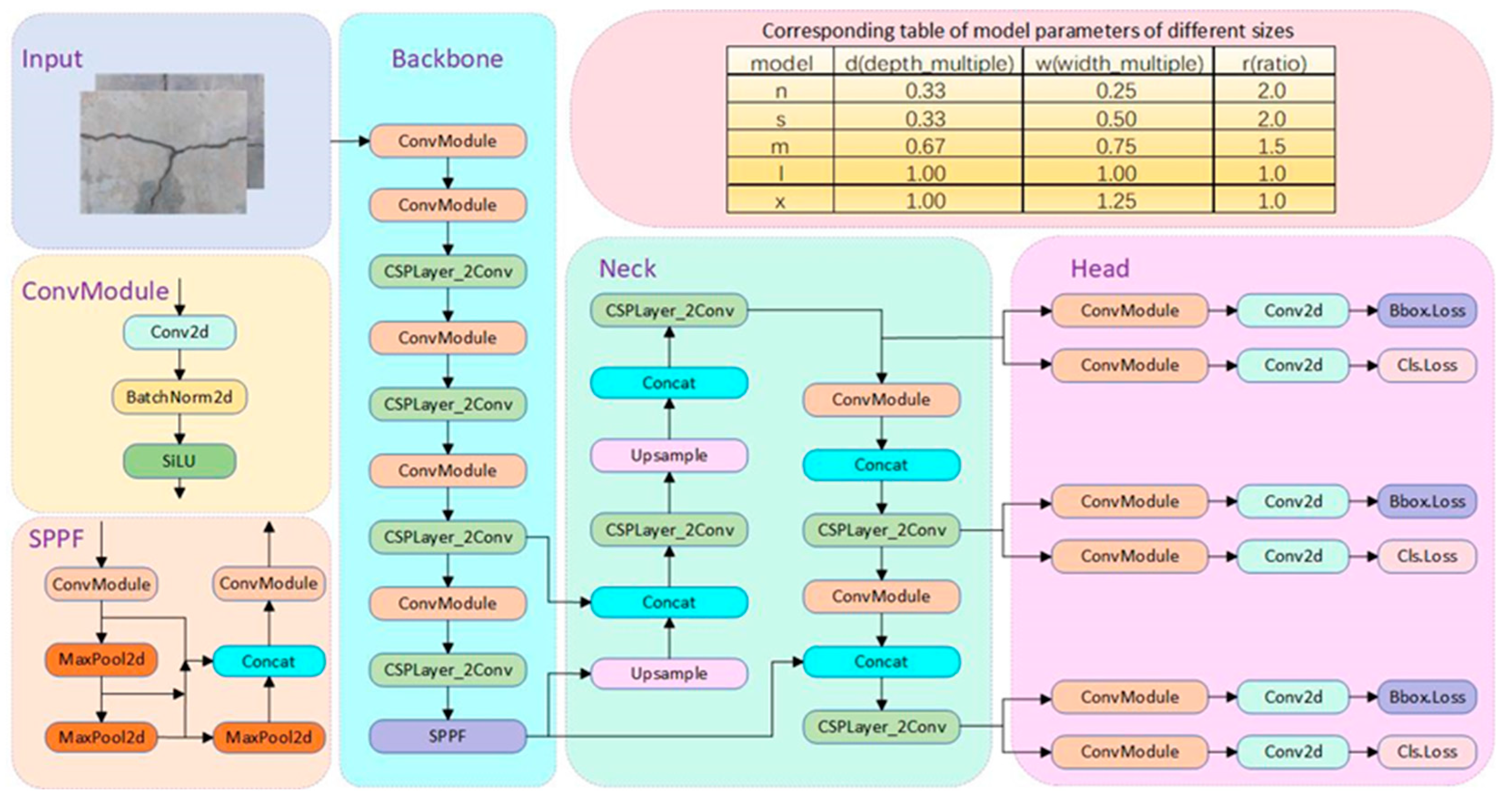
2.1. Overview of the YOLOv8 Algorithm
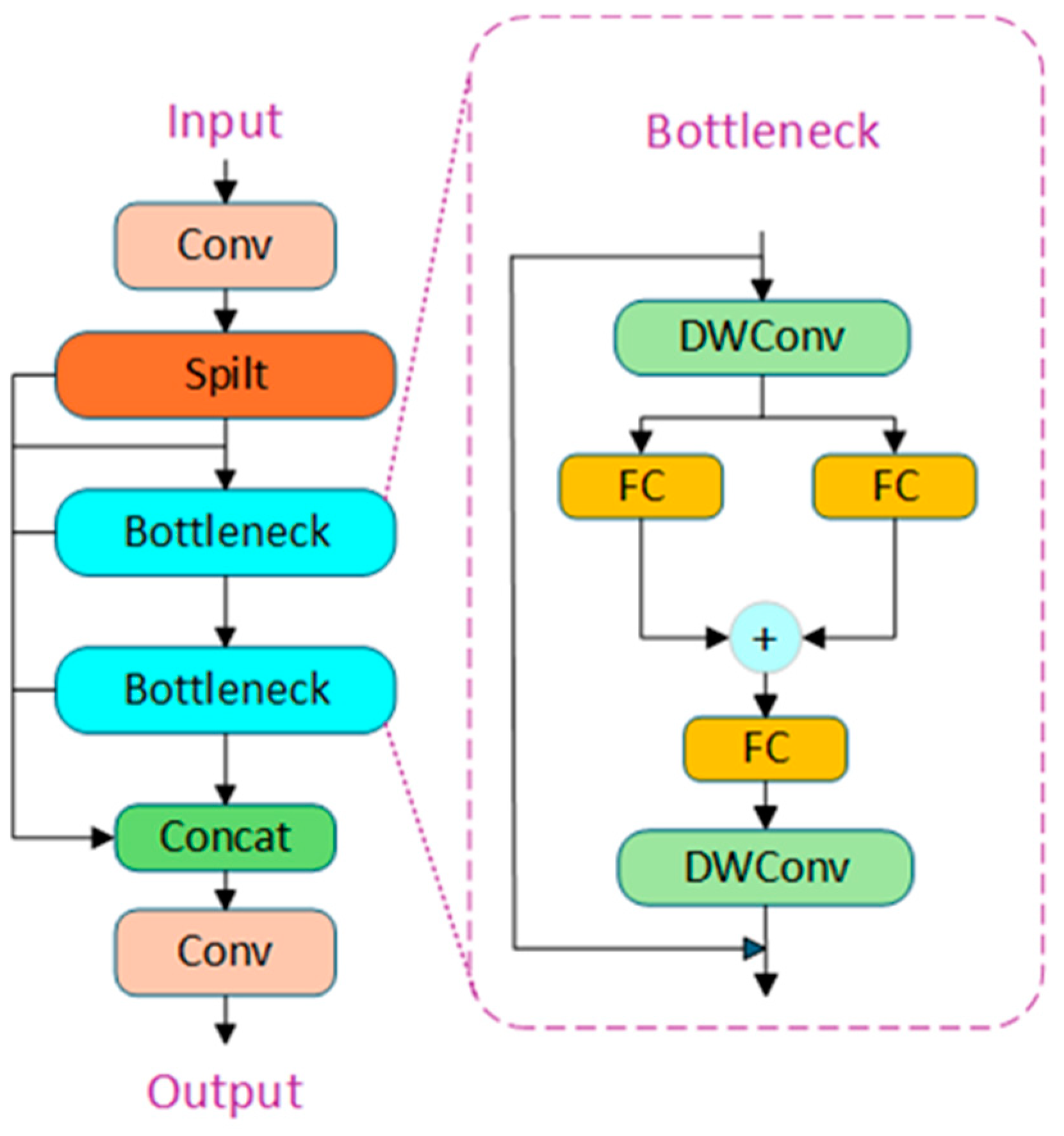
2.2. STNC2f Module
2.3. Intrascale Feature Interaction
2.4. Task Dynamic Mutual Detection Head (TDMDH)
2.5. SATH–YOLO Detection
3. Experiment-Related Preparation
3.1. Experimental Equipment and Hyperparameters
3.2. Experimental Dataset
3.3. Evaluation Metrics
4. Experiments and Discussion
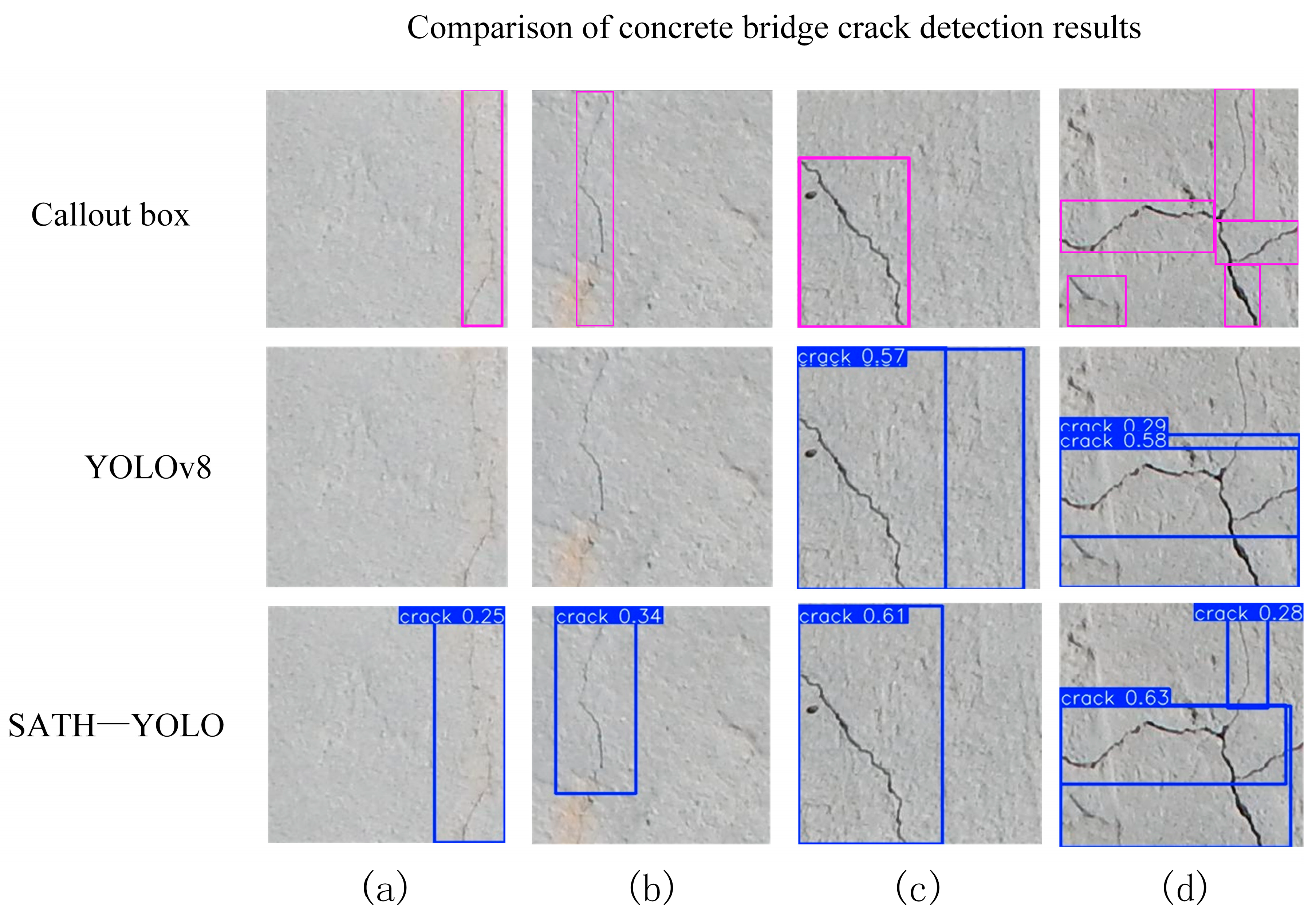
4.1. Visual Comparative
- In rows a and b, the heatmap of YOLOv8 shows a slightly diffused attention range, failing to fully align with the edges of the cracks, resulting in less precise detection box boundaries. In contrast, the heatmap of SATH–YOLO better covers the entire crack region, demonstrating higher detection stability.
- In row c, SATH–YOLO clearly focuses on the core area of the crack, while YOLOv8’s response is unevenly distributed, diminishing detection reliability.
- In row d, the YOLOv8 heatmap exhibits significant background interference, with the detected area failing to clearly highlight the crack path. In contrast, the SATH–YOLO heatmap effectively reduces interference and accurately identifies crack features.
4.2. Ablation Study
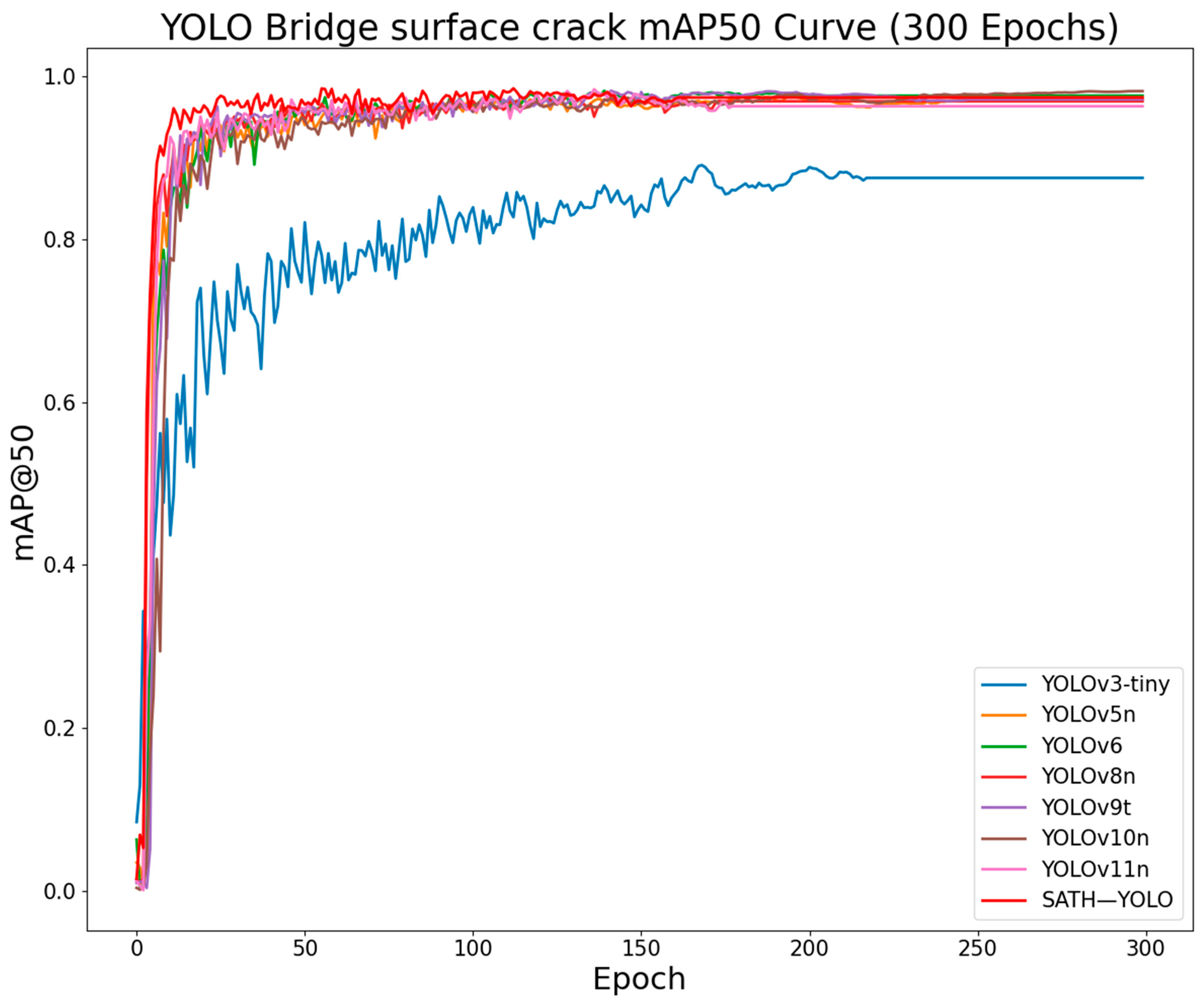
4.3. Comparative Experiments
4.4. Statistical Analysis and Significance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yongliang, Z.; Dawei, Z. Durability assessment model of concrete bridge based on multi-evidence fusion under NRS. China Saf. Sci. J. 2023, 33, 169. [Google Scholar]
- Yang, G.; Qi, Y.; Du, Y.; Shi, X. Improved YOLOv7 and SeaFormer Bridge Cracks Identification and Measurement. J. Railw. Sci. Eng. 2025, 22, 429–442. (In Chinese) [Google Scholar]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, S.; Li, X.; Li, G.; Li, X. Lightweight bridge crack detection method based on segnet and bottleneck depth-separable convolution with residuals. IEEE Access 2021, 9, 161649–161668. [Google Scholar] [CrossRef]
- Wang, J.; He, X.; Faming, S.; Lu, G.; Cong, H.; Jiang, Q. A real-time bridge crack detection method based on an improved inception-resnet-v2 structure. IEEE Access 2021, 9, 93209–93223. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, J.; Cai, F. On bridge surface crack detection based on an improved YOLO v3 algorithm. IFAC-Pap. 2020, 53, 8205–8210. [Google Scholar] [CrossRef]
- Liao, Y.-n.; Li, W. Bridge crack detection method based on convolution neural network. Comput. Eng. Des. 2021, 42, 2366–2372. (In Chinese) [Google Scholar] [CrossRef]
- Huang, K.; Zhao, Y.; Hu, N.; Cao, J.; Xiang, Y. Study on Concrete Bridge Crack Recognition Using Attention-based YOLOv5 Network. Bull. Sci. Technol. 2024, 40, 71–76. (In Chinese) [Google Scholar] [CrossRef]
- Li, P.; Han, F.; Yang, K.; Li, Z. Automatic Detection and Classification of Bridge Cracks Based on Improved YOLOv5s Algorithm. Transp. Sci. Technol. 2024, 3, 53–58. [Google Scholar]
- Inam, H.; Islam, N.U.; Akram, M.U.; Ullah, F. Smart and automated infrastructure management: A deep learning approach for crack detection in bridge images. Sustainability 2023, 15, 1866. [Google Scholar] [CrossRef]
- Xu, Y.; Wei, S.; Bao, Y.; Li, H. Automatic seismic damage identification of reinforced concrete columns from images by a region-based deep convolutional neural network. Struct. Control Health Monit. 2019, 26, e2313. [Google Scholar] [CrossRef]
- Li, R.; Yuan, Y.; Zhang, W.; Yuan, Y. Unified vision-based methodology for simultaneous concrete defect detection and geolocalization. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 527–544. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road damage detection and classification using deep neural networks with smartphone images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Deng, L.; Chu, H.; Long, L.; Wang, W.; Kong, X.; Cao, R. Review of Deep Learning-based Crack Detection for Civil Infrastructures. China J. Highw. Transp. 2023, 36, 1–21. (In Chinese) [Google Scholar] [CrossRef]
- Luo, H.; Wang, W.; Ye, X.; Zhu, S.; Bai, Y. Research Progress of Directed Object Detection Based on Deep Learning. J. Image Signal Process. 2024, 13, 258. (In Chinese) [Google Scholar] [CrossRef]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 5694–5703. [Google Scholar]
- Yi, L.; Huang, Z.; Yi, Y. Improved YOLOv8 foreign object detection method for transmission lines. Electron. Meas. Technol. 2024, 47, 125–134. (In Chinese) [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2017; IEEE Computer Society: Washington, DC, USA, 2021; pp. 3490–3499. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Xu, W.F.; Lei, Y.; Wang, H.T.; Zhang, X. Research on object detection models for edge devices. CAAI Trans. Intell. Syst. 2024, 1–11. Available online: https://link.cnki.net/urlid/23.1538.TP.20241211.1852.004 (accessed on 22 February 2025). (In Chinese).
- Peng, J.X.; Zhang, R.F.; Liu, Y.H. Corrupt fruit detection model based on improved YOLOv5n. Appl. Electron. Tech. 2024, 50, 55–60. (In Chinese) [Google Scholar] [CrossRef]
- Wang, M.; Dong, L.D.; Dong, W.; Zhang, H.X. An Elevator Passenger Abnormality Detection Method and Experimental. System Based on Edge Intelligence. J. Hangzhou Norm. Univ. 2024, 23, 439–445. (In Chinese) [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Parameter | Hyperparameter | Value |
|---|---|---|---|
| CPU | Intel(R) Core(TM) i7-12700KF | Training Strategy | SGD |
| RAM | 32 GB | Momentum | 0.937 |
| Operating System | Windows 10 Pro | Initial Learning Rate | 0.01 |
| GPU | NVIDIA GeForce RTX 4060Ti | Final Learning Rate | 0.0001 |
| GPU Memory | 8GB | Batch Size | 16 |
| Programming Tool | Visual Studio Code 1.96.4 | Workers | 5 |
| Programming Language | Python 3.9.19 | Imgsz | 640 |
| Deep Learning Framework | PyTorch 2.3.1 | Total Epochs | 300 |
| STNC2f | AIFI | TDMDH | Params/M | Flops/G | Precision/% | Recall/% | mAP@50/% | Model Size/MB |
|---|---|---|---|---|---|---|---|---|
| — | — | — | 3.01 | 8.1 | 96.5 | 92.4 | 97.2 | 5.96 |
| √ | — | — | 2.50↓ | 6.9↓ | 97.5↑ | 92.8↑ | 96.8 | 5.08↓ |
| √ | √ | — | 2.90↓ | 8.0↓ | 95.9 | 94.4↑ | 96.9 | 5.83↓ |
| — | — | √ | 2.20↓ | 8.6 | 95.2 | 93.3↑ | 97.5↑ | 4.49↓ |
| √ | √ | — | 2.53↓ | 7.1↓ | 97.0↑ | 94.0↑ | 97.9↑ | 5.09↓ |
| √ | — | √ | 1.85↓ | 7.1↓ | 96.4 | 94.7↑ | 97.8↑ | 3.75↓ |
| — | √ | √ | 2.19↓ | 8.5 | 97.8↑ | 91.7 | 97.6↑ | 4.40↓ |
| √ | √ | √ | 1.87↓ | 7.4↓ | 98.8↑ | 94.1↑ | 98.2↑ | 3.80↓ |
| Model | Params/M | Flops/G | Precision/% | Recall/% | mAP@50/% | Model Size/MB |
|---|---|---|---|---|---|---|
| YOLOv3-tiny | 12.13 | 18.9 | 79.9 | 82.2 | 88.9 | 23.2 |
| YOLOv5n | 2.50 | 7.1↓ | 98.2 | 93.4 | 97.4 | 5.05 |
| YOLOv6 | 4.23 | 11.8 | 97.6 | 90.3 | 97.3 | 8.30 |
| YOLOv8n | 3.01 | 8.1 | 96.5 | 92.4 | 97.2 | 5.96 |
| YOLOv9t | 1.97 | 7.6 | 95.7 | 94.6↑ | 97.9 | 4.45 |
| YOLOv10n | 2.27 | 6.5↓ | 95.1 | 94.3↑ | 98.2 | 5.53 |
| YOLOv11n | 2.58 | 6.3↓ | 97.1 | 95.3↑ | 97.7 | 5.23 |
| SATH–YOLO | 1.87 | 7.4 | 98.8 | 94.1 | 98.2 | 3.80 |
| Model | Accuracy (%) | Standard Deviation (%) | t-Statistic | p-Value | Statistical Significance |
|---|---|---|---|---|---|
| YOLOv8 | 97.2 | 0.20 | |||
| SATH—YOLO | 98.2 | 0.16 | 10.87 | 4.54 × | Significant (p < 0.05) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, L.; Liu, A. Intelligent Detection Algorithm for Concrete Bridge Defects Based on SATH–YOLO Model. Sensors 2025, 25, 1449. https://doi.org/10.3390/s25051449
Zou L, Liu A. Intelligent Detection Algorithm for Concrete Bridge Defects Based on SATH–YOLO Model. Sensors. 2025; 25(5):1449. https://doi.org/10.3390/s25051449
Chicago/Turabian StyleZou, Lanlin, and Ao Liu. 2025. "Intelligent Detection Algorithm for Concrete Bridge Defects Based on SATH–YOLO Model" Sensors 25, no. 5: 1449. https://doi.org/10.3390/s25051449
APA StyleZou, L., & Liu, A. (2025). Intelligent Detection Algorithm for Concrete Bridge Defects Based on SATH–YOLO Model. Sensors, 25(5), 1449. https://doi.org/10.3390/s25051449