
Insulator Defect Detection Algorithm Based on Improved YOLOv11n

Abstract
1. Introduction
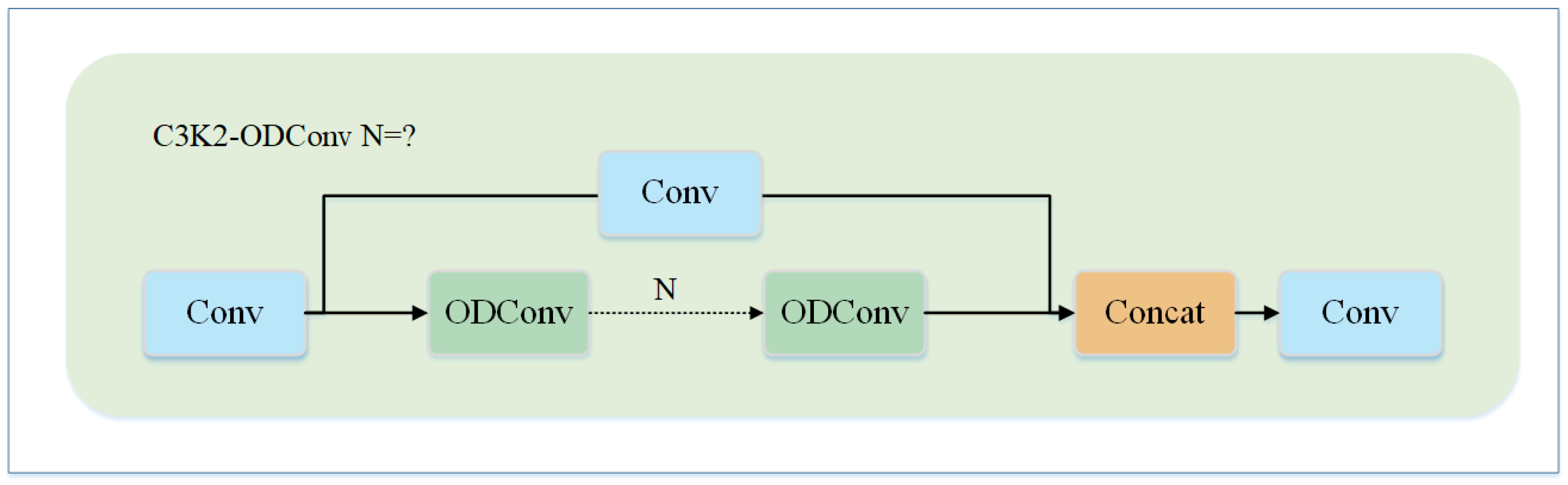
- The C3k2 module within the backbone network was redesigned based on ODConv, leading to the proposition of the C3k2_ODConv module, in which the two ordinary convolutions in the original bottleneck structure are replaced by multidimensional dynamic convolutions, thereby effectively enhancing the feature extraction capability for irregular defects.
- Slimneck replaces the neck component of YOLOv11n, reducing both the model’s parameter count and computational complexity.
- The WIoU loss function is introduced to optimize the anchor frames to more accurately locate defect positions and speed up network convergence.
2. Methods
2.1. YOLOv11 Algorithm
2.2. Proposed Method
2.2.1. Improved C3k2 Module
2.2.2. Slimneck
2.2.3. WIoU Loss Function
3. Experiments and Results
3.1. Experimental Implementation
3.1.1. Experiment Platform
3.1.2. Dataset
3.1.3. Evaluation Indicators
- mAP50: The mean average precision at an intersection over union (IoU) threshold of 0.50.
- mAP50-95: The mean average precision calculated at IoU thresholds ranging from 0.50 to 0.95 (in increments of 0.05).
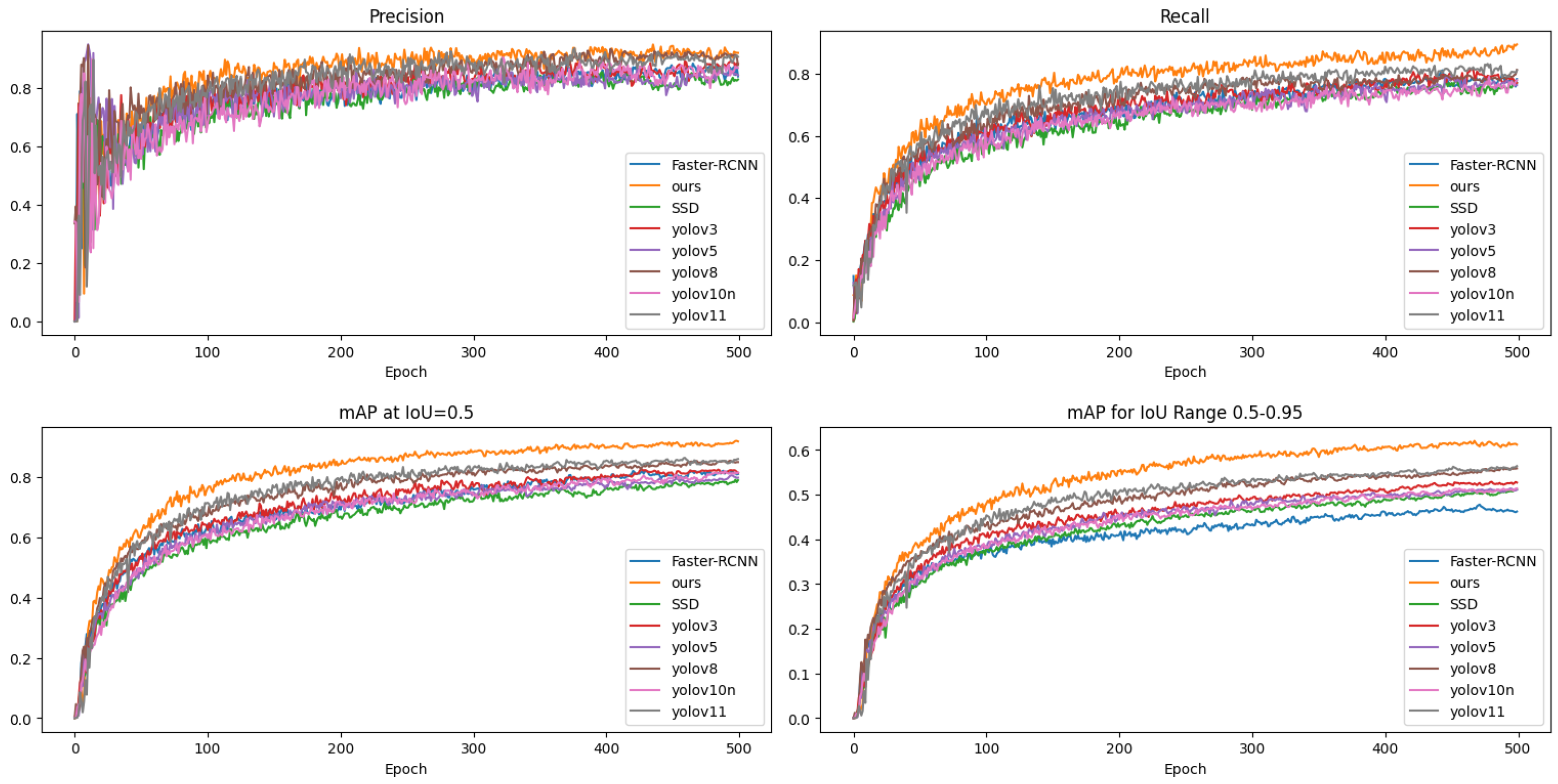
3.2. Comparative Experiment
3.3. Ablation Experiment
3.4. Visualization Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meng, D.; Yang, S.; Yang, H.; De Jesus, A.M.P.; Correia, J.; Zhu, S.P. Intelligent-Inspired Framework for Fatigue Reliability Evaluation of Offshore Wind Turbine Support Structures under Hybrid Uncertainty. Ocean Eng. 2024, 307, 118213. [Google Scholar] [CrossRef]
- Meng, D.; Yang, H.; Yang, S.; Zhang, Y.; De Jesus, A.M.P.; Correia, J.; Fazeres-Ferradosa, T.; Macek, W.; Branco, R.; Zhu, S.P. Kriging-Assisted Hybrid Reliability Design and Optimization of Offshore Wind Turbine Support Structure Based on a Portfolio Allocation Strategy. Ocean Eng. 2024, 295, 116842. [Google Scholar] [CrossRef]
- Bindi, M.; Piccirilli, M.C.; Luchetta, A.; Grasso, F. A Comprehensive Review of Fault Diagnosis and Prognosis Techniques in High Voltage and Medium Voltage Electrical Power Lines. Energies 2023, 16, 7317. [Google Scholar] [CrossRef]
- Salem, A.A.; Lau, K.Y.; Rahiman, W.; Abdul-Malek, Z.; Al-Gailani, S.A.; Rahman, R.A.; Al-Ameri, S. Leakage Current Characteristics in Estimating Insulator Reliability: Experimental Investigation and Analysis. Sci. Rep. 2022, 12, 14974. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Liu, Y.; Li, E.; Peng, J.; Liang, Z. A Review on State-of-the-Art Power Line Inspection Techniques. IEEE Trans. Instrum. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Ruszczak, B.; Michalski, P.; Tomaszewski, M. Overview of Image Datasets for Deep Learning Applications in Diagnostics of Power Infrastructure. Sensors 2023, 23, 7171. [Google Scholar] [CrossRef]
- Sharma, P.; Saurav, S.; Singh, S. Object Detection in Power Line Infrastructure: A Review of the Challenges and Solutions. Eng. Appl. Artif. Intell. 2024, 130, 107781. [Google Scholar] [CrossRef]
- Xu, C.; Li, Q.; Zhou, Q.; Zhang, S.; Yu, D.; Ma, Y. Power Line-Guided Automatic Electric Transmission Line Inspection System. IEEE Trans. Instrum. Meas. 2022, 71, 3512118. [Google Scholar] [CrossRef]
- Li, S.; Cao, B.; Li, J.; Cui, Y.; Kang, Y.; Wu, G. Review of Condition Monitoring and Defect Inspection Methods for Composited Cable Terminals. High Volt. 2023, 8, 431–444. [Google Scholar] [CrossRef]
- Bandara, S.; Rajeev, P.; Gad, E. A Review on Condition Assessment Technologies for Power Distribution Network Infrastructure. Struct. Infrastruct. Eng. 2024, 20, 1834–1851. [Google Scholar] [CrossRef]
- Alhassan, A.B.; Zhang, X.; Shen, H.; Xu, H. Power Transmission Line Inspection Robots: A Review, Trends and Challenges for Future Research. Int. J. Electr. Power Energy Syst. 2020, 118, 105862. [Google Scholar] [CrossRef]
- Santos, T.; Cunha, T.; Dias, A.; Moreira, A.P.; Almeida, J. UAV Visual and Thermographic Power Line Detection Using Deep Learning. Sensors 2024, 24, 5678. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhang, X.; Liu, J.; Wu, B.; Hu, Y. Graph Features Dynamic Fusion Learning Driven by Multi-Head Attention for Large Rotating Machinery Fault Diagnosis with Multi-Sensor Data. Eng. Appl. Artif. Intell. 2023, 125, 106601. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, L.; Wang, L.; Zhang, T.; Zhang, F. A Pruned-Optimized Weighted Graph Convolutional Network for Axial Flow Pump Fault Diagnosis with Hydrophone Signals. Adv. Eng. Inform. 2024, 60, 102365. [Google Scholar] [CrossRef]
- Zhang, D.; Han, J.; Cheng, G.; Yang, M.H. Weakly Supervised Object Localization and Detection: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5866–5885. [Google Scholar] [CrossRef]
- Han, K.; Sheng, V.S.; Song, Y.; Liu, Y.; Qiu, C.; Ma, S.; Liu, Z. Deep Semi-Supervised Learning for Medical Image Segmentation: A Review. Expert Syst. Appl. 2024, 245, 123052. [Google Scholar] [CrossRef]
- Ren, Z.; Wang, S.; Zhang, Y. Weakly Supervised Machine Learning. CAAI Trans. Intell. Technol. 2023, 8, 549–580. [Google Scholar] [CrossRef]
- Gu, Y.; Ai, Q.; Xu, Z.; Yao, L.; Wang, H.; Huang, X.; Yuan, Y. Cost-Effective Image Recognition of Water Leakage in Metro Tunnels Using Self-Supervised Learning. Autom. Constr. 2024, 167, 105678. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, Y.; Xin, M.; Liao, J.; Xie, Q. A Light-Weight Network for Small Insulator and Defect Detection Using UAV Imaging Based on Improved YOLOv5. Sensors 2023, 23, 5249. [Google Scholar] [CrossRef]
- Han, G.; Zhao, L.; Li, Q.; Li, S.; Wang, R.; Yuan, Q.; He, M.; Yang, S.; Qin, L. A Lightweight Algorithm for Insulator Target Detection and Defect Identification. Sensors 2023, 23, 1216. [Google Scholar] [CrossRef]
- Zheng, J.; Wu, H.; Zhang, H.; Wang, Z.; Xu, W. Insulator-Defect Detection Algorithm Based on Improved YOLOv7. Sensors 2022, 22, 8801. [Google Scholar] [CrossRef]
- Yu, Z.; Lei, Y.; Shen, F.; Zhou, S. Application of Improved YOLOv5 Algorithm in Lightweight Transmission Line Small Target Defect Detection. Electronics 2024, 13, 305. [Google Scholar] [CrossRef]
- Han, G.; Yuan, Q.; Zhao, F.; Wang, R.; Zhao, L.; Li, S.; He, M.; Yang, S.; Qin, L. An Improved Algorithm for Insulator and Defect Detection Based on YOLOv4. Electronics 2023, 12, 933. [Google Scholar] [CrossRef]
- Cao, Z.; Chen, K.; Chen, J.; Chen, Z.; Zhang, M. CACS-YOLO: A Lightweight Model for Insulator Defect Detection Based on Improved YOLOv8m. IEEE Trans. Instrum. Meas. 2024, 73, 3530710. [Google Scholar] [CrossRef]
- Zhang, Z.D.; Zhang, B.; Lan, Z.C.; Liu, H.C.; Li, D.Y.; Pei, L.; Yu, W.X. FINet: An Insulator Dataset and Detection Benchmark Based on Synthetic Fog and Improved YOLOv5. IEEE Trans. Instrum. Meas. 2022, 71, 6006508. [Google Scholar] [CrossRef]
- Fang, G.; An, X.; Fang, Q.; Gao, S. Insulator Defect Detection Based on YOLOv5s-KE. Electronics 2024, 13, 3483. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, J.; Li, Y.; Zhu, C.; Wang, G. IL-YOLO: An Efficient Detection Algorithm for Insulator Defects in Complex Backgrounds of Transmission Lines. IEEE Access 2024, 12, 14532–14546. [Google Scholar] [CrossRef]
- Wang, D.; Tan, J.; Wang, H.; Kong, L.; Zhang, C.; Pan, D.; Li, T.; Liu, J. SDS-YOLO: An Improved Vibratory Position Detection Algorithm Based on YOLOv11. Measurement 2025, 244, 116518. [Google Scholar] [CrossRef]
- Sani, A.R.; Zolfagharian, A.; Kouzani, A.Z. Automated Defects Detection in Extrusion 3D Printing Using YOLO Models. J. Intell. Manuf. 2024, 1–21. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-Dimensional Dynamic Convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar] [CrossRef]
- Luo, X.; Shen, Q.; Gao, M.; Ni, X.; Wang, S.; Zhang, C.; Cao, Z.; Qin, G. Improved YOLOv7-Tiny Insulator Defect Detection Based on Drone Images. In Proceedings of the Advanced Intelligent Computing Technology and Applications, Tianjin, China, 5–8 August 2024; Huang, D.S., Zhang, X., Guo, J., Eds.; pp. 345–353. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-Neck by GSConv: A Lightweight-Design for Real-Time Detector Architectures. J. Real-Time Image Process. 2024, 21, 62. [Google Scholar] [CrossRef]
- Fang, G.; Zhao, Y. Detection of Critical Parts of River Crab Based on Lightweight YOLOv7-SPSD. Sensors 2024, 24, 7593. [Google Scholar] [CrossRef] [PubMed]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar] [CrossRef]
- Xiong, C.; Zayed, T.; Abdelkader, E.M. A novel YOLOv8-GAM-Wise-IoU model for automated detection of bridge surface cracks. Constr. Build. Mater. 2024, 414, 135025. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Setup |
|---|---|
| Batch size | 64 |
| Image size | 640 × 640 |
| Initial learning rate | 0.01 |
| Final learning rate | 0.01 |
| Weight decay | 0.0005 |
| Momentum | 0.937 |
| Optimizer | SGD |
| Model | P | R | mAP50 | mAP50-95 | GFLOPs |
|---|---|---|---|---|---|
| Faster-RCNN | 0.856 | 0.783 | 0.817 | 0.477 | 50.6 |
| SSD | 0.83 | 0.774 | 0.798 | 0.514 | 24.2 |
| YOLOv3 | 0.851 | 0.8 | 0.824 | 0.536 | 14.3 |
| YOLOv5 | 0.885 | 0.802 | 0.836 | 0.537 | 13.8 |
| YOLOv8 | 0.909 | 0.785 | 0.854 | 0.559 | 28.4 |
| YOLOv10 | 0.85 | 0.806 | 0.838 | 0.541 | 14.3 |
| YOLOv11 | 0.906 | 0.84 | 0.873 | 0.574 | 7.6 |
| Ours | 0.918 | 0.881 | 0.91 | 0.619 | 6.5 |
| Model | P | R | mAP50 | mAP50-95 |
|---|---|---|---|---|
| Y-CIoU | 0.906 | 0.84 | 0.873 | 0.574 |
| Y-EIoU | 0.868 | 0.841 | 0.872 | 0.579 |
| Y-DIoU | 0.909 | 0.838 | 0.875 | 0.581 |
| Y-SIoU | 0.907 | 0.834 | 0.872 | 0.578 |
| Y-GIoU | 0.897 | 0.839 | 0.876 | 0.582 |
| Y-WIoU | 0.899 | 0.845 | 0.888 | 0.588 |
| Model | C3k2_ODConv | Slimneck | WIoU | P | R | mAP50 | mAP50-95 | FPS | Params/M |
|---|---|---|---|---|---|---|---|---|---|
| Model 1 | 0.906 | 0.84 | 0.873 | 0.574 | 186 | 2.58 | |||
| Model 2 | Y | 0.934 | 0.829 | 0.88 | 0.577 | 172 | 2.65 | ||
| Model 3 | Y | 0.91 | 0.848 | 0.876 | 0.579 | 234 | 2.10 | ||
| Model 4 | Y | 0.899 | 0.845 | 0.888 | 0.588 | 208 | 2.58 | ||
| Model 5 | Y | Y | 0.908 | 0.858 | 0.889 | 0.594 | 214 | 2.32 | |
| Model 6 | Y | Y | 0.935 | 0.844 | 0.89 | 0.599 | 195 | 2.64 | |
| Model 7 | Y | Y | 0.912 | 0.843 | 0.893 | 0.593 | 241 | 2.15 | |
| ours | Y | Y | Y | 0.918 | 0.881 | 0.91 | 0.619 | 228 | 2.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, J.; Miao, S.; Kang, R.; Cao, L.; Zhang, L.; Ren, Y. Insulator Defect Detection Algorithm Based on Improved YOLOv11n. Sensors 2025, 25, 1327. https://doi.org/10.3390/s25051327
Zhao J, Miao S, Kang R, Cao L, Zhang L, Ren Y. Insulator Defect Detection Algorithm Based on Improved YOLOv11n. Sensors. 2025; 25(5):1327. https://doi.org/10.3390/s25051327
Chicago/Turabian StyleZhao, Junmei, Shangxiao Miao, Rui Kang, Longkun Cao, Liping Zhang, and Yifeng Ren. 2025. "Insulator Defect Detection Algorithm Based on Improved YOLOv11n" Sensors 25, no. 5: 1327. https://doi.org/10.3390/s25051327
APA StyleZhao, J., Miao, S., Kang, R., Cao, L., Zhang, L., & Ren, Y. (2025). Insulator Defect Detection Algorithm Based on Improved YOLOv11n. Sensors, 25(5), 1327. https://doi.org/10.3390/s25051327