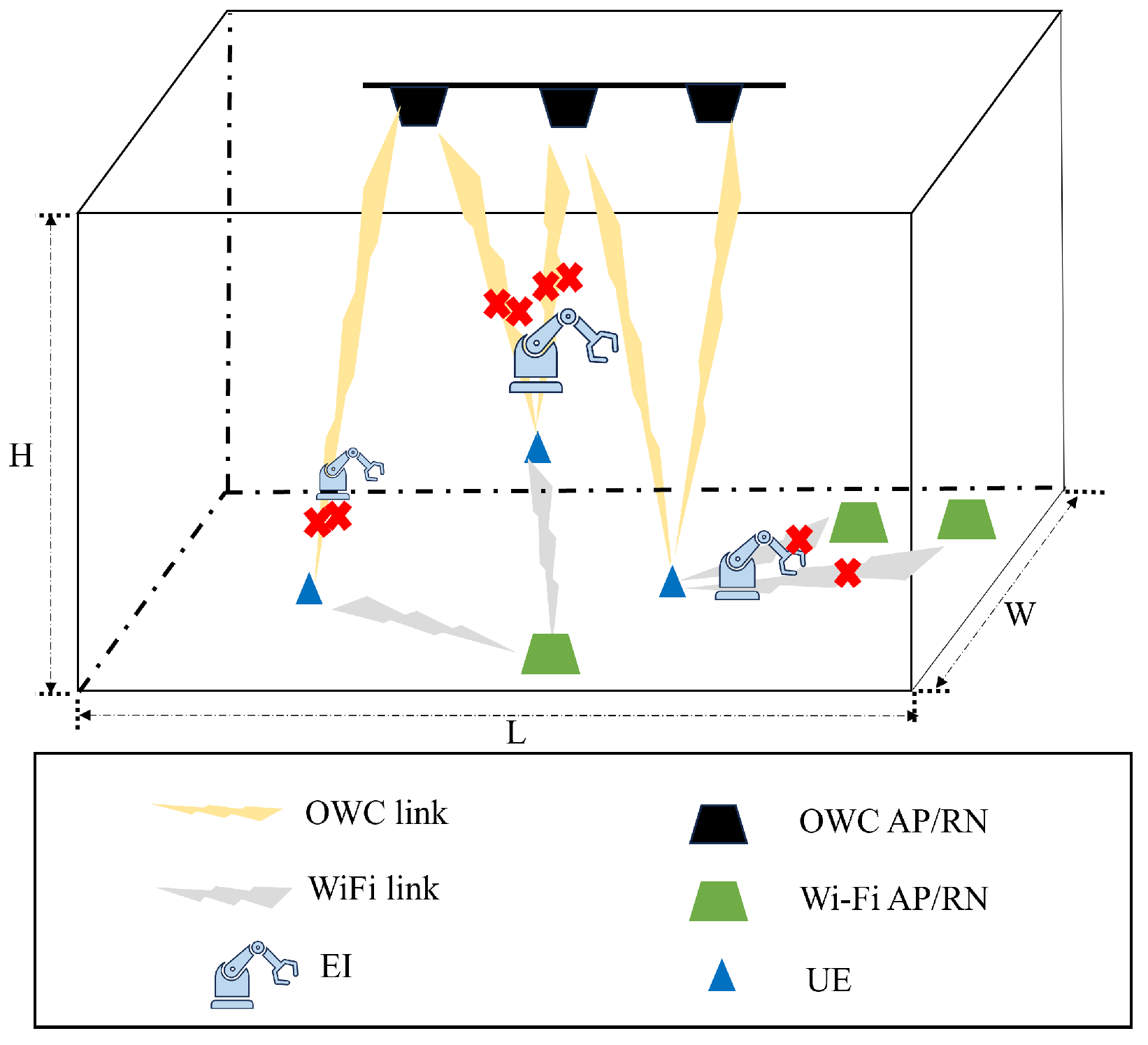
1. Introduction
Recently, the indoor localization problem has garnered significant attention in research, driven by the growing popularity of indoor mobile robots for transportation and artificial intelligence communication services [
1,
2]. Unlike outdoor localization, indoor localization presents unique challenges that classic Global Positioning System (GPS)-assisted methods cannot meet due to the stringent accuracy requirements. Especially in a highly dynamic environment, localization has to deal with the case of environmental layouts changing [
3]. Meanwhile, the fingerprinting method is widely applied due to the advantages of high localization accuracy, effective linear and nonlinear models, and easy upgrade information to amend [
4]. It has two phases: offline dataset establishment phase and online localization phase. In the first phase, parameters such as Received Signal Strength (RSS) and Channel State Information (CSI) are first collected from Access Points (APs)/Reference Nodes (RNs) at different known locations, and then stored in a database along with their corresponding location coordinates, therefore creating a “fingerprint” map of the environment. In the online localization phase, the measured parameters are compared to the stored fingerprints, and then by matching the current measured parameters with the closest fingerprint in the database, localization is finally achieved [
5]. The key to achieving high localization accuracy with the fingerprint method lies in the real-time precision of the database. However, in a dynamic environment with multiple moving robots or services, the database is always changing [
6,
7]. Ref. [
8] demonstrates the susceptibility of RSS to environmental variability by testing and comparing the RSS variation in six months (long term) and the one in one week (short term). According to existing research, the variation in RSS distributions at the same location over 44 days is demonstrated [
9]. Consequently, the accuracy of location estimation can degrade significantly as time passes.
To solve this problem, Deep Learning (DL) methods have been used by updating the offline database training phase or online matching phase. Ref. [
10] uses a Machine Learning (ML)-based feedback loop during the database online calibration step and updates the database in real time to learn the variability of the environment. The feedback data are collected by additional devices that are different from the ones used in the offline calibration. This makes continuous fingerprint calibration feasible even in the presence of different machines and Internet-of-Things (IoT) sensors that introduce variations to the electromagnetic environment. Ref. [
11] explores a new paradigm of radio map construction and adaptation with few-shot relation learning. It augments the collected data and models the fundamental relationships of the neighborhood fingerprints. In this way, network updating is not necessary, decreasing the time cost. Ref. [
12] applies Long Short-Term Memory (LSTM) deep network architectures to achieve localization based on collected RSS data. This study also improves the Long Short Term Memory (LSTM) architecture and conduct some comparison with other Convolutional Neural Networks (CNNs). As a result, the proposed model achieves localization with meter-level accuracy. However, DL-based methods are still time-consuming and labor-intensive due to the collection of labeled data, which limits the applicability of fingerprint-based localization systems.
In this case, Transfer Learning (TL) is popular to solve the fingerprint adaption in a dynamic environment [
13,
14]. It maps features from the source domain (initial environment) and the target domain (changed environment) into the same feature space using supervised or semi-supervised learning. This enables the reuse of previously invalid labeled fingerprints in the new environment, therefore reducing the reliance on labeled data in the new environment. Ref. [
6] improves the traditional fingerprint method in both offline establishment and online localization stages. It applies the Domain-Adversarial Neural Network (DANN) [
15] based on TL in the offline stage to construct the database using only unlabeled data and the Passive Aggressive (PA) algorithm [
16] in the online stage to track the dynamic characteristics of the environment and calibrate the entire localization system. Transfer Learning methods such as zero-shoot learning and one-shoot learning focus on excelling at new tasks but fail to prevent the catastrophic forgetting of previously learned tasks or other new tasks in the same domain [
17]. In this case, as the fingerprinting database changes over time and the new task is learned, the old information cannot achieve high-precision localization when applied to the new model. For example, let us assume the following: (1) the old database is established at time
; (2) a new model
is created based on new information at time
t; (3) catastrophic forgetting occurs during this TL process; (4) the database at time
is identical to the one at time
; and (5) model
is trained using the same TL approach and the database at time
. Consequently, the localization accuracy at time
is lower than that at time
, illustrating the effects of catastrophic forgetting.
Continual Learning (CL) is applied to deal with the catastrophic forgetting by using only new data. Usually, it can be categorized into (1) regularization-based methods [
18,
19], which work by penalizing changes in the critical weights associated with previous tasks or introducing orthogonality constraints in the training objectives, thereby reducing the risk of the model forgetting prior knowledge; (2) modular-based methods [
20], which expand the model’s capacity by assigning new parameters to each task; and (3) replay-based methods [
21], which store samples from old scenes in a fixed-size buffer or using generative models to reconstruct and reproduce images of old scenarios, and therefore experience replay can be implemented. In theory, CL approaches could be leveraged not only to manage forgetting but also to decrease training complexity [
22]. In fact, regularization-based methods require the retention of past gradients or feature maps, akin to replay-based methods, to prevent forgetting and ensure the continuity of learning. In contrast, modular-based methods involve increasing the model’s capacity by adding new parameters for each task, which can complicate the model’s structure. When the model size is fixed, experience replay-based methods have been shown to outperform regularization-based methods in preserving previously learned knowledge. Moreover, integrating regularization and experience replay approaches has been demonstrated with more effective results [
23]. Therefore, in this paper, we apply a replay-based method to fulfill localization in a dynamic environment. Until now, only few studies have applied CL in the wireless localization field. Ref. [
22] proposed a novel real-time CL method based on “Latent Replay” policy. It integrates old data at a selected intermediate layer, rather than the input layer, based on the desired balance between accuracy and efficiency. Meanwhile, it keeps the layers below the selected layer frozen not only to decrease the time cost but also to save the old information. A year later, the same authors applied this novel method to localize Unmanned Aerial Vehicles (UVAs) outdoors using a multi-camera and assisted by the GPS information [
24]. In this paper, mini-batches are generated first, then Convolutional Neural Network (CNN)-based continual training using the old created mini-batches, and finally the available model is used to classify the current image, providing a discrete label that can be mapped to a GPS coordinate. This is the first work to localize the target based on the replay-based CL. Later, the authors improved the localization system by using a multi-model so that localization can be accomplished even when GPS cannot work [
25]. At the same time, another research team also applied CL to accomplish localization. A robust baseline was proposed in [
26] that relies on storing and replaying images from a fixed memory called buffer. Additionally, the study introduces a novel sampling method called Buff-Coverage Score (Buff-CS), which adapts existing sampling strategies within the buffering process to address catastrophic forgetting. These studies all utilize images as their input. In image-based CL localization methods, the lower layers of a CNN process fundamental information with lower complexity and faster processing speeds compared to the higher layers [
24]. This behavior contrasts that observed in data-driven Neural Network (NN) models, such as those commonly employed in RSS-based fingerprinting for indoor localization.
Therefore, in this paper, we propose a novel data-based CL method for real-time indoor localization. It uses replay policy and reintroduces previously learned information not directly from the input layer but through intermediate layers, allowing for more refined feature extraction and processing. Meanwhile, it improves localization accuracy by leveraging features extracted from multiple lower layers rather than depending on a single, predetermined layer. By utilizing a broader range of feature representations such as some weights and bias, it ensures a more comprehensive understanding of the data, leading to more robust and precise localization results. Furthermore, it reduces training complexity and time cost by freezing the upper layers, which is a different approach from that used in image-based CL methods. Overall, the contributions in this paper are summarized as follows:
This paper is the first to apply a data-based CL method for indoor localization, whereas previous approaches to CL in indoor localization have all been image-based.
This paper enhances indoor localization accuracy and avoids catastrophic forgetting by replaying some partial features across multiple layers, rather than relying on a single layer.
It accelerates training time by freezing the upper layers, as they involve higher complexity.
The proposed system enables real-time localization thanks to the robustness of the trained model, which incorporates information from multiple time periods.
To present this work, our paper is organized as follows:
Section 2 provides an overview of the system model, including data generation and the NN structure.
Section 3 describes the proposed data-based CL architecture for high-accuracy and real-time localization. The simulations and the analysis of the results are presented in
Section 4. Finally,
Section 5 provides the conclusions and outlines future work.
3. Proposed Architecture
As mentioned above, we propose an improved rehearsal-based CL system for real-time localization. The proposed system is designed with two primary objectives: preventing the catastrophic forgetting of previous data and ensuring high localization accuracy for new data. The first objective is addressed through the rehearsal strategy detailed in
Section 2. Traditional rehearsal-based CL methods typically focus on replaying data at the input layer, while the limited existing research on CL for localization emphasizes rehearsals at the chosen intermediate layer. To further enhance localization accuracy, our system extends the rehearsal policy to multiple intermediate layers, rather than relying on a single layer. In addition, to reduce computational complexity, the processing speed in the upper layers—where most of the computational load occurs—is deliberately slowed down. The second objective, maintaining localization accuracy for new data, is achieved by initializing the parameters in the lower layers using a partially trained NN based on the new dataset, which ensures that the system remains efficient while effectively integrating new information. The whole process will be explained further. First, at time
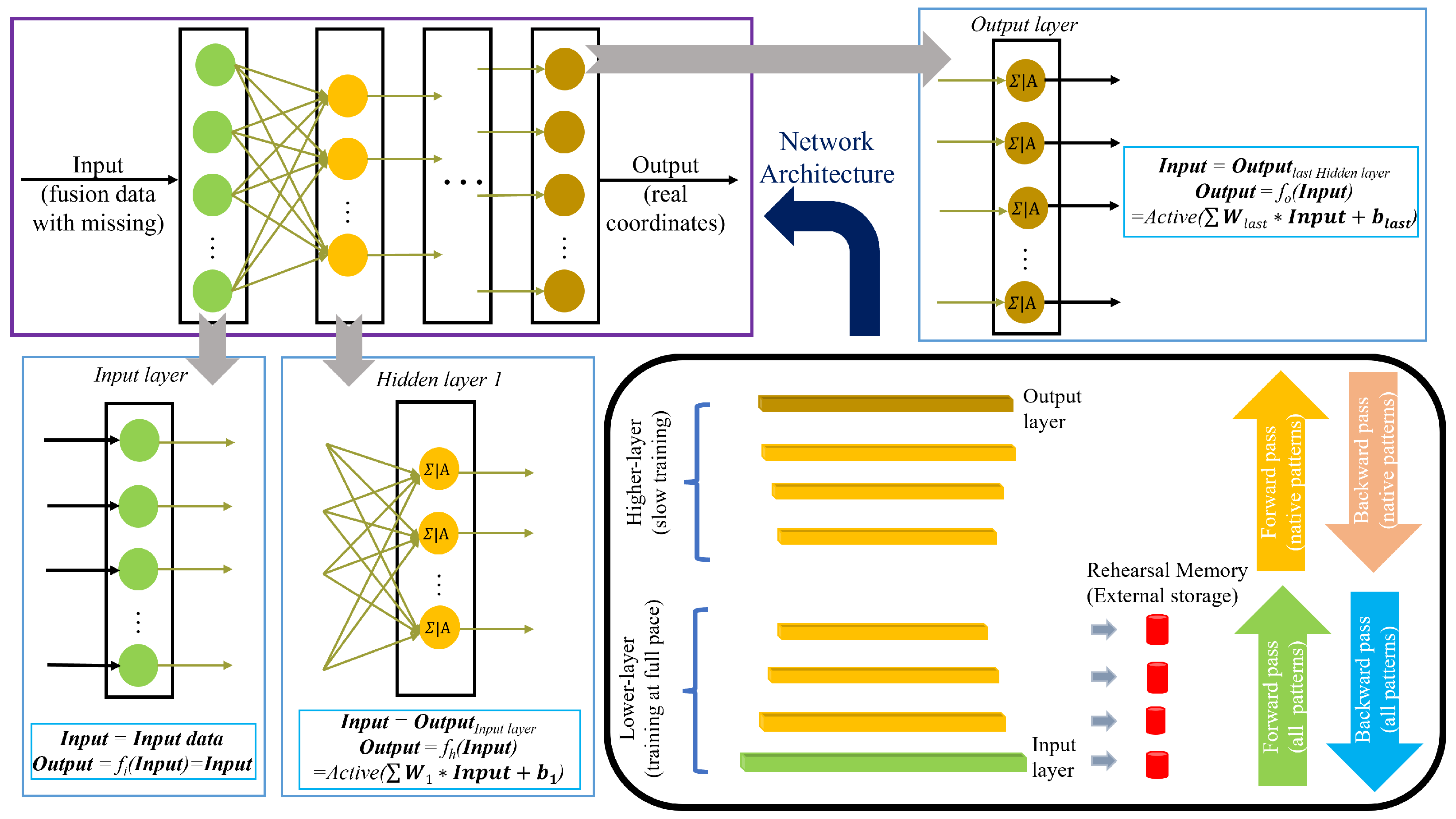
t, a trained
based on old data is determined. The NN is structured into three main types of layers: the input layer, which receives the initial data; hidden layers, where complex computations and feature extractions occur; and the output layer, which produces the final result or prediction. Each layer comprises multiple neurons, which are the basic units that process the information. In a traditional fully connected NN, also known as a dense network, every neuron in one layer is linked to every neuron in the following layer. These connections allow for the full transfer of information from one layer to the next. Specifically, the output from each neuron in a layer is passed through an activation function, which introduces non-linearity into the model, and then this processed output becomes the input for the neurons in the subsequent layer. For the input layer, let Input represent the input data (which in this case are the fusion data with missing values), and the output is given by
, where
denotes the activation function. For the hidden layer, the output is calculated as
, where
W refers to the weights connected to each neuron, and
b is the bias term. An example of this is seen in the first hidden layer, as illustrated in
Figure 2. The output layer functions similarly to the hidden layers. This whole process is generally as shown in the upper left corner of
Figure 2. The dense connections and layered structure enables the NN to learn and represent complex patterns within the data.
At time , new data arrive, and the corresponding is trained following the traditional neural network approach. During this process, the external memory is refreshed. Initially, selected layers of have their parameters extracted. The CL network is then trained by initializing its parameters, including weights and biases, based on the pre-trained model . In this stage, the lower layers are updated by integrating the parameters stored in the external memory. To manage the high computational complexity of the upper layers, we reduce the training speed specifically for these layers. This strategy prevents the model from being overwhelmed by the complex adjustments required in the upper layers while still incorporating new information effectively. As a result, we obtain the updated CL model, denoted as , which integrates both the new data and the retained knowledge from previous training.
The complete pipeline of the proposed CL system is outlined in Algorithm 3. In this paper, key functions are applied. Gradient descent function
is the gradient of function
with respect to
.
are parameters chosen from
L layers in one network. Also, key parameters in the rehearsal process are utilized. Training data
represent the raw data RSS and the corresponding real locations for training to generate the CL model. Parameters
include weights and bias in one network. Batch size
B is the number of receivers used per iteration. The learning rate
controls the step size taken in the direction of the gradient during each update in gradient-based optimization. Layers for fine-tuning
L indicate the layers that are updated during the fine-tuning process. External memory
refers to a storage mechanism used to retain previous and old RSS data. Two networks work in the whole pipeline: the old network
and the new network
.
is trained based on the old RSS data and
is trained by the new RSS data.
| Algorithm 3 Proposed Continual Learning rehearsal pipeline for fingerprint-based indoor real-time localization |
- 1:
Input: Training data , Batch size B, Learning rate , Layers for fine-tune L, External memory - 2:
Output: Updated model with parameters - 3:
Initialize model parameters - 4:
Initialize the external memory - 5:
for each epoch do - 6:
Shuffle training data - 7:
for each batch b in do - 8:
if first batch then - 9:
Train model based on batch b - 10:
Update model parameters:
where is the loss function. - 11:
else - 12:
Train model based on batch b for the new network - 13:
Sample parameters from selected layers L of : - 14:
Update the external memory with sampled parameters : - 15:
Incorporate data stored in into the previous network : - 16:
- Randomly discard parameters in selected layers of : - 17:
- Fuse parameters in selected layers L from external memory : - 18:
Perform fine-tuning on the previous by minimizing the loss function: - 19:
Reduce the training speed for upper layers L by updating learning rate :
where is a reduction factor. - 20:
end if - 21:
end for - 22:
end for - 23:
Return Updated model with parameters
|
4. Simulation Analysis
In this section, we present the performance evaluation of the proposed CL system for real-time localization and compare it with traditional fully connected feed-forward DL systems, which employ Levenberg–Marquardt optimization with a learning rate of 0.01, 100 epochs, and a batch size of 100. Additionally, we compare it with the TL system, using fine-tuning as a benchmark. Therefore, we have four models: , which is traditionally trained using the old dataset; , which is traditionally trained using the new dataset; a fine-tuning model trained based on a basic TL system; and finally, our proposed CL model. In the proposed CL model, we aim to identify the optimal configuration by testing various data rehearsal proportions, specifically 0%, 20%, 50%, 80%, and 100%. In training neural networks, various structures are explored to identify the optimal configuration. In this context, TL is implemented using fine-tuning with a consistent network structure. Similarly, CL is tested with different rehearsal memory sizes, but also using the same network structure.
We have two primary goals as introduced in
Section 3: preventing the catastrophic forgetting of previous data and ensuring high localization accuracy for new data. In this case, the accuracy of the fine-tuning model on the old dataset is expected to be lower than that of the CL model on the same dataset. Additionally, the accuracy of
on the new dataset is expected to be lower than that of the CL model on the same dataset.
Four verification tests are conducted to validate the system’s effectiveness in dynamic environments, considering not only variations in missing data proportions but also changes in noise levels. Datasets are generated as firstly introduced in
Section 2. In each dataset, we take 70% data for training process and 30% data for validation or testing. In this study, for the rehearsal policy, we rehearse partial neurons from the first three hidden layers of a network with five hidden layers, each containing ten neurons. In
Table 2, we present the used NN architectures where
is the number of neurons in the
hidden layer, and to guarantee the adaption between NNs, we set the same architecture for each NN. Here, we choose
as our rehearsal layers.
4.1. Verification When Missing Data Proportion Changes over Time
To simulate a dynamic environment, we utilize two datasets to represent the data at time t and time , respectively. To assess the system’s ability to prevent catastrophic forgetting, we choose a dataset with a higher missing data proportion for time t and a dataset with a lower missing data proportion for time . Specifically, in the smaller room, Dataset 1 represents the data at time , while Dataset 3 represents the data at time t, forming a comparison pair. Similarly, Dataset 2 and Dataset 4 form another pair. Here, we will present the results of the first comparison.
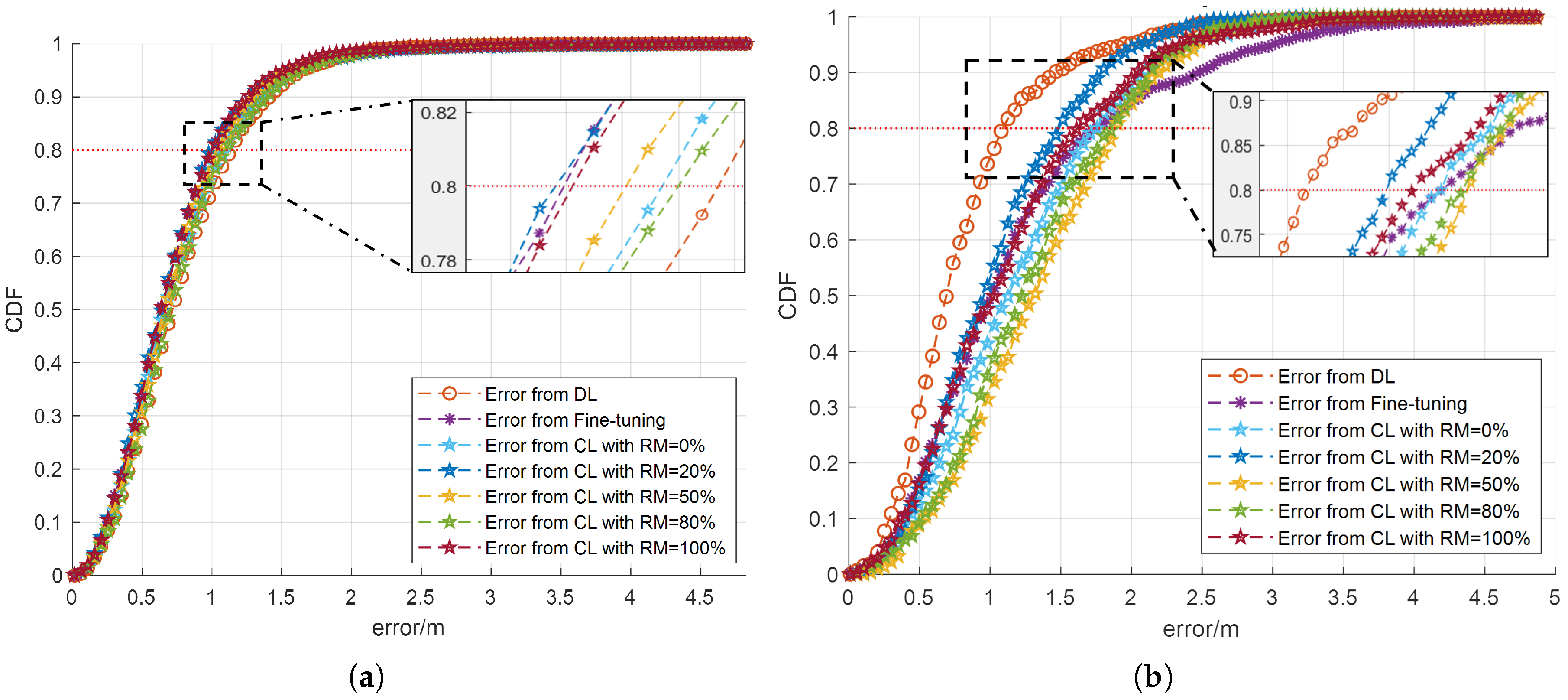
The Cumulative Distribution Function (CDF) of the localization error for various networks in the small room is shown in
Figure 3. To provide a comprehensive evaluation, the results are presented separately for each dataset, highlighting the network’s performance with the new data Dataset 1 at time
and the old data Dataset 3 at time
t.
As shown in
Figure 3a, for the new dataset, CL networks, irrespective of the rehearsal memory size, consistently exhibit faster convergence compared to the DL network trained solely on the new dataset. This indicates that the proposed CL approach more effectively integrates new information while retaining prior knowledge. A particularly noteworthy observation is that in the case of 80% receivers, the localization error for the CL network with
is significantly lower than that of the fine-tuning network. These findings are visually represented in
Figure 3a, further validating the advantage of using a CL approach in dynamic environments. Meanwhile, when evaluating the performance on the old dataset, as shown in
Figure 3b, the DL network still outperforms the other models, achieving the best results. However, the proposed CL network with
closely follows, ranking as the second-best performer. This outcome further reinforces the effectiveness of the CL approach in balancing new and old knowledge. Furthermore, it should be noted that the fine-tuning network exhibits the slowest convergence rate, underscoring the limitations of the fine-tuning approach in maintaining accuracy on previously learned data and further emphasizing the advantage of the CL network in mitigating catastrophic forgetting. The same analysis and conclusion can also be verified with the result when counting for 80% receivers. Therefore, the proposed CL approach with 20% data rehearsal not only improves the localization accuracy for the new data compared to the fine-tuning approach, but also avoids catastrophic forgetting for the previous dataset. Here, we provide the concrete localization Mean Squared Error (MSE) results generated by the DL method, the TL method with fine-tuning, and the proposed CL approach with a 20% rehearsal proportion, as exhibited in
Table 3. In this table, as introduced above, the old dataset is the one with 50% data missing, which is Dataset 3, and the new dataset is the one with 20% data missing, which is Dataset 1.
In
Table 3, we observe that for the new dataset, the proposed CL approach achieves a localization MSE of 0.616 m, which is an improvement of 16% over the fine-tuning approach and 66% over the DL approach. This confirms the high localization accuracy of the proposed CL approach. For the old dataset, the error of the proposed CL approach is 0.681 m, a 47% improvement compared to the fine-tuning approach, further validating its ability to mitigate catastrophic forgetting.
Similarly, in the larger room, where Dataset 7 represents the old dataset and Dataset 5 represents the new dataset, the proposed CL approach demonstrates superior localization accuracy compared to the TL approach. It also effectively mitigates catastrophic forgetting, as evidenced by an 80% rehearsal proportion. As shown in
Table 4, it is observed that with an 80% rehearsal proportion, the proposed CL approach achieves a localization MSE of 2.551 m for the new dataset, which represents a 19% improvement over the fine-tuning approach and a 35% improvement over the DL approach, confirming its high localization accuracy. For the old dataset, the proposed CL approach yields an error of 6.297 m, reflecting a 50% improvement compared to the fine-tuning approach, further validating its ability to mitigate catastrophic forgetting.
4.2. Verification When Noise Varies over Time
We also verify the proposed CL approach in a dynamic environment with noise variation over time. In this scenario, within the smaller room, Dataset 2 serves as the old dataset and Dataset 1 as the new one, simulating a dynamic environment. Additionally, Dataset 4 and Dataset 3 can form another comparison pair. Here, we present the results from the first dataset pair.
As shown in
Figure 4, similar observations are made as in
Figure 3, with the proposed CL approach demonstrating the best performance among the presented rehearsal proportions at 20%. For the new dataset, CL networks convergence faster compared to the DL network trained exclusively on the new dataset, regardless of the rehearsal memory size. This highlights the CL approach’s superior ability to integrate new information while preserving prior knowledge. Notably, for 80% receivers, the localization error for the CL network with
is lower than that of the fine-tuning network. These findings, shown in
Figure 4a, underscore the advantages of the CL approach in dynamic environments for the new dataset. It can be noticed that the results from fine-tuning and CL with
,
,
,
, and
are very similar. This is because in conditions where only small changes occur in the environment, indicating that the rehearsal data are similar to the previous ones and further implying that the new dataset has minimal differences from the old one, fine-tuning and CL may achieve similar accuracy performance. For the old dataset, as shown in
Figure 4b, the proposed CL approach with 20% rehearsal proportion performs higher localization accuracy and also avoids catastrophic forgetting. The MSE results are shown in
Table 5.
As presented in
Table 5, the proposed CL approach with a 20% rehearsal proportion achieved a localization MSE of 0.048 m for the new dataset, which represents a 29% improvement compared to the fine-tuning approach and a 26% improvement compared to the DL approach. For the old dataset, the proposed approach also showed a 29% improvement over the fine-tuning approach, verifying its ability to avoid catastrophic forgetting.
For the larger room, similar conclusions are observed with an 80% rehearsal proportion. As shown in
Table 6, the proposed approach demonstrates higher localization accuracy, improved by 14% compared to the fine-tuning approach for the new dataset. Additionally, it mitigates catastrophic forgetting by achieving a 44% improvement compared to the fine-tuning approach for the old dataset.





{kind=link}
{kind=link}
{kind=link}
{kind=link}