
Deep Learning-Based Algorithm for Road Defect Detection

Abstract
1. Introduction
2. RepGD-YOLOV8W Algorithm Construction
2.1. GD
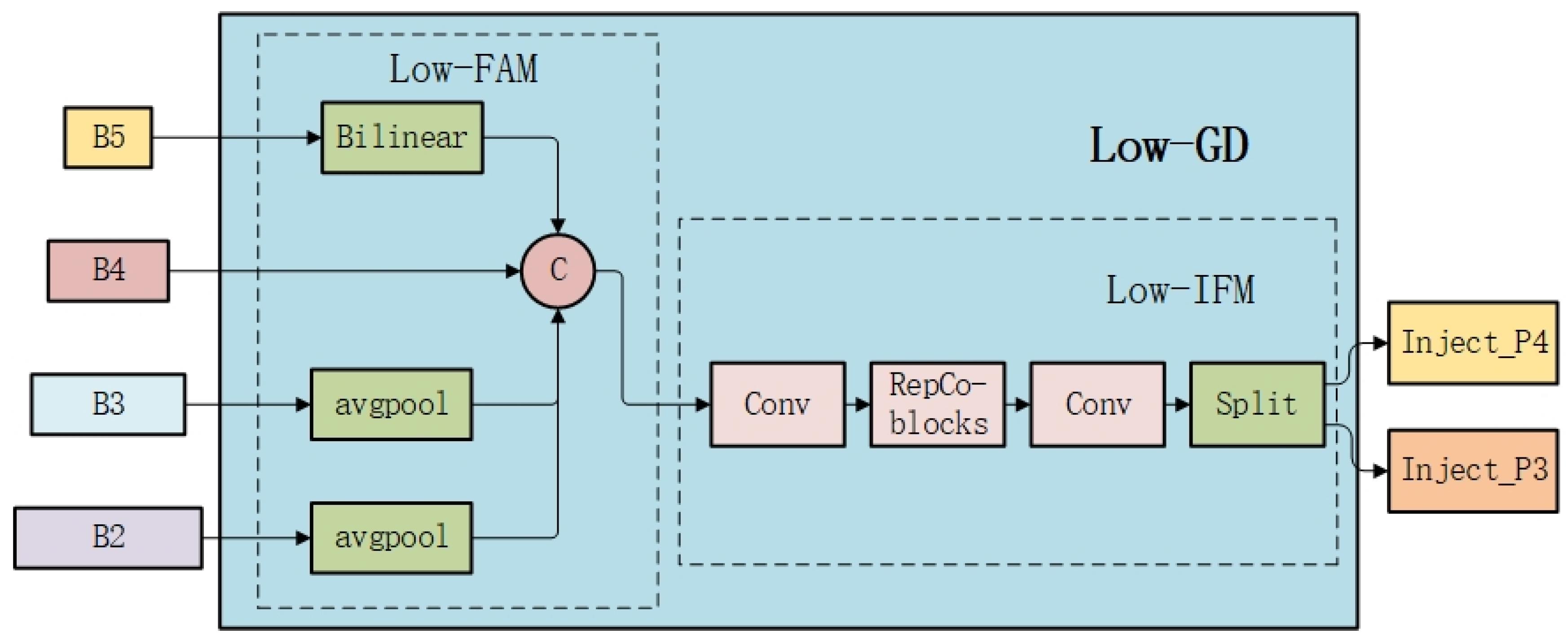
2.1.1. Low-GD
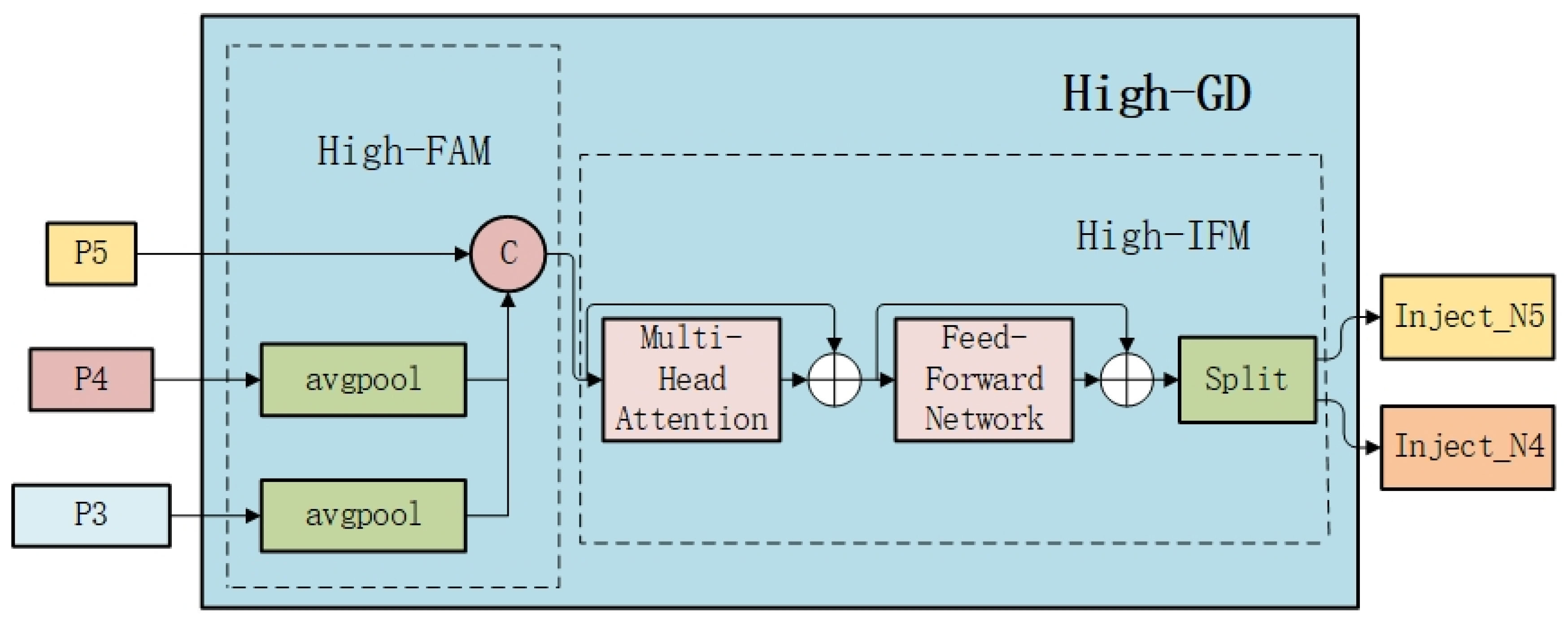
2.1.2. High-GD
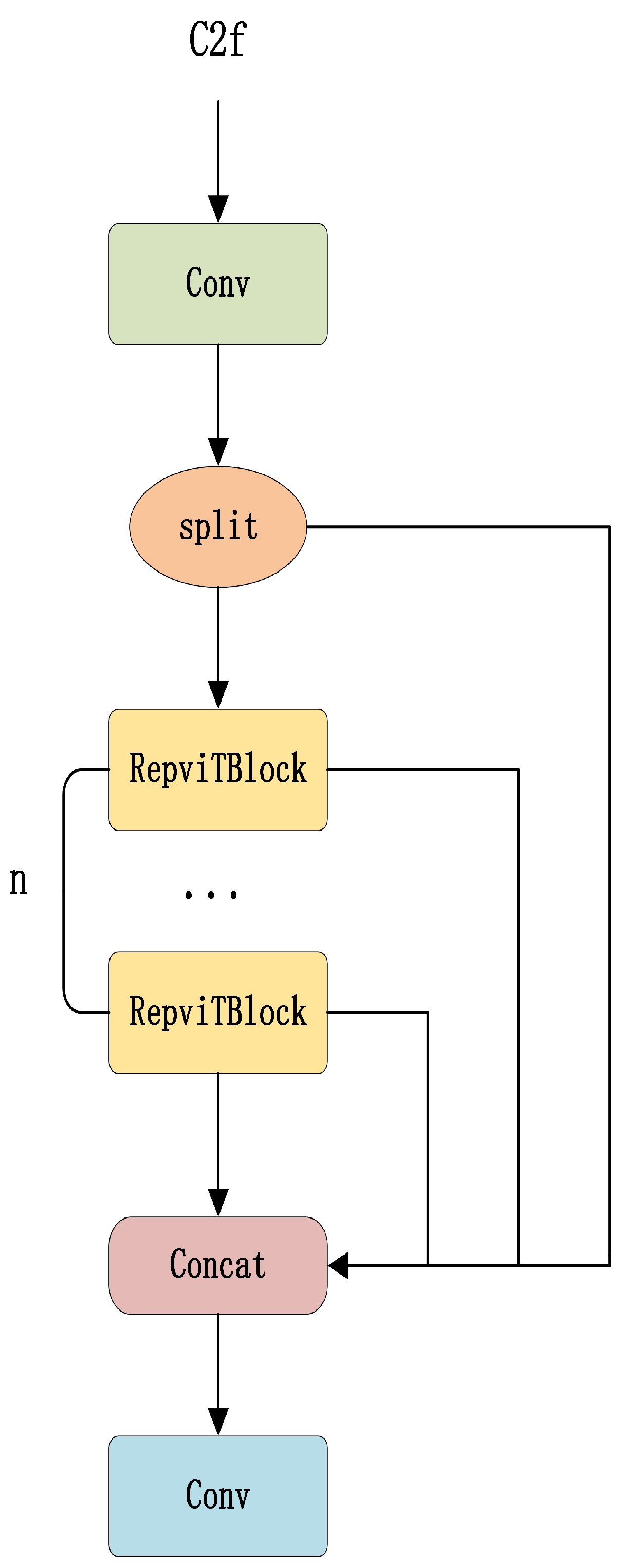
2.2. Introduction of RepViTBlock
2.3. Wise-IoU Loss Function
3. Experiments and Results
3.1. Evaluation Criteria
3.2. Ablation Experiments
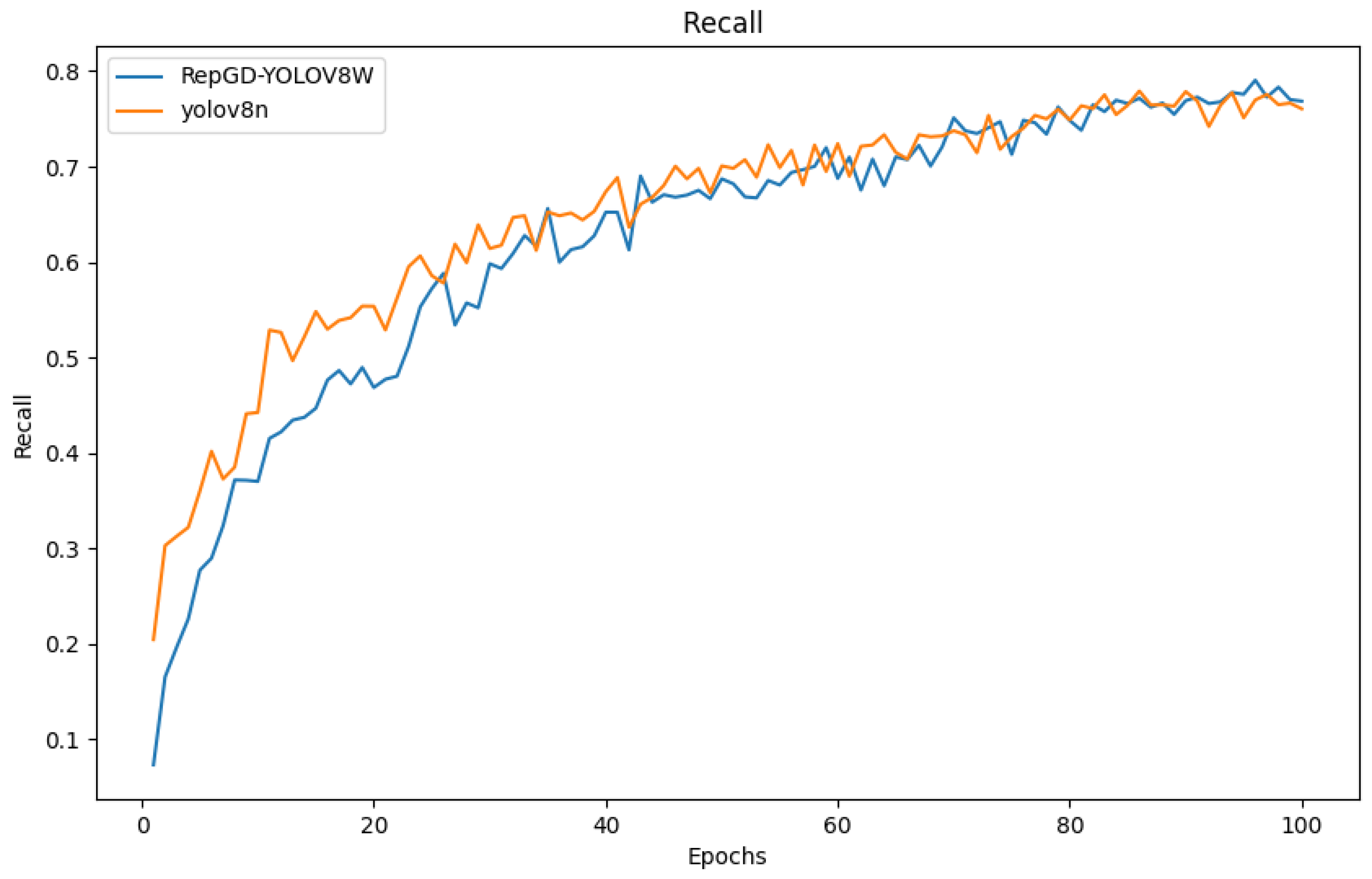
3.3. Comparative Experiments
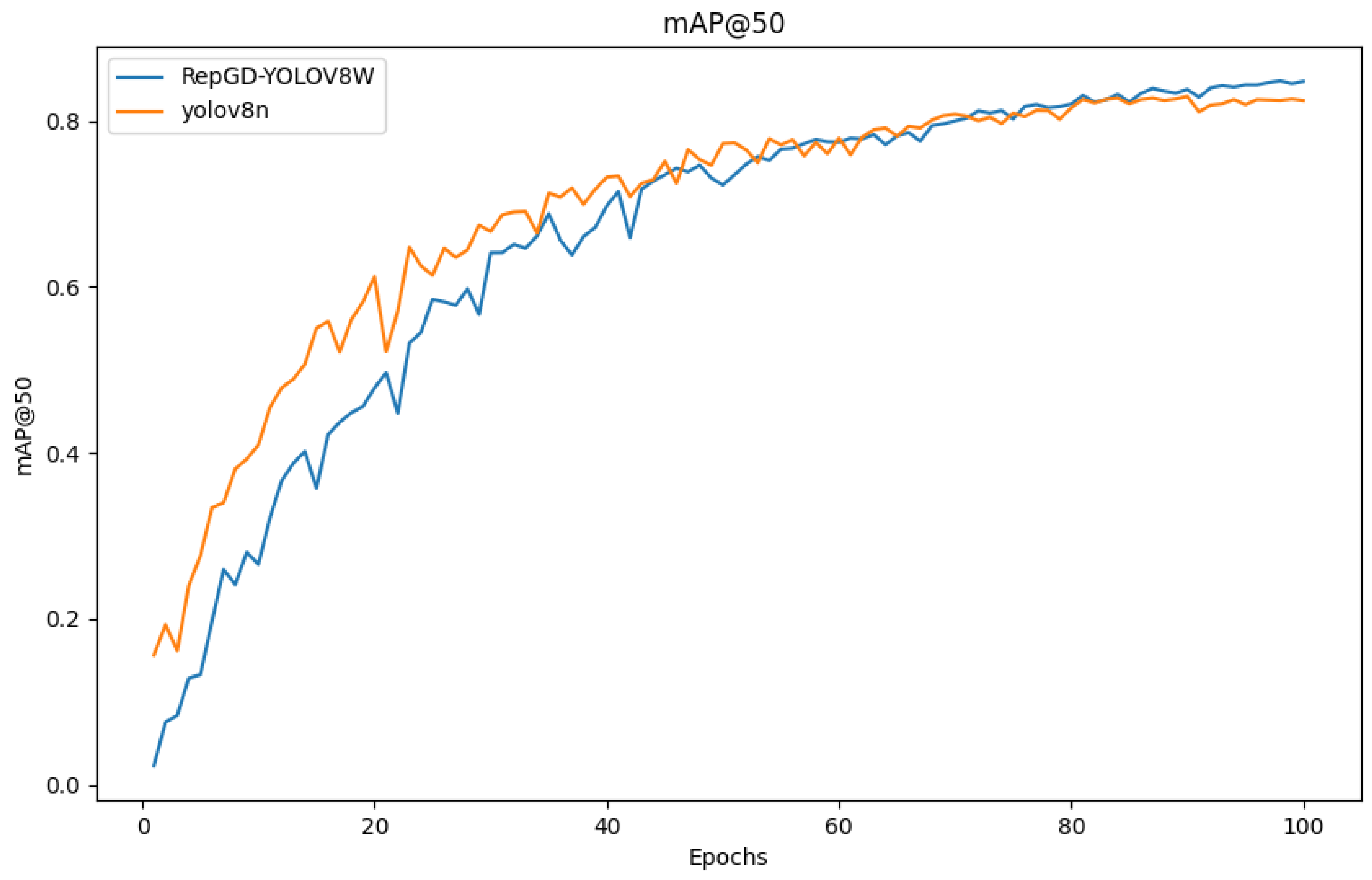
3.4. Comparison of Test Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You only look once |
| RepGD-YOLOV8W | RepViTBlock Gather-and-Distribute YOLOV8n Wise-IoU loss function |
| GD | Gather-and-Distribute |
| IOU | Intersection over union |
| AP | Average precision |
| mAP | Mean average precision |
References
- Transportation Ministry of China. 2023 Statistical Bulletin on the Development of the Transportation Industry (Highway Section), Commercial Vehicle; Transportation Ministry of China: Beijing, China, 2024; pp. 56–57.
- Fang, H. Discussion on main damage forms and causes of asphalt pavement. Real Estate 2022, 224–226. [Google Scholar]
- Mandal, V.; Mussah, A.R.; Adu-Gyamfi, Y. Deep learning frameworks for pavement distress classification: A comparative analysis. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5577–5583. [Google Scholar]
- Ma, J.; Zhao, X.; He, S.; Song, H.; Zhao, Y.; Song, H.; Cheng, L.; Wang, J.; Yuan, Z.; Huang, F.; et al. Review of pavement detection technology. J. Traffic Transp. Eng. 2017, 17, 121–137. [Google Scholar]
- Fan, L.; Zhao, H.; Li, Y. RAO-UNet: A residual attention and octave UNet for road crac k detection via balance loss. IET Intell. Transp. Syst. 2022, 16, 332–343. [Google Scholar] [CrossRef]
- Ma, N.; Fan, J.; Wang, W.; Wu, J.; Jiang, Y.; Xie, L.; Fan, R. Computer vision for road imaging and pothole detection: A state-of-the-art review of systems and algorithms. Transp. Saf. Environ. 2022, 4, 1–16. [Google Scholar] [CrossRef]
- Lu, C.; Tang, X. Surpassing Human-Level Face Verification Performance on LFW with Gaussian Face. In Proceedings of the 29th AAAI National Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 3811–3819. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Back, T.; Chesus, M.; Corrado, G.S.; Darzi, A.; et al. International Evaluation of an AI System for Breast Cancer Screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.W. Forklift Fatigue Driving Detection Algorithm Based on Knowledge Distillation. Agric. Equip. Intell. Technol. 2024, 3, 21–24. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Sun, W.; Xu, W.; Wang, C. Intelligent Surgical Speech Recognition Based on YAMNet Transfer Learning. Mod. Inf. Technol. 2024, 8, 61–65. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Guo, H.; Zheng, K.; Fan, X.; Yu, H.; Wang, S. Visual Attention Consistency Under Image Transforms for Multi-Label Image Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 729–739. [Google Scholar]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention Mechanisms in Computer Vision: A Survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.; Hu, S. Visual Attention Network. arXiv 2022, arXiv:2202.09741. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Cao, W.; Liu, Q.; He, Z. Review of pavement defect detection methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Cao, J.G.; Yang, G.T.; Yang, X.Y. Deep learning-based pavement crack detection with attention mechanism. J. Comput.-Aided Des. Comput. Graph. 2020, 32, 1324–1333. [Google Scholar]
- Ren, M.; Zhang, X.; Chen, X.; Zhou, B.; Feng, Z. YOLOv5s-M: A deep learning network model for road pavement damage detection from urban street-view imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 120, 103335. [Google Scholar] [CrossRef]
- Hu, X.W.; Yan, Y.X.; Wang, D.W.; Zhang, Y.H. Lightweight pavement defect detection method based on YOLOM algorithm. China J. Highw. Transp. 2024, 382–391. [Google Scholar]
- Guo, G.; Zhang, Z. Road damage detection algorithm for improved YOLOv5. Sci. Rep. 2022, 12, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. In Proceedings of the Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Repvit: Revisiting mobile cnn from vit perspective. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 15909–15920. [Google Scholar]
- Zheng, Q.; Saponara, S.; Tian, X.; Yu, Z.; Elhanashi, A.; Yu, R. A real-time constellation image classification method of wireless communication signals based on the lightweight network MobileViT. Cogn. Neurodyn. 2023, 18, 659–671. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding boxregression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Omata, H.; Kashiyama, T.; Sekimoto, Y. Crowdsensing-based road damage detection challenge (CRDDC’2022). In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 6378–6386. [Google Scholar]
- Seo, D.-M.; Woo, H.-J.; Kim, M.-S.; Hong, W.-H.; Kim, I.-H.; Baek, S.-C. Identification of asbestos slates in buildings based on faster region-based convolutional neural network (faster R-CNN) and drone-based aerial imagery. Drones 2022, 6, 194. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y. YOLOv7: Trainable bag-of-freebies sets new state of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Li, T.; Li, G. Road Defect Identification and Location Method Based on an Improved ML-YOLO Algorithm. Sensors 2024, 24, 6783. [Google Scholar] [CrossRef]
- Fu, J.Y.; Zhang, Z.J.; Sun, W.; Zou, K. Improved YOLOv8 Small Target Detection Algorithm in Aerial Images. Comput. Eng. Appl. 2024, 60, 100–109. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P% | R% | map50% | Params | GFLOPs |
|---|---|---|---|---|---|
| YOLOv8n | 0.939 | 0.95 | 0.825 | 3,230,908 | 8.4 |
| YOLOv8n+GD | 0.947 | 0.95 | 0.833 | 6,227,228 | 12.3 |
| YOLOv8n+Rep-GD | 0.941 | 0.94 | 0.840 | 5,822,236 | 11.7 |
| YOLOv8n+Wise-IoU | 0.946 | 0.94 | 0.839 | 3,230,908 | 8.4 |
| YOLOv8n+GD+Wise-IoU | 0.904 | 0.94 | 0.836 | 6,227,228 | 12.3 |
| YOLOv8n+Rep-GD+Wise-IoU | 0.969 | 0.94 | 0.849 | 5,822,236 | 11.7 |
| Model | mAP50% | Params/M |
|---|---|---|
| Faster R-CNN | 0.758 | 41.14 |
| SSD | 0.754 | 24.83 |
| YOLOv5n | 0.802 | 1.77 |
| YOLOv5s | 0.810 | 7.03 |
| YOLOv7tiny | 0.818 | 6.02 |
| YOLOv8n | 0.825 | 3.01 |
| ML-YOLO | 0.840 | 139.5 |
| CA-YOLOv8 | 0.839 | 7.40 |
| RepGD-YOLOV8W | 0.849 | 5.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Zhang, D. Deep Learning-Based Algorithm for Road Defect Detection. Sensors 2025, 25, 1287. https://doi.org/10.3390/s25051287
Li S, Zhang D. Deep Learning-Based Algorithm for Road Defect Detection. Sensors. 2025; 25(5):1287. https://doi.org/10.3390/s25051287
Chicago/Turabian StyleLi, Shaoxiang, and Dexiang Zhang. 2025. "Deep Learning-Based Algorithm for Road Defect Detection" Sensors 25, no. 5: 1287. https://doi.org/10.3390/s25051287
APA StyleLi, S., & Zhang, D. (2025). Deep Learning-Based Algorithm for Road Defect Detection. Sensors, 25(5), 1287. https://doi.org/10.3390/s25051287