Abstract
Video portrait segmentation is essential for intelligent sensing systems, including human-computer interaction, autonomous navigation, and augmented reality. However, dynamic video environments introduce significant challenges, such as temporal variations, occlusions, and computational constraints. This study introduces RVM+, an enhanced video segmentation framework based on the Robust Video Matting (RVM) architecture. By incorporating Convolutional Gated Recurrent Units (ConvGRU), RVM+ improves temporal consistency and captures intricate temporal dynamics across video frames. Additionally, a novel knowledge distillation strategy reduces computational demands while maintaining high segmentation accuracy, making the framework ideal for real-time applications in resource-constrained environments. Comprehensive evaluations on challenging datasets show that RVM+ outperforms state-of-the-art methods in both segmentation accuracy and temporal consistency. Key performance indicators such as MIoU, SAD, and dtSSD effectively verify the robustness and efficiency of the model. The integration of knowledge distillation ensures a streamlined and effective design with negligible accuracy trade-offs, highlighting its suitability for practical deployment. This study makes significant strides in intelligent sensor technology, providing a high-performance, efficient, and scalable solution for video segmentation. RVM+ offers potential for applications in fields such as augmented reality, robotics, and real-time video analysis, while also advancing the development of AI-enabled vision sensors.
1. Introduction
Video portrait segmentation is the process of accurately distinguishing between foreground and background regions in video frames [1]. It plays a crucial role in diverse applications, including human-computer interaction, augmented reality (AR), video editing, autonomous navigation, and video surveillance. The exponential growth in video content has increased the demand for advanced segmentation technologies that can deliver both high accuracy and computational efficiency in dynamic scenarios [2,3]. However, achieving reliable segmentation in video sequences is challenging due to factors such as temporal variations, occlusions, deformations, and the need for real-time processing in resource-constrained environments.
Pixel-level image segmentation (ISS) forms the foundation for video segmentation by analyzing features such as contrast, texture, and grayscale values for pixel-wise classification [4,5]. ISS is crucial for various applications, including pedestrian detection, intelligent rescue operations, medical imaging, and autonomous driving [6,7]. While significant progress has been made in static image segmentation, extending these techniques to video introduces additional complexities. Ensuring temporal consistency across frames and handling rapid motion, occlusions, and dynamic backgrounds require more sophisticated algorithms [8,9].
Deep learning has revolutionized semantic segmentation over the past decade. Fully Convolutional Networks (FCNs) replaced fully connected layers with convolutional layers [10], enabling pixel-level classification. Architectures such as U-Net [11] and SegNet [12] introduced hierarchical feature extraction and upsampling, enhancing resolution and performance. Further innovations, such as pyramid pooling in PSPNet [13] and atrous convolutions in DeepLab [8], have improved segmentation by integrating multiscale features and global context.
Lightweight architectures have become increasingly popular for balancing accuracy and computational efficiency. ENet optimized depth while maintaining speed [14], ICNet utilized multi-resolution branches [15], and BiSeNet combined detail and semantic branches for real-time segmentation [16]. MobileNet-v2 leveraged depthwise separable convolutions for lightweight, efficient models [17]. While these architectures perform well in resource-constrained scenarios, they often struggle to maintain temporal consistency and robustness in dynamic video environments.
The challenges of video segmentation are further amplified in scenarios with significant motion, multi-subject overlaps, or complex backgrounds [18,19]. Many existing models fail to maintain frame-to-frame consistency, particularly in long sequences with intricate temporal dynamics. Additionally, their high computational demands hinder real-time applicability.
The Robust High-Resolution Video Matting (RVM) framework introduced temporal guidance to improve segmentation in dynamic video data [3,20]. However, this method still struggles with vanishing gradients in long sequences and performance drops in overlapping or fast-moving scenarios.
To address these limitations, this study introduces RVM+, an enhanced framework built upon the RVM architecture. The key innovation is the integration of Convolutional Gated Recurrent Units (ConvGRU) to improve temporal modeling. ConvGRUs effectively capture dependencies between frames, retaining both spatial and temporal features, ensuring temporal consistency, and achieving accurate segmentation even in dynamic scenarios. Additionally, we propose a knowledge distillation strategy to optimize the RVM+ model. By transferring knowledge from a fully trained teacher model to a smaller student model, computational requirements are reduced without compromising accuracy. This optimization is crucial for real-time applications on resource-constrained platforms such as mobile devices and edge systems. Rigorous evaluations on multiple challenging datasets confirm that RVM+ outperforms state-of-the-art methods. Finally, we use key metrics such as Mean Intersection over Union (MIoU), Sum of Absolute Differences (SAD), and temporal-specific measures (dtSSD) to validate the model’s efficiency and temporal consistency.
This work makes the following contributions:
- (1)
- Development of the RVM+ model: By integrating ConvGRU into the RVM framework, this study represents a significant advancement in video segmentation technology, particularly in handling dynamic content and temporal changes.
- (2)
- Optimization through knowledge distillation: The study introduces an innovative approach to model optimization using knowledge distillation, effectively reducing model size and computational requirements—critical for real-time processing applications.
- (3)
- Comprehensive performance evaluation: Extensive testing on a variety of challenging datasets demonstrates the enhanced segmentation capabilities of the RVM+ model, setting new benchmarks for accuracy compared to existing segmentation models.
The remainder of this paper is organized as follows: Section 2 provides a detailed explanation of the RVM+ framework and its methodology. Section 3 presents experimental results, followed by a discussion of findings in Section 4. Finally, Section 5 concludes the paper by summarizing the contributions and outlining future research directions.
2. Materials and Methods
This study outlines a systematic approach to developing an advanced video portrait segmentation algorithm. The process begins with the collection and augmentation of diverse datasets containing portrait images and video sequences, forming a robust foundation for training and testing. A balanced subset of this data, incorporating both static and dynamic content, is then selected for effective algorithm training. A key innovation in this workflow is the use of knowledge distillation to optimize the model’s size and speed, making it suitable for real-time applications. The process concludes with a comprehensive evaluation of the model, benchmarking its accuracy, efficiency, and robustness against existing methods. This entire workflow, depicted in Figure 1, is designed to yield a highly efficient and accurate model for video portrait segmentation.

Figure 1.
Flowchart of our video portrait segmentation structure.
2.1. Datasets and Preprocessing
In this study, we developed the VM-datasets for video portrait segmentation, focusing on capturing a wide range of real-world scenarios. Our approach to assembling these datasets was multifaceted and methodically structured to ensure both diversity and realism.
Organization of Open-Source Datasets: The first step was to aggregate data from various open-source web datasets, selecting images that represented a broad spectrum of demographics, backgrounds, and scenarios. Acknowledging the limitations of these datasets, particularly in multi-subject scenes and complex backgrounds, we strategically augmented our collection with an additional 100 images, referred to as MulData [21,22,23,24,25,26,27]. These images were specifically chosen to fill gaps and ensure comprehensive representation of various portrait settings. Furthermore, to enhance the dataset for video applications, we added 2000 unique non-human background images to provide a richer variety of environmental contexts.
This careful curation process is illustrated in Figure 2 and Figure 3, which showcase the diversity of the added data. We also filtered out irrelevant data during the collection process to maintain the dataset’s quality and relevance. Table 1 provides the names and descriptions of the datasets used for training and testing the proposed algorithm.

Figure 2.
Static background sample images.

Figure 3.
MulData dataset sample images.

Table 1.
The Internet’s open-source datasets.
Data Enhancements: To further enrich our dataset, we employed a series of data enhancement techniques designed to mimic real-world variability. These enhancements included motion-related changes, such as scaling and rotation (Figure 4), as well as color adjustments (e.g., brightness and saturation), applied to preserve the natural integrity of the images [28]. To introduce temporal diversity in the video data, we incorporated techniques such as clip reversal and speed variations. Additionally, for static datasets such as VMD and PhotoMatte85, we created composite images by combining transparent background subject images with various backgrounds from the BG dataset (Figure 5). Each subject image was paired with 20 different backgrounds to ensure a realistic and representative mix. This process expanded PhotoMatte85 to 13,165 images and VMD to 89,227 images, simulating a wide range of portrait environments. Each step of our dataset assembly and augmentation was systematically structured and executed with the goal of developing a robust, diverse, and realistic dataset—essential for effective training and testing of our video portrait segmentation model.

Figure 4.
Results of random rotation.

Figure 5.
Results of background fitting.
2.2. Design of the Model Network Structure
Our study focuses on developing a video portrait segmentation model, with an emphasis on the evolution of video portrait processing algorithms. We provide an in-depth analysis of the RVM model’s structure and detail the specific enhancements and adjustments made to optimize its performance.
2.2.1. General Framework of the RVM
The RVM model functions as a real-time foreground segmentation framework for video scenes, employing a U-shaped architecture. It incorporates MobileNetV3-Large as an efficient backbone and utilizes the LR-ASPP module of MobileNetV3 for semantic segmentation tasks. The model architecture consists of a three-part encoder for frame feature extraction, a cyclic decoder for temporal information aggregation, and a depth-guided filter module for high-resolution upsampling, as illustrated in Figure 6.
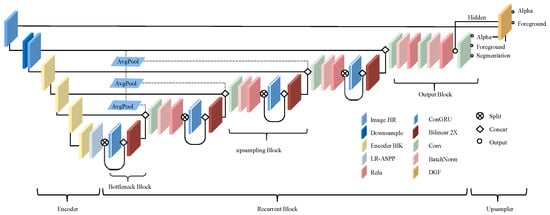
Figure 6.
RVM model structure.
When processing high-resolution video, the model first downsamples the input to manage resolution and computational load effectively. The encoder then extracts frame features at multiple scales, generating a detailed feature map. These features are passed to the recurrent decoder, where temporal information plays a crucial role.
2.2.2. Structure of the ConvGRU
The ConvGRU, an integral component of the RVM+ model, represents an advanced evolution in video segmentation, particularly effective for tasks requiring temporal sequencing [29]. The design of ConvGRU is characterized by its dual ability to retain relevant information from previous inputs while simultaneously processing new data. This functionality is crucial for accurately contextualizing each frame in a video sequence. ConvGRU selectively retains important information for future frames while discarding data from distant past frames that are no longer relevant. This selective retention is key to the module’s efficiency, as illustrated in Figure 7. By incorporating convolutional layers into its architecture, ConvGRU effectively handles both spatial and temporal data, which is highly advantageous for real-time applications requiring a nuanced understanding of complex video content. The ConvGRU is calculated as follows:
where represents the input data at the current time step, and represents the network’s memory or state at the current time step, which depends on the previous hidden state and the current input . denotes the sigmoid function, is the standard two-dimensional convolution operation, and denotes the Hadamard product. The parameters , , , and are the corresponding 3 3 convolution kernels.
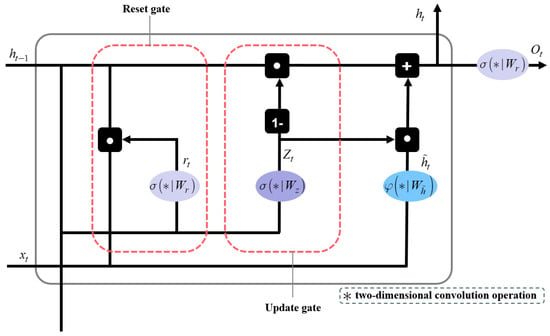
Figure 7.
Structure of the ConvGRU module for extracting temporal features.
2.2.3. Structure of the Proposed RVM+
In the RVM+ model, an advanced iteration of the RVM framework, ConvGRU is strategically integrated to address the specific challenges of portrait segmentation in video. At the bottleneck stage of the model, ConvGRU is crucial for retaining and accurately processing essential temporal information within this compressed segment. This stage plays a key role in distilling significant features from the input data while preserving their temporal coherence. During upsampling, as spatial resolution is progressively restored, ConvGRU modules are vital for reintroducing and refining temporal details. This is essential for maintaining the integrity of time-sensitive features in dynamic scenes, as illustrated in Figure 8.
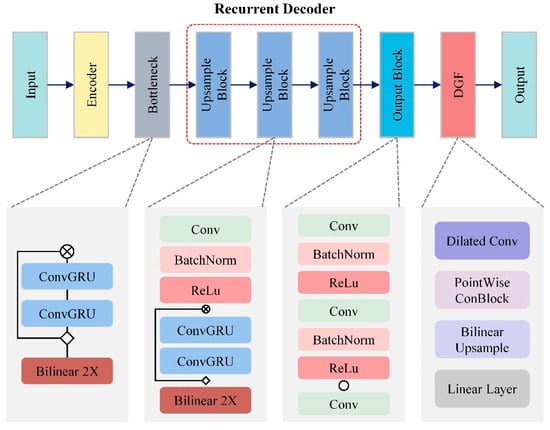
Figure 8.
Structure of the RVM+ model.
The effectiveness of the RVM+ model is significantly enhanced by the role of ConvGRU in maintaining temporal continuity, a crucial factor for understanding each frame in its proper context. This is especially important in videos with constantly changing subjects and backgrounds. The model’s feature propagation mechanism enables accurate segmentation across multiple frames, even in complex scenarios involving overlapping objects, variable lighting, and other challenging conditions. This capability is invaluable for high-precision applications such as advanced video editing, augmented reality, and real-time surveillance systems.
Moreover, the RVM+ model emphasizes computational efficiency, which is essential for applications requiring real-time processing, such as live video streaming or interactive AR/VR environments. The efficient ConvGRU modules within the RVM+ model’s streamlined architecture ensure rapid processing of video frames without compromising accuracy, making the model particularly well-suited for environments with limited computing resources.
2.2.4. Loss Function
The model utilizes the Laplace pyramid loss for the alpha map of each frame in the video, with an additional temporal correlation loss introduced to account for the temporal nature of the video. The total loss is defined as follows:
where is the test map and is the true label.
To learn foreground and true label , L1 loss and temporal correlation loss are proposed, where , whose loss is defined as follows:
Thus, the overall loss function can be described as follows:
For semantic segmentation, the network is trained solely on the human category. To learn the segmentation probability and the true binary label , we compute the binary cross-entropy loss as follows:
2.3. Model Knowledge Distillation Strategy
Our study employs a knowledge distillation process to create a compact yet robust model, particularly suited for complex image segmentation tasks [30]. As illustrated in Figure 9, this process begins by using the RVM+ model as a “teacher”, which, once fully trained, captures intricate relationships within the dataset. The predictions of the teacher model, referred to as “soft targets”, are essential for transferring knowledge to a smaller, simpler “student” model. To enhance the effectiveness of this transfer, we incorporate a label transfer data mining method and introduce a temperature variable T. This approach accurately represents label relationships, facilitating more efficient knowledge transfer. The training of the student model involves a combination of insights from the teacher model and a specialized distillation loss function that balances the KLDiv loss for soft targets and the BCE loss for real labels. During online prediction, the student model operates at a reduced temperature setting (T = 5), optimizing the extraction of distilled knowledge from the teacher model.
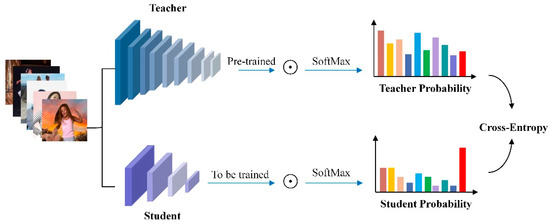
Figure 9.
Specific schematic of knowledge distillation.
This distillation technique is an integral part of our training methodology, enabling the development of an efficient yet powerful model. It compresses the rich knowledge of the teacher model into the smaller student model, effectively overcoming the challenges associated with large-scale models while leveraging their strengths in a resource-optimized manner. The temperature variable T plays a crucial role in influencing the probability distribution during this process. Together, these elements ensure a comprehensive and effective approach to training the student model, addressing the limitations of large-scale models while exploiting their advantages in a more resource-efficient manner.
3. Results
3.1. Evaluation Metrics
To evaluate the accuracy of image and video segmentation networks in our study, we use a comprehensive set of metrics, categorized into pixel accuracy and Intersection over Union (IoU). These metrics include MIoU, which calculates the average IoU across different categories, providing a measure of semantic segmentation accuracy. We also use Mean Squared Error (MSE) to assess the average squared deviation between predicted and actual values, where a lower MSE indicates better accuracy. The SAD measures the absolute differences between corresponding pixels in image blocks, offering an intuitive measure of similarity. For video segmentation, we use the dtSSD and MESSDdt metrics, which account for time-dependent errors and are crucial for evaluating the model’s ability to maintain temporal consistency [31]. Together, these metrics ensure a thorough evaluation of the models’ effectiveness in both image and video segmentation tasks.
where is the true value, is the predicted value, is the number of predictions from to , and is the total number of categories; signifies the predicted value at pixel at time , and represents the true value at pixel at time ; m represents the number of pixels and represents the motion vector at pixel , computed by an optical flow algorithm from the true value time series.
3.2. Experimental Results
3.2.1. Ablation Study
In our ablation study, we systematically evaluated the performance improvements of the RVM+ model, focusing specifically on the impact of integrating the ConvGRU module. The goal of this study was to quantify the improvements in segmentation accuracy resulting from this integration. We selected three distinct datasets—VS-test, VMHD_TS, and PhotoMatte85-TS—for comprehensive analysis. These datasets were chosen for their varying levels of complexity and relevance to video portrait segmentation, ensuring a robust evaluation of the model’s capabilities.
Several detailed evaluation metrics were employed to assess the performance of the RVM+ model: MIoU for semantic segmentation accuracy, SAD to measure pixel-level discrepancies, dtSSD to evaluate time-dependent errors crucial for video segmentation, and MSE to quantify prediction accuracy. These metrics provide a multifaceted view of the model’s performance, covering various aspects of segmentation accuracy and error measurement.
The results of this study, presented in Table 2, highlight the performance of the RVM+ model compared to the original version across these metrics. The best-performing metrics for each dataset are highlighted in bold, providing a clear visual representation of the superior performance of the RVM+ model. This comparative analysis demonstrates the improved video portrait segmentation accuracy of the RVM+ model, attributing the improvement primarily to the integration of the ConvGRU module. The study results not only validate the effectiveness of the ConvGRU integration in the RVM+ model but also establish its superiority over the original version in handling complex video segmentation tasks.
Table 2.
Ablation study results.
3.2.2. Quantitative and Qualitative Results
The results in Table 3 illustrate the performance of our proposed RVM+ model on three video portrait segmentation datasets: VS-test, VMHD_TS, and PhotoMatte85-TS. The model achieves an impressive MIoU of 0.974 on the VS-test set, indicating highly accurate segmentation relative to the ground truth. Its performance drops slightly on the more challenging VMHD_TS and PhotoMatte85-TS datasets, with MIoUs of 0.852 and 0.895, respectively. This decrease may be attributed to the increased complexity or variability within these datasets. The SAD scores are low for all datasets, with the lowest being 5.81 for the VS-test set, suggesting a close match between the segmented portraits and the ground truth. The dtSSD and MSE metrics further corroborate the model’s accuracy, with particularly low MSE scores, the lowest being 0.011 on VMHD_TS, underscoring the model’s consistency in pixel-wise accuracy. Additionally, the bps value indicates the model’s computational efficiency, reaching up to 4.15 M on the VMHD_TS dataset. The FPS value reflects the model’s real-time performance capability, achieving a peak of 32.3 FPS on the VS-test dataset, demonstrating the model’s effectiveness in real-time applications. Taken together, these results indicate that the RVM+ model is highly effective for video portrait segmentation tasks, with some variability in performance across different datasets—typical of model generalization.
Table 3.
Quantitative results on the VS-test, VMHD_TS, and PhotoMatte85-TS datasets.
In our study, we extended the evaluation of the RVM+ model to include various real-world scenarios. To achieve this, we selected six test videos, each chosen to represent a diverse set of challenges commonly encountered in video segmentation. These challenges included different motion dynamics, lighting conditions, and scene complexity, providing a robust testbed for assessing the model’s capabilities. For each video, we systematically selected three key frames that exemplified these challenges, ensuring a comprehensive and representative assessment of the RVM+ model’s performance across typical and complex situations.
Enhanced visual representations in Figure 10 provide a side-by-side comparison of the RVM+ model’s segmentation results with the corresponding ground truth data. By juxtaposing the model’s output with the actual data, we offer a clear visual assessment of its performance in different scenarios. This illustrative approach not only highlights the model’s segmentation capabilities but also complements and reinforces the quantitative data presented in our study.

Figure 10.
Segmentation results of a three-frame test video.
Furthermore, our study offers a detailed technical analysis of the advanced segmentation model, highlighting its ability to address challenging scenarios commonly encountered in video segmentation. The model employs a sophisticated convolutional neural network architecture augmented with depth-aware layers, which are critical for effectively distinguishing overlapping objects in densely populated scenes—a common issue in multi-subject overlap scenarios. As shown in Figure 11a, this feature enables the model to handle complex multi-subject scenes, ensuring accurate segmentation even when subjects are closely intertwined or overlapping.

Figure 11.
Segmentation results from challenging scenarios.
In addition to managing static complexity, the model excels in dynamic motion scenarios. It incorporates temporal consistency algorithms that leverage data from adjacent frames, maintaining segmentation accuracy throughout the motion sequence. The integration of optical flow techniques allows the model to dynamically track and adapt to motion, resulting in remarkably accurate segmentation of moving objects, as illustrated in Figure 11b. This capability is essential for videos with moving objects, ensuring consistent and reliable segmentation throughout the sequence.
The model also excels in low-contrast environments, where distinguishing between foreground and background can be particularly challenging. To address this, the model incorporates advanced contrast enhancement techniques, such as adaptive histogram equalization. Additionally, it is rigorously trained on a diverse dataset to ensure robust performance, even when foreground and background colors or brightness levels are closely matched. Figure 11c demonstrates the model’s ability to accurately segment objects in such challenging conditions, showcasing its effectiveness in low-contrast scenarios.
After incorporating advanced features into the segmentation model, we applied knowledge distillation to further optimize its performance. To assess the impact of knowledge distillation, we evaluated the model using the VS-test dataset, with the results presented in Table 4. Our analysis revealed that the accuracy loss following the distillation process was minimal, ranging from 1.0% to 1.5%. This slight decrease in accuracy is considered an acceptable trade-off, particularly given the significant gains in the reduced model size and increased processing speed. These factors are crucial for practical applications where resource efficiency is as important as accuracy.
Table 4.
Comparison of evaluation indices before and after knowledge distillation processing.
Additionally, the post-distillation MSE of the model was 0.022, indicating that the model’s ability to predict accurate outcomes was largely maintained despite the reduction in size and complexity. This result highlights the effectiveness of the knowledge distillation process in producing a streamlined yet powerful model, suitable for efficient and accurate video segmentation across various applications.
4. Discussion
In our comprehensive evaluation, detailed in Table 5, we compared the performance of five segmentation models—BGMv2 [32], ConnectNet [33], DeepLabV3 [34], MODNet [35], and the extended RVM+ model—across multiple datasets. This comparison was designed to rigorously assess their segmentation accuracy and overall effectiveness in different scenarios. As the results show, the RVM+ model consistently outperformed the other models across all evaluated datasets. One of the notable achievements of the RVM+ model is its remarkable MIoU score of 0.974 on the VS-test set. This high MIoU indicates the model’s exceptional precision in distinguishing objects from the background, a critical aspect of segmentation accuracy. The RVM+ model also maintained the lowest SAD value of 5.81, indicating that the segmented portrait closely matches the ground truth. In contrast, while DeepLabV3 excels in network depth and multi-scale contextual understanding, it falls short in handling fine edges. MODNet achieves fast inference due to its lightweight design but lags behind RVM+ in detail preservation and edge clarity in complex scenes. ConnectNet’s performance falls between these two, showing good accuracy on certain datasets but still trailing behind RVM+ overall. In summary, these results convincingly demonstrate the superior performance of RVM+ in video portrait segmentation tasks, establishing its potential for high-fidelity segmentation applications.
Table 5.
Comparison of segmentation results with the different models.
In addition to its MIoU performance, the RVM+ model recorded the lowest SAD score of 5.81, emphasizing its ability to closely match the ground truth and its precision in segmentation. The superiority of the RVM+ model is further confirmed by its performance on other metrics such as dtSSD and MSE. Specifically, on the VMHD_TS dataset, the RVM+ model achieved an MSE of 0.011, reflecting its high accuracy in segmentation tasks. These results underscore the exceptional ability of RVM+ to produce accurate and consistent segmentation, highlighting its adaptability and robustness in addressing diverse segmentation challenges.
Figure 12 presents a side-by-side visual evaluation of the segmentation quality of three models using frames from validation videos. The original frames provide context for the segmentation challenge, while the local zooms focus on areas that require precise detail handling, such as hair and edges. The RVM+ model’s segmentation is remarkably detailed and accurate, with clean boundaries and well-preserved fine features, outperforming the other models. BGMv2 captures the general shape of the object but shows reduced edge precision, particularly in finer details. ConnectNet’s results exhibit more pronounced inaccuracies, with blurred edges and a loss of detail, indicating lower segmentation accuracy compared to RVM+, which strikes a balance between detail preservation and edge clarity—critical for high-fidelity segmentation. DeepLabV3 is renowned for its deep network architecture and multi-scale context understanding capabilities. It performs well in capturing the large-scale structures of objects but falls slightly short in handling fine edges. MODNet lags behind in detail retention and edge clarity compared to RVM+ in complex scenarios. This contrast highlights RVM+’s superior performance in video portrait segmentation tasks, particularly in balancing detail preservation and edge sharpness, which is essential for high-fidelity segmentation.

Figure 12.
Detailed comparison of segmentation results across different models.
Figure 13 provides a detailed analysis of how RVM+ excels at capturing fine textures, hair strands, and facial details, emphasizing its ability to maintain high-quality segmentation results. BGMv2, while proficient in object segmentation, falls short in contour accuracy, occasionally resulting in minor mis-segmentation or blurred boundaries. ConnectNet, although adequate, tends to be less accurate than both RVM+ and BGMv2, exhibiting noticeable segmentation errors and reduced clarity in subject contours.

Figure 13.
Comparative effects of multi-angle portrait segmentation.
Despite these limitations, both ConnectNet and BGMv2 have unique strengths. For example, ConnectNet may offer advantages in certain computing environments, while BGMv2 may perform better in specific segmentation scenarios. Acknowledging these strengths alongside their limitations provides a balanced perspective on the current state of subject segmentation technologies. Comparing these models highlights not only the advances made by RVM+ but also the ongoing evolution of video processing. The results of this study offer valuable insight into potential applications where RVM+ could be particularly beneficial, such as real-time video analysis or complex scene interpretation.
5. Conclusions
This study introduces RVM+, an advanced video portrait segmentation model designed to tackle the challenges of dynamic video analysis. By integrating ConvGRUs into the RVM framework, RVM+ enhances temporal consistency and segmentation accuracy, particularly in complex scenarios involving rapid motion, occlusions, and overlapping subjects. Additionally, the implementation of a novel knowledge distillation strategy reduces the model’s computational complexity and size, making it suitable for real-time applications in resource-constrained environments without a significant loss in accuracy. Extensive evaluations on diverse and challenging datasets demonstrate the superiority of RVM+ over state-of-the-art methods. The model consistently delivers high segmentation fidelity, as evidenced by improvements in MIoU, SAD, and temporal-specific metrics such as dtSSD. These results highlight RVM+’s robustness, efficiency, and adaptability to dynamic environments, positioning it as a promising solution for AI-enabled vision sensors. Beyond improved segmentation accuracy, this work contributes to the development of efficient, scalable, and practical solutions for video analysis. Future research will focus on enhancing the model’s generalizability to handle more complex multi-subject and multi-modal scenarios. Moreover, integrating the RVM+ framework with advanced sensing systems, such as IoT devices and wearable sensors, presents exciting opportunities for applications in augmented reality, human–computer interaction, and autonomous systems.
Author Contributions
The study was conceived and designed by N.T., Y.L., X.L. and J.C. N.T., Y.C., X.L. and J.C. conducted the literature search. Data analysis and curation were performed by N.T., Y.L., Y.C. and J.C. Data visualization was performed by N.T., Y.L. and J.C. Software implementation was carried out by N.T., Y.C. and J.C. N.T., Y.L., G.Y. and J.C. prepared the tables and figures. The report was written by N.T., Y.L., Y.C., X.L. and J.C. and revised and edited by N.T., Y.L., Y.C., X.L. and J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work is funded in part by the Zhejiang Provincial Basic Public Welfare Research Project of China (LTGY23H270001). YG is supported in part by the ERC IMI (101005122), the H2020 (952172), the MRC (MC/PC/21013), the Royal Society (IEC\NSFC\211235), the NVIDIA Academic Hardware Grant Program, the SABER project supported by Boehringer Ingelheim Ltd., and the UKRI Future Leaders Fellowship (MR/V023799/1).
Informed Consent Statement
Not applicable.
Data Availability Statement
The public VMHD_TS and PhotoMatte85-TS datasets analyzed in this study are available at https://grail.cs.washington.edu/projects/background-matting-v2/#/datasets (accessed on 6 August 2024). The private dataset (VS-test) presented in this article is not readily available, as the raw and processed data required to reproduce these results cannot be shared at this time due to their inclusion in an ongoing study. Requests for access to the dataset should be addressed to LXB at dmia_lab@zcmu.edu.cn.
Conflicts of Interest
The authors declare no competing interests.
References
- Wang, Y.; Zhang, W.; Wang, L.; Yang, F.; Lu, H. Temporal consistent portrait video segmentation. Pattern Recognit. 2021, 120, 108143. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Seong, S.; Choi, J. Semantic Segmentation of Urban Buildings Using a High-Resolution Network (HRNet) with Channel and Spatial Attention Gates. Remote Sens. 2021, 13, 3087. [Google Scholar] [CrossRef]
- Du, X.; Wang, X.; Li, D.; Zhu, J.; Tasci, S.; Upright, C.; Walsh, S.; Davis, L. Boundary-sensitive Network for Portrait Segmentation. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J.J.A. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Ding, H.; Jiang, X.; Shuai, B.; Liu, A.Q.; Wang, G. Context Contrasted Feature and Gated Multi-Scale Aggregation for Scene Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kim, Y.W.; Byun, Y.C.; Krishna, A.V.N. Portrait segmentation using ensemble of heterogeneous deep-learning models. Entropy 2021, 23, 197. [Google Scholar] [CrossRef]
- Ma, Z.; Yao, G. Deep portrait matting via double-grained segmentation. Multimed. Syst. 2023, 29, 3549–3557. [Google Scholar] [CrossRef]
- Yung-Yu, C.; Curless, B.; Salesin, D.H.; Szeliski, R. A Bayesian approach to digital matting. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhou, C.; Xu, C.; Cui, Z.; Zhang, T.; Yang, J. Self-Teaching Video Object Segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 1623–1637. [Google Scholar] [CrossRef]
- Zheng, S.; Song, Y.; Leung, T.; Goodfellow, I. Improving the Robustness of Deep Neural Networks via Stability Training. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lin, S.; Yang, L.; Saleemi, I.; Sengupta, S. Robust high-resolution video matting with temporal guidance. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar]
- Sun, Y.; Tang, C.K.; Tai, Y.W. Ultrahigh Resolution Image/Video Matting with Spatio-Temporal Sparsity. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Wu, J.; Jiang, Y.; Liu, Q.; Yuan, Z.; Bai, X.; Bai, S. General object foundation model for images and videos at scale. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Lin, S.; Ryabtsev, A.; Sengupta, S.; Curless, B.; Seitz, S.; Kemelmacher-Shlizerman, I. Real-Time High-Resolution Background Matting. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Dai, Y.; Price, B.L.; Zhang, H.; Shen, C. Boosting Robustness of Image Matting with Context Assembling and Strong Data Augmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhang, X.; Yang, K.; Lu, Q.; Wu, J.; Yu, L.; Lin, Y. Predicting carbon futures prices based on a new hybrid machine learning: Comparative study of carbon prices in different periods. J. Environ. 2023, 346, 118962. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Lin, Y.; Wang, W.; Zhao, Y.; Wei, Y.; Shi, H. Diffusion for Natural Image Matting. In Proceedings of the 2024 European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Liu, H.; Soto, R.A.R.; Xiao, F.; Lee, Y.J. YolactEdge: Real-time Instance Segmentation on the Edge. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xian, China, 30 May–5 June 2021. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Siam, M.; Valipour, S.; Jagersand, M.; Ray, N. Convolutional gated recurrent networks for video segmentation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Gou, J.; Hu, Y.; Sun, L.; Wang, Z.; Ma, H. Collaborative knowledge distillation via filter knowledge transfer. Expert Syst. Appl. 2024, 238, 121884. [Google Scholar] [CrossRef]
- Ren, J.; Zhang, M.; Yu, C.; Liu, Z. Balanced MSE for Imbalanced Visual Regression. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Li, J.; Ohanyan, M.; Goel, V.; Navasardyan, S.; Wei, Y.; Shi, H. VideoMatt: A Simple Baseline for Accessible Real-Time Video Matting. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Chu, L.; Liu, Y.; Wu, Z.; Tang, S.; Chen, G.; Hao, Y.; Peng, J.; Yu, Z.; Chen, Z.; Lai, B.; et al. PP-HumanSeg: Connectivity-Aware Portrait Segmentation with a Large-Scale Teleconferencing Video Dataset. arXiv 2021, arXiv:2112.07146. [Google Scholar]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ke, Z.; Li, K.; Zhou, Y.; Wu, Q.; Mao, X.; Yan, Q.; Lau, R.W. Is a green screen really necessary for real-time portrait matting. arXiv 2020, arXiv:2011.11961. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).