1. Introduction
Compressed sensing (CS) has gained prominence in signal processing due to its ability to reconstruct high-dimensional signals from significantly fewer measurements [
1]. This technique proves especially effective in scenarios where resources for data acquisition, such as bandwidth and storage, are constrained [
2,
3,
4,
5,
6,
7]. By exploiting the inherent sparsity or compressibility of signals, CS offers a structured approach to signal recovery applicable across various fields, including medical imaging, telecommunications, and industrial automation.
CS works in two main steps. First, during the sampling phase, a high-dimensional signal
is projected into a lower-dimensional measurement
(where
) using a sensing matrix
:
where
represents noise. In the second step, the goal is to recover
by solving an optimization problem that balances the accuracy of the data and the sparsity of the signal:
Here,
represents the transform basis, and
controls the trade-off between the reconstruction accuracy and sparsity.
Researchers have developed numerous algorithms to solve this problem. Methods like Orthogonal Matching Pursuit (OMP) [
8] and the Iterative Shrinkage-Thresholding Algorithm (ISTA) [
9] address the optimization efficiently in many cases. However, computational limitations and reduced accuracy at low sampling rates remain persistent challenges. Algorithms such as the Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) [
10] incorporate momentum-based updates to improve convergence speed, significantly enhancing scalability in large-scale settings.
The integration of deep learning with CS has introduced new possibilities. Hybrid frameworks combine traditional optimization methods with neural network-based models to achieve better performance. ISTA-Net [
11], for example, adapts ISTA into a trainable neural network, while ADMM-CSNet [
12] integrates alternating direction method of multipliers (ADMM) with deep learning for faster and more accurate results. Transformer-based approaches like TransCS [
13] utilize attention mechanisms to capture global dependencies effectively. Additionally, architectures based on generative adversarial networks (GANs) [
14,
15] have been employed to enhance image resolution and recover fine details.
Despite these advancements, computational complexity and trade-offs between speed and accuracy present ongoing difficulties. Transformer-based models, though capable of modeling global features, exhibit quadratic complexity in self-attention mechanisms, limiting their use in real-time applications. Lightweight designs, such as CSNet [
16], improve processing speed but often compromise reconstruction quality.
Alternative approaches have emerged to address these shortcomings. The Mamba architecture introduces a selective state-space model that captures local and global dependencies efficiently. Unlike Transformers, which rely on self-attention mechanisms with quadratic complexity , Mamba achieves linear complexity through a more computationally efficient design. This approach reduces processing overhead and enhances scalability, making it well suited for high-dimensional image data.
Inspired by Mamba’s efficient dependency modeling, this work combines its state-space modeling with the momentum-based optimization of FISTA. The resulting framework achieves faster convergence, improved accuracy, and enhanced adaptability across various reconstruction scenarios.
This study makes the following contributions:
A novel compressive sensing framework is proposed, integrating Mamba’s state-space modeling and FISTA’s optimization. This design removes the dependence on manually defined hyperparameters such as sensing matrices.
Improvements in computational efficiency and reconstruction accuracy are demonstrated, with reduced training and inference times.
Extensive evaluations across multiple datasets highlight the framework’s adaptability and robustness under varying sampling rates and noise levels.
The paper proceeds as follows:
Section 2 examines related works in CS and hybrid frameworks.
Section 3 describes the proposed framework in detail.
Section 4 presents experimental results and comparisons.
Section 5 concludes with an outlook on future research.
3. Methods
In this section, we present the proposed framework for efficient image reconstruction. The overall system pipeline is illustrated in
Figure 1. The framework consists of three primary components: the sampling module, the reconstruction module, and the loss function design. The sampling module compresses high-dimensional image data into compact measurements, which are then used by the reconstruction module to recover the original image. The reconstruction module includes both initial reconstruction and deep reconstruction stages, iteratively refining the output to achieve high-fidelity results. Finally, the loss function ensures the reconstruction accuracy by balancing fidelity, perceptual similarity, and structural consistency.
3.1. Sampling Module
The sampling module is designed to efficiently transform high-dimensional image data into compressed measurements while preserving essential structural information. Given an input image , where B represents the batch size and H, W denote the height and width, respectively, we propose a structured block-wise sampling approach that leverages learnable measurement matrices.
The foundation of our sampling mechanism is a learnable measurement matrix
, where
with
being the target compression ratio and
denoting the dimensionality of each block. The complete sampling process is detailed in Algorithm 1.
| Algorithm 1 Block-wise Adaptive Sampling Process |
- Require:
Input image - Ensure:
Compressed measurements - 1:
{Initialize measurement matrix} - 2:
- 3:
- 4:
- 5:
{Initialize reconstruction matrix} - 6:
{Block partitioning} - 7:
if or then - 8:
Apply padding operator - 9:
end if - 10:
- 11:
{Vectorization} - 12:
- 13:
{Measurement computation} - 14:
- 15:
return
|
The sampling process consists of three key transformations. Initially, we define a block partitioning operator
, where
N represents the total number of blocks. This operator decomposes the input image into non-overlapping blocks:
Subsequently, we employ a vectorization operator
that transforms each block into a vector representation:
The final transformation computes the compressed measurements through linear projection:
A key innovation in our approach is the simultaneous learning of a reconstruction initialization matrix
, initialized as
. This dual learning strategy enables joint optimization of the sampling and initial reconstruction processes, leading to the following objective:
where
represents our reconstruction network.
To handle inputs of any size, we use a padding operator to adjust the input to the nearest multiple of . After the experiments, we found that provides the best balance between speed and reconstruction quality. The adaptive sampling matrices and block-based processing help the framework capture important image features, while keeping the computation simple. This sampling module provides a strong foundation for reducing dimensionality efficiently while preserving critical image structures. It prepares the data for the reconstruction process, which is explained in the next section.
3.2. Reconstruction Module
3.2.1. Initial Reconstruction
The image signal is compressed into through the sampling module, and this is used as the input to the initial reconstruction, providing the preliminary estimate . This estimate forms the basis for subsequent refinement and optimization.
The process begins with a linear operation:
where
is initialized as the transpose of the sampling matrix
. Specifically,
, ensuring that the initial estimate aligns naturally with the compressed data.
To maintain stability and support effective training, the entries of
are drawn from a normal distribution:
where
m denotes the dimensionality of the compressed measurements. This initialization strategy promotes stable gradient flow during backpropagation and enables the model to learn meaningful reconstruction patterns.
When the dimensions of the input image do not align with the block size used in the sampling module, padding is applied to adjust the height (
H) and width (
W). The required padding values are determined as follows:
This adjustment ensures consistent processing of all image blocks and retains the spatial relationships present in the original image.
3.2.2. Deep Reconstruction
The initial reconstruction result
is used as input to the deep reconstruction module, where it is further improved through iterative optimization and advanced feature modeling. This stage combines momentum-based updates inspired by FISTA with multi-directional selective state-space modeling (SSM). Together, these techniques enable efficient and accurate recovery of high-dimensional image data from compressed measurements. The full process is described in Algorithm 2.
| Algorithm 2 Deep Reconstruction Process |
- Require:
Initial reconstruction , compressed measurements , sampling matrix - Ensure:
Final reconstructed image - 1:
Initialize , - 2:
for to L do - 3:
Compute momentum - 4:
Update intermediate state - 5:
Apply gradient correction - 6:
Pre-process features - 7:
Apply selective state-space modeling: - 8:
for each direction do - 9:
Compute state evolution - 10:
end for - 11:
Aggregate results - 12:
Post-process features - 13:
end for - 14:
Reshape final result - 15:
return
|
In each iteration l, the reconstruction follows these steps:
First, momentum-based acceleration is used to speed up convergence. The intermediate state
is updated as follows:
where
is a momentum factor initialized as
. This step incorporates information from previous iterations to ensure faster convergence and improved reconstruction quality.
Next, to maintain consistency with the compressed measurements
, a gradient descent step is applied to
:
where
is a learnable step size parameter. This correction minimizes the data fidelity term, aligning the reconstruction with the measurement constraints.
Before applying state-space modeling, a pre-processing network
is employed to enhance local image features:
where
is implemented as a series of convolutional layers designed to extract fine-grained image details.
The refined intermediate signal
is then processed using a multi-directional selective state-space model. This step captures both local and global dependencies by scanning the input in four directions: horizontal, vertical, main diagonal, and secondary diagonal. For each direction
r, the modeling is defined as
Here,
represents the state evolution matrix,
is the input projection matrix,
is a nonlinear activation function that ensures stability, and
is the adaptive time step for the
r-th direction. The outputs from all directions are combined as
After state-space modeling, a post-processing network
refines the reconstructed signal. This refinement is performed using
where
is a set of learnable convolutional layers designed to remove residual errors and improve the global structure of the signal.
Once
L iterations are complete, the final reconstructed signal
is reshaped into its original spatial dimensions:
where
is the reshaping operator.
This iterative process combines momentum-based optimization, feature extraction, and selective state-space modeling to achieve accurate and high-quality reconstruction. The integration of learnable parameters and adaptive strategies allows the model to handle diverse image structures and varying compression conditions effectively, ensuring both efficiency and accuracy.
3.3. Loss Function
To ensure accurate and high-quality reconstruction, we design a loss function that balances pixel-wise fidelity, perceptual quality, and structural consistency.
The MSE loss ensures pixel-wise accuracy by minimizing the
norm between the reconstructed image
and the ground truth
:
where
N is the total number of pixels.
To improve perceptual quality, the SSIM loss measures structural similarity between
and
:
where
captures luminance, contrast, and structure.
The edge gradient loss enhances edge preservation by penalizing differences in image gradients:
where
and
represent horizontal and vertical gradient operators, respectively.
Finally, the total loss integrates these components, balancing their contributions with weighting factors
and
:
This comprehensive loss function ensures faithful reconstruction while preserving structural details and perceptual quality, enabling the model to achieve robust and high-quality results.
4. Experimental Results
4.1. Experimental Settings
The training and evaluation of SSM-Net use a variety of datasets, including satellite imagery, urban environments, natural scenes, and high-resolution images. The primary training process relies on the BSD500 dataset [
37], which consists of 200 training images, 100 validation images, and 200 testing images. From each training image, 200 patches of size
pixels are extracted, resulting in a total of 100,000 training samples. Data augmentation methods, such as bidirectional flips, rotations, and scaling, are applied to increase image diversity.
To evaluate performance, several benchmark datasets are selected, each addressing specific challenges in image reconstruction:
(1) UCMerced Land Use Dataset: This dataset includes 21 land-use classes, each containing 100 images at a spatial resolution of 0.3 m. The dataset evaluates how well the model processes and distinguishes diverse land cover patterns.
(2) Urban100 [
38]: This high-resolution dataset focuses on urban architecture and building facades. It tests the model’s ability to capture detailed structural features in dense urban environments.
(3) BSD100 [
39]: A dataset of natural scene images, which features a range of terrain types and vegetation patterns. It provides insight into the model’s generalization capabilities across varied natural landscapes.
(4) Set5 [
40]: This benchmark dataset contains high-resolution images designed to evaluate the reconstruction of fine-scale features. It is particularly useful for scenarios where precise detail recovery is critical.
Each dataset presents unique challenges, offering insights into the model’s behavior under different conditions. These datasets also serve as standardized benchmarks, enabling direct comparisons with existing methods such as ISTA-Net+, Csformer [
41], AMP-Net, CPP-Net [
42], and TransCS. By incorporating diverse structural patterns, textures, and details, the evaluation framework ensures a rigorous assessment of reconstruction performance. The observed results reflect the model’s ability to adapt to various image characteristics, confirming its effectiveness in reconstructing high-quality images under challenging conditions.
All experiments were conducted using PyTorch 1.9.0 on a machine equipped with an Intel® Xeon® 8336 CPU and a GeForce RTX 4090 GPU. To ensure fair comparison, all competing models were trained using the same BSD500 dataset and evaluated under identical conditions across all test datasets.
4.2. Comparisons with State-of-the-Art Methods
Table 1 presents comprehensive quantitative comparisons between SSM-Net and current state-of-the-art methods across four benchmark datasets (UCMerced, Set5, Urban100, and BSD100) at various sampling rates (
). The sampling rate
is defined as the ratio between the number of measurements
M and the total number of pixels in the image
N. Specifically, we define the sampling rate as
This sampling rate controls how much of the image is used during the reconstruction process, with lower values of corresponding to higher levels of compression. The experimental results demonstrate that SSM-Net achieves competitive or superior performance compared to existing approaches.
On the UCMerced dataset, which consists of satellite remote sensing imagery, SSM-Net demonstrates competitive performance particularly at lower sampling rates. At , our method achieves a PSNR of 25.28 dB and an SSIM of 0.6959, outperforming both CSformer (25.21 dB/0.6957) and TransCS (25.18 dB/0.6950). The advantage is more pronounced at , where SSM-Net achieves 29.53 dB PSNR and 0.8449 SSIM, surpassing TransCS (29.41 dB/0.8412) and CSformer (29.47 dB/0.8437). At , our method achieves the highest PSNR of 34.71 dB among all compared methods, demonstrating its particular effectiveness in medium-rate compression scenarios for remote sensing applications. While the performance shows some limitations at very high sampling rates (), the strong results in the critical low-to-medium sampling rate range highlight SSM-Net’s practical value for bandwidth-constrained remote sensing scenarios where efficient compression is most needed.
For the Set5 dataset, SSM-Net demonstrates superior performance across the full range of sampling rates. At lower rates ( and ), our method achieves 23.37 dB and 29.32 dB PSNR, respectively, outperforming TransCS (22.98 dB and 29.02 dB). This advantage is maintained through medium rates ( and ) with PSNRs of 37.61 dB and 38.74 dB, and extends to higher rates ( and ) reaching 41.81 dB and 42.72 dB, consistently surpassing both TransCS and CSformer across all compression levels.
In the Urban100 dataset, which contains complex urban structures, SSM-Net shows balanced performance across different sampling rates. While slightly lower than TransCS at (19.18 dB vs. 19.53 dB), our method demonstrates competitive results at medium rates ( and ) with PSNRs of 30.78 dB and 31.21 dB, and achieves superior reconstruction at higher rates ( and ) with values of 33.34 dB and 34.93 dB, respectively, demonstrating particular effectiveness in preserving architectural details.
On the BSD100 dataset, featuring diverse natural landscapes, SSM-Net exhibits strong performance across sampling rates, with notable advantages at medium to high rates. Starting from with 27.60 dB PSNR, our method shows progressive improvement through and (31.45 dB and 32.79 dB), culminating in strong high-rate performance at and (34.96 dB and 36.89 dB). This consistent scaling demonstrates our method’s effectiveness in handling varied natural textures across different compression levels.
Table 2 further shows the WS-PSNR and MSSIM comparisons of different image reconstruction methods on the UCMerced, Set5, Urban100, and BSD100 datasets at various sampling rates (
). The results show that SSM-Net can achieve the current state-of-the-art performance on various datasets and sampling rates.
Figure 2 demonstrates the reconstruction results for satellite sensing images. As shown in the detailed regions (highlighted by red boxes), SSM-Net achieves superior reconstruction quality with PSNR/SSIM values of 33.41/0.8443 and 33.32/0.9192 for different sampling rates, effectively preserving both global structure and fine details in remote sensing imagery.
Figure 3 provides additional visual comparisons for high-resolution images. The results show that SSM-Net better preserves fine textures and sharp edges, achieving PSNR/SSIM values of 31.55/0.8896 and 35.42/0.9753 for different test cases. This visual quality improvement aligns with the quantitative metrics, confirming our method’s effectiveness in maintaining both structural integrity and local details.
These comprehensive results demonstrate that SSM-Net has achieved state-of-the-art performance, consistently matching or exceeding existing methods across different datasets and sampling rates. The balanced performance across various scenarios, particularly in remote sensing applications, validates our approach of combining momentum-based optimization with efficient feature modeling through the Mamba architecture.
4.3. Noise Robustness Analysis
We evaluate our method’s robustness against measurement noise using the BSD100 dataset. Our experiments introduce Gaussian noise with different variances at various sampling rates (
).
Table 3 presents the quantitative comparisons between SSM-Net, AMP-Net, and Csformer under these conditions.
SSM-Net consistently outperforms the competing methods across all noise levels and sampling rates. At low noise (), our method achieves higher PSNR values than both AMP-Net and Csformer, with improvements of up to 0.95 dB at . This advantage remains evident at higher noise levels (), where SSM-Net maintains better reconstruction quality with PSNR values of 22.74 dB, 24.31 dB, and 26.06 dB at sampling rates of 0.04, 0.10, and 0.25, respectively.
The visual comparisons in
Figure 4 further demonstrate our method’s superior noise handling capabilities. SSM-Net preserves more image details and produces cleaner reconstructions compared to AMP-Net and Csformer, particularly in challenging cases with both high noise levels and low sampling rates. These results confirm that our approach offers enhanced stability and reconstruction accuracy in noisy conditions.
4.4. Training Convergence Rate Analysis
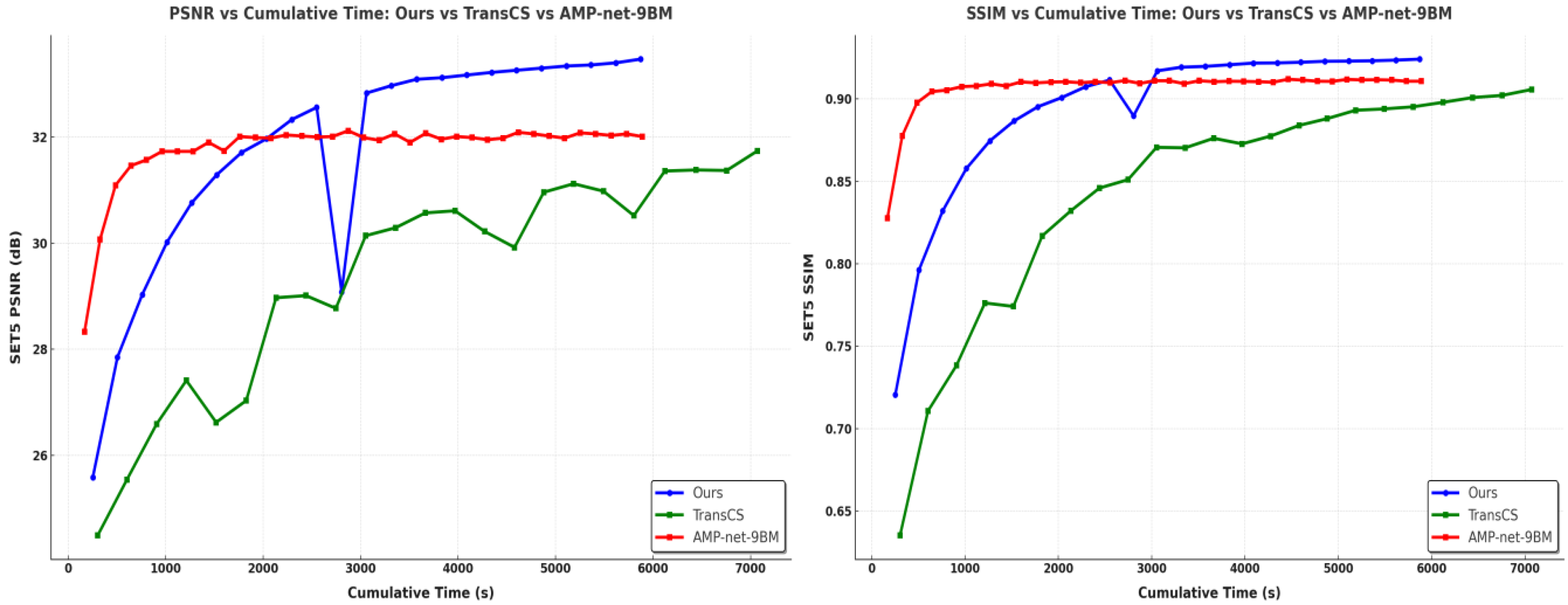
We analyze the training convergence speed by comparing the PSNR and SSIM curves of different methods during the training process, as shown in
Figure 5. The curves are obtained by evaluating performance on the validation set during training iterations.
Our SSM-Net achieves faster convergence compared to TransCS, reaching stable PSNR and SSIM values within approximately 3000 s. In contrast, TransCS requires nearly 5000 iterations to achieve comparable performance levels. While AMP-Net converges slightly faster, reaching stability at around 2000 s, its final reconstruction quality is notably lower than that of SSM-Net. For example, at sampling rate , SSM-Net achieves a dB PSNR improvement over AMP-Net after convergence.
The rapid convergence of SSM-Net can be attributed to two factors: the momentum-based optimization strategy from FISTA and the efficient feature modeling of the Mamba architecture. Specifically, FISTA optimizes the training process by incorporating momentum, which accelerates convergence by utilizing information from previous gradients. This allows the model to make larger, more accurate updates during training, speeding up the process and improving performance.
The Mamba architecture, in contrast to the Transformer-based models, improves convergence by modeling both local and global feature dependencies efficiently. Transformers, while highly effective at capturing global relationships, require extensive computational resources due to their self-attention mechanism, which scales quadratically with the image size. Mamba’s state-space modeling (SSM) addresses this challenge by representing dependencies in a more compact and efficient manner, reducing computational complexity. By utilizing SSM, Mamba effectively captures long-range dependencies without the heavy computational burden typical of Transformers, leading to faster convergence and better performance in terms of both quality and efficiency.
The sudden drop observed in the blue curve (representing SSM-Net) around 2000 s is a notable point. This drop can be explained by the dynamic adjustments the model makes during training. It likely occurs due to the optimization algorithm adapting to the more challenging aspects of the data as the training progresses, where certain features or structures in the image require fine-tuning. This brief decrease is followed by rapid recovery, indicating that the model’s optimization strategy is robust enough to handle such challenges, and it stabilizes quickly. This behavior highlights the balance between exploration and fine-tuning during training, which is an essential aspect of the learning process.
Thus, the combination of FISTA’s momentum-based optimization and Mamba’s state-space modeling contributes significantly to the fast convergence of SSM-Net. The architecture’s efficiency in modeling dependencies and its ability to quickly adapt to complex image features ensure that the network converges faster while maintaining high reconstruction quality.
4.5. Complexity Analysis
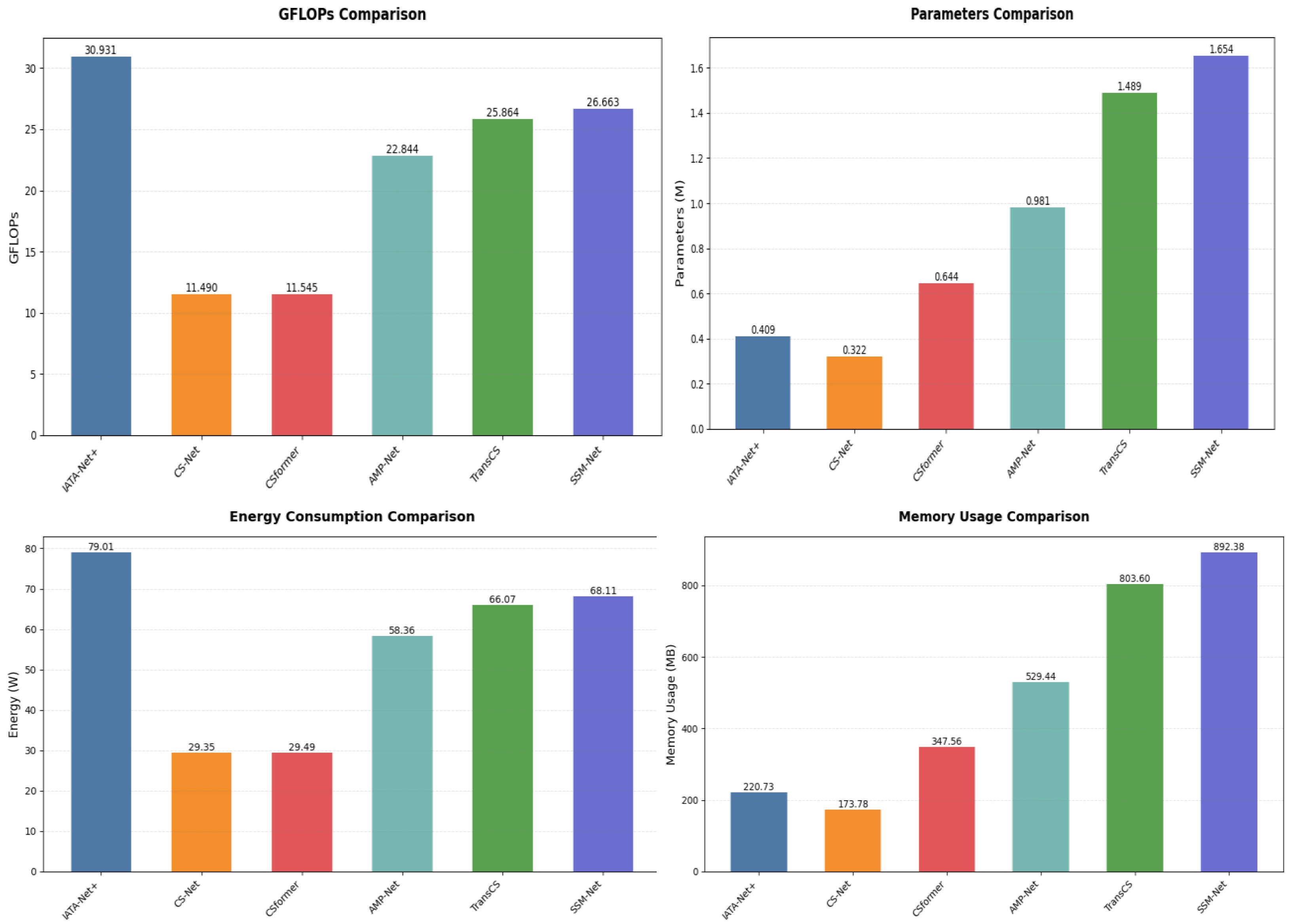
We analyze the computational complexity of SSM-Net compared to existing methods. All experiments use a standard input size of pixels and sampling rate .
As shown in
Figure 6, SSM-Net requires 26.6626 GFLOPs (billion floating-point operations), which falls between lightweight models like CSNet (11.49 GFLOPs) and heavier models like ISTA-Net+ (30.931 GFLOPs). The parameter count of SSM-Net is 1.654 M, similar to that of TransCS (1.489 M). This moderate computational cost enables SSM-Net to achieve superior reconstruction quality while maintaining reasonable efficiency. In terms of energy consumption, SSM-Net requires 68.11 W, which is higher than lightweight models such as CSNet (29.35 W) and CSformer (29.49 W), but still more efficient than models like ISTA-Net+ (79.01 W). Similarly, SSM-Net’s memory usage stands at 892.38 MB, which is significantly higher than CSNet’s 173.78 MB and CSformer’s 347.56 MB, but lower than TransCS (803.60 MB) and ISTA-Net + (220.73 MB). These values highlight the trade-off between higher model performance and the increased computational cost in terms of energy consumption and memory usage.
Table 4 shows inference time comparisons on an RTX 4090 GPU. SSM-Net consistently processes images in approximately 0.0202 s across different sampling rates. This stable processing time demonstrates better scalability compared to methods like CSformer, which shows increasing inference times from 0.0469 to 0.0486 s at higher sampling rates. While CSNet achieves faster inference (0.0078–0.0099 s), it produces lower-quality reconstructions as shown by the PSNR results.
The efficiency of SSM-Net comes from the linear complexity of Mamba’s state-space model and FISTA’s momentum-based optimization. These components work together to provide fast convergence without excessive computational demands. The results show that SSM-Net balances computational cost and reconstruction quality effectively, offering strong performance while maintaining practical processing speeds.
4.6. Ablation Studies
Figure 7 and
Table 5 show the results of the ablation study, which evaluates the impact of removing the FISTA algorithm and the Mamba module on image reconstruction quality and computational efficiency. We compare three configurations: SSM-Net (full model), without FISTA, and without Mamba, as well as Mamba replaced with Transformer.
Removing the FISTA algorithm results in a significant reduction in reconstruction quality. At , the PSNR drops from 30.78 dB (SSM-Net) to 27.85 dB (without FISTA), while the runtime improves slightly to 0.0180 s per image. This demonstrates that FISTA is crucial for enhancing both the quality and convergence of the reconstruction.
Similarly, removing the Mamba module also significantly degrades the performance. At , the PSNR decreases from 30.78 dB (SSM-Net) to 28.47 dB (without Mamba). The model also suffers from a loss of important global and local feature modeling, which is essential for high-quality reconstruction. The runtime remains competitive at 0.0184 s per image, but this speed comes at the expense of a noticeable loss in PSNR.
In contrast, the complete SSM-Net model achieves the best balance between reconstruction quality and computational efficiency. At , SSM-Net delivers a PSNR of 30.78 dB, while the runtime is 0.0204 s per image. This shows that the Mamba module plays a key role in improving the reconstruction quality without introducing significant computational overhead.
Finally, replacing Mamba with Transformer brings the PSNR closer to the performance of SSM-Net, reaching 30.12 dB at , compared to 28.47 dB without Mamba. However, the computational time increases significantly to 0.024 s per image. This indicates that although the Transformer configuration achieves PSNR values near SSM-Net, it incurs a substantial increase in runtime due to the quadratic complexity of attention mechanisms, making it less efficient than SSM-Net.
The ablation study demonstrates the critical role of both the Mamba module and FISTA in improving the reconstruction quality. Removing the Mamba module reduces the model’s ability to capture global and local dependencies, as evidenced by the significant drop in PSNR. This shows that Mamba’s capability to model these dependencies is essential for preserving fine image details.
In contrast, FISTA optimization enhances the reconstruction process by accelerating convergence and refining the image quality. When FISTA is removed, the network’s reconstruction is slower, and the model struggles to reach the same level of accuracy. This is reflected in the lower PSNR of “without FISTA” compared to SSM-Net, particularly at higher compression rates, where FISTA’s optimization is most beneficial.
These comparisons clearly demonstrate the benefits of the full SSM-Net model. Removing FISTA or Mamba degrades both the quality and efficiency of the model, while the Transformer-based alternative, although offering PSNR values close to those of SSM-Net, suffers from a substantial increase in runtime. This underscores the importance of Mamba in maintaining high-quality reconstruction with minimal computational cost.
5. Conclusions
In this paper, we propose SSM-Net, a new framework for efficient remote sensing image reconstruction based on SSM and deep unfolding techniques. The framework integrates a sampling module for efficient data compression, an initial reconstruction module for fast signal estimation, and a deep reconstruction module that iteratively refines the results. By leveraging FISTA-inspired momentum updates and selective state-space modeling, SSM-Net achieves a balance between reconstruction accuracy, computational efficiency, and fast training convergence.
Comprehensive experiments on standard benchmark datasets demonstrate that SSM-Net offers competitive performance in terms of PSNR and SSIM while maintaining a lightweight architecture and computational efficiency. Although the training process exploits natural image datasets, the framework exhibits strong generalization potential for remote sensing scenarios. Its modular design ensures adaptability and scalability, making it a practical solution for real-world remote sensing applications where storage and transmission constraints are critical.
Looking ahead, we aim to further optimize the proposed framework by incorporating ideas from the Mamba-2 model, particularly the selective state-space decoding SSD methodology. The SSD concept introduces more effective ways of modeling spatial dependencies, which can potentially enhance reconstruction accuracy and robustness. Additionally, we plan to explore domain-specific adaptations of SSM-Net by fine-tuning the framework on large-scale remote sensing datasets, including hyperspectral and SAR images. These advancements will further extend the applicability of SSM-Net, paving the way for its deployment in practical remote sensing systems.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}