1. Introduction
In recent years, cyber-physical systems (CPSs) have achieved fruitful results in the research field and have found extensive applications in domains including military defense, intelligent transportation, and smart grids [
1,
2,
3,
4,
5]. However, due to the involvement of numerous critical infrastructures, any attack on CPSs can result in severe losses. With the emergence of various sophisticated intrusion techniques, attackers can disrupt network systems in a short period [
6,
7,
8,
9]. Major security incidents worldwide have highlighted the importance of CPS security issues. For example, in 2018, GitHub experienced 1.35 Tbps delayed traffic, leading to a 10 min service interruption; in September 2021, the Russian internet giant Yandex suffered a large-scale Distributed Denial of Service (DDoS) attack with requests per second reaching up to 21.8 million [
10]. Therefore, with the rapid development of CPSs, the identification and prevention of network security intrusions have become particularly crucial.
In the literature [
11,
12,
13], researchers have discussed the optimal power scheduling problem for Denial of Service (DoS) attacks based on Signal-to-Interference-plus-Noise Ratio (SINR) in CPSs, considering energy constraints of sensors and attackers. Li et al. [
11] simulated the interaction decision-making process between sensors and attackers by establishing a Markov game framework. Ref. [
12] proposed a Stackelberg Equilibrium (SE) framework to examine the strategic interaction between defenders and attackers in situations involving two distinct forms of incomplete information. Additionally, ref. [
13] delved into a Stackelberg game involving a defender and multiple attackers. Distinguishing itself from the existing literature, which predominantly centers on equilibrium in static games, this study also reflects the dynamic process of Stackelberg games, demonstrating the intelligence of attackers in switching channel allocation for attack energy.
To ensure the security and reliability of network system resources, real-time monitoring of network transmissions is necessary to maintain confidentiality, integrity, and availability. The research in [
14,
15,
16,
17,
18,
19,
20,
21,
22] proposes attack detection methods tailored to the constructed attack models, highlighting the existence of trade-off thresholds. In particular, the work in [
19] designed a replay attack detection framework based on model-free reinforcement learning to effectively deal with attackers purposefully changing attack strategies. Furthermore, Agah et al. proved through a game theory framework that a Nash equilibrium is reached between attackers and Intrusion Detection System (IDS) [
20]. In another study [
22], a game-theoretic intrusion detection and defense method for DDoS attacks on the internet was proposed, modeling the interaction between the system and entities as a two-player Bayesian signal zero-sum game. These studies hold significant theoretical and practical value within the realm of network security, offering invaluable perspectives and solutions for real-time monitoring of network transmissions and the security of network system resources.
A Denial of Service (DoS) attack is a type of cyberattack where a single attacker floods a target system with excessive traffic or requests, aiming to overwhelm its resources and make it unavailable to legitimate users. The attack is typically launched from a single machine or a small number of machines [
23,
24,
25,
26,
27,
28]. A Distributed Denial of Service (DDoS) attack is a more advanced form of a DoS attack, where multiple compromised systems (often referred to as a “botnet”) are used to flood the target system with traffic. The distributed nature of the attack makes it much harder to defend against, as the traffic comes from many different sources, making it difficult to block all incoming connections without affecting legitimate users [
6,
29]. In most literature, Nash Equilibrium (NE) is commonly used to describe game situations where participants simultaneously choose actions. However, when decisions of defenders and attackers are made sequentially, the Stackelberg game framework is better suited to elucidate this procedure [
12,
30].
Although traditional DDoS attacks typically occur at the network layer, such as by flooding target servers with a large number of packets, physical layer attacks pose a significant threat in wireless sensor networks (WSNs). The open and interference-prone nature of wireless channels allows attackers to disrupt sensor node communications by transmitting high-power wireless signals, leading to degraded signal quality and even complete communication outages. Studies have shown that high-power interference can significantly reduce the signal-to-noise ratio (SINR) at the receiver, causing communication interruptions [
31]. Additionally, physical layer attacks possess characteristics such as strong stealth and high energy efficiency, enabling attackers to achieve significant disruption with minimal energy expenditure [
32]. To address this challenge, this study assumes that the attacker primarily influences system performance through physical layer interference. This assumption is supported by multiple studies that highlight the effectiveness of physical layer attacks in WSNs, especially under conditions of limited energy resources [
33].
Unlike existing research, which typically assumes a static network environment and symmetric information between attackers and defenders [
13,
21], our study introduces dynamic channel changes, transmission costs, and the signal-to-interference-plus-noise ratio (SINR) into a Stackelberg game framework. This approach provides a more realistic simulation of real-world attack and defense scenarios. Additionally, our IDS uses remote state estimation for more precise detection, offering a clear advantage over traditional feature or anomaly-based methods. By considering energy constraints, environmental background noise, and time factors, we have developed a multi-stage Stackelberg game model that better reflects actual attack and defense interactions. These innovations significantly enhance system security and robustness, providing new theoretical and technical support for the field of wireless network security. The primary contributions of this research are outlined as follows:
Optimal energy scheduling under Distributed Denial of Service (DDoS) attack: The optimal energy scheduling problem is modeled in consideration of channels’ Signal-to-Interference-Noise Ratio (SINR) and transmission cost under Distributed Denial of Service (DDoS) attack. In the absence of an Intrusion Detection System (IDS), profit functions for the attacker and defenders are provided. To find the optimal solution, an improved differential evolution algorithm based on Adaptive Penalty Function (APF) is used to address the corresponding non-linear and non-convex optimization problems. Remote state estimation-based Detection System (IDS): We design an Intrusion Detection System (IDS) at the receiver end based on remote state estimation, using Packet Reception Rate (PPR) as the intrusion detection criterion. Unlike traditional feature- or anomaly-based methods [
12,
13], this approach is more suitable for real-world applications. Experimental results demonstrate that the presence of IDS can reduce the attacker’s profit and increase the defender’s profit. Multi-stage Stackelberg game model: A multi-stage Stackelberg game model is constructed to deal with the optimization problem, considering energy constraints of attacker and defenders, defenders’ awareness of environmental background noise, and introducing a time factor to build a finite-time Stackelberg game model. Compared to existing game models [
12,
13], our model better reflects the dynamic interactions between attackers and defenders, providing a more complex and realistic description of the attack and defense process. This new model offers valuable insights into developing effective defense strategies.
Notations: and represent the n-dimensional and m-dimensional Euclidean space. and represent the sets of natural numbers and nonnegative integers, respectively. The superscript denotes transpose. The symbols and represent the probability and expectation. is the aggregation of positive semidefinite matrices. is defined as for vectors x and y. . presents the spectral radius of a matrix. For any two functions f and g, their composition is defined as .
2. Model Setup
2.1. Process and Sensor Model
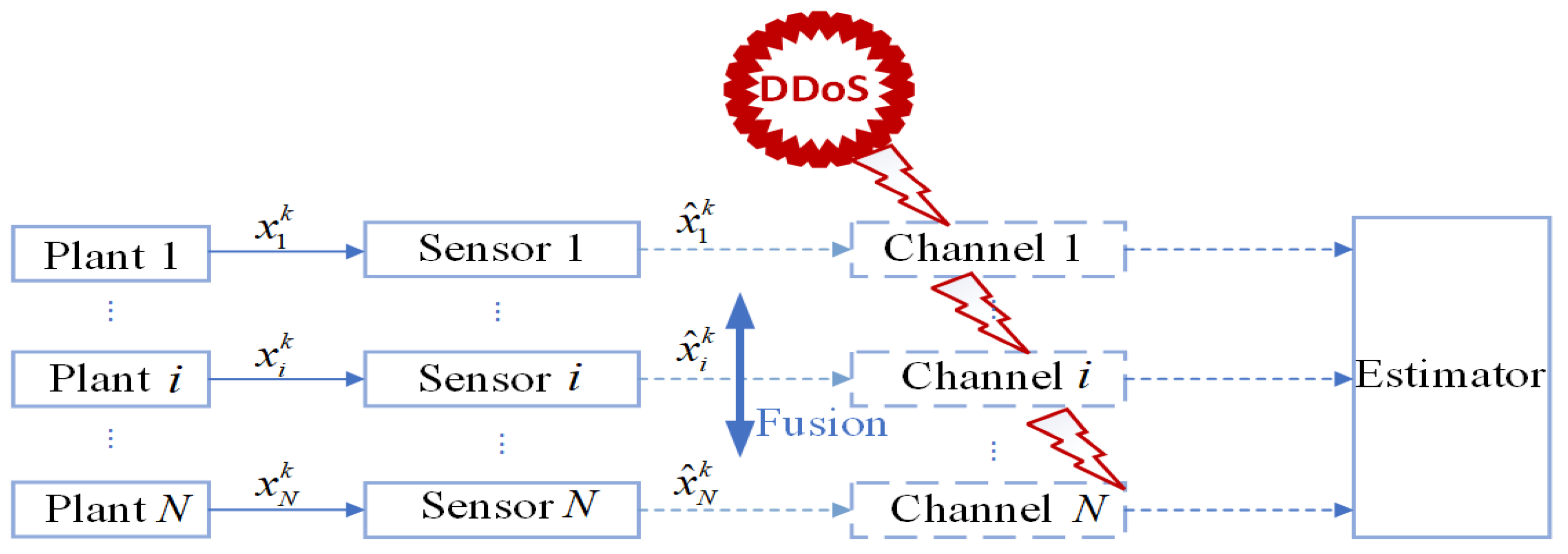
We consider discrete linear systems with multiple sensors as shown in
Figure 1, consisting of a total of
N independent discrete-time linear time-invariant systems and
N sensors. The
i-th sensor monitors the
i-th system as follows:
where
, the time index
.
is the state transition matrix, where
is the dimension of the state vector
.
is the observation matrix, where
is the dimension of the observation vector
.
and
are independent zero-mean Gaussian white noises, satisfying
,
,
, the covariance
,
,
. The initial state
is a zero-mean Gaussian random vector with covariance
, which is uncorrelated with
and
. To avoid trivial issues, we assume that the system is unstable, i.e.,
,
. We assume that
is observable, and
is controllable.
We assume that the sensors are “smart” and have sufficient computational capabilities. Following the measurement of the respective system at time step
k, every sensor initiates a local Kalman filter to gauge the state of the process, incorporating all amassed measurements up to time
k [
34]. Subsequently, each sensor forwards its local estimate to a remote estimator. Based on the local estimate of the current state, we can calculate the minimum error estimate
of the local state of the
i-th subsystem and the corresponding estimate error covariance matrix
:
Computed by standard Kalman filtering [
35]:
We further define the Lyapunov operator and Riccati operators
and
:
:
where ∘ denotes the
k-fold composition of the function
, i.e., the function
applied consecutively
k times.
is an
symmetric positive semi-definite matrix, representing the system’s covariance matrix or the estimation error covariance matrix.
The local estimate error covariance
converges to a steady-state value at an exponential rate. Therefore, we make the assumption:
where
is the unique positive semi-definite solution to
.
2.2. Communication Model with SINR
After receiving the data packet, sensor
i obtains a local estimate
, which is then sent to the data fusion center through a wireless lossy channel. Due to channel attenuation and interference effects, random data loss occurs. To simulate this scenario, we assume that the channel uses an Additive White Gaussian Noise (AWGN) channel with Quadrature Amplitude Modulation (QAM) [
11]. Subsequently, utilizing digital communication theory reveals the relationship between Symbol Error Rate (SER) and signal-to-noise ratio (SNR) [
24]:
where
is a parameter.
SNR can be described as:
where
is the fading channel gain for channel
i,
is the background noise,
represents the transmission power allocated by sensor
i to channel
i at time
k,
is the correlation coefficient between channels
i and
j.
We assume that DDoS attacks primarily occur at the physical layer, where the attacker interferes with sensor node communications by transmitting high-power wireless signals. If considering a DDoS attack on channel
i, the SNR should be modified to the signal-to-interference-plus-noise ratio (SINR) as follows:
where
is the fading channel gain for the attacker on channel
i, and
represents the transmission power allocated by the attacker to channel
i at time
k. Additionally, for sensors and attackers, the cost of transmitting unit power is assumed to be
and
, respectively. In CPSs, wireless channels are susceptible to external interference. Attackers can significantly reduce the SINR at the receiver by increasing the transmission power
, thereby impacting the system’s performance.
2.3. DDoS Attack
Distributed Denial of Service (DDoS) attacks can block communication between components of cyber-physical systems (CPSs), thereby reducing the overall system performance. In current research, the attacker weakens system performance by continuously invading and maliciously disrupting communication channels. In real-life scenarios, energy constraints are an unavoidable issue for both sensors and attackers, impacting the performance of remote estimation and the strategies of both sides. Due to the presence of energy constraints, sensors need to manage energy efficiently to prolong their operational time, while attackers may exploit this limitation to design more destructive attack strategies. Therefore, when designing and deploying remote estimation systems, considering energy constraints is crucial for system stability and security. Attackers can use noise to interfere with communication channels between sensors and the fusion center.
In practical applications, both the defender and the attacker can estimate each other’s power levels by monitoring Channel State Information (CSI) or through other methods such as historical data analysis and predictive models [
36,
37]. Therefore, we assume that at time
k, the defender knows the total power of the attacker is
, and the attacker knows the total power of the defender is
Here,
represents the total power of the attacker across all channels at time
k, while
represents the total power of the defender across all channels at time
k. On channel
i, the total power of the attacker and the defender over the time horizon
T is denoted as
and
, respectively, where
. Within the entire time range
T, the total power of the attacker and the defender across all channels is denoted as
and
, respectively, where
.
In practical applications, attackers face energy budget constraints and therefore need to carefully decide whether to launch the DDoS attack on the wireless channel at each sampling instant. This strategic decision involves balancing the impact of the attack with energy expenditure. Attackers may formulate attack strategies based on system performance metrics, communication requirements, and their own energy resources. By effectively managing energy budgets and strategically timing attack, attackers can maximize the impact on the performance of remote estimators while ensuring their ability to sustain attack behavior. We use to represent the attacker’s attack on channel i at time k; otherwise, . Within a finite time domain T, the i-th communication channel suffers a DDoS attack denoted by , . If , then ; if , then . Within the time domain T, assuming the DDoS attacker applies constant interference power on the i-th communication channel, when the constant power is given, we can determine the total number of attacks on channel i within the time range T as .
Therefore, the attacker’s attack strategy
can be represented as:
The energy constraint faced by the attacker is:
where
and
represent the lower and upper power limits of
, respectively.
Similarly, we use to represent the i-th sensor selecting to transmit a data packet at time k; otherwise, . Within a finite time domain T, the i-th sensor sends data packets denoted by , . If , then ; if , then . Assuming the i-th sensor maintains a constant transmission power within the time domain T, when the constant power is given, we can determine the total number of data packets sent by the i-th sensor within the time range T as .
Therefore, the sensor’s transmission strategy
can be represented as:
The energy constraint faced by the sensor is:
where
and
represent the lower and upper bounds of the transmission power
, respectively.
2.4. Remote Estimation with a Lossy Channel
In each time step
k, sensor
i transmits its result from the local Kalman filter
to a fusion center through a lossy communication channel. Let
represent whether the data packet is received by the fusion center without errors. If it is successfully received,
; otherwise,
. When an attacker launches an attack and blocks the channel, sensor data packets are received with a probability
. Assume that
follows a Bernoulli distribution and
Using
to represent all the data packets received by the remote estimator at time step
k, the remote estimator estimates the minimum mean square error
and covariance
of the remote end based on the received
, as follows:
If
is successfully received, it is used to estimate
; otherwise, the estimator forecasts the estimate using its prior estimate and the system model. Therefore, the minimum mean square error
and covariance
obtained by the remote estimator can be derived as follows:
At time k, can only take values from a finite set , where satisfies .
Therefore, we can represent the expected error covariance as:
4. Stackelberg Game for the Optimization Problem
The Stackelberg game is an important model in game theory. It describes a game process between a leader and a follower, where the defender, as the leader, formulates a strategy first, and the attacker reacts after observing the defender’s strategy. Both parties can formulate their own optimal strategies by analyzing the best response of the other party, and thus engage in a repeated game process, gradually approaching an equilibrium point. Under conditions of incomplete information, both parties need to infer the possible behaviors of the other party based on known information and probabilities, in order to formulate the optimal strategy. The elements of the Stackelberg game framework outlined in this paper are as follows:
Players: N sensors and a Distributed Denial of Service (DDoS) attack.
Strategy: The strategies of the defender and attacker are, respectively, and .
Reward: The reward function of the defender is , and the reward function of the attacker is .
Interaction: A continuous-time two-stage dynamic game. First, the defender makes a decision as the leader, and then the attacker makes their own decision based on the defender’s decision, and so on.
We define the best responses of both sides in the game as follows [
38].
Definition 1. The best response is the action that brings the maximum return to a player while taking into account the actions of the other players. Specifically, the best responses for the defender and attacker are and , respectively.
Theorem 1. The solution of the Stackelberg game first involves calculating:then computingThus, represents the equilibrium solution of the Stackelberg game. Proof. When the defender’s defense strategy
is given, the attacker chooses the attack strategy as
. The defender is aware of this reaction from the attacker, so the defender will choose a corresponding defense strategy to maximize their payoff
, which can be represented as:
Upon observing the defender’s strategy
, the attacker responds accordingly to determine the optimal strategy
:
Proof completed. □
Remark 2. The Stackelberg equilibrium and the Nash equilibrium have significant differences. In the Stackelberg model, the leader first chooses the strategy , and then the follower selects the optimal response based on the leader’s strategy. This sequential decision making mechanism allows the leader to optimize global performance, maximize the system’s total utility, and enhance security. In contrast, in the Nash equilibrium, all participants choose their strategies simultaneously, with each participant’s strategy considering only their own interests, which can lead to suboptimal solutions, especially in cases of conflict or competition. Additionally, the Stackelberg model typically offers better stability and predictability, making it suitable for long-term planning and global optimization scenarios. On the other hand, the Nash model may exhibit higher short-term utility in environments with high information transparency and ideal market conditions, but it tends to be less stable in dynamic and complex environments. The Stackelberg equilibrium must satisfy the following conditions: Considering the conditions that need to be met in problem 1, we design the attacker’s best response through the following optimization problem:
Problem 2. which is equivalent to the following problem: Problem 3. Then, by calculation, we can obtainand The results indicate that when and , we have . Clearly, for all , we have . The attacker can observe the defense strategy chosen by the defender; therefore, they only launch attacks upon detecting the transmission of sensor data to save energy. We assume that at time k, if , then ; if , then , where , ψ denotes the number of . Therefore, (36) can be solved through the following convex optimization problem:
Theorem 2. If the defender’s strategy is θ, then the attacker’s best response can be calculated by the following formula:where is obtained from the following equation: Proof. We define the Lagrangian function at each time point
k as:
where
,
,
,
,
. Thus, the Karush–Kuhn–Tucker (KKT) conditions can be represented as:
Through Equations (44) to (52), we systematically verify each part of the KKT conditions. Equation (44) ensures that the gradient of the objective function, when combined linearly with the Lagrange multipliers of all constraints, is zero, thereby satisfying the stationarity condition. Equations (45) to (49) ensure that all primal feasibility and dual feasibility conditions are met, including constraints such as energy limits and transmission power limits. Equations (50) to (52) utilize the complementary slackness conditions to determine which constraints are active, i.e., which constraints are binding at the optimal solution, where
Define
. Therefore, the relationship between
and
is given by (41). □
Remark 3. It should be noted that is crucial for designing the optimal strategy and the parameters should be computed first. However, since is not easily computable, we provide Algorithm 1 to solve for it.
| Algorithm 1 Calculating parameter |
- 1:
Calculate - 2:
Sort : - 3:
Find such that , where - 4:
if , then
|
The defender’s best response can be obtained by solving the following optimization problem:
where
.
Theorem 3. If is given, then there exists , so the defender’s best strategy can be . After obtaining , Algorithm 2 can be used to calculate . Therefore, is the Stackelberg equilibrium.
| Algorithm 2 APF-based Differential Evolution |
- 1:
Construct adaptive penalty function: where , , - 2:
Initialize: represents an N-dimensional variable, where and G is the generation. Choose , where , and . - 3:
Variation: Generate variogram vector, as follows: , where and , and the adaptive mutation operator F can be given by , where . represents the maximum generation. - 4:
Crossover: Denote , If , else where is crossover operator, and is a sequence selected randomly.
|
To obtain the defender’s strategy, the optimization problem (54) needs to be solved. However, due to the nonlinearity and possible non-convexity of the reward function
, solving (54) is not easy. This paper combines the Adaptive Penalty Function (APF) method and the Differential Evolution Algorithm to handle related non-convex and nonlinear optimization problems [
39]. Algorithm 2 details the main steps of the Differential Evolution algorithm based on APF. Differential Evolution (DE) is an efficient global optimization algorithm suitable for nonlinear, non-convex, and multimodal problems. Artificial Potential Field (APF) is a path-planning method that quickly finds feasible paths using potential fields. By combining DE and APF, we leverage DE’s global search capabilities to find the global optimum and APF’s local guidance to speed up convergence. This integration enhances optimization efficiency and better handles complex environments and constraints. Once
is obtained, the attacker’s best response
can be calculated according to Theorem 2.
5. Simulations
In this section, we use numerical examples to demonstrate the theoretical results of the Stackelberg game strategies under the presence of Intrusion Detection System (IDS) detectors as proposed in this paper. We set the following parameters:
. To further validate the proposed framework’s effectiveness in practical wireless communication, we refer to recent experiments using real-world datasets and testbeds. For instance, ref. [
40] evaluated a similar strategy on an IEEE 802.11-based testbed, showing improved throughput and SINR under interference. Similarly, ref. [
41] used USRP devices to simulate a multi-user environment and showed effective attack mitigation while maintaining high communication quality. These studies demonstrate advantages and achievements from different perspectives, providing useful references. It is worth noting that our proposed framework includes an IDS detector. Compared with [
12], its uniqueness is introducing this detector at the estimator end. This innovation makes our framework more effective in practical scenarios. Through in-depth analyses, we find it more robust and applicable, offering more reliable guarantees and better performance.
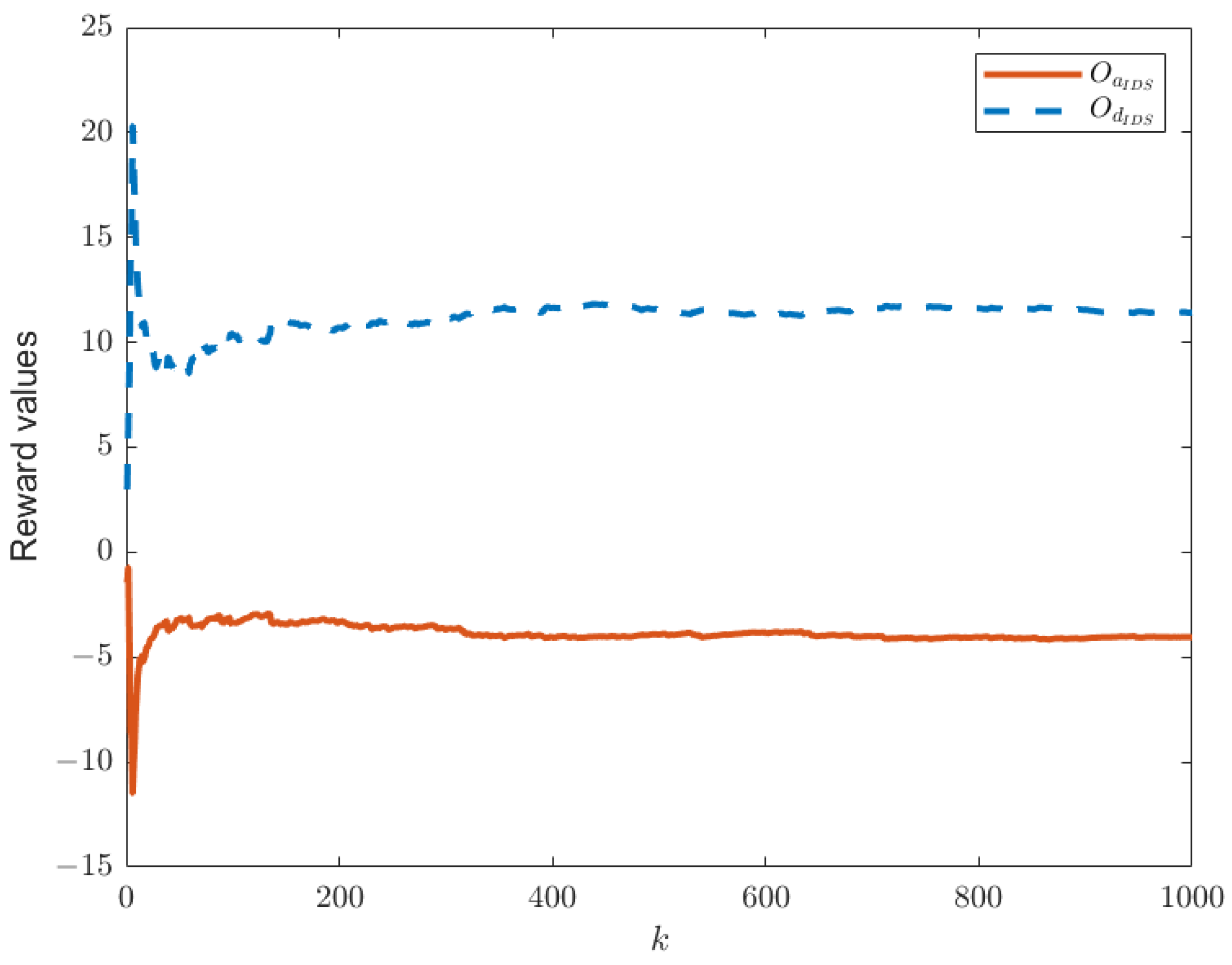
When the IDS does not exist in the system model, as shown in
Figure 1, the reward functions of both sides are as given by Equations (21) and (22). Keeping other parameters constant, we can establish the relationship between time
k and the reward functions of both sides, as shown in
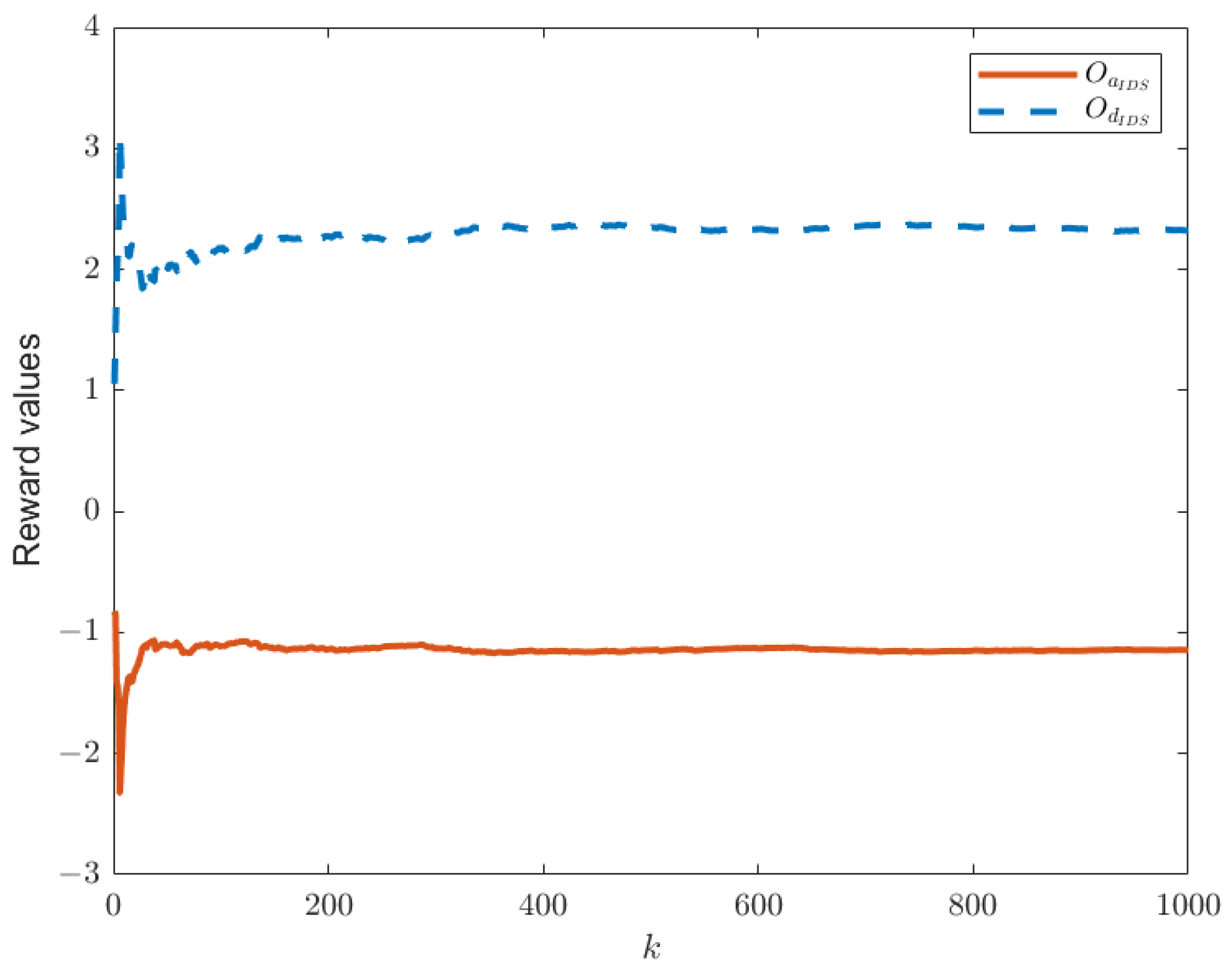
Figure 3. In this paper, we have designed an IDS at the remote estimator end, as depicted in
Figure 2. By choosing
and
, we are able to obtain the relationship between time
k and the reward functions of both sides, as shown in
Figure 4, as well as the strategic choices of both participants when reaching equilibrium in
Figure 5. The three graphs from top to bottom in
Figure 5, respectively, display the strategy values of attackers and defenders on channels 1, 2, and 3. By comparing
Figure 3 and
Figure 4, it can be observed that the proposed IDS detector in this paper can reduce the reward value of attackers and effectively increase the reward value of defenders. In
Figure 4, after each participant undergoes 650 iterations, the reward function converges to the optimal value.
By solving Theorem 2 and Algorithm 2, the relationship between the boundary values
,
triggering alarms in the IDS detector, and the reward values of both players is illustrated in
Figure 6. We choose
and
. The first graph in
Figure 6 represents the reward function of the defender, while the second graph illustrates the reward function of the attacker. From the graph, we can conclude that when
is fixed,
has a significant impact on
, with an increase in
corresponding to a larger
. The influence of
on
is minimal. When
is determined, changes in
result in different reward values for both players in the game. As
transitions from 0 to 1, it is evident that the reward function value of the attacker sharply decreases, while the defender’s reward value slightly increases. For
the attacker’s reward value exhibits minor periodic fluctuations, while the defender’s reward value remains relatively stable.
In the simulation, we can select the range of values for
based on the communication constraints of each channel, which in turn affects the optimization results. Therefore, the results obtained may not be the optimal solution but a suboptimal one. Given this, the nonlinear and non-convex optimization proposed in this paper can provide a feasible solution. In
Figure 4, we have chosen
. If we set
, the reward function values for both parties are depicted in
Figure 7.
Our optimization scheme combines the global search capabilities of Differential Evolution (DE) with the local guidance advantages of the Artificial Potential Field (APF) method. The time complexity of DE is , where is the population size, G is the maximum number of iterations, and D is the dimensionality of each individual. This complexity arises from the matrix operations involved in evaluating the fitness function. The time complexity of APF is , primarily dependent on the number of nodes N and the size of the channel gain matrix H. Therefore, the overall time complexity of our combined approach is . Based on our current experimental setup (), the average runtime is 2.5 s. Although these experiments were conducted on a smaller scale, we can extrapolate the performance for larger scales by adjusting parameters (e.g., ). Our complexity analysis suggests that while runtime will increase, it will remain within a reasonable range. To evaluate real-time performance, we simulated a scenario requiring one optimization decision per second. Under current settings, the optimization completes within 1 s, meeting real-time requirements. However, for larger problem scales, we may need to adjust parameters, such as reducing population size or lowering the number of iterations, to maintain real-time performance. We also explored parallel computing, where processing individuals across multiple nodes can significantly reduce runtime without sacrificing optimization effectiveness. This approach is a promising direction for future research.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}