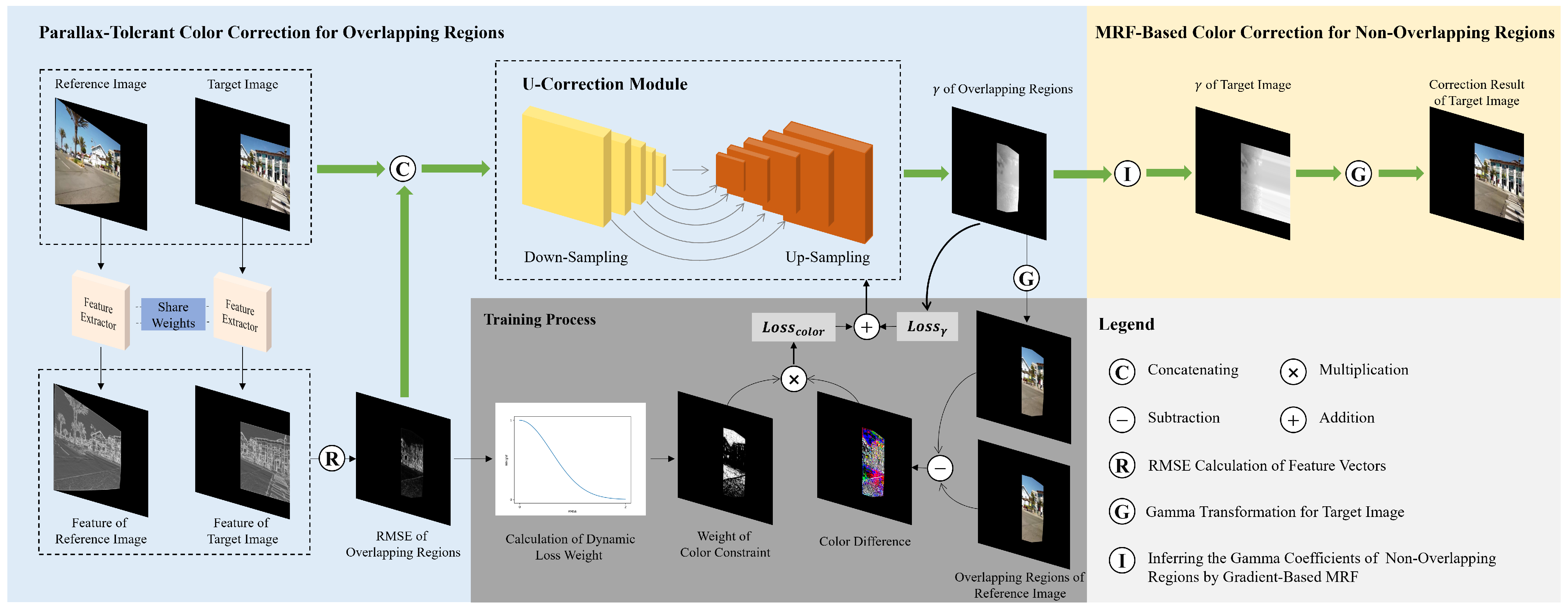
To evaluate the performance of the proposed method, we qualitatively and quantitatively compare our color correction results with the uncorrected original UDIS++ [
9], and mean-based methods GLC [
12] and GCC [
13], as well as feature-based method HHM [
15]. In addition, we incorporate the Transformer-based model TransUNet [
36] into our correction framework, which not only validates the effectiveness of our correction framework but also demonstrates that our proposed CNN-based PTDCC is more suitable than Transformer-based methods for addressing the color correction problem in image stitching. Considering that the input image size in our framework is arbitrary, while the linear layers in Transformer-based methods require a fixed input size, and the Transformer module in TransUNet is pre-trained on the ImageNet [
37], we resize the input images to the standard ImageNet size of 224 × 224 so that the U-correction module in our correction framework can be replaced with TransUNet. Afterward, the gamma correction coefficients output by the network are resized back to the original image size through interpolation. To ensure the rigor of the comparison, other parts of the framework and implementation details remain consistent with our PTDCC.
4.2.1. Qualitative Comparison
To demonstrate the effectiveness of our color correction network, we categorize the test images into three groups: images with evenly distributed brightness differences, images with unevenly distributed brightness differences, and images with significant hue differences, whose correction difficulties range from low to high.
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11 present the comparison of our results with other methods. As shown in
Figure 8b,
Figure 9b,
Figure 10b and
Figure 11b, the GLC algorithm, which solely adjusts the brightness channel based on the mean value, is inadequate in addressing unevenly distributed brightness differences and hue discrepancies, leading to conspicuous stitching artifacts. Although GCC performs color correction in the Lab color space, it calculates the correction coefficients based on the average differences of all pixels in overlapping regions, which can result in inadequate compensation and noticeable stitching artifacts as demonstrated in
Figure 9c. In addition, since GCC performs color correction by adding the compensation parameters to the original image, areas close to white may have distortion after correction, as shown in
Figure 7c,
Figure 8c,
Figure 10c and
Figure 11c. The feature-based method HHM fits the mapping function across all three RGB channels, enabling it to effectively correct images with substantial color discrepancies and minimal parallax. However, for images with significant parallax, this method is prone to generating erroneous mappings, leading to conspicuous stitching artifacts in the composite results, as illustrated in
Figure 9d and
Figure 11d. As for TransUNet, it can achieve a certain degree of correction across various scenarios, which validates the effectiveness of the correction framework we proposed. However, the constraint of fixed input size may lead to the loss of feature information during the resizing process, which results in imperfections in its correction outcomes. For instance, visible color differences persist in the ground region of
Figure 8e and
Figure 10e, and in the wall region of
Figure 11e. Conversely, our color correction network mitigates color differences across all three RGB channels through pixel-wise gamma correction and dynamically adjusts the weights of color mutation depending on the magnitude of the parallax without feature information loss; thus, we can effectively eliminate stitching traces and artifacts in the final outputs.
4.2.2. Quantitative Comparison
In line with the qualitative comparison experiments, the quantitative comparison experiments also categorize the test data into three groups: easy group, moderate group, and hard group, based on the complexity of color correction, respectively.
- (a)
Existing Evaluation Metrics
As for the overlapping regions, since our color correction network takes the reference image as weak supervision, we employ PSNR and SSIM to evaluate the similarity of overlapping regions. The results, presented in
Table 2, demonstrate that our color correction network delivers superior performance across various levels of color correction complexities.
Additionally, for the overall composition results, we utilize image naturalness evaluation metrics BRISQUE [
38] and NIQE [
39], which are often used to measure the similarity between composite images and natural images. The results, displayed in
Table 3, indicate that our color correction method produces results that most closely resemble natural images, outperforming the other methods, which is consistent with our qualitative comparison findings.
- (b)
Innovative Metric
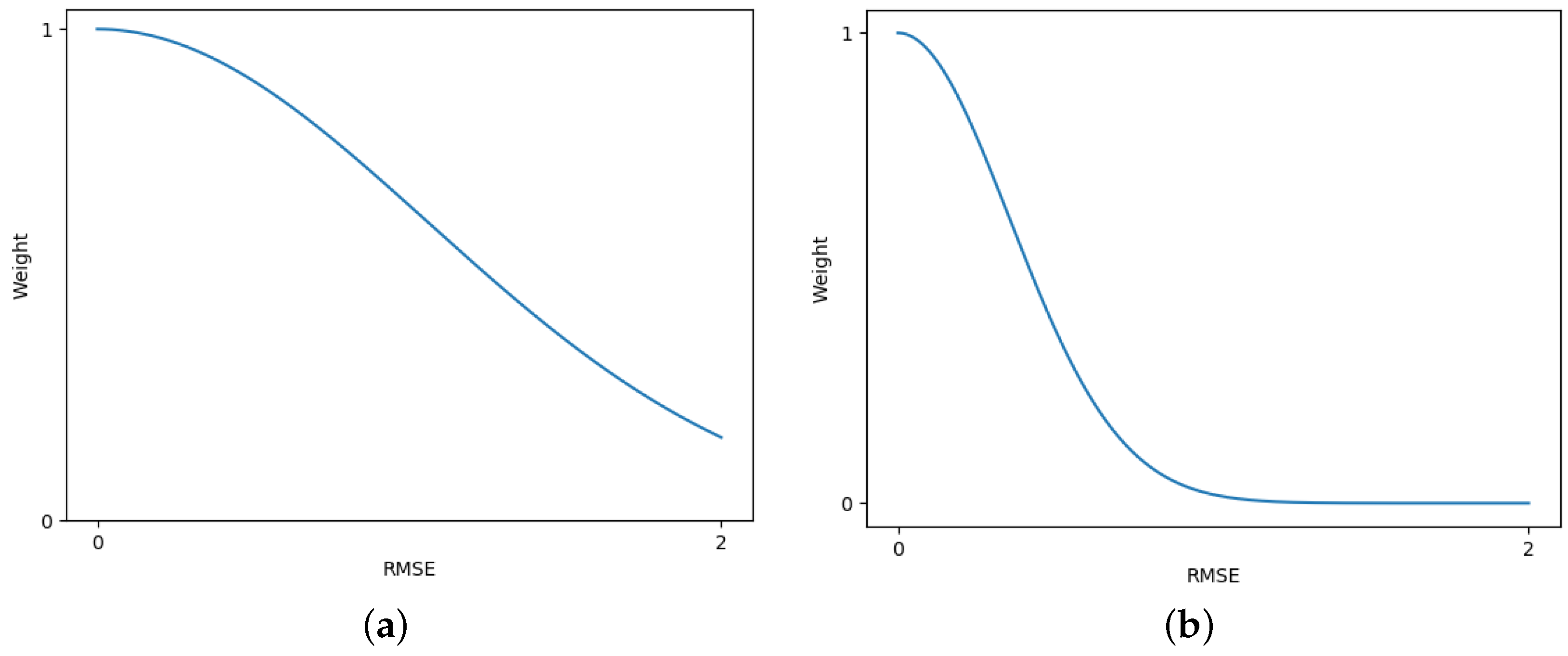
Although existing evaluation metrics can reflect the strengths and weaknesses of different algorithms to some extent, they still have limitations and are not fully applicable to image-stitching scenarios with parallax and color differences.
Figure 12 shows a pair of target and reference images. Although both images focus on the bicycle as the main subject, they are taken from different angles. As can be seen in
Figure 12c, there is noticeable parallax but no color difference between the two images. Therefore, we can use the seam-based method to obtain a composition result without noticeable stitching artifacts, as shown in
Figure 12d. However, for such images, the evaluation metrics PSNR and SSIM, with the reference image as the ground truth, yield poor results. The PSNR of
Figure 12b is only 18.66, and the SSIM is only 0.608. These results contradict our original intention of measuring the visibility of stitching artifacts. Therefore, we believe that PSNR and SSIM are not entirely suitable for evaluating image pairs with parallax, as it is possible to obtain results with no stitching artifacts even when PSNR and SSIM are low.
As for BRISQUE and NIQE, although they can measure the naturalness of an image, the contours of conventional images in natural scenes are often standard rectangles. However, in image-stitching scenarios, image alignment inevitably causes image deformation, so the contour of the effective region (the area containing the scene) in the stitching result is no longer a standard rectangle, and it varies with the relative position of viewpoints.
Figure 13 shows an example of two images with similar content but significantly different contours. In
Figure 13a, the upper boundary, left boundary, and right boundary of the effective region closely match the outer contour, with only the bottom boundary being irregular. In
Figure 13b, only the left boundary matches the outer contour, while the other three boundaries are irregular. Due to the differences in the contours, the BRISQUE and NIQE of
Figure 13a are much smaller than those of
Figure 13b. However, in this study, we aim to compare the visibility of stitching artifacts. Considering that both images display similar content and show no noticeable stitching artifacts, their evaluation results should be similar, which is inconsistent with the current outcomes. Therefore, we can conclude that BRISQUE and NIQE also have certain limitations.
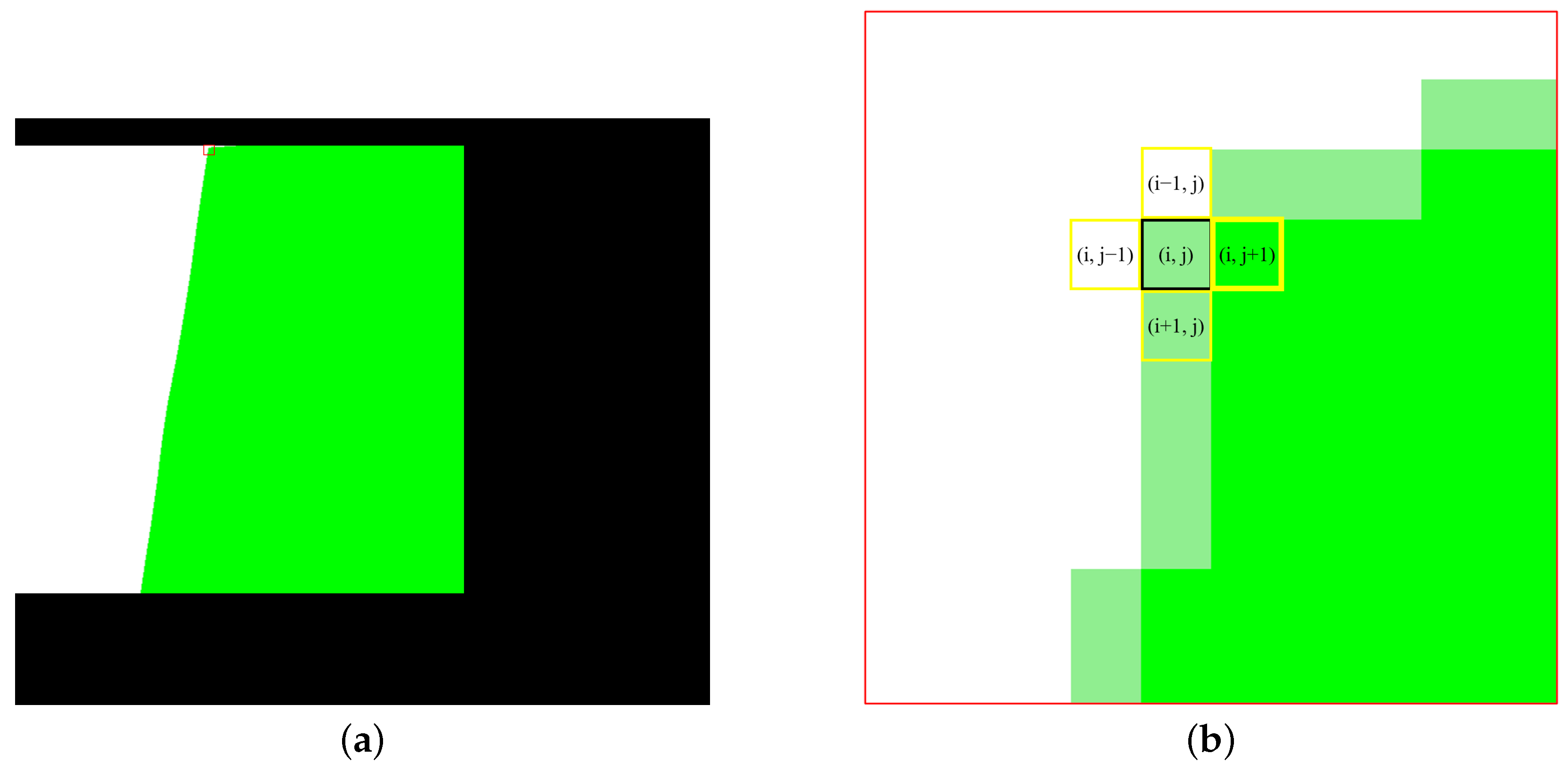
To overcome the limitations of existing evaluation metrics, we innovatively propose an evaluation metric specifically used to measure the smoothness of the transitions across the composition seam, called Color Differences Across the Seam (CDCS). CDCS focuses solely on measuring the prominence of stitching artifacts, unaffected by parallax and contour shapes. It is defined as the ratio of the color differences across the seam to the length of the seam, which can be calculated as follows:
where
L represents the length of the seam, and the color difference at the
i-th row is determined by the RMSE of the average values of the five pixels closest to the seam on both sides. Since the UDIS-D dataset only includes the most common image-stitching scenarios, where the relative positions of the images to be stitched are approximately horizontal, the composition seams are curves that extend from the top to the bottom of the images. Therefore, here we calculate the color differences between the pixels on the left and right sides of the seam:
where
and
represent the average RGB values of the five closest pixels to the seam on the left and right side, respectively (in cases where the images are positioned vertically relative to each other, the reference for calculating CDCS can be adjusted to the pixels on the upper and lower sides of the seam). Consequently, we can transform the subjective assessment of “the visibility of stitching artifact”, which is ordinarily evaluated by human perception, into an objective metric that can be quantitatively expressed in numerical terms, thereby facilitating more precise comparisons. The CDCS of
Figure 12d is 10.32, while the CDCS of
Figure 13a is 10.26 and that of
Figure 13b is 10.13. The similar results for the three images with no noticeable stitching artifacts also confirm the scientific validity and effectiveness of CDCS.
The comparison results of the CDCS for the test set are shown in
Table 4. Our color correction results consistently outperform the other methods, exhibiting the smallest color differences across the seam.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}