1. Introduction
Effective navigation in crowded and dynamic environments, as illustrated in
Figure 1, is critical for a wide range of real-world robotic applications, such as autonomous delivery robots maneuvering through busy urban streets, service robots operating in congested shopping malls, and search-and-rescue robots deployed in disaster-stricken areas. Traditional navigation methods, such as those based on Simultaneous Localization and Mapping (SLAM), which rely on pre-mapping of environments, often underperform in these complex settings. The main limitation of SLAM-based approaches is their dependence on static maps and the assumption that the environment remains relatively unchanging [
1,
2], resulting in frequent localization errors and suboptimal navigation paths in dynamic environments.
In response to this challenge, deep reinforcement learning (DRL) has emerged as a promising solution. DRL’s ability to learn directly from interactions with the environment enables it to adapt to a wide variety of scenarios, making it particularly effective in unknown and dynamic environments [
3,
4,
5]. Unlike conventional methods, DRL-based approaches do not require a predefined map, instead modeling navigation tasks as Partially Observable Markov Decision Processes (POMDPs) [
6,
7], an extension of Markov Decision Processes (MDPs). A POMDP is defined by the tuple:
where
represents the state space, A denotes the action space,
is the transition probability,
is the reward function,
is the observation space,
is a set of conditional observation probabilities, and
is the discount factor [
8,
9,
10]. DRL techniques, including specific algorithms such as Deep Q-Networks (DQNs) and Proximal Policy Optimization (PPO), as well as broader frameworks like Actor-Critic methods, have demonstrated significant potential in enabling robots to navigate dynamic environments without relying on prebuilt maps. These approaches effectively handle the complex, sequential decision-making processes inherent in such tasks [
11,
12].
However, existing DRL-based mapless navigation solutions are often constrained by their reliance on complex feature extraction processes and sensor fusion strategies, which typically require systems with a wide field of view (FOV), as shown in [
13,
14,
15,
16]. While other methods are effective in relatively static environments as shown in [
17,
18,
19], they struggle in highly dynamic settings characterized by partial observability. In such environments, robots receive incomplete observations, which increases decision uncertainty. Moreover, traditional MDP-based approaches face significant challenges in handling large or continuous state and action spaces, often requiring function approximation techniques that can complicate model convergence and degrade real-time performance. The heavy reliance on handcrafted feature extraction methods exacerbates these issues, reducing generalization capabilities of the learned models.
Navigating in environments with limited FOV introduces additional complexities. The restricted observational capacity hampers a robot’s ability to accurately characterize its state, thereby reducing situational awareness. Furthermore, high-dimensional state representations derived from multimodal sensing data pose substantial difficulties for conventional DRL algorithms, particularly when generating continuous action spaces. This can lead to overfitting, limiting robot’s adaptability to unseen scenarios.
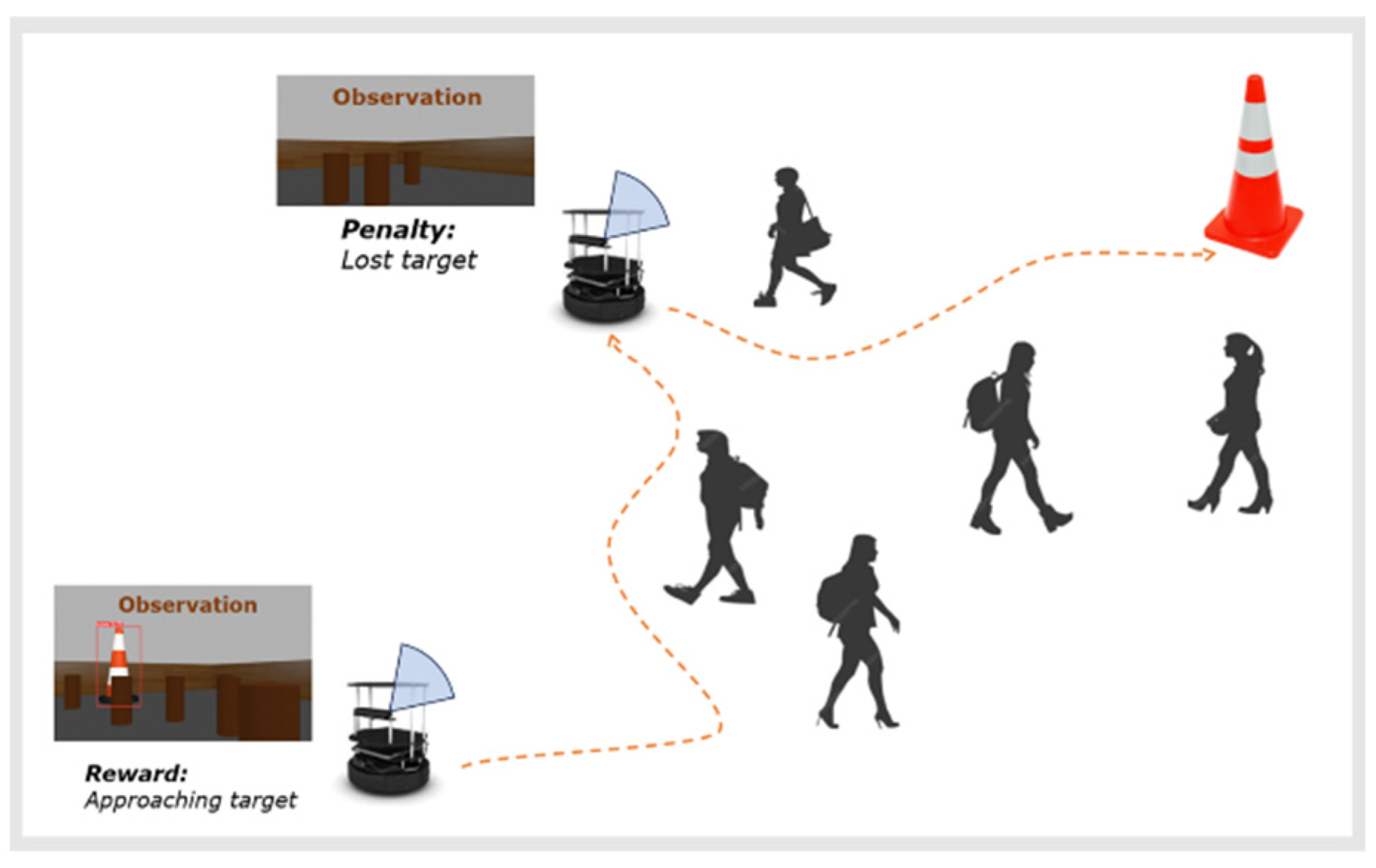
To address these challenges, this paper proposes a DRL-based method specifically for visual target-driven navigation in crowded environments with limited FOV. Our approach is grounded in key principles aimed at enhancing generalization and practical applicability. First, we minimize hardware requirements by employing a single RGB-D camera with limited FOV, thereby reducing dependency on complex localization techniques, and enhancing deployment versatility across a broad spectrum of robotic platforms. This minimalist sensor setup not only reduces costs but also simplifies the overall system architecture, making it more robust and accessible for various applications.
Second, we mitigate the risk of overfitting by incorporating dynamic obstacles into the training process, ensuring that the learned strategies are robust and adaptable to changing conditions in real-world scenarios. By introducing a randomly positioned visual target during training, we prevent the model from becoming overly dependent on specific environmental configurations, thereby enhancing the generalization capabilities.
Furthermore, to overcome the challenge associated with target tracking within a limited FOV, our method integrates a self-attention network (SAN). The SAN infers positional information of the lost target based on past observations, enabling the robot to effectively search for the target.
At the core of our approach is the Twin-Delayed Deep Deterministic Policy Gradient (TD3) algorithm, known for its effectiveness in handling continuous action spaces, to enable efficient navigation in crowded environments. The TD3 algorithm addresses the challenges associated with traditional DRL approaches by introducing several innovations, including twin Q-networks and delayed policy updates, which improve stability and performance in complex environments.
In summary, this paper addresses the gaps in the current literature on DRL-based navigation in crowded environments by proposing a practical solution that reduces both observational and computational demands while maximizing adaptability. Our contributions are threefold:
We propose a novel DRL-based architecture for mapless navigation in unseen and dynamic environments, which relies exclusively on a visual target without requiring any environment modeling or prior mapping.
We propose a SAN-based feature extractor to enhance the robot’s ability to search for and track targets in environments with dynamic obstacles and randomly positioned targets.
Experimental results have demonstrated the superior performance of the proposed architecture in navigating in crowded and dynamic environments, even with a limited FOV.
The remainder of this paper is organized as follows:
Section 2 provides a review of related work on DRL-based navigation, with emphasis on visual target-driven approaches.
Section 3 details the system architecture of the proposed method. In
Section 4, we present the navigation policy representation.
Section 5 introduces the training algorithms used for the proposed model.
Section 6 presents the experimental results and compares our approach with existing methods.
Section 7 discusses the experiment results. Finally,
Section 8 concludes the paper and discusses directions for future work.
3. System Architecture
3.1. Overall System Design
The architecture of the proposed DRL-based robot navigation approach, as shown in
Figure 2, integrates several components, including depth data processing via a convolutional neural network (CNN), YOLOv5-based target detection, a SAN for temporal feature extraction, and TD3 algorithm for policy learning. Collectively, these components form a robust framework for visual target-driven robot navigation in crowded environments.
3.2. Depth and Visual Data Processing
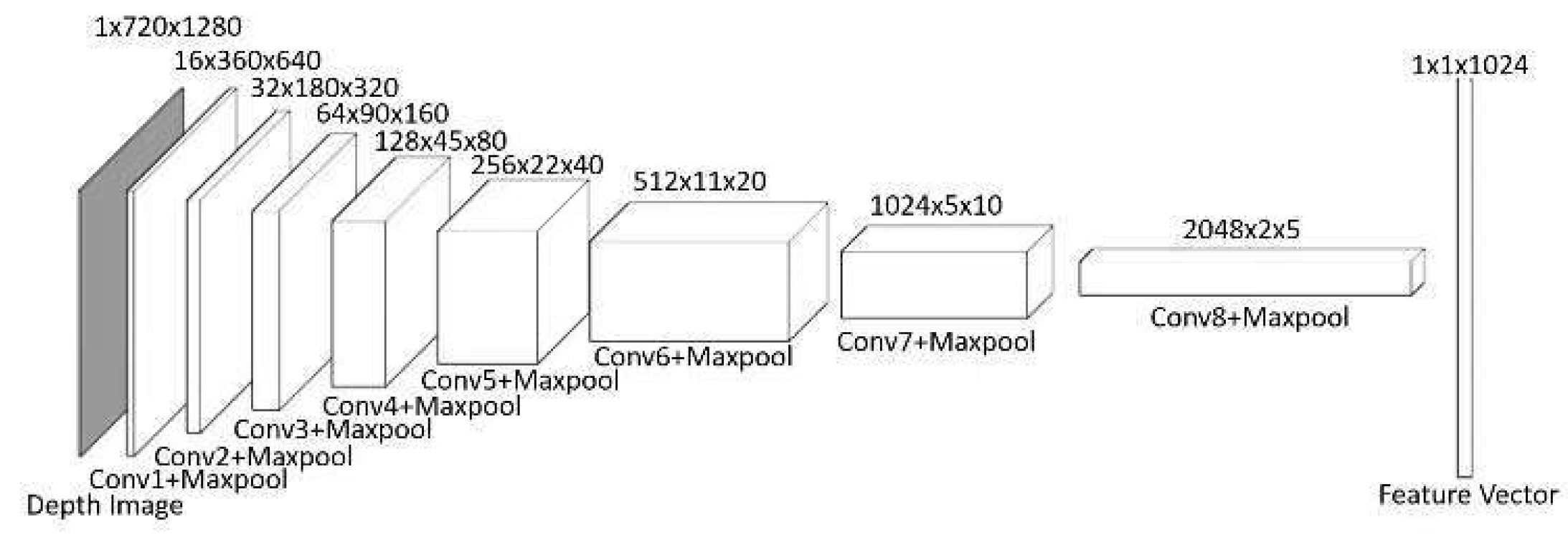
The system receives input from an onboard RGB-D camera with 70-degree horizontal FOV, a compact setup compared to systems in many existing works assuming a 360-degree FOV [
27]. The depth data (1280
720 pixels), representing the 3D structure of the environment, are processed through an eight-layer CNN, as shown in
Figure 3. Each layer uses 3
3 kernels with 2
2 max-pooling to down-sample the data, reducing them to a feature representation (2048
2
5), which is further connected to a fully connected layer and then flattened to feature vector with dimension of 1024 for integration into the decision-making pipeline. The choice of the feature vector’s dimension is guided by a trade-off among TD3 training convergence, the adequacy of environmental representation, and the real-time performance during inference.
In parallel, YOLOv5 is employed to perform real-time target detection using RGB data capture by the same RGB-D camera. YOLOv5 predicts bounding boxes and class probabilities in a single pass, allowing continuous target tracking as the robot navigates. Once the target’s bounding box is detected, the depth value at its center is retrieved from the depth map, enabling the system to estimate the target’s distance and enhance situational awareness during navigation.
3.3. Self-Attention Network for Temporal Feature Processing
One key challenge posed by the robot’s limited 70-degree FOV is its restricted ability to perceive the entire environment, making it harder to track the target which moves outside its visual range. To mitigate this, the SAN is employed to compensate for the limited FOV by extracting temporal and spatial dependencies from past observations. This approach is inspired by the SAN’s demonstrated effectiveness in capturing complex dependencies in previous research [
28,
29]. By learning patterns and relationships between actions and their outcomes over time, the SAN enables the robot to maintain situational awareness beyond its current FOV.
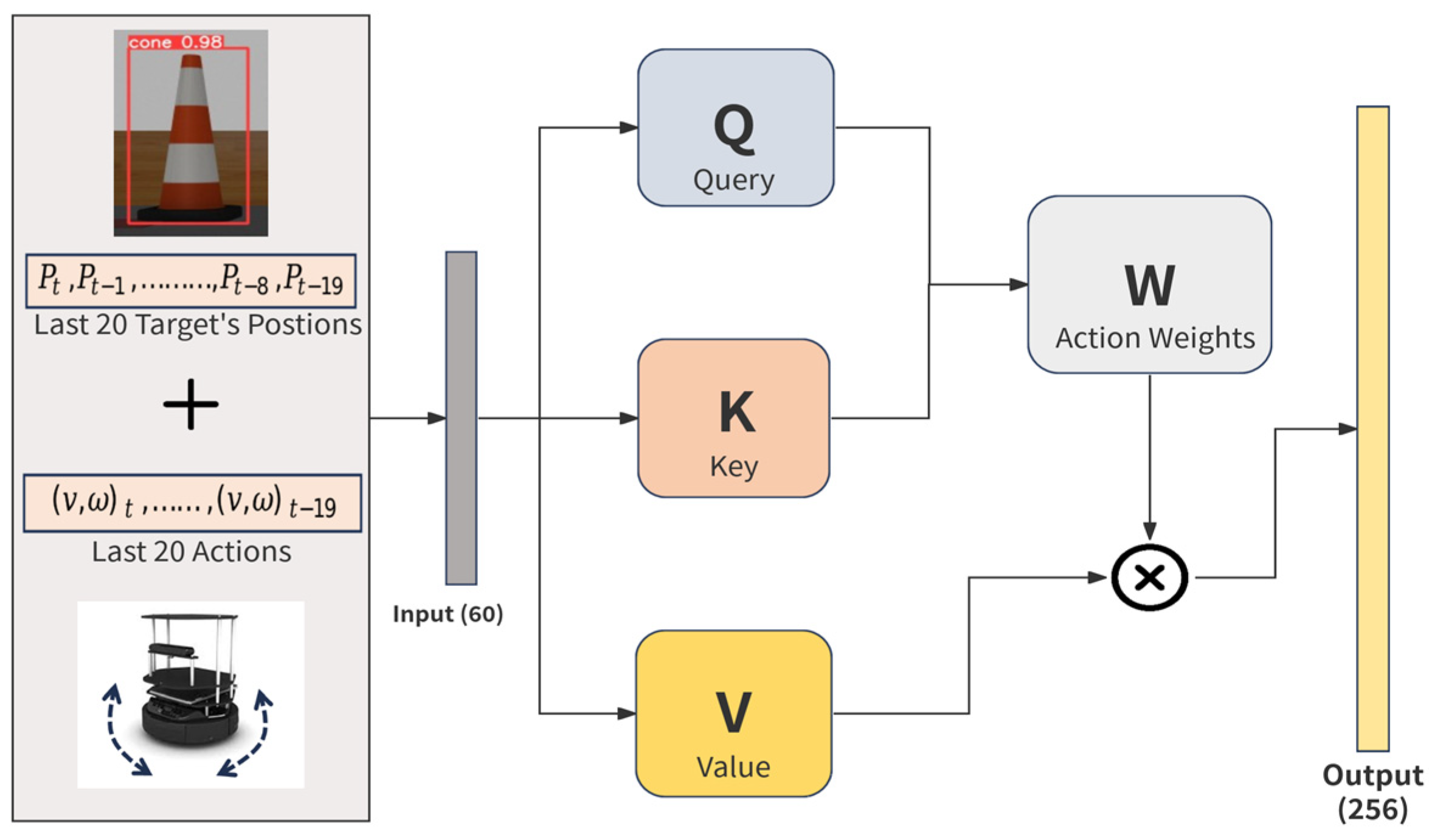
In this study, the SAN processes sequences of 20 past target positions and 20 corresponding actions, producing a 128-dimensional feature vector, as illustrated in
Figure 4. This dimension is selected to strike a balance between computational efficiency and the capacity to capture sufficient temporal patterns for effective decision-making. This configuration enables the robot to “reconstruct” a broader understanding of the environment, enabling it to track the target’s location even when it temporarily falls outside the camera’s view. By leveraging these temporal patterns, the SAN improves decision-making in target pursuit in dynamic environments.
The effectiveness of the SAN in our approach lies in its ability to dynamically prioritize relevant spatial and temporal features, allowing the robot to respond when the target is lost from its current view. The self-attention mechanism works by allowing the model to assign varying levels of importance to different parts of its past observations, such as past target locations and actions. This means that when key information, like the target’s location, is missing from the current FOV, the model can attend to previous observations that still hold useful data about the target’s movement patterns. By computing relationships between queries, keys, and values, the robot can better predict where the target is likely to be, even when direct visual input is unavailable. This dynamic allocation of attention enables the robot to maintain robust situational awareness and make more informed navigation decisions, even in challenging environments.
Mathematically, this attention mechanism is represented by the following formula:
where the robot’s input sequence (i.e., past target positions and actions) is transformed into three distinct matrices—Query (Q), Key (K), and Value (V). Queries assess relevance, Keys represent the elements being attended to, and Values provide the actual data being aggregated. This allows the robot to focus on the most critical parts of its environment and adjust its behavior accordingly, despite the limited FOV.
3.4. Twin-Delayed Deep Determinstic Policy Gradient (TD3)
Building on the feature extraction capabilities of the CNN and SAN, TD3 is employed as the core policy learning algorithm to manage continuous action spaces in the crowd navigation task. TD3 enhances stability by using twin critics to reduce Q-value overestimation and delayed policy updates to improve training efficiency [
30]. Its strength in continuous action optimization makes it effective for real-time obstacle avoidance in dynamic environments, as demonstrated by its integration with methods like the Dynamic Window Approach (DWA) for LiDAR-based navigation [
31] and Long Short-Term Memory (LSTM) networks for path-following in autonomous systems [
32]. In dynamic environments with unpredictable obstacle movement, TD3 is advantageous in managing continuous action space for obstacle avoidance. Its twin critics compute conservative value estimates, addressing overestimation bias, which is particularly critical in environments where rapid changes occur. The TD3 loss function is defined as follows:
where
represents the action-value function approximated by the i-th Q-network, with
denoting its parameters. The term
refers to the target Q-value, which is calculated as the minimum value between the two Q-networks, addressing the issue of overestimation. Specifically, the target Q-value
is computed as follows:
Here, represents the target Q network, where are the parameters slowly updated from the current Q network parameters . This gradual update process helps stabilize training by providing more consistent target Q-values. The reward is obtained after executing action in state , and γ is the discount factor. The target policy is used to compute the next action, with ϵ being a small noise added to encourage exploration.
To further enhance stability, TD3 implements delayed policy updates and soft target network updates to further stabilize the learning process. These enhancements ensure more accurate Q-value estimation and robust training, setting TD3 apart from other reinforcement learning algorithms like DDPG. TD3’s robustness in managing continuous action spaces, coupled with its enhancements for stability and efficiency, makes it perform well in crowd navigation.
4. Navigation Policy Framework
In this section, we present the design of the navigation policy for the proposed system.
4.1. Observation Space
In our proposed method, the observation feature representation, which is used as the input to the TD3 network, is composed of three distinct components, each providing crucial information for effective navigation. First, a 1024-dimensional vector is extracted from the depth image via a CNN. This vector captures spatial features of the environment, helping the robot identify obstacles and free spaces. Second, the depth value of the target object, represented as a scalar, is derived from the depth at the center point of the bounding box detected by YOLO, providing essential target distance information. Lastly, a 128-dimensional vector is produced by a SAN, which processes the historical context of the last 20 actions and the last 20 target positions. This vector captures temporal dependencies and relationships between past actions and target positions, enhancing the robot’s ability to make informed decisions based on prior experiences. By integrating these three components, the TD3 network is equipped with comprehensive spatial and temporal information, allowing it to navigate complex environments and efficiently track the target.
4.2. Action Space
The action space is represented by a two-dimensional vector, , where denotes the linear velocity and represents the angular velocity. Actions are selected based on a deterministic policy , conditioned on the current observation o. Specifically, the action a is sampled from the policy distribution . The linear velocity ranges from 0 to 0.55 m/s, allowing control over the forward speed, while the angular velocity ω represents the angular velocity ranging from −1.5 to 1.5 rad/s, allowing the robot to adjust its heading during navigation.
The limits for the linear and angular velocities are selected based on the hardware specifications of the real robot employed in this study, which ensure that the actions generated by the trained policy in the simulation environment are compatible with the robot’s physical capabilities to address the sim-to-real gap. By matching the velocity limits to the robot’s motor capabilities, reliable movement is achieved while minimizing excessive inertia, thereby ensuring robust and efficient performance during real-world navigation.
4.3. Reward Function
The reward function in our approach is designed to guide the robot toward efficient and safe navigation in dynamic environment. It is defined as follows:
4.3.1. Step Penalty
This component encourages the robot to reach the target efficiently by imposing a constant penalty for each time step. It discourages prolonged navigation and oscillatory behavior. The penalty is set at a constant value of
4.3.2. Distance Reward
The distance reward is designed to incentivize the robot to move closer to the target. The reward is proportional to the change in distance between the current position and the target, denoted by
, and the previous distance,
. The robot is penalized for moving away from the target:
4.3.3. Camera View Reward
This reward component encourages the robot to keep the target within the camera’s view. The robot is rewarded when the target is visible and penalized when it is lost. The reward is based on whether the target’s bounding box is detected.
4.3.4. Target Position Reward
This reward component encourages the robot to center the target in its view. The closer the target to the center of the camera’s view, the higher the reward. The position of the target within the view is denoted as
.
4.3.5. Obstacle Distance Penalty
This term penalizes the robot for moving too close to obstacles. The penalty is proportional to the change in distance between the robot and the nearest obstacle, where
and
represent the current and previous distance, respectively:
4.3.6. Collision Risk Penalty
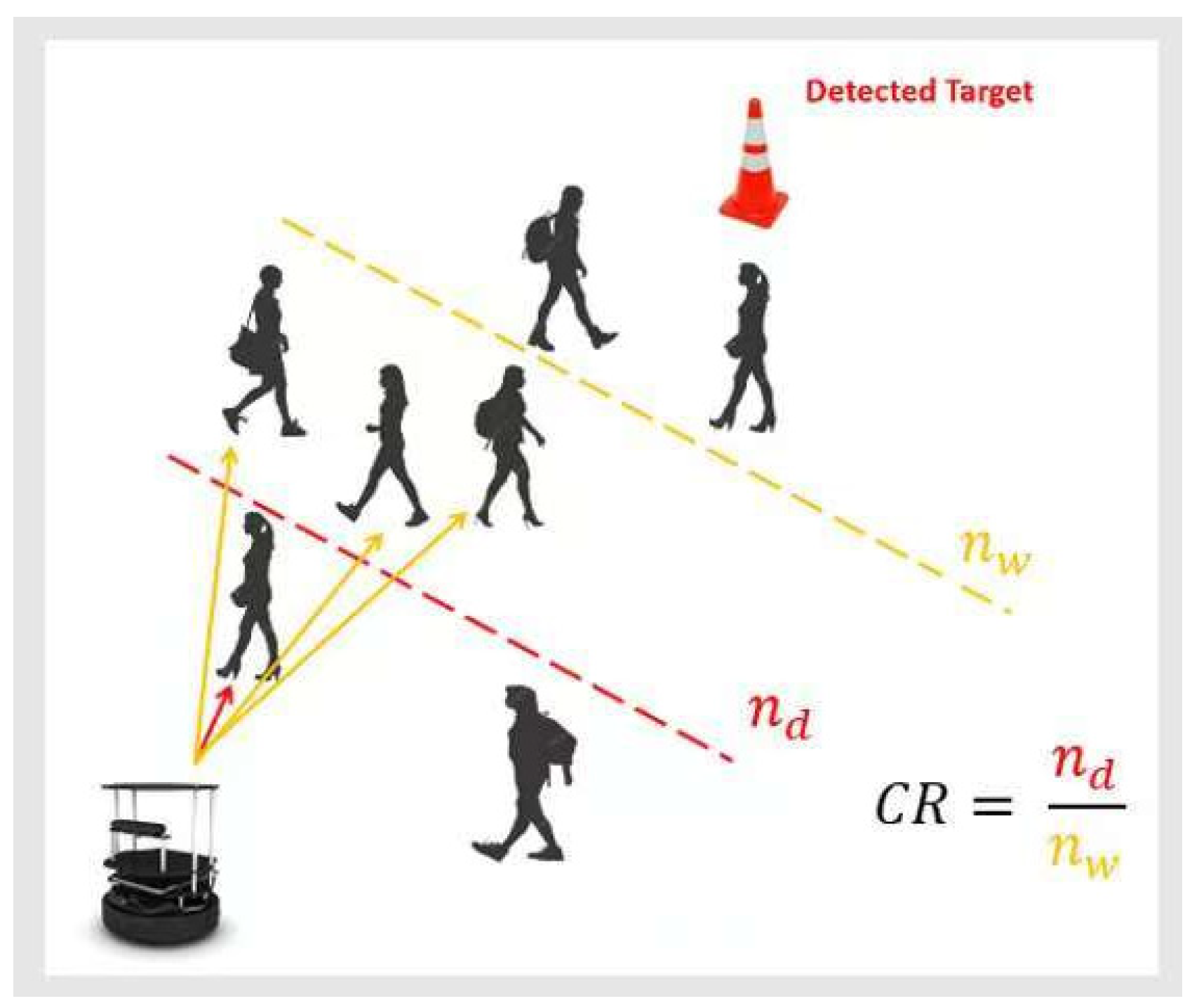
A collision risk penalty is introduced to penalize the robot for operating in high-risk areas. As illustrated in
Figure 5, it is calculated as the ratio of the number of “dangerous-level” depth pixels
, where their depth is below a danger threshold, to the number of “warning-level” depth pixels
, where their depth is below a warning threshold:
The corresponding penalty is as follows:
The collision risk penalty encourages the robot to avoid highly crowded areas and choose a less crowded area for navigation.
Figure 5.
The collision risk penalty based on the ratio of the number of “dangerous-level” depth pixels to the number of “warning-level” depth pixels.
Figure 5.
The collision risk penalty based on the ratio of the number of “dangerous-level” depth pixels to the number of “warning-level” depth pixels.
4.3.7. Design Principles of Reward Function
The reward function is designed based on two fundamental principles: (1) the ultimate objective is to reach the target location, and (2) the robot must avoid obstacles along the way. These principles synergize to guide the robot’s behavior, ensuring efficient movement toward the target while minimizing collisions and navigational inefficiencies.
In accordance with the first principle, the robot is incentivized to move toward the target through the “distance reward”, , which is assigned a substantial negative weight of −150. This strong penalty discourages deviations and promotes consistent progress toward the target. While keeping the target near the center of the robot’s FOV is beneficial for navigation, it is considered less critical. Therefore, the “target position reward”, , is assigned a relatively lower gain of ±15. Additionally, to account for scenarios where temporarily losing sight of the target may facilitate better obstacle avoidance, the “camera view reward”, , is assigned a low gain of ±10. This balance ensures that the robot prioritizes progress toward the target while remaining flexible in its navigation strategy.
In alignment with the second principle, the reward function incorporates components that penalize risky proximity to obstacles. The “collision risk penalty”, , acts as a preventive measure, signaling danger and discouraging the robot from navigating through crowded areas. This is achieved with a strong penalty weight of −180. Furthermore, the “obstacle distance penalty”, , penalizes the robot which is extremely near an obstacle. This component carries an extremely high penalty of 3000 to strongly encourage rapid evasive actions to prevent imminent collisions.
5. Model Training
This section outlines the training process for the proposed model, which integrates both CNN and SAN modules within a DRL framework.
5.1. Network Training
By combining the spatial information extracted by the CNN with the temporal dependencies captured by the SAN, the model addresses the limitations posed by the robot’s constrained FOV. This fusion enables more informed and anticipatory decision-making, particularly in dynamic and crowded environments.
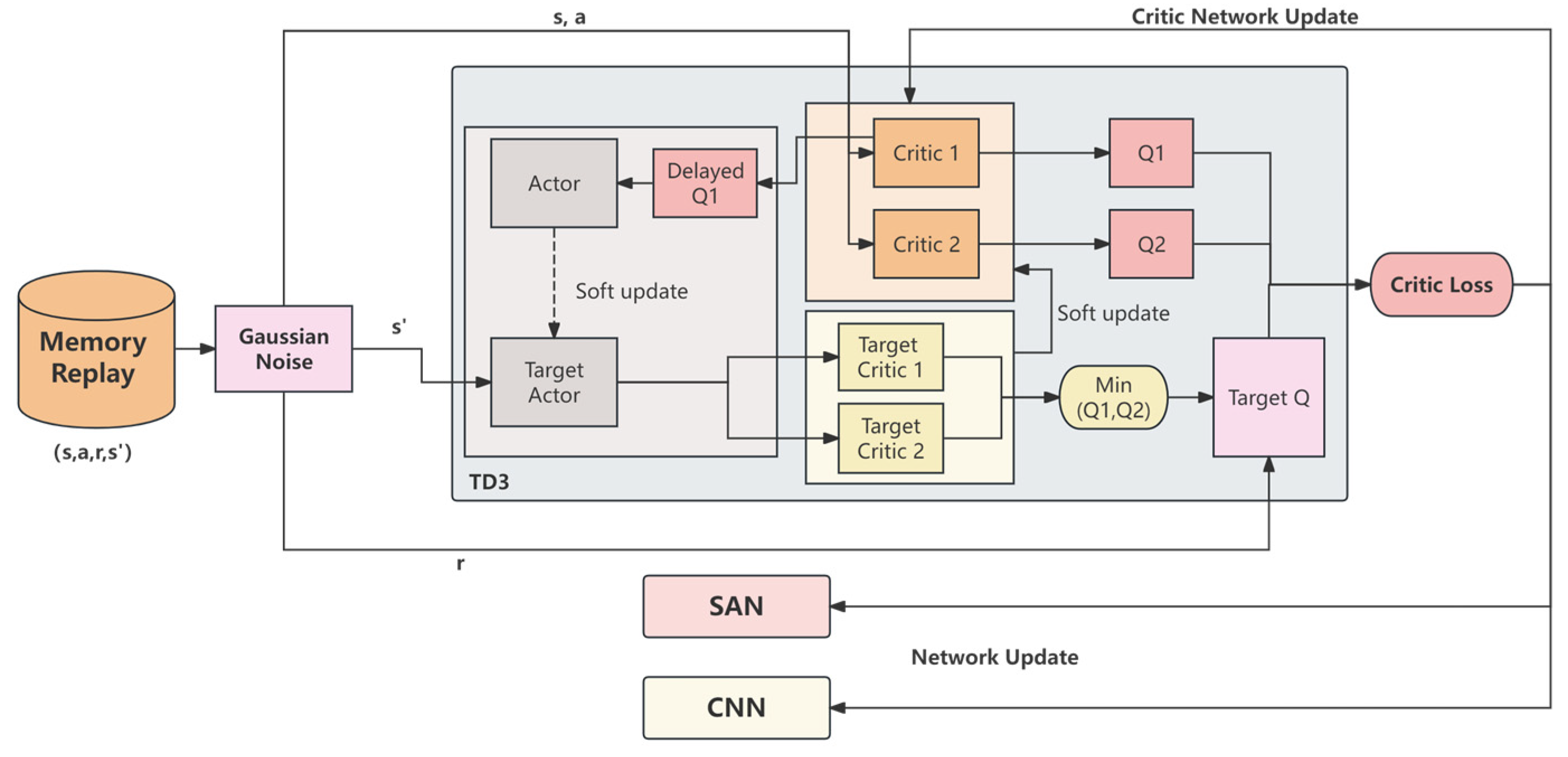
Figure 6 illustrates the overall framework of our proposed enhanced TD3 algorithm, where the critic loss of TD3 network is used not only to update the traditional critic network but also to simultaneously update the CNN and SAN. Specifically, the state–action–reward–next state
data in the experience replay buffer are first processed with Gaussian noise to generate a noisy next state
. At this point, the TD3 algorithm uses two critic networks (Q1 and Q2) to compute the Q-values, and the target Q-value
is generated by taking the minimum of the two target critic networks (Target Critic 1 and Target Critic 2), which is then used to calculate critic loss.
In standard TD3, the critic loss is solely used to update the parameters of the critic network itself. However, in our design, the critic loss is further utilized to update the parameters of the CNN and SAN, enabling them to learn features that help reduce the Q-value prediction error. The parameters of the CNN and SAN are updated simultaneously by minimizing this loss function. The gradient descent update rules are given by
where α is the learning rate, and
and
are the gradients of the loss function with respect to the CNN and SAN parameters, respectively. Specifically, the CNN is primarily responsible for extracting visual information from RGB-D images, while the SAN is used to extract temporal features from historical target positions and action sequences. By aligning the CNN and SAN with the target of the critic loss, they can collectively learn state and action features that are beneficial for Q-value prediction, thereby enhancing the accuracy of the Critic network’s Q-value estimation.
Moreover, this joint optimization method ensures consistency between the feature extraction networks and the policy network, reducing the issue of feature mismatch among networks and improving the stability and overall performance of the training process.
We provide the pseudocode, outlined in Algorithm 1, which details the comprehensive steps and procedures employed during the model training process. The pseudocode includes important aspects such as algorithm initialization, the training process, and parameter updates to facilitate the reader’s understanding of the algorithm’s implementation.
| Algorithm 1: Combined Training of TD3 with CNN and SAN |
| 1 | Initialize critic networks , and actor network with parameters and |
| 2 | Initialize target networks , |
| 3 | Initialize replay buffer |
| 4 | while do |
| 5 | |
| 6 |
for do |
| 7 | |
| 8 | |
| 9 | store into |
| 10 | if then |
| 11 | Sample mini-batch from |
| 12 | Next action |
| 13 | |
| 14 | |
| 15 | Update critics |
| 16 | Update CNN |
| 17 | Update SAN |
| 18 | if mod d then |
| 19 | Update by deterministic policy gradient: |
| 20 | |
| 21 | Update target networks: |
| 22 | |
| 23 | |
| 24 | end if |
| 25 | end if |
| 26 | end for |
| 27 | end while |
In TD3, the critic network plays a crucial role in estimating Q-values by minimizing the critic loss, which measures the error between predicted and target Q-values. This process ensures accurate value functions and stable convergence. The CNN and SAN are integral components of the framework, with the former extracting spatial features from RGB-D images and the latter capturing temporal dependencies from historical data. However, when optimized independently, these networks face limitations, as their feature extraction processes are not directly aligned with the reinforcement learning objective of minimizing Q-value prediction errors. This misalignment can lead to feature mismatch, reducing the effectiveness of the overall system.
To address this, we leverage the critic loss to simultaneously update the CNN and SAN, aligning their training objectives with the reinforcement learning goal. This joint optimization provides several key benefits:
Direct Alignment with RL Objectives: The CNN and SAN no longer optimize features independently but instead learn representations that directly minimize Q-value prediction errors, improving overall efficiency.
Reduced Feature Mismatch: By aligning feature extraction with the critic’s loss function, the features learned by the CNN and SAN are more consistent and better suited to support the critic network.
Improved Stability and Performance: The unified training process enhances the stability of the learning process, accelerates convergence, and improves policy performance by ensuring that spatial and temporal features are optimized to complement each other.
Enhanced Feature Representation: The CNN and SAN learn richer and more task-relevant features, enabling the critic network to model complex environments effectively.
Avoiding Optimization Conflicts: Jointly training the CNN and SAN avoids potential conflicts or redundancies that may arise when these networks are optimized independently.
This integrated design allows the model to utilize spatial and temporal information more efficiently, compensating for limited FOV and enabling robust decision-making in dynamic and crowded environments.
5.2. Training Environment and Procedure
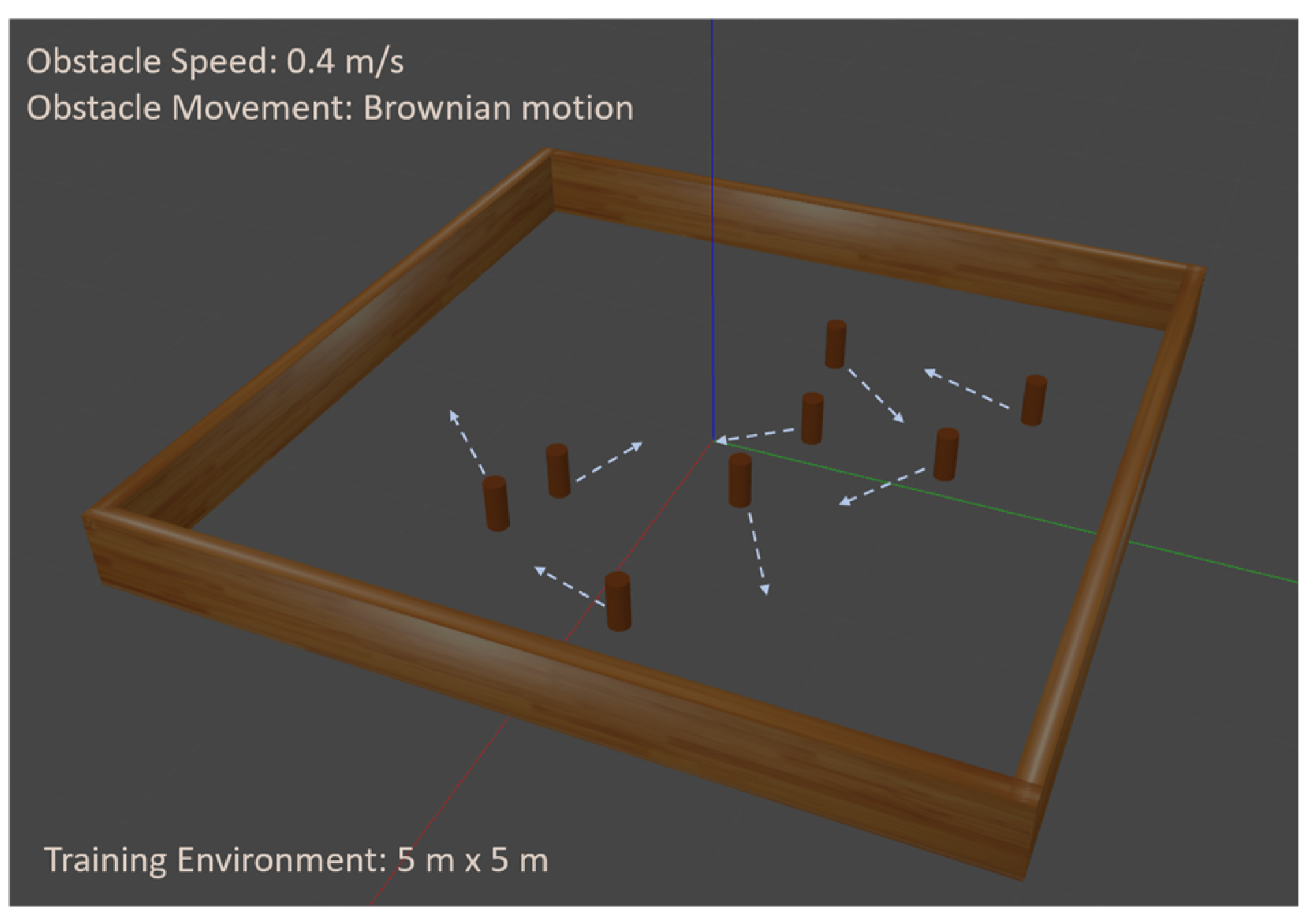
The model training was conducted using an NVIDIA RTX 3090 GPU running Robot Operating System (ROS) Noetic distribution and Gazebo simulator. The simulated environment, as shown in
Figure 7, comprises a 5 m × 5 m square area populated with 12 dynamic obstacles.
These obstacles are cylindrical in shape with a height of 0.24 m and a radius of 0.05 m, exhibiting random Brownian motion with a maximum linear speed of 0.4 m/s. The autonomous robot, a TurtleBot Burger equipped with an Intel RealSense D435 depth camera, was tasked with navigating this environment. The robot’s mobility constraints were set with a maximum linear velocity of 0.55 m/s and a maximum angular velocity of 0.15 rad/s. The depth camera provides both depth and visual input, which are subsequently processed to extract crucial environment information for navigation.
Over the course of training, the robot underwent 120,000 episodes, totaling approximately 185 h. Each episode initiated with the robot positioned randomly within the environment, aiming to reach a predefined target location while avoiding collisions with the moving obstacles. The primary training objective focused on maximizing the cumulative reward, designed to incentivize efficient and safe target pursuit. Throughout the training phase, the robot’s policy was continually refined via the TD3 algorithm. This enhancement was supported by a SAN, which leveraged both spatial and temporal information from historical observations and target.
This training setup enabled the robot to learn navigation strategies within a crowded and dynamically changing environment, achieving real-time decision-making under limited FOV.
6. Results
We tested our approach in a simulated environment with different obstacle movement patterns and conducted evaluations of our method across three distinct scenarios to assess its performance relative to existing DRL-based approaches. Our comparison was made with (1) map-based DRL approaches in static environments, (2) vision-based DRL approaches in static environments, and (3) TD3-based approach in dynamic environments.
6.1. Trajectory Visualization in Dynamic Environment
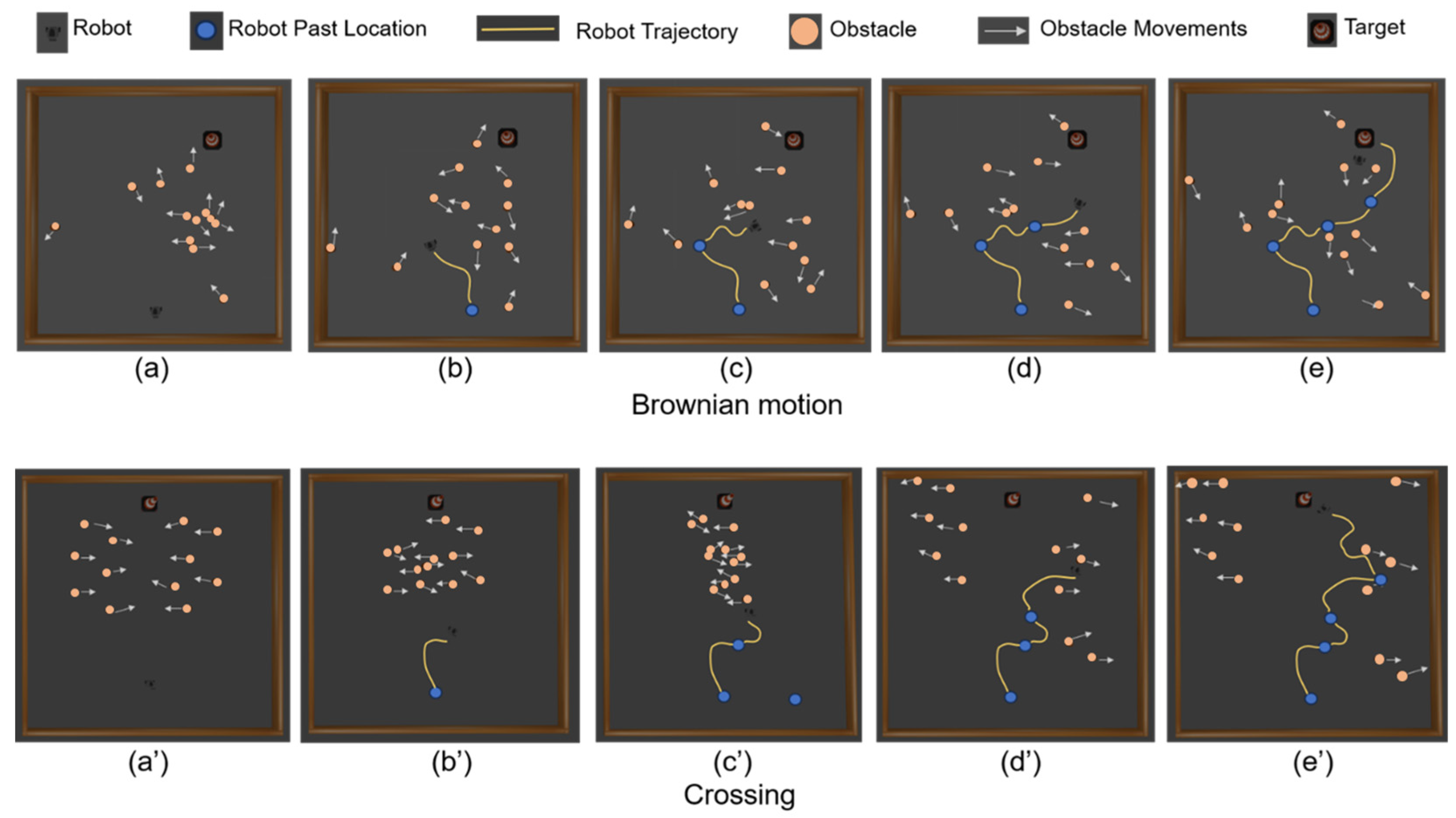
To evaluate the robot’s navigation performance in dynamic environments, we visualized its trajectory in a simulated space.
Figure 8 illustrates a typical trajectory of a robot navigating a 5 m × 5 m simulated space populated with eight cylindrical obstacles, each measuring 0.24 m in height and 0.05 m in radius. These obstacles are programmed to move in patterns of Brownian motion and crossing motion, with a maximum velocity of 0.4 m/s. The robot leverages its RGB-D camera to capture frames representing its state, comprising both RGB and depth data, at successive time intervals as it progressively navigates toward the target in a dynamic environment. The variations in the trajectory confirm the robot’s real-time adaptability to the movements of the obstacles, demonstrating the effectiveness and flexibility of the self-attention enhanced DRL approach in complex navigation tasks.
6.2. Comparison with Map-Based DRL Approaches in Static Environment
Our experimental setup included a comparative evaluation against map-based DRL approaches. Our method achieved a success rate of 0.97 based on 100 test episodes in a mapless, target-driven simulation environment utilizing a single RGB-D camera. This result outperforms other DRL-based methods in similar static environments, as summarized in
Table 1.
It is important to highlight that these baseline methods depend on prebuilt maps and a predefined fixed target location, substantially simplifying the navigation task compared to our mapless, visual target-driven setup. In our trials, we employed a 5 m × 5 m indoor environment with four randomly placed static cylindrical objects and a randomly located target object. Despite the challenging conditions, our method demonstrated superior navigation capabilities, achieving the highest success rate, and illustrating its adaptability and efficacy in unstructured, mapless environments, which is a crucial advantage for real-world applications where prebuilt maps are unfeasible.
6.3. Comparision with Mapless Vision-Based DRL Approaches in Static Environment
In further evaluations, our method was contrasted against other vision-based DRL strategies in indoor environments, as detailed in
Table 2. Our approach recorded a success rate of 0.87 based on 100 test episodes in the simulation environment with eight obstacles in Brownian motion, utilizing a single RGB-D sensor for perception. In contrast, the method developed by Wu et al. [
26], tested in a static indoor bathroom using the AI2-THOR framework, achieved a success rate of 0.627. The PPAC+LSTM method [
25] reported a perfect success rate of 1.0 in a simulated static indoor bathroom scenario, without any moving obstacle. The DS-DSAC with the PredRNN++ [
36] method reported a 0.86 success rate in large indoor offices. Similarly, the Goal-Directed method proposed by Zhou et al. [
37] achieved a 0.82 success rate to navigate to specific rooms from a corridor.
Our test environment, a 5 m × 5 m simulated space populated with eight cylindrical obstacles each 0.24 m in height and 0.05 m in radius moving at a maximum velocity of 0.4 m/s in a Brownian motion, represents a more complex and realistic challenge compared to the static conditions of the baseline methods. This demonstrates the robustness and adaptability of our method, offering significant benefits for practical robotic navigation, especially when employing a vision sensor with limited FOV.
6.4. Comparision with Mapless Vision-Based DRL Approaches in Dynamic Environment
In further tests, we compared our method with a baseline TD3 algorithm [
13] under varying obstacle densities (4, 8, and 12 obstacles) in Brownian motion. Using a single RGB-D camera, our approach achieved success rates of 0.93, 0.87, and 0.57, respectively, based on 100 test episodes per scenarios, outperforming the baseline TD3 method running in our simulation environment, as summarized in
Table 3.
We extensively tested the open-source program of [
13] in the same simulated environment and recorded its average performance in
Table 3. This baseline method, while achieving similar performance in low-density environments, showed significant performance declines in higher obstacle densities. This performance indicates that our approach not only maintains competitive success rates but also facilitates faster and more efficient navigation, validating its effectiveness in visual target-driven robot navigation tasks under varying dynamic conditions.
6.5. Study on Limited FOV
To investigate the impact of FOV on the robot’s navigation performance, we designed an experiment by progressively cropping the original RGB and depth images to simulate varying FOVs. The original resolutions of the RGB and depth data are 1920
1080 pixels and 1280
720 pixels, respectively. The images were cropped at their borders in 10% increments for both RGB and depth data, as detailed in
Table 4. The experiment was conducted in a simulation environment with eight dynamic obstacles moving in Brownian motion. For each scenario, we evaluated the navigation policy based on success rate and average time, based on 100 test episodes per scenario.
6.6. Ablation Study
To determine the efficacy of various reinforcement learning configurations, we conducted an ablation study comparing three configurations with respect to their learning convergence and reward maximization. The result is shown in
Figure 9.
6.6.1. TD3 + SAN
This configuration exhibited stable convergence throughout the training period. Initially, the reward values progressively increased from −3000, approaching a level of approximately 2000 within the first 90,000 episodes. After this phase, the reward plateaued around 2300, indicative of high performance and long-term stability.
6.6.2. Standalone TD3
Standalone TD3: In contrast, the standalone TD3 algorithm demonstrated faster convergence compared to the TD3 + SAN, with rewards rising from the initial values and stabilizing near 1900. Despite some fluctuations observed between episodes 65,000 and 75,000, the final reward consistently hovered around 1900, suggesting quicker convergence but at a lower reward threshold compared to the TD3 + SAN.
6.6.3. DQN + SAN
The DQN + SAN configuration showed the least favorable outcomes among the three tested configuration. Starting with an initial reward of −3400, it exhibited modest improvement during the first 45,000 episodes before stabilizing at a final reward of approximately 920. This configuration suffered from the highest degree of oscillation and demonstrated substantial instability, marking it as the least effective in this task.
It can be concluded from the ablation study that the TD3 + SAN configuration outperformed the others by achieving the highest final rewards and exhibiting significant training stability, albeit with a slower convergence rate. Conversely, the TD3 algorithm, though converging faster, failed to achieve the higher reward levels of the TD3 + SAN. DQN + SAN displayed considerable instability and underperformance, reinforcing its unsuitability for robust task execution.
6.7. Experiment Using a Real Robot
To validate the proposed visual target-driven navigation approach, real-world experiments were conducted using a mobile robot, as shown in
Figure 10. The robot was equipped with an RGB-D camera, which provided a 70-degree field of view, and operated under ROS Noetic. The experiments were carried out in a 9.5 m × 7 m indoor environment, with the robot and the target positioned at opposite ends of the area. To simulate a dynamic environment, five pedestrians were included, moving at typical walking speeds to represent moving obstacles. The safety cone served as the visual target for the robot.
The failure condition was defined as the robot coming within 6 cm of a human or a wall, as detected by an ultrasonic sensor, to ensure safety. Additionally, if the robot failed to reach the target within 30 s, the trial was considered a failure. The success condition was defined as the robot coming within 15 cm of the target, as detected by the RGB-D camera.
Three distinct scenarios were tested to evaluate the performance of the trained policy: (a) pedestrians standing randomly along the pathway from the robot to the target without movement; (b) pedestrians positioned on either side of the pathway, with some crossing the pathway; and (c) pedestrians positioned on either side of the pathway, with some walking toward the target. The experimental setup is shown in
Figure 11. Each scenario was tested 20 times, and the success rate and average passing time for each trial are summarized in
Table 5.
7. Discussion
7.1. Benefits of TD3 + SAN
In
Figure 8, the incorporation of the SAN led to a significant improvement in performance, particularly in the TD3 + SAN configuration. This improvement can be attributed to the SAN’s ability to enable the robot to dynamically focus on relevant information and recover lost targets when the target temporarily leaves its FOV. By leveraging past observations and capturing global contextual relationships, the SAN helps the robot infer the target’s approximate position and resume tracking effectively. Specifically, the SAN offers two key advantages:
Target Recovery and Tracking: Through its relational reasoning capability, the SAN correlates spatial and temporal patterns in previous observations, allowing the robot to infer the target’s location even in scenarios with occlusions or limited visibility.
Dynamic Focus on Critical Regions: The mechanism of the SAN enables the robot to dynamically assign importance weights to different regions in the observation space. This allows the robot to prioritize target- and obstacle-related information, enhancing decision-making under uncertainty.
Compared to traditional approaches, the SAN improves the robot’s robustness to partial observability, reduces instability, and ensures smoother navigation trajectories. These advantages are evident in the TD3 + SAN results, where the robot achieved higher rewards and greater long-term stability than TD3 alone.
7.2. Overcoming the Challenge of Limited FOV
In visual target-driven crowd navigation, the limited FOV often causes the target to be lost, hindering navigation performance. Our method integrates the SAN, which leverages information from past frames to help the robot recover and track the target effectively. Additionally, we utilize the TD3 algorithm, which is particularly well suited for handling continuous action spaces, to enable the robot to efficiently navigate and reach the target. TD3’s Actor-Critic mechanism, along with its key features of target value smoothing and delayed updates, ensures stable learning, allowing the robot to adapt to dynamic crowd environments even with a limited FOV. Moreover, our reward function design of camera view reward and target position reward effectively encourages the robot to keep the target within its view.
The results of the TD3 + SAN demonstrate that the combination of the SAN and TD3 enhances the robot’s robustness and navigation performance under limited FOV conditions, validating the effectiveness of our approach.
7.3. Collaborate Training of CNN, SAN, and TD3 for Better Performance
The experimental results are shown in
Figure 9. The TD3 + SAN demonstrates significant advantages in dynamic and crowded environments with limited field of view. Compared to traditional TD3 and DQN + SAN, the TD3 + SAN converges to a higher average reward more quickly, exhibits better stability, and achieves significantly better final reward values. This indicates that the collaborative optimization of the CNN and SAN effectively utilizes both visual and temporal features, compensating for the perception limitations due to the restricted field of view, while enhancing decision-making robustness and performance in complex interaction scenarios.
7.4. Performance in Real Deployment
In the simulation environment, experiments were conducted on two scenarios: Brownian motion and crossing. The success rate for crossing was lower than that for Brownian motion, primarily because the robot is often surrounded by obstacles during crossing. In real-world deployment, simulating Brownian motion is not feasible. Instead, experiments were conducted on crossing and approaching scenarios. Unlike in the simulation, human movement speeds are variable, as individuals may move faster or slower, further reducing the robot’s success rate. In the approaching scenario, obstacles frequently formed a “wall” around the robot, causing it to lose track of the target. The robot often failed to recover the target before timing out, which significantly impacted its success rate.
8. Conclusions
In this study, we proposed a new visual target-driven navigation strategy for robots operating in crowded and dynamic environments with a limited FOV. Our approach utilizes the TD3 algorithm and integrates the SAN, enabling effective navigation without the need for pre-mapped environments.
Our contributions offer meaningful advancements in the field of autonomous robotic navigation. Firstly, we successfully reduced hardware and computational requirements by employing a single RGB-D camera, thereby simplifying the system’s architecture, and lowering the overall cost and complexity. Secondly, the incorporation of a SAN enabled our system to maintain awareness of the navigation target even with a limited sensory field, enhancing the robot’s ability to relocate and track dynamic targets efficiently. Finally, the robust performance of our approach was demonstrated through extensive simulation and real robot experiments, which showed superior navigation capabilities in terms of both obstacle avoidance and target pursuit in complex environments.
The experimental results validated that our model outperforms traditional DRL-based methods in dynamic environments, achieving higher success rates and shorter average target-reaching times. Notably, our method exhibited greater adaptability to changes within the environment, proving particularly effective in real-world scenarios where unpredictability and the presence of dynamic obstacles are common.
In future work, we plan to systematically investigate the impact of hardware configurations on the performance of the proposed navigation policy across various scenarios. For example, a lower camera resolution may reduce the system’s accuracy in detecting targets and obstacles, thereby negatively affecting navigation performance and success rates. Future research could focus on developing adaptive policies that dynamically adjust to varying hardware constraints or explore hardware augmentation strategies to enhance the robustness and reliability of navigation in complex and dynamic environments.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}