Abstract
Generative adversarial networks (GANs) typically require large datasets for effective training, which poses challenges for volumetric medical imaging tasks where data are scarce. This study addresses this limitation by extending adaptive discriminator augmentation (ADA) for three-dimensional (3D) StyleGAN2 to improve generative performance on limited volumetric data. The proposed 3D StyleGAN2-ADA redefines all 2D operations for volumetric processing and incorporates the full set of original augmentation techniques. Experiments are conducted on the NoduleMNIST3D dataset of lung CT scans containing 590 voxel-based samples across two classes. Two augmentation pipelines are evaluated—one using color-based transformations and another employing a comprehensive set of 3D augmentations including geometric, filtering, and corruption augmentations. Performance is compared against the same network and dataset without any augmentations at all by assessing generation quality with Kernel Inception Distance (KID) and 3D Structural Similarity Index Measure (SSIM). Results show that volumetric ADA substantially improves training stability and reduces the risk of a mode collapse, even under severe data constraints. A strong augmentation strategy improves the realism of generated 3D samples and better preserves anatomical structures relative to those without data augmentation. These findings demonstrate that adaptive 3D augmentations effectively enable high-quality synthetic medical image generation from extremely limited volumetric datasets. The source code and the weights of the networks are available in the GitHub repository.
1. Introduction
Computer vision in medical imaging is widely used to build decision-support systems for diagnosis and initial analysis [1,2]. There are many challenges in obtaining sufficient data and de-identifying patient data. Those problems become even more critical in terms of 3D (volumetric) data [3]. In this paper, we investigate the feasibility and effectiveness of applying StyleGAN2-ADA adapted for 3D datasets with a limited number of 3D images. Generative adversarial networks (GANs) are a machine learning framework in which two neural networks (generator, G, and discriminator, D) compete against each other in a zero-sum game. The goal of the discriminator is to distinguish real images from the synthetic images produced by the generator. The goal of the generator is to produce realistic images. The original GAN architecture was introduced in 2014 by Ian Goodfellow et al. [4] and has undergone multiple improvements and modifications since then. In this research we concentrate on StyleGAN2-ADA introduced by T. Karras et al. in 2020 [5], as one of its key features is the ability to successfully train on small datasets. Adaptive Discriminator Augmentation (ADA) is a training strategy that combats discriminator over-fitting. Rather than choosing a fixed augmentation pipeline, ADA adaptively adjusts the augmentation probability P based on the discriminator’s behavior. It monitors the proportion of real training images that receive positive discriminator outputs. If the proportion becomes too high, P is increased. If the proportion decreases, P is lowered accordingly.
The manuscript is organized as follows. Section 1 provides introduction and the overview of related works and the usage of the GAN in medical imaging. Section 2 describes the 3D dataset used for the experiments, 3D network architecture, implemented augmentations, and the training process. Additionally, in Section 2, we provide a brief explanation of the quality evaluation metrics, along with example results. Then in Section 3 we present the final findings and ideas for the future research. Our main contributions are as follows:
- StyleGAN2-ADA PyTorch adaptation for 3D data with all augmentation methods of the base implementation adapted to work with 3D data.
- An empirical evaluation of the adapted network across varying augmentation settings (full augmentation set, color-only augmentations, and no augmentations at all) for the balanced dataset containing 590 3D images of CT scans of lung nodules. The metrics used in evaluation are Kernel Inception Distance and 3D Structural Similarity Index Measure calculated on the generated and original objects.
- A comparative analysis using established image-synthesis metrics between three different augmentation scenarios.
Related Works
The usage of a GAN to generate medical data is a promising field of research. Often combined with downstream tasks like classification and detection, it is applied to different types of data—such as brain tumor MR images [6], dermatoscopic images [7], retinal fundus data [8], chest X-rays [9,10,11], and colonoscopy frames [12]. The slice-wise approach is also often used due to small computational resources requirements, for example, in rib segmentation on X-ray slices [11] or synthetic CT reconstruction from MR slices [13]. The main challenge remains in combining the generated slices into the final 3D form while preserving medical features. Three-dimensional convolutional GANs are also widely used with different types of data, including applications in urogenital imaging [14] and hybrid augmentation pipelines for lesion classification [12]. The adaptation of StyleGAN2-ADA for 3D medical imaging was explored by Hong et al. in [15], but ADA itself was not used in their published experiments. Although a public repository [16] associated with that work provides a partial implementation of 3D augmentations, these augmentations were not employed in the paper, and only a limited subset of simple transformations is actually enabled in the code. Most geometric operations (e.g., flipping, rotation, translation, scaling, cutout) and advanced filtering augmentations are disabled or not adapted for 3D, leaving primarily basic color adjustments and noise injection. In contrast, our implementation is based on the official PyTorch codebase [17] and incorporates the full set of ADA mechanisms adapted for 3D.
The recent surge in applications of vision transformers and diffusion models to 3D medical imaging demonstrates promising developments in the field; however, data scarcity remains one of the most significant obstacles to future progress [6,18,19,20,21]. Diffusion models have shown strong potential in medical imaging, particularly for denoising, reconstruction, and synthetic data generation [22]. Their ability to capture complex distributions has been applied to MRI and CT, often outperforming GANs in sample fidelity [23]. Moreover, hybrids combining diffusion with vision transformers are emerging; for example, adversarial diffusion networks enhanced with Local Vision Transformers for MRI reconstruction [24] and transformer-based diffusion frameworks for segmentation [25]. However, both of those new architectures require vast training samples to fully realize their potential.
2. Materials and Methods
2.1. Dataset
We use NoduleMNIST3D [26] from MedMNIST benchmark dataset. The dataset contains 1633 objects representing computed tomography (CT) scans of lung nodules. The dataset is split into 3 subsets—training, containing 1158 objects; validation, containing 165 objects; and testing, containing 310 objects. The dataset is divided into two classes by the level of malignancy of the nodules. Class 0 (negative) contains nodules with malignancy levels 1 or 2; class 1 contains malignancy levels 4 or 5.
The training set of the NoduleMNIST3D dataset is not balanced—out of 1158 objects there are 863 objects of class 0 and 295 objects of class 1. The randomly selected 568 objects of class 0 were removed from the dataset. This serves two purposes—balancing the dataset and reducing the total amount of available training data to better simulate a limited data availability scenario.
The images are spatially normalized to 1 × 1 × 1 mm voxel spacing. A center-crop cube of voxels around each nodule was downsampled to and then upsampled to [27,28]. Due to memory constraints of the utilised NVIDIA A100 GPUs, for training we have downsampled them to size. Each image representing a nodule was stored as PyTorch tensor with shape of 32 × 32 × 32 and data-range 0–255.
A total of 295 images of each class are used for training of the networks (590 training images in total). The middle slices of an example object from the dataset are represented in Figure 1.

Figure 1.
Middle slices along each principal axis of a lung-nodule volumetric object from the training dataset.
2.2. Networks
Our solution is based on the official PyTorch implementation of StyleGAN2-ADA with original generator and discriminator architectures. We replaced all 2D convolution layers, resampling and gradfix operations with 3D counterparts. We closely follow the original implementation in selection of architecture details like convolutional kernel sizes, stride configurations, weights demodulation, and regularization, expanding to third dimension when necessary retaining observed symmetry. The mapping network remained the same as in the base 2D implementation. The StyleGAN2 loss function was adjusted to work with 3D images instead of 2D ones. Depth dimension (D) was added to gradient penalty. Noise normalization in path length regularization was modified to divide by instead of .
The base implementation provides heuristics to decide which PyTorch memory format should be used (contiguous or channels last). We removed these heuristics in favor of channels last as the default memory format for both forward and backward passes.
The source code of the implementation used during the experiments is available at the GitHub repository: https://github.com/fedorukol/3d-stylegan2-ada (accessed on 1 December 2025).
2.3. Augmentations
All two-dimensional methods of the augmentation pipeline from the base implementation were adapted to operate on volumetric data. These include the following:
- Pixel-level editing—horizontal flipping along the sagittal axis, random rotations in the axial plane, and integer translations along the sagittal, coronal, and axial axes.
- Geometric transformations—isotropic scaling, arbitrary rotations, anisotropic scaling, and fractional translations.
- Color transformations—adjustments to brightness, saturation, and contrast; luma inversion; and hue rotation.
- Image-space filtering—filtering by amplification or suppression of the frequency content in different bands.
- Image corruptions—cutouts of parts of the images and application of Gaussian noise.
2.4. Training
We compare three augmentations pipelines: no augmentations at all, color-only augmentations, and strong augmentations with all transformations enabled. All three networks are trained with the same set of hyperparameters that were selected for providing the best results after several experimental runs. Each network is trained to generate two classes from the original dataset.
The generator and discriminator are trained using the Adam optimizer with learning rates set to 0.002 and parameters , . Following the recommendation in the StyleGAN2-ADA publication, the value for regularization is selected empirically by testing multiple values. It was set to 10 initially; however, the network produced blurry images. The value was then reduced to 5, 1, , and , with used in the final training. A very small value () was also tested, but the network failed to train and produced random noise without signs of improvement. The batch size is set to 16, and the ADA target to .
All networks are trained for 300 kimg, where kimg denotes the number of thousands of images processed over subsequent training epochs. In other words, the models see a total of 300,000 images. This training schedule requires approximately 36 h on an NVIDIA A100 GPU.
2.5. Quality Evaluation and Metrics
We use several image quality metrics to assess the quality of the produced results. Kernel Inception Distance (KID) [29] measures the squared Maximum Mean Discrepancy (MMD) between feature representations of real and generated images extracted from a pretrained Inception network, using a polynomial kernel. Lower KID values indicate that the distribution of generated images is closer to that of the real images. In our experiments, KID is calculated on the middle-depth slices of the images for each tick (which corresponds to approximately 4000 images seen by the discriminator of the network).
The best epoch for a given training process is picked on the basis of the KID curve smoothed with a moving-average filter. We compute a moving average over a fixed window of 5 checkpoints with tolerance to obtain a more stable estimate of model performance. The epoch corresponding to the minimum of this smoothed KID curve is then selected as the best model snapshot, providing a robust criterion that reduces sensitivity to metric fluctuations and mitigates the risk of overfitting late in training.
For the selected network state snapshot, we evaluate each strategy based on 3D Structural Similarity Index Measure (SSIM) [30], a metric commonly used in the literature [15]. We use a cubic Gaussian window of size with standard deviation in all three spatial dimensions, and the standard SSIM stability constants and with .
SSIM quantifies how structurally similar two samples are by comparing their local patterns of intensity, contrast, and texture within a 3D neighborhood window. A higher SSIM value indicates that the two volumes share more consistent spatial structure and therefore appear more alike [31]. To access the similarity between the original and generated nodules we calculate 3D SSIM for each pair of original objects from the training set. We also calculate it for each pair between original and generated objects. The calculated values are plotted on the histograms where bigger overlap means more similar objects.
3. Results
3.1. Findings
We observe that stronger augmentation ensures a better level of training stability in the 3D-adapted network. While color augmentation pipeline demonstrates a promising start, it is not enough to continue improving the generator as it is visible in Figure 2. After around 120,000 images shown to discriminator, the quality of generated samples starts to reduce. A similar scenario happens with the training without any augmentations. The KID value steadily decreases until a point where the discriminator starts to overfit and the generator starts to produce noisy images that are frozen into a small set of outputs, which could indicate an early stages of mode collapse. This behavior is visible at Figure 3 where most of the objects contain a similar single nodule.
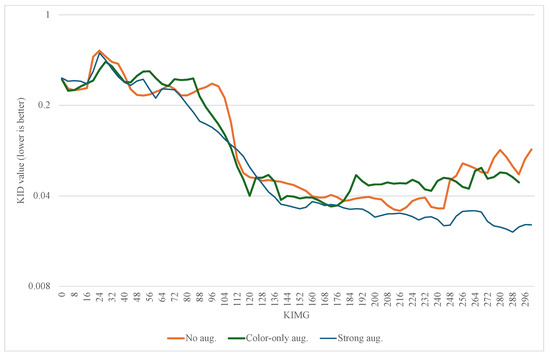
Figure 2.
Mean value of KID for class 0 and class 1.
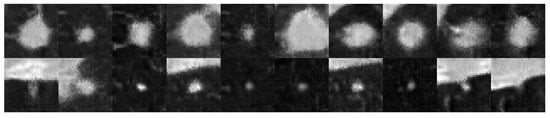
Figure 3.
Middle slices of a lung nodule volumetric object generated by the network without ADA enabled. (Top row) contains images of the Class 0, (bottom row) contains images of the Class 1.
The examples of the objects of both classes generated with the best snapshots of the networks without any, color-only, and strong augmentations are displayed on Figure 4, Figure 5, and Figure 6, respectively.

Figure 4.
Middle slices along each principal axis for two lung-nodule volumetric objects generated by the best snapshot of the adapted StyleGAN2-ADA without augmentations: (a,b) show two representative examples.

Figure 5.
Middle slices along each principal axis for two lung-nodule volumetric objects generated by the best snapshot of the adapted StyleGAN2-ADA with color-only augmentations: (a,b) show two representative examples.

Figure 6.
Middle slices along each principal axis for two lung-nodule volumetric objects generated by the best snapshot of the adapted StyleGAN2-ADA with strong augmentations: (a,b) show two representative examples.
The evolution of the KID metrics for the no augmentation, color-only augmentation, and the strong augmentation is presented in Figure 2.
The histograms of SSIM values for no augmentation, color-only augmentation, and the strong augmentation are presented in (Figure 7a,b), the 3D adapted network with color-only augmentation (Figure 7c,d), and the 3D adapted network with strong augmentation (Figure 7e,f), respectively.
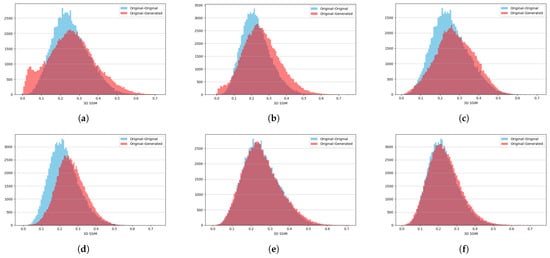
Figure 7.
Three-dimensional SSIM histograms for the two object classes under three different training settings: (a,b) No augmentations for Class 0 and Class 1. (c,d) Color-only augmentation for Class 0 and Class 1. (e,f) Strong augmentation for Class 0 and Class 1.
3.2. Discussion
We introduce for the first time, a full set of 3D augmentation methods for ADA and successfully use it on limited medical imaging dataset. We demonstrate that the application of full set of augmentation techniques used in the 3D ADA pipeline makes it possible to train volumetric GANs on very small datasets. Moreover, it allows avoiding overfitting and mode collapse which are the main reasons why GANs are harder to train on small datasets. The styling mechanism incorporated into the StyleGAN architectures allows successful training for both classes and generates diverse and realistic output.
While achieved results are promising, there are several important topics to be considered. Full augmentation pipeline with all possible augmentation mechanisms could not be applied to every dataset—some volumetric features are not compatible with some augmentations. For example, data flips could not be used with chest PET scans, as they risk producing images in which the heart (and other organs) appear in anatomically incorrect positions [32]. This limitation reduces possible cases where such an approach could be applied.
Important limitation of our current implementation is its memory footprint. Due to memory constraints of the NVIDIA A100 GPUs, we reduced the image size considered in the research to . However, with increasing sizes of VRAM in recent GPU architectures and possible optimizations to our implementation the proposed approach could be applied to larger resolutions.
3.3. Future Research
The quality of the generated images may be constrained when compared with more recent architectures such as vision transformers, which remain computationally demanding and particularly challenging to scale in three-dimensional settings. Future research will focus on extending the present findings to such architectures, examining diffusion-based models and/or vision transformers that offer higher generative quality but with reduced computational efficiency [33], and further reducing the cost of generating volumetric objects under low-data conditions.
Introduction of diffusion models and visual transformers opened new ways of graphical data generation with great results. We believe it is possible to incorporate achievements of those architectures in volumetric low-data scenarios by combining them with the introduced ADA methods. Finally, we plan to include downstream tasks like classification to additionally validate the findings.
Author Contributions
Conceptualization, O.F. and K.K.; methodology, O.F.; software, O.F.; validation, O.F., K.K. and M.K.; formal analysis, K.K.; investigation, O.F. and K.K.; resources, O.F.; data curation, O.F.; writing—original draft preparation, O.F.; writing—review and editing, K.K. and M.K.; visualization, O.F.; supervision, K.K. and M.K.; project administration, K.K. and M.K.; funding acquisition, K.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. We used the NoduleMNIST3D dataset from the MedMNIST collection, which is openly accessible at https://medmnist.com/ (accessed on 1 December 2025).
Acknowledgments
We gratefully acknowledge Polish high-performance computing infrastructure PLGrid (HPC Center: ACK Cyfronet AGH) for providing computer facilities and support within computational grant no. PLG/2024/017410.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Khan, W.; Leem, S.; See, K.B.; Wong, J.K.; Zhang, S.; Fang, R. A Comprehensive Survey of Foundation Models in Medicine. IEEE Rev. Biomed. Eng. 2025; online ahead of print. [Google Scholar] [CrossRef]
- Dorfner, F.J.; Patel, J.B.; Kalpathy-Cramer, J.; Gerstner, E.R.; Bridge, C.P. A review of deep learning for brain tumor analysis in MRI. npj Precis. Oncol. 2025, 9, 2. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.P.; Wang, L.; Gupta, S.; Goli, H.; Padmanabhan, P.; Gulyás, B. 3D deep learning on medical images: A review. Sensors 2020, 20, 5097. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems 27 (NeurIPS 2014); Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Montreal, QC, Canada, 2014; pp. 2672–2680. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training Generative Adversarial Networks with Limited Data. In Advances in Neural Information Processing Systems 33 (NeurIPS 2020); Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.-F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020. [Google Scholar]
- Akbar, M.U.; Larsson, M.; Blystad, I.; Eklund, A. Brain tumor segmentation using synthetic MR images—A comparison of GANs and diffusion models. Sci. Data 2024, 11, 259. [Google Scholar] [CrossRef] [PubMed]
- Mekala, R.R.; Pahde, F.; Baur, S.; Chandrashekar, S.; Diep, M.; Wenzel, M.; Wisotzky, E.L.; Yolcu, G.Ü.; Lapuschkin, S.; Ma, J.; et al. Synthetic Generation of Dermatoscopic Images with GAN and Closed-Form Factorization. In Computer Vision—ECCV 2024 Workshops; Del Bue, A., Canton, C., Pont-Tuset, J., Tommasi, T., Eds.; Springer: Cham, Switzerland, 2025; pp. 368–384. [Google Scholar]
- Liu, J.; Xu, S.; He, P.; Wu, S.; Luo, X.; Deng, Y.; Huang, H. VSG-GAN: A high-fidelity image synthesis method with semantic manipulation in retinal fundus image. Biophys. J. 2024, 123, 2815–2829. [Google Scholar] [CrossRef] [PubMed]
- Fedoruk, O.; Klimaszewski, K.; Ogonowski, A.; Kruk, M. Additional look into GAN-based augmentation for deep learning COVID-19 image classification. Mach. Graph. Vis. 2023, 32, 107–124. [Google Scholar] [CrossRef]
- Bahani, M.; El Ouaazizi, A.; Avram, R.; Maalmi, K. Enhancing chest X-ray diagnosis with text-to-image generation: A data augmentation case study. Displays 2024, 83, 102735. [Google Scholar] [CrossRef]
- Huang, L.; Ma, D.; Zhao, X.; Li, C.; Zhao, H.; Tang, J.; Li, C. Semantics guided disentangled GAN for chest X-ray image rib segmentation. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV 2024), Urumqi, China, 18–20 October 2024. [Google Scholar] [CrossRef]
- Golhar, M.V.; Bobrow, T.L.; Ngamruengphong, S.; Durr, N.J. GAN inversion for data augmentation to improve colonoscopy lesion classification. IEEE J. Biomed. Health Inform. 2025, 29, 3864–3873. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zhao, Y.; Court, L.E.; Wang, H.; Pan, T.; Phan, J.; Wang, X.; Ding, Y.; Yang, J. SC-GAN: Structure-completion generative adversarial network for synthetic CT generation from MR images with truncated anatomy. Comput. Med. Imaging Graph. 2024, 113, 102353. [Google Scholar] [CrossRef] [PubMed]
- Van Booven, D.J.; Chen, C.-B.; Malpani, S.; Mirzabeigi, Y.; Mohammadi, M.; Wang, Y.; Kryvenko, O.N.; Punnen, S.; Arora, H. Synthetic Genitourinary Image Synthesis via Generative Adversarial Networks: Enhancing Artificial Intelligence Diagnostic Precision. J. Pers. Med. 2024, 14, 703. [Google Scholar] [CrossRef] [PubMed]
- Hong, S.; Marinescu, R.; Dalca, A.V.; Bonkhoff, A.K.; Bretzner, M.; Rost, N.S.; Golland, P. 3D-StyleGAN: A style-based generative adversarial network for generative modeling of three-dimensional medical images. In Deep Generative Models, and Data Augmentation, Labelling, and Imperfections (DGM4MICCAI 2021, DALI 2021), MICCAI Workshops; Engelhardt, S., Oksuz, I., Zhu, D., Yuan, Y., Mukhopadhyay, A., Heller, N., Huang, S.X., Nguyen, H., Sznitman, R., Xue, Y., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2021; Volume 13003, pp. 24–34. [Google Scholar] [CrossRef]
- Hong, S. 3D-StyleGAN2-ADA: Unofficial PyTorch Implementation with Partial 3D Augmentations. GitHub Repository. 2021. Available online: https://github.com/sh4174/3d-stylegan2-ada (accessed on 15 November 2025).
- StyleGAN2-ADA—Official PyTorch Implementation. Available online: https://github.com/NVlabs/stylegan2-ada-pytorch (accessed on 5 October 2025).
- Angermann, C.; Bereiter-Payr, J.; Stock, K.; Degenhart, G.; Haltmeier, M. Three-Dimensional Bone-Image Synthesis with Generative Adversarial Networks. J. Imaging 2024, 10, 318. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Hang, Y.; Wu, F.; Wang, S.; Hong, Y. Super-resolution of 3D medical images by generative adversarial networks with long and short-term memory and attention. Sci. Rep. 2025, 15, 20828. [Google Scholar] [CrossRef] [PubMed]
- Vellmer, S.; Aydogan, D.B.; Roine, T.; Cacciola, A.; Picht, T.; Fekonja, L.S. Diffusion MRI GAN synthesizing fibre orientation distribution data using generative adversarial networks. Commun. Biol. 2025, 8, 512. [Google Scholar] [CrossRef] [PubMed]
- Aydin, O.U.; Hilbert, A.; Koch, A.; Lohrke, F.; Rieger, J.; Tanioka, S.; Frey, D. Generative modeling of the Circle of Willis using 3D-StyleGAN. NeuroImage 2024, 304, 120936. [Google Scholar] [CrossRef] [PubMed]
- Kazerouni, A.; Aghdam, E.K.; Heidari, M.; Azad, R.; Fayyaz, M.; Hacihaliloglu, I.; Merhof, D. Diffusion models in medical imaging: A comprehensive survey. Med. Image Anal. 2023, 88, 102846. [Google Scholar] [CrossRef] [PubMed]
- Wolleb, J.; Bieder, F.; Sandkühler, R.; Cattin, P.C. Diffusion Models for Medical Anomaly Detection. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2022; Wang, L., Dou, Q., Fletcher, P.T., Speidel, S., Li, S., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13438, pp. 35–45. [Google Scholar] [CrossRef]
- Zhao, X.; Yang, T.; Li, B.; Yang, A.; Yan, Y.; Jiao, C. DiffGAN: An adversarial diffusion model with local transformer for MRI reconstruction. Magn. Reson. Imaging 2024, 109, 108–119. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Ji, W.; Fu, H.; Xu, M.; Jin, Y.; Xu, Y. MedSegDiff-V2: Diffusion-based medical image segmentation with transformer. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI-24), Vancouver, BC, Canada, 20–27 February 2024; pp. 6030–6038. [Google Scholar]
- Armato, S.G., III; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Zhao, B.; Aberle, D.R.; Henschke, C.I.; Hoffman, E.A.; et al. The Lung Image Database Consortium (LIDC) and Image Database Resource Initiative (IDRI): A completed reference database of lung nodules on CT scans. Med. Phys. 2011, 38, 915–931. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Shi, R.; Wei, D.; Liu, Z.; Zhao, L.; Ke, B.; Pfister, H.; Ni, B. MedMNIST v2—A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification. Sci. Data 2023, 10, 41. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Shi, R.; Ni, B. MedMNIST classification decathlon: A lightweight AutoML benchmark for medical image analysis. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 191–195. [Google Scholar] [CrossRef]
- Bińkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying MMD GANs. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zeng, K.; Wang, Z. 3D-SSIM for video quality assessment. In Proceedings of the 19th IEEE International Conference on Image Processing (ICIP), Orlando, FL, USA, 30 September–3 October 2012; pp. 621–624. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Kebaili, A.; Lapuyade-Lahorgue, J.; Ruan, S. Deep learning approaches for data augmentation in medical imaging: A review. J. Imaging 2023, 9, 81. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtual Event, 3–7 May 2021; Available online: https://openreview.net/forum?id=YicbFdNTTy (accessed on 11 October 2025).







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).