
A Dual-Channel and Frequency-Aware Approach for Lightweight Video Instance Segmentation


Abstract
1. Introduction
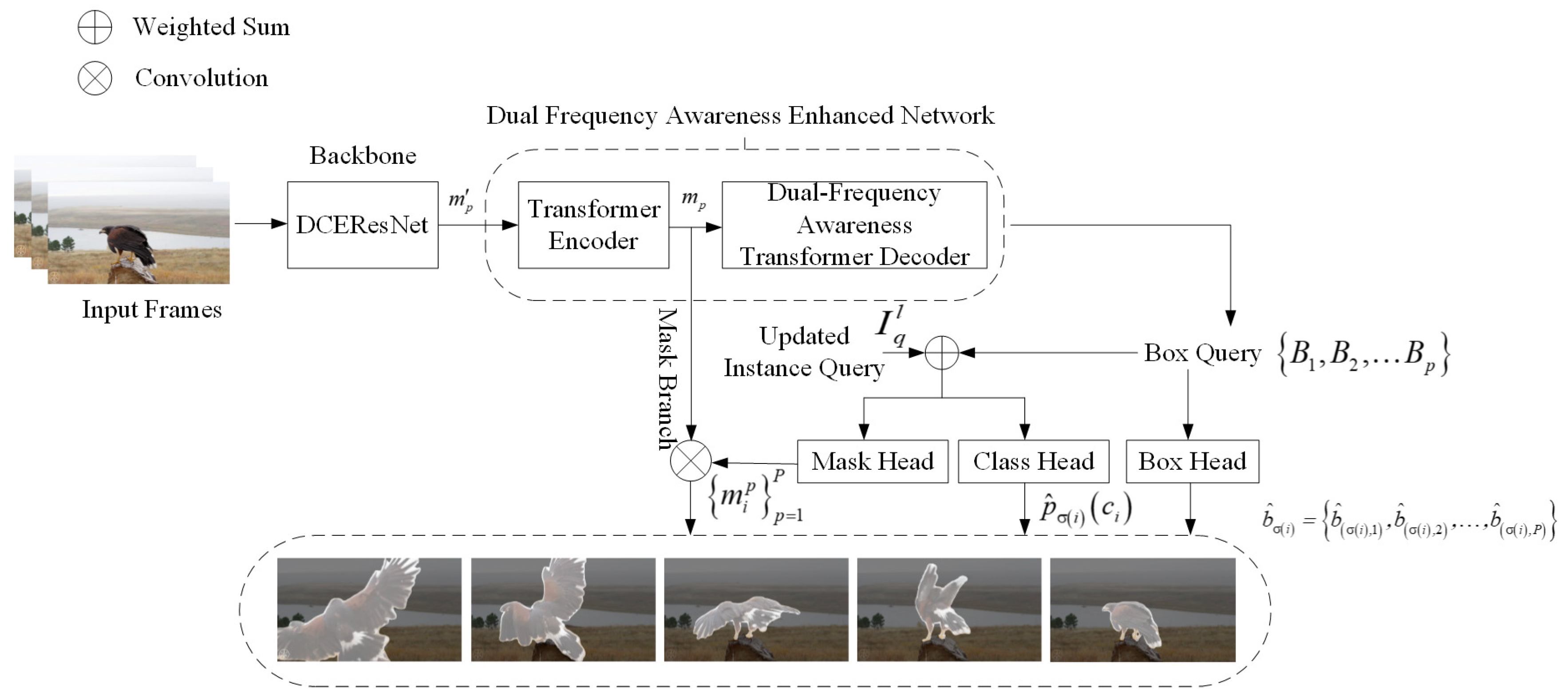
- The DCFA-LVIS model introduced in this work offers a streamlined and effective end-to-end system that processes an input video, regardless of its length, and simultaneously generates the classification, frame sequence, and mask sequence. This approach eliminates the need for separate tracking components or manual post-processing, effectively preventing the risk of error accumulation.
- The DCFA-LVIS approach demonstrated in this study shows notable improvements when evaluated on the YouTube-VIS 2019 benchmark. These enhancements are evident across various metrics, including average accuracy (AP), average completeness (AR), model parameter count, and detection rate (FPS).
- The DCEResNet backbone in the DCFA-LVIS model effectively captures the temporal features of the video using a dual-channel feature enhancement mechanism. At the same time, it controls the number of parameters and computational complexity.
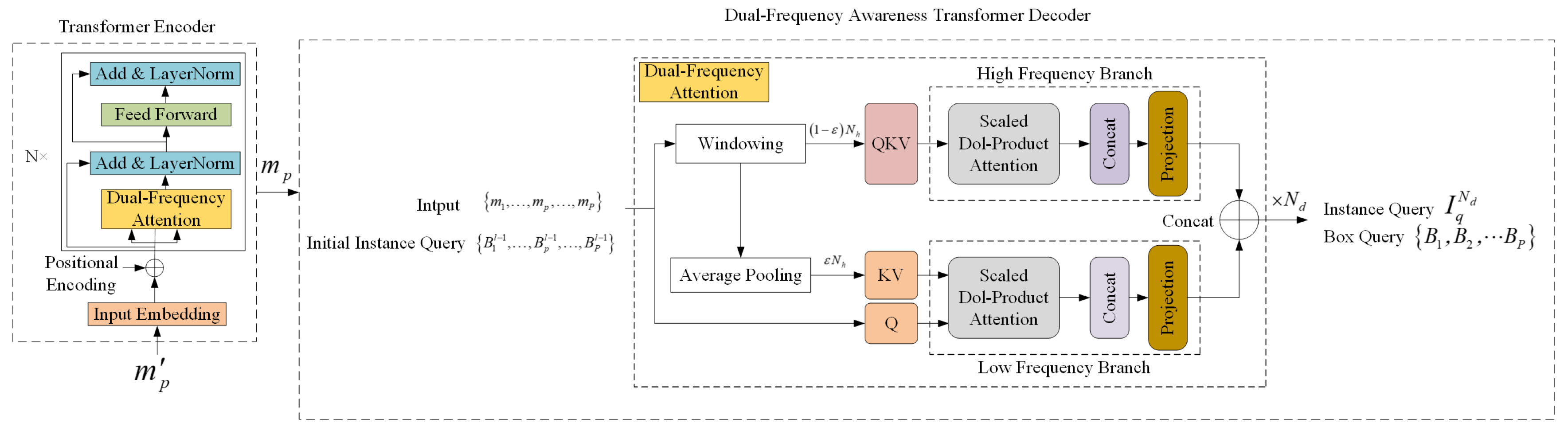
- The Dual Frequency Awareness Enhanced Network Module in the DCFA-LVIS model proposed in this paper introduces the Dual Frequency Awareness Transformer Decoder. This decoder employs an innovative instance-tracking mechanism that focuses on the motion trajectories of instances, enabling the learning of rich instance sequence representations. By utilizing frame-level feature queries, the model ensures that the attention mechanism consistently focuses on the same instance across frames, effectively aggregating information across the entire video and enhancing global feature learning. The decoder processes high-frequency and low-frequency information in separate layers, reducing computational complexity, minimizing overhead, and improving speed while lowering memory consumption. This ensures outstanding performance under lightweight conditions.
2. Related Work
2.1. Image Instance Segmentation
2.2. Video Instance Segmentation
2.3. Transformers
3. Methodology
3.1. The Comprehensive Framework of DCFA-LVIS
3.1.1. Backbone: DCEResNet
3.1.2. Dual Frequency Awareness Enhanced Network Module
3.1.3. Output Heads Setting
3.2. Matching of Instance Sequences and Associated Loss Calculation
4. Experimental Results and Analysis
4.1. Datasets and Metrics
4.2. Implementation Details
4.2.1. Model Settings
4.2.2. Training
4.2.3. Inference
4.3. Main Results
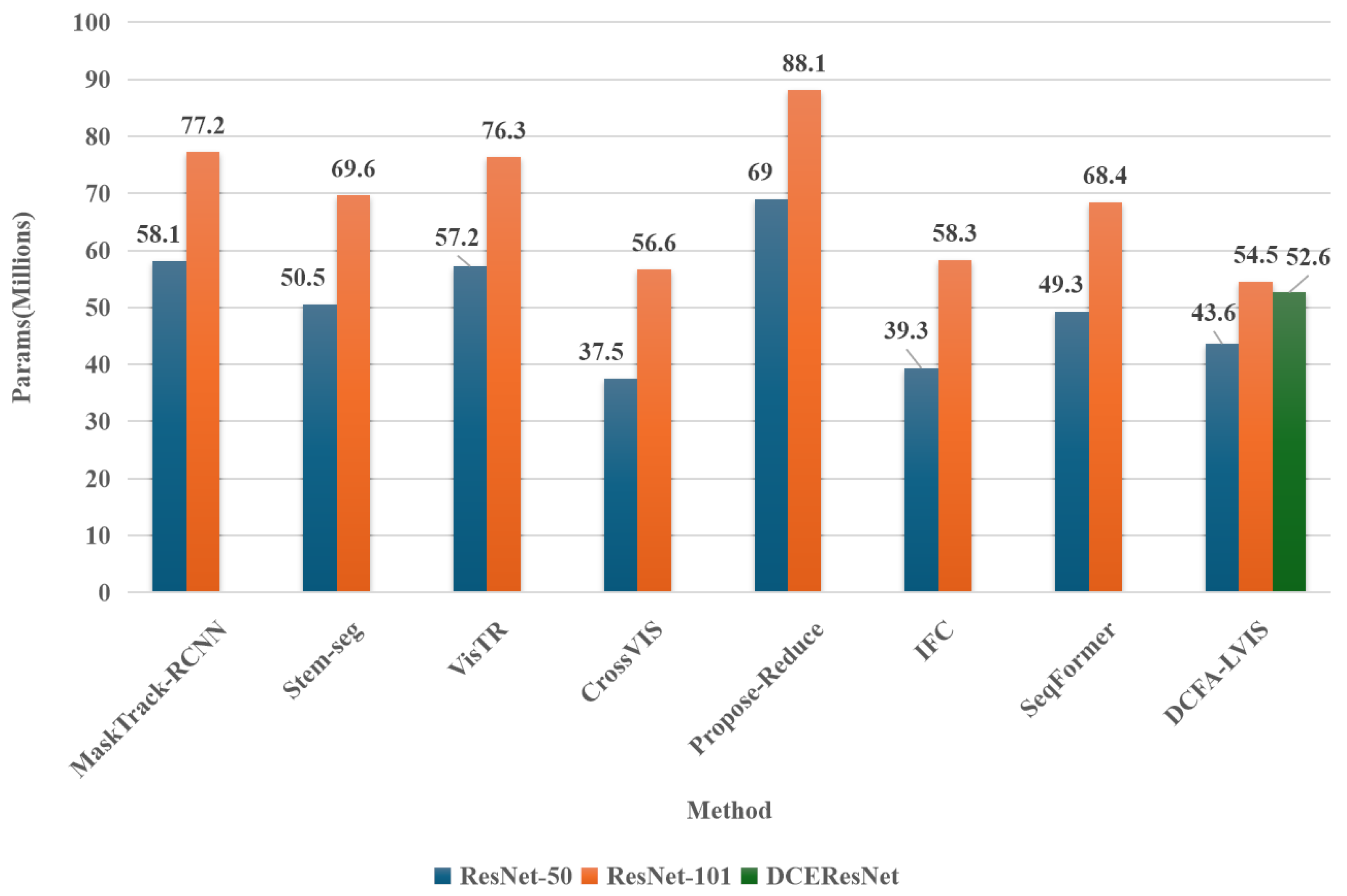
- Performance with ResNet-50 Backbone
- Model with the lowest parameter count: SipMask has the lowest parameter count (33.2 M), with an FPS of 30.0 and an AP of 33.5%. In contrast, the DCFA-LVIS model proposed in this paper, despite a 31% increase in parameters, achieves a 145% improvement in FPS and a 44% increase in AP, showing a significant enhancement in both speed and accuracy.
- Model with the highest FPS: IFC achieves the highest FPS (107.1) with 39.3 M parameters and an AP of 42.6%. Compared to this, DCFA-LVIS improves AP by 13%, adds 10.9% more parameters, but experiences a 45.7% reduction in segmentation speed.
- Model with the highest AP: DCFA-LVIS achieves the highest AP (48.3%), demonstrating significant advantages in segmentation accuracy.
- Performance with ResNet-101 Backbone
- Optimal model in terms of parameters and accuracy: DCFA-LVIS achieves 54.5 M parameters and an AP of 49.9%, showing the best parameter efficiency and segmentation accuracy with ResNet-101.
- Model with the highest FPS: IFC achieves the highest FPS (89.4%), with 58.3 M parameters and an AP of 44.4%. In comparison, DCFA-LVIS improves AP by 12.4%, reduces parameters by 6.9%, but experiences a 37% decrease in segmentation speed. Notably, as the backbone depth increases, IFC’s performance advantage diminishes significantly (FPS decreases by 19.7%, parameters increase by 48.3%). In contrast, DCFA-LVIS demonstrates better robustness (FPS decreases by only 13%, parameters increase by 25%, and AP remains high at 49.9%), effectively balancing accuracy and speed when handling large video datasets.
- Performance with DCEResNet Backbone
- When using DCEResNet as the backbone, DCFA-LVIS achieves 52.6 M parameters, 65.9 FPS, and an AP of 50.1%. These results validate the comprehensive advantages of the proposed method in terms of accuracy, speed, and parameter efficiency.
- Instances with complex motions (first row): In this scenario, multiple instances exhibit significant motion variations. DCFA-LVIS can precisely capture and track the details of each instance. Despite the complexity of the motions, the masks for each instance remain highly consistent, showcasing their outstanding performance.
- Indistinguishable similar backgrounds (second row): When the background and foreground are highly similar, it is typically difficult to accurately segment the instances. However, DCFA-LVIS successfully segments the foreground instances, avoiding background interference, and demonstrating its exceptional discrimination capability in complex backgrounds.
- Reappearance of occluded instances (third row): After instances are partially or completely occluded, many models may fail to continue tracking them accurately. DCFA-LVIS, however, can accurately resume tracking and segmentation when the instances reappear, highlighting its strong occlusion recovery ability.
- Instances with rapid movements (fourth row): Rapid movements often result in motion blur and deformation, presenting significant challenges for segmentation. DCFA-LVIS maintains precise segmentation even under high-speed motion, proving its efficiency in handling dynamic scenes.
- Instances in multi-object scenes (fifth row): In multi-object scenes where multiple instances exist simultaneously and interfere with each other, the model needs to have strong instance differentiation and tracking capabilities. DCFA-LVIS is able to accurately distinguish between different instances in such complex environments and maintain efficient tracking and segmentation between instances, demonstrating its superior performance in handling multi-object interaction scenarios.
- Segmentation detail accuracy: When handling complex backgrounds or intricate structures, VisTR, IFC, and SeqFormer often exhibit blurred edges or loss of detail. In contrast, DCFA-LVIS demonstrates superior precision in capturing these details, maintaining edge clarity and integrity, particularly excelling in complex scenes.
- Segmentation performance under occlusion: For instances that are partially or fully occluded, VisTR, IFC, and SeqFormer frequently produce inaccurate mask predictions upon the instance’s reappearance, leading to misaligned or overlapping instance boundaries. DCFA-LVIS, however, excels at recovering the boundaries of occluded instances, ensuring accurate and consistent masks, highlighting its robust capability to handle occlusion.
- Instance tracking in high-speed motion scenarios: In scenes with high-speed motion, VisTR, IFC, and SeqFormer often fail in tracking or produce imprecise segmentations due to motion blur or instance deformation. In comparison, DCFA-LVIS effectively maintains mask continuity and stability when tracking fast-moving instances, significantly reducing segmentation errors and interruptions in tracking.
4.4. Ablation Studies
4.4.1. Dual-Channel Feature Enhancement for Adaptive Convolution and Temporal Consistency
4.4.2. Efficient Instance Query Optimization Based on Dual-Frequency Awareness
4.4.3. Effectiveness of Instance Representation and Mask Head Generalization with Reduced Frame Count
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qi, J.; Gao, Y.; Hu, Y.; Wang, X.; Liu, X.; Bai, X.; Belongie, S.; Yuille, A.; Torr, P.H.S.; Bai, S. Occluded Video Instance Segmentation: A Benchmark. Int. J. Comput. Vis. 2022, 130, 2022–2039. [Google Scholar] [CrossRef]
- Yang, L.; Fan, Y.; Xu, N. Video instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5188–5197. [Google Scholar]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-guided feature aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 408–417. [Google Scholar]
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep feature flow for video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2349–2358. [Google Scholar]
- Zhou, T.; Porikli, F.; Crandall, D.J.; Van Gool, L.; Wang, W. A survey on deep learning techniques for video segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7099–7122. [Google Scholar] [CrossRef] [PubMed]
- Voigtlaender, P.; Krause, M.; Osep, A.; Luiten, J.; Gnana Sekar, B.B.; Geiger, A.; Leibe, B. MOTS: Multi-object tracking and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7942–7951. [Google Scholar]
- Bertasius, G.; Torresani, L. Classifying, segmenting, and tracking object instances in video with mask propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9739–9748. [Google Scholar]
- Athar, A.; Mahadevan, S.; Osep, A.; Leal-Taixe, L.; Leibe, B. STEM-SEG: Spatio-temporal embeddings for instance segmentation in videos. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XI. Springer International Publishing: Cham, Switzerland, 2020; pp. 158–177. [Google Scholar]
- Lin, H.; Wu, R.; Liu, S.; Lu, J.; Jia, J. Video instance segmentation with a propose-reduce paradigm. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 1739–1748. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Wang, Y.; Xu, Z.; Wang, X.; Shen, C.; Cheng, B.; Shen, H.; Xia, H. End-to-end video instance segmentation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8741–8750. [Google Scholar]
- Hwang, S.; Heo, M.; Oh, S.W.; Kim, S.J. Video instance segmentation using inter-frame communication transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 13352–13363. [Google Scholar]
- Wu, J.; Jiang, Y.; Bai, S.; Zhang, W.; Bai, X. Seqformer: Sequential transformer for video instance segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 553–569. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Peng, Y.; Wang, H. Road traffic sign detection method based on RTS R-CNN instance segmentation network. Sensors 2023, 23, 6543. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Song, J.; Du, C.; Wang, C. Online scene semantic understanding based on sparsely correlated network for AR. Sensors 2024, 24, 4756. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Liu, Q.; Jiang, Y.; Bai, S.; Yuille, A.; Bai, X. In defense of online models for video instance segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 588–605. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. BlendMask: Top-down meets bottom-up for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8573–8581. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Huang, T.; Li, H.; Zhou, G.; Li, S.; Wang, Y. A Survey of Research on Instance Segmentation Methods. J. Front. Comput. Sci. Technol. 2023, 17, 810–825. Available online: http://fcst.ceaj.org/CN/10.3778/j.issn.1673-9418.2209051 (accessed on 19 June 2023).
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image segmentation as rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- Suresha, M.; Kuppa, S.; Raghukumar, D.S. PointRend segmentation for a densely occluded moving object in a video. In Proceedings of the 2021 Fourth International Conference on Computational Intelligence and Communication Technologies (CCICT), Jaipur, India, 3 July 2021; pp. 282–287. [Google Scholar]
- Fang, Y.; Yang, S.; Wang, X.; Li, Y.; Fang, C.; Shan, Y.; Feng, B.; Liu, W. Instances as queries. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 6910–6919. [Google Scholar]
- Cao, J.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y. SipMask: Spatial information preservation for fast image and video instance segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 1–18. [Google Scholar]
- Fu, Y.; Yang, L.; Liu, D.; Huang, T.S.; Shi, H. CompFeat: Comprehensive feature aggregation for video instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1361–1369. [Google Scholar]
- Yang, S.; Fang, Y.; Wang, X.; Li, Y.; Fang, C.; Shan, Y.; Feng, B.; Liu, W. Crossover learning for fast online video instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 8043–8052. [Google Scholar]
- Xu, K.; Yang, X.; Yin, B.; Lau, R.W.H. Learning to restore low-light images via decomposition-and-enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2281–2290. [Google Scholar]
- Chen, L.; Fu, Y.; Gu, L.; Yan, C.; Harada, T.; Huang, G. Frequency-aware feature fusion for dense image prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10763–10780. [Google Scholar] [CrossRef] [PubMed]
- Warren, A.; Xu, K.; Lin, J.; Tam, G.K.L.; Lau, R.W.H. Effective video mirror detection with inconsistent motion cues. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 16–22 June 2024; pp. 17244–17252. [Google Scholar]
- Ott, M.; Edunov, S.; Grangier, D.; Auli, M. Scaling neural machine translation. arXiv 2018, arXiv:1806.00187. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, Z.; Stoyanov, V. RoBERTa: A robustly optimized BERT pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.; Salakhutdinov, R. Transformer-XL: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Meinhardt, T.; Kirillov, A.; Leal-Taixe, L.; Feichtenhofer, C. TrackFormer: Multi-object tracking with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8844–8854. [Google Scholar]
- Wu, J.; Jiang, Y.; Sun, P.; Yuan, Z.; Luo, P. Language as queries for referring video object segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4974–4984. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lucic, M.; Schmid, C. ViVit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 565–571. [Google Scholar]
- Li, B.; Yao, Y.; Tan, J.; Zhang, G.; Yu, F.; Lu, J.; Luo, Y. Equalized focal loss for dense long-tailed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6990–6999. [Google Scholar]
- Xu, N.; Yang, L.; Yang, J.; Yue, D.; Fan, Y.; Liang, Y.; Huang, T.S. YouTubeVIS Dataset 2021 Version. Available online: https://youtube-vos.org/dataset/vis/ (accessed on 12 March 2023).
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Method | Params (M) | FPS (%) | AP | AP50 | AP75 | AR1 | AR10 (%) |
|---|---|---|---|---|---|---|---|---|
| ResNet-50 | MaskTrack R-CNN [2] | 58.1 | 20.0 | 30.1 | 50.9 | 32.4 | 30.8 | 35.3 |
| STEm-Seg [8] | 50.5 | 7.0 | 30.4 | 50.5 | 33.3 | 37.4 | 36.9 | |
| SipMask [27] | 33.2 | 30.0 | 33.5 | 53.9 | 35.6 | 35.2 | 39.9 | |
| CompFeat [28] | - | - | 35.1 | 55.8 | 38.4 | 32.9 | 40.1 | |
| VisTR [11] | 57.2 | 69.9 | 36.0 | 59.6 | 36.7 | 37.0 | 42.2 | |
| MaskProp [7] | - | - | 39.8 | - | 42.7 | - | - | |
| CrossVIS [29] | 37.5 | 39.8 | 36.1 | 56.6 | 38.7 | 35.4 | 40.5 | |
| Propose–Reduce [9] | 69.0 | - | 40.2 | 62.8 | 43.6 | 40.9 | 49.5 | |
| IFC [12] | 39.3 | 107.1 | 42.6 | 65.6 | 46.6 | 43.6 | 51.0 | |
| SeqFormer [13] | 49.3 | 72.3 | 47.4 | 66.9 | 51.8 | 45.5 | 54.8 | |
| DCFA-LVIS | 43.6 | 73.5 | 47.6 | 67.4 | 52.2 | 46.2 | 55.4 | |
| DCFA-LVIS | 43.6 | 73.5 | 48.3 | 68.2 | 52.8 | 46.4 | 55.9 | |
| ResNet-101 | MaskTrack R-CNN [2] | 77.2 | - | 31.6 | 52.8 | 33.4 | 33.0 | 37.4 |
| STEm-Seg [8] | 69.6 | - | 34.4 | 55.6 | 37.7 | 34.2 | 41.4 | |
| VisTR [11] | 76.3 | 57.7 | 39.9 | 63.8 | 44.8 | 38.1 | 44.7 | |
| MaskProp [7] | - | - | 42.3 | - | 45.4 | - | - | |
| CrossVIS [29] | 56.6 | 35.6 | 36.4 | 57.1 | 39.5 | 35.8 | 41.8 | |
| Propose–Reduce [9] | 88.1 | - | 43.6 | 65.3 | 47.2 | 42.8 | 53.0 | |
| IFC [12] | 58.3 | 89.4 | 44.4 | 69.0 | 49.3 | 43.8 | 51.9 | |
| SeqFormer [13] | 68.4 | 64.6 | 49.0 | 71.1 | 55.7 | 46.8 | 56.9 | |
| DCFA-LVIS | 54.5 | 65.0 | 49.9 | 72.1 | 56.0 | 47.9 | 58.2 | |
| DCEResNet | DCFA-LVIS | 52.6 | 65.9 | 50.1 | 72.7 | 57.0 | 48.1 | 59.4 |
| Backbone | Method | Params (M) | FPS (%) | AP | AP50 | AP75 | AR1 | AR10 (%) |
|---|---|---|---|---|---|---|---|---|
| ResNet-50 | MaskTrack R-CNN [2] | 58.1 | 20.0 | 28.4 | 48.7 | 29.4 | 26.3 | 33.6 |
| SipMask [27] | 33.2 | 30.0 | 31.5 | 52.3 | 33.8 | 30.6 | 37.6 | |
| CrossVIS [28] | 37.5 | 39.8 | 34.0 | 54.2 | 37.7 | 30.2 | 38.0 | |
| IFC [12] | 39.3 | 107.1 | 36.4 | 57.7 | 39.1 | - | - | |
| SeqFormer [13] | 49.3 | 72.3 | 40.3 | 62.2 | 43.5 | 35.9 | 47.9 | |
| DCFA-LVIS | 43.6 | 73.5 | 41.8 | 63.9 | 44.6 | 37.0 | 49.5 | |
| DCEResNet | DCFA-LVIS | 52.6 | 65.9 | 43.9 | 68.4 | 49.3 | 39.2 | 52.0 |
| DCE | Params (M) | FPS (%) | AP | AP50 | AP75 | AR1 | AR10 (%) |
|---|---|---|---|---|---|---|---|
| No | 68.4 | 64.6 | 49.0 | 71.1 | 55.7 | 46.8 | 56.9 |
| Yes | 53.7 | 65.3 | 49.9 | 71.8 | 56.2 | 47.7 | 58.4 |
| Variables | Params (M) | FPS (%) | AP | AP50 | AP75 | AR1 | AR10 (%) |
|---|---|---|---|---|---|---|---|
| None | 64.7 | 64.9 | 34.1 | 53.7 | 34.9 | 34.8 | 40.9 |
| DFA | 54.5 | 65.0 | 47.6 | 72.1 | 54.7 | 48.0 | 58.0 |
| Frames | AP | AP50 | AP75 | AR1 | AR10 (%) |
|---|---|---|---|---|---|
| 1 | 38.6 | 58.8 | 41.8 | 39.2 | 48.0 |
| 3 | 43.9 | 65.9 | 48.1 | 42.9 | 51.8 |
| 5 | 45.1 | 67.0 | 50.2 | 45.3 | 55.1 |
| 10 | 45.2 | 67.4 | 50.0 | 44.8 | 54.0 |
| All | 45.6 | 67.4 | 51.0 | 46.1 | 55.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Zhang, W.; Wei, H. A Dual-Channel and Frequency-Aware Approach for Lightweight Video Instance Segmentation. Sensors 2025, 25, 459. https://doi.org/10.3390/s25020459
Liu M, Zhang W, Wei H. A Dual-Channel and Frequency-Aware Approach for Lightweight Video Instance Segmentation. Sensors. 2025; 25(2):459. https://doi.org/10.3390/s25020459
Chicago/Turabian StyleLiu, Mingzhu, Wei Zhang, and Haoran Wei. 2025. "A Dual-Channel and Frequency-Aware Approach for Lightweight Video Instance Segmentation" Sensors 25, no. 2: 459. https://doi.org/10.3390/s25020459
APA StyleLiu, M., Zhang, W., & Wei, H. (2025). A Dual-Channel and Frequency-Aware Approach for Lightweight Video Instance Segmentation. Sensors, 25(2), 459. https://doi.org/10.3390/s25020459