
Incorporating Multimodal Directional Interpersonal Synchrony into Empathetic Response Generation


Abstract
1. Introduction
- We propose a modified CEM that incorporates multimodal directional synchrony.
- The proposed model shows that incorporating multimodal directional synchrony could improve empathetic response generation.
- Our exploratory analysis provides insight into the association between multimodal directional synchrony and the different components of the empathetic communication mechanisms.
2. Related Work
2.1. Empathetic Response Generation
2.2. Directional Interpersonal Synchrony
- “Proximity” refers to the similarity of feature values, while “Synchrony” refers to the similarity of temporal changes in the features [33]. In our study, synchrony is evaluated using the cosine similarity between the features of two interlocutors. Cosine similarity captures both “Proximity” and “Synchrony”. Specifically, “Proximity” involves the similarity of features representing “non-contextual” elements, which do not include temporal changes (e.g., facial expression in one frame), while “Synchrony” captures the similarity of “contextual” features, which account for temporal changes (e.g., body movement in a series of images within a turn). Since our study processes features that include both “contextual” and “non-contextual” elements, it is difficult to classify our approach strictly as “Proximity” or “Synchrony” based on Wynn and Borrie’s framework.
- The level of synchrony refers to the timescale at which synchrony is measured. “Local” is operationally defined as a synchrony between units that are at or below adjacent turns. “Global” means any time scale greater than adjacent turns. We extract synchrony features between adjacent turns in our work. Thus, we should consider our “Interpersonal Synchrony” to be in the “Local” class.
- The concept of “Static” is defined as synchrony without considering statistical changes over time, whereas the concept of “Dynamic” is defined as changes in synchrony over time. In this work, “Interpersonal Synchrony” is defined as a cosine similarity between features from two interlocutors without considering the change in synchrony over time. The concept should be comparable to that of “Static”.
2.3. Empathy Communication Mechanisms
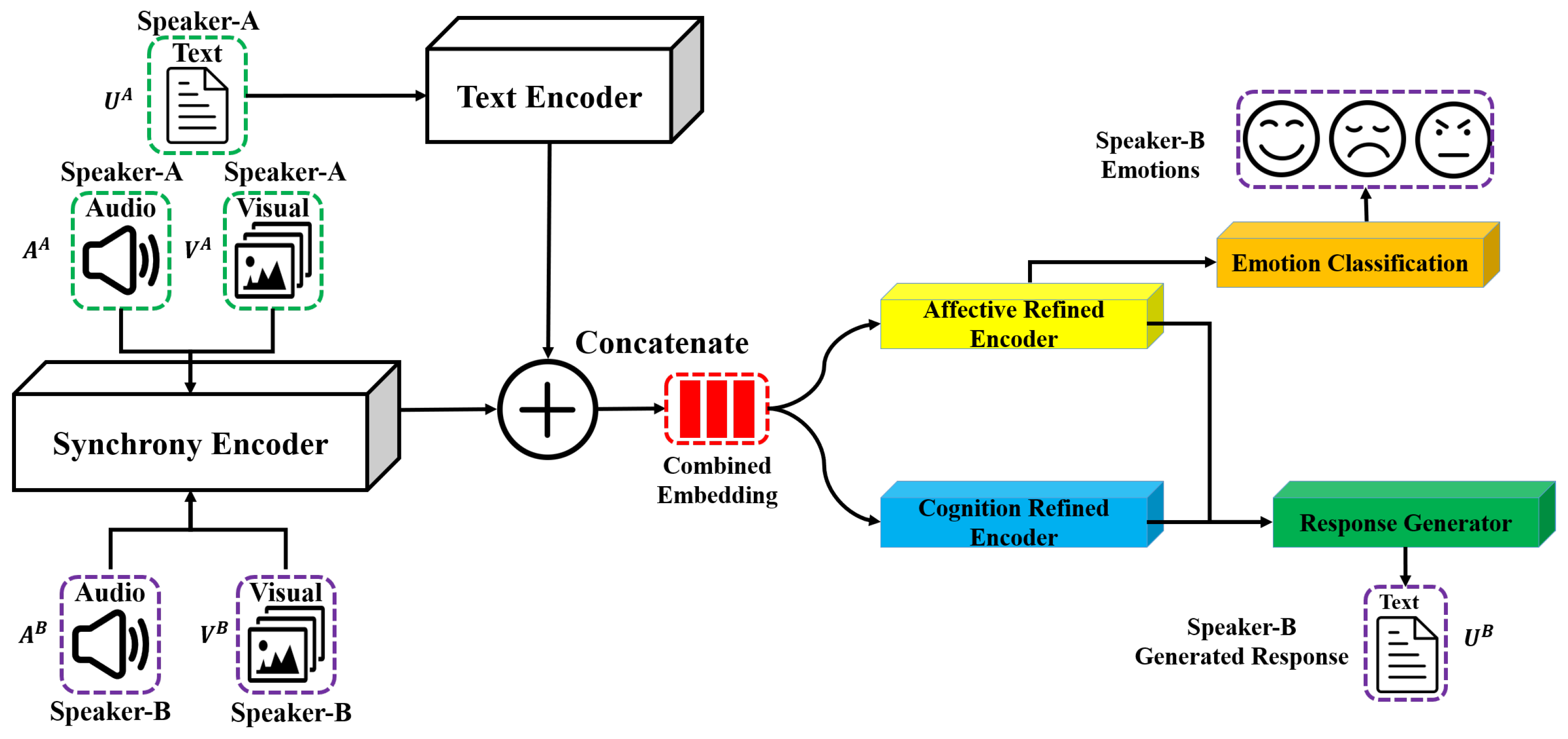
3. Methodology
3.1. Problem Definition
3.2. Data Preparation
3.3. Model Creation
3.3.1. Backbone Model Introduction
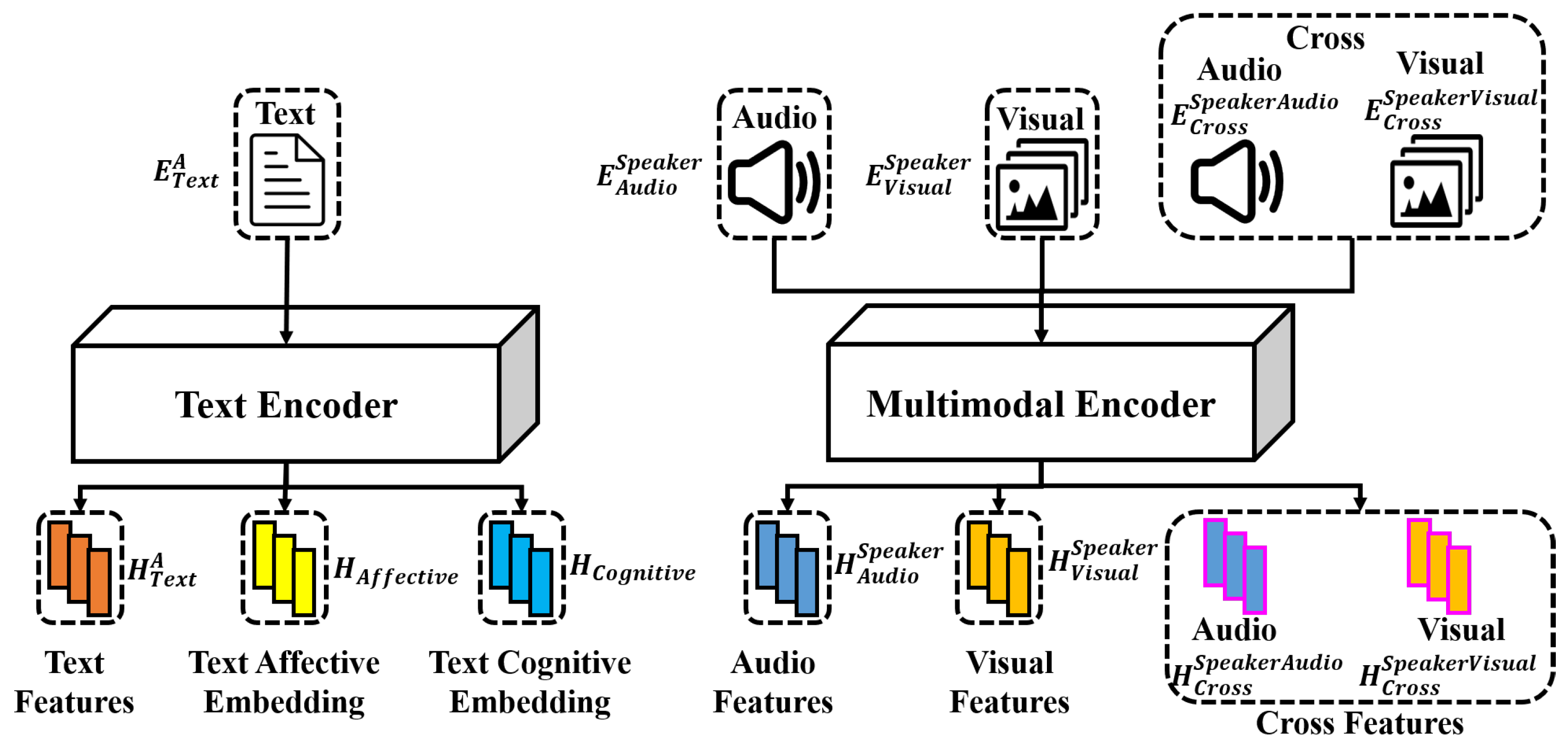
3.3.2. Individual Feature Encoding
3.3.3. Interpersonal Synchronization Encoding
- Positive related features:, , ,
- Negative related features:,, ,
3.3.4. Model Frameworks
3.4. Evaluation Metrics
4. Experiment Results and Discussion
4.1. Dataset Preparation
4.2. Implementation Details
4.3. Empathetic Response Generation Using Multimodality: Effectiveness Test
4.4. Empathetic Response Generation Using Directional Synchronizations: Effectiveness Test
- In the visual modality, there was an increase of 1.82 in BLEU, 0.0291 in ROUGE-1, 0.0156 in ROUGE-2, 0.0048 in Dist-1, and 0.0663 in Dist-2.
- In the audio modality, there was an increase of 1.81 in BLEU, 0.0305 in ROUGE-1, 0.0145 in ROUGE-2, 0.0046 in Dist-1, and 0.0459 in Dist-2.
- In the cross-modality, there was an increase of 0.79 in BLEU, 0.0092 in ROUGE-1, 0.0040 in ROUGE-2, 0.0055 in Dist-1, and 0.0441 in Dist-2.
- Audio modality shows that utilizing positive synchrony solely improved emotion classification accuracy by 1.34, while utilizing negative synchrony solely improved it by 0.72.
- Cross-modality shows that utilizing positive synchrony solely improved emotion classification accuracy by 0.44, while utilizing negative synchrony solely improved it by 0.09.
4.5. Synchronization Analysis Based on Empathetic Communication Mechanisms
- Positive synchrony results in an average decrease in the F1-scores of for exploration.
- Negative synchrony results in an average decrease in the F1-scores of for exploration.
- Positive synchrony results in an average increase in the F1-scores of for interpretation.
- Negative synchrony results in an average increase in the F1-scores of for interpretation.
5. Discussion
Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sundaram, D.S.; Webster, C. The role of nonverbal communication in service encounters. J. Serv. Mark. 2000, 14, 378–391. [Google Scholar] [CrossRef]
- Huang, C.; Zaiane, O.R.; Trabelsi, A.; Dziri, N. Automatic dialogue generation with expressed emotions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 49–54. [Google Scholar]
- Huang, Y.; Li, K.; Chen, Z.; Wang, L. Generating Emotional Coherence and Diverse Responses in a Multimodal Dialogue System. In Proceedings of the 2021 2nd International Conference on Electronics, Communications and Information Technology (CECIT), Sanya, China, 27–29 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 625–630. [Google Scholar]
- Wang, S.; Alexanderson, S.; Gustafson, J.; Beskow, J.; Henter, G.E.; Székely, É. Integrated speech and gesture synthesis. In Proceedings of the 2021 International Conference on Multimodal Interaction, Montréal, QC, Canada, 18–22 October 2021; pp. 177–185. [Google Scholar]
- Young, T.; Pandelea, V.; Poria, S.; Cambria, E. Dialogue systems with audio context. Neurocomputing 2020, 388, 102–109. [Google Scholar] [CrossRef]
- Firdaus, M.; Chauhan, H.; Ekbal, A.; Bhattacharyya, P. EmoSen: Generating sentiment and emotion controlled responses in a multimodal dialogue system. IEEE Trans. Affect. Comput. 2020, 13, 1555–1566. [Google Scholar] [CrossRef]
- Raamkumar, A.S.; Yang, Y. Empathetic conversational systems: A review of current advances, gaps, and opportunities. IEEE Trans. Affect. Comput. 2022, 14, 2722–2739. [Google Scholar] [CrossRef]
- Kann, K.; Ebrahimi, A.; Koh, J.; Dudy, S.; Roncone, A. Open-domain dialogue generation: What we can do, cannot do, and should do next. In Proceedings of the 4th Workshop on NLP for Conversational AI, Dublin, Ireland, 27 May 2022; pp. 148–165. [Google Scholar]
- Zhou, H.; Huang, M.; Zhang, T.; Zhu, X.; Liu, B. Emotional chatting machine: Emotional conversation generation with internal and external memory. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Nandwani, P.; Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef] [PubMed]
- Bhirud, N.; Tataale, S.; Randive, S.; Nahar, S. A literature review on chatbots in healthcare domain. Int. J. Sci. Technol. Res. 2019, 8, 225–231. [Google Scholar]
- Yan, Z.; Duan, N.; Chen, P.; Zhou, M.; Zhou, J.; Li, Z. Building task-oriented dialogue systems for online shopping. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Valle-Cruz, D.; Alejandro Ruvalcaba-Gomez, E.; Sandoval-Almazan, R.; Ignacio Criado, J. A review of artificial intelligence in government and its potential from a public policy perspective. In Proceedings of the 20th Annual International Conference on Digital Government Research, Dubai United Arab Emirates, 18–20 June 2019; pp. 91–99. [Google Scholar]
- Mayo, O.; Gordon, I. In and out of synchrony—Behavioral and physiological dynamics of dyadic interpersonal coordination. Psychophysiology 2020, 57, e13574. [Google Scholar] [CrossRef]
- Lackner, H.K.; Feyaerts, K.; Rominger, C.; Oben, B.; Schwerdtfeger, A.; Papousek, I. Impact of humor-related communication elements in natural dyadic interactions on interpersonal physiological synchrony. Psychophysiology 2019, 56, e13320. [Google Scholar] [CrossRef] [PubMed]
- Koehne, S.; Hatri, A.; Cacioppo, J.T.; Dziobek, I. Perceived interpersonal synchrony increases empathy: Insights from autism spectrum disorder. Cognition 2016, 146, 8–15. [Google Scholar] [CrossRef]
- Basile, C.; Lecce, S.; van Vugt, F.T. Synchrony During Online Encounters Affects Social Affiliation and Theory of Mind but Not Empathy. Front. Psychol. 2022, 13, 886639. [Google Scholar] [CrossRef]
- Lumsden, J.; Miles, L.K.; Macrae, C.N. Sync or sink? Interpersonal synchrony impacts self-esteem. Front. Psychol. 2014, 5, 108474. [Google Scholar] [CrossRef]
- van Ulzen, N.R.; Lamoth, C.J.; Daffertshofer, A.; Semin, G.R.; Beek, P.J. Characteristics of instructed and uninstructed interpersonal coordination while walking side-by-side. Neurosci. Lett. 2008, 432, 88–93. [Google Scholar] [CrossRef] [PubMed]
- Richardson, M.J.; Marsh, K.L.; Isenhower, R.W.; Goodman, J.R.; Schmidt, R.C. Rocking together: Dynamics of intentional and unintentional interpersonal coordination. Hum. Mov. Sci. 2007, 26, 867–891. [Google Scholar] [CrossRef] [PubMed]
- Sabour, S.; Zheng, C.; Huang, M. Cem: Commonsense-aware empathetic response generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 11229–11237. [Google Scholar]
- Ma, Y.; Nguyen, K.L.; Xing, F.Z.; Cambria, E. A survey on empathetic dialogue systems. Inf. Fusion 2020, 64, 50–70. [Google Scholar] [CrossRef]
- Qian, Y.; Wang, B.; Lin, T.E.; Zheng, Y.; Zhu, Y.; Zhao, D.; Hou, Y.; Wu, Y.; Li, Y. Empathetic response generation via emotion cause transition graph. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Inui, K.; Jiang, J.; Ng, V.; Wan, X. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Stroudsburg, PA, USA, 2019. [Google Scholar]
- Li, Q.; Chen, H.; Ren, Z.; Ren, P.; Tu, Z.; Chen, Z. EmpDG: Multi-resolution Interactive Empathetic Dialogue Generation. In Proceedings of the 28th International Conference on Computational Linguistics. International Committee on Computational Linguistics, Barcelona, Spain, 8–13 December 2020. [Google Scholar]
- Majumder, N.; Hong, P.; Peng, S.; Lu, J.; Ghosal, D.; Gelbukh, A.; Mihalcea, R.; Poria, S. MIME: MIMicking Emotions for Empathetic Response Generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 8968–8979. [Google Scholar]
- Huber, B.; McDuff, D.; Brockett, C.; Galley, M.; Dolan, B. Emotional dialogue generation using image-grounded language models. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Hu, J.; Huang, Y.; Hu, X.; Xu, Y. The acoustically emotion-aware conversational agent with speech emotion recognition and empathetic responses. IEEE Trans. Affect. Comput. 2022, 14, 17–30. [Google Scholar] [CrossRef]
- Das, A.; Kottur, S.; Moura, J.M.; Lee, S.; Batra, D. Learning cooperative visual dialog agents with deep reinforcement learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2951–2960. [Google Scholar]
- Shi, W.; Yu, Z. Sentiment Adaptive End-to-End Dialog Systems. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1509–1519. [Google Scholar]
- Zhang, Y.; Kong, F.; Wang, P.; Sun, S.; SWangLing, S.; Feng, S.; Wang, D.; Zhang, Y.; Song, K. STICKERCONV: Generating Multimodal Empathetic Responses from Scratch. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 7707–7733. [Google Scholar]
- Hu, Y.; Cheng, X.; Pan, Y.; Hu, Y. The intrapersonal and interpersonal consequences of interpersonal synchrony. Acta Psychol. 2022, 224, 103513. [Google Scholar] [CrossRef]
- Wynn, C.J.; Borrie, S.A. Classifying conversational entrainment of speech behavior: An expanded framework and review. J. Phon. 2022, 94, 101173. [Google Scholar] [CrossRef] [PubMed]
- Reddish, P.; Fischer, R.; Bulbulia, J. Let’s dance together: Synchrony, shared intentionality and cooperation. PLoS ONE 2013, 8, e71182. [Google Scholar] [CrossRef] [PubMed]
- Cornejo, C.; Cuadros, Z.; Morales, R.; Paredes, J. Interpersonal coordination: Methods, achievements, and challenges. Front. Psychol. 2017, 8, 296793. [Google Scholar] [CrossRef]
- Prochazkova, E.; Kret, M.E. Connecting minds and sharing emotions through mimicry: A neurocognitive model of emotional contagion. Neurosci. Biobehav. Rev. 2017, 80, 99–114. [Google Scholar] [CrossRef] [PubMed]
- Lin, D.; Zhu, T.; Wang, Y. Emotion contagion and physiological synchrony: The more intimate relationships, the more contagion of positive emotions. Physiol. Behav. 2024, 275, 114434. [Google Scholar] [CrossRef]
- Tschacher, W.; Rees, G.M.; Ramseyer, F. Nonverbal synchrony and affect in dyadic interactions. Front. Psychol. 2014, 5, 117886. [Google Scholar] [CrossRef] [PubMed]
- Williams, G.P.; Kleinke, C.L. Effects of mutual gaze and touch on attraction, mood, and cardiovascular reactivity. J. Res. Personal. 1993, 27, 170–183. [Google Scholar] [CrossRef]
- Haken, H.; Kelso, J.S.; Bunz, H. A theoretical model of phase transitions in human hand movements. Biol. Cybern. 1985, 51, 347–356. [Google Scholar] [CrossRef] [PubMed]
- Amazeen, P.G.; Schmidt, R.; Turvey, M.T. Frequency detuning of the phase entrainment dynamics of visually coupled rhythmic movements. Biol. Cybern. 1995, 72, 511–518. [Google Scholar] [CrossRef] [PubMed]
- Marsh, K.L.; Richardson, M.J.; Baron, R.M.; Schmidt, R. Contrasting approaches to perceiving and acting with others. Ecol. Psychol. 2006, 18, 1–38. [Google Scholar] [CrossRef]
- Macrae, C.N.; Duffy, O.K.; Miles, L.K.; Lawrence, J. A case of hand waving: Action synchrony and person perception. Cognition 2008, 109, 152–156. [Google Scholar] [CrossRef]
- Quan, J.; Miyake, Y.; Nozawa, T. Incorporating interpersonal synchronization features for automatic emotion recognition from visual and audio data during communication. Sensors 2021, 21, 5317. [Google Scholar] [CrossRef]
- Bota, P.; Zhang, T.; El Ali, A.; Fred, A.; da Silva, H.P.; Cesar, P. Group synchrony for emotion recognition using physiological signals. IEEE Trans. Affect. Comput. 2023, 14, 2614–2625. [Google Scholar] [CrossRef]
- Launay, J.; Dean, R.T.; Bailes, F. Synchronization can influence trust following virtual interaction. Exp. Psychol. 2013, 60, 53–63. [Google Scholar] [CrossRef]
- Bailenson, J.N.; Yee, N. Digital chameleons: Automatic assimilation of nonverbal gestures in immersive virtual environments. Psychol. Sci. 2005, 16, 814–819. [Google Scholar] [CrossRef] [PubMed]
- Kroczek, L.O.; Mühlberger, A. Time to smile: How onset asynchronies between reciprocal facial expressions influence the experience of responsiveness of a virtual agent. J. Nonverbal Behav. 2023, 47, 345–360. [Google Scholar] [CrossRef]
- Li, L.; Zhang, D.; Zhu, S.; Li, S.; Zhou, G. Response generation in multi-modal dialogues with split pre-generation and cross-modal contrasting. Inf. Process. Manag. 2024, 61, 103581. [Google Scholar] [CrossRef]
- Li, W.; Yang, Y.; Tuerxun, P.; Fan, X.; Diao, Y. A response generation framework based on empathy factors, common sense, and persona. IEEE Access 2024, 12, 26819–26829. [Google Scholar] [CrossRef]
- Wang, X.; Sharma, D.; Kumar, D. A Review on AI-based Modeling of Empathetic Conversational Response Generation. In Proceedings of the 2023 Asia Conference on Cognitive Engineering and Intelligent Interaction (CEII), Hong Kong, China, 15–16 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 102–109. [Google Scholar]
- Sofronieva, E. Empathy and communication. Rhetor. Commun. E-J. 2012, 4, 5–17. [Google Scholar]
- Preston, S.D.; De Waal, F.B. The communication of emotions and the possibility of empathy in animals. In Altruistic Love: Science, Philosophy, and Religion in Dialogue; Post, S., Underwood, L.G., Schloss, J.P., Hurlburt, W.B., Eds.; Oxford University Press: Oxford, UK, 2002. [Google Scholar]
- Sharma, A.; Miner, A.; Atkins, D.; Althoff, T. A Computational Approach to Understanding Empathy Expressed in Text-Based Mental Health Support. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 5263–5276. [Google Scholar] [CrossRef]
- Gao, J.; Liu, Y.; Deng, H.; Wang, W.; Cao, Y.; Du, J.; Xu, R. Improving empathetic response generation by recognizing emotion cause in conversations. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 807–819. [Google Scholar]
- Chen, C.; Li, Y.; Wei, C.; Cui, J.; Wang, B.; Yan, R. Empathetic Response Generation with Relation-aware Commonsense Knowledge. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Merida, Mexico, 4–8 March 2024; pp. 87–95. [Google Scholar]
- Majumder, N.; Poria, S.; Hazarika, D.; Mihalcea, R.; Gelbukh, A.; Cambria, E. Dialoguernn: An attentive rnn for emotion detection in conversations. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6818–6825. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Gao, J.; Dolan, B. A Diversity-Promoting Objective Function for Neural Conversation Models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Knight, K., Nenkova, A., Rambow, O., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 110–119. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Park, C.Y.; Cha, N.; Kang, S.; Kim, A.; Khandoker, A.H.; Hadjileontiadis, L.; Oh, A.; Jeong, Y.; Lee, U. K-EmoCon, a multimodal sensor dataset for continuous emotion recognition in naturalistic conversations. Sci. Data 2020, 7, 293. [Google Scholar] [CrossRef] [PubMed]
- van Son, R.J.; Wesseling, W.; Sanders, E.; Van Den Heuvel, H. Promoting free dialog video corpora: The IFADV corpus example. In Proceedings of the International LREC Workshop on Multimodal Corpora, Marrakech, Morocco, 26 May–1 June 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 18–37. [Google Scholar]
- Reece, A.; Cooney, G.; Bull, P.; Chung, C.; Dawson, B.; Fitzpatrick, C.; Glazer, T.; Knox, D.; Liebscher, A.; Marin, S. The CANDOR corpus: Insights from a large multimodal dataset of naturalistic conversation. Sci. Adv. 2023, 9, eadf3197. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Hazarika, D.; Poria, S.; Zadeh, A.; Cambria, E.; Morency, L.P.; Zimmermann, R. Conversational memory network for emotion recognition in dyadic dialogue videos. In Proceedings of the Conference North American Chapter of the Association for Computational Linguistics, New Orleans, LA, USA, 1–6 June 2018; Volume 2018, p. 2122. [Google Scholar]
- Sonnby-Borgström, M.; Jönsson, P.; Svensson, O. Emotional empathy as related to mimicry reactions at different levels of information processing. J. Nonverbal Behav. 2003, 27, 3–23. [Google Scholar] [CrossRef]
- Hess, U. The communication of emotion. In Emotions, Qualia, and Consciousness; World Scientific: Singapore, 2001; pp. 397–409. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train + Val | Test | |
|---|---|---|
| Counts of total turns | 3750 | 1118 |
| Average utterance counts per turn | 1.44 | 1.39 |
| Average word counts per turn | 21.74 | 22.13 |
| Average duration (s) | 6.65 | 6.36 |
| Models | BLEU | ROUGE-1 | ROUGE-2 | Dist-1 | Dist-2 | EA |
|---|---|---|---|---|---|---|
| Text (MIME) | ||||||
| Text (CEM) | ||||||
| Text and Visual | ||||||
| Text and Audio | ||||||
| Text and Cross |
| Models | BLEU | ROUGE-1 | ROUGE-2 | Dist-1 | Dist-2 | EA | |
|---|---|---|---|---|---|---|---|
| Text and Visual | Pos Sync | ||||||
| Neg Sync | |||||||
| Pos & Neg Sync | |||||||
| Text and Audio | Pos Sync | ||||||
| Neg Sync | |||||||
| Pos & Neg Sync | |||||||
| Text and Cross | Pos Sync | ||||||
| Neg Sync | |||||||
| Pos & Neg Sync | |||||||
| Model | Cohen’s d |
|---|---|
| Text and Visual | 1.89 |
| Text and Audio | 1.86 |
| Text and Cross | 1.68 |
| Models | Emotional Reactions | Explorations | Interpretations | |||
|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |
| Finetune Results | ||||||
| Models | Emotional Reactions | Explorations | Interpretations | ||||
|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | ||
| Text and Visual | Pos Sync | ||||||
| Neg Sync | |||||||
| With Pos & Neg Sync | |||||||
| Without Sync | |||||||
| Text and Audio | Pos Sync | ||||||
| Neg Sync | |||||||
| With Pos & Neg Sync | |||||||
| Without Sync | |||||||
| Text and Cross | Pos Sync | ||||||
| Neg Sync | |||||||
| With Pos & Neg Sync | |||||||
| Without Sync | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quan, J.; Miyake, Y.; Nozawa, T. Incorporating Multimodal Directional Interpersonal Synchrony into Empathetic Response Generation. Sensors 2025, 25, 434. https://doi.org/10.3390/s25020434
Quan J, Miyake Y, Nozawa T. Incorporating Multimodal Directional Interpersonal Synchrony into Empathetic Response Generation. Sensors. 2025; 25(2):434. https://doi.org/10.3390/s25020434
Chicago/Turabian StyleQuan, Jingyu, Yoshihiro Miyake, and Takayuki Nozawa. 2025. "Incorporating Multimodal Directional Interpersonal Synchrony into Empathetic Response Generation" Sensors 25, no. 2: 434. https://doi.org/10.3390/s25020434
APA StyleQuan, J., Miyake, Y., & Nozawa, T. (2025). Incorporating Multimodal Directional Interpersonal Synchrony into Empathetic Response Generation. Sensors, 25(2), 434. https://doi.org/10.3390/s25020434