1. Introduction
As transportation infrastructure continues to grow, there is an increasing need to detect target vehicles in an unobtrusive manner for logistics applications. In densely populated cities, many roadways are already equipped with traffic cameras that could be used for vehicle detection. However, there are a number of back roads, gravel roads, and railways where cameras are not always present that many large vehicles traverse when transporting equipment. These routes are frequently traveled to provide deliveries to more remote locations. In these situations, new sensor installments are required for non-contact vehicle detection. Although physical trackers for vehicles exist, they can become costly when deployed at a large scale, and they first require access to the targets of interest [
1]. Thus, an alternative, non-intrusive approach is to identify the vehicles from a roadside view with the use of vision sensors such as a LiDAR or camera. A single roadside vehicle detection system can be set along a route to track an infinite number of targets, no matter how remote the path may be. Since this system is portable, it can also change locations as traveled routes are updated or new targets are identified. When changing views, additional training may be required to maintain high detection accuracy. To track the number of targets crossing a route, the detection networks can be integrated into a larger tracking system that identifies individual target instances over time.
The first step of developing this system is identifying data from a roadside view for training and testing. There are very few publicly available and robust roadway datasets which consist of multimodal data in a range of environmental conditions, let alone from a roadside perspective [
2]. Datasets that target roadways or vehicles usually do so from two different viewpoints: first person or overhead. These datasets are primarily used for autonomous driving or traffic monitoring systems [
3]. The first person view is captured from sensors either within or mounted atop a vehicle [
4,
5,
6,
7,
8,
9]. These datasets train models with constantly changing viewpoints and targets with varying distances from the sensors. Additionally, many of these datasets with changing viewpoints comprise complicated scenes with twenty or more different classes. The proposed roadside detection system is only interested in a single target of interest—train cars when targeted on railways and semi-trucks when targeted on roads—and is thus a simpler problem to solve. This can lead to lower rates of inference mislabeling in practice. Another view commonly used in the literature is an overhead view that is captured either from traffic cameras or sensors on a UAV above the roadway [
10,
11]. Similar to a roadside system, the statically mounted traffic cameras maintain a set distance from targets of interest. These Bird’s-Eye-View systems may not be well suited where transportation infrastructure is not already setup or non-urban areas with heavy occlusion zones. Conversely, a deployable roadside vehicle detection system is easy to relocate to avoid natural or changing occlusions such as foliage or large, manmade structures.
There are also publicly available datasets involving train cars for further logistics tracking, but they have their limitations. They are normally in a first person view from the train car targeting the tracks [
12,
13,
14]. The main purpose of these datasets is to improve train safety, rather than to track cargo [
15]. We offer a unique roadside perspective for evaluating object detection of both train cars and semi-trucks using computer vision. Semantic segmentation performance is evaluated and compared for camera and LiDAR data. This approach yields successful semantic segmentation results suited for situations where other vantage points are not possible or preferable for sensor deployment.
We utilize the UA_L-DoTT dataset, which features a large set of multimodal, labeled data collected from this unique roadside perspective [
16]. This dataset comprises 93,000 images from a monocular camera and 350,000 point clouds from multiple LiDARs with varying operational characteristics collected under changing weather and lighting conditions. An example of the sensor setup targeting one of the railway sites is displayed in
Figure 1. To our knowledge, no other dataset targeting train cars and semi-trucks with these parameters exists. Due to the heterogeneous data, two separate Convolutional Neural Network (CNN) architectures were developed and trained to evaluate semantic segmentation performance for classifying vehicles of interest. All code is publicly available on the UA Roadside Semantic Segmentation GitHub Organization (
https://github.com/UA-Roadside-Semantic-Segmentation/Multimodal-Roadside-Detection/tree/main, accessed on 1 May 2024). The mean Intersection-Over-Union (mIOU) and standard deviation metrics were calculated for both camera- and LiDAR-based models on training hardware. mIOU is commonly used to evaluate the accuracy of a model’s prediction. The standard deviation is included as a metric to give insight into the number of false positives and negatives present in each system. Semantic segmentation inference was also performed on embedded platforms suitable for edge deployment at a roadside view for real-time train car and semi-truck monitoring.
Our results support many of the inherent advantages provided by LiDAR, and they indicate that the segmentation performance of LiDAR systems is comparable to that of camera systems. Specifically, the LiDAR models have comparable validation and testing mIOU to the camera model. The LiDAR models typically had a higher frame rate and power consumption than the camera model on the embedded platforms. The LiDAR models also significantly outperformed the camera model in low-light conditions, and the generic LiDAR model performed well across data from multiple different LiDARs, indicating that sensor-agnostic deployments can perform favorably. However, the results indicate that the LiDAR models do not generalize as well as the camera model, and thus could require additional training for comparable performance when deployed to new locations.
The remainder of the paper is organized as follows. The Related Works section discusses the relevant and recent contributions to the semantic segmentation problem with both camera and LiDAR data. Within the Materials and Methods section, the location of the large dataset of collected camera images, LiDAR point clouds, and correlating data are provided in the Dataset subsection. The details of the CNN architectures used for semantic segmentation are covered in the Camera Architecture and LiDAR Architecture subsections. The breakdown of the training sets for the sensors for both train car data and semi-truck data can be found in the Training Sets subsection. Information on embedded platforms used as edge devices is included in the Embedded Platforms subsection. A brief description of several metrics of interest is provided in the final subsection within Materials and Methods. The performance of the networks executed on both training PCs and embedded platforms is presented with various metrics in the Training Results and Embedded Platform Results subsections, respectively, within the Results section. The Discussion section covers general outcomes of the research, as well as future works.
2. Related Works
Neural networks are commonly used for performing both object detection and semantic segmentation [
17,
18,
19,
20]. Object detection is the process of identifying objects within an image, often times placing axis-aligned bounding boxes around the objects [
21,
22,
23,
24]. Semantic segmentation more specifically categorizes each pixel of an image as belonging to an object of interest or not [
25,
26,
27]. To perform semantic segmentation, several types of deep neural network models can be utilized [
28,
29,
30,
31,
32]. These include CNNs [
33,
34], Graph Neural Networks (GNNs) [
35], and transformers [
36,
37], among others. However, CNNs are among the most commonly used methodologies due to the effectiveness of the convolution layer at extracting image features [
33]. As such, there are many publicly available tools that have been developed in order to train a CNN for semantic segmentation [
38].
Among these tool sets are a diverse range of network architectures available for utilization, including Multi-Receptive Field Module (MRFM) [
39], Pyramid Scene Parsing Network (PSPNet) [
40], Fully Convolutional Networks (FCN) [
41], and DeepLabV3+ [
42], among many others. With the wide range of networks available, it can be difficult to determine which to choose for a certain application. A common selection process is to evaluate each network’s performance on common, publicly available datasets, such as the PASCAL Visual Object Classes (PASCAL-VOC) dataset [
43]. DeepLabV3+ was the best performing network at the time of network selection [
44]. DeepLabV3+ is an extension to the original DeepLabV3 network architecture, and utilizes Atrous Spatial Pyramid Pooling (ASPP) in order to perform convolution. However, DeepLabV3+ also incorporates the common Encoder–Decoder methodology in order to improve segmentation speed and performance. DeepLabV3+ also allows for the utilization of multiple different backbones to make up the network architecture, including XCeption [
45], RESNet [
46], and MobileNetV2 [
47]. These various backbones impact how many parameters the network needs to train, impacting both accuracy and speed.
There have been many analyses of LiDAR and camera sensor fusion approaches for a semantic segmentation application [
8,
48,
49,
50,
51,
52]. However, it is much harder to find a strict comparison of camera vs. LiDAR performance on semantic segmentation of the same dataset. This is, in part, due to the fact that cameras and LiDAR are inherently different sensor modalities with different resulting data formats; a 3D point cloud scan cannot be directly compared against a 2D image. For both fusion techniques and comparison studies, LiDAR data are usually converted to a range image, and this results in some amount of data loss. The semantic segmentation performance results between different modalities is useful for when only one type of sensor can be used. Inherently, LiDARs and their associated point clouds offer several advantages over traditional camera-based systems [
48,
53]. LiDAR is not dependent upon ambient lighting conditions, and it can be very robust when compared specifically to cameras in low-light conditions [
54,
55,
56,
57,
58]. LiDAR also provides distance data directly as an output from the sensor, while camera-based systems typically require significant processing to produce distance data for each pixel [
59,
60].
Several methods exist to process point clouds using CNN models. First, the point cloud can be voxelized and a 3D CNN used to process the input [
61]. This method is extremely computationally intensive and the majority of the compute time is wasted due to the sparsity of the point cloud. The Bird’s-Eye-View method is less intensive, but it is inefficient on embedded platforms [
62]. A spherical projection is less computationally expensive and more suitable for converting point clouds to an image representation on the edge in real-time [
63]. This is a critical step that is required to be able to compare image and LiDAR segmentation results against one another.
3. Materials and Methods
3.1. Dataset
The utilization of the UA_L-DoTT dataset was crucial in comparing the LiDAR vs. camera performance for semantic segmentation in varying locations under different weather conditions [
16]. This multimodal dataset consists of large amounts of annotated data from five unique LiDAR—Velodyne Puck (VLP-16), Velodyne Puck Hi-Res (VLP-16 Hi-Res), Velodyne 32MR, Ouster OS-1, and Ouster OS-2—as well as a 2D RGB monocular camera—FLIR Blackfly S GigE BFS-PGE-31S4C-C. The dataset contains approximately 93,000 raw images and 350,000 raw LiDAR scans, collected across four separate locations with varying environmental conditions. This further allowed evaluation of the presented system to generalize to a range of environments. The accompanying dataset includes all of the raw images and point clouds collected, as well as 9000 labeled text files that correspond to the images, 77,000 labeled point clouds, and 33 timestamp files. The timestamps correlate images to point clouds via POSIX time. The dataset is publicly available at UA_L-DoTT (
https://plus.figshare.com/articles/dataset/UA_L-DoTT_University_of_Alabama_s_Large_Dataset_of_Trains_and_Trucks_-_Dataset_Repository/19311938/1, accessed on 15 March 2022) [
64].
Data collection was performed during five separate instances, four of which targeted train tracks (with one repeat location) and one that targeted a four-lane highway (for semi-truck targets). The distance to the targets of interest ranged from 42 to 240 m, depending on the site. The base data collection frequency for the VLP-16, VLP-16 Hi-Res, and 32MR was 8 Hz, and the baseline for the OS-1, OS-2, and Blackfly was 10 Hz. Only every 3–7 images were labeled, or roughly data at 1–3 Hz, to increase the diversity of data. LiDAR downsampling also occurred at several of the sites, resulting in labeling every 3–5 scans, or a labeling frequency of 1–3 Hz, to ensure adequate change in scenery across consecutive scans. Lighting conditions also ranged from bright sun to overcast to darkness. Data were collected statically at the first four sites. Here, the stationary sensors were panned back and forth occasionally to vary the viewpoint while maintaining a set distance between the sensors and targets of interest. Readers interested in additional detailed information regarding the creation and characteristics of the dataset are directed to [
16]. During the final data collection, the sensors were mounted to a dynamic vehicle to provide a constantly changing viewpoint while maintaining a similar distance between the sensor setup and the targets of interest. Although it is expected that real-world sensor deployments will be roadside and stationary, collecting data from a mobile platform helped create a more robust training set, requiring the networks to identify the targets regardless of their positions within the sensor’s FoV. A specific site location will be known before deployment but, critically, the exact sensor location may or may not be known. The distance from the targets of interest is an important parameter that must be defined when deploying the roadside sensor suite to ensure adequate coverage. However, the sensors may be deployed anywhere along a roadside at this set distance to avoid occlusions or obstacles.
3.2. Sensor Characteristics
RGB cameras and LiDARs represent data in fundamentally different formats. LiDAR is a time-of-flight technology that emits a laser pulse and measures the time it takes to receive the echo after the laser pulse reflects off various objects in the field-of-view (FoV). LiDARs are available in “spinning” models and solid-state models. Spinning models use an emitter and a detector (or a set of them) that spin completely around the vertical axis, providing a horizontal FoV. There are several characteristics of a spinning LiDARs that directly impact the point clouds produced. The horizontal FoV is typically , but the vertical FoV varies depending on the model. Specifically, the number of scanlines and the vertical angular resolution define the vertical FoV and the vertical point density.
Images collected from an RGB camera, as well as point clouds from multiple spinning LiDARs with varying operational characteristics, are utilized for identifying vehicles of interest in this work. Inherently, LiDARs and their associated point clouds offer several advantages over traditional camera-based systems. For example, LiDARs are not dependent upon ambient lighting conditions. Secondly, spinning LiDARs have a
horizontal FoV, significantly larger than a standard 2D camera. This can reduce the number of deployment units necessary to cover the region of interest. LiDARs provide distance data directly as an output from the sensor while cameras typically require significant processing to produce distance data for each pixel. This additional data allows users to take advantage of the spatial relationships among objects in the FoV, minimizing the complexity required to count target instances.
Table 1 shows the sensor specifications for the five LiDAR sensors used in this project. Synced data were collected from these sensors at each of the five data collection sites. This provided slightly different-looking data all targeting the same scene, allowing a comparison of the data generated from each of the LiDAR. For example, some LiDARs were significantly cheaper than others, but had a shorter range. This meant that not all targets of interest were recognized by all LiDARs if they were past a certain distance. Similarly, a LiDAR with a larger vertical or horizontal resolution might miss smaller targets far away. The LiDARs were chosen to provide variety in number of scanlines (S.Lines), vertical FoV (V. FoV), vertical resolution (
), horizontal resolution (
), and range. We draw the reader’s attention to the range metric. LiDAR range is a function of the intensity and size of the target and, in most cases, the provided range metric is measured using targets of varying color, size, and reflectivity. Therefore, the stated ranges are often not consistent in real-world operations.
3.3. Camera Architecture
Segmentation of the 3D point cloud data and 2D image data are treated as two independent tasks. Many off-the-shelf models exist to perform image segmentation. We chose the DeepLabV3+ network architecture for the reasons discussed in
Section 2. The MobileNetV2 backbone is optimized to run on embedded devices, as would be needed in edge deployments, so it was integrated into the network [
47]. Transfer learning with the PASCAL-VOC dataset was utilized to accelerate the training process [
44].
The model was trained using the Adam optimizer with the Categorical Cross-Entropy loss function [
65,
66]. This enabled high quality results with minimal hyperparameter optimization. Evaluation was performed using the mIOU and standard deviation metrics. Standard augmentations including Gaussian noise, random flipping, and random crops were applied to reduce overfitting.
3.4. LiDAR Architecture
A spherical projection was chosen to convert the point clouds to an image representation due to its efficiency on embedded platforms. This system converts the Euclidean representation of point clouds into spherical coordinates which are then projected onto an image plane. The resulting resolution is the number of scanlines times the number of horizontal points per scanline. Each pixel in the image includes the point coordinates, (XYZ), and the return intensity, I. The input to the network is therefore an image with four input channels (XYZI) instead of three colors (RGB). The model then outputs (N, H, W, C) tensors, where N is the point cloud index, H and W are the pixel coordinates, and C is the confidence associated with the particular class, vehicle or not a vehicle, normalized with softmax.
This projection produces varying image dimensions dependent upon the number of scanlines per LiDAR. Thus, LiDARs with different numbers of scanlines require separate deep learning models. It is advantageous to have one, unified model capable of accepting point clouds from all the LiDAR scanners. For this reason, a nearest-neighbor up-sampling methodology to increase the scanlines of the lower resolution LiDARs was developed. Each scanline of the lower resolution LiDAR is duplicated such that the height of the final input image remains equal to the maximum number of scanlines that are supported.
DeepLabV3+ utilizes symmetric down-sampling of the input data, which works well for relatively square input data, such as camera imagery. However, the vastly asymmetric point cloud resolution (16 × 2048) would result in poor segmentation performance of the network. When the input data only has 16 rows, downsampling quickly decimates the resolution of the data. This causes the model to lose critical spatial information used to produce the semantic segmentation. To address this, an architecture inspired by DeepLabV3+ was created to downsample exclusively across the width of the input data. Additionally, the dilations in the atrous kernels are applied only along the width. This enables the use of an architecture very similar to DeepLabV3+ without the internal decimation of the point cloud resolution. The point cloud model follows the same training process as the camera model. Again, categorical cross-entropy loss, the Adam optimizer, and the mIOU/standard deviation evaluation metrics are used. Random flipping, Gaussian noise to the range of the return, and Gaussian intensity noise augmentations are applied during training.
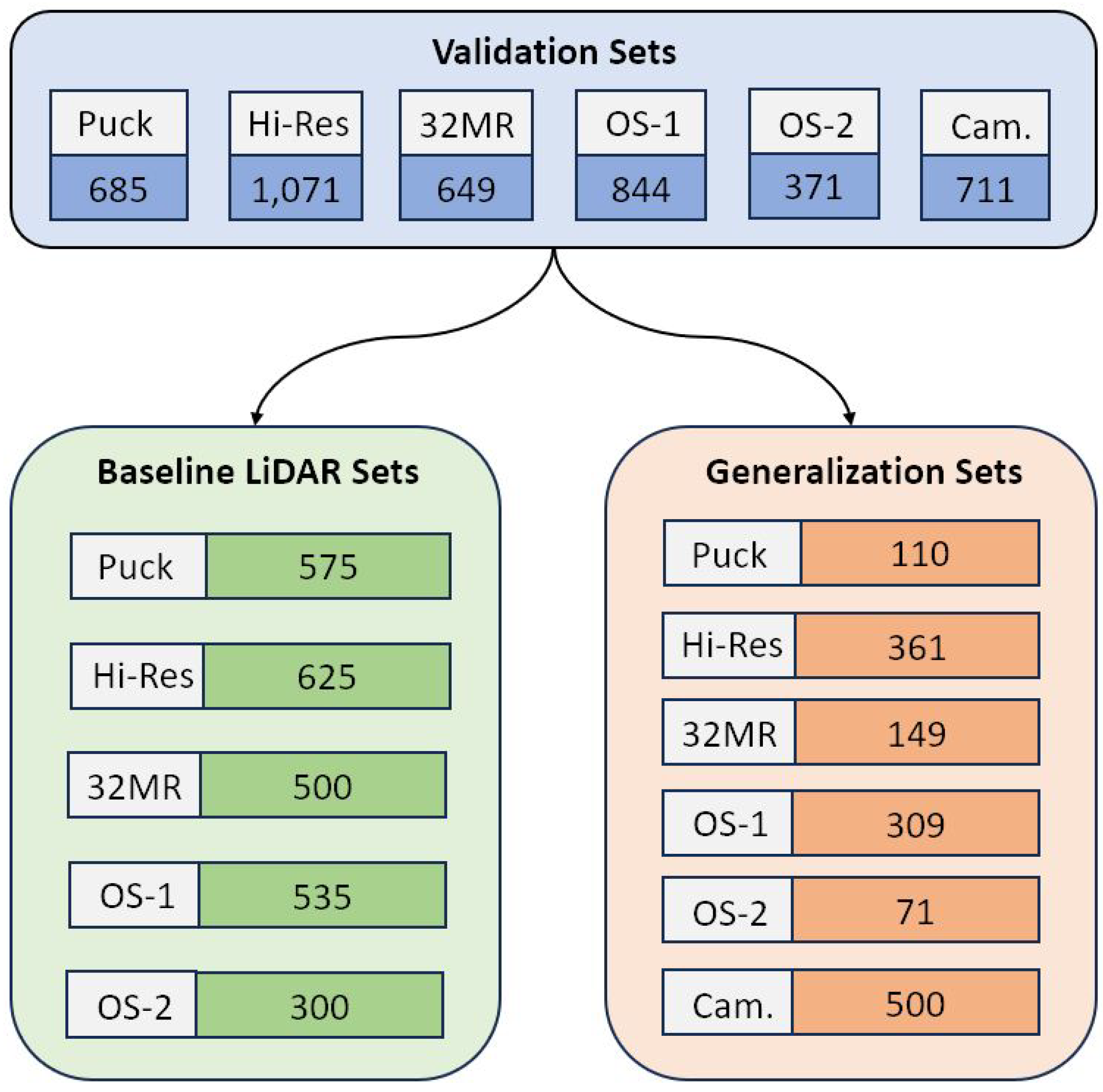
3.5. Training Sets
Numerous benchmarks of the presented systems were tested and compared between sensors. Many of these benchmarks required a different training set for accurate evaluation. An initial split of all data were dictated by the target of interest: train car, discussed in the sections below, or semi-truck, discussed in
Appendix A. A summary of the various testing sets is outlined in
Table 2 for the train car dataset below and
Table A1 for the truck dataset in the Appendix. In each table, “Pos. Scans” refers to any scan in the dataset that included a target of interest, and “Neg. Scans” refers to any scans that did not. The datasets are split into training, “Train”, validation, “Val.”, and test, “Test”, sets. These sets were randomly generated, and consisted of 80%, 10%, and 10% of the total size of the overall data, respectively. Due to randomization during the generation of training, validation, and test set splitting, similar scans may appear across sets. This results in the models intentionally overfitting to data at these specific locations. Commonly, overfitting is viewed as a negative byproduct of not following proper training procedures. However, we show an alternative, beneficial use case for overfitting when inference is always performed on very similar data in the same “scene”. In a real-world deployment, sensor(s) would be placed in a stationary position targeting a railway or road of interest. Here, the viewpoints of the targets would not change, opposite to a constantly changing viewpoint used in autonomous vehicles, and this static relationship can be exploited to increase detection accuracy at these specific deployment locations with a priori knowledge of FoV and target perspective.
The Puck, Hi-Res, 32MR, OS-1, and OS-2 sets were utilized to test how the network performed when trained and tested on data from a single sensor. This served as a baseline in the nearest-neighbor up-sampling methodology previously discussed. The Camera set was produced to evaluate the overall performance compared to the LiDAR sets. The All-LiDAR set was generated to see how well the presented system generalized to any network with all LiDAR sensors. This allows testing of a single, unified model independent of sensor parameters.
The “Light (LiDAR)” and “Light (Camera)” sets were produced to compare the low-light performance of the proposed LiDAR system to that of a camera-based system. Only data from the 32MR was utilized in this LiDAR set as a mid-range sensor. Utilization of a single sensor ensures any issues from the up-sampling methodology does not negatively impact this benchmark. Both the low-light LiDAR and camera sets were generated utilizing data collected at site 4. Finally, “Gen. (LiDAR)” and “Gen. (Camera)” are generalization sets utilized to evaluate the capability of the proposed system to perform in environments not seen during the training process. Here, the up-sampling methodology was utilized with all LiDAR. If the unified model performs comparably to the individual models, then its generalization performance can reasonably be extrapolated to the individual models. Generalization sets were generated using sites 2, 4, and 5, and then inferred and evaluated on site 1. This allows the only variable of change to be the environmental characteristics of the location.
3.6. Embedded Platforms
The models were normally trained on lab PCs containing high-end hardware including NVIDIA Quadro RTX8000 or Titan RTX GPUs. However, embedded platforms such as the NVIDIA Jetson family have special hardware intended for running deep learning models in real-time. The NVIDIA Jetson AGX Xavier, Nano, and NX as well as a Raspberry Pi 4 outfitted with a Google Coral Tensor Processing Unit (TPU) were evaluated for computing on the edge.
3.7. Metrics of Interest
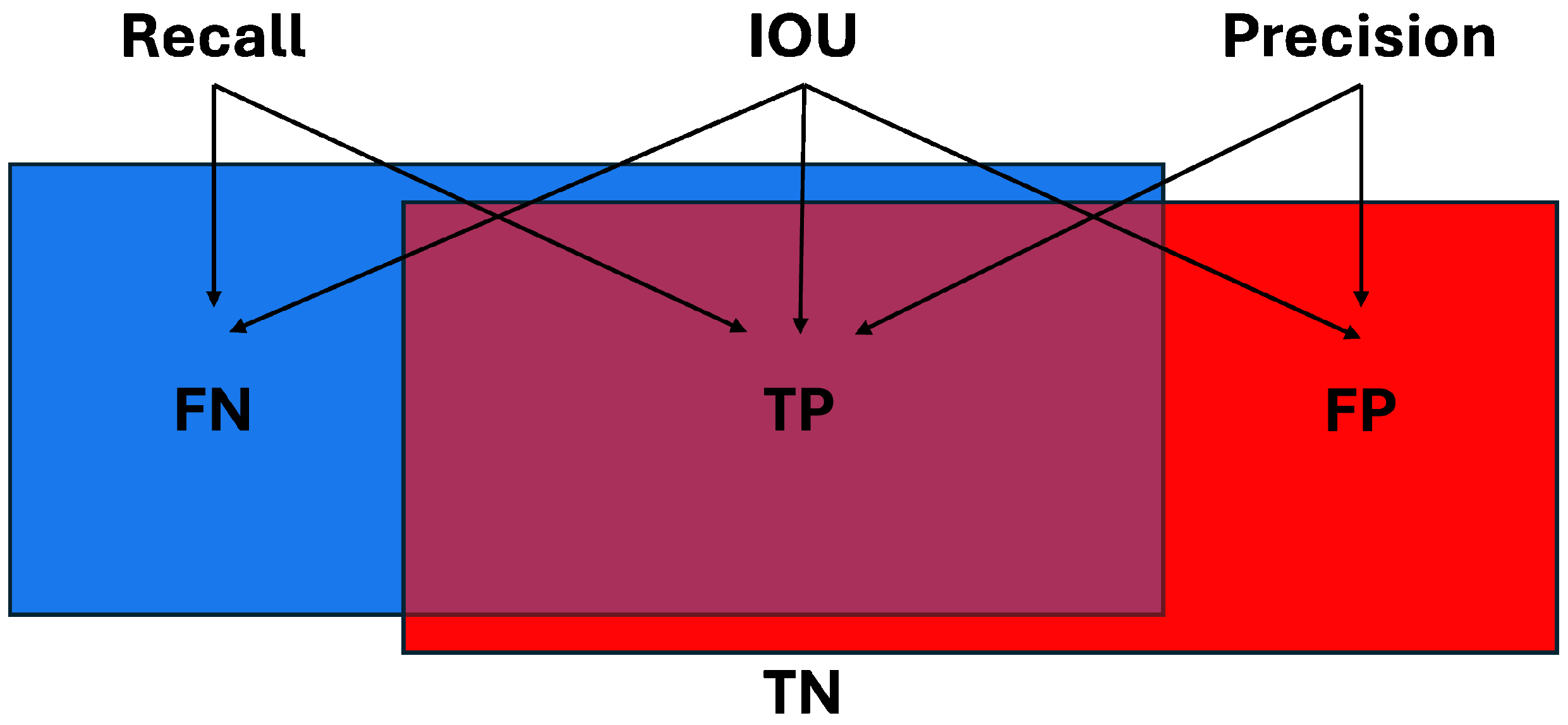
There are a multitude of metrics used to measure performance in the world of segmentation prediction. A brief description of common metrics and justification for using each is provided below. Most of the metrics are derived from four variables:
True Positive (TP)—the ground truth “positive” label for a given class;
True Negative (TN)—all other parts of the data that are not the class label;
False Positive (FP)—the predicted portion of an object that is not labeled as that class in the ground truth data;
False Negative (FN)—the ground truth object that is not classified in the prediction.
Using these four variables, several different performance metrics can be defined for evaluating inference results against the ground truth data. The first is recall which looks at the correctly labeled class TP versus the remainder of the ground truth class FN,
This is useful when determining what portion of the entire ground truth class was labeled correctly, but does not provide any information on how much data were incorrectly labeled as a class, highlighted in
Figure 2. Precision, also shown in
Figure 2, evaluates what percentage of the estimated output was correct by looking at TP and FP,
Precision identifies what portion of the estimated output was correctly labeled, but disregards any ground truth label that was missed. Accuracy considers all four variables to attempt to obtain the full picture of the predicted result,
However, TN can throw off results if its quantity is high, as this artificially inflates the accuracy. By removing TN from the equation, IOU can provide a more realistic accuracy metric that evaluates all parts of the data,
Notice in
Figure 2 that IOU evaluates all parts of the data that are labeled as a specified class in both the ground truth and prediction. Another metric that evaluates TP, FP, and FN variables is F1. It combines precision and recall together resulting in a very similar equation to IOU,
The primary difference between the two most recent metrics mentioned is that F1 places half as much of an emphasis on FP and FN as IOU does. This results in a metric that rewards TP more and punishes FP and FN less. We believe that IOU better captures the accuracy of the system, and thus use mIOU to measure accuracy across all pixels/points. Another metric utilized is the standard deviation,
, of mIOU,
where
n is the number of images/point clouds,
is the IOU score for a given image/point cloud, and
is the average mIOU score across all images/point clouds. The standard deviation helps account for uncertainty and variability in the prediction performance to identify how reliable the network behaves. The final metric utilized is frames per second (FPS) to evaluate whether the deployed network classifies as a real-time system.
5. Discussion
The proposed roadside detection system has the potential to be a powerful tool in tracking vehicles of interest along any road. Targets of train cars and semi-trucks were successfully classified in multiple environments with changing distances from the sensors and traveling at varying speeds. Both LiDAR and camera data were successful at segmenting the targets from other vehicles traveling along the same roads with different advantages. In general, the LiDAR models had comparable validation and testing mIOU results to the camera models. They also displayed a slightly higher frame rate on the embedded platforms. However, the results indicate that the LiDAR models do not generalize as well as the camera models, and thus could require more training to obtain comparable performance when deployed to new sites. Generic LiDAR models such as the All-LiDAR set can be developed to perform well across different LiDAR sensors. This could lead to sensor agnostic deployments that have many benefits.
The strong performance of LiDAR for this application points toward it being a viable and powerful alternative to cameras for semantic segmentation and object classification on the edge. Excellent vehicle semantic segmentation results with data from various vision sensors can be achieved with the proposed roadside/trackside perspective in real-time. The preliminary results indicate this method as being a useful tool to detecting vehicles such as train cars or semi-trucks along any roadside in a non-intrusive manner. This is especially useful in rural areas and back roads where there may be no other intelligent transportation systems present. One specific commercial application is for the detection of semi-trucks on small roadways attempting to bypass required weigh stations which are typically located on primary or major traffic routes. The transportability of this system lends itself to deployment and redeployment for this application and can offer states a solution to this growing problem [
67,
68,
69]. Similarly, this system is capable of remote deployment trackside to monitor railroad traffic for verification of payloads. In urban areas, several upgrades could be integrated into the system. Multiple roadside sensor deployments could remotely connect to one another for identifying heavy flow paths of semi-trucks. Additionally, pre-existing intelligent transportation systems could utilize these data for: (1) counting the instances of vehicles of interest for traffic management; (2) estimating the flow of payloads or personnel of interest along a certain route; (3) rerouting traffic to avoid congestion.
Future works include increasing the robustness of the roadside detection system. The LiDAR models perform well in a low-light environment, but more challenging, real-world conditions such as heavy rain or snow could be difficult for LiDAR to take accurate readings due to unwanted reflections. Performing sensor fusion between the camera and LiDAR could increase the resilience of the system in these extreme weather situations. This will require restructuring the CNN architecture to accept and correlate multimodal raw data that will be fused together through a multi-channel input. More data with a wider range of weather conditions and locations must be collected and trained on to further strengthen the models. Effort will be made to collect smaller amounts of data at a larger number of data collection sites to enhance the diversity of the system and increase the immediate usability. Finally, the models must be tested with other publicly available datasets such as Cityscapes [
70] to perform a comparison study. Similarly, state-of-the-art models will be tested with the custom dataset in future studies to further evaluate the effectiveness on other models.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}