1. Introduction
Human Activity Recognition (HAR) endeavors to comprehend human behaviors and states, utilizing AI systems to proactively furnish effective assistance based on human needs [
1]. Consequently, HAR has evolved into a pivotal realm of investigation, playing an essential role in various domains, encompassing sports, healthcare, smart homes, abnormal activity detection, and smart driving [
2,
3,
4,
5,
6]. The implementation of HAR in these domains typically relies on the utilization of cameras, WiFi-based transmitters and receivers, microphones, and Inertial Measurement Units (IMUs) for gathering data from humans. Nevertheless, cameras and microphones pose privacy concerns in numerous real-world application scenarios [
7]. WiFi-based transmitters and receivers typically depend on channel state information, and the intricate nature of this model introduces challenges in signal acquisition, diminishing the model’s efficiency [
8]. Consequently, smartphones and other wearable devices furnished with inertial sensors, like accelerometers and gyroscopes, find extensive application in HAR. This is attributed to their less intrusive monitoring of human activities and ease of wear. Illustrated in
Figure 1, in general, HAR using IMUs sensors is a classification problem based on temporal signals, in which the corresponding sensor data are collected continuously in chronological order, and the activities are classified according to the user’s activities under different locations.
HAR focuses on analyzing sensor timing signals with long-term dependencies by applying feature extraction and pattern classification techniques to classify the activities performed by users [
1,
9]. In recent years, deep learning has emerged as the predominant technique in the HAR, automatically extracting high-level features tailored to the target task, thereby compensating for the absence of characterization in shallow, hand-crafted features typical in traditional machine learning. In particular, Convolutional Neural Networks (CNNs) [
10] and their variants, such as ResNet [
11], have garnered significant attention in recent times for leveraging the local dependencies and scale invariance present in sensor timing signals to improve the recognition capabilities of models [
12]. Nevertheless, earlier studies [
13] have shown that, for the classification of intricate actions, relying solely on the local dependencies of sensor timing signals is insufficient. This issue arises from the constrained receptive fields of CNN and their variants, making it challenging to extract global information from sensor timing data. Consequently, they struggle to effectively capture long dependencies in sensor timing signals [
14]. Recurrent Neural Networks (RNNs) can leverage the correlation between neurons and are well-suited for addressing time-series problems. Specifically, RNN models utilizing Long Short-Term Memory (LSTM) can capture the temporal long dependencies in sensor time-series signals through LSTM units. However, the sequential nature of the recurrent architecture impedes the parallelization of model training, resulting in sluggish weight updates in the model network [
15]. Moreover, its ability to model long dependencies is restricted by its limited memory capacity. On the other hand, the Transformer model [
16], an architecture designed for highly parallel operations based on a self-attention mechanism, was proposed in previous research. It can capture long dependencies across the entire time series using the attention mechanism, and the extensive receptive domain of the attention mechanism provides richer contextual information [
17]. Not surprisingly, given the success of the Transformer model in Natural Language Processing (NLP), numerous prior studies have explored its application in diverse domains, including computer vision [
18], music series analysis [
19], and others. Furthermore, the method has demonstrated superiority over RNNs and LSTM-based RNNs in sequence classification problems, achieving state-of-the-art generalization capabilities [
20].
In the Transformer model, the self-attention mechanism serves as its core [
16]. This attention mechanism, akin to human perception, seeks to selectively focus on specific regions of the target, enhancing fine details while suppressing irrelevant and potentially confusing information [
21]. The self-attention mechanism is employed to calculate self-attention weights on the time series, capturing the temporal relationships within the input time series. However, a significant limitation of the self-attention mechanism is its divergence from a recurrent network structure, hindering its ability to effectively capture positional information along the time dimension [
22]. This limitation becomes more pronounced in time series data due to its less informative data context [
17]. Consequently, incorporating explicit representations of positional information becomes crucial, as proposed in methods like Sin-Cos Function Position Embedding. In contrast, prior HAR studies employing the Transformer model framework [
15,
20,
23] have exclusively utilized APE (Sin-Cos Function). Nonetheless, Relative Position Embedding (RPE) offers an advantage by providing more positional information—specifically, information about the positions of different elements within the same sequence. This enhancement aids the model in capturing the interdependence of various positions and, consequently, in better comprehending the structural information of the time series [
24], as demonstrated in [
17]. However, for HAR, which is based on acceleration signals, further research and analyses are required.
To address the aforementioned challenges, this paper proposed a high-performance HAR model based on the Transformer architecture, drawing inspiration from the data processing approach in the Vision Transformer [
25]. The model leverages the benefits of the convolutional layer for local dependencies and scale invariance. Recognizing that a sole convolutional layer falls short in preserving local contextual information, we employ three 1D convolutional layers as a feature extractor block to capture local features within the input time series. Subsequently, the Transformer’s self-attention mechanism is employed to adeptly capture the long dependencies within the input time series, utilizing both local and long features for activity classification. Simultaneously, to counteract the Transformer model’s potential oversight of position information within the input time-series data and to enrich the model with additional position information, this paper introduced a pioneering relative position embedding method, vRPE, specifically tailored for acceleration time-series signals associated with human activities. The primary contributions are as follows:
We proposed a novel Transformer model for IMU sensor-based HAR scenarios, which globally models the temporally localized features extracted by the convolutional network instead of the raw input signals, and more comprehensively takes into account the positional information within the sensor timing data via vRPE.
Within the realm of IMU sensor-based HAR, we conducted the first-ever verification using the Transformer model, demonstrating the superiority of RPE over APE. Furthermore, building upon the initial RPE, we introduce the vRPE method and validate its superiority over both existing APE and initial RPE.
To better utilize the different levels of features in the data, we proposed using a multi-layer convolutional neural network as a feature extractor to process the input data, which ensures that richer and hierarchical high-level features are built to improve the model’s generalization ability.
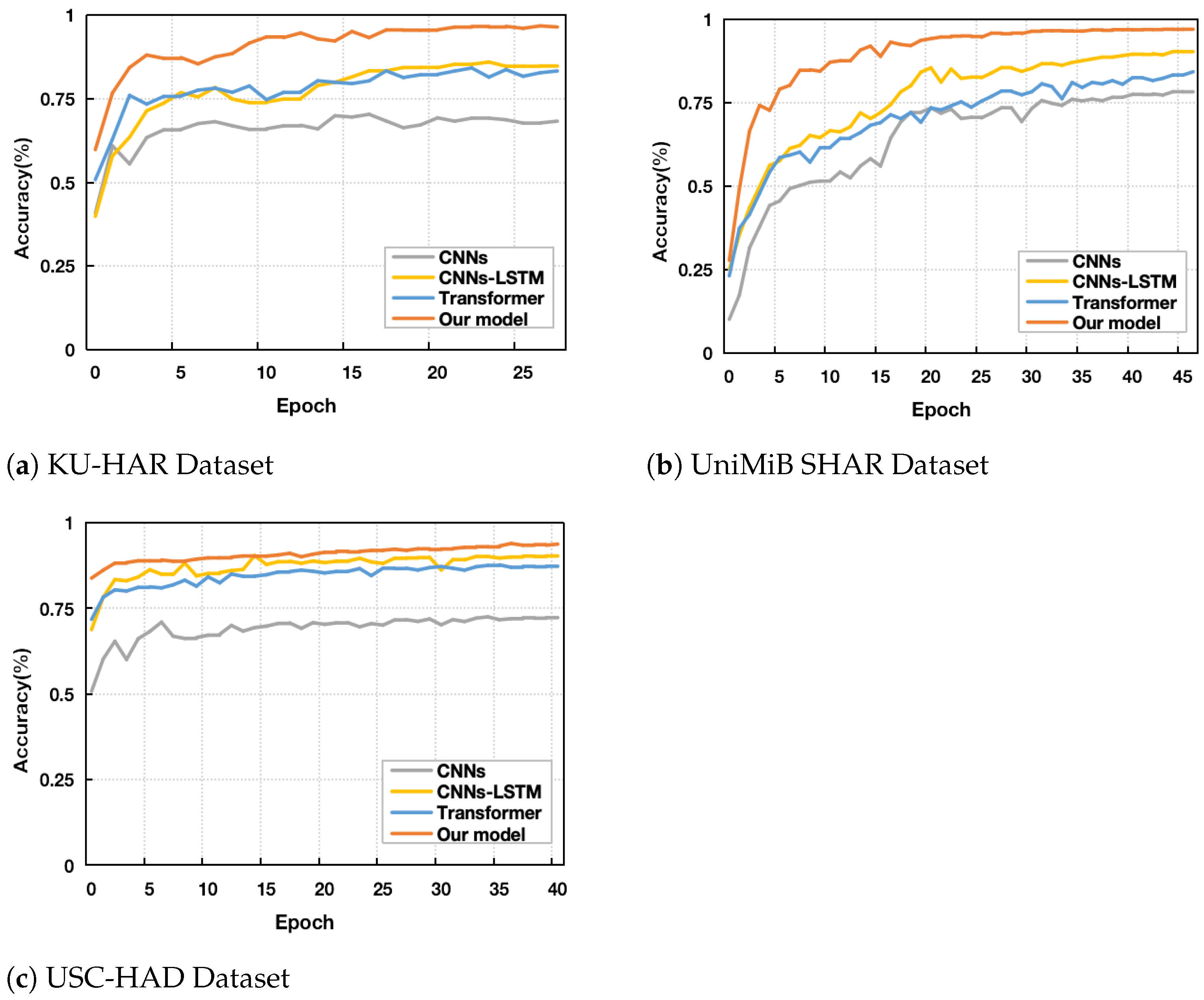
The model exhibits enhanced capability in comprehending the structural information of the input signal and representing features, surpassing the Baseline Models (BMs). Consequently, it attains superior classification performance on three publicly available human activity datasets, namely KU-HAR [
26], UniMiB SHAR [
27], and USC-HAD [
28]. Moreover, the HAR model proposed in this paper has the best performance of our proposed model compared to the existing competitive HAR models.
The structure of this paper is as follows.
Section 2 provides a review of related work.
Section 3 details the proposed model, the baseline model, and the dataset information.
Section 4 outlines the experimental setup and presents the results.
Section 5 delves into the impact of the CFEB, Initial RPE, and our proposed relative position embedding on the Transformer model’s performance. Ablation experiments are conducted to scrutinize our model more comprehensively. Lastly,
Section 6 concludes the paper.
3. Methods
This paper aims to establish a high-performance HAR model based on the Transformer architecture. It encompasses two primary improvements. First, multi-layer convolutional layers capture local temporal features of acceleration signals. Second, we introduce vRPE to traditional MHSA, enabling the model to better interpret the structural information of sensor timing signals for stronger feature modeling.
Figure 2 illustrates the model architecture. Initially, Z-score Normalization is applied to expedite training. Next, CFEB employs a fixed-size window with a one-dimensional convolutional layer to learn deeper local features in the temporal dimension. The encoder then extracts global temporal correlations in the time series using a multi-head attention mechanism with RPE, enhancing the model’s understanding of long dependencies. The final classification layer, comprising fully connected layers and a SoftMax function, produces classification outputs. Moreover, the hyperparameters of the model were optimized through ablation experiments. Ultimately, end-to-end training on publicly available datasets produced a model that outperformed existing methods. The following sections provide further model details.
3.1. Inputs Definition
The given time series dataset consists of n samples, , where represents a -dimensional time series with length L. Here, , and the set of corresponding response labels is denoted as , where and c signifies the number of classes.
3.2. Convolutional Feature Extractor Block
IMU-based HAR tasks usually involve time-series data from sensors, which have significant local time dependence [
15,
23]. Due to the excellent local awareness and translation invariance properties of convolutional layers, they can effectively extract local time-dependent features in time series and improve generalization performance [
42]. However, single-layer convolutional layers are deficient in preserving contextual information, and especially, they have limited effectiveness in modeling patterns across time windows. Therefore, we design CFEB to capture multi-scale local time-dependent features by stacking three 1D convolutional layers. This design not only strikes a balance between computational efficiency and classification performance, but also more fully extracts the local contextual information in the signal, where each layer utilizes an identical set of 256 filters and maintains a consistent kernel size of 5. Meanwhile, to reduce the computational overhead of CFEB as well as to improve the generalization performance of the whole model, we will add the batch normalization layer after the last convolutional layer. Therefore, for a given input sample
, local temporal feature extraction is conducted through convolutional layers, yielding convolutional output
(where
D represents the mapping dimension of the convolutional layer) for
. The CFEB, depicted in the dashed box on the right side of
Figure 2c, specifically processes
through a Convolution Feature Extractor Block that comprises a normalization layer, 1D convolutional layers, batch normalization layer, and ReLU activation. This process is expressed as:
3.3. Multi-Head Self Attention
The attention mechanism can be characterized as a process that maps a query and a set of key-value pairs to an output. This output is computed as a weighted sum of values, with the weight assigned to each value determined by the compatibility function of the query with the corresponding key [
16]. Initially, attention mechanisms were introduced within the domain of natural language processing, relying on recurrent neural networks at their core [
43]. However, Vaswani et al. [
16] proposed a transformer model that exclusively utilizes self-attention. In this model, a query and a set of key-value pairs are mapped to an output. The query vector represents the current element in the sequence, while the key and value vectors represent the other elements in the sequence. To be more specific, for an input sequence,
, self-attention computes an output sequence
, where
. This output is calculated as a weighted sum of input elements:
Each coefficient weight
is calculated by using the SoftMax function:
where
is an attention weight from positions
j to
i and is computed using a scaled dot-product:
The projection matrices
are individual parameter matrices unique to each layer. Instead of performing self-attention just once, the Multi-Head Self-Attention (MHSA) [
16] approach carries out this process in parallel multiple times, employing
h attention heads. The output from each attention head undergoes a linear transformation and is then concatenated to conform to the standard dimensions, namely:
where
,
,
,
.
3.4. Vector-Based RPE
The Transformer architecture relies on explicit positional encoding to retain the positional information of the input data [
41]. Consequently, self-attention alone is incapable of capturing positional information along the time dimension. This inherent limitation is further pronounced when applied to time series data, as such data inherently possess less contextual information compared to other data types [
17]. To address this limitation, in this paper, a method is proposed that utilizes the following RPE approach. This approach primarily involves incorporating the relative positional bias
into each head when calculating weights in the self-attention mechanism. Adding relative positional bias
to (6):
The vRPE we propose is an extension of the attention mechanism, specifically designed to consider the pairwise relationship between two-time points within the input timing signal. The algorithm is presented in Algorithm 1. In Equation (8), the relative position bias
corresponds to the value at position
in vector
. The relative position indexTable
is computed from the positional differences between each time point and other time points in
using a fixed window size. Subsequently, the relative position vector
is obtained by using the index value in the
I to fetch the value in the trainable relative position biasTable
. Accordingly, we need to index
elements from the
vector. The flowchart of the self-injecting attention mechanism operation with vRPE, as can be seen in
Figure 2a. Furthermore, as shown in
Table 1, our proposed vRPE is more efficient in terms of both memory and time complexity compared to the initial RPE methods in the literature.
| Algorithm 1 Vector-based Relative Position Embedding |
| 1: Input: | |
| 2: | ▹ Input sequence of length L and dimension d |
| 3: | ▹ Query and Key weight matrices |
| 4: | ▹ Trainable relative position bias vector |
| 5: | ▹ Relative position index table |
| 6: Output: | |
| 7: | ▹ Relative position bias added to attention weights |
| 8: Initialization: | |
| 9: Compute the relative position index table I based on positional differences |
| 10: Fetch the relative position bias vector using I and T |
| 11: for each time point i from 1 to L do |
| 12: for each time point j from 1 to L do |
| 13: Compute the query vector |
| 14: Compute the key vector |
| 15: Compute the dot product for self-attention score |
| 16: Add the relative position bias from to the self-attention score |
| 17: Calculate the final attention score: |
| 18: end for |
| 19: end for |
| 20: Return:
|
3.5. Feed-Forward Network
The Feed-Forward Network (FFN) alters the output space of the Multi-Head Self-Attention, introducing non-linearity to the Transformer model. The FFN consists of two fully connected layers with a GeLU activation function in between. The corresponding formula is as follows:
3.6. Baseline Models
CNNs model [
31]: As a representative deep learning method, CNNs has become a powerful benchmark. We adapted a one-dimensional CNN training scheme based on [
31] for the three HAR datasets utilized in the experiments. The model comprises three convolutional layers, each connected by a Max Pooling layer activated by a ReLU non-linear function. The output features of the final layer are mapped to a fully connected layer where a Softmax operation is subsequently applied to predict the corresponding probabilities for each activity category.
CNNs-LSTM model [
13]: The advantages of deep convolutional and recurrent networks in sequence modeling tasks have been extensively investigated. For comparison purposes, we replicate the widely used CNNs-LSTM framework [
13] on three benchmark datasets for HAR. The framework is designed by stacking three 2D convolutional layers, each followed by a BatchNorm layer. Two LSTM layers are then inserted to capture long-range dependencies. The filters for the three convolutional layers are 64, 128, and 256, respectively, and the activation function is ReLU. Finally, the output of the third convolutional layer is fed into two LSTM layers, each with 128 hidden neurons. The output of the second LSTM layer is flattened and fed into a fully connected layer to produce the final Softmax probability for activity recognition.
Transformer model [
40]: The self-attention mechanism in the Transformer model calculates potential correlations among the temporal signals themselves in parallel to capture long-range dependencies [
15]. Therefore, to assess the relative performance gains resulting from the proposed approach, the Transformer encoder model [
40] is employed as the BM in this paper. The BM comprises three main parts. The first part is the position embedding section, utilizing APE [
16]. The second part consists of the Transformer encoder layers. In this paper, three encoder layers are configured, with each layer having an input dimension
of 256, a multi-head self-attention
n-heads of 8, and a feed-forward neural network dimension
of 256.
3.7. Dataset Description and Preprocessing
In this study, we conducted experiments using three widely used public datasets: KU-HAR [
26], UniMiB SHAR [
27], and USC-HAD [
28]. These datasets offer a diverse range of activity categories and intricate data distributions, providing robust evidence for evaluating HAR systems. This paper selected three publicly available human activity datasets for evaluation and adopted various data preprocessing methods to improve activity recognition accuracy. Specifically, a third-order Butterworth low-pass filter with a cutoff frequency of 20 Hz is suitable for noise reduction, as nearly all measurable body motion is confined to frequency components below 20 Hz, with 99% of the signal energy concentrated below 15 Hz [
44], thus not resulting in the loss of important features in the data, as shown in
Figure 3. Then, a low-pass filter with a cut-off frequency of 0.2 Hz was employed to eliminate the effect of gravity [
11,
27]. Sensor data were segmented into continuous samples using a sliding window technique. Window size significantly influences the performance of activity recognition. According to a previous study [
45], due to the diversity of human activities in the datasets, there is no clear consensus on the optimal window size. Therefore, to ensure a fair comparison, we adopted the same parameter settings used in [
23,
26,
27]. We summarize the key details of the three datasets in
Table 2.
6. Conclusions
This paper utilizes the Transformer model to capture global information from acceleration time series signals and explores enhancements for robustness in IMU sensor-based activity recognition. Initially, we incorporated RPE into the conventional MHSA mechanism, introducing relative timing position information to enhance the Transformer’s ability to model acceleration signals. Building on this foundation, we proposed the vRPE method, which proved more effective than APE and the initial RPE in helping the Transformer model understand distance and correlation information present in acceleration data. This improves the model’s fine-grained perception of actions, particularly the classification of excessive actions. Additionally, we addressed the Transformer’s limitation in capturing local features by introducing the CFEB, which incorporates local dependencies and scale invariance. Experimental results showed that CFEB improved the Transformer’s performance in analyzing action signals. Finally, testing on several benchmark public HAR datasets demonstrated that our proposed methods enhance the Transformer model’s robustness for HAR tasks.
Future Research: The experimental results demonstrate the proposed model’s effectiveness in accurately classifying activity categories within IMU sensor time series signals. However, further research is needed for real-world applications, as sensor placement and activity variability across different age groups may cause model instability. Our future work will focus on developing and testing practical HAR applications to ensure the model’s effectiveness and applicability in real-world scenarios.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}