Abstract
Single remote sensing image dehazing aims to eliminate atmospheric scattering effects without auxiliary information. It serves as a crucial preprocessing step for enhancing the performance of downstream tasks in remote sensing images. Conventional approaches often struggle to balance haze removal and detail restoration under non-uniform haze distributions. To address this issue, we propose a Dual-domain Feature Fusion Network (DFFNet) for remote sensing image dehazing. DFFNet consists of two specialized units: the Frequency Restore Unit (FRU) and the Context Extract Unit (CEU). As haze primarily manifests as low-frequency energy in the frequency domain, the FRU effectively suppresses haze across the entire image by adaptively modulating low-frequency amplitudes. Meanwhile, to reconstruct details attenuated due to dense haze occlusion, we introduce the CEU. This unit extracts multi-scale spatial features to capture contextual information, providing structural guidance for detail reconstruction. Furthermore, we introduce the Dual-Domain Feature Fusion Module (DDFFM) to establish dependencies between features from FRU and CEU via a designed attention mechanism. This leverages spatial contextual information to guide detail reconstruction during frequency domain haze removal. Experiments on the StateHaze1k, RICE and RRSHID datasets demonstrate that DFFNet achieves competitive performance in both visual quality and quantitative metrics.
1. Introduction
With the rapid advancement of remote sensing technology, remote sensing images have been widely applied in numerous fields such as civil engineering, forestry resource surveys, and geological exploration [1,2,3,4,5]. However, these images are frequently degraded by environmental factors such as atmospheric scattering and cloud, leading to issues such as excessive whitening, reduced contrast, and obscured content [6]. Such degradations severely undermine the utility of remote sensing images in downstream tasks. Consequently, image dehazing has become an essential preprocessing step to enhance the quality and reliability of remote sensing applications.
Early remote sensing image dehazing methods were typically grounded in the atmospheric scattering model [7], where represents the observed hazy image at pixel x, and the model is expressed as
In this model, the global atmospheric light A and the transmission map are estimated using handcrafted priors, and the haze-free image is subsequently reconstructed. Representative priors include the Dark Channel Prior (DCP) [8], Color Attenuation Prior (CAP) [9], and the haze-line model [10]. Fusion-based approaches [11] have also been explored to enhance contrast via multi-scale information. While effective in certain scenarios, these methods rely heavily on assumptions that limit their generalizability in complex haze conditions.
In contrast, deep learning-based approaches have shown superior feature extraction and modeling capabilities, enabling more robust dehazing in complex scenes. DehazeNet [12] and AOD-Net [13] were among the first to introduce convolutional neural networks (CNNs) to this task, demonstrating notable improvements in modeling capacity. Subsequent works such as GridDehazeNet [14] and KFA-Net [15] further improved performance through multi-scale fusion and attention mechanisms, enhancing fine detail recovery. To enhance perceptual quality, generative adversarial networks (GANs), including FD-GAN [16] and recent work by Shen et al. [17], have employed adversarial learning to generate more natural textures. However, GAN-based models often suffer from training instability. Recently, Transformer-based architectures have attracted attention due to their strong long-range dependency modeling capabilities. Methods such as DehazeFormer [18] and GTMNet [19] have demonstrated impressive results, particularly in remote sensing scenarios. Nonetheless, they often struggle with preserving local structures and impose high computational costs. In addition, diffusion models have emerged as a promising direction owing to their stability and generative fidelity. For instance, Huang et al. [20] pioneered the use of diffusion models for dehazing. Yet, their iterative sampling process remains time-consuming.
Despite the significant progress in image dehazing in recent years, most existing approaches still rely heavily on spatial domain modeling while overlooking the potential of frequency domain information. In fact, frequency domain processing offers notable advantages for haze suppression [21,22,23]: since the haze-related signals is primarily concentrated in the low-frequency amplitude components, modulating these components helps to suppress haze more effectively. In contrast, spatial domain methods exhibit strong sensitivity to local details, making them more suitable for restoring details. Therefore, establishing an effective synergy between spatial and frequency domains features holds promise for more precise dehazing. Building on these insights, we design an end-to-end dehazing network via dual-domain feature fusion for remote sensing image. The contributions of this paper are as follows:
- We propose a dual-domain parallel modeling module, termed the Spatial–Frequency Block (Spa-Fre Block), which incorporates a spatial branch using Context Extract Unit (CEU) to capture multi-scale contextual features for local details restruction and a frequency branch using Frequency Restore Unit (FRU) to modulate amplitude for global haze suppression.
- We introduce a Dual-Domain Feature Fusion Module (DDFFM), which serves as a feature fusion attention mechanism. This module builds contextual dependencies between spatial and frequency features based on the self-attention mechanism. To address the limited local modeling capability of Transformers, a parallel convolutional branch is introduced to enhance local perception. In addition, a fusion weight modulation mechanism is employed to adaptively balance spatial and frequency features across different stages.
- We propose an end-to-end network, DFFNet, which features a dual-domain fusion architecture. It incorporates skip connections and attention mechanisms to enhance feature representation, while leveraging the atmospheric scattering model to impose explicit constraints on the dehazing process.
2. Related Work
2.1. Image Dehazing
Image dehazing, a fundamental problem in the field of image enhancement, was initially addressed using contrast adjustment techniques and physical prior-based models.
Enhancement-based methods, such as histogram equalization [24], Retinex [25], MSRCR [26,27], and homomorphic filtering [28], restore images by improving contrast or separating reflectance components. Physical prior-based methods rely on the atmospheric scattering model in Equation (1) to estimate parameters like the transmission map and atmospheric light A through scene statistics. Representative works include Dark Channel Prior (DCP) [8], which assumes low intensity in non-sky regions; Non-Local Image Dehazing [10], leveraging repetitive color patterns; TAN [29], maximizing local contrast; and Fattal’s method [30], based on independent component analysis of reflectance. While these approaches perform well under their respective assumptions, their heavy reliance on such priors—e.g., DCP depends on non-sky regions—limits their effectiveness and generalization in scenarios involving white objects, sky regions, or complex illumination.
With the advancement of deep learning, learning-based dehazing methods have gained prominence in image dehazing. One approach integrates deep networks with physical models to estimate key parameters. For example, DehazeNet [12] employs multi-layer CNNs to extract multi-scale features and uses bilateral ReLU activation for transmission estimation. MSCNN [31] performs coarse-to-fine multi-scale transmission estimation to guide dehazing. AOD-Net [13] consolidates transmission and atmospheric light into a single parameter , mitigating error accumulation. DMMFD [32] combines classical atmospheric scattering model decomposition with deep learning through a multi-model fusion framework. Alternatively, other methods focus on optimizing network architectures, loss functions, and similar components. DCPDN [33] utilizes densely connected pyramid networks to enhance multi-scale feature usage; CycleGAN [34] employs cycle-consistency loss for unpaired haze-to-clear image translation; FD-GAN [35] introduces a fused discriminator that leverages both low- and high-frequency features to guide the generator, exploring more effective end-to-end dehazing.
In recent years, Transformer models have demonstrated strong capabilities in modeling long-range dependencies and capturing global context, leading to notable improvements in image dehazing performance. For instance, DehazeFormer [18] leverages a Swin Transformer backbone with an enhanced window attention mechanism to capture spatial context. AIDTransformer [36] incorporates deformable multi-head attention and spatial attention offset modules, combined with edge-enhanced skip connections, to focus on relevant contextual information while preserving texture and edge details. PCSformer [37] introduces sliding cross-shaped stripes and local–global proxy Transformer blocks to strengthen contextual interactions. Additionally, some approaches have explored the joint utilization of spatial and frequency domain features for dehazing. FOTformer [22] employs frequency-aware attention and content reconstruction networks in the frequency domain, effectively integrating spatial and frequency features to improve the recovery of complex textures and structures. SFAN [23] utilizes hybrid expert modulation and frequency decoupling learning to dynamically adapt to multi-scale features, efficiently handling frequency domain information.
Despite significant progress in image dehazing and some recent works have incorporated frequency domain processing to enhance global modeling, most existing methods perform spatial–frequency feature fusion either sequentially or via channel concatenation, without adequately accounting for their inherent differences. This often leads to feature redundancy or ineffective fusion. Therefore, designing more effective spatial–frequency fusion strategies is critical to fully leverage the complementary strengths of both domains and holds promise for improving dehazing performance in complex haze conditions.
2.2. Feature Fusion
Feature fusion is widely applied in image processing, aiming to integrate multi-level, multi-scale, or multi-modal features to enhance the network’s representational capacity.
Early feature fusion methods primarily relied on multi-scale architectures to extract both local textures and global contours through varying receptive fields, followed by simple concatenation or element-wise addition to integrate features. For instance, MSD-Net [38] employs multi-branch dilated convolutions to capture multi-scale representations, combined with an adaptive fusion strategy to enable cross-scale complementarity—effectively restoring object structures and haze boundaries. Similarly, the U-Net architecture [39] leverages skip connections between the encoder and decoder to fuse shallow detail features with deeper semantic information, making it a widely adopted framework in remote sensing image dehazing. However, such straightforward fusion strategies often fail to distinguish the relative importance of features across different regions, which can lead to redundant or irrelevant information interfering with the network’s representational capacity.
To enhance fusion quality, attention mechanisms have been widely adopted as adaptive weighting strategies in feature fusion. For example, FFA-Net [40] incorporates channel and pixel attention mechanisms at each layer to effectively highlight key regions for dehazing and improve overall reconstruction quality. MSF2DN [41] achieves extensive multi-scale feature interaction through multi-stream fusion modules and dense connections, demonstrating superior performance on real haze images. PSPAN [42] leverages pyramid spatial weighted pixel attention to build multi-scale attention pathways and further boosts cross-scale feature integration efficiency via a feature aggregation module.
With the growing application of Transformers in low-level vision tasks, integrating CNNs and Transformers has emerged as a promising direction for feature fusion [43,44]. This hybrid approach leverages the strengths of CNNs in capturing local details and the capability of Transformers to model long-range dependencies, balancing both local textures and global structures. For instance, ref. [45] employs a Transformer branch to model long-range dependencies and incorporates a cross-attention mechanism to facilitate effective feature interaction between CNN and Transformer representations, resulting in more refined image details and a more coherent global structure. DEA-Net [46] further enhances this synergy by introducing a content-guided attention mechanism in its detail enhancement module, generating adaptive spatial weight maps for each channel to enable differentiated fusion across feature channels.
Against this background, we propose an enhanced self-attention fusion mechanism that leverages the complementary strengths of CNNs and Transformers. This mechanism computes self-attention across features extracted from both the spatial and frequency branches, allowing the model to capture contextual dependencies while simultaneously employing a dedicated convolutional branch to emphasize local structure. To address the high computational cost typically associated with Transformer-based attention, we further reformulate the Query–Key multiplication as an element-wise operation in the frequency domain. This transformation preserves the representational capacity of self-attention while significantly reducing spatial complexity, thereby improving the overall efficiency of the network.
3. Method
3.1. Overall Framework
As illustrated in Figure 1, DFFNet adopts a typical encoder–decoder architecture. During encoding, the network progressively downsamples the input to compress spatial information and increase the number of feature channels. Meanwhile, skip connections from both the spatial and frequency domains are preserved separately for later decoding stage. The decoder mirrors the structure of the encoder and gradually restores the spatial resolution of the image. At each decoding layer, the current feature is fused with the corresponding same-domain skip feature via SKFusion. Notably, DFFNet delays the interaction between spatial and frequency domain features until the decoding phase, thereby minimizing interference between early-stage features from distinct domains. This delayed fusion is later implemented via the DDFFM. Finally, a soft reconstruction module, inspired by [47], is employed to constrain the haze distribution and generate the final dehazed image.
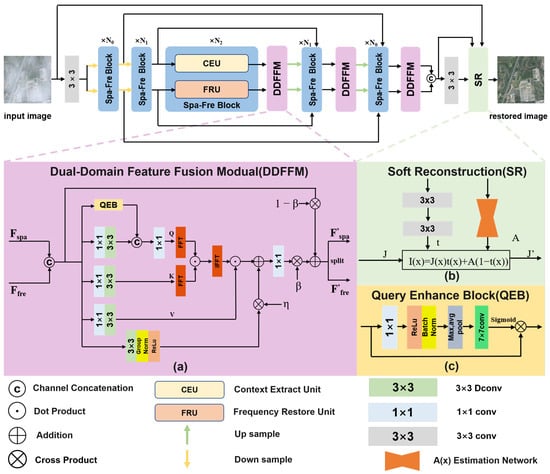
Figure 1.
The overall network architecture of DFFNet (top). The middle parts illustrate (a) the Dual-Domain Feature Fusion Module (DDFFM), (b) the implementation details of soft reconstruction, and (c) the Query Enhance Block (QEB) within the DDFFM. The bottom part contains the symbol legend for basic operations such as convolution and concatenation.
3.2. Spa-Fre Block
The Spa-Fre Block is one of the core functional components of DFFNet. It consists of two parallel branches, the spatial domain unit (CEU) and the frequency domain unit (FRU) as illustrated in Figure 2a and Figure 2b, respectively. This parallel design facilitates the independent processing of spatial and frequency features within the same layer, thereby reducing interference caused by serial computation. The detailed workflow of the Spa-Fre Block is as follows.
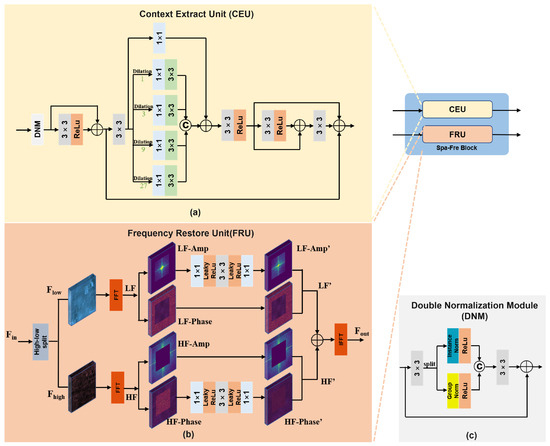
Figure 2.
Architecture of the Spa-Fre Block. The subfigures illustrate (a) the Context Extract Unit (CEU), (b) the Frequency Restore Unit (FRU) and (c) the Double Normalization Module.
Given spatial and frequency features from the previous layer (where B is batch size, C is channels, and H and W are height and width), these are separately fed into the CEU and FRU for further processing. The operation can be formulated as
(a) FRU. In the FRU, we adopt the adaptive threshold mask M proposed in [23] to separate the input feature into high-frequency () and low-frequency () components as follows:
where ⊙ denotes element-wise multiplication. To further process frequency-specific information, we transform both components into the frequency domain via the Fast Fourier Transform (FFT):
Next, to suppress haze-related information, we modulate the amplitude of the low-frequency component using a series of convolutional and LeakyReLU layers:
where is the activation function LeakyReLU. The modulated low-frequency feature is then denoted as . For the high-frequency component , we focus on phase enhancement to strengthen global structural cues. The phase component is modulated as
This results in the refined high-frequency feature . Finally, the restored frequency domain representation is reconstructed by applying an inverse FFT:
(b) CEU. Inspired by the work in [48], the CEU employs multiple dilated convolutions with different dilation rates to capture multi-scale receptive fields. Before performing detail extraction, we introduce a Double Normalization Module (DNM) (Figure 2c) to enhance feature representation and stabilize training.
In the DNM, the input spatial feature is first processed by a convolution and then evenly split along the channel dimension into two parts, and :
Each part is then normalized using Instance Normalization and Group Normalization, respectively, followed by ReLU activation:
The two normalized features are concatenated along the channel axis and passed through another convolution, followed by a residual connection with the original input:
After DNM, the feature is enhanced via a convolution followed by ReLU, and added to the residual to produce the refined feature :
Then, a convolution is applied, followed by a series of parallel dilated convolutions, where each branch is first processed by a convolution:
The resulting multi-scale features are aggregated via channel-wise concatenation and a residual identity connection:
Finally, a series of convolutions with ReLU activations is applied to progressively refine the features, producing the final spatial domain output .
3.3. DDFFM
DDFFM is designed to integrate spatial and frequency domain features. By jointly modeling global dependencies and local structural cues, DDFFM facilitates a more refined fusion to handle spatially non-uniform haze more effectively. It works as follows:
(1) Joint Feature Construction. Given spatial and frequency domain features , we first concatenate them along the channel dimension to form a unified representation:
(2) Global Dependency Modeling. The unified feature F is passed through a convolution followed by a depthwise separable convolution to produce the query (Q), key (K), and value (V) features:
To enhance the expressiveness of the query feature Q, we incorporate a Query Enhance Block (QEB). QEB begins with a convolution followed by ReLU activation and batch normalization. It then extracts statistical priors via max and average pooling, applies a convolution for modulation, and generates attention weights through a sigmoid activation to produce the enhanced query
Next, and K are partitioned into non-overlapping blocks and transformed into the frequency domain using FFT, yielding and . Dot-product attention is computed in the frequency domain to reduce spatial complexity:
The resulting features are converted back to the spatial domain via inverse FFT, and layer normalization is applied to produce . Finally, weighted aggregation of the Value features V is then performed using matrix multiplication:
(3) Local Detail Enhancement. To capture local structure, the original joint feature F is processed using convolutions, Group Normalization, and ReLU activation, yielding local feature :
We design a learnable parameter to balance the global and local contributions:
(4) Fusion Control. Following the findings in [49,50], which suggest cross-domain fusion in later stages improves performance, we introduce a learnable parameter to adjust the contribution of fusion:
(5) Feature Redistribution. Finally, the fused feature Y is split along the channel dimension to generate the enhanced spatial and frequency outputs, and , respectively,
3.4. Loss Function
To jointly optimize both local detail preservation and global semantic consistency, we design a composite loss function comprising pixel-wise L1 loss, perceptual loss, frequency domain loss, and a reconstruction consistency loss for soft dehazing.
Perceptual loss is employed to capture high-level semantic similarity between the predicted image p and the ground truth g. It leverages multi-level features extracted from a pretrained VGG-19 network, specifically from layers conv1_2 to conv5_2:
where is the weight for the i-th layer .
Pixel-level L1 loss is used to ensure point-wise fidelity between predictions and ground truth:
For frequency loss, it is adopted following [51] to emphasize consistency in the spectral domain. Both predicted and ground truth images are transformed via FFT, and the difference is measured with adaptive weighting:
where the dynamic weight is defined as
Here, and represent the frequency components of the reference and predicted images, respectively. The exponent controls the sensitivity to frequency differences and is set to 1 in our implementation.
Soft reconstruction loss is introduced to improve the estimation accuracy of the transmission map and the hazy image . It minimizes the L1 distance between the input hazy image h and the re-synthesized haze image I:
Finally, the overall loss function is defined as a weighted sum:
In this paper, the weights are set as and .
4. Experiments
4.1. Datasets
We evaluate our proposed DFFNet on three publicly available haze remote sensing datasets: StateHaze1k [52], RICE [53], and RRSHID [54]. The image resolution of StateHaze1k and RICE is , whereas that of RRSHID is .
StateHaze1k contains three subsets with different levels of haze density, namely haze1k_thin, haze1k_moderate, and haze1k_thick. Each subset includes approximately 400 pairs of synthesized RGB remote sensing images; among them, 320 image pairs are used for training, 45 for testing, and 35 for validation.
In the haze1k_thick subset, most images are dominated by dense haze with relatively concentrated distribution. The haze1k_thin subset contains images with light haze, where some regions are nearly haze-free. In contrast, the haze1k_moderate subset exhibits the most complex haze distribution, featuring a mix of thin haze, dense haze, and clear areas, thus demonstrating significant non-uniformity.
RICE is a real-world dataset created by Google Earth for the task of remote sensing image dehazing. It is divided into two subsets: RICE1 and RICE2.
In RICE1, most images have evenly distributed haze, with only about 10 images showing uneven haze patterns. To ensure representative coverage of such characteristics, we allocate 5 uneven haze images to both the training and testing sets. In total, the training set consists of 402 image pairs, and the testing set includes 98 pairs.
RICE2 contains images of coastal and inland scenes obscured by real clouds. After manual selection, 24 representative images are designated for the testing set. In total, this subset contains 590 images for training and 146 for testing.
RRSHID is a large-scale real-world dataset featuring paired hazy and haze-free remote sensing images. Unlike synthetic datasets that rely on simplified atmospheric models, RRSHID captures authentic atmospheric phenomena, such as heterogeneous haze densities and spatial distributions within individual images, intricate interactions between haze and diverse land cover types, and color deviations caused by variations in natural lighting and atmospheric composition. This makes it well-suited for validating the robustness of models in real-world scenarios. It is stratified by haze density into three subsets: RRSHID_thin, RRSHID_moderate, and RRSHID_thick.
The RRSHID_thin subset includes 763 image pairs, with 610 for training, 76 for testing, and 77 for validation. The RRSHID_moderate subset, the largest among the three, contains 1526 pairs, allocated as 1220 for training, 152 for testing, and 154 for validation. The RRSHID_thick subset has 764 pairs, with 611 for training, 76 for testing, and 77 for validation.
4.2. Evaluation Metrics
We evaluate the quality of restored images using three commonly adopted standard metrics, which have been widely used in prior works (e.g., [37,55,56]): Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). These metrics collectively assess the restoration performance from pixel-level, structural, and perceptual perspectives.
PSNR quantifies the pixel-wise error between the restored and reference images. Higher PSNR values indicate lower distortion and better fidelity. SSIM measures perceptual similarity by comparing luminance, contrast, and structural information; values closer to 1 denote higher structural consistency. LPIPS evaluates perceptual similarity based on deep features extracted from a pretrained neural network, capturing high-level semantic differences. Lower LPIPS scores correspond to better perceptual alignment.
Together, these metrics provide a comprehensive evaluation of both global semantics and local detail preservation after dehazing. The formulas for each metric are as follows:
where is the maximum pixel value in the image, is base-10 logarithm, x is the dehazed image produced by the model, y is the ground truth, and are the height and width of the image, respectively:
where denotes the mean, is the variance, is the covariance of x and y, and and are constants used to prevent division by zero:
where and represent the feature maps of images x and y extracted at the l-th layer of a pretrained network, and is the weight coefficient of that layer. In this paper, AlexNet is used as the backbone network.
4.3. Implementation Details
We implement and train DFFNet using the PyTorch framework with an NVIDIA RTX 4090 GPU (24 GB). During training, RGB remote sensing images are randomly cropped to a size of , with a batch size of 4. During validation, evaluation is conducted on full-resolution images without cropping. On each subset, DFFNet is trained for 500 epochs, with the total training time being approximately 5–7 h. This time includes per-epoch validation on the training set, which can vary across datasets depending on their size.
In DFFNet, the number of Spa-Fre Blocks in each stage is set to , and the corresponding embedding channel dimensions are . We use the Adam optimizer with an initial learning rate of , , , , and without weight decay. The learning rate is adjusted using a cosine annealing schedule with (i.e., the total number of training epochs) and a minimum learning rate .
4.4. Experimental Results and Analysis
We compare DFFNet with classical dehazing methods and several recent high-impact approaches. These include the prior-based DCP [8], the CNN-based AOD-Net [13], FFA-Net [40], and DCMPNet [57], the Transformer-based DehazeFormer [18], SFAN [23], and the diffusion model-based RSHazeDiff [58]. It is worth noting that SFAN also incorporates frequency domain processing, which aligns it conceptually with our approach and makes the comparison more relevant. To ensure a fair comparison, we adopt the same batch size and input resolution as used in DFFNet, while keeping all other settings consistent with the original implementations of the respective methods. The experimental results are presented as follows.
(1) Results on StateHaze1K: The quantitative evaluation results of different methods on the StateHaze1K dataset are shown in Table 1, which shows that our method achieves top or second-best performance across all haze levels on the StateHaze1K dataset. Notably, it ranks first in both PSNR and LPIPS in light and medium haze conditions, and maintains competitive results under heavy haze, reflecting its effectiveness in both perceptual quality and robustness under varying atmospheric degradations. The “Average” value reported in the table is computed as the arithmetic mean across all haze-level subsets, consistent with the standard practice in related works.

Table 1.
Quantitative results of different methods on the StateHaze1K dataset. The best and second-best results in each column are bolded and underlined, respectively.
The qualitative visual results (see Figure 3) further support these conclusions. In light haze images, DCP exhibits noticeable color oversaturation, while AOD-Net suffers from color distortion and large areas of residual haze. Although FFA-Net, SFAN, and RSHazeDiff perform relatively well in general, there are still slight haze remnants along the left edge of the image. In contrast, both DehazeFormer and our method produce cleaner, more natural-looking images with better detail restoration and perceptual consistency.

Figure 3.
Qualitative comparison on the StateHaze1K dataset. Images in the first, second, and third rows are sampled from the haze1k_thin, haze1k_moderate, and haze1k_thick subsets, respectively. The numbers above each image indicate PSNR, SSIM, and LPIPS scores.
In the medium haze scene, the input image contains haze that is unevenly distributed and varies in thickness. Except for our method, most others show varying degrees of residual haze in the denser lower part of the image. DCP, AOD-Net, and FFA-Net show obvious remnants with a bluish tint, while DCMPNet, SFAN, and RSHazeDiff leave only small residual areas but still show whitening artifacts. Our method, however, achieves complete haze removal and maintains an overall tone closer to the ground truth, aligning well with human visual perception.
In heavy haze images, although most methods can remove the majority of haze, some, such as DCMPNet and RSHazeDiff, still show whitening in grassy areas. Our method effectively restores true color in these regions, maintaining consistency with the surrounding context and demonstrating its precise modeling of contextual information in strongly degraded regions.
(2) Results on RICE: As shown in Table 2, DFFNet achieves the best average performance across PSNR, SSIM, and LPIPS on the RICE dataset. It consistently ranks among the top methods on both RICE1 and RICE2, demonstrating strong capabilities in brightness restoration, structural preservation, and perceptual quality. We also provide qualitative results (Figure 4). In RICE1, we select a lightly hazed image with uneven haze distribution for comparison. Although DCP removes haze globally, it results in severe oversaturation. AOD-Net shows almost no change. While FFA-Net, SFAN, and RSHazeDiff manage to remove the haze, the brightness in the previously hazy areas remains largely unchanged. In contrast, DCMPNet, DehazeFormer, and our DFFNet maintain more uniform brightness across the image, effectively removing haze while preserving natural and consistent colors and contrast. The image shown in RICE2 depicts scenes characterized by light haze and scattered cloud patches. DCP and AOD-Net primarily attempt haze removal by increasing saturation, leaving cloud structures still visible, and AOD-Net incorrectly tints them green. FFA-Net removes the clouds but leaves noticeable green patches in the areas where the clouds were. SFAN and RSHazeDiff show slight improvements but introduce smearing artifacts. By comparison, DCMPNet, DehazeFormer, and our DFFNet not only thoroughly eliminate the haze and clouds but also reasonably restore details in the ground and river regions, delivering a more natural and coherent visual effect.
Table 2.
Quantitative results of different methods on the RICE dataset. The best and second-best results in each column are bolded and underlined, respectively.

Figure 4.
Qualitative comparison on the RICE dataset. Images in the first and second rows are sampled from the RICE1 and RICE2 subsets, respectively. The values displayed above each image indicate PSNR, SSIM, and LPIPS metrics.
(3) Results on RRSHID: According to the quantitative results presented in Table 3, DFFNet demonstrates superior dehazing performance across all three haze levels as well as in the overall average. It consistently achieves the highest values in PSNR and SSIM, along with the lowest LPIPS, particularly excelling under thick haze conditions. These results indicate that DFFNet possesses strong generalization ability and robustness across a wide range of challenging haze scenarios.It is noteworthy that both DFFNet and SFAN incorporate frequency domain processing mechanisms, yet a clear performance gap exists between the two. Although SFAN maintains relatively high SSIM and low LPIPS under moderate and thick haze, its overall PSNR and average performance are inferior. This can be attributed to the more effective spatial–frequency integration in the architecture of DFFNet. RSHazeDiff also performs competitively across multiple metrics, with particularly strong perceptual quality as reflected by its LPIPS score. However, due to its diffusion-based structure, it incurs significantly higher training and inference costs, which may hinder its deployment in practical applications.The qualitative visual results (Figure 5) demonstrate that our model effectively balances detail restoration and haze removal under all three haze levels. It also shows a relatively accurate recovery of ground object colors, indicating strong visual consistency across varying haze densities.
Table 3.
Quantitative results of different methods on the RRSHID dataset. The best and second-best results in each column are bolded and underlined, respectively.

Figure 5.
Qualitative comparison on the RRSHID dataset. Images in the first, second, and third rows are sampled from the RRSHID_thin, RRSHID_moderate, and RRSHID_thick subsets, respectively. The numbers above each image indicate PSNR, SSIM, and LPIPS scores.
4.5. Efficiency Analysis
4.5.1. Inference Time
We evaluate the runtime efficiency on the Haze1k_thick validation set at the original 512 × 512 resolution with the batch size set to 4. As shown in Table 4, DFFNet requires approximately 0.0997 s per image during inference. While not the fastest, it remains comparable to SFAN (0.0880 s), which also incorporates frequency domain processing. The added cost primarily stems from convolution operations in the spatial domain. Nonetheless, DFFNet achieves a good trade-off between performance and efficiency, with inference time still within an acceptable range.
Table 4.
Comparison of model efficiency in terms of parameter count, FLOPs, and inference time. All FLOPs are computed for 256 × 256 inputs, except for the first stage of RSHazeDiff (computed at 64 × 64 resolution).
In contrast, diffusion-based models such as RSHazeDiff are significantly more time-consuming (9.48 s/image) due to their inherently iterative denoising process. For reference, classical methods like DCP, which operate solely on the CPU, are also generally slower than modern CNN-based approaches.
4.5.2. Model Size and Computational Complexity
Table 4 also presents a comparison of model complexity across different dehazing methods in terms of parameter count and FLOPs per 256 × 256 image (except for RSHazeDiff, which operates on a fixed 64 × 64 resolution at the first stage). DFFNet consists of approximately 17.64 million parameters and requires 168.22 GFLOPs, which is higher than lightweight models such as AODNet (0.0018M/0.114G) and frequency-based SFAN (4.03M/16.58G) but still moderate compared to larger networks like FFANet (4.46M/287.53G) and DCMPNet (32.73M/113.63G). RSHazeDiff adopts a two-stage architecture, where the total parameters (109.68M + 0.63M) and FLOPs (15.78G + 6.63G) are reported based on the input sizes specific to each stage.
Although DFFNet achieves a reasonable balance between performance and efficiency, we observe that its relatively high computational complexity mainly stems from the spatial domain branch, particularly the successive 3 × 3 convolutions following dilated operations in each CEU (Table 5). These operations contribute significantly to the overall FLOPs and inference time. Our future work will investigate more lightweight alternatives or convolution-efficient designs to reduce redundancy without sacrificing performance.
Table 5.
Effect of different architectural components on model complexity. seq/par refers to whether FRU and CEU process in serial or parallel. Bold numbers indicate the complexity of the final model (FRU and CEU in parallel), which is adopted as our default architecture.
4.5.3. Effect of Dilation Rates
In this experiment, we evaluate the performance of five different dilation rate configurations on the haze1k_moderate dataset for the image reconstruction task. As shown in Table 6, the configuration (1,3,9,27) achieves the best overall results, with a PSNR of 25.49 dB, SSIM of 0.9066, and the lowest LPIPS (0.0540), indicating superior performance in both structural preservation and perceptual quality. The (1,4,9,16) setting performs slightly worse but still yields competitive results. In contrast, configurations such as (1,2,4,8) and (3,5,7,9) achieve lower reconstruction quality, suggesting that simply using closely spaced dilation rates may limit the model’s receptive field diversity. While larger dilation factors tend to improve performance to some extent, the configuration (1,3,9,36) does not surpass (1,3,9,27), indicating that blindly increasing dilation rates does not always lead to further gains. Excessively large gaps may cause aliasing or the ineffective aggregation of local details. Moreover, higher dilation rates also introduce a marginal increase in inference time. These results demonstrate that the choice of dilation rates significantly impacts model performance. A carefully designed multi-scale spacing is essential for achieving a favorable trade-off between reconstruction quality and computational efficiency.
Table 6.
Effect of different dilation rate settings on model performance. Bold numbers denote the best performance among all settings, which corresponds to the final chosen configuration.
4.6. Ablation Study
4.6.1. Ablation Studies on Model Components
We conduct ablation experiments on the Haze1k_moderate dataset to evaluate the contributions of the CEU, FRU, and DDFFM modules, and to examine the effect of arranging CEU and FRU in series. All experiments use identical training settings.
As shown in Table 7, replacing DDFFM with vanilla attention, removing either FRU or CEU, or arranging FRU and CEU in series all lead to noticeable drops in PSNR and other evaluation metrics, compared to the complete DFFNet.
Table 7.
Ablation studies for different components in the model. The best results in each column are bolded.
Specifically, replacing DDFFM degrades the effectiveness of spatial–frequency feature fusion, as vanilla attention only models global dependencies within each domain, ignoring local interactions. Removing FRU leads to weaker haze suppression. While FRU still contributes to global haze suppression, removing CEU results in inadequate restoration of local details due to the lack of spatial contextual information.
Moreover, serially connecting FRU and CEU within the same layer degrades performance significantly (PSNR drops by 4.61 dB, SSIM by 0.208). This arrangement introduces redundant noise from FRU that cannot be effectively refined by the subsequent CEU.
Figure 6 provides qualitative evidence that aligns with the analytical insights derived from the ablation results. Compared to variants (b–e), image (f) exhibits the least residual haze in the bottom-right corner and the most visually consistent tone with the surrounding areas, highlighting the superior restoration quality achieved by the complete DFFNet.

Figure 6.
Results of the ablation study. (a) Input image. (b) CEU + DDFFM. (c) CEU + FRU (sequential) + DDFFM. (d) CEU + FRU (parallel) + vanilla attention. (e) FRU + DDFFM. (f) CEU + FRU (parallel) + DDFFM (ours). (g) Ground Truth.
4.6.2. Ablation on Learnable Fusion Weights
To evaluate the impact of the two learnable parameters and in the proposed DDFFM module on model performance, we conducted an ablation study by comparing the results under different fixed values of these parameters. Specifically, we conducted controlled experiments under four different parameter settings, where both and were fixed to either 0.5 or 1. In each setting, all three DDFFM modules in the network used the same values of and . The results are summarized in Table 8. Additionally, we recorded the learned values of and during standard training, collected from DDFFM modules at different layers, as shown in Table 9.
Table 8.
Comparison of model performance under different fixed parameters and on haze1k_moderate.
Table 9.
The actual learned parameter values of and (for each DDFFM module) by the model on Haze1k_moderate.
From the results, we observe that the fixed setting achieves the best performance, yielding the highest PSNR and SSIM as well as the lowest LPIPS. However, the learned values of and vary significantly across different layers, suggesting that the model adapts its fusion strategy based on spatial location or semantic content.
4.6.3. Component Effectiveness Analysis
In this subsection, a representative remote sensing image characterized by non-uniform haze distribution is selected as an input example, where the bottom-left region is heavily obscured by dense haze, while the remaining areas are relatively clear or haze-free. Figure 7 illustrates how the input is progressively processed across different layers of the network. Frequency domain and spatial domain feature maps are highlighted with orange and yellow borders, respectively. Layers 3 to 5 illustrate the feature representations before and after DDFFM fusion. From left to right, the columns correspond to input features from the frequency and spatial branches, concatenated dual-domain features, fused outputs after DDFFM processing, and separately recovered frequency domain and spatial domain outputs obtained via channel-wise decomposition.
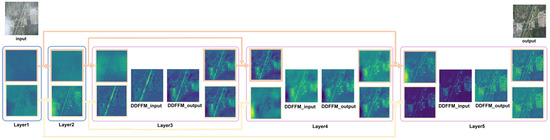
Figure 7.
Visualization of PCA-reduced feature maps using the Viridis colormap. Note that in the Viridis colormap, brighter colors indicate higher feature values and do not correspond to the actual image colors.
In the early feature extraction stages (Layer1–Layer2), the spatial and frequency branches process the input image independently. The spatial domain features preserve texture and structural details with well-defined ground object contours. In contrast, the frequency domain features contain less fine detail but begin to reflect the global distribution of haze across the image. This stage clearly highlights the representational differences between the two branches.
By Layer3, before DDFFM fusion, the frequency domain features begin to exhibit green-colored activations corresponding to hazy regions, indicating that the network has started responding to haze-specific signals. Meanwhile, spatial features remain focused on key structural regions such as roads, retaining stronger local details.
In Layer4, before DDFFM fusion, frequency domain features appear blurred and lack structural sharpness, whereas spatial features maintain rich contextual information due to residual connections from earlier layers (e.g., Layer2). Following fusion via the DDFFM module in Layer4, both branches show evidence of complementary enhancement. Although details in the densest haze regions remain partially suppressed, the overall structural coherence improves.
In Layer5, prior to DDFFM fusion, the frequency domain branch exhibits homogeneous green blobs over the dense haze regions, indicating a strong activation response. Conversely, the spatial branch features are more textured and edge-enhanced, often attributed to skip connections that incorporate earlier feature representations. After final fusion in Layer5, the outputs from both branches become more consistent in color and structure, with significant detail restoration in previously obscured haze regions.
This progression demonstrates the complementary nature of spatial and frequency modeling: while the frequency branch excels at capturing and suppressing global haze artifacts, it is less effective at fine-grained detail recovery. The spatial branch, providing contextual cues, enhances local structural reconstruction.
The proposed DDFFM module enables dynamic feature integration between the two domains, achieving both noise suppression and information enhancement. This mitigates information loss in the frequency branch and reduces interference during fusion, ultimately yielding superior reconstruction quality—particularly in dense haze regions. These observations validate the complementary advantages of dual-domain modeling and highlight the critical role of DDFFM in bridging local detail recovery with global semantic awareness.
5. Conclusions
In this study, we proposed DFFNet, an end-to-end dehazing network for remote sensing images that leverages dual-domain feature fusion from spatial and frequency domains. By processing spatial and frequency features in parallel, DFFNet exploits the global modeling capacity of the frequency domain and the fine-grained detail preservation of the spatial domain, effectively addressing the challenges posed by spatially uneven haze. A dedicated fusion module in the decoder selectively integrates complementary features from both domains, while a composite loss function—comprising pixel-wise L1 loss, perceptual loss, frequency domain loss, and soft reconstruction loss to ensure a balanced optimization of local detail and global consistency. Extensive experiments demonstrate that DFFNet achieves competitive performance across various haze conditions and maintains strong generalization ability. While effective, the frequency domain processing still has room for improvement. Our future work will explore more advanced frequency modeling techniques and extend the framework to broader remote sensing image enhancement tasks. Additionally, the spatial branch of the model incurs considerable computational overhead, which poses challenges for deployment. Therefore, we will also investigate more efficient architectural designs to reduce complexity while maintaining performance.
Author Contributions
Conceptualization, H.J.; methodology, Z.C. and Z.S.; software, H.J. and Z.C.; validation, H.J. and Z.S.; writing—original draft preparation, Z.C. and Z.S.; writing—review and editing, H.J. and Z.S.; visualization, Z.C. and Z.S.; supervision, K.S. and Z.S.; project administration, H.J.; funding acquisition, Z.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (NSFC), grant number 42301434.
Data Availability Statement
The datasets used in this study are publicly available: StateHaze1k, https://www.dropbox.com/scl/fi/wtga5ltw5vby5x7trnp0p/Haze1k.zip?rlkey=70s52w3flhtif020nx250jru3&e=1&dl=0 (accessed on 16 August 2025); RICE, https://drive.google.com/file/d/1CricZtIj28BGFvkD_x-W8fSexPiDtgHk/view (accessed on 16 August 2025); RRSHID, https://drive.google.com/file/d/1uBwHM8tyw69xafFHd01vMERs3TadUmxT/view (accessed on 16 August 2025). The source code implementing DFFNet is available at https://github.com/chen29181/DFFNet (accessed on 16 August 2025). Implementations of comparison methods are not included in our repository; we relied on their official releases as cited.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Park, S.; Song, A. Shoreline Change Analysis with Deep Learning Semantic Segmentation Using Remote Sensing and GIS data. KSCE J. Civ. Eng. 2024, 28, 928–938. [Google Scholar] [CrossRef]
- Zhuang, L.W.; Wen, Z.M.; Lin, M.X. Research Progress and Prospect of Forestry Eco-efficiency in China. World For. Res. 2024, 37, 80–85. [Google Scholar]
- Yu, Y.; Ai, H.; He, X.J.; Yu, S.H.; Zhong, X.; Zhu, R.F. Attention-based Feature Pyramid Networks for Ship Detection of Optical Remote Sensing Image. J. Remote Sens. 2020, 24, 107–115. [Google Scholar] [CrossRef]
- Liu, S. Advances in Remote Sensing Extraction of Urban Roads. E3S Web Conf. 2021, 290, 02023. [Google Scholar]
- Nagar, S.; Farahbakhsh, E.; Awange, J.; Chandra, R. Remote Sensing Framework for Geological Mapping via Stacked Autoencoders and Clustering. Adv. Space Res. 2024, 74, 4502–4516. [Google Scholar] [CrossRef]
- Liu, K.; He, L.; Ma, S.; Gao, S.; Bi, D. A Sensor Image Dehazing Algorithm Based on Feature Learning. Sensors 2018, 18, 2606. [Google Scholar] [CrossRef] [PubMed]
- Ju, M.; Gu, Z.; Zhang, D. Single Image Haze Removal Based on the Improved Atmospheric Scattering Model. Neurocomputing 2017, 260, 180–191. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. Single Image Dehazing Using Color Attenuation Prior. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 1–5 September 2014; pp. 1–8. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local Image Dehazing. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing Underwater Images and Videos by Fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-Net: All-in-One Dehazing Network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4780–4788. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Jiang, B.; Wang, J.; Wu, Y.; Wang, S.; Zhang, J.; Chen, X.; Li, Y.; Li, X.; Wang, L. A Dehazing Method for Remote Sensing Image Under Nonuniform Hazy Weather Based on Deep Learning Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Dong, Y.; Liu, Y.; Zhang, H.; Chen, S.; Qiao, Y. FD-GAN: Generative Adversarial Networks with Fusion-Discriminator for Single Image Dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10729–10736. [Google Scholar]
- Shen, H.; Zhong, T.; Jia, Y.; Wu, C. Remote Sensing Image Dehazing Using Generative Adversarial Network With Texture and Color Space Enhancement. Sci. Rep. 2024, 14, 12382. [Google Scholar] [CrossRef]
- Song, Y.; He, Z.; Qian, H. Vision Transformers for Single Image Dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef]
- Li, H.; Zhang, Y.; Liu, J.; Ma, Y. GTMNet: A Vision Transformer with Guided Transmission Map for Single Remote Sensing Image Dehazing. Sci. Rep. 2023, 13, 9222. [Google Scholar] [CrossRef]
- Huang, Y.; Xiong, S. Remote Sensing Image Dehazing Using Adaptive Region-Based Diffusion Models. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Jiang, X.; Zhang, X.; Gao, N.; Deng, Y. When Fast Fourier Transform Meets Transformer for Image Restoration. In Computer Vision—ECCV 2024; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2025; Volume 15103, pp. 22:1–22:15. [Google Scholar] [CrossRef]
- Zhang, Y.; He, X.; Zhan, C.; Li, J. Frequency-Oriented Transformer for Remote Sensing Image Dehazing. Sensors 2024, 24, 3972. [Google Scholar] [CrossRef] [PubMed]
- Shen, H.; Ding, H.; Zhang, Y.; Cong, X.; Zhao, Z.-Q.; Jiang, X. Spatial-frequency Adaptive Remote Sensing Image Dehazing with Mixture of Experts. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4211114. [Google Scholar] [CrossRef]
- Hadjidemetriou, E. Use of Histograms for Recognition. Ph.D. Thesis, Columbia University, New York, NY, USA, 2002. [Google Scholar]
- Land, E. Lightness and Retinex Theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. Retinex Processing for Automatic Image Enhancement. J. Electron. Imaging 2004, 13, 100–110. [Google Scholar] [CrossRef]
- Rahman, Z.U.; Jobson, D.J.; Woodell, G.A. Multi-scale Retinex for Color Image Enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996. [Google Scholar]
- Seow, M.J.; Asari, V.K. Ratio Rule and Homomorphic Filter for Enhancement of Digital Colour Image. Neurocomputing 2006, 69, 954–958. [Google Scholar] [CrossRef]
- Tan, R.T. Visibility in Bad Weather From a Single Image. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Fattal, R. Single Image Dehazing. ACM Trans. Graph. 2008, 27, 1–9. [Google Scholar] [CrossRef]
- Ren, W.; Pan, J.; Zhang, H.; Cao, X.; Yang, M.H. Single Image Dehazing via Multi-scale Convolutional Neural Networks with Holistic Edges. Int. J. Comput. Vis. 2019, 128, 240–259. [Google Scholar] [CrossRef]
- Zhang, H.; Patel, V.M. Densely Connected Pyramid Dehazing Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3194–3203. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Yu, J.; Xiong, C.; Li, D. Physics-Based Fast Single Image Fog Removal. In Proceedings of the IEEE 10th International Conference on Signal Processing Proceedings, Beijing, China, 24–28 October 2010. [Google Scholar]
- Deng, Z.; Zhu, L.; Hu, X.; Fu, C.W.; Xu, X.; Zhang, Q.; Qin, J.; Heng, P.A. Deep multi-model Fusion for Single-image Dehazing. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2453–2462. [Google Scholar]
- Kulkarni, A.; Murala, S. Aerial Image Dehazing with Attentive Deformable Transformers. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 6305–6314. [Google Scholar]
- Zhang, X.; Xie, F.; Ding, H.; Yan, S.; Shi, Z. Proxy and Cross-Stripes Integration Transformer for Remote Sensing Image Dehazing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Tong, L.; Liu, Y.; Li, W.; Chen, L.; Chen, E. Haze-Aware Attention Network for Single-Image Dehazing. Appl. Sci. 2024, 14, 5391. [Google Scholar] [CrossRef]
- Zhou, H.; Chen, Z.; Li, Q.; Tao, T. Dehaze-UNet: A Lightweight Network Based on UNet for Single-Image Dehazing. Electronics 2024, 13, 2082. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. In Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020; pp. 11908–11915. [Google Scholar]
- Wang, J.; Ma, C.; Zhao, S. MSF2DN: Multi-scale Fusion and Features Distillation Network for Single Image Dehazing. In Proceedings of the Asian Conference Computer Vision (ACCV), Macao, China, 4-8 December 2022; pp. 563–580. [Google Scholar]
- Zhang, Y.; Liu, Q.; Wang, D. PSPAN: A Pyramid Space Pixel Attention Network for Single Image Dehazing. Multimed. Tools Appl. 2023, 82, 13719–13741. [Google Scholar]
- Chen, J.; Tian, X.; Du, C. DPCSANet: Dual-Path Convolutional Self-Attention for Small Ship Detection in Optical Remote Sensing Images. Electronics 2025, 14, 1225. [Google Scholar] [CrossRef]
- Pan, P.; Wang, H.; Wang, C.; Nie, C. ABC: Attention with Bilinear Correlation for Infrared Small Target Detection. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 2381–2386. [Google Scholar]
- Liu, H.; Li, X.; Tan, T. Interaction-Guided Two-branch Image Dehazing Network. In Proceedings of the Asian Conference on Computer Vision (ACCV), Hanoi, Vietnam, 8–12 December 2024; pp. 4069–4084. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z.M. DEA-Net: Single Image Dehazing Based on Detail-Enhanced Convolution and Content-Guided Attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef]
- Yu, H.; Huang, J.; Zheng, K.; Zhao, F. High-Quality Image Dehazing with Diffusion Model. arXiv 2023, arXiv:2308.11949. [Google Scholar]
- Chalavadi, V.; Jeripothula, P.; Datla, R.; Ch, S.B.; Mohan, C.K. mSODANet: A Network for Multi-Scale Object Detection in Aerial Images Using Hierarchical Dilated Convolutions. Pattern Recognit. 2022, 126, 108548. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, Q.; Yuan, M.; Zhang, Y. SFDFusion: An Efficient Spatial-Frequency Domain Fusion Network for Infrared and Visible Image Fusion. In Proceedings of the 27th European Conference on Artificial Intelligence (ECAI), Santiago de Compostela, Spain, 19–24 October 2024; pp. 482–489. [Google Scholar]
- Chen, L.; Fu, Y.; Gu, L.; Yan, C.; Harada, T.; Huang, G. Frequency-aware Feature Fusion for Dense Image Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2024. [Google Scholar] [CrossRef]
- Jiang, L.; Dai, B.; Wu, W.; Loy, C.C. Focal Frequency Loss for Image Reconstruction and Synthesis. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13919–13929. [Google Scholar]
- Huang, B.; Zhi, L.; Yang, C.; Sun, F.; Song, Y. Single Satellite Optical Imagery Dehazing Using SAR Image Prior Based on Conditional Generative Adversarial Networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1806–1813. [Google Scholar]
- Lin, D.; Xu, G.; Wang, X.; Wang, Y.; Sun, X.; Fu, K. A Remote Sensing Image Dataset for Cloud Removal. arXiv 2019, arXiv:1901.00600. [Google Scholar] [CrossRef]
- Zhu, Z.H.; Lu, W.; Chen, S.B.; Ding, C.H.Q.; Tang, J.; Luo, B. Real-World Remote Sensing Image Dehazing: Benchmark and Baseline. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–14. [Google Scholar] [CrossRef]
- Lv, M.; Song, S.; Jia, Z.; Li, L.; Ma, H. Multi-Focus Image Fusion Based on Dual-Channel Rybak Neural Network and Consistency Verification in NSCT Domain. Fractal Fract. 2025, 9, 432. [Google Scholar] [CrossRef]
- Guan, X.; He, R.; Wang, L.; Zhou, H.; Liu, Y.; Xiong, H. DWTMA-Net: Discrete Wavelet Transform and Multi-Dimensional Attention Network for Remote Sensing Image Dehazing. Remote Sens. 2025, 17, 2033. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, S.; Li, H. Depth Information Assisted Collaborative Mutual Promotion Network for Single Image Dehazing. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 2846–2855. [Google Scholar]
- Xiong, J.; Yan, X.; Wang, Y.; Zhao, W.; Zhang, X.-P.; Wei, M. RSHazeDiff: A Unified Fourier-Aware Diffusion Model for Remote Sensing Image Dehazing. IEEE Trans. Intell. Transp. Syst. 2025, 26, 1055–1070. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).