
Text-Guided Visual Representation Optimization for Sensor-Acquired Video Temporal Grounding

Abstract
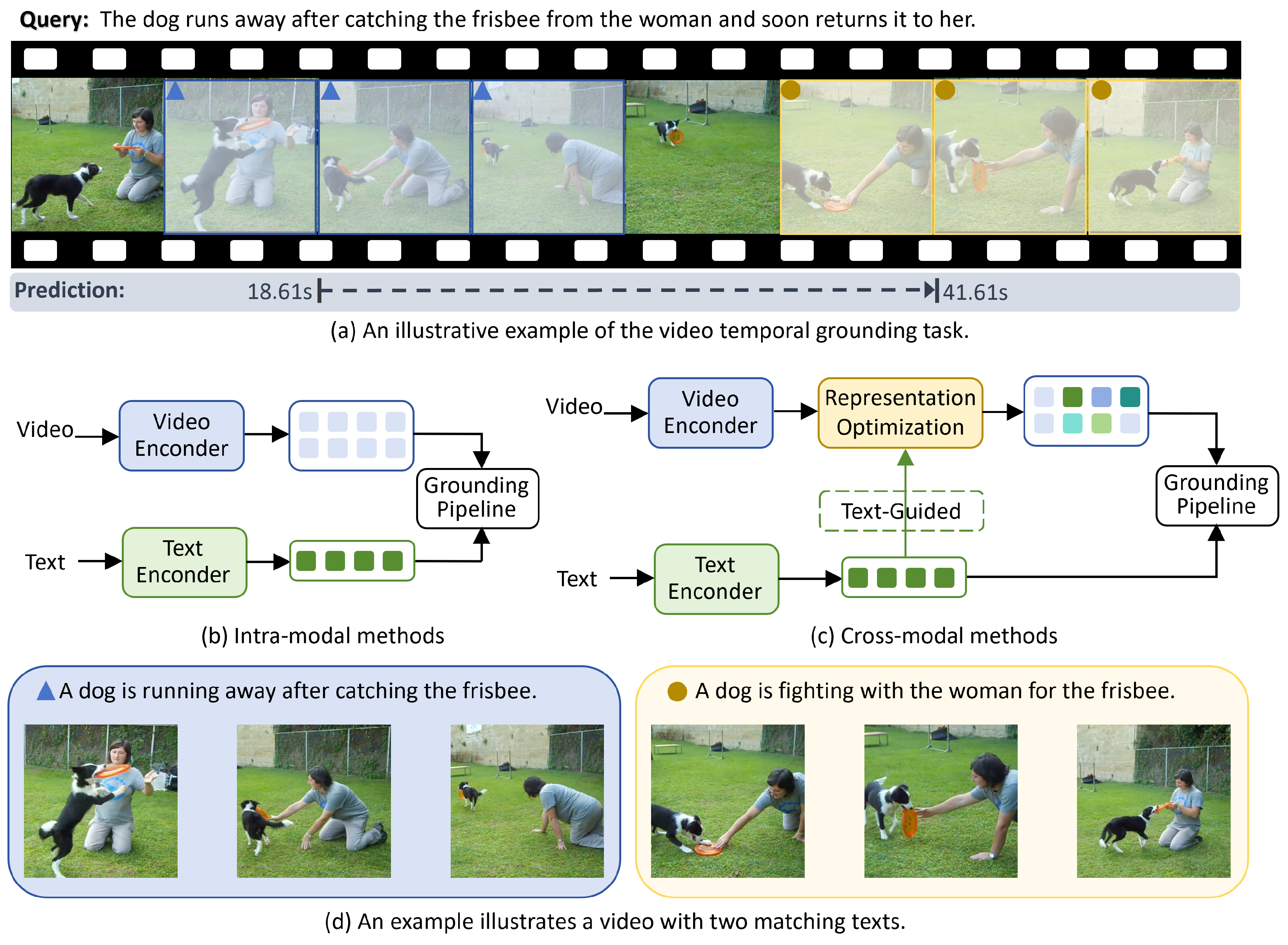
1. Introduction
- We propose a text-guided visual representation optimization framework for video temporal grounding, which introduces cross-modal interaction during the visual encoding stage. This framework reshapes visual representations derived from sensor-acquired video signals under semantic conditioning by natural language queries.
- We design spatial and temporal optimization modules that identify semantically relevant patches and frames from sensed video streams. These modules enhance the discriminability of visual features at both intra-frame and inter-frame levels, contributing to more precise semantic grounding.
- Extensive experiments on three public benchmarks demonstrate that our method consistently outperforms existing approaches. Furthermore, the proposed modules exhibit strong generalization and can be seamlessly integrated into various VTG architectures, offering performance improvements without modifying the core structure. These results highlight the method’s potential in intelligent visual sensing and semantic-level video interpretation.
2. Related Work
2.1. Video Temporal Grounding
2.2. Cross-Modal Learning for VTG
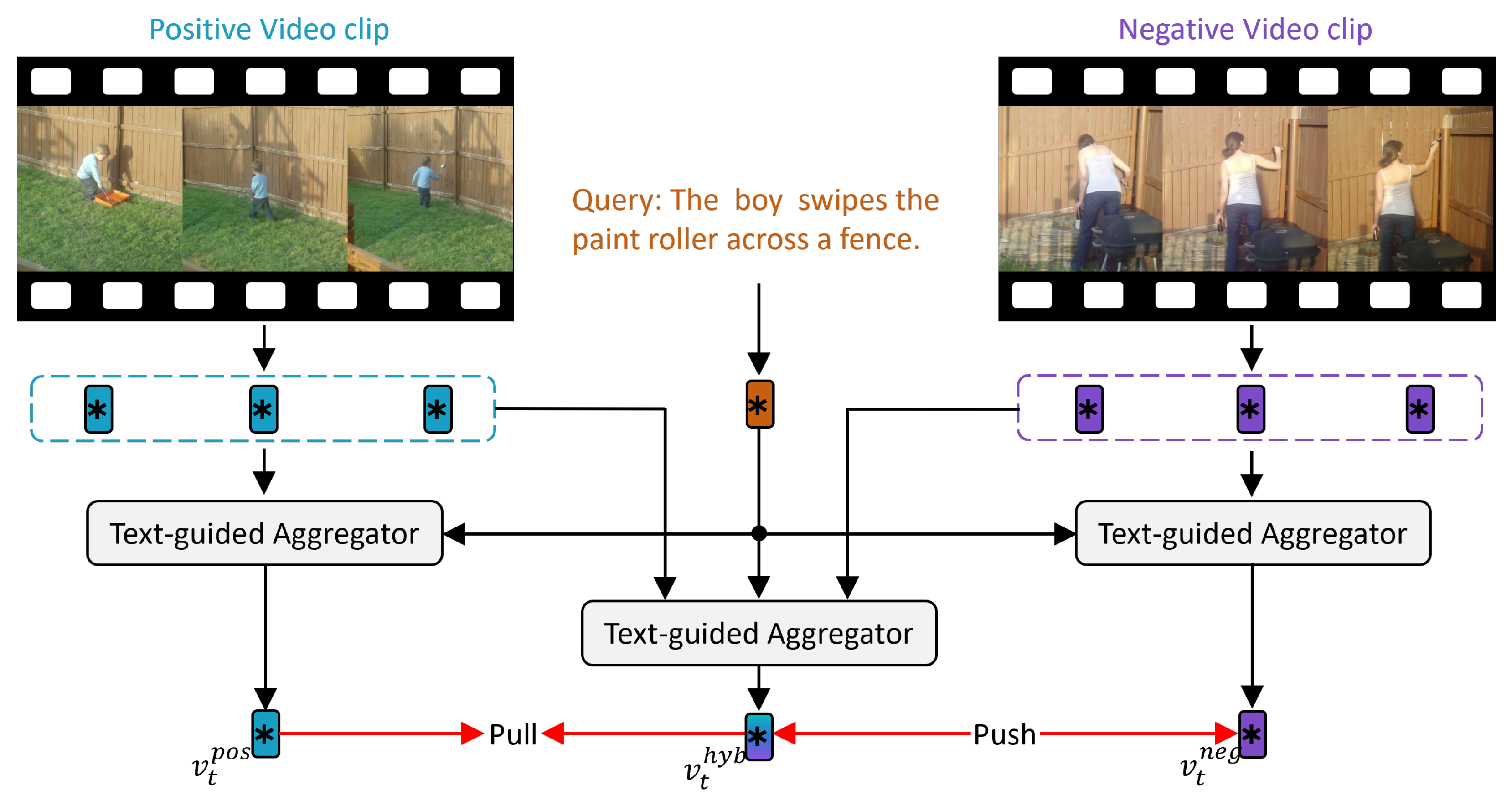
2.3. Contrastive Learning for VTG
3. Methodology
3.1. Problem Definition
3.2. Preparation
3.3. Spatial Visual Representation Optimization
3.4. Temporal Visual Representation Optimization
3.5. Grounding Head
3.6. Loss Function
3.6.1. Binary Cross-Entropy
3.6.2. Cross-Modal Matching
4. Experiments
4.1. Datasets
4.2. Experimental Settings
4.2.1. Evaluation Metrics
4.2.2. Implementation Details
4.3. Comparison to State-of-the-Art Methods
4.3.1. Comparative Methods
4.3.2. Quantitative Comparison
4.3.3. Plug and Play
4.4. Ablation Study
4.4.1. Effect of Individual Components
4.4.2. Effect of Text-Guided Mechanisms in Different Components
4.4.3. Effect of the Number of Salient Patches
4.4.4. Parameter Sensitivity
4.4.5. Effect of Different Visual Features
4.5. Qualitative Analysis
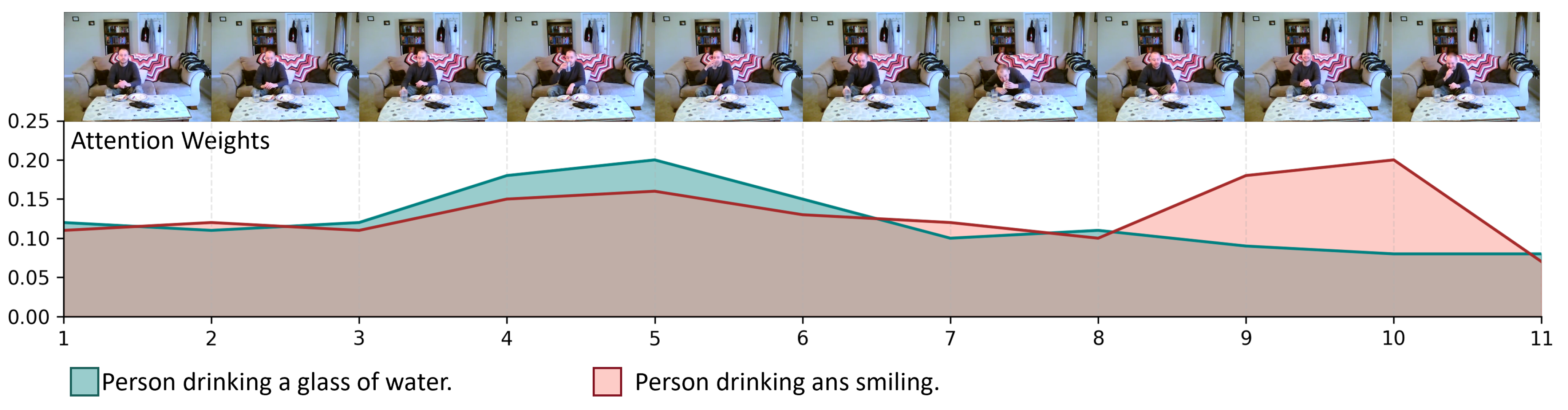
4.5.1. Inter-Frame Visualization
4.5.2. Intra-Frame Visualization
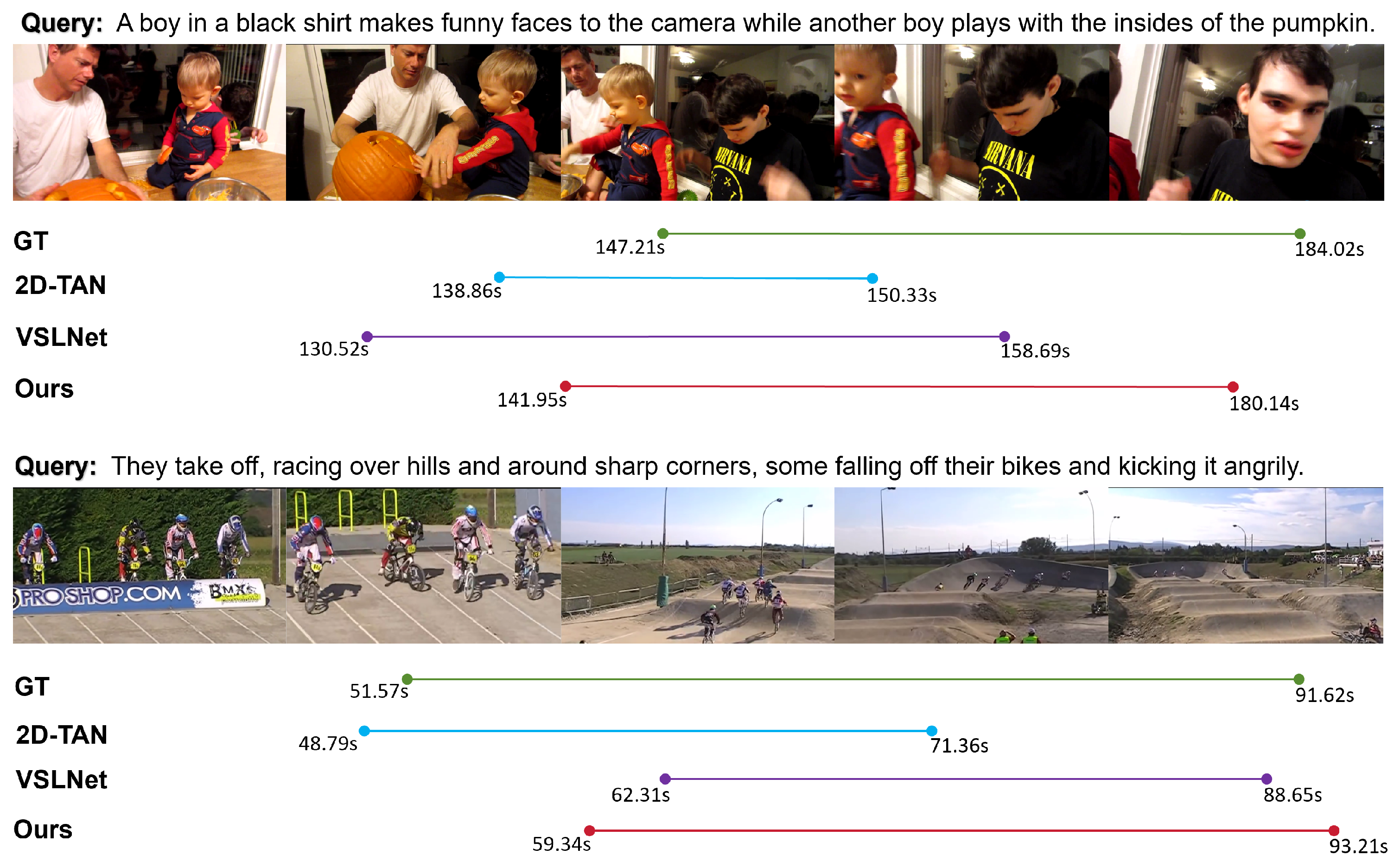
4.5.3. Grounding Results
4.6. Case Study
4.6.1. Case Study in Challenging Scenarios
4.6.2. Case Study Under Environmental Perturbations
4.7. Computational Complexity Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, L.; Li, W.; Li, W.; Van Gool, L. Appearance-and-Relation Networks for Video Classification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1430–1439. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar] [CrossRef]
- Zhao, Y.; Xiong, Y.; Wang, L.; Wu, Z.; Tang, X.; Lin, D. Temporal Action Detection with Structured Segment Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2933–2942. [Google Scholar] [CrossRef]
- Lin, Z.; Zhao, Z.; Zhang, Z.; Zhang, Z.; Cai, D. Moment Retrieval via Cross-Modal Interaction Networks with Query Reconstruction. IEEE Trans. Image Process. 2020, 29, 3750–3762. [Google Scholar] [CrossRef]
- Gao, J.; Sun, C.; Yang, Z.; Nevatia, R. TALL: Temporal Activity Localization via Language Query. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5277–5285. [Google Scholar] [CrossRef]
- Chu, Y.W.; Lin, K.Y.; Hsu, C.C.; Ku, L.W. End-to-End Recurrent Cross-Modality Attention for Video Dialogue. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2021, 29, 2456–2464. [Google Scholar] [CrossRef]
- Ji, W.; Li, Y.; Wei, M.; Shang, X.; Xiao, J.; Ren, T.; Chua, T.S. VidVRD 2021: The Third Grand Challenge on Video Relation Detection. In Proceedings of the 29th ACM International Conference on Multimedia, MM’21, Chengdu, China, 20–24 October 2021; pp. 4779–4783. [Google Scholar] [CrossRef]
- Shang, X.; Li, Y.; Xiao, J.; Ji, W.; Chua, T.S. Video Visual Relation Detection via Iterative Inference. In Proceedings of the 29th ACM International Conference on Multimedia, MM’21, Chengdu, China, 20–24 October 2021; pp. 3654–3663. [Google Scholar] [CrossRef]
- Shang, X.; Ren, T.; Guo, J.; Zhang, H.; Chua, T.S. Video Visual Relation Detection. In Proceedings of the 25th ACM International Conference on Multimedia, MM’17, Mountain View, CA, USA, 23–27 October 2017; pp. 1300–1308. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Xiao, J.; Ji, W.; Chua, T.S. Invariant Grounding for Video Question Answering. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2918–2927. [Google Scholar] [CrossRef]
- Xiao, J.; Yao, A.; Liu, Z.; Li, Y.; Ji, W.; Chua, T.S. Video as Conditional Graph Hierarchy for Multi-Granular Question Answering. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2804–2812. [Google Scholar] [CrossRef]
- Zhong, Y.; Ji, W.; Xiao, J.; Li, Y.; Deng, W.; Chua, T.S. Video Question Answering: Datasets, Algorithms and Challenges. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 6439–6455. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, L.; Wu, T.; Li, T.; Wu, G. Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding. arXiv 2021, arXiv:2109.04872. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, T.; Zhang, Y.; Wu, F. Local Correspondence Network for Weakly Supervised Temporal Sentence Grounding. IEEE Trans. Image Process. 2021, 30, 3252–3262. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, J.; Zhou, W.; Li, H. Weakly Supervised Temporal Adjacent Network for Language Grounding. IEEE Trans. Multimed. 2022, 24, 3276–3286. [Google Scholar] [CrossRef]
- Ji, W.; Qin, Y.; Chen, L.; Wei, Y.; Wu, Y.; Zimmermann, R. Mrtnet: Multi-Resolution Temporal Network for Video Sentence Grounding. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 2770–2774. [Google Scholar] [CrossRef]
- Li, H.; Shu, X.; He, S.; Qiao, R.; Wen, W.; Guo, T.; Gan, B.; Sun, X. D3G: Exploring Gaussian Prior for Temporal Sentence Grounding with Glance Annotation. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 13688–13700. [Google Scholar] [CrossRef]
- Gorti, S.K.; Vouitsis, N.; Ma, J.; Golestan, K.; Volkovs, M.; Garg, A.; Yu, G. X-Pool: Cross-Modal Language-Video Attention for Text-Video Retrieval. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4996–5005. [Google Scholar] [CrossRef]
- Guan, P.; Pei, R.; Shao, B.; Liu, J.; Li, W.; Gu, J.; Xu, H.; Xu, S.; Yan, Y.; Lam, E.Y. PIDRo: Parallel Isomeric Attention with Dynamic Routing for Text-Video Retrieval. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 11130–11139. [Google Scholar] [CrossRef]
- Liu, Y.; Xiong, P.; Xu, L.; Cao, S.; Jin, Q. TS2-Net: Token Shift and Selection Transformer for Text-Video Retrieval. In Computer Vision—ECCV 2022, Proceedings of the 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XIV; Springer: Berlin/Heidelberg, Germany, 2022; pp. 319–335. [Google Scholar] [CrossRef]
- Wang, Z.; Sung, Y.L.; Cheng, F.; Bertasius, G.; Bansal, M. Unified Coarse-to-Fine Alignment for Video-Text Retrieval. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 2804–2815. [Google Scholar] [CrossRef]
- Krishna, R.; Hata, K.; Ren, F.; Fei-Fei, L.; Niebles, J.C. Dense-Captioning Events in Videos. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 706–715. [Google Scholar] [CrossRef]
- Rohrbach, M.; Regneri, M.; Andriluka, M.; Amin, S.; Pinkal, M.; Schiele, B. Script data for attribute-based recognition of composite activities. In Proceedings of the 12th European Conference on Computer Vision ECCV’12, Florence, Italy, 7–13 October 2012; pp. 144–157. [Google Scholar] [CrossRef]
- Lin, T.; Zhao, X.; Shou, Z. Single Shot Temporal Action Detection. In Proceedings of the 25th ACM International Conference on Multimedia, MM’17, Mountain View, CA, USA, 23–27 October 2017; pp. 988–996. [Google Scholar] [CrossRef]
- Hendricks, L.A.; Wang, O.; Shechtman, E.; Sivic, J.; Darrell, T.; Russell, B. Localizing Moments in Video with Natural Language. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5804–5813. [Google Scholar] [CrossRef]
- Mun, J.; Cho, M.; Han, B. Local-Global Video-Text Interactions for Temporal Grounding. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10807–10816. [Google Scholar] [CrossRef]
- Xu, Z.; Wei, K.; Yang, X.; Deng, C. Point-Supervised Video Temporal Grounding. IEEE Trans. Multimed. 2023, 25, 6121–6131. [Google Scholar] [CrossRef]
- Luo, D.; Huang, J.; Gong, S.; Jin, H.; Liu, Y. Towards Generalisable Video Moment Retrieval: Visual-Dynamic Injection to Image-Text Pre-Training. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 23045–23055. [Google Scholar] [CrossRef]
- Liu, D.; Qu, X.; Dong, J.; Zhou, P.; Cheng, Y.; Wei, W.; Xu, Z.; Xie, Y. Context-aware Biaffine Localizing Network for Temporal Sentence Grounding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11230–11239. [Google Scholar] [CrossRef]
- Zhang, H.; Sun, A.; Jing, W.; Zhen, L.; Zhou, J.T.; Goh, S.M.R. Parallel Attention Network with Sequence Matching for Video Grounding. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Association for Computational Linguistics, Online Event, 1–6 August 2021. [Google Scholar] [CrossRef]
- Chen, Y.W.; Tsai, Y.H.; Wang, T.; Lin, Y.Y.; Yang, M.H. Referring Expression Object Segmentation with Caption-Aware Consistency. arXiv 2019. [Google Scholar] [CrossRef]
- Chen, Y.W.; Tsai, Y.H.; Yang, M.H. Understanding Synonymous Referring Expressions via Contrastive Features. arXiv 2021, arXiv:2104.10156. [Google Scholar] [CrossRef]
- Kim, J.; Ma, M.; Pham, T.; Kim, K.; Yoo, C.D. Modality Shifting Attention Network for Multi-Modal Video Question Answering. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10103–10112. [Google Scholar] [CrossRef]
- Gheini, M.; Ren, X.; May, J. Cross-Attention is All You Need: Adapting Pretrained Transformers for Machine Translation. arXiv 2021. [Google Scholar] [CrossRef]
- Zhang, H.; Sun, A.; Jing, W.; Zhou, J.T. Span-based Localizing Network for Natural Language Video Localization. arXiv 2020. [Google Scholar] [CrossRef]
- Chen, L.; Lu, C.; Tang, S.; Xiao, J.; Zhang, D.; Tan, C.; Li, X. Rethinking the Bottom-Up Framework for Query-Based Video Localization. Proc. AAAI Conf. Artif. Intell. 2020, 34, 10551–10558. [Google Scholar] [CrossRef]
- Wang, J.; Gong, T.; Zeng, Z.; Sun, C.; Yan, Y. C3CMR: Cross-Modality Cross-Instance Contrastive Learning for Cross-Media Retrieval. In Proceedings of the 30th ACM International Conference on Multimedia, MM’22, Lisboa, Portugal, 10–14 October 2022; pp. 4300–4308. [Google Scholar] [CrossRef]
- Ma, Y.; Xu, G.; Sun, X.; Yan, M.; Zhang, J.; Ji, R. X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval. In Proceedings of the 30th ACM International Conference on Multimedia, MM’22, Lisboa, Portugal, 10–14 October 2022; pp. 638–647. [Google Scholar] [CrossRef]
- Yuan, L.; Qian, R.; Cui, Y.; Gong, B.; Schroff, F.; Yang, M.H.; Adam, H.; Liu, T. Contextualized Spatio-Temporal Contrastive Learning with Self-Supervision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13957–13966. [Google Scholar] [CrossRef]
- Ding, S.; Qian, R.; Xiong, H. Dual Contrastive Learning for Spatio-temporal Representation. In Proceedings of the 30th ACM International Conference on Multimedia, MM ’22, Lisboa, Portugal, 10–14 October 2022; pp. 5649–5658. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Proceedings of Machine Learning Research. Volume 139, pp. 8748–8763. [Google Scholar]
- Luo, H.; Ji, L.; Zhong, M.; Chen, Y.; Lei, W.; Duan, N.; Li, T. CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval. arXiv 2021, arXiv:2104.08860. [Google Scholar] [CrossRef]
- Xue, H.; Sun, Y.; Liu, B.; Fu, J.; Song, R.; Li, H.; Luo, J. CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Language Representation Alignment. arXiv 2023, arXiv:2209.06430. [Google Scholar] [CrossRef]
- Tian, Y.; Guo, X.; Wang, J.; Li, B. Enhancing video temporal grounding with large language model-based data augmentation. J. Supercomput. 2025, 81, 658. [Google Scholar] [CrossRef]
- Ibrahimi, S.; Sun, X.; Wang, P.; Garg, A.; Sanan, A.; Omar, M. Audio-Enhanced Text-to-Video Retrieval using Text-Conditioned Feature Alignment. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 12020–12030. [Google Scholar] [CrossRef]
- Jin, P.; Li, H.; Cheng, Z.; Huang, J.; Wang, Z.; Yuan, L.; Liu, C.; Chen, J. Text-video retrieval with disentangled conceptualization and set-to-set alignment. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI ’23, Macao, SAR, 19–25 August 2023. [Google Scholar] [CrossRef]
- Zhang, S.; Peng, H.; Fu, J.; Luo, J. Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language. arXiv 2020, arXiv:1912.03590. [Google Scholar] [CrossRef]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding. arXiv 2016, arXiv:1604.01753. [Google Scholar] [CrossRef]
- Heilbron, F.C.; Escorcia, V.; Ghanem, B.; Niebles, J.C. ActivityNet: A large-scale video benchmark for human activity understanding. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar] [CrossRef]
- Regneri, M.; Rohrbach, M.; Wetzel, D.; Thater, S.; Schiele, B.; Pinkal, M. Grounding Action Descriptions in Videos. Trans. Assoc. Comput. Linguist. 2013, 1, 25–36. [Google Scholar] [CrossRef]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2018, arXiv:1706.02677. [Google Scholar] [CrossRef]
- Zheng, M.; Huang, Y.; Chen, Q.; Peng, Y.; Liu, Y. Weakly Supervised Temporal Sentence Grounding with Gaussian-based Contrastive Proposal Learning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 15534–15543. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, Z.; Zhang, Z.; Lin, Z. Cascaded Prediction Network via Segment Tree for Temporal Video Grounding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4195–4204. [Google Scholar] [CrossRef]
- Zeng, R.; Xu, H.; Huang, W.; Chen, P.; Tan, M.; Gan, C. Dense Regression Network for Video Grounding. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10284–10293. [Google Scholar] [CrossRef]
- Zhang, Z.; Lin, Z.; Zhao, Z.; Xiao, Z. Cross-Modal Interaction Networks for Query-Based Moment Retrieval in Videos. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR’19, Paris, France, 21–25 July 2019; pp. 655–664. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Xie, H.; Li, P.; Ge, J.; Liu, S.A.; Jin, G. Towards balanced alignment: Modal-enhanced semantic modeling for video moment retrieval. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, AAAI’24/IAAI’24/EAAI’24, Vancouver, BC, Canada, 20–27 February 2024. [Google Scholar] [CrossRef]
- Bao, P.; Xia, Y.; Yang, W.; Ng, B.P.; Er, M.H.; Kot, A.C. Local-global multi-modal distillation for weakly-supervised temporal video grounding. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, AAAI’24/IAAI’24/EAAI’24, Vancouver, BC, Canada, 20–27 February 2024. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Publication | Rank@1 | mIoU ↑ | ||
|---|---|---|---|---|---|
| IoU = 0.3 ↑ | IoU = 0.5 ↑ | IoU = 0.7 ↑ | |||
| 2D-TAN [47] | AAAI2020 | 57.31 | 39.70 | 23.31 | 39.23 |
| DRN [55] | CVPR2020 | — | 42.90 | 23.68 | — |
| GDP [36] | AAAI2020 | 54.54 | 39.47 | 18.49 | — |
| CBLN [29] | CVPR2021 | — | 43.67 | 24.44 | — |
| CPN [54] | CVPR2021 | 64.41 | 46.08 | 25.06 | 43.90 |
| LCNet [14] | ITIP2021 | 59.60 | 39.19 | 18.87 | 38.94 |
| WSTAN [15] | ITM2022 | 43.39 | 29.35 | 12.28 | — |
| CPL [53] | CVPR2022 | 66.40 | 49.24 | 22.39 | — |
| MMN [13] | AAAI2022 | — | 47.41 | 27.28 | — |
| PS-VTG [27] | ITM2022 | 60.40 | 39.22 | 20.17 | 39.77 |
| D3G [17] | ICCV2023 | — | 41.64 | 19.60 | — |
| VDI [28] | CVPR2023 | — | 46.47 | 28.63 | 41.60 |
| MESM [57] | AAAI2024 | — | 56.69 | 35.99 | 37.33 |
| MMDist [58] | AAAI2024 | 67.26 | 51.58 | 24.22 | — |
| MRTNet [16] | ICASSP2024 | 59.23 | 44.27 | 25.88 | 40.59 |
| Ours | — | 65.54 | 45.83 | 28.91 | 42.55 |
| Methods | Publication | Rank@1 | mIoU ↑ | ||
|---|---|---|---|---|---|
| IoU = 0.3 ↑ | IoU = 0.5 ↑ | IoU = 0.7 ↑ | |||
| 2D-TAN [47] | AAAI2020 | 59.45 | 44.51 | 26.54 | 43.29 |
| DRN [55] | CVPR2020 | 58.52 | 41.51 | 23.07 | 43.13 |
| GDP [36] | AAAI2020 | 56.17 | 39.27 | — | 39.80 |
| LGI [26] | CVPR2020 | 58.52 | 41.51 | 23.07 | 41.13 |
| CBLN [29] | CVPR2021 | 66.34 | 48.12 | 27.60 | — |
| LCNet [14] | ITIP2021 | 48.49 | 26.33 | — | 34.29 |
| CPN [54] | CVPR2021 | 62.81 | 45.10 | 28.10 | — |
| SeqPAN [30] | ACL2021 | 61.65 | 45.50 | 28.37 | 45.11 |
| WSTAN [15] | ITM2022 | 52.45 | 30.01 | — | — |
| CPL [53] | CVPR2022 | 55.73 | 31.14 | — | — |
| MMN [13] | AAAI2022 | 65.05 | 48.59 | 29.26 | — |
| PS-VTG [27] | ITM2022 | 59.71 | 39.59 | 21.98 | 41.49 |
| D3G [17] | ICCV2023 | 58.25 | 36.68 | 18.54 | — |
| VDI [28] | CVPR2023 | — | 32.35 | 16.02 | 34.32 |
| MMDist [58] | AAAI2024 | 56.92 | 31.80 | — | — |
| MRTNet [16] | ICASSP2024 | 60.71 | 45.59 | 28.07 | 44.54 |
| Ours | — | 66.37 | 49.18 | 30.36 | 45.76 |
| Methods | Publication | Rank@1 | mIoU ↑ | ||
|---|---|---|---|---|---|
| IoU = 0.3 ↑ | IoU = 0.5 ↑ | IoU = 0.7 ↑ | |||
| 2D-TAN [47] | AAAI2020 | 37.29 | 25.32 | 13.32 | 25.19 |
| VSLNet [35] | ACL2020 | 29.61 | 24.27 | 20.03 | 24.11 |
| CMIN [56] | SIGIR2020 | 32.35 | 22.54 | — | — |
| CBLN [29] | CVPR2021 | 38.98 | 27.65 | — | — |
| CPN [54] | CVPR2021 | 47.69 | 36.33 | 21.58 | 34.49 |
| SeqPAN [30] | ACL2021 | 31.72 | 27.19 | 21.65 | 25.86 |
| MMN [13] | AAAI2022 | 38.57 | 27.24 | — | — |
| PS-VTG [27] | ITM2022 | 23.64 | 10.00 | 3.35 | 17.39 |
| D3G [17] | ICCV2023 | 27.27 | 12.67 | 4.70 | — |
| MRTNet [16] | ICASSP2024 | 37.81 | 26.01 | 14.95 | 26.29 |
| Ours | — | 45.33 | 31.81 | 18.15 | 28.27 |
| Methods | Variant | Rank@1 | mIoU ↑ | ||
|---|---|---|---|---|---|
| IoU = 0.3 ↑ | IoU = 0.5 ↑ | IoU = 0.7 ↑ | |||
| MMN | Origin | — | 47.31 | 29.28 | — |
| +Ours | 66.03 | 49.14 | 30.21 | 44.20 | |
| LCNet | Origin | 59.60 | 39.19 | 18.87 | 38.94 |
| +Ours | 62.45 | 41.52 | 20.12 | 39.88 | |
| Components | Rank@1 | mIoU ↑ | |||
|---|---|---|---|---|---|
| SRVO | TVRO | IoU = 0.3 ↑ | IoU = 0.5 ↑ | IoU = 0.7 ↑ | |
| ✗ | ✓ | 63.51 | 46.89 | 28.37 | 42.32 |
| ✓ | ✗ | 64.78 | 45.17 | 26.02 | 41.18 |
| ✗ | ✗ | 61.42 | 43.33 | 25.51 | 39.21 |
| ✓ | ✓ | 66.37 | 49.18 | 30.36 | 45.76 |
| TGPS | SRVO | TVRO | Rank@1 | mIoU ↑ | ||
|---|---|---|---|---|---|---|
| Text Guidance | IoU = 0.3 ↑ | IoU = 0.5 ↑ | IoU = 0.7 ↑ | |||
| ✗ | ✗ | ✓ | 63.02 | 45.26 | 27.38 | 41.16 |
| ✓ | ✓ | ✗ | 64.31 | 45.87 | 27.01 | 41.28 |
| ✓ | ✗ | ✓ | 63.29 | 44.28 | 26.10 | 40.55 |
| ✓ | ✓ | ✓ | 67.37 | 49.18 | 30.36 | 44.76 |
| Salient Patches | Rank@1 | mIoU ↑ | ||
|---|---|---|---|---|
| IoU = 0.3 ↑ | IoU = 0.5 ↑ | IoU = 0.7 ↑ | ||
| 66.12 | 48.36 | 29.59 | 44.02 | |
| 67.37 | 49.18 | 30.36 | 44.76 | |
| 66.21 | 48.20 | 29.74 | 44.05 | |
| 66.28 | 47.83 | 29.11 | 44.12 | |
| (all) | 62.93 | 45.10 | 26.97 | 41.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Guo, X.; Wang, J.; Liang, X. Text-Guided Visual Representation Optimization for Sensor-Acquired Video Temporal Grounding. Sensors 2025, 25, 4704. https://doi.org/10.3390/s25154704
Tian Y, Guo X, Wang J, Liang X. Text-Guided Visual Representation Optimization for Sensor-Acquired Video Temporal Grounding. Sensors. 2025; 25(15):4704. https://doi.org/10.3390/s25154704
Chicago/Turabian StyleTian, Yun, Xiaobo Guo, Jinsong Wang, and Xinyue Liang. 2025. "Text-Guided Visual Representation Optimization for Sensor-Acquired Video Temporal Grounding" Sensors 25, no. 15: 4704. https://doi.org/10.3390/s25154704
APA StyleTian, Y., Guo, X., Wang, J., & Liang, X. (2025). Text-Guided Visual Representation Optimization for Sensor-Acquired Video Temporal Grounding. Sensors, 25(15), 4704. https://doi.org/10.3390/s25154704