
TOSQ: Transparent Object Segmentation via Query-Based Dictionary Lookup with Transformers

Abstract
1. Introduction
2. Related Work
2.1. Hand-Crafted Feature-Based Methods
2.2. CNN-Based Methods
2.3. Transformer-Based Methods
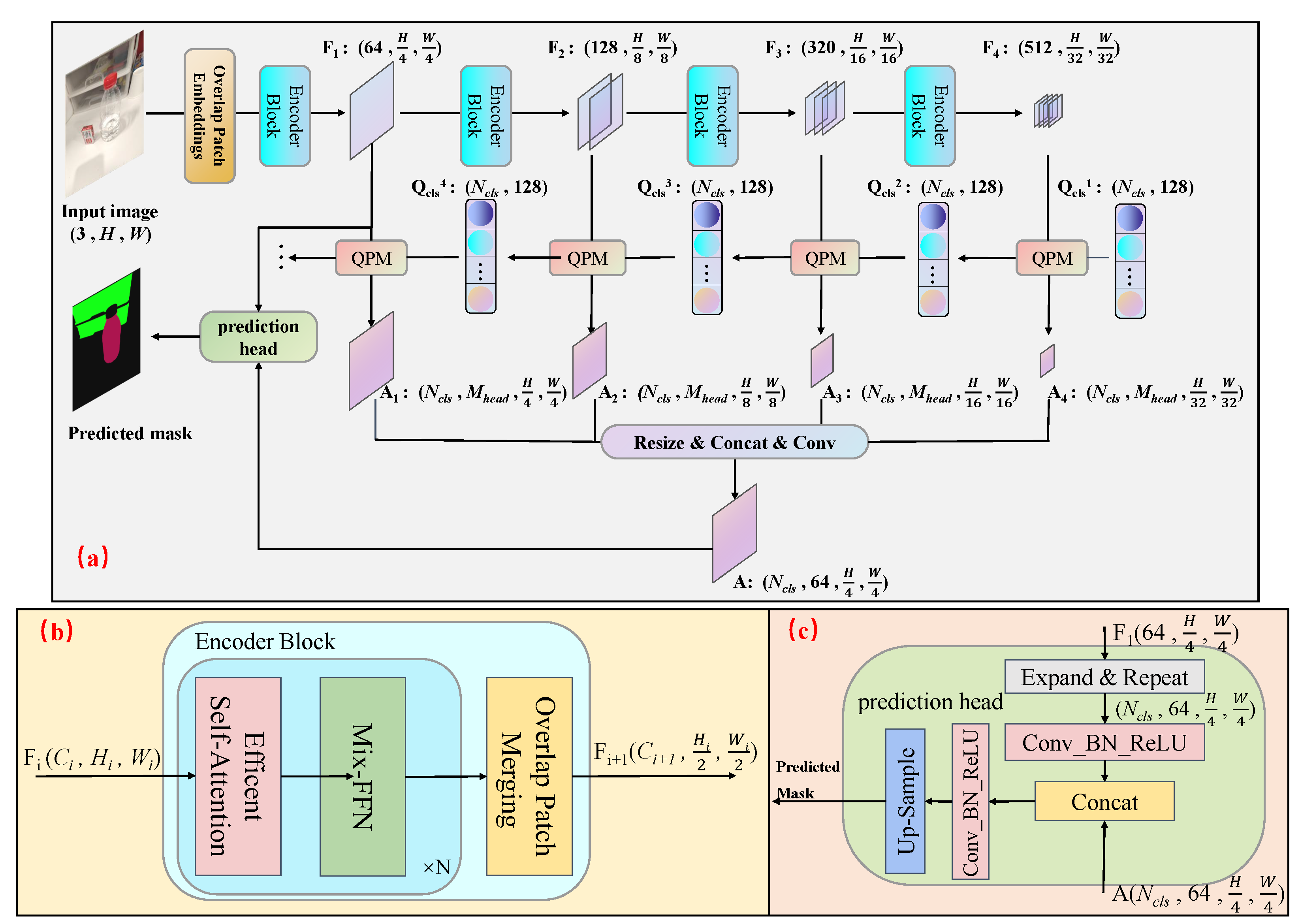
3. Our Method
3.1. Encoder
3.2. Decoder
4. Experiments
4.1. Details
4.2. Comparisons with State-of-the-Art Models
4.3. Ablation Study
4.3.1. Ablation Study on Encoder
4.3.2. Ablation Study on the Class Prototypes
4.4. Cross-Dataset Generalization on Cityscapes
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, Y.; Nagahara, H.; Shimada, A.; Taniguchi, R. Transcut: Transparent object segmentation from a light-field image. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3442–3450. [Google Scholar]
- Xie, E.; Wang, W.; Wang, W.; Sun, P.; Xu, H.; Liang, D.; Luo, P. Segmenting transparent object in the wild with transformer. arXiv 2021, arXiv:2101.08461. [Google Scholar]
- Xie, E.; Wang, W.; Wang, W.; Ding, M.; Shen, C.; Luo, P. Segmenting transparent objects in the wild. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 696–711. [Google Scholar]
- Lin, J.; Yeung, Y.H.; Lau, R.W. Depth-aware glass surface detection with cross-modal context mining. arXiv 2022, arXiv:2206.11250. [Google Scholar]
- Ummadisingu, A.; Choi, J.; Yamane, K.; Masuda, S.; Fukaya, N.; Takahashi, K. Said-nerf: Segmentation-aided nerf for depth completion of transparent objects. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 7535–7542. [Google Scholar]
- Huo, D.; Wang, J.; Qian, Y.; Yang, Y.H. Glass segmentation with RGB-thermal image pairs. IEEE Trans. Image Process. 2023, 32, 1911–1926. [Google Scholar] [CrossRef] [PubMed]
- Mei, H.; Dong, B.; Dong, W.; Yang, J.; Baek, S.H.; Heide, F.; Peers, P.; Wei, X.; Yang, X. Glass segmentation using intensity and spectral polarization cues. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12622–12631. [Google Scholar]
- Yu, R.; Ren, W.; Zhao, M.; Wang, J.; Wu, D.; Xie, Y. Transparent objects segmentation based on polarization imaging and deep learning. Opt. Commun. 2024, 555, 130246. [Google Scholar] [CrossRef]
- McHenry, K.; Ponce, J. A Geodesic Active Contour Framework for Finding Glass. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 1038–1044. [Google Scholar] [CrossRef]
- McHenry, K.; Ponce, J.; Forsyth, D. Finding glass. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 973–979. [Google Scholar] [CrossRef]
- Lin, X.; Sun, S.; Huang, W.; Sheng, B.; Li, P.; Feng, D.D. EAPT: Efficient attention pyramid transformer for image processing. IEEE Trans. Multimed. 2021, 25, 50–61. [Google Scholar] [CrossRef]
- Chen, Z.; Qiu, G.; Li, P.; Zhu, L.; Yang, X.; Sheng, B. Mngnas: Distilling adaptive combination of multiple searched networks for one-shot neural architecture search. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13489–13508. [Google Scholar] [CrossRef]
- Jiang, N.; Sheng, B.; Li, P.; Lee, T.Y. Photohelper: Portrait photographing guidance via deep feature retrieval and fusion. IEEE Trans. Multimed. 2022, 25, 2226–2238. [Google Scholar] [CrossRef]
- Chen, G.; Han, K.; Wong, K.Y.K. TOM-Net: Learning Transparent Object Matting from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Madessa, A.H.; Dong, J.; Dong, X.; Gao, Y.; Yu, H.; Mugunga, I. Leveraging an Instance Segmentation Method for Detection of Transparent Materials. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, Leicester, UK, 19–23 August 2019; pp. 406–412. [Google Scholar] [CrossRef]
- Mei, H.; Yang, X.; Wang, Y.; Liu, Y.; He, S.; Zhang, Q.; Wei, X.; Lau, R.W. Don’t Hit Me! Glass Detection in Real-World Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Xu, Z.; Lai, B.; Yuan, L.; Liu, T. Real-time Transparent Object Segmentation Based on Improved DeepLabv3+. In Proceedings of the 2021 China Automation Congress (CAC), Beijing, China, 22–24 October 2021; pp. 4310–4315. [Google Scholar] [CrossRef]
- Yu, L.; Mei, H.; Dong, W.; Wei, Z.; Zhu, L.; Wang, Y.; Yang, X. Progressive Glass Segmentation. IEEE Trans. Image Process. 2022, 31, 2920–2933. [Google Scholar] [CrossRef]
- Cao, Y.; Zhang, Z.; Xie, E.; Hou, Q.; Zhao, K.; Luo, X.; Tuo, J. FakeMix augmentation improves transparent object detection. arXiv 2021, arXiv:2103.13279. [Google Scholar]
- He, H.; Li, X.; Cheng, G.; Shi, J.; Tong, Y.; Meng, G.; Prinet, V.; Weng, L. Enhanced Boundary Learning for Glass-Like Object Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15859–15868. [Google Scholar]
- Lin, J.; He, Z.; Lau, R.W. Rich context aggregation with reflection prior for glass surface detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13415–13424. [Google Scholar]
- Lin, J.; Yeung, Y.H.; Lau, R. Exploiting Semantic Relations for Glass Surface Detection. Adv. Neural Inf. Process. Syst. 2022, 35, 22490–22504. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Yao, D.; Shao, Y. A data efficient transformer based on Swin Transformer. Vis. Comput. 2024, 40, 2589–2598. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, K.; Constantinescu, A.; Peng, K.; Müller, K.; Stiefelhagen, R. Trans4Trans: Efficient transformer for transparent object and semantic scene segmentation in real-world navigation assistance. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19173–19186. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- MMSegmentation Contributors. MMSegmentation: Openmmlab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation/tree/v1.2.0 (accessed on 1 May 2025).
- Liu, M.; Yin, H. Feature pyramid encoding network for real-time semantic segmentation. arXiv 2019, arXiv:1909.08599. [Google Scholar]
- Mehta, S.; Rastegari, M.; Shapiro, L.; Hajishirzi, H. Espnetv2: A light-weight, power efficient, and general purpose convolutional neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9190–9200. [Google Scholar]
- Poudel, R.P.; Bonde, U.; Liwicki, S.; Zach, C. Contextnet: Exploring context and detail for semantic segmentation in real-time. arXiv 2018, arXiv:1805.04554. [Google Scholar]
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. Dfanet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9522–9531. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Chao, P.; Kao, C.Y.; Ruan, Y.S.; Huang, C.H.; Lin, Y.L. Hardnet: A low memory traffic network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3552–3561. [Google Scholar]
- Li, G.; Yun, I.; Kim, J.; Kim, J. Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar]
- Wang, Y.; Zhou, Q.; Liu, J.; Xiong, J.; Gao, G.; Wu, X.; Latecki, L.J. Lednet: A lightweight encoder-decoder network for real-time semantic segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1860–1864. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Jin, Q.; Meng, Z.; Pham, T.D.; Chen, Q.; Wei, L.; Su, R. DUNet: A deformable network for retinal vessel segmentation. Knowl.-Based Syst. 2019, 178, 149–162. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Xue, H.; Liu, C.; Wan, F.; Jiao, J.; Ji, X.; Ye, Q. Danet: Divergent activation for weakly supervised object localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6589–6598. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Method | GFLOPs | ACC | mIoU | Category IoU | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Background | Shelf | Jar/Tank | Freezer | Window | Door | Eyeglass | Cup | Wall | Bowl | Bottle | Box | ||||
| FPENet [31] | 0.76 | 70.31 | 10.14 | 74.97 | 0.01 | 0.00 | 0.02 | 2.11 | 2.83 | 0.00 | 16.84 | 24.81 | 0.00 | 0.04 | 0.00 |
| ESPNetv2 [32] | 0.83 | 73.03 | 12.27 | 78.98 | 0.00 | 0.00 | 0.00 | 0.00 | 6.17 | 0.00 | 30.65 | 37.03 | 0.00 | 0.00 | 0.00 |
| ContextNet [33] | 0.87 | 86.75 | 46.69 | 89.86 | 23.22 | 34.88 | 32.34 | 44.24 | 42.25 | 50.36 | 65.23 | 60.00 | 43.88 | 53.81 | 20.17 |
| FastSCNN [34] | 1.01 | 88.05 | 51.93 | 90.64 | 32.76 | 41.12 | 47.28 | 47.47 | 44.64 | 48.99 | 67.88 | 63.80 | 55.08 | 58.86 | 24.65 |
| DFANet [35] | 1.02 | 85.15 | 42.54 | 88.49 | 26.65 | 27.84 | 28.94 | 46.27 | 39.47 | 33.06 | 58.87 | 59.45 | 43.22 | 44.87 | 13.37 |
| ENet [36] | 2.09 | 71.67 | 8.50 | 79.74 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 22.25 | 0.00 | 0.00 | 0.00 |
| HRNet w18 [37] | 4.20 | 89.58 | 54.25 | 92.47 | 27.66 | 45.08 | 40.53 | 45.66 | 45.00 | 68.05 | 73.24 | 64.86 | 52.85 | 62.52 | 33.02 |
| HardNet [38] | 4.42 | 90.19 | 56.19 | 92.87 | 34.62 | 47.50 | 42.40 | 49.78 | 49.19 | 62.33 | 72.93 | 68.32 | 58.14 | 65.33 | 30.90 |
| DABNet [39] | 5.18 | 77.43 | 15.27 | 81.19 | 0.00 | 0.09 | 0.00 | 4.10 | 10.49 | 0.00 | 36.18 | 42.83 | 0.00 | 8.30 | 0.00 |
| LEDNet [40] | 6.23 | 86.07 | 46.40 | 88.59 | 28.13 | 36.72 | 32.45 | 43.77 | 38.55 | 41.51 | 64.19 | 60.05 | 42.40 | 53.12 | 27.29 |
| ICNet [28] | 10.64 | 78.23 | 23.39 | 83.29 | 2.96 | 4.91 | 9.3 | 19.24 | 15.35 | 24.11 | 44.54 | 41.49 | 7.58 | 27.47 | 3.80 |
| BiSeNet [36] | 19.91 | 89.13 | 58.40 | 90.12 | 39.54 | 53.71 | 50.90 | 46.95 | 44.68 | 64.32 | 72.86 | 63.57 | 61.38 | 67.88 | 44.85 |
| Trans4Trans-S [25] | 19.92 | 94.57 | 74.15 | 95.60 | 57.05 | 71.18 | 70.21 | 63.95 | 61.25 | 81.67 | 87.34 | 78.52 | 77.13 | 81.00 | 64.88 |
| Trans4Trans M [25] | 34.38 | 95.01 | 75.14 | 96.08 | 55.81 | 71.46 | 69.25 | 65.16 | 63.96 | 83.84 | 88.21 | 80.29 | 76.33 | 83.09 | 68.09 |
| DenseASPP [29] | 36.20 | 90.86 | 63.01 | 91.39 | 42.41 | 60.93 | 64.75 | 48.97 | 51.40 | 65.72 | 75.64 | 67.93 | 67.03 | 70.26 | 49.64 |
| DeepLabv3 [41] | 37.98 | 92.75 | 68.87 | 93.82 | 51.29 | 64.65 | 65.71 | 55.26 | 57.19 | 77.06 | 81.89 | 72.64 | 70.81 | 77.44 | 58.63 |
| FCN [42] | 42.23 | 91.65 | 62.75 | 93.62 | 38.84 | 56.05 | 58.76 | 46.91 | 50.74 | 82.56 | 78.71 | 68.78 | 57.87 | 73.66 | 46.54 |
| OCNet [43] | 43.31 | 92.03 | 66.31 | 93.12 | 41.47 | 63.54 | 60.05 | 54.10 | 51.01 | 79.57 | 81.95 | 69.40 | 68.44 | 78.41 | 54.65 |
| RefineNet [44] | 44.56 | 87.99 | 58.18 | 90.63 | 30.62 | 53.17 | 55.95 | 42.72 | 46.59 | 70.82 | 76.01 | 62.91 | 57.05 | 70.34 | 41.32 |
| Trans2Seg [2] | 49.03 | 94.14 | 72.15 | 95.35 | 53.43 | 67.82 | 64.20 | 59.64 | 60.56 | 88.52 | 86.67 | 75.99 | 73.98 | 82.43 | 57.17 |
| Translab [3] | 61.31 | 92.67 | 69.00 | 93.90 | 54.36 | 64.48 | 65.14 | 54.58 | 57.72 | 79.85 | 81.61 | 72.82 | 69.63 | 77.50 | 56.43 |
| DUNet [45] | 123.69 | 90.67 | 59.01 | 93.07 | 34.20 | 50.95 | 54.96 | 43.19 | 45.05 | 79.80 | 76.07 | 65.29 | 54.33 | 68.57 | 42.64 |
| UNet [46] | 124.55 | 81.90 | 29.23 | 86.34 | 8.76 | 15.18 | 19.02 | 27.13 | 24.73 | 17.26 | 53.40 | 47.36 | 11.97 | 37.79 | 1.77 |
| DANet [47] | 198.00 | 92.70 | 68.81 | 93.69 | 47.69 | 66.05 | 70.18 | 53.01 | 56.15 | 77.73 | 82.89 | 72.24 | 72.18 | 77.87 | 56.06 |
| PSPNe [48] | 187.03 | 92.47 | 68.23 | 93.62 | 50.33 | 64.24 | 70.19 | 51.51 | 55.27 | 79.27 | 81.93 | 71.95 | 68.91 | 77.13 | 54.43 |
| TOSQ-128 | 41.48 | 95.34 | 76.63 | 96.07 | 47.56 | 78.94 | 66.63 | 88.75 | 75.18 | 69.13 | 90.69 | 72.96 | 87.18 | 81.47 | 64.98 |
| TOSQ-256 | 43.15 | 95.53 | 77.47 | 96.22 | 52.08 | 81.82 | 66.65 | 88.70 | 75.69 | 69.14 | 91.03 | 68.38 | 87.82 | 81.76 | 67.32 |
| Layer | MParams | GFLOPs | Acc (%) | mIoU (%) |
|---|---|---|---|---|
| F1-2 | 3.484 | 27.58 | 70.63 | 24.82 |
| F1-3 | 14.04 | 37.43 | 85.86 | 38.90 |
| F1-4 | 25.31 | 41.48 | 95.34 | 76.63 |
| MParams | GFLOPs | Acc (%) | mIoU (%) | |
|---|---|---|---|---|
| 64 | 24.65 | 40.98 | 93.42 | 71.14 |
| 128 | 25.31 | 41.48 | 95.34 | 76.63 |
| 256 | 27.81 | 43.15 | 95.53 | 77.47 |
| Category | Trans4Trans (%) | TOSQ (%) |
|---|---|---|
| road | 97.04 | 96.04 |
| sidewalk | 71.78 | 76.67 |
| building | 86.44 | 87.79 |
| wall | 46.24 | 48.99 |
| fence | 31.30 | 44.31 |
| pole | 39.50 | 40.69 |
| traffic light | 42.49 | 22.40 |
| traffic sign | 53.62 | 60.14 |
| vegetation | 88.38 | 88.08 |
| terrain | 50.97 | 60.53 |
| sky | 92.61 | 89.57 |
| person | 66.14 | 67.01 |
| rider | 41.41 | 46.10 |
| car | 88.23 | 89.60 |
| truck | 50.30 | 68.65 |
| bus | 60.00 | 74.19 |
| train | 57.18 | 53.54 |
| motorcycle | 28.90 | 38.26 |
| bicycle | 58.95 | 55.66 |
| mIoU | 60.61 | 63.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, B.; Ma, M.; Li, R.; Zheng, J.; Li, D. TOSQ: Transparent Object Segmentation via Query-Based Dictionary Lookup with Transformers. Sensors 2025, 25, 4700. https://doi.org/10.3390/s25154700
Ma B, Ma M, Li R, Zheng J, Li D. TOSQ: Transparent Object Segmentation via Query-Based Dictionary Lookup with Transformers. Sensors. 2025; 25(15):4700. https://doi.org/10.3390/s25154700
Chicago/Turabian StyleMa, Bin, Ming Ma, Ruiguang Li, Jiawei Zheng, and Deping Li. 2025. "TOSQ: Transparent Object Segmentation via Query-Based Dictionary Lookup with Transformers" Sensors 25, no. 15: 4700. https://doi.org/10.3390/s25154700
APA StyleMa, B., Ma, M., Li, R., Zheng, J., & Li, D. (2025). TOSQ: Transparent Object Segmentation via Query-Based Dictionary Lookup with Transformers. Sensors, 25(15), 4700. https://doi.org/10.3390/s25154700