
Robotic Arm Trajectory Planning in Dynamic Environments Based on Self-Optimizing Replay Mechanism

Abstract
1. Introduction
2. Related Work
- Expanding a small amount of human expert demonstrations and successful experiences generated by the algorithm into a large number of expert experiences, enabling the robotic arm to obtain a large amount of high-quality experience data throughout the entire training phase.
- Designing a dynamic sampling strategy to divide the experiences generated by the algorithm into successful experiences and failed experiences, then using a neural network to dynamically extract experiences from successful experiences, failed experiences, and expert experiences at different ratios in different training stages, integrating expert experiences into the algorithm while improving the utilization rate of experience data. NETM does not introduce additional hyperparameters and has relatively low time complexity.
- For moving targets in trajectory planning, adding velocity constraints between the end-effector and the moving target to the gravitational potential field of the artificial potential field method, canceling the action range of the obstacle repulsive potential field for dynamic obstacles in the environment, and proposing a generalized safety reward (GSR) suitable for dynamic environments based on this.
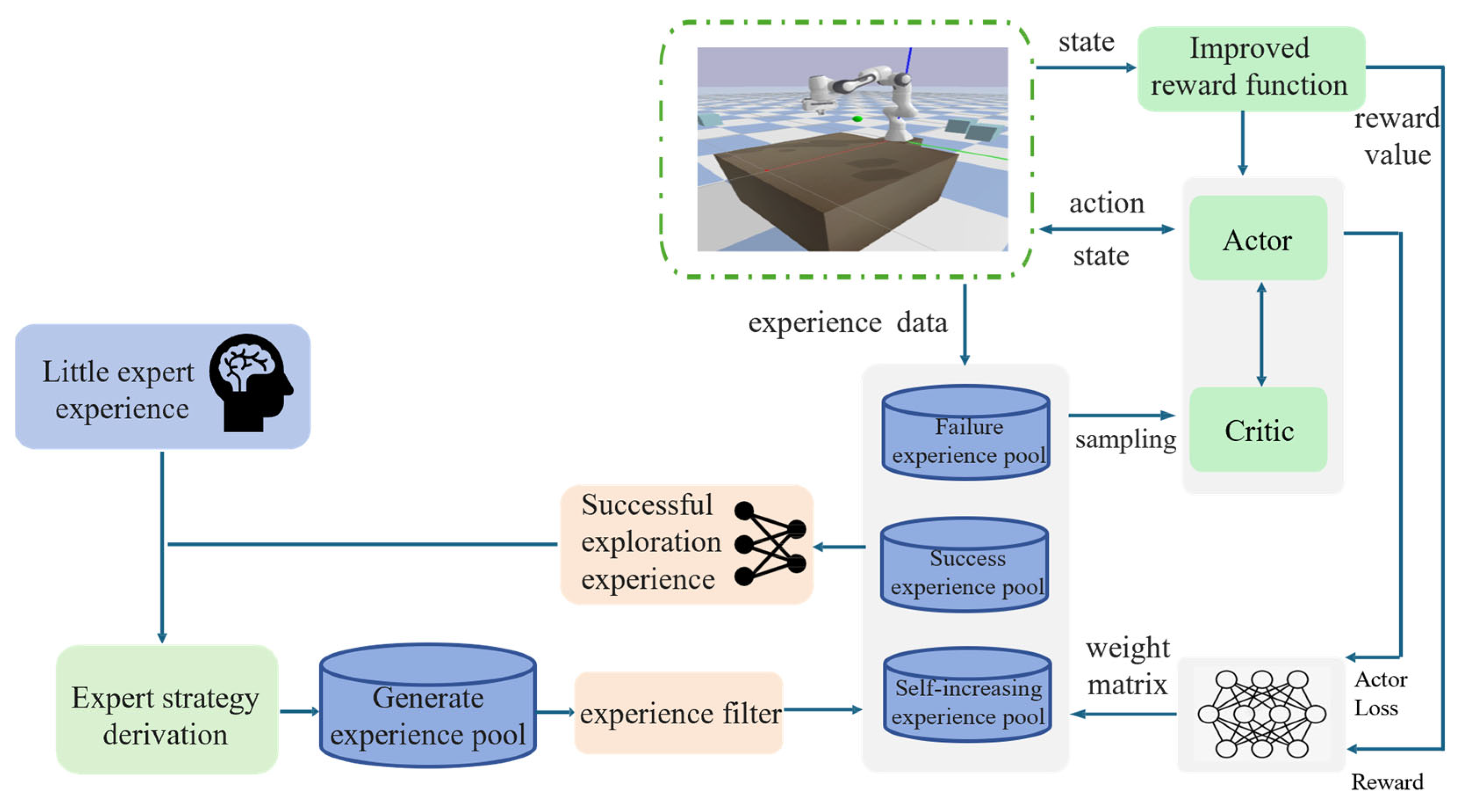
3. Method Introduction
3.1. Neural Network-Based Expert-Guided Experience Sampling Strategy
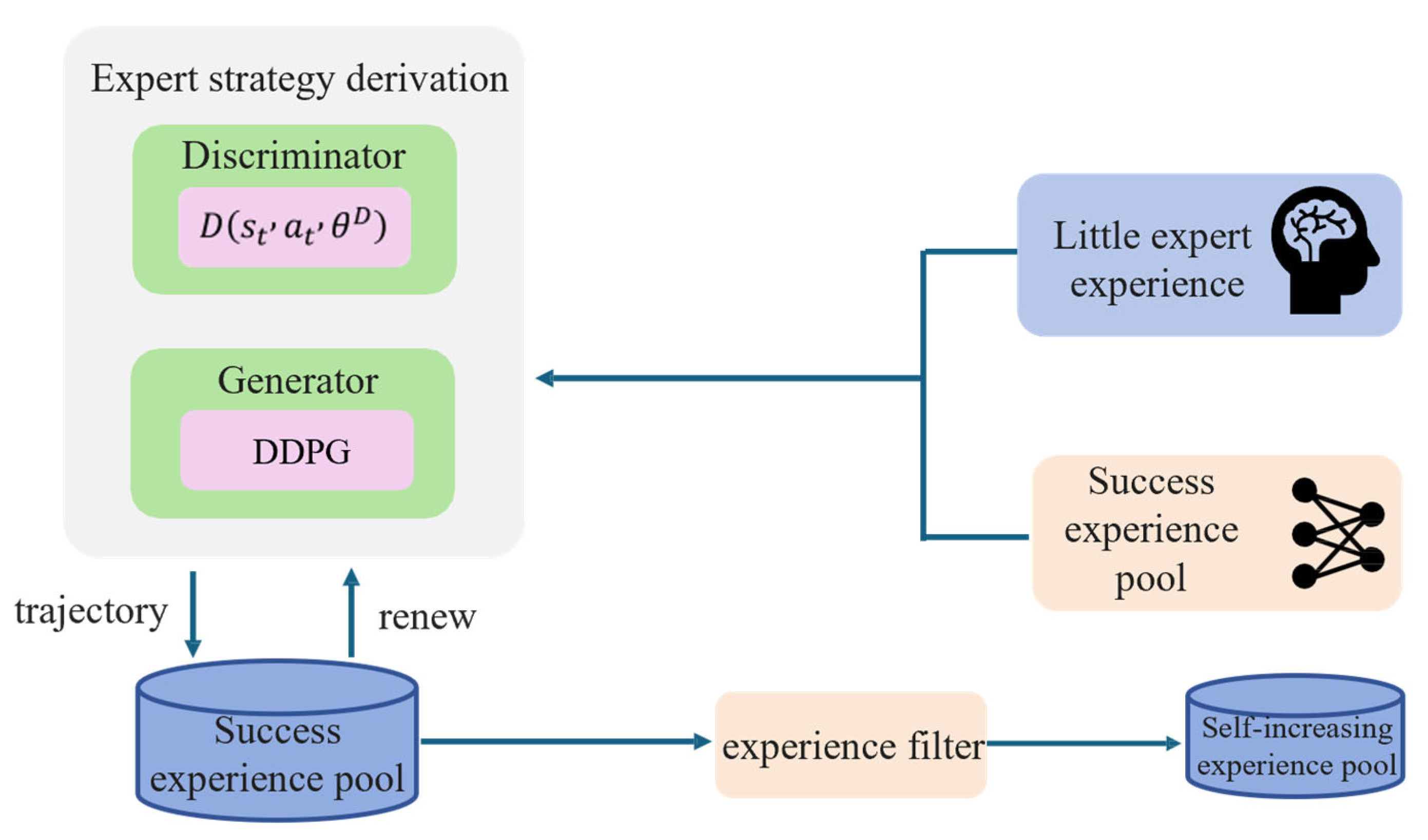
3.1.1. Expert Policy Derivation
3.1.2. Neural Network-Based Experience Sampling Strategy
3.2. Reward Function Based on Improved Artificial Potential Field Method in Dynamic Environment
3.3. State Space and Action Space Design
4. Experimental Setup and Result Analysis
4.1. Parameter and Task Settings
4.2. Evaluation Indicators
4.3. Experimental Result Analysis and Discussion
4.3.1. Comparison of Experience Replay Mechanism Experimental Effects
4.3.2. Comparison of Time Complexity of Different Experience Replay Mechanisms
4.3.3. Comparison of Reward Function Training Experimental Effects
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barbosa, W.S.; Gioia, M.M.; Natividade, V.G.; Wanderley, R.F.; Chaves, M.R.; Gouvea, F.C.; Gonçalves, F.M. Industry 4.0: Examples of the use of the robotic arm for digital manufacturing processes. Int. J. Interact. Des. Manuf. (IJIDeM) 2020, 14, 1569–1575. [Google Scholar] [CrossRef]
- Lin, H.I. Design of an intelligent robotic precise assembly system for rapid teaching and admittance control. Robot. Comput.-Integr. Manuf. 2020, 64, 101946. [Google Scholar] [CrossRef]
- Han, D.; Mulyana, B.; Stankovic, V.; Cheng, S. A survey on DRL algorithms for robotic manipulation. Sensors 2023, 23, 3762. [Google Scholar] [CrossRef]
- Maghooli, N.; Mahdizadeh, O.; Bajelani, M.; Moosavian, S.A.A. Control of Continuum Manipulators with Shape Constraints via DRL. In Proceedings of the 2024 12th RSI International Conference on Robotics and Mechatronics (ICRoM), Tehran, Iran, 17–19 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 631–636. [Google Scholar]
- Gu, S.X.; Lillicrap, T.; Sutskever, I.; Levine, S. Continuous deep q-learning with model-based acceleration. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; PMLR: New York, NY, USA, 2016; pp. 2829–2838. [Google Scholar]
- Mahmood, A.R.; Korenkevych, D.; Vasan, G.; Ma, W.; Bergstra, J. Benchmarking reinforcement learning algorithms on real-world robots. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; PMLR: New York, NY, USA, 2018; pp. 561–591. [Google Scholar]
- Lim, J.; Ha, S.; Choi, J. Prediction of reward functions for DRL via Gaussian process regression. IEEE/ASME Trans. Mechatron. 2020, 25, 1739–1746. [Google Scholar] [CrossRef]
- Qi, G.J.; Li, Y. Reinforcement learning control for robotic arm grasping based on improved DDPG. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4132–4137. [Google Scholar]
- Li, X.J.; Liu, H.; Dong, M. A general framework of motion planning for redundant robot manipulator based on DRL. IEEE Trans. Ind. Inform. 2021, 18, 5253–5263. [Google Scholar] [CrossRef]
- Ma, R.D.; Oyekan, J. Guiding DRL by Modelling Expert’s Planning Behavior. In Proceedings of the 2021 7th International Conference on Control, Automation and Robotics (ICCAR), Singapore, 23–26 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 321–325. [Google Scholar]
- Ying, F.K.; Liu, H.; Jiang, R.; Dong, M. Extensively explored and evaluated actor-critic with expert-guided policy learning and fuzzy feedback reward for robotic trajectory generation. IEEE Trans. Ind. Inform. 2022, 18, 7749–7760. [Google Scholar] [CrossRef]
- Tang, W.; Cheng, C.; Ai, H.; Chen, L. Dual-arm robot trajectory planning based on deep reinforcement learning under complex environment. Micromachines 2022, 13, 564. [Google Scholar] [CrossRef] [PubMed]
- Heaton, J.; Givi, S.G. A deep reinforcement learning solution for the low level motion control of a robot manipulator system. In Proceedings of the 2023 IEEE International Systems Conference (SysCon), Vancouver, BC, Canada, 7–20 April 2023; pp. 1–6. [Google Scholar]
- Wu, M.P.; Niu, Y.; Gu, M.; Cheng, J. (Eds.) Proceedings of 2021 International Conference on Autonomous Unmanned Systems (ICAUS 2021); Springer Nature: Berlin/Heidelberg, Germany, 2022; Volume 861. [Google Scholar]
- Wang, T.; Peng, X.; Wang, T.; Liu, T.; Xu, D. Automated design of action advising trigger conditions for multiagent reinforcement learning: A genetic programming-based approach. Swarm Evol. Comput. 2024, 85, 101475. [Google Scholar] [CrossRef]
- Fang, B.; Jia, S.; Guo, D.; Xu, M.; Wen, S.; Sun, F. Survey of imitation learning for robotic manipulation. Int. J. Intell. Robot. Appl. 2019, 3, 362–369. [Google Scholar] [CrossRef]
- Kong, S.-H.; Nahrendra, I.M.A.; Paek, D.-H. Enhanced Off-Policy Reinforcement Learning With Focused Experience Replay. IEEE Access 2021, 9, 93152–93164. [Google Scholar] [CrossRef]
- Chandak, Y.; Niekum, S.; da Silva, B.; Learned-Miller, E.; Brunskill, E.; Thomas, P.S. Universal off-policy evaluation. Adv. Neural Inf. Process. Syst. 2021, 34, 27475–27490. [Google Scholar]
- Osa, T.; Esfahani, A.M.G.; Stolkin, R.; Lioutikov, R.; Peters, J.; Neumann, G. Guiding trajectory optimization by demonstrated distributions. IEEE Robot. Autom. Lett. 2017, 2, 819–826. [Google Scholar] [CrossRef]
- Ramicic, M.; Bonarini, A. Attention-Based Experience Replay in Deep Q-Learning. In Proceedings of the 9th International Conference on Machine Learning and Computing (ICMLC ′17), Singapore, 24–26 February 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 476–481. [Google Scholar]
- Zhang, H.; Qu, C.; Zhang, J.; Li, J. Self-Adaptive Priority Correction for Prioritized Experience Replay. Appl. Sci. 2020, 10, 6925. [Google Scholar] [CrossRef]
- Li, Y.; Ke, L.; Zhang, C. Dynamic obstacle avoidance and grasping planning for mobile robotic arm in complex environment based on improved TD3. Appl. Intell. 2025, 55, 776. [Google Scholar] [CrossRef]
- Zhang, Z.; Fu, H.; Yang, J.; Lin, Y. DRL for path planning of autonomous mobile robots in complicated environments. Complex Intell. Syst. 2025, 11, 277. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Zare, M.; Kebria, P.M.; Khosravi, A.; Nahavandi, S. A survey of imitation learning: Algorithms, recent developments, and challenges. IEEE Trans. Cybern. 2024, 54, 7173–7186. [Google Scholar] [CrossRef]
- Di, C.; Li, F.; Xu, P.; Guo, Y.; Chen, C.; Shu, M. Learning automata-accelerated greedy algorithms for stochastic submodular maximization. Knowl. Based Syst. 2023, 282, 111118. [Google Scholar] [CrossRef]
- Cheng, N.; Wang, P.; Zhang, G.; Ni, C.; Nematov, E. Prioritized experience replay in path planning via multi-dimensional transition priority fusion. Front. Neurorobotics 2023, 17, 1281166. [Google Scholar] [CrossRef]
- Chen, S.; Yan, D.; Zhang, Y.; Tan, Y.; Wang, W. Live working manipulator control model based on dppo-dqn combined algorithm. In Proceedings of the 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, 20–22 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2620–2624. [Google Scholar]
- Gharbi, A. A dynamic reward-enhanced Q-learning approach for efficient path planning and obstacle avoidance in mobile robotics. Appl. Comput. Inform. 2024. [Google Scholar] [CrossRef]
- Xiang, Y.; Wen, J.; Luo, W.; Xie, G. Research on collision-free control and simulation of single-agent based on an improved DDPG algorithm. In Proceedings of the 2020 35th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Zhanjiang, China, 16–18 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 552–556. [Google Scholar]
- Rajendran, P.; Thakar, S.; Bhatt, P.M.; Kabir, A.M.; Gupta, S.K. Strategies for speeding up manipulator path planning to find high quality paths in cluttered environments. J. Comput. Inf. Sci. Eng. 2021, 21, 011009. [Google Scholar] [CrossRef]
- Chen, C.; Su, S.; Shu, M.; Di, C.; Li, W.; Xu, P.; Guo, J.; Wang, R.; Wang, Y. Slippage Estimation via Few-Shot Learning Based on Wheel-Ruts Images for Wheeled Robots on Loose Soil. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6555–6566. [Google Scholar] [CrossRef]
- Wang, R.; Yin, X.; Wang, Q.; Jiang, L. Direct Amplitude Control for Voice Coil Motor on High Frequency Reciprocating Rig. IEEE/ASME Trans. Mechatron. 2020, 25, 1299–1309. [Google Scholar] [CrossRef]
- Huang, C.L.; Fallah, Y.P.; Sengupta, R.; Krishnan, H. Intervehicle transmission rate control for cooperative active safety system. IEEE Trans. Intell. Transp. Syst. 2010, 12, 645–658. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Actor network learning rate | 0.00015 | Memory pool capacity | 1,000,000 |
| Critic network learning rate | 0.0015 | 0.05 | |
| Reward discount factor | 0.99 | 250 | |
| Soft update rate | 0.001 | 15 | |
| Batch_size | 64 | 35 | |
| Expert memory pool capacity | 10,000 | 0.2 | |
| Maximum time steps | 100 | 4 |
| Model | Environment 1 | Environment 2 | ||||
|---|---|---|---|---|---|---|
| NTM-DDPG | −804 | 44.68% | 99.80% | −856 | 50.76% | 99.57% |
| NETM-DDPG | −405 | 59.93% | 99.43% | −616 | 55.89% | 99.68% |
| DDPG | −1161 | 32.15% | 98.81% | −2144 | 22.18% | 97.40% |
| PER-DDPG | −885 | 43.22% | 99.81% | −1209 | 34.30% | 96.93% |
| NTM-SAC | −565 | 67.25% | 99.85% | −636 | 57.94% | 99.86% |
| NETM-SAC | −360 | 70.51% | 99.96% | −500 | 62.69% | 99.86% |
| SAC | −701 | 61.43% | 99.88% | −939 | 43.35% | 99.58% |
| PER-SAC | −596 | 63.26% | 99.82% | −808 | 50.26% | 99.65% |
| Method | Total Time (ms) | Sampling Time (ms) | Update Time (ms) |
|---|---|---|---|
| NETM-DDPG | 1356.21 | 6.17 | 1007.65 |
| DDPG | 1306.08 | 4.84 | 974.82 |
| PER-DDPG | 1456.39 | 31.51 | 1269.87 |
| NETM-SAC | 1986.57 | 137.35 | 1754.36 |
| SAC | 2246.11 | 148.21 | 2002.02 |
| PER-SAC | 2037.74 | 141.53 | 1797.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, P.; Di, C.; Lv, J.; Zhao, P.; Chen, C.; Wang, R. Robotic Arm Trajectory Planning in Dynamic Environments Based on Self-Optimizing Replay Mechanism. Sensors 2025, 25, 4681. https://doi.org/10.3390/s25154681
Xu P, Di C, Lv J, Zhao P, Chen C, Wang R. Robotic Arm Trajectory Planning in Dynamic Environments Based on Self-Optimizing Replay Mechanism. Sensors. 2025; 25(15):4681. https://doi.org/10.3390/s25154681
Chicago/Turabian StyleXu, Pengyao, Chong Di, Jiandong Lv, Peng Zhao, Chao Chen, and Ruotong Wang. 2025. "Robotic Arm Trajectory Planning in Dynamic Environments Based on Self-Optimizing Replay Mechanism" Sensors 25, no. 15: 4681. https://doi.org/10.3390/s25154681
APA StyleXu, P., Di, C., Lv, J., Zhao, P., Chen, C., & Wang, R. (2025). Robotic Arm Trajectory Planning in Dynamic Environments Based on Self-Optimizing Replay Mechanism. Sensors, 25(15), 4681. https://doi.org/10.3390/s25154681