1. Introduction
With the increasing scale of industrial equipment and the widespread deployment of sensors, a large volume of heterogeneous time series data (e.g., temperature, vibration, current, pressure) is continuously collected from the Industrial Internet of Things (IIoT). These sensor streams reflect changes in the operational status of devices and, when properly analyzed, can support timely fault detection, improve equipment reliability, and reduce operational costs [
1].
To extract actionable insights from such data, the concept of situation awareness—including perception, comprehension, and prediction—provides a structured framework [
2]. In the context of industrial devices, this translates into monitoring operational conditions, identifying abnormal behaviors, and predicting future faults based on temporal sensor patterns.
Many mathematical statistics or machine learning methods have emerged to analyze and process industrial equipment data. Models can be trained on normal and abnormal data and then used to detect abnormalities [
3]. The operation status of the equipment is often a dynamic process, and the data collected by the sensors have temporal characteristics. Traditional methods based on static data analysis are difficult to capture the evolution trend of equipment status. As a deep learning model that can handle long-term sequence dependencies, Long Short-Term Memory Networks [
4] (LSTMs) are widely used in the operation state awareness of industrial equipment. LSTMs can automatically extract features from time series data and identify equipment status trends so as to achieve more accurate fault detection and prediction.
Considering the increasing complexity of industrial device data and the rarity of abnormal instances in real-world scenarios, traditional LSTM models often suffer from overfitting to normal patterns and fail to detect novel or subtle anomalies [
5]. Also, it is difficult to rely on machine learning models alone to ensure the security and trustworthiness of data. To prevent data from being tampered with during transmission and storage, blockchain technology can be used in conjunction with an LSTM model. Despite extensive research efforts, two core challenges persist: fault instances are rare and evolve dynamically, making traditional machine learning methods insufficient for high-accuracy anomaly detection; and current systems lack secure, tamper-resistant mechanisms for storing and verifying sensitive device status data.
To address these challenges, we propose a hybrid system that combines deep learning with blockchain technology for device situation awareness. Specifically, we design an LSTM-based encoder–attention–decoder model to capture long-term dependencies in multivariate time series data and accurately detect faults. Meanwhile, we integrate smart contracts on a blockchain to securely record and verify device status and trigger alerts in real-time. According to the data collected by various devices, we can judge their operation status by analyzing their changes in the time series, and then make corresponding decisions. In our model, the running state is mainly divided into two modes: suspicious mode and anomalous mode. The main contributions of our research are described below.
We propose LEAD, a novel LSTM–Attention-based encoder–decoder model for time series anomaly detection in industrial devices. The model effectively addresses the challenge of detecting rare anomalies and improves the score to 0.96, outperforming existing RNN, LSTM, and BI-LSTM baselines.
We design and implement a blockchain-based smart contract mechanism that ensures secure, tamper-resistant, and automated recording of device data and anomaly results. The system is capable of detecting unauthorized uploads, tampering attempts, and generating alerts.
The remainder of the article is organized as follows:
Section 2 reviews the work on device state-aware prediction using LSTM-related methods. In
Section 3, a method for anomaly detection of time series data based on LSTM combined with an attention mechanism is proposed. In
Section 4, we explain how to deploy an auto-detection module on the blockchain to implement on-chain data tampering alarms through smart contracts. In
Section 5, we analyze and discuss the results of experiments on real datasets using the RNN, LSTM, BI-LSTM, and LSTM–Attention methods. On-chain anomaly detection and tamper alarms were demonstrated to verify security and effectiveness.
Section 6 summarizes the content of this study.
2. Related Works
Time series anomaly detection has evolved from traditional statistical methods to machine learning paradigms. Early approaches, such as support vector machines [
6], offered simplicity, but struggled with nonlinear temporal dependencies, while basic recurrent networks [
7] improved sequence modeling at the cost of gradient vanishing in long-range predictions. The emergence of LSTM-based architectures addressed these limitations, establishing dominance in industrial applications. Bontemps et al. [
8] pioneered neural prediction error thresholds for collective anomalies, yet their fixed error thresholds lacked adaptability to dynamic operational environments. Malhotra et al. [
5,
9] overcame labeled data scarcity through LSTM autoencoders, but their reconstruction-based approach risked overfitting to normal patterns, limiting detection of novel anomaly types. Park, based on the work of Malhotra et al. [
9], implemented EncDec-AD (RNN) [
10]. Subsequent unsupervised variants like Provotar et al.’s autoencoder [
11] and Ergen et al.’s variable-length sequence analysis [
12] enhanced generalization, albeit at the expense of interpretability in decision boundaries.
Hybrid architectures emerged to balance robustness and sensitivity. Lin et al. [
13] integrated VAEs with LSTMs, leveraging VAE’s local feature generation and LSTM’s temporal coherence for multi-scale detection. However, their disjointed training of VAE and LSTM modules introduced optimization complexity. Park et al. [
14] combined autoencoders with LSTM ensembles, achieving superior multivariate fault diagnosis, but requiring prohibitive computational resources for real-time deployment. The attention mechanism in Kong et al.’s AMBi-GAN [
15] adaptively weighted bidirectional LSTM features, yet its GAN-based framework suffered from mode collapse in low-diversity industrial datasets. Complementing these, dynamic thresholding techniques addressed false positive trade-offs: Hundman et al. [
16] introduced nonparametric thresholds for spacecraft telemetry, adapting to seasonal patterns, but requiring manual sensitivity tuning, while Wang et al.’s BiLSTM–Attention model [
17] automated context-aware thresholds through learned data distributions. Wen and Li [
18] proposed an LSTM–Attention–LSTM model for time series forecasting, employing dual LSTMs as encoder–decoder with interleaved attention to capture long-range dependencies in non-stationary data.
In this study, we focus on evaluating the effect of integrating attention mechanisms and blockchain with classical RNN and LSTM-based encoder–decoder models, which are representative baselines for time series anomaly detection. While alternative architectures such as GRU and BiLSTM also offer promising capabilities, we reserve these for future work in order to maintain a clear focus on the contributions of attention and secure model integration.
The integration of blockchain technology within the Industrial Internet of Things (IIoT) has garnered significant research interest [
19,
20,
21,
22]. Blockchain frameworks, like Li et al.’s data sharing model [
23] and Griggs et al.’s medical monitoring system [
24], ensure tamper-proof data integrity through smart contracts. However, their consensus mechanisms incurred latency incompatible with time-sensitive anomaly responses. Lightweight diagnostic alternatives emerged: Zhang et al. [
25] exploited Raft logs for near-zero-overhead distributed storage diagnosis, but limited detection to consensus-related failures, while ScalaLog [
26] circumvented log parsing via LLM-based RAG, enabling scalable failure diagnosis at the cost of dependency on pre-trained language models’ domain adaptability.
Table 1 describes the evaluation criteria that different methods emphasize. In order to address the shortcomings of existing methods, this paper proposes an LSTM Encoder–Attention–Decoder method for time series prediction by inserting a multi-head self-attention module, which improves detection sensitivity and interpretability by highlighting the critical temporal segments that contribute most to anomalies. Compared to complex hybrid architectures like VAEs or GANs, LEAD remains lightweight and more stable in training. At the same time, there are still problems such as insufficient data trustworthiness and lack of automation performance. Due to the requirements of the industrial field, this paper designs a blockchain awareness mechanism to realize the functions of safe storage and anomaly detection through smart contracts. Our work targets device-level anomaly detection and data integrity assurance using blockchain smart contracts. By embedding anomaly scores and detection results directly on-chain, the proposed system extends fault observability to data-origin faults.
3. LSTM-Based Encoder–Attention–Decoder (LEAD) Architecture
This section first introduces the basic architecture of the LSTM model, and then specifically explains the LSTM-based Encoder–Attention–Decoder (LEAD) structure. Next, it explains the training and testing modes of this model, as well as the indicators established for equipment time series fault detection for actual anomaly observation.
3.1. Proposed Model Architecture
This study proposes an LEAD model for anomaly detection and device situational awareness of time series data from devices. Set time series . Each data point represents the observation value of the m dimensional sensor reading at time . Due to the multidimensional and strong temporal correlation characteristics of industrial equipment data, we extract fixed-length subsequences from long time series through sliding windows to construct a dataset for model training and detection.
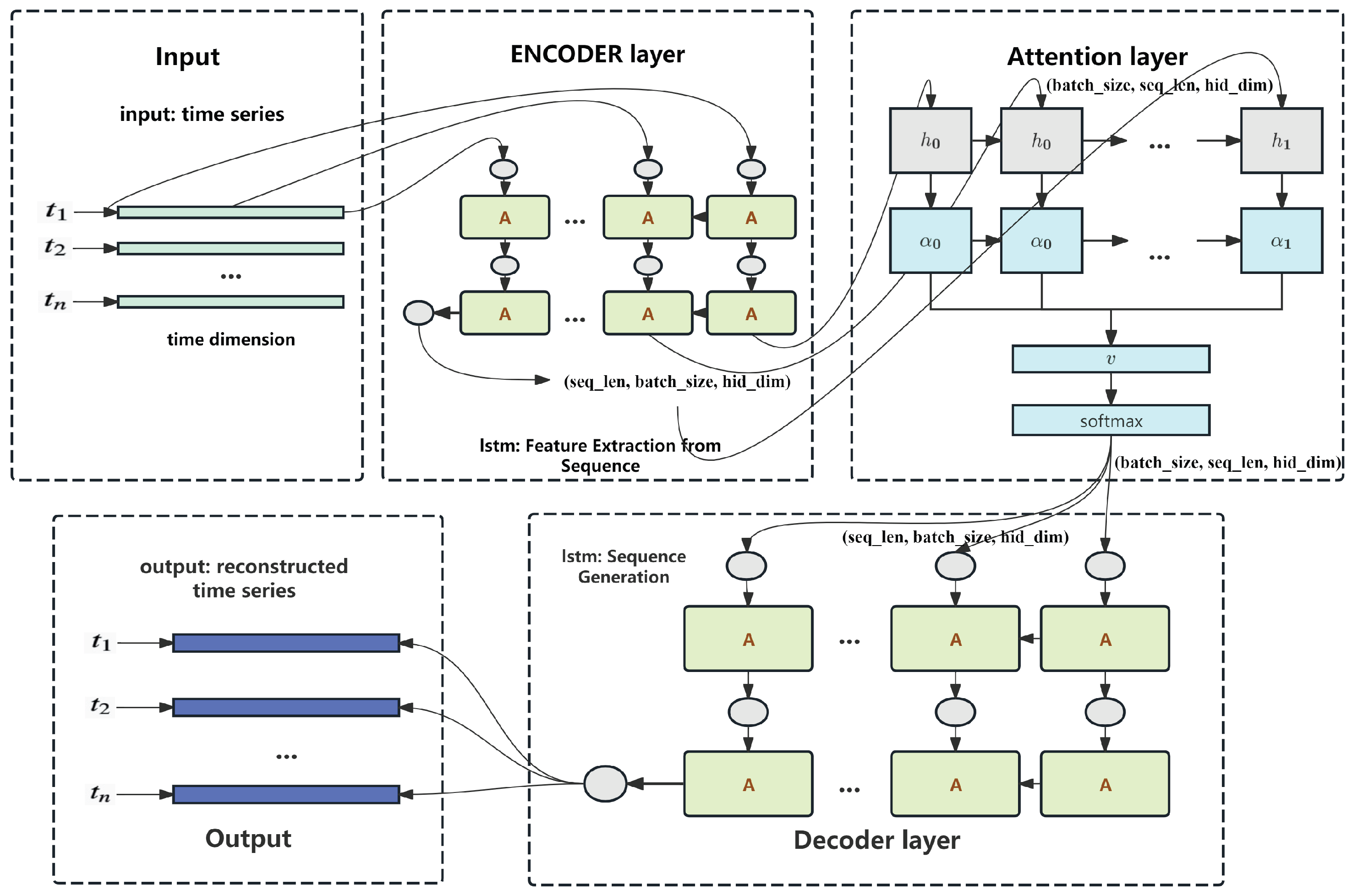
As illustrated in
Figure 1, the LEAD architecture consists of an LSTM-based encoder, a self-attention mechanism, and an LSTM-based decoder. The encoder captures the temporal dependencies of the input sequence and transforms it into a sequence of hidden states. These hidden states are passed through a multi-head self-attention module, which assigns dynamic weights to different time steps, enabling the model to focus on informative moments that may indicate early signs of faults. The attention-weighted representation is then input to the decoder, which reconstructs the original sequence in a step-by-step manner.
During training, the model minimizes the reconstruction error between the input and output sequences, effectively learning the normal temporal patterns of the system. In the inference phase, the reconstruction error for each time step is computed and used to derive an anomaly score for each data point . A higher anomaly score indicates a greater deviation from the learned normal pattern, suggesting a higher likelihood of fault or abnormal behavior.
3.2. Prediction Model Using LEAD
We employ the LEAD to train and predict normal time series.
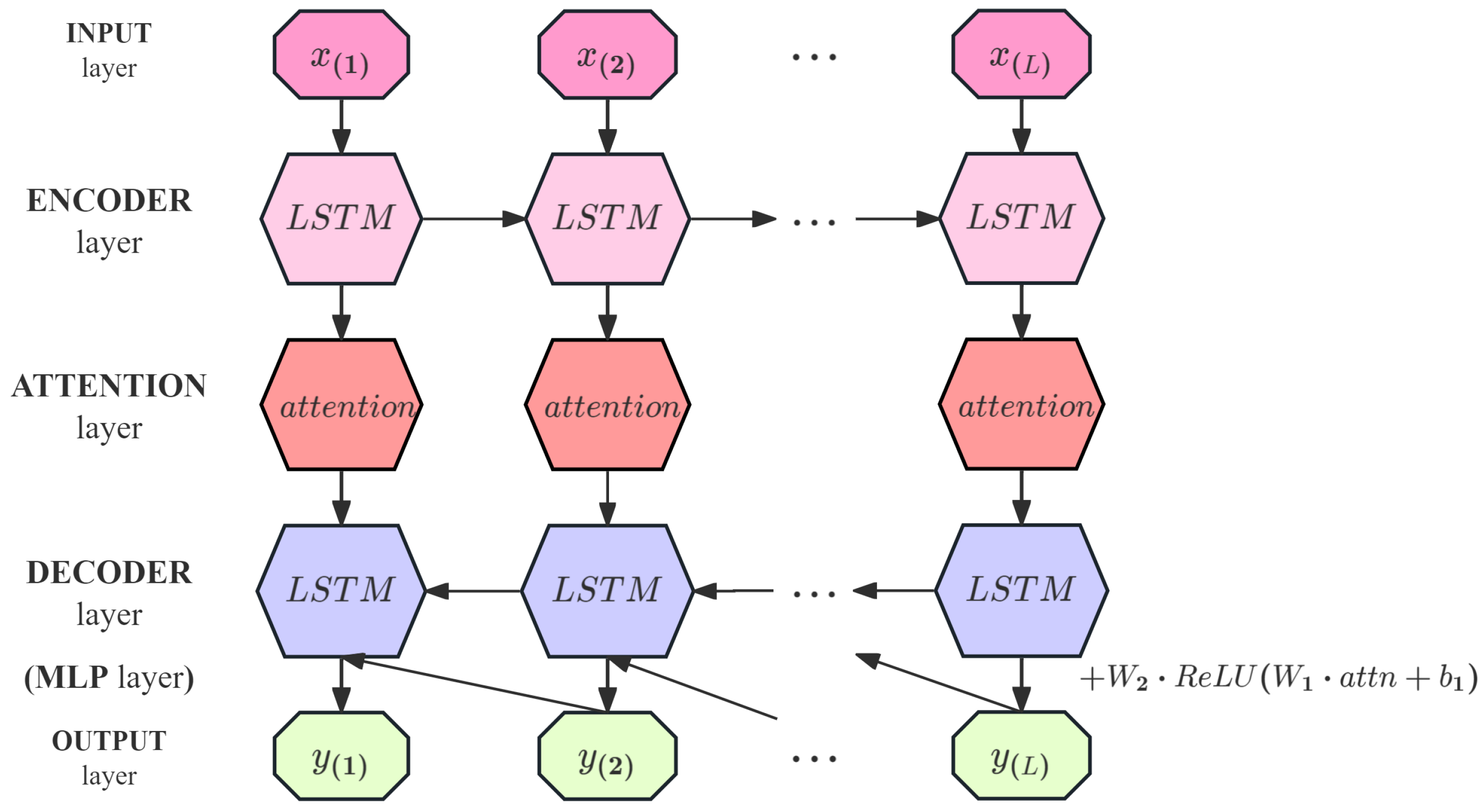
Figure 2 depicts the five main layers of the LEAD. The encoder learns a fixed-length vector representation of the input time series. The LSTM units extract the timing features and generate the hidden state. The attention mechanism assigns different weights at each time step, allowing for the model to focus on various parts of the sequence. The decoder utilizes the encoder’s output representation along with the attention-weighted historical information to predict the time series, relying on the current hidden state and the prediction from the previous time step. This layer is attached with an MLP branch, with the LSTM layer decoding the encoded features and then further extracting the features using MLP. The LSTM decoder output and the MLP branch output are fused outputs.
As
Figure 2 shows, given a time series
X =
,
represents the hidden state of the encoder at time
, where
and
c is the number of LSTM units in the encoder’s hidden layer. The encoder and decoder are jointly trained to reconstruct the target time series in reverse order (similar to Malhotra et al., 2016) [
5], i.e., the target time series is
. The decoder uses
as input to obtain the state
. The final hidden state
of the encoder is used as the initial state of the attention layer. The output of the attention layer
is fed into the decoder through a fully connected layer. The decoder takes the final hidden state of the encoder
as the initial input hidden state
of the decoder. The decoder employs LSTM units with the same architecture as the encoder and performs step-by-step reverse prediction. At each step
i (from
to
), the decoder uses the previously generated output
as the input to the LSTM to update its hidden state
. Then, the current hidden state
is used to generate the predicted output
. This process is performed in an autoregressive manner until the entire reversed prediction sequence
is generated.
3.3. Illustrative Example of LEAD Workflow
To clarify the working process of the proposed LEAD model, we provide an illustrative example using a representative time series subsequence from the ECG dataset. Suppose we observe a univariate input segment , where the sudden spike at indicates a potential anomaly.
This sequence is first processed by the LSTM-based encoder, which transforms it into hidden states . The self-attention mechanism then calculates attention weights to emphasize the most informative time steps. For example, the weights might be , assigning the highest weight to due to its abnormal value.
Using the weighted context, the decoder reconstructs the sequence, resulting in
. The anomaly score at each step is calculated as
, yielding
Since significantly exceeds the threshold, is flagged as an anomaly. This detection result, along with its timestamp and device metadata, is then recorded on the blockchain via smart contracts to ensure secure and verifiable logging.
3.4. LSTM Unit
The LSTM architecture comprises three main gates—forget, input, and output—that regulate the flow of information through time [
4]. These gates control what information to discard, update, and expose at each time step. Let
be the input,
the previous hidden state, and
the previous cell state. The LSTM update equations are as follows:
where
denotes the sigmoid function, and tanh is the hyperbolic tangent function. These equations govern how the LSTM updates its internal cell state and produces the hidden state
at each time step. Equation (
2) summarizes the core components of the LSTM unit:
: Forget gate—controls which parts of the previous cell state should be discarded.
: Input gate—determines which new information should be added to the cell state.
: Candidate memory—represents potential new information for the cell state.
: Updated cell state—integrates retained memory and new candidate values.
: Output gate—controls which parts of the cell state contribute to the hidden state.
: Hidden state—serves as both the output at time step t and input for the next step.
3.4.1. Encoder Layer
LSTM is part of encoder, which is responsible for converting the input sequence into a fixed-length context vector. This context vector typically contains information from the input series and captures the dependencies of a longer range in the time series. The encoder’s LSTM processes the input sequence and outputs the final hidden state.
The encoder first receives multidimensional time series data with shape
, where
B is the batch size (number of sequences processed together),
T is the sequence length (number of time steps), and
is the encoder input dimension (number of features at each time step). A linear transformation is applied to project the input into a dimension-reduced feature space
, which is more suitable for the LSTM layer. The transformation is
where emb is the embedded representation,
is the weight matrix, and
is the bias. After this operation, the data shape becomes
.
This embedded input is then passed into an LSTM, along with an initial hidden state. The LSTM captures the temporal dependencies and outputs, which are subsequently passed into the attention layer, a hidden state of shape , and an output feature sequence of shape .
3.4.2. Attention Layer
Before applying self-attention, adjust the LSTM output from
to
to fit the attention computation:
where
denotes the LSTM output tensor,
T is the sequence length,
B is the batch size, and
H is the hidden dimension.
Self-attention [
27] models dependencies between time steps by projecting the input into three matrices: query (
Q), key (
K), and value (
V). The dot-product of
Q and
K generates attention scores, which are weighed
V to produce context-aware representations.
We employ multi-head self-attention [
27] to capture diverse feature relationships. Compared to single-head or additive attention mechanisms, multi-head attention allows for the model to jointly attend to information from different representation subspaces at different time steps. This enables the model to better capture complex temporal dependencies and subtle variations across multivariate time series data. The hidden dimension
H is divided into
m heads (
m denotes the number of attention heads), and each head computes independent attention. The outputs are concatenated to form refined features. The matrix transformations are
After splitting,
where
d is the dimension per attention head.
The attention weights for the
i-th head are computed as
where
represents the unnormalized attention energy and
is the attention output of the
i-th head.
Finally, the multi-head outputs are concatenated and linearly transformed:
To align with decoder inputs, the tensor is transposed to
where
denotes the refined self-attention output.
3.4.3. Decoder Layer
The input to the decoder is the output from the attention module. The initial hidden state of the decoder is inherited from the final hidden state of the encoder LSTM. By reusing the encoder’s final state, the decoder is provided with contextual information learned during the encoding phase, enabling it to generate coherent and relevant outputs.
The LSTM receives the refined self-attention output
and hidden state
h as input, applying recurrent computation across the temporal dimension:
where
D denotes the decoder output tensor, maintaining shape
for compatibility with downstream layers.
A linear projection maps the hidden representation to the target space:
where
is the projection matrix and
aligns with the encoder’s input dimension
for potential residual connections.
The attention output
is processed by an MLP with ReLU activation:
where
,
are weight matrices,
is the bias vector, and
denotes the MLP’s hidden dimension.
The outputs are combined via weighted averaging:
When residual connections are enabled,
where
is the original input tensor and the equality
ensures dimensional consistency.
The complete prediction workflow is detailed in Algorithm 1. It illustrates the computation flow from input sequence to output prediction, highlighting key operations and corresponding tensor shape transformations at each stage.
| Algorithm 1 LSTM-based Encoder–Attention–Decoder. |
- 1:
▹ - 2:
▹ - 3:
Initialize - 4:
▹
- 5:
▹ - 6:
▹ - 7:
▹ - 8:
▹
- 9:
▹ - 10:
▹ - 11:
- 12:
- 13:
if use_residual then - 14:
- 15:
end if - 16:
▹
|
3.4.4. Multi-Objective Joint Training Strategy
Similarly to the process of [
10], in our approach, the model is jointly optimized using a three-part loss function.
- A.
Free-Running Loss
In the free-running mode, the model uses its own predictions as input during the decoding phase. This simulates the inference process and enhances the model’s long-term prediction capabilities. However, since errors accumulate over multiple steps, this mode demands better generalization ability from the model.
The free-running loss evaluates long-term prediction stability:
where
N denotes the number of samples,
refers to the free-running prediction of the
i-th sample,
refers to ground truth sequence, and
calculates the squared Euclidean norm.
During free-running, predictions are recursively fed as input:
where
denotes the model with parameters
, enforcing multi-step prediction capability.
- B.
Teacher Forcing Loss
Teacher forcing loss measures short-term prediction accuracy:
where
uses ground truth inputs:
This direct feeding mechanism accelerates convergence by minimizing error accumulation.
- C.
Hidden State Consistency Loss
Aligning hidden representations between modes,
where
represents the hidden states from free-running LSTM and
represents the hidden states from teacher-forced LSTM.
The hidden states are generated through
This consistency constraint enhances model robustness against different inference modes.
The difference between the hidden states is penalized, encouraging the model to maintain consistent internal states across the two modes, thus improving stability during inference.
The final loss function is the sum of the three individual losses:
This combined loss function balances long-term and short-term accuracy while ensuring consistency between the hidden states, leading to a more robust and stable model during inference.
3.5. Anomaly Detection
Inspired by Malhotra’s method [
5], we formalize the anomaly detection procedure into three stages. First, assume prediction errors follow a Gaussian distribution during normal operation, and estimate its parameters (mean and variance) from training data. Second, quantify deviations using Mahalanobis distance, which account for feature-scale variations and reduce to a standardized Euclidean distance under independence assumptions. Then, optimize thresholds by maximizing the
score to balance precision and recall. Finally, classify anomalies using a double-threshold rule derived from the optimized criteria. This pipeline ensures statistically grounded detection while operationalizing thresholds for nuanced state awareness (normal/suspicious/anomalous).
3.5.1. Prediction Error Modeling
Suppose that, under normal operating conditions, the prediction error (i.e., the difference between the actual observed value and the predicted value) is of a Gaussian distribution (normal distribution). Let the time series observation at time
t be denoted by
, and the model’s predicted output by
. The prediction residual is defined as
For each feature dimension , it is assumed that the residuals under normal operating conditions follow a Gaussian distribution . The parameters and are estimated from the training data, capturing the mean and variance of the residuals for each feature dimension. This Gaussian assumption allows for the model to detect anomalies by measuring deviations from the expected distribution during inference.
3.5.2. Standardized Anomaly Scores
Mahalanobis distance is generally used to measure the degree to which the current forecast error deviates from the normal distribution. For the multivariate prediction error vector
calculated from Equation (
23), the Mahalanobis distance of the error vector is defined as
where
is the mean vector of the training set errors, and
is the covariance matrix of the training set errors. Assuming the features are independent:
The covariance matrix
will reduce to a diagonal matrix:
Under this assumption, the Mahalanobis distance can be reduced to the standardized Euclidean distance of the individual features:
In this case, the Mahalanobis distance is effectively reduced to a sum of squared, normalized deviations along each feature dimension. This standardization accounts for the different scales and variances of the individual features, making the anomaly detection more robust. Therefore, we define as anomaly score. The anomaly score follows a chi-squared distribution with d degrees of freedom .
The mathematical expectation of the anomaly score is given by . The chi-squared distribution is used to measure the deviation of the residuals from the expected normal behavior. A larger anomaly score indicates a greater deviation from the normal distribution, which can be used to detect abnormal conditions in the time series data.
3.5.3. Threshold Setting
The selection of the threshold depends on the score, which balances the model’s precision (P) and recall (R). Following standard evaluation metrics for anomaly detection, we define the following parameters:
Precision (
P) is the proportion of true anomalies among detected anomalies, calculating how many of the samples we predict of a certain type of sample are correctly predicted.
where
and
denote true and false positives, respectively.
Recall (
R) is the proportion of actual anomalies correctly identified, calculating how many samples are correctly predicted for the original actual samples.
where
as false negatives.
The
score combines
P and
R as a weighted harmonic mean:
where
adjusts the emphasis on
R (e.g.,
prioritizes recall). The optimal
maximizes
, trading off detection sensitivity (
R) and reliability (
P).
3.5.4. Double-Threshold Classification
The optimal threshold
maximizing
(Equation (
30)) provides a single critical value for anomaly declaration. However, to enable early warnings and severity stratification, we generalize this to a double-threshold scheme, which is defined as follows:
where
denotes the
-th quantile of the anomaly scores
from the training dataset.
and
represent the thresholds corresponding to the 90th and 95th percentiles of the training scores, respectively.
The anomaly status at time t is determined based on the anomaly score. If the anomaly score is less than or equal to , the state is classified as normal. If the score lies between and , the state is marked as suspicious, indicating a possible anomaly. If the score exceeds , the state is classified as anomalous, indicating a high likelihood of abnormal behavior.
The double-threshold mechanism provides a nuanced classification, distinguishing between normal, suspicious, and anomalous states based on the severity of the deviation from the normal distribution, supporting the awareness of the device’s situation.
4. Blockchain System
The proposed system integrates time series anomaly detection with a blockchain-based mechanism through a synergistic architecture. On the device layer, industrial sensors feed multivariate temporal data to the LEAD module (
Section 3), where deep learning models generate anomaly scores while smart contracts automate the execution of response protocols based on anomaly scores, eliminating the need for human intervention in routine fault-handling procedures. The blockchain layer, built upon the FISCO-BCOS [
28] consortium chain, establishes an immutable trust anchor by cryptographically binding detection processes with operational outcomes: model hashes and anomaly metadata are permanently recorded on-chain, whereas sensor data remains securely stored off-chain with periodic hash commitments.
4.1. Data On-Chain Process
In this system, industrial device sensors periodically collect data and key information is stored on the blockchain to ensure data integrity and traceability. The entire data on-chain process includes data collection, hash computation, identity verification, data storage, and anomaly detection.
- A.
Data Collection and Pre-processing
As mentioned in
Section 3.1, the device data can be represented as a time series D =
, where
represents the device’s situation information at time
t, such as temperature, pressure, and vibration. The collected data is preprocessed locally to facilitate subsequent hash computation and anomaly detection.
- B.
Device Data Hash Computation
When a device uploads data D to the blockchain, we use the SHA-256 hash function to compute a unique identifier . This hash value ensures data immutability. Even if the raw data is not stored on-chain, its integrity can be verified through hash validation.
- C.
Device Identity Verification and Data Signing
To prevent unauthorized devices from uploading false data, a digital signature mechanism is used to ensure data authenticity. Suppose the private key of device
i is
, then the signature is computed as
When uploading data, the smart contract verifies the signature using the device’s public key
:
If the verification fails, it indicates that the data source is “untrusted”. The contract rejects data storage and triggers the UnauthorizedAttempt event.
4.1.1. Data Storage and Anomaly Detection
Once the identity verification is successful, the hash value
and related metadata (device ID, timestamp
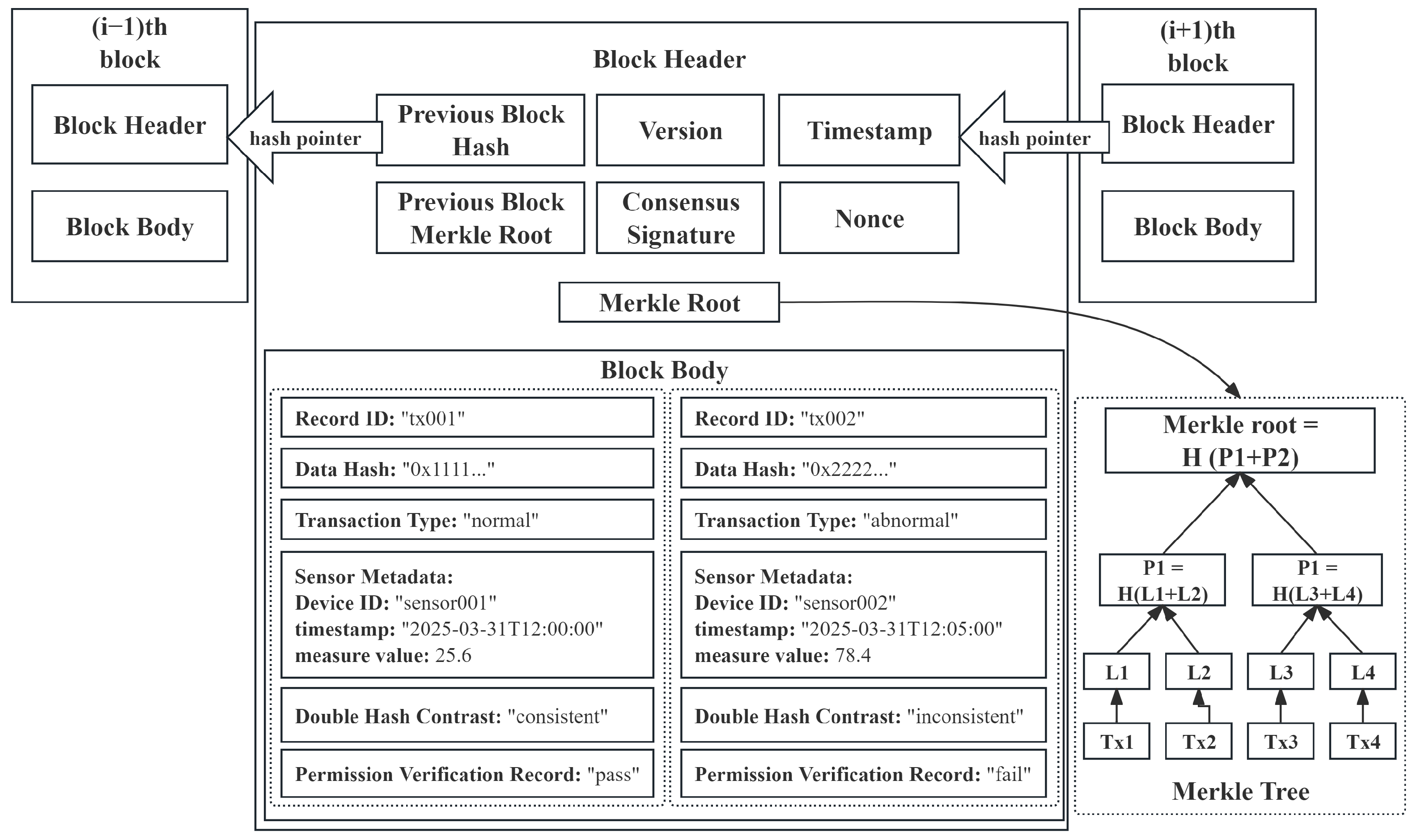
T) are stored on the blockchain. The structure of the specific data storage is shown in
Figure 3. Meanwhile, an LSTM–Attention–LSTM model performs anomaly detection, calculating the anomaly probability
. If
, where
refers to the classification threshold mentioned in
Section 3.5.4, the contract triggers the
AnomalyDetected event to notify maintenance personnel to take necessary actions.
4.1.2. Data Integrity Verification and Tampering Detection
To check if data has been tampered with, the device can query the stored hash value from the blockchain and compute the local hash value for comparison. If the two values do not match, the HashMismatch event is triggered, indicating possible data tampering.
Additionally, a Merkle tree (referring
Figure 3) is used to improve data audit efficiency:
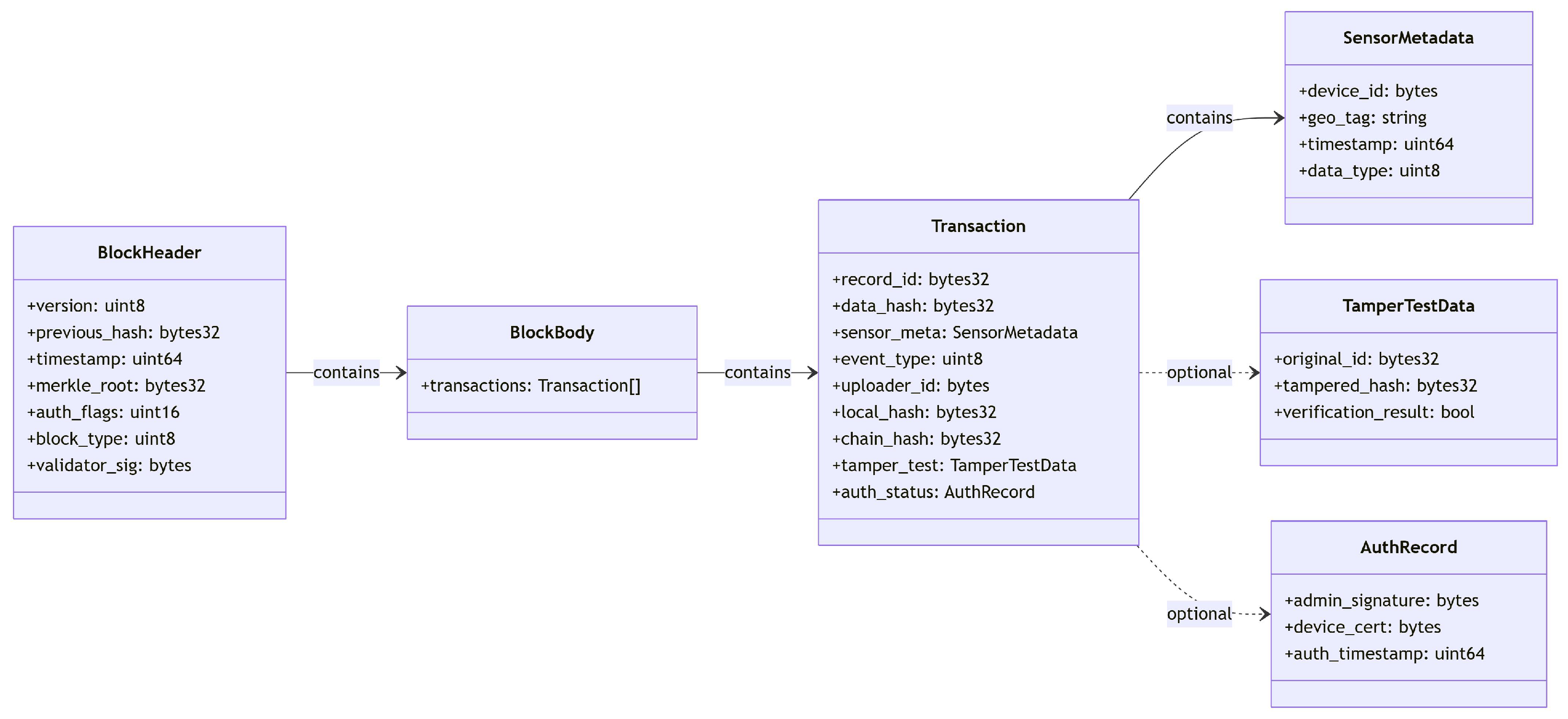
This ensures that, even with a large amount of data stored in a block, data integrity can still be efficiently verified. The above transactions will be recorded in the chain in detail, including data collection, hash computation, identity verification, data storage, and anomaly detection, and the structure of the transaction storage is shown in
Figure 4.
4.2. Smart Contract Mechanism
FISCO BCOS uses Solidity language to write smart contracts to achieve trusted storage of device status data and exception detection logic. Smart contracts are deployed on the blockchain network. Whenever industrial equipment uploads sensor data, the contract will automatically execute, verify data integrity, and store it on the blockchain. The smart contract also contains exception detection trigger logic, that is, when our LEAD model detects an abnormal device status, the contract will call the notification mechanism, send an alert to the relevant maintenance personnel, and record the event in the blockchain ledger. This automated smart contract execution mode not only reduces human intervention, but also ensures the transparency and tamper resistance of device status data.
We design four smart contracts here, which are responsible for data storage, anomaly detection, identity verification, and data integrity checks, respectively, ensuring a trustworthy record of device status (see Algorithm 2).
| Algorithm 2 Data management contracts |
- 1:
Data Structure:
- 2:
State Variables: - 3:
▹ Contract constructor - 4:
function uploadData(d, h) - 5:
Require: onlyAuthorized - 6:
- 7:
- 8:
Emit EventUpload - 9:
end function - 10:
function verifyData(r, d) - 11:
if then - 12:
Revert: “Record invalid” - 13:
end if - 14:
- 15:
if then - 16:
Emit EventHashMismatch - 17:
end if - 18:
end function - 19:
function checkAnomaly(r, p) - 20:
if then - 21:
Emit EventAnomaly - 22:
end if - 23:
end function - 24:
function manageDeviceAccess(a, mode) - 25:
if mode = admin then - 26:
if then - 27:
Revert: “Access denied” - 28:
end if - 29:
else if mode = authorize then - 30:
Require: - 31:
- 32:
else if mode = revoke then - 33:
Require: - 34:
- 35:
else if mode = check then - 36:
if then - 37:
Revert: “Device unauthorized” - 38:
end if - 39:
end if - 40:
end function
|
When a device submits data to the blockchain, the contract first verifies whether the device is authorized. If authorized, the data is stored along with its hash, timestamp, and sender address. An anomaly detection mechanism is incorporated to identify potential faults by analyzing anomaly probabilities. If a high anomaly probability is detected, an event is triggered for further investigation.
This dual-layer design not only preserves the temporal sensitivity of LSTM-based detection, but also embeds verifiable audit trails into every decision cycle, transforming statistical anomalies into actionable, tamper-proof events. The contract also supports data auditing, allowing for users to verify whether the stored hash matches the locally computed hash.
5. Experiments and Analysis
In order to verify the effect of our system model, our experiment first focuses on the LEAD model to explore its superiority over similar models. Next, we simulate the blockchain system to verify the effectiveness and then analyze its efficiency and security.
5.1. Experimental Settings
We use LEAD on the electrocardiogram (ECG) dataset [
29], which consists of a univariate ECG signal of two channels that records the electrical activity of the human heart over time. The dataset includes 5000 samples, each consisting of 140 time steps. Among them, only a small proportion represent abnormal heartbeats, introducing a realistic data imbalance similar to that seen in industrial equipment monitoring tasks.
During the data preprocessing stage, time series data serialized in Pickle format is loaded from the specified directory and split into features and labels, where the label corresponds to the last dimension of each data instance. Before training, all data were normalized to the range [0, 1]. We then segmented the signals into fixed-size windows and labeled them according to their ground truth: normal, suspicious, or fault. This preparation allowed us to evaluate our LSTM–Attention anomaly detection model’s ability to identify subtle temporal deviations in time series signals.
We implemented our LEAD model using PyTorch 2.6.0+cu124. The experiments were conducted on a machine with an NVIDIA GPU (CUDA-enabled), and
Table 2 shows the hyperparameters used throughout training and evaluation.
During training, the teacher forcing ratio was set to 0.7. We also applied residual connections in the LSTM layers to enhance gradient flow. All models were trained with a fixed random seed (1111) for reproducibility. Anomaly detection was based on reconstruction error, with thresholds determined from training statistics.
To simulate the on-chain mechanism, we use the FISCO-BCOS mentioned above. The operating system is Ubuntu 20.04.6. We import the block structure and smart contract into the blockchain system according to the block design described in
Section 4.1 and
Section 4.2, and upload simplified sensor data to the chain for the subsequent detection and simulation steps.
5.2. Evaluation Index
We use precision, recall, and
to judge the effectiveness of the model. According to Equation (
30), when
, precision is given more weight; when
, recall is given more weight. Here, we choose
because, in industrial equipment anomaly detection, data are highly imbalanced (anomalous samples are extremely rare). The proportion of actual anomaly points in sequences labeled as anomalous may not be high, so the recall is expected to be low [
30]. Therefore, select the threshold at which the
score is the highest. The values of precision, recall, and
at this threshold are used for evaluation.
5.3. Result Analysis
5.3.1. LEAD Prediction
For the training data, the global mean and standard deviation are computed and used to perform z-score standardization, ensuring that each feature dimension has zero mean and unit variance. A Gaussian noise-based data augmentation strategy is employed, in which noise scaled by the standard deviation is added to the original data to generate multiple augmented samples. For test data, the same normalization parameters obtained from the training set are reused, and data augmentation can optionally be applied. We use the LEAD model to predict the future time sequence. Compute the prediction prediction error in order to obtain the anomaly score. The results are then compared with the results of Bi-LSTM [
17], EncDec-AD(LSTM) [
5] and EncDec-AD(RNN) [
10].
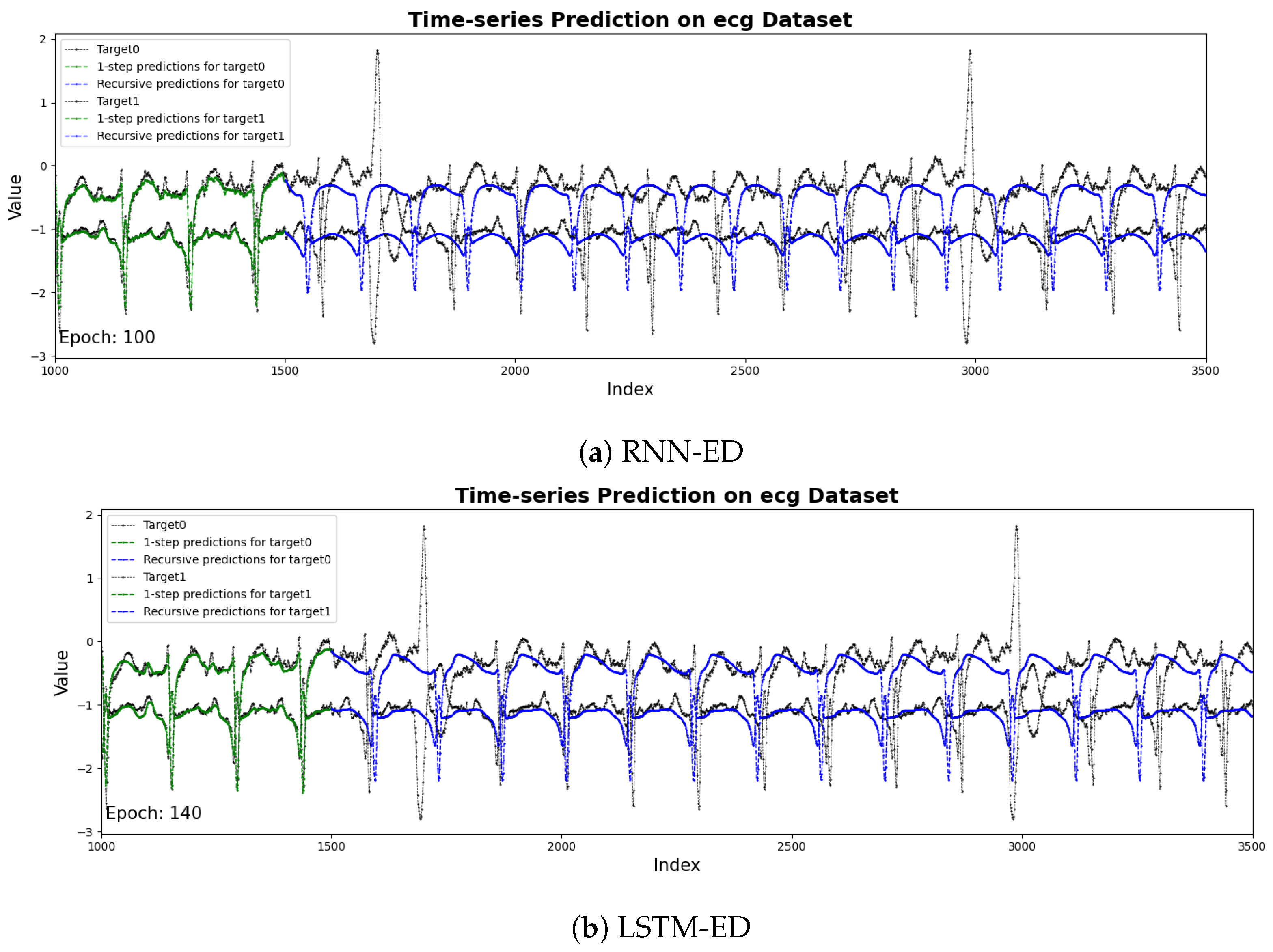
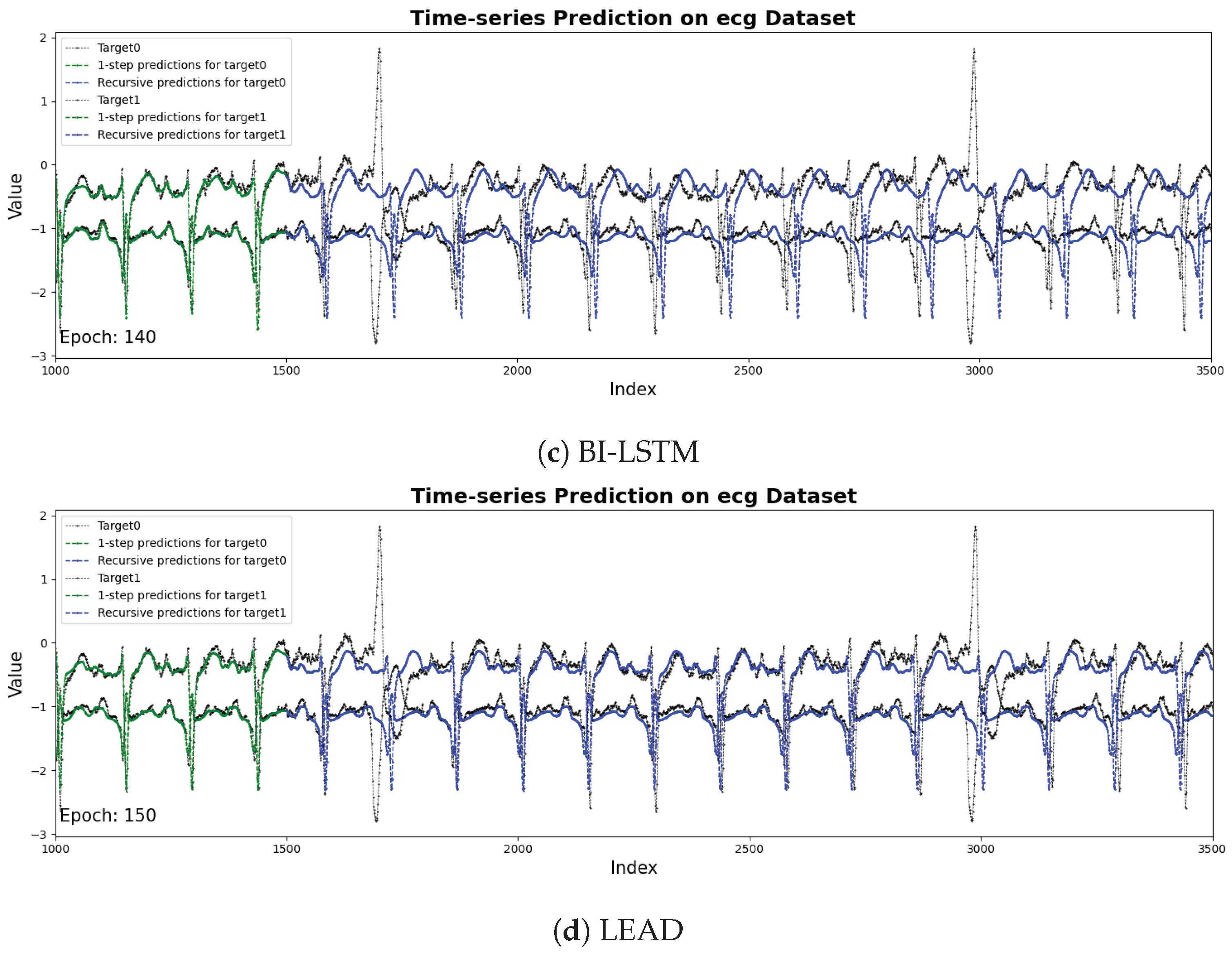
Figure 5 shows the results of the prediction sequences by RNN, LSTM, BI-LSTM and LEAD. The two time series represent the two channels in the dataset, respectively. The black line represents the raw sensor data from the target channel, while the blue line denotes the predicted values generated by the model. It is obvious that LEAD performs best in the details of prediction. LEAD has more parameters. The attention mechanism introduces additional weight matrix and computational logic, and the model needs more epochs to fully learn effective time-dependent and contextual information during training. the best can be achieved at the 150th epoch.
5.3.2. Anomaly Detection
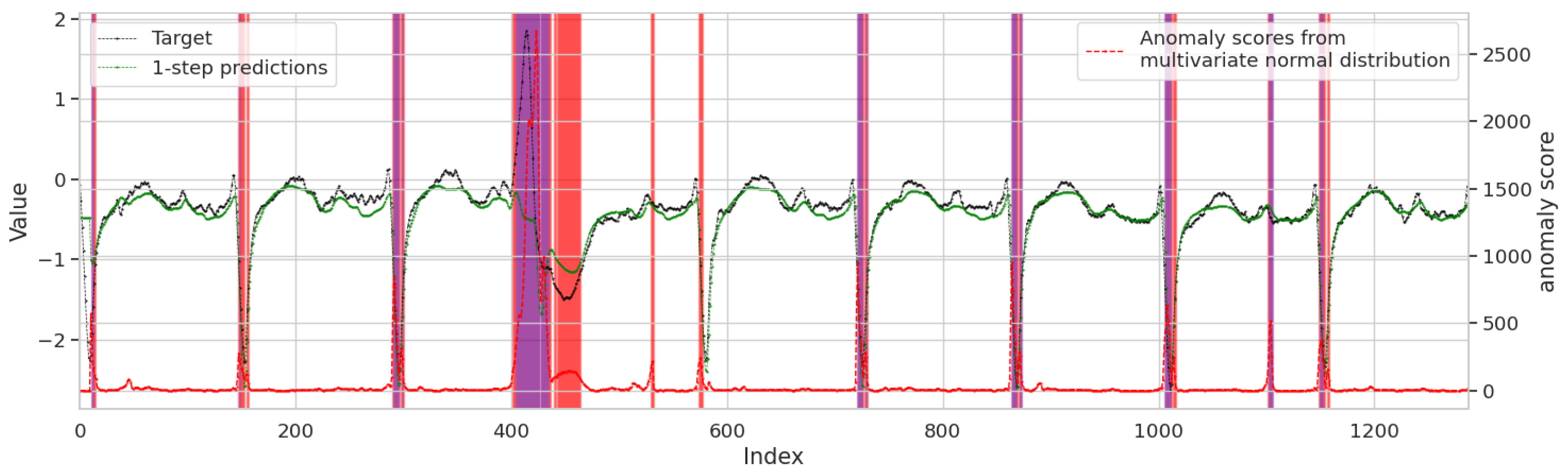
Figure 6 provides a detailed analysis of the LEAD model’s detection results. In the middle panel, the black line and green line represent the target sequence and predicted values, respectively. This sequence is split from one of the two channels in
Figure 5 for anomaly detection. The close alignment between these two lines during normal operation demonstrates the model’s predictive accuracy. In the lower panel, the red line illustrates the calculated anomaly scores over time, reflecting the degree of deviation between the actual and predicted values. Regions shaded in red correspond to suspicious windows, where the anomaly score exceeds the predefined suspicion threshold 0.90, indicating potential, but not definitive, anomalies. Regions shaded in purple mark abnormal windows, where the anomaly score surpasses the higher anomaly threshold 0.95. This visualization highlights the LEAD model’s ability to distinguish between slight deviations and true anomalies.
Table 3 shows that all four models—RNN-ED, LSTM-ED, BI-LSTM, and LEAD—achieve 100% precision on both test channels, indicating high reliability in anomaly detection. However, their recall rates vary significantly: 8%, 14%, 13%, and 19%, respectively. Correspondingly, the F
0.1 scores improve with model complexity, from 0.90 (RNN-ED) to 0.94 (LSTM-ED and BI-LSTM) and 0.96 (LEAD), demonstrating the benefits of architectural enhancements under a precision-focused evaluation. The improvements stem from better temporal modeling: while RNN/LSTM-ED suffer from information compression into fixed-length hidden states, BI-LSTM captures bidirectional dependencies, and the attention mechanism in LEAD further strengthens the model’s ability to focus on early warning patterns.
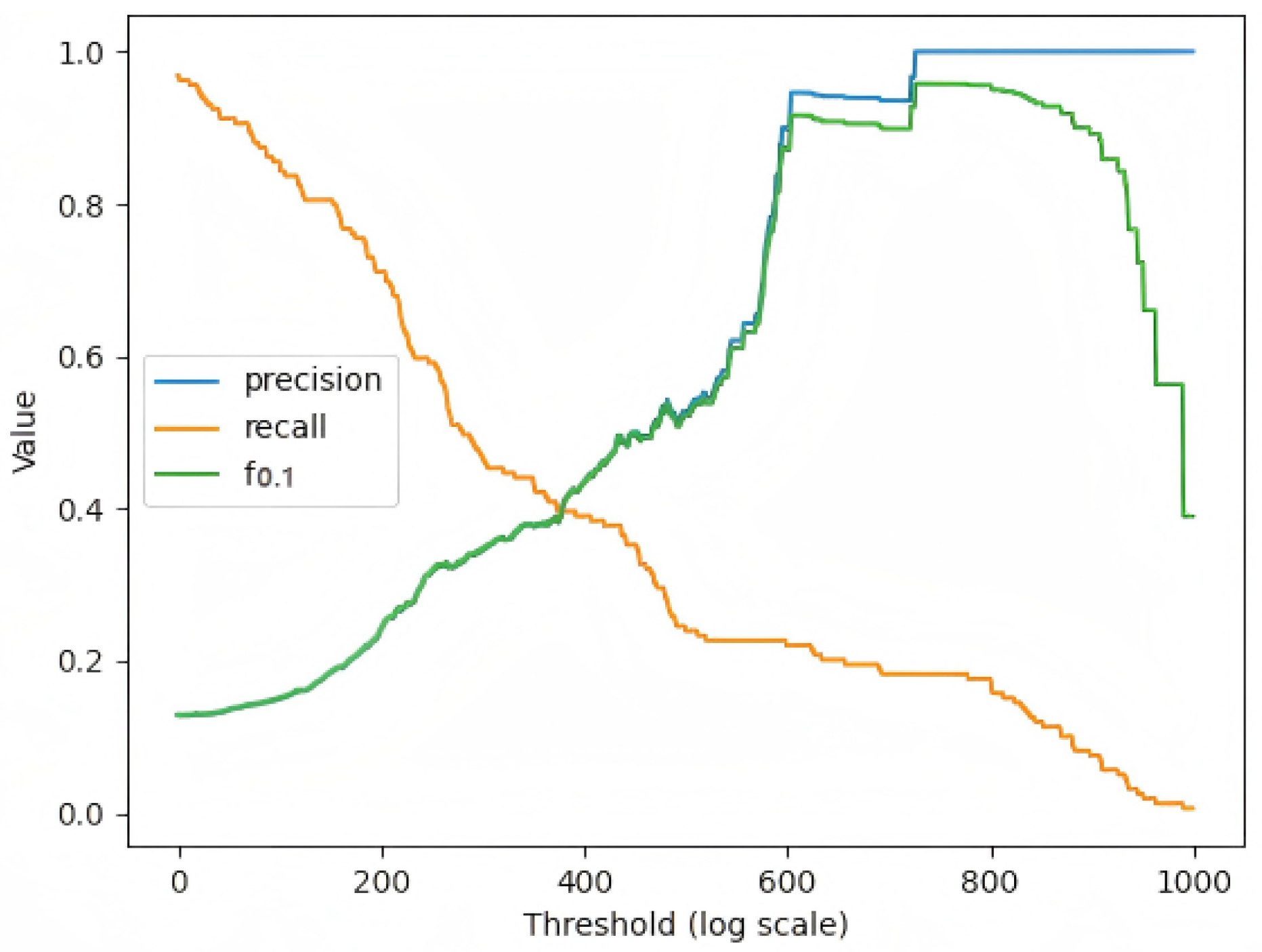
Figure 7 shows how the
score of the LEAD model changes when different thresholds are taken. We take the maximum value that the recall reaches when the precision reaches 1. In anomaly detection of industrial equipment, there are far fewer abnormal samples than normal samples. There are few abnormal samples in the dataset, and we set threshold to quite high to guarantee the precision. The model tends to predict normally, and the sample with a very high probability will be judged as abnormal, so the precision will be high as 100%, but the recall will be low.
5.3.3. On-Chain Simulation
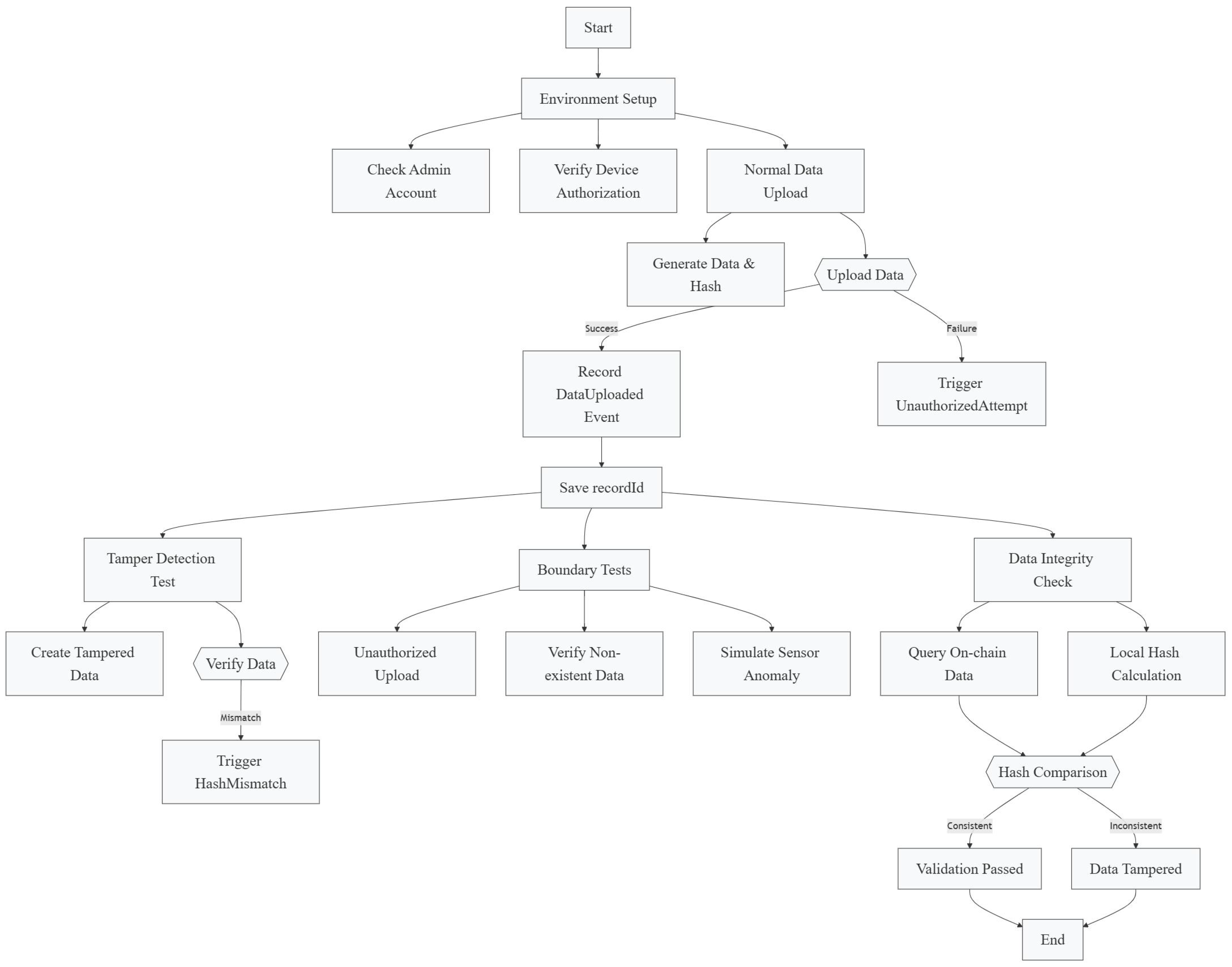
We deploy the proposed LEAD model within a simulated FISCO BCOS blockchain environment to emulate a real-world IIoT data pipeline. A single-group chain with four or more nodes is configured, and smart contracts are automatically deployed without manual intervention. To evaluate the system’s performance, we design and execute four representative test scenarios: (1) normal data upload, (2) tampered data verification, (3) simulated sensor fault detection, and (4) rejection of unauthorized device access. All testing procedures are fully scripted and automated to reflect realistic IIoT operations.
Once a transaction is completed, the smart contract emits an event log containing two indexed topics: the first captures the triggered event type, and the second contains the recordID, which serves as a unique key to verify data consistency. Since recordID is defined as an indexed parameter, it is stored within the transaction’s topic log.
Figure 8 shows the test process of our transactions.
Table 4 gives the results of the three transaction tests that we performed.
Under the consensus, the delay of a single data upload is about 200 ms, which meets the real-time requirements of the industry. When the hash match fails, the HashMismatchevent is triggered (Topic 0: 0x7d7e4bfb...). When a rogue device uploads data, the contract rolls back the transaction (Status 16) through the require statement and triggers the UnauthorizedAttempt event to verify the validity of identity authentication based on digital signature. When the LEAD model detects an anomaly probability , the smart contract triggers the AnomalyDetected event in real-time to notify the maintenance personnel.
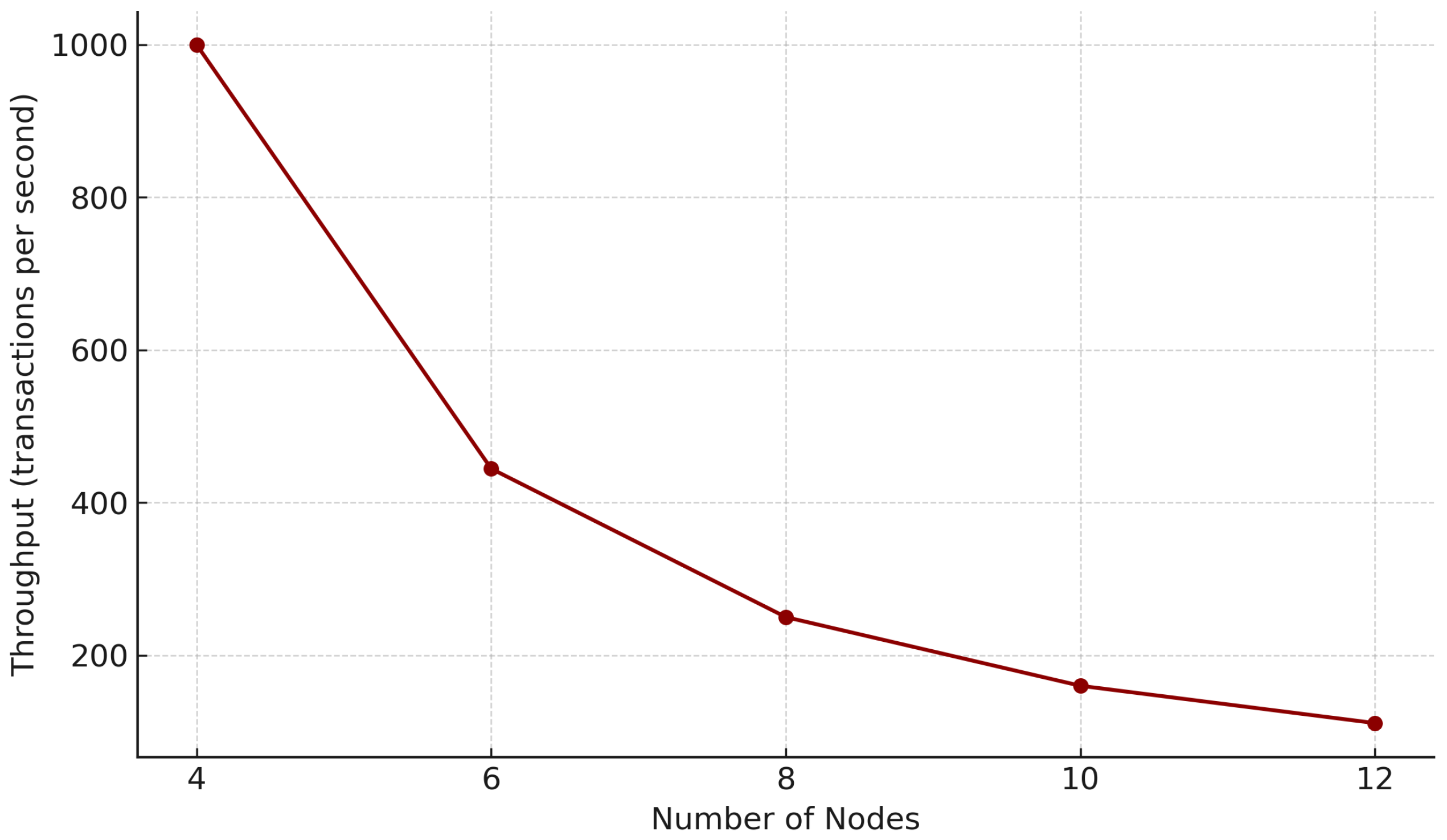
Figure 9 shows that, as the number of nodes in the FISCO-BCOS network decreases, the network throughput decreases rapidly. This phenomenon stems from the three-stage broadcasting feature of the consensus mechanism. Therefore, this mechanism is more suitable for consortium blockchains with a small number of nodes, and, in practical applications, large-scale nodes can be divided into multiple subgroups (such as five nodes per group). Since the consensus protocol is not the focus of this paper, we will not make any adjustments to it.
6. Threats to Validity
There are several potential threats to the validity of our experimental results.
One limitation is the manual selection of anomaly thresholds. Although threshold tuning is common in anomaly detection research, manually set values may introduce subjective bias and affect the consistency of classification results across datasets. In addition, we only evaluated the impact of the multi-head self-attention mechanism, without comparing it to alternative attention variants such as additive or sparse attention. This limits the interpretability of why multi-head attention performs better in our context.
Our model was primarily trained and evaluated on a public ECG benchmark dataset. While this dataset provides clean and labeled sequences for testing, it may not fully reflect the complex operating environments of industrial devices. Furthermore, due to the depth of the proposed model, it requires a relatively large number of training epochs to converge, which may affect reproducibility under constrained hardware or noisy data.
The proposed blockchain integration was tested in a simulated FISCO-BCOS consortium environment with a limited node scale and controlled data upload scenarios. This limits the generalizability of the results to real-world IIoT deployments involving high-throughput, high-frequency sensor networks and unpredictable failure behaviors. The use of ECG data, although structurally similar to other time series, may also reduce generalization to more complex multivariate industrial sensor data.
7. Conclusions
This research presents a novel integration of blockchain and deep learning for industrial device fault detection. The LEAD model leverages an attention-enhanced LSTM architecture to capture long-term temporal dependencies in sensor data, while blockchain ensures data immutability through cryptographic hashing and smart contracts. Experimental results validate the model’s superiority in precision and robustness, particularly in scenarios with rare anomalies.
Our study contributes to the literature by bridging two previously separated research streams: deep learning-based fault detection and blockchain-based secure data management. Theoretically, we demonstrate how integrating an LSTM–Attention model with decentralized blockchain infrastructure can improve anomaly detection accuracy while ensuring data integrity and traceability. Practically, the proposed LEAD system can be applied in real-time Industrial IoT environments where equipment failures need to be identified early and securely logged. The blockchain smart contract mechanism ensures unauthorized or tampered data are flagged instantly, which is crucial for safety-critical industries.
In future work, we will optimize the smart contract design to reduce on-chain storage overhead and improve query efficiency. Lightweight inference techniques such as model quantization and knowledge distillation will be explored for edge deployment. Moreover, we will validate the framework on diverse industrial datasets to assess its cross-domain generalizability and robustness under varied conditions.
Author Contributions
Q.Z. conceived the concept and method; Q.Z. and C.Y. conceived and designed the experiments; Q.Z. and C.Y. performed the experiments; Q.Z. and X.D. analyzed the data; Q.Z. contributed the materials; D.W. validated the concept; Q.Z., C.Y., and X.D. wrote the paper; X.D., G.D., and D.W. reviewed and edited the paper; D.W. managed the progress of the project. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the science and technology project of the Shuohuang Railway Development Co., Ltd., National Energy Group “Research on secure data interaction and digital security management of devices based on blockchain technology” (SHTL-23-30).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding author.
Conflicts of Interest
Authors Qiang Zhang and Caiqing Yue are employed by the company Shuohuang Railway Development Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Krishnamurthi, R.; Kumar, A.; Gopinathan, D.; Nayyar, A.; Qureshi, B. An Overview of IoT Sensor Data Processing, Fusion, and Analysis Techniques. Sensors 2020, 20, 6076. [Google Scholar] [CrossRef] [PubMed]
- Endsley, M.R. Toward a Theory of Situation Awareness in Dynamic Systems. Hum. Factors 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Diro, A.; Chilamkurti, N.; Nguyen, V.D.; Heyne, W. A Comprehensive Study of Anomaly Detection Schemes in IoT Networks Using Machine Learning Algorithms. Sensors 2021, 21, 8320. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based Encoder-Decoder For Multi-sensor Anomaly Detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Mounce, S.R.; Mounce, R.; Boxall, J. Novelty Detection for Time Series Data Analysis in Water Distribution Systems Using Support Vector Machines. J. Hydroinform. 2011, 13, 672–686. [Google Scholar] [CrossRef]
- Nanduri, A.; Sherry, L. Anomaly Detection in Aircraft Data Using Recurrent Neural Networks (RNN). In Proceedings of the 2016 Integrated Communications Navigation and Surveillance Conference (ICNS), Herndon, VA, USA, 19–21 April 2016; pp. 5C2-1–5C2-8. [Google Scholar] [CrossRef]
- Bontemps, L.; Cao, V.L.; McDermott, J.; Le-Khac, N.A. Collective Anomaly Detection Based on Long Short-Term Memory Recurrent Neural Networks. arXiv 2016, arXiv:1610.03875. [Google Scholar]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long short term memory networks for anomaly detection in time series. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 22–24 April 2015; Volume 89, p. 94. [Google Scholar]
- Park, J. RNN Based Time-Series Anomaly Detector Model Implemented in Pytorch. 2018. Available online: https://github.com/chickenbestlover/RNN-Time-series-Anomaly-Detection (accessed on 8 January 2025).
- Provotar, O.I.; Linder, Y.M.; Veres, M.M. Unsupervised Anomaly Detection in Time Series Using LSTM-Based Autoencoders. In Proceedings of the 2019 IEEE International Conference on Advanced Trends in Information Theory (ATIT), Kyiv, Ukraine, 18–20 December 2019; pp. 513–517. [Google Scholar] [CrossRef]
- Ergen, T.; Kozat, S.S. Unsupervised Anomaly Detection With LSTM Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 31, 3127–3141. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.; Clark, R.; Birke, R.; Schönborn, S.; Trigoni, N.; Roberts, S. Anomaly Detection for Time Series Using VAE-LSTM Hybrid Model. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4322–4326. [Google Scholar] [CrossRef]
- Park, P.; Di Marco, P.; Shin, H.; Bang, J. Fault Detection And Diagnosis Using Combined Autoencoder And Long Short-Term Memory Network. Sensors 2019, 19, 4612. [Google Scholar] [CrossRef] [PubMed]
- Kong, F.; Li, J.; Jiang, B.; Wang, H.; Song, H. Integrated Generative Model for Industrial Anomaly Detection Via Bidirectional LSTM and Attention Mechanism. IEEE Trans. Ind. Inform. 2023, 19, 541–550. [Google Scholar] [CrossRef]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 387–395. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, T.; Tang, Y.; Huang, L. Enhanced KPI Anomaly Detection: An Unsupervised Hybrid Model with Dynamic Threshold. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 7140–7144. [Google Scholar] [CrossRef]
- Wen, X.; Li, W. Time Series Prediction Based on LSTM-Attention-LSTM Model. IEEE Access 2023, 11, 48322–48331. [Google Scholar] [CrossRef]
- Huang, J.; Kong, L.; Chen, G.; Wu, M.Y.; Liu, X.; Zeng, P. Towards Secure Industrial IoT: Blockchain System with Credit-Based Consensus Mechanism. IEEE Trans. Ind. Inform. 2019, 15, 3680–3689. [Google Scholar] [CrossRef]
- Miao, Y.; Zhou, M.; Ghoneim, A. Blockchain and AI-Based Natural Gas Industrial IoT System: Architecture and Design Issues. IEEE Netw. 2020, 34, 76–83. [Google Scholar] [CrossRef]
- Alabadi, M.; Habbal, A. Next-generation Predictive Maintenance: Leveraging Blockchain and Dynamic Deep Learning in A Domain-independent System. PeerJ Comput. Sci. 2023, 9, e1364. [Google Scholar] [CrossRef] [PubMed]
- Ismail, S.S.; Dandan, S.; Dawoud, D.W.; Reza, H. A Comparative Study of Lightweight Machine Learning Techniques for Cyber-Attacks Detection in Blockchain-Enabled Industrial Supply Chain. IEEE Access 2024, 12, 60276–60298. [Google Scholar] [CrossRef]
- Li, Y.; Huang, J.; Qin, S.; Wang, R. Big Data Model of Security Sharing Based on Blockchain. In Proceedings of the 2017 2nd International Conference on Big Data Technologies (ICBDT), Chengdu, China, 10–11 August 2017; pp. 98–102. [Google Scholar] [CrossRef]
- Griggs, K.N.; Ossipova, O.; Kohlios, C.P.; Baccarini, A.N.; Howson, E.A.; Hayajneh, T. Healthcare Blockchain System Using Smart Contracts For Secure Automated Remote Patient Monitoring. J. Med. Syst. 2018, 42, 130. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Jia, T.; Jia, M.; Liu, H.; Yang, Y.; Wu, Z.; Li, Y. Towards Close-To-Zero Runtime Collection Overhead: Raft-Based Anomaly Diagnosis on System Faults for Distributed Storage System. IEEE Trans. Serv. Comput. 2024, 18, 1054–1067. [Google Scholar] [CrossRef]
- Zhang, L.; Jia, T.; Jia, M.; Wu, Y.; Liu, H.; Li, Y. ScalaLog: Scalable Log-Based Failure Diagnosis Using LLM. In Proceedings of the ICASSP 2025—2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; pp. 1–5. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- FISCO BCOS Community. FISCO BCOS: A High-Performance Consortium Blockchain Platform. 2019. Available online: https://www.fisco.com.cn (accessed on 5 July 2025).
- Keogh, E.; Lin, J.; Fu, A. HOT SAX: Efficiently finding the most unusual time series subsequence. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; p. 8. [Google Scholar] [CrossRef]
- Bergmann, P.; Batzner, K.; Fauser, M.; Sattlegger, B.; Steger, C. The MVTec Anomaly Detection Dataset: A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. Int. J. Comput. Vis. 2021, 129, 1038–1059. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}