MFPI-Net: A Multi-Scale Feature Perception and Interaction Network for Semantic Segmentation of Urban Remote Sensing Images

 , and
, and
Abstract
1. Introduction
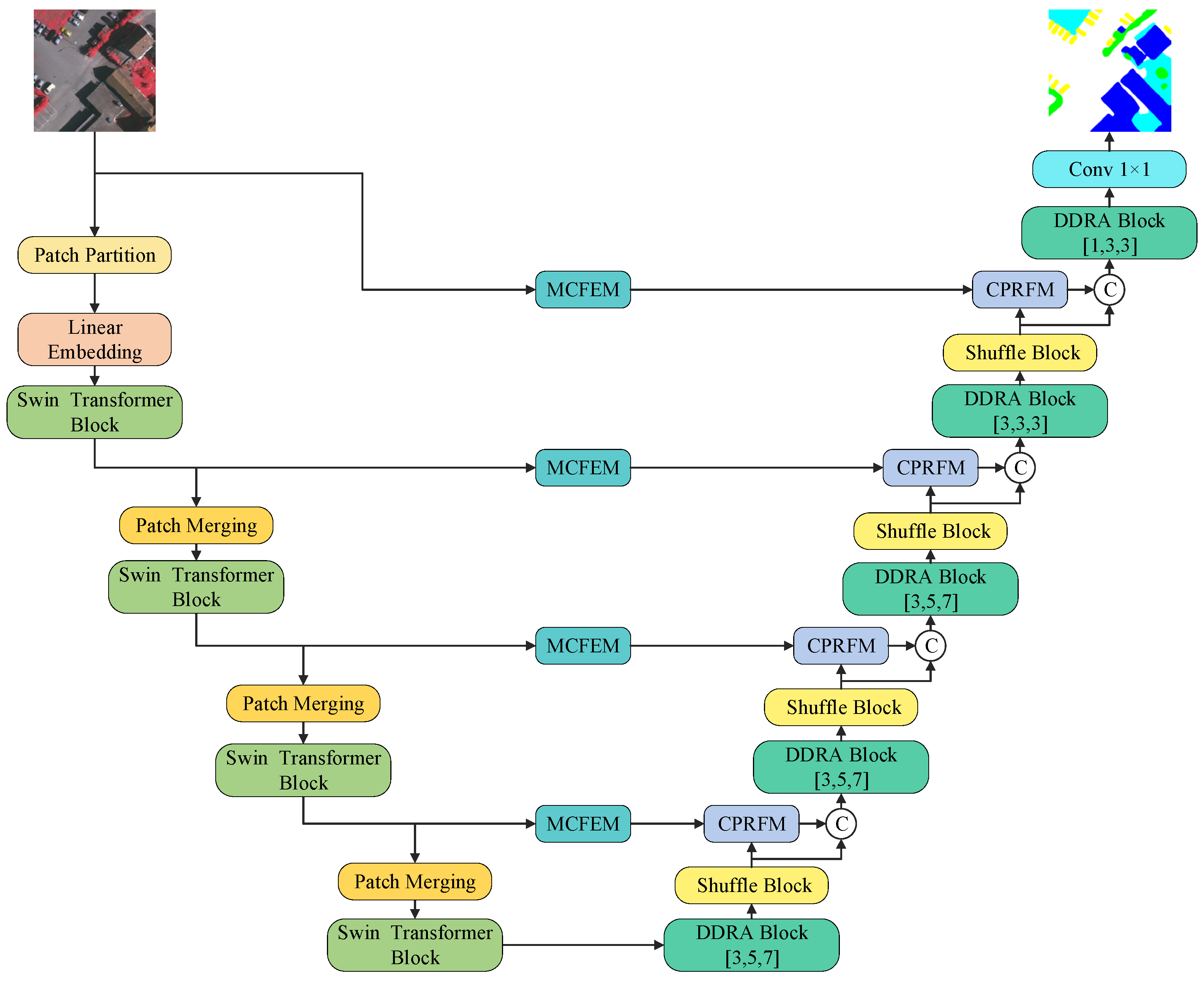
- We adopt the Swin Transformer as the encoder backbone [13], leveraging its hierarchical structure and shifted window self-attention mechanism to effectively model spatial dependencies and contextual relationships of complex targets in urban remote sensing images, while maintaining high computational efficiency. The Swin Transformer extracts and compresses image features layer by layer, generates multi-level, globally consistent semantic representations, and provides strong expressive feature support for subsequent modules, thereby significantly improving the model’s structural modeling capabilities and segmentation performance in complex remote sensing scenes.
- We designed the DDRASD consisting of the DDRA Block and the Shuffle Block to efficiently decode semantic information from multi-scale feature maps. Specifically, the DDRA Block obtains information from multiple scales and a wide range of contexts for decoding through different dilation rates, while introducing channel and coordinate attention mechanisms to enhance feature representation and improve the model’s ability to detect and segment objects of different sizes. The Shuffle Block achieves resolution improvement by rearranging the pixels of the input feature map to avoid the checkerboard artifacts that may be caused by traditional deconvolution.
- We conceived the CNN-based MCFEM to enhance the modeling capability of multi-scale targets in remote sensing images. This module constructs parallel branches through different convolution kernels to perceive spatial context information from fine-grained to large-scale. The MCFEM is integrated into the network input stage and the jump connection path of the encoder, introducing local spatial structure and multi-scale details, effectively making up for the shortcomings of Swin Transformer in edge details and local texture modeling, achieving efficient fusion of spatial details and global semantic information, and improving overall segmentation performance.
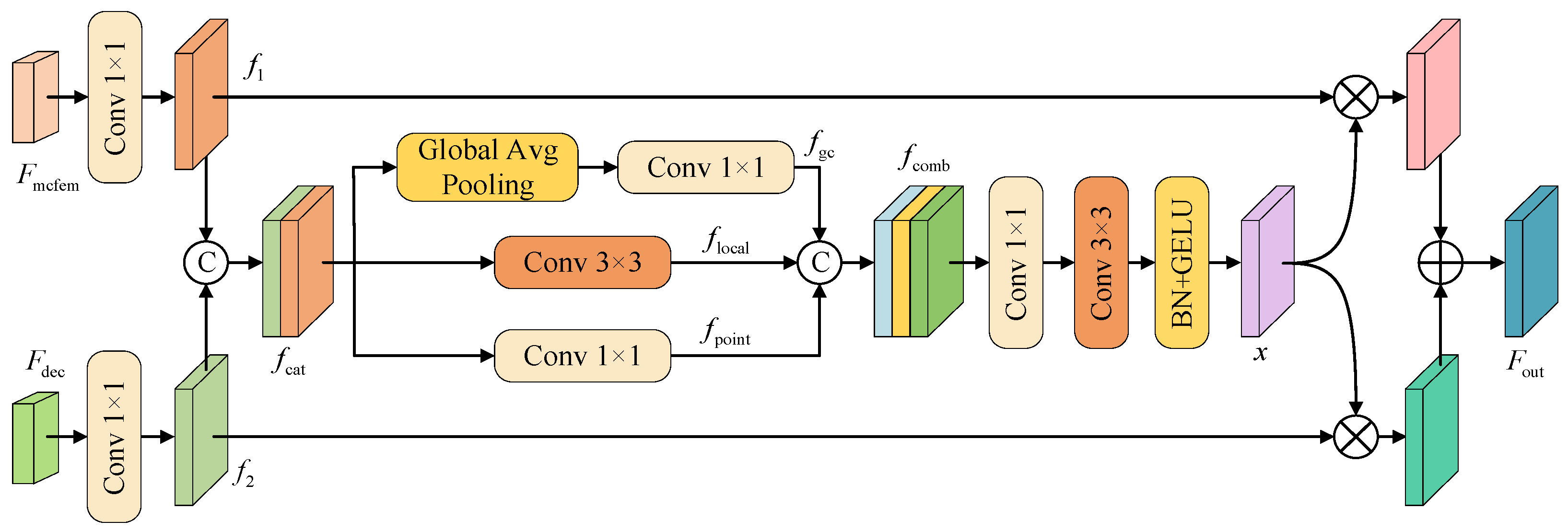
- We designed the CPRFM to efficiently integrate feature information from different network layers. We constructed a multi-branch feature path through global context, local convolution, and point convolution to extract multi-scale information. In the fusion stage, we adopted a feature-enhanced residual multiplication and addition mechanism to effectively strengthen the complementary relationship and distinguishing ability between different features, achieve more delicate feature interaction and information integration, and effectively improve the recognition ability of subtle targets and similar categories in complex environments.
2. Related Work
2.1. Semantic Segmentation Methods
2.2. Structural Optimization Strategy and Feature Enhancement Module
2.3. Deficiencies of Existing Methods and Research Motivation
3. Methodology
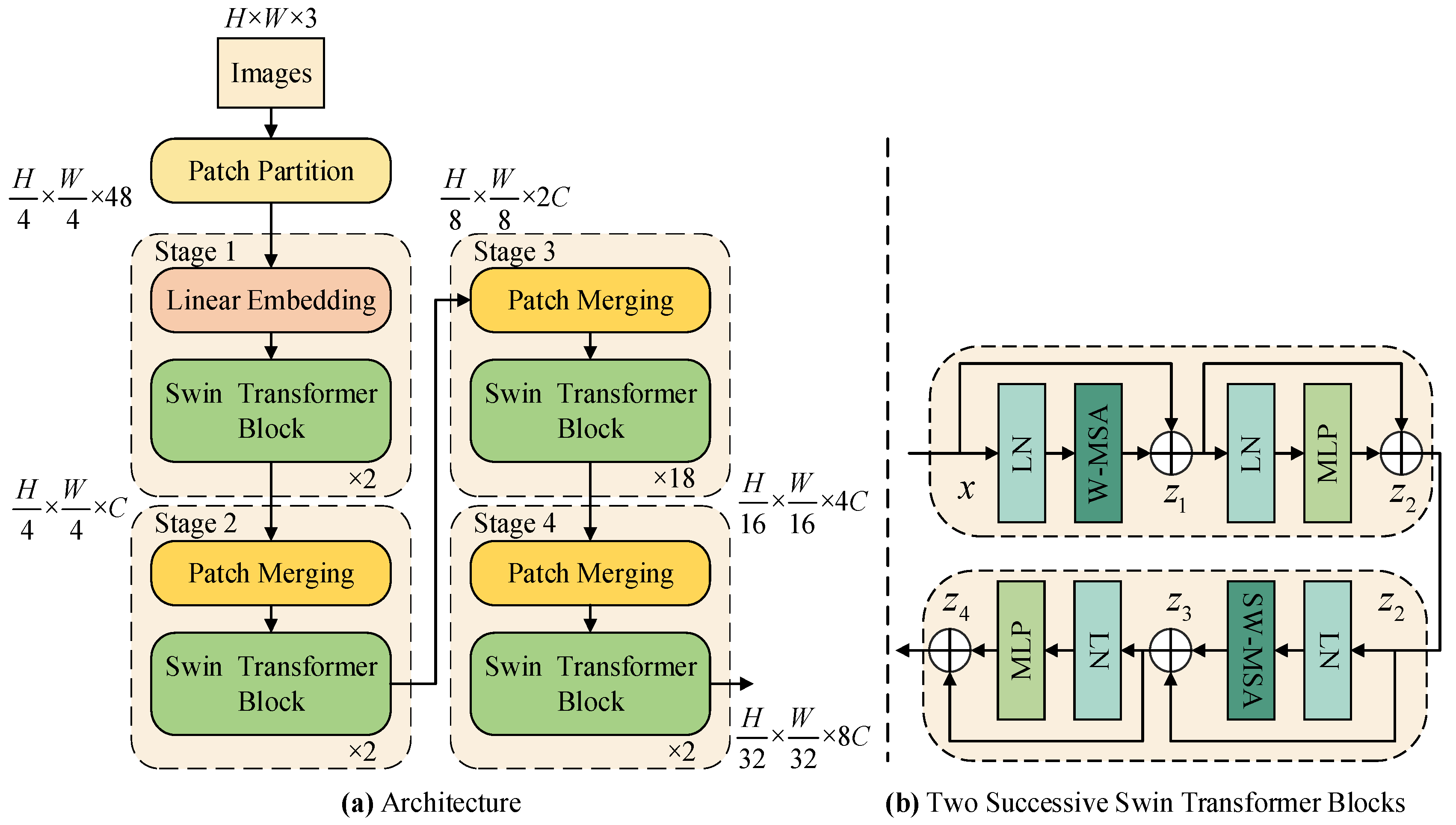
3.1. Swin Transformer Encoder
- (1)
- Patch Embedding: The Patch Embedding layer is responsible for converting the input image into a feature sequence suitable for Transformer processing, which includes two key steps: Patch Partition and Linear Embedding. First, Patch Partition divides the original RGB image into non-overlapping 4 × 4 pixel blocks (patches). Each block is flattened into a vector of length 4 × 4 × 3 = 48, which is equivalent to splitting the image into patch tokens. Next, Linear Embedding projects each patch vector to the specified dimension through a fully connected layer. For example, the embedding dimension of Stage 1 in Swin-B is 128, forming a feature matrix of dimension . This step is similar to “breaking” the image into feature blocks and giving each block a semantic representation suitable for deep network processing.
- (2)
- Swin Transformer encoder block: The Swin Transformer encoder block is the core component for modeling image context information. By introducing a shift window strategy, SW-MSA enables information interaction between different windows, thereby enhancing the expressiveness of the model while maintaining a low computational cost. Each encoder block consists of a W-MSA or SW-MSA module and a multi-layer feedforward neural network (MLP), combined with layer normalization and residual connections, ensuring the stability of deep network training and excellent performance.
- (3)
- Patch Merging: The Patch Merging layer is used to reduce the spatial resolution of feature maps between layers and increase the channel dimension to achieve hierarchical modeling. Specifically, it first splices adjacent 2 × 2 patches to form a new patch. If the input feature map size is H × W and the number of channels is C, each 2 × 2 area is flattened into a vector of length 4C and reduced to 2C dimensions through linear mapping to achieve spatial downsampling and channel expansion. This operation retains key information while compressing the amount of computation, which helps capture image semantics at different scales.
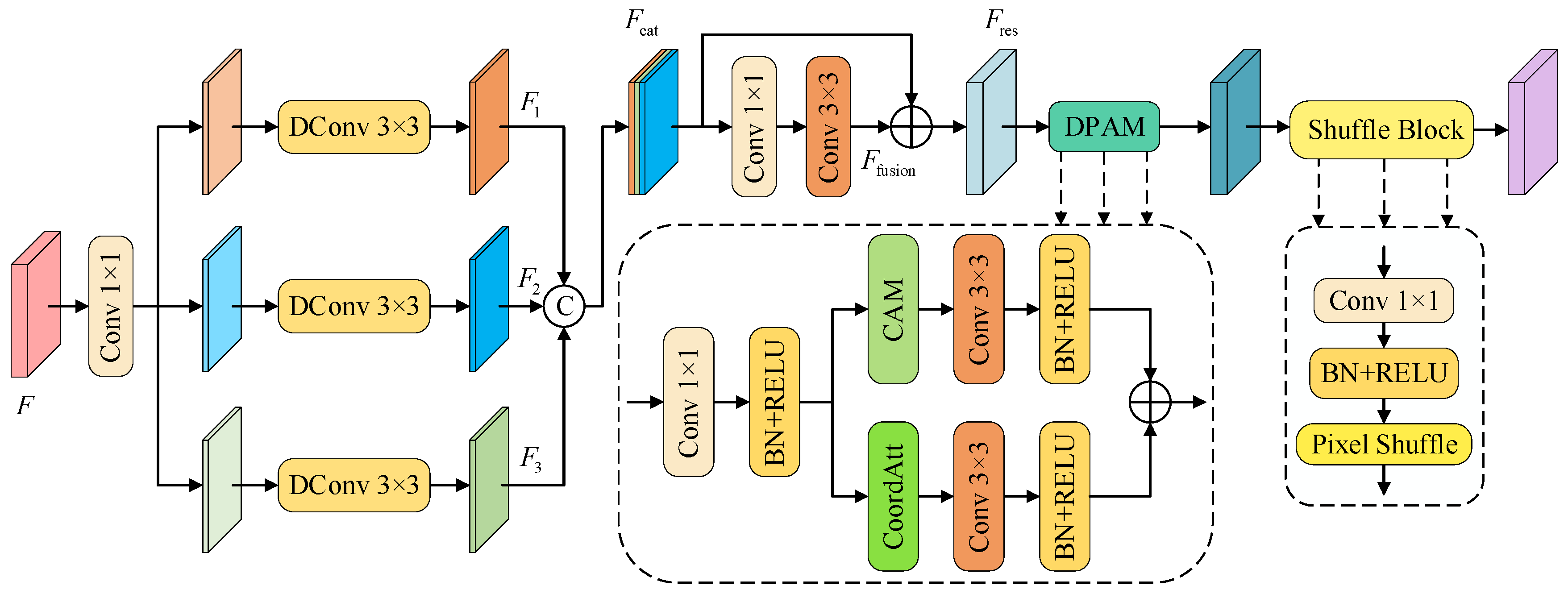
3.2. Diverse Dilation Rates Attention Shuffle Decoder
- (1)
- DDRA Block: The DDRA Block is a structural reconstruction module designed for the decoder stage. It integrates multi-scale feature analysis, residual information guidance, and dual-path attention enhancement. The goal is to strengthen semantic understanding and structural perception, enhance the response strength of target regions, and achieve accurate restoration and detailed reconstruction in complex scenes. The module adopts a strategy that combines convolutional path extraction with diverse dilation rates, multi-level feature fusion, and attention-guided optimization. A total of five DDRA Blocks are deployed in the decoder. These modules construct appropriate receptive field structures by setting different dilation rates, thereby enabling the fine-grained modeling of features at different semantic levels. The first three modules employ convolutional paths with diverse dilation rates, using receptive field configurations of [3,5,7], and adopt a progressively increasing dilation strategy to capture multi-scale contextual information and enhance the semantic representation of deep features. The fourth module uses a uniform dilation configuration of [3] to form a standard receptive field structure, focusing on extracting local details from shallow features. The fifth module adopts a receptive field configuration of [1,3] to effectively integrate deep semantic and shallow spatial information, thereby improving segmentation accuracy and the structural restoration of small-object boundaries.
- (2)
- Shuffle Block: The Shuffle Block uses the Pixel Shuffle mechanism to achieve 2× spatial upsampling. First, a 1 × 1 convolution is used to expand the number of channels of the input feature to 4 times the number of target channels to meet the channel reconstruction requirements of Pixel Shuffle. Subsequently, Batch Normalization and ReLU activation functions are introduced to standardize and nonlinearly map the convolution output to enhance the feature expression capability. Finally, the Pixel Shuffle operation is used to effectively rearrange the channel dimension to the spatial dimension. The Shuffle Block ultimately achieves a 2× expansion of the feature map spatial size and a compression of the number of channels to half of the original, significantly improving the spatial resolution of the feature map and avoiding the checkerboard artifacts that are easily generated by traditional deconvolution methods. This module does not require the introduction of additional parameters, has high computational efficiency, and helps to preserve structural information and improve upsampling quality. In the network structure, a total of four Shuffle Blocks are designed, which are placed after the first four DDRA Blocks, gradually restore the spatial resolution of the feature map, and achieve multi-level feature detail enhancement.
3.3. Multi-Scale Convolutional Feature Enhancement Module
3.4. Cross-Path Residual Fusion Module
3.5. Loss Function
4. Experimental Settings and Datasets
4.1. Datasets
- (1)
- ISPRS Vaihingen: The ISPRS Vaihingen dataset is a standard remote sensing image semantic segmentation benchmark dataset released by the International Society for Photogrammetry and Remote Sensing (ISPRS). It is widely used in pixel-level object classification research in urban scenes. The dataset contains 33 high-resolution images, including five categories: impervious surface, building, low vegetation, tree, and car, as well as a cluttered background category. Due to the high resolution of the original images, in order to adapt to the video memory and computing limitations during model training, we use a sliding window strategy to crop them into small tiles of 512 × 512 pixels. On this basis, in order to enhance the diversity of image directions and improve the model’s learning ability and robustness for target features in different directions, the image is randomly flipped horizontally or vertically with a probability of 0.5. In addition, in order to enhance the model’s adaptability under various lighting conditions, a photometric distortion operation is introduced, including random adjustments to the image’s brightness, contrast, saturation, and hue, thereby simulating a complex lighting environment. The dataset is randomly divided into a training set, a validation set, and a test set in a ratio of 8:1:1, and finally 6820 training images, 852 validation images, and 852 test images are obtained.
- (2)
- ISPRS Potsdam: The ISPRS Potsdam dataset is another standard benchmark dataset released by ISPRS and widely used in remote sensing image semantic segmentation tasks. It is mainly used to evaluate the pixel-level classification performance of models in high-resolution urban remote sensing scenes. This dataset contains 38 high-resolution images, and the categories are consistent with the Vaihingen dataset, including five categories: impervious surface, building, low vegetation, tree, car, and cluttered background. For the processing of this dataset, we also used the sliding window strategy to crop the original image into small tiles of 512 × 512 pixels, and used the same data augmentation strategy to improve the robustness and generalization ability of the model. The dataset was randomly divided into training set, validation set and test set in a ratio of 8:1:1, and finally 12,696 training images, 1587 validation images, and 1587 test images were obtained.
4.2. Experimental Environment and Parameter Configuration
4.3. Evaluation Metrics
5. Experimental Results and Analysis
5.1. Comparative Experimental Design and Results Analysis
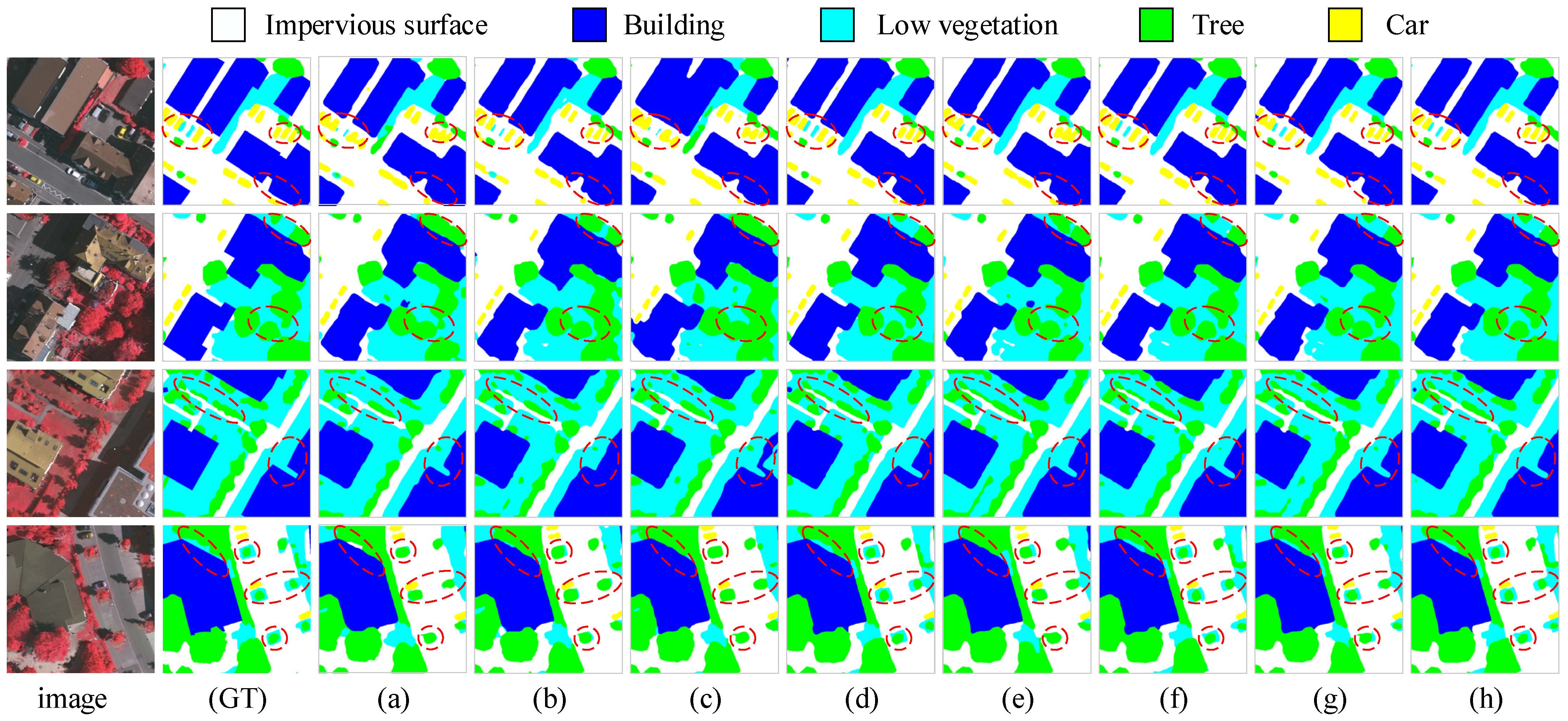
5.1.1. Comparative Analysis on the Vaihingen Dataset
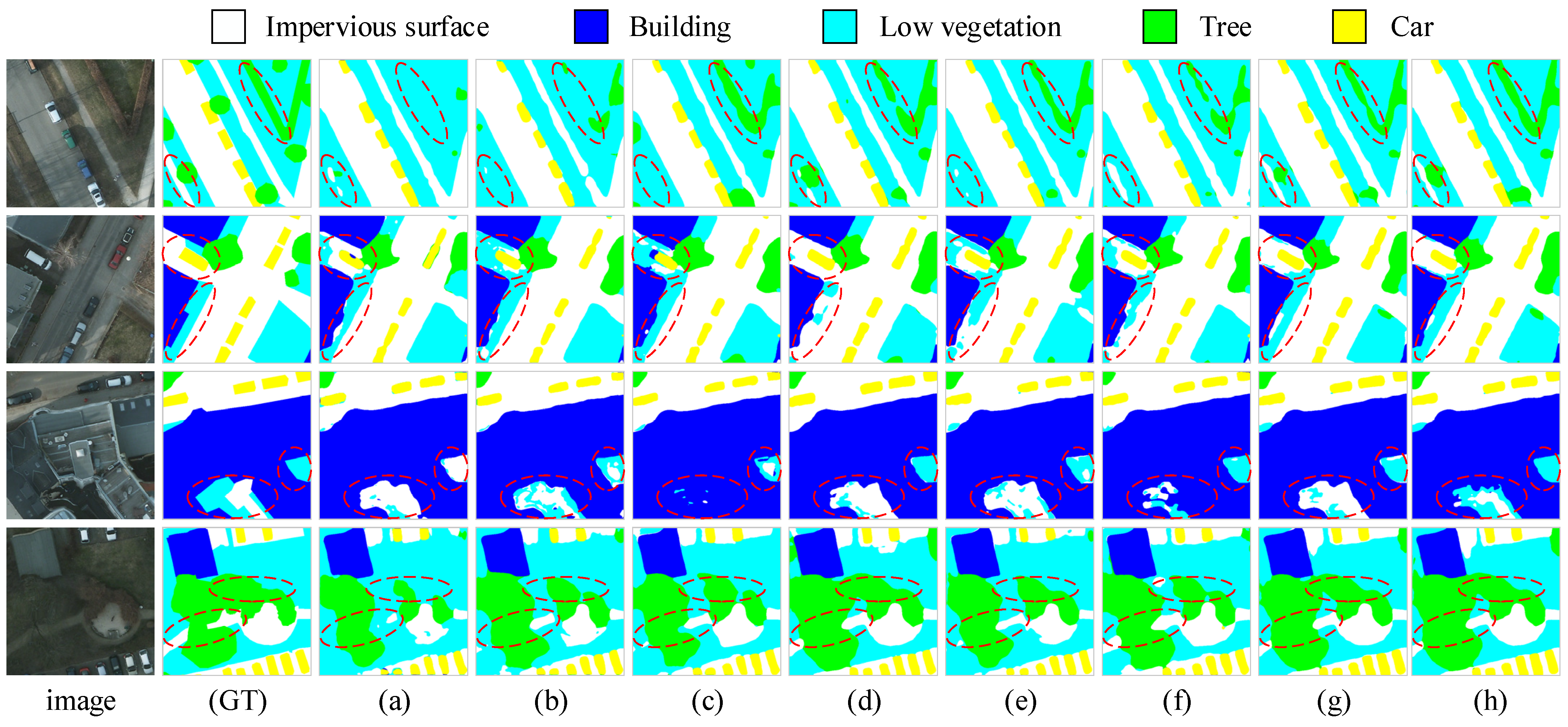
5.1.2. Comparative Analysis on the Potsdam Dataset
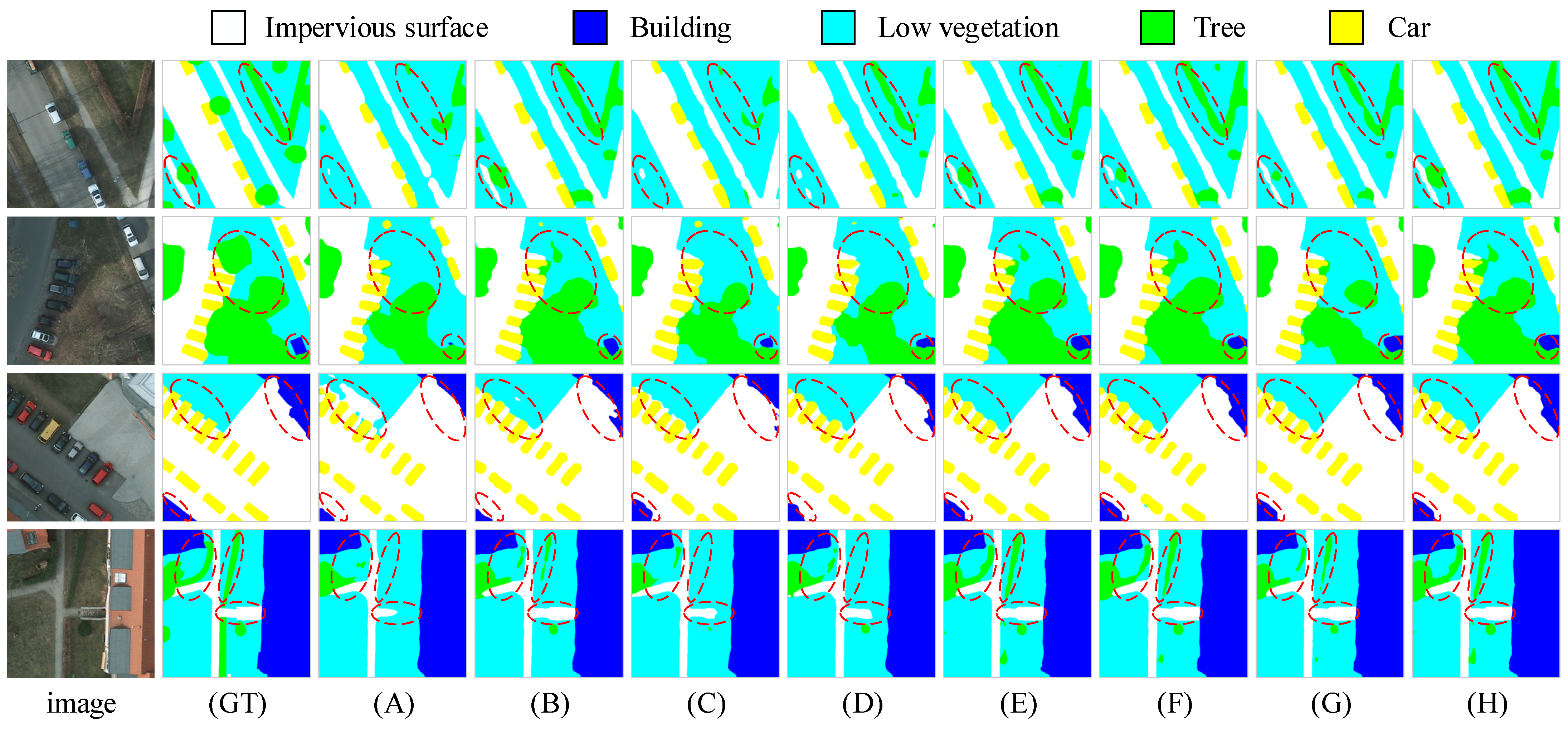
5.2. Ablation Experiment Design and Results Analysis
5.3. The Impact of Different Scale Swin Transformer Backbones on Model Performance
5.4. Training Process and Confusion Matrix Visualization Analysis
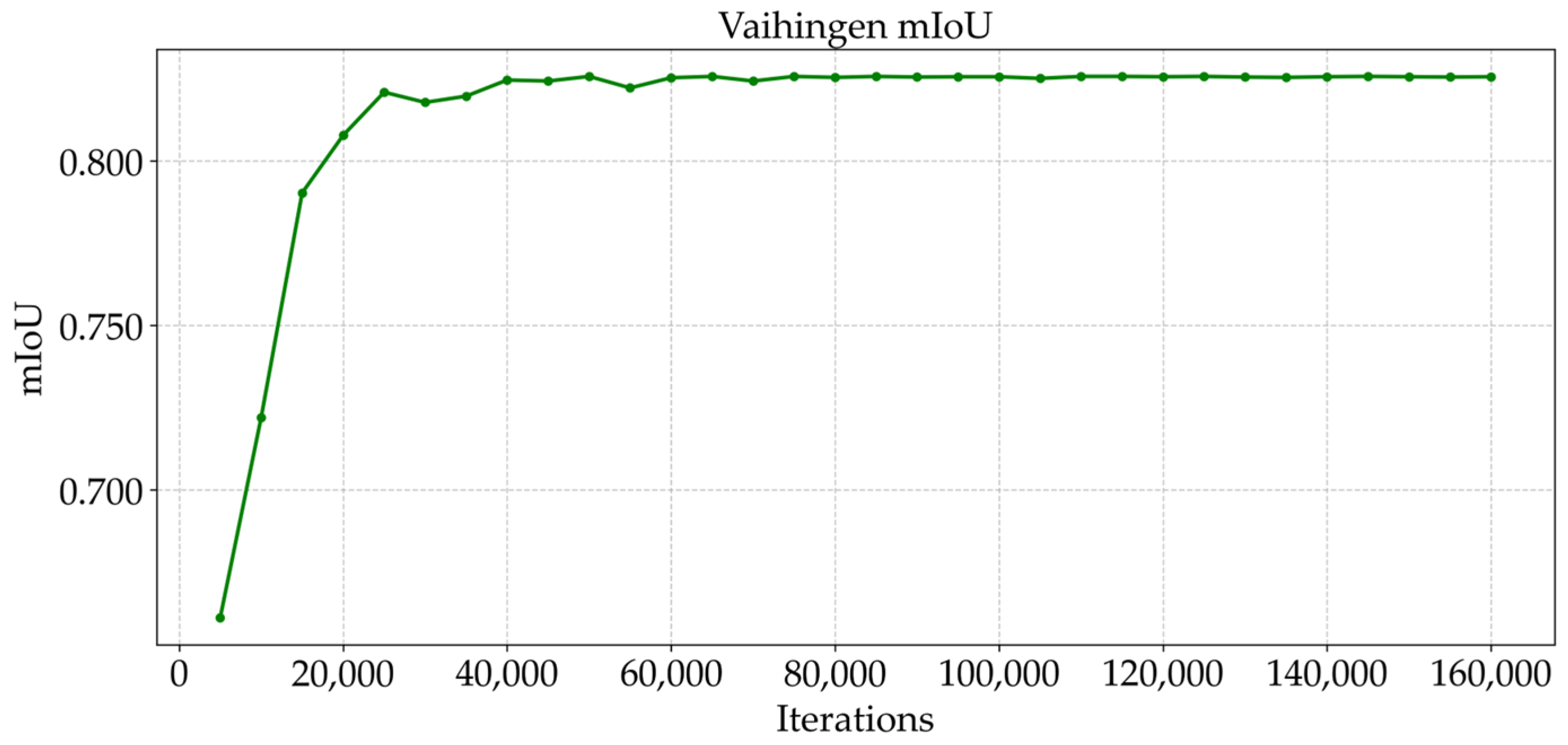
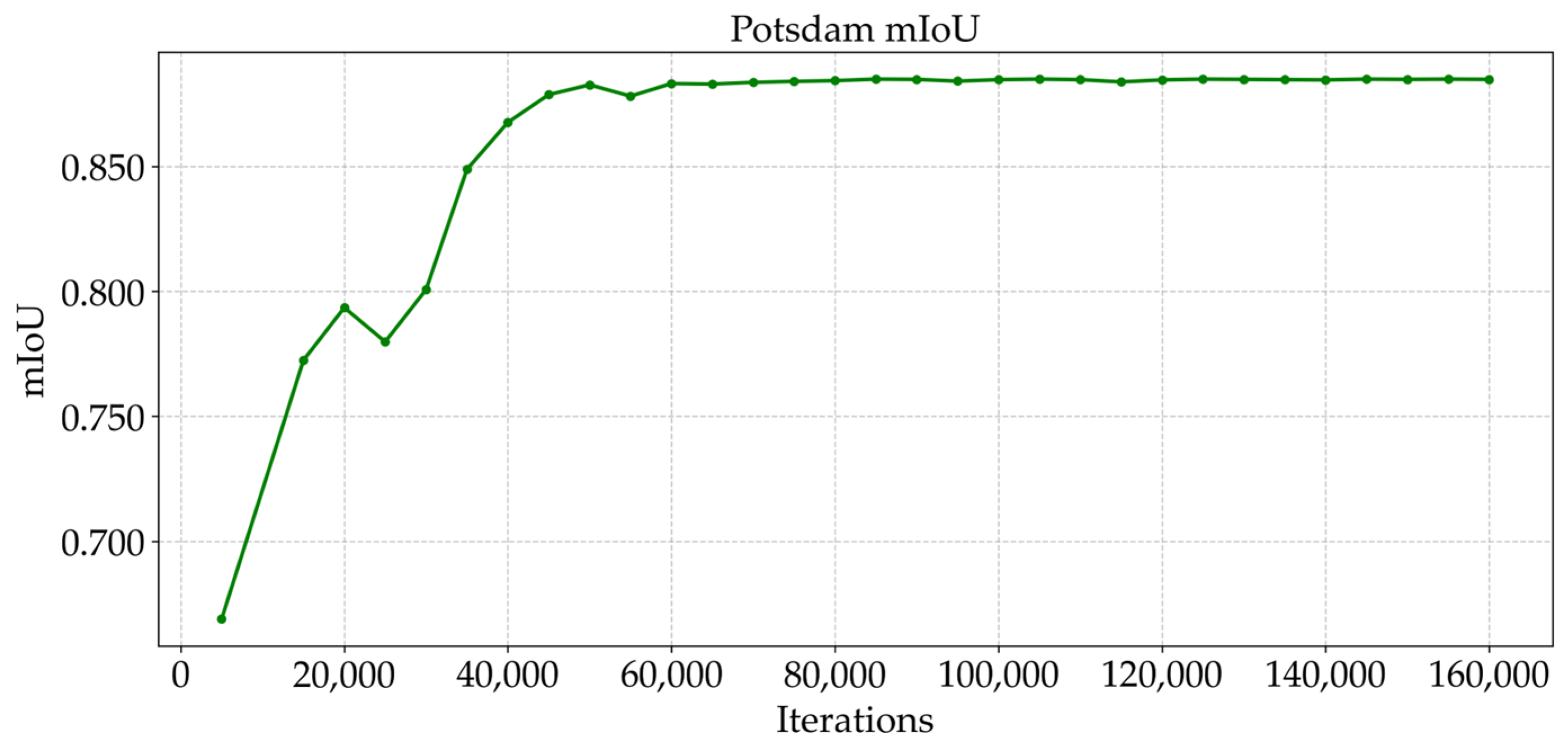
5.4.1. Visual Analysis of the Training Process
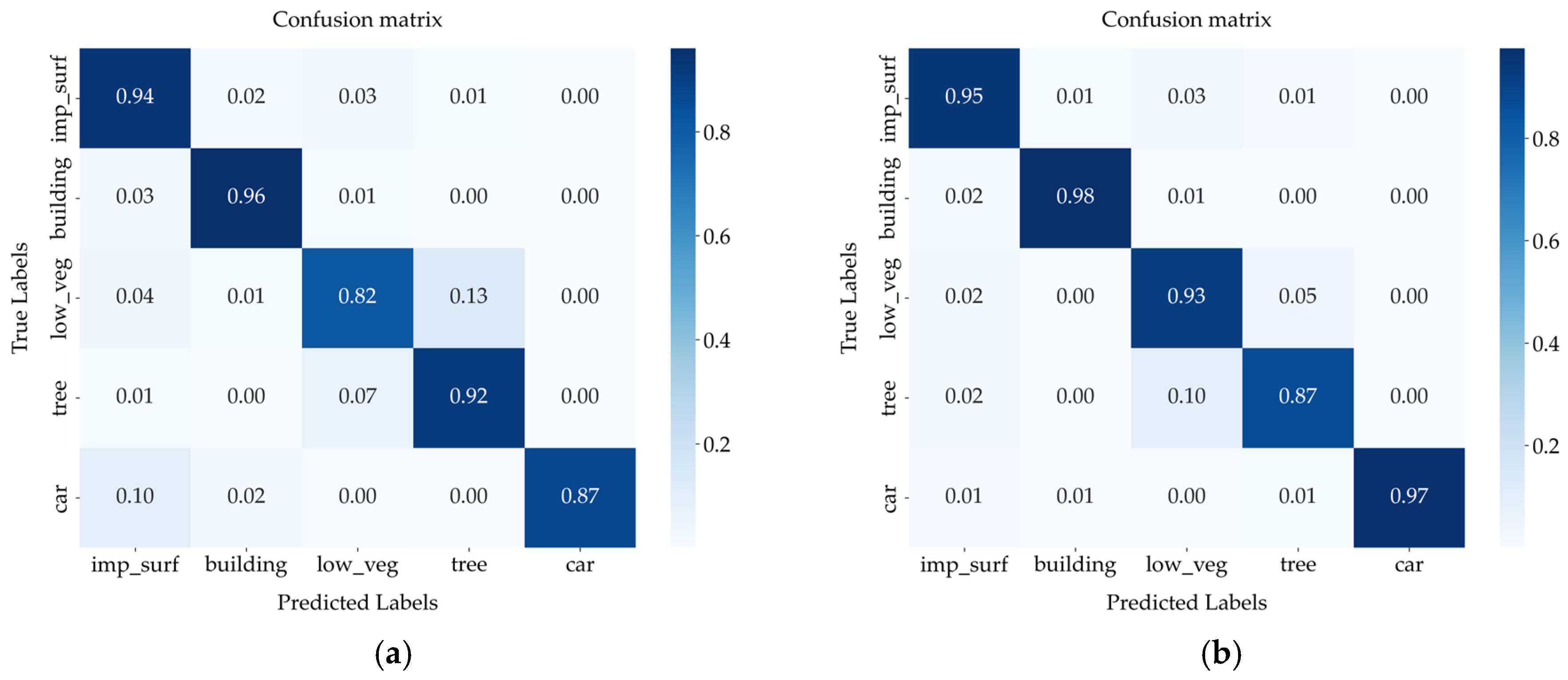
5.4.2. Confusion Matrix Visualization Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, P.; Chen, C.; Zhang, D.; Sang, Y.; Zhang, L. Semantic segmentation of deep learning remote sensing images based on band combination principle: Application in urban planning and land use. Comput. Commun. 2024, 217, 97–106. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A Fully Convolutional Neural Network for Automatic Building Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-Cover Classification with High-Resolution Remote Sensing Images Using Transferable Deep Models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Fan, Z.; Zhan, T.; Gao, Z.; Li, R.; Liu, Y.; Zhang, L.; Jin, Z.; Xu, S. Land cover classification of resources survey remote sensing images based on segmentation model. IEEE Access 2022, 10, 56267–56281. [Google Scholar] [CrossRef]
- Wang, R.; Sun, Y.; Zong, J.; Wang, Y.; Cao, X.; Wang, Y.; Cheng, X.; Zhang, W. Remote sensing application in ecological restoration monitoring: A systematic review. Remote Sens. 2024, 16, 2204. [Google Scholar] [CrossRef]
- Khan, S.D.; Basalamah, S. Multi-Scale and Context-Aware Framework for Flood Segmentation in Post-Disaster High Resolution Aerial Images. Remote Sens. 2023, 15, 2208. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Wang, G.; Zhai, Q.; Lin, J. Multi-Scale Network for Remote Sensing Segmentation. IET Image Process. 2022, 16, 1742–1751. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing swin transformer and convolutional neural network for remote sensing image semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Li, Y.; Wu, G. Multi-Scale Feature Fusion and Global Context Modeling for Fine-Grained Remote Sensing Image Segmentation. Appl. Sci. 2025, 15, 5542. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, C.; Li, R.; Duan, C.; Meng, X.; Atkinson, P.M. Scale-Aware Neural Network for Semantic Segmentation of Multi-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 5015. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. arXiv 2021, arXiv:2101.01169. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408820. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, L.; Yang, R.; Chen, N.; Zhao, Y.; Dai, Q. Semantic Segmentation of High Spatial Resolution Remote Sensing Imagery Based on Weighted Attention U-Net. In Proceedings of the Fourteenth International Conference on Graphics and Image Processing (ICGIP 2022), Nanjing, China, 27 June 2023; Xiao, L., Xue, J., Eds.; SPIE: Bellingham, WA, USA, 2023; p. 107. [Google Scholar]
- Zhang, X.; Chen, M.; Liu, F.; Li, S.; Rao, J.; Song, X. MSSSHANet: Hyperspectral and Multispectral Image Fusion Algorithm Based on Multi-Scale Spatial-Spectral Hybrid Attention Network. Meas. Sci. Technol. 2025, 36, 035407. [Google Scholar] [CrossRef]
- Chen, H.; Chen, M.; Li, H.; Peng, H.; Su, Q. Feature Fusion Image Dehazing Network Based on Hybrid Parallel Attention. Electronics 2024, 13, 3438. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical image computing and computer-assisted intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Kumari, M.; Kaul, A. Deep learning techniques for remote sensing image scene classification: A comprehensive review, current challenges, and future directions. Concurr. Comput. Pract. Exp. 2023, 35, e7733. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-Like Pure Transformer for Medical Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Cham, Switzerland, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Liu, Y.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Xiao, T.; Liu, Y.; Huang, Y.; Li, M.; Yang, G. Enhancing multiscale representations with transformer for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605116. [Google Scholar] [CrossRef]
- Zhang, L.; Tan, Z.; Zhang, G.; Zhang, W.; Li, Z. Learn more and learn useful: Truncation Compensation Network for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4403814. [Google Scholar]
- Ding, R.X.; Xu, Y.H.; Liu, J.; Zhou, W.; Chen, C. LSENet: Local and Spatial Enhancement to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 7506005. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A Novel Transformer Based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Zhou, H.; Yang, J.; Zhang, T.; Dai, A.; Wu, C. EAS-CNN: Automatic Design of Convolutional Neural Network for Remote Sensing Images Semantic Segmentation. Int. J. Remote Sens. 2023, 44, 3911–3938. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13708–13717. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607713. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Yao, M.; Zhang, Y.; Liu, G.; Pang, D. SSNet: A Novel Transformer and CNN Hybrid Network for Remote Sensing Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3023–3037. [Google Scholar] [CrossRef]
- Zheng, J. ConvNeXt-Mask2Former: A Semantic Segmentation Model for Land Classification in Remote Sensing Images. In Proceedings of the 5th International Conference on Computer Vision, Image and Deep Learning (CVIDL), Zhuhai, China, 19–21 April 2024; pp. 676–682. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Class IoU% | mIoU % | mF1 % | OA % | ||||
|---|---|---|---|---|---|---|---|---|
| Impervious Surface | Building | Low Vegetation | Tree | Car | ||||
| UNet | 79.49 | 90.59 | 69.78 | 77.42 | 72.38 | 77.93 | 87.42 | 88.46 |
| DeepLabV3+ | 80.22 | 90.95 | 70.34 | 76.83 | 76.51 | 78.97 | 88.09 | 88.66 |
| TransUNet | 81.83 | 89.26 | 68.27 | 77.42 | 72.99 | 77.95 | 87.43 | 88.29 |
| DC-Swin | 87.60 | 93.26 | 72.59 | 80.27 | 76.31 | 82.01 | 89.93 | 91.17 |
| EAS-CNN | 87.51 | 92.94 | 71.22 | 79.63 | 72.70 | 80.80 | 89.15 | 90.83 |
| SSNet | 86.99 | 92.57 | 71.88 | 79.91 | 74.67 | 81.20 | 89.43 | 90.81 |
| ConvNext-Mask2Former | 87.41 | 93.36 | 71.86 | 79.68 | 75.31 | 81.53 | 89.62 | 90.95 |
| MFPI-Net | 87.76 | 93.29 | 72.71 | 80.28 | 78.81 | 82.57 | 90.28 | 91.23 |
| Method | Class IoU% | mIoU % | mF1 % | OA % | ||||
|---|---|---|---|---|---|---|---|---|
| Impervious Surface | Building | Low Vegetation | Tree | Car | ||||
| UNet | 84.04 | 93.02 | 62.97 | 52.29 | 83.03 | 75.07 | 84.88 | 85.67 |
| DeepLabV3+ | 86.38 | 92.08 | 73.35 | 72.37 | 82.79 | 81.39 | 89.55 | 90.11 |
| TransUNet | 85.29 | 87.22 | 71.64 | 74.18 | 85.24 | 80.71 | 89.18 | 89.24 |
| DC-Swin | 90.17 | 95.53 | 79.31 | 79.09 | 91.82 | 87.19 | 93.01 | 93.05 |
| EAS-CNN | 87.12 | 94.32 | 74.74 | 76.20 | 90.53 | 84.58 | 91.45 | 91.25 |
| SSNet | 88.03 | 94.01 | 76.18 | 74.17 | 88.10 | 84.10 | 91.17 | 91.43 |
| ConvNext-Mask2Former | 89.97 | 95.34 | 78.84 | 77.36 | 92.07 | 86.72 | 92.72 | 92.71 |
| MFPI-Net | 90.92 | 96.03 | 80.93 | 80.55 | 94.02 | 88.49 | 93.77 | 93.64 |
| Model Name | Modules | mIoU % | mF1 % | OA % | ||
|---|---|---|---|---|---|---|
| DDRASD | MCFEM | CPRFM | ||||
| A | × | × | × | 81.66 | 89.71 | 89.99 |
| B | √ | × | × | 85.51 | 92.00 | 92.01 |
| C | × | √ | × | 83.44 | 90.69 | 90.81 |
| D | × | × | √ | 82.94 | 90.44 | 90.46 |
| E | √ | √ | × | 87.88 | 93.41 | 93.35 |
| F | √ | × | √ | 87.76 | 93.34 | 93.22 |
| G | × | √ | √ | 85.43 | 91.87 | 92.04 |
| H | √ | √ | √ | 88.49 | 93.77 | 93.64 |
| Network | Block Number | Channel Number | Heads |
|---|---|---|---|
| Swin-T | (2, 2, 6, 2) | 96 | (3, 6, 12, 24) |
| Swin-S | (2, 2, 18, 2) | 96 | (3, 6, 12, 24) |
| Swin-B | (2, 2, 18, 2) | 128 | (4, 8, 16, 32) |
| Network | Vaihingen | Potsdam | ||||
|---|---|---|---|---|---|---|
| mIoU% | mF1% | OA% | mIoU% | mF1% | OA% | |
| Swin-T | 79.73 | 88.58 | 89.08 | 85.51 | 92.01 | 91.89 |
| Swin-S | 81.98 | 89.92 | 90.83 | 87.88 | 93.41 | 93.29 |
| Swin-B | 82.57 | 90.28 | 91.23 | 88.49 | 93.77 | 93.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, X.; Chen, M.; Rao, J.; Luo, Y.; Lin, Z.; Zhang, X.; Li, S.; Hu, X. MFPI-Net: A Multi-Scale Feature Perception and Interaction Network for Semantic Segmentation of Urban Remote Sensing Images. Sensors 2025, 25, 4660. https://doi.org/10.3390/s25154660
Song X, Chen M, Rao J, Luo Y, Lin Z, Zhang X, Li S, Hu X. MFPI-Net: A Multi-Scale Feature Perception and Interaction Network for Semantic Segmentation of Urban Remote Sensing Images. Sensors. 2025; 25(15):4660. https://doi.org/10.3390/s25154660
Chicago/Turabian StyleSong, Xiaofei, Mingju Chen, Jie Rao, Yangming Luo, Zhihao Lin, Xingyue Zhang, Senyuan Li, and Xiao Hu. 2025. "MFPI-Net: A Multi-Scale Feature Perception and Interaction Network for Semantic Segmentation of Urban Remote Sensing Images" Sensors 25, no. 15: 4660. https://doi.org/10.3390/s25154660
APA StyleSong, X., Chen, M., Rao, J., Luo, Y., Lin, Z., Zhang, X., Li, S., & Hu, X. (2025). MFPI-Net: A Multi-Scale Feature Perception and Interaction Network for Semantic Segmentation of Urban Remote Sensing Images. Sensors, 25(15), 4660. https://doi.org/10.3390/s25154660