
Image Alignment Based on Deep Learning to Extract Deep Feature Information from Images



Abstract

1. Introduction
- It proposes an image alignment method based on deep learning to extract deep feature information from images, aiming to fully leverage the global information in both infrared and visible light images to extract key features in the middle and upper layers effectively.
- It designs a spatial information fusion module (SFM) that integrates spatial pyramid pooling technology to extract deep key features with high stability and strong discriminative power.
- A feature weight adaptive adjustment mechanism is designed to dynamically adjust weight coefficients based on the stability and discriminative power of features, thereby highlighting the representational capabilities of key features.
2. Related Work
2.1. Region-Based Image Alignment Method
2.2. Feature-Based Image Alignment Method
2.3. Deep Learning-Based Image Alignment Method
3. Methods
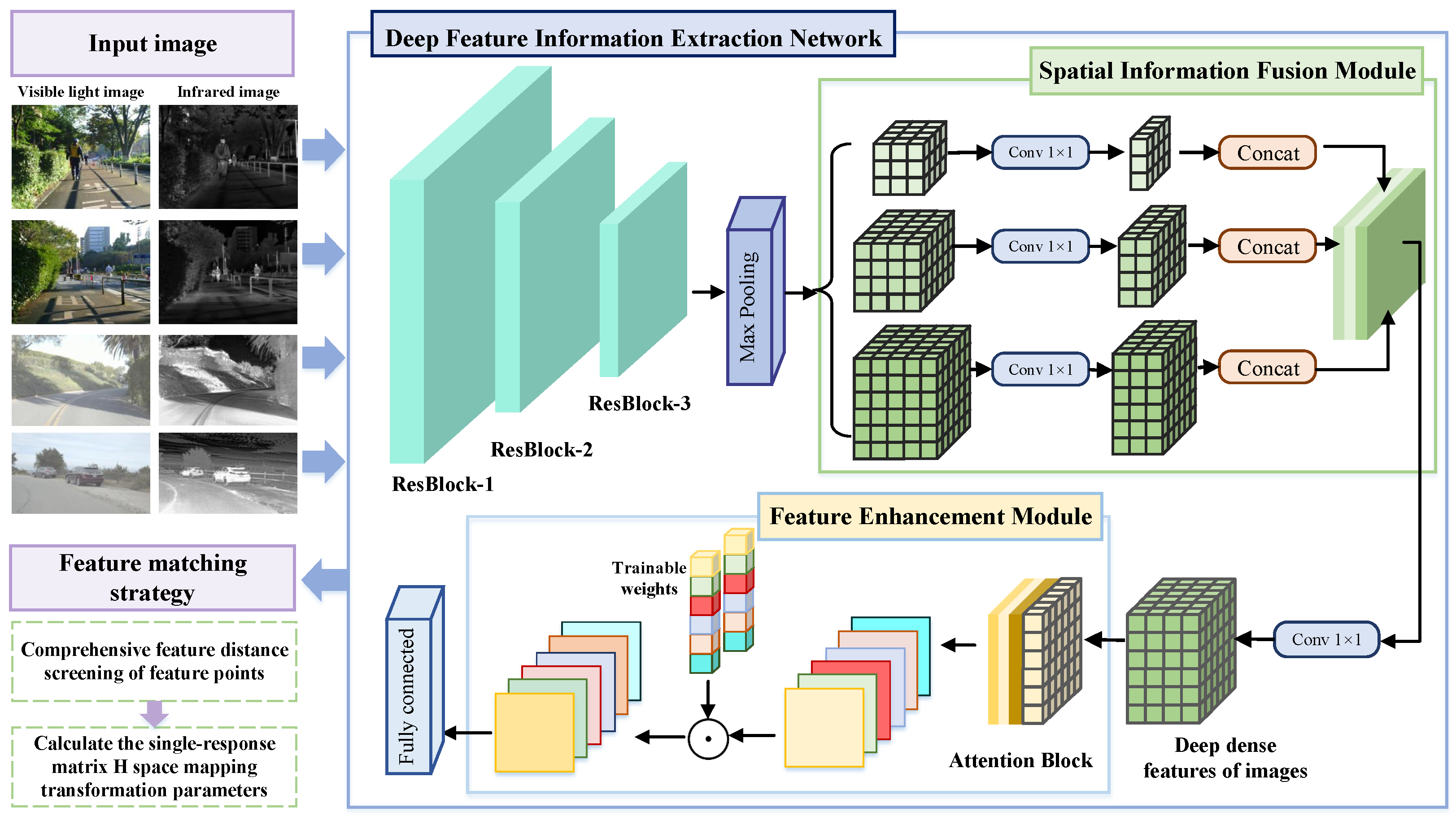
3.1. Deep Feature Information Extraction Network
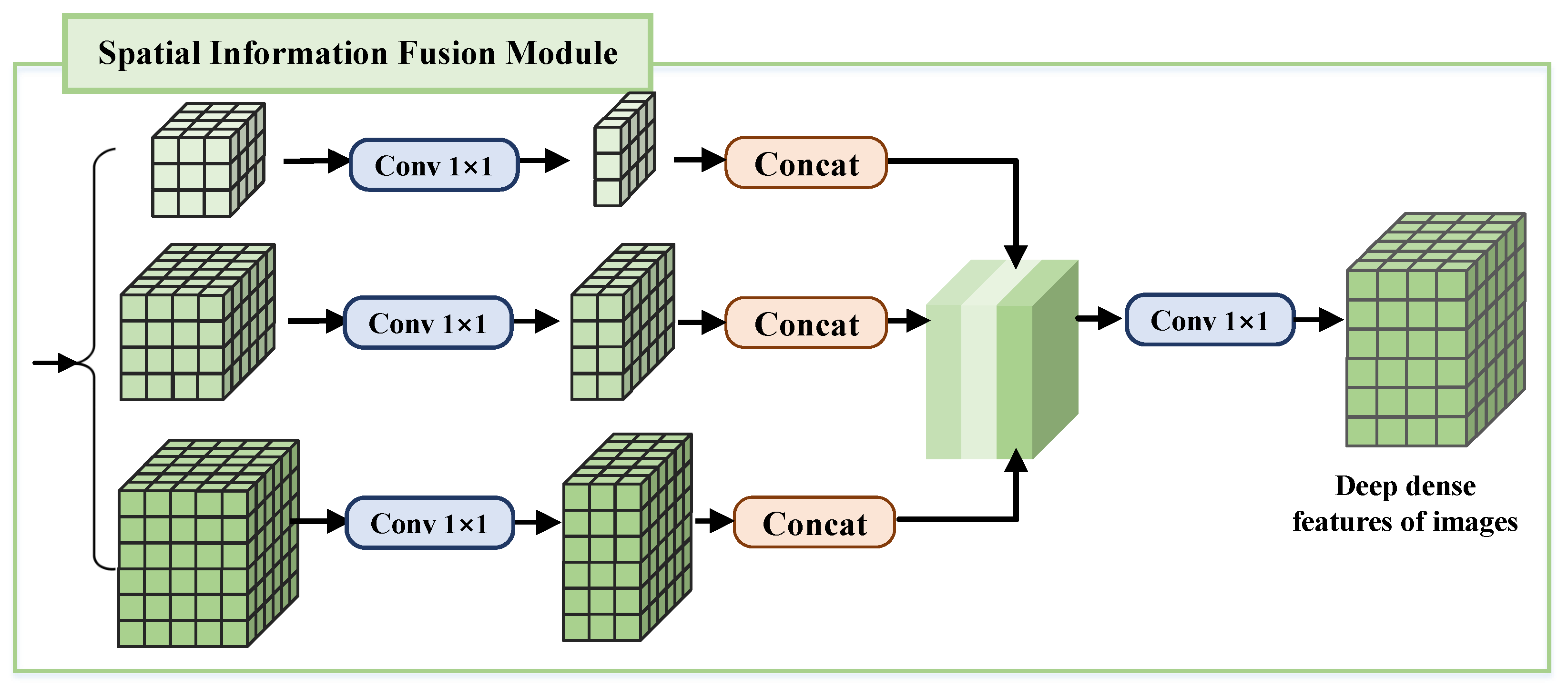
3.2. Multi-Scale Adaptive Spatial Information Fusion Structure
3.3. Feature Enhancement Structure Based on Self-Attention Mechanism
3.4. Feature Matching Strategy
4. Experiments and Discussion
4.1. Image Dataset and Evaluation Metrics
4.2. Ablation Experiment
4.2.1. Analysis of Ablation Experiments on the SFM
4.2.2. Analysis of Ablation Experiments on the FEM
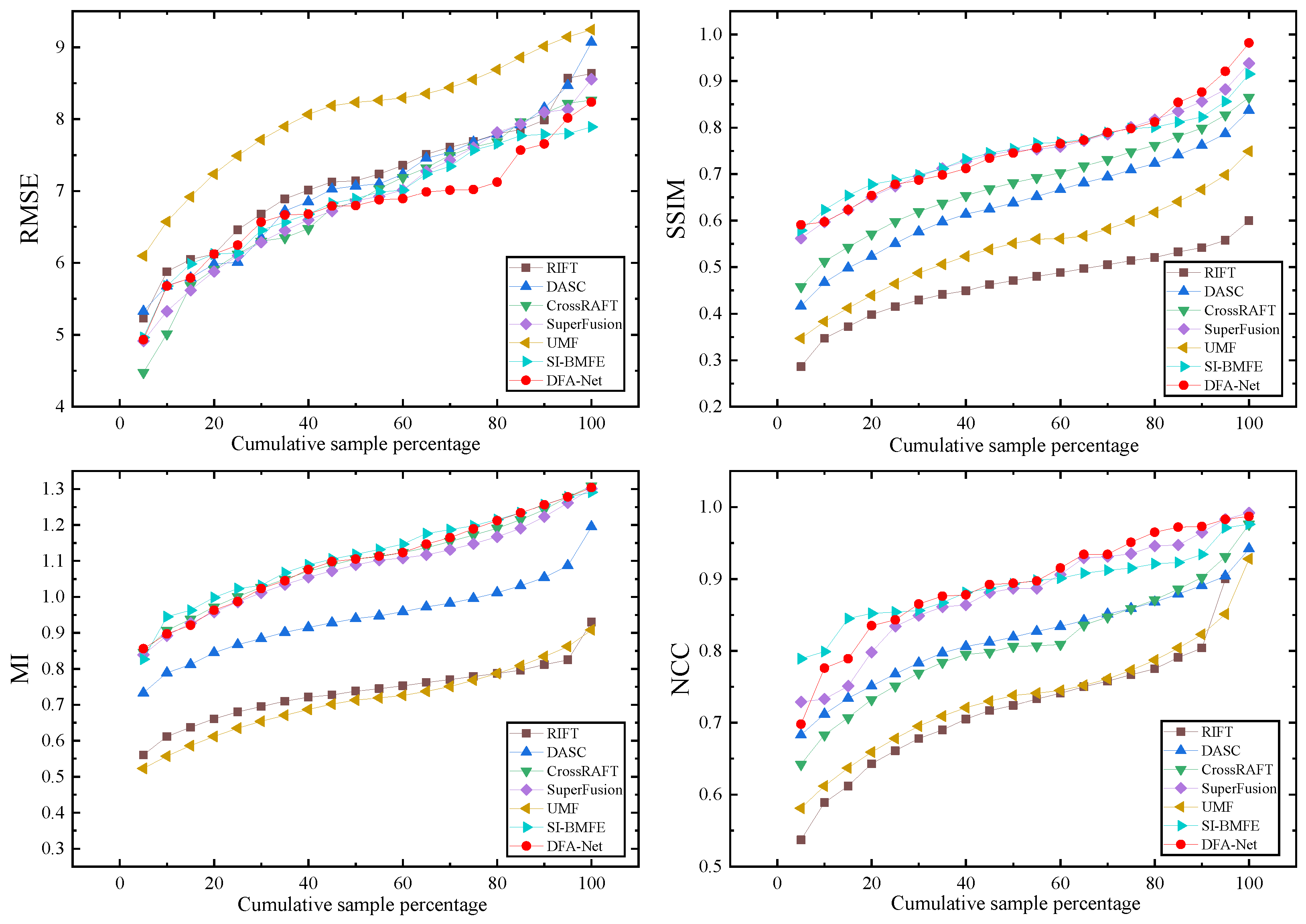
4.3. Comparison of Results with Other Methods
5. Conclusions
- Optimization of algorithm efficiency: While current deep learning-based registration methods offer advantages in terms of accuracy, their high computational complexity makes it challenging to meet the efficiency constraints of engineering applications. Future research could explore hybrid architecture designs by integrating traditional feature matching methods with deep feature representation techniques to create lightweight models with feature sharing mechanisms, thereby enhancing computational efficiency while maintaining registration accuracy.
- Task collaboration framework design: Current research mostly treats registration and fusion as independent tasks, leading to redundancy in the feature extraction process. For example, in a power inspection scenario, the future research could construct a joint optimization framework by designing shared feature encoders and adaptive weight allocation mechanisms to achieve collaborative optimization of registration parameter estimation and feature fusion. This end-to-end architecture not only reduces computational resource consumption but also enhances system performance through feature reuse mechanisms, driving the transition of the technology towards engineering applications.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DFA-Net | Deep feature information image alignment network |
| DFEN | Deep feature information extraction network |
| SFM | Spatial information fusion module |
| FEM | Feature enhancement module |
| RMSE | Root mean square error |
| SSIM | Structure similarity index measure |
| MI | Mutual information |
| NCC | Normalized cross-correlation |
References
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Jhan, J.P.; Rau, J.Y. A generalized tool for accurate and efficient image registration of UAV multi-lens multispectral cameras by N-SURF matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6353–6362. [Google Scholar] [CrossRef]
- Ma, W.; Wang, K.; Li, J.; Yang, S.X.; Li, J.; Song, L.; Li, Q. Infrared and visible image fusion technology and application: A review. Sensors 2023, 23, 599. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Wang, Z.; Feng, X.; Xu, G.; Wu, Y. A robust visible and infrared image matching algorithm for power equipment based on phase congruency and scale-invariant feature. Opt. Lasers Eng. 2023, 164, 107517. [Google Scholar] [CrossRef]
- Liu, Z.; Feng, R.; Chen, H.; Wu, S.; Gao, Y.; Gao, Y.; Wang, X. Temporal feature alignment and mutual information maximization for video-based human pose estimation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10996–11006. [Google Scholar]
- Li, J.; Wu, X.; Liao, P.; Song, H.; Yang, X.; Zhang, R. Robust registration for infrared and visible images based on salient gradient mutual information and local search. Infrared Phys. Technol. 2023, 131, 104711. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Deng, Y.; Ma, J. ReDFeat: Recoupling detection and description for multimodal feature learning. IEEE Trans. Image Process. 2022, 32, 591–602. [Google Scholar] [CrossRef]
- Mao, Y.; He, Z. Dual-Y network: Infrared-visible image patches matching via semi-supervised transfer learning. Appl. Intell. 2021, 51, 2188–2197. [Google Scholar] [CrossRef]
- Tang, L.; Deng, Y.; Ma, Y.; Huang, J.; Ma, J. SuperFusion: A versatile image registration and fusion network with semantic awareness. IEEE/CAA J. Autom. Sin. 2022, 9, 2121–2137. [Google Scholar] [CrossRef]
- Qiu, J.; Li, H.; Cao, H.; Zhai, X.; Liu, X.; Sang, M.; Yu, K.; Sun, Y.; Yang, Y.; Tan, P. RA-MMIR: Multi-modal image registration by robust adaptive variation attention gauge field. Inf. Fusion 2024, 105, 102215. [Google Scholar] [CrossRef]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A Trainable CNN for Joint Description and Detection of Local Features. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8084–8093. [Google Scholar]
- Cui, S.; Ma, A.; Zhang, L.; Xu, M.; Zhong, Y. MAP-Net: SAR and optical image matching via image-based convolutional network with attention mechanism and spatial pyramid aggregated pooling. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1000513. [Google Scholar] [CrossRef]
- Jiang, W.; Wu, J.; Chen, C.; Chen, J.; Zeng, X.; Zhong, L.; Di, J.; Wu, X.; Qin, Y. Registration of multi-modal images under a complex background combining multiscale features extraction and semantic segmentation. Opt. Express 2022, 30, 35596–35607. [Google Scholar] [CrossRef]
- Mok, T.C.W.; Li, Z.; Bai, Y.; Zhang, J.; Liu, W.; Zhou, Y.J.; Yan, K.; Jin, D.; Shi, Y.; Yin, X.; et al. Modality-agnostic structural image representation learning for deformable multi-modality medical image registration. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 11215–11225. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Luo, Y.; Yu, X.; Yang, D.; Zhou, B. A survey of intelligent transmission line inspection based on unmanned aerial vehicle. Artif. Intell. Rev. 2023, 56, 173–201. [Google Scholar] [CrossRef]
- Lu, C.; Qi, X.; Ding, K.; Yu, B. An improved FAST algorithm based on image edges for complex environment. Sensors 2022, 22, 7127. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inf. Fusion 2022, 83, 79–92. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. RIFT: Multi-modal image matching based on radiation-variation insensitive feature transform. IEEE Trans. Image Process. 2019, 29, 3296–3310. [Google Scholar] [CrossRef]
- Kim, S.; Min, D.; Ham, B.; Do, M.N.; Sohn, K. DASC: Robust dense descriptor for multi-modal and multi-spectral correspondence estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1712–1729. [Google Scholar] [CrossRef]
- Zhou, S.; Tan, W.; Yan, B. Promoting single-modal optical flow network for diverse cross-modal flow estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 3562–3570. [Google Scholar]
- Wang, D.; Liu, J.; Fan, X.; Liu, R. Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI), Vienna, Austria, 23–29 July 2022; pp. 3508–3515. [Google Scholar]
- Tian, C.; Xu, L.; Li, X.; Zhou, H.; Song, X. Semantic-Injected Bidirectional Multiscale Flow Estimation Network for Infrared and Visible Image Registration. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 3686–3695. [Google Scholar] [CrossRef]
- Wang, W.; Yin, B.; Li, L.; Li, L.; Liu, H. A Low Light Image Enhancement Method Based on Dehazing Physical Model. Comput. Model. Eng. Sci. (CMES) 2025, 143, 1595–1616. [Google Scholar] [CrossRef]
- Wang, M.; Li, J.; Zhang, C. Low-light image enhancement by deep learning network for improved illumination map. Comput. Vis. Image Underst. 2023, 232, 103681. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Optimizer | Batch Size | Epochs | Initial Learning Rate |
|---|---|---|---|---|
| Parameter settings | Adam | 32 | 1100 |
| Baseline | SFM | FEM | RMSE | SSIM | MI | NCC |
|---|---|---|---|---|---|---|
| ✓ | × | × | 4.571 | 0.716 | 0.743 | 0.683 |
| ✓ | ✓ | × | 4.362 | 0.755 | 0.781 | 0.767 |
| ✓ | × | ✓ | 4.173 | 0.829 | 0.866 | 0.804 |
| ✓ | ✓ | ✓ | 3.910 | 0.871 | 0.906 | 0.894 |
| Baseline | SFM | FEM | RMSE | SSIM | MI | NCC |
|---|---|---|---|---|---|---|
| ✓ | × | × | 7.255 | 0.644 | 0.873 | 0.779 |
| ✓ | ✓ | × | 7.106 | 0.673 | 0.909 | 0.825 |
| ✓ | × | ✓ | 6.933 | 0.717 | 1.062 | 0.846 |
| ✓ | ✓ | ✓ | 6.782 | 0.752 | 1.099 | 0.893 |
| Model | RMSE | SSIM | MI | NCC | Time (s) |
|---|---|---|---|---|---|
| RIFT | 5.473 | 0.736 | 0.517 | 0.558 | 9.457 |
| DASC | 4.583 | 0.846 | 0.653 | 0.679 | 26.624 |
| CrossRAFT | 4.476 | 0.830 | 0.815 | 0.833 | 2.641 |
| SuperFusion | 4.164 | 0.845 | 0.910 | 0.871 | 1.094 |
| UMF | 5.679 | 0.728 | 0.572 | 0.531 | 3.931 |
| SI-BMFE | 3.944 | 0.852 | 0.879 | 0.878 | 3.847 |
| DFA-Net | 3.910 | 0.871 | 0.906 | 0.894 | 2.605 |
| Model | RMSE | SSIM | MI | NCC | Time (s) |
|---|---|---|---|---|---|
| RIFT | 7.141 | 0.465 | 0.735 | 0.714 | 10.690 |
| DASC | 7.061 | 0.638 | 0.943 | 0.818 | 13.478 |
| CrossRAFT | 6.840 | 0.678 | 1.091 | 0.810 | 2.599 |
| SuperFusion | 6.877 | 0.747 | 1.080 | 0.880 | 1.307 |
| UMF | 8.062 | 0.545 | 0.712 | 0.736 | 3.624 |
| SI-BMFE | 6.868 | 0.748 | 1.110 | 0.889 | 4.347 |
| DFA-Net | 6.782 | 0.752 | 1.099 | 0.893 | 3.235 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Mao, Y.; Pan, J. Image Alignment Based on Deep Learning to Extract Deep Feature Information from Images. Sensors 2025, 25, 4628. https://doi.org/10.3390/s25154628
Zhu L, Mao Y, Pan J. Image Alignment Based on Deep Learning to Extract Deep Feature Information from Images. Sensors. 2025; 25(15):4628. https://doi.org/10.3390/s25154628
Chicago/Turabian StyleZhu, Lin, Yuxing Mao, and Jianyu Pan. 2025. "Image Alignment Based on Deep Learning to Extract Deep Feature Information from Images" Sensors 25, no. 15: 4628. https://doi.org/10.3390/s25154628
APA StyleZhu, L., Mao, Y., & Pan, J. (2025). Image Alignment Based on Deep Learning to Extract Deep Feature Information from Images. Sensors, 25(15), 4628. https://doi.org/10.3390/s25154628