
FFT-RDNet: A Time–Frequency-Domain-Based Intrusion Detection Model for IoT Security


Abstract
1. Introduction
- (1)
- Inspired by the frequency characteristics of different network attacks, we model the features of network attacks from the time and frequency domains, respectively. By converting one-dimensional features into two-dimensional features, the extraction of the network traffic’s features is improved.
- (2)
- We propose a network intrusion detection model FFT-RDNet based on a time–frequency-domain analysis. Through depthwise separable convolution and residual networks, the two-dimensional variations between different features of different attacks are captured from the transformed two-dimensional features.
- (3)
- Experiments were conducted on the NSL-KDD dataset and the CIC-IDS2018 dataset. These experiments demonstrate that the proposed method outperforms most of the existing model structures in multiple indicators. The ablation experiments verify the effectiveness of the different modules of the system.
2. Related Work
3. The Proposed Model
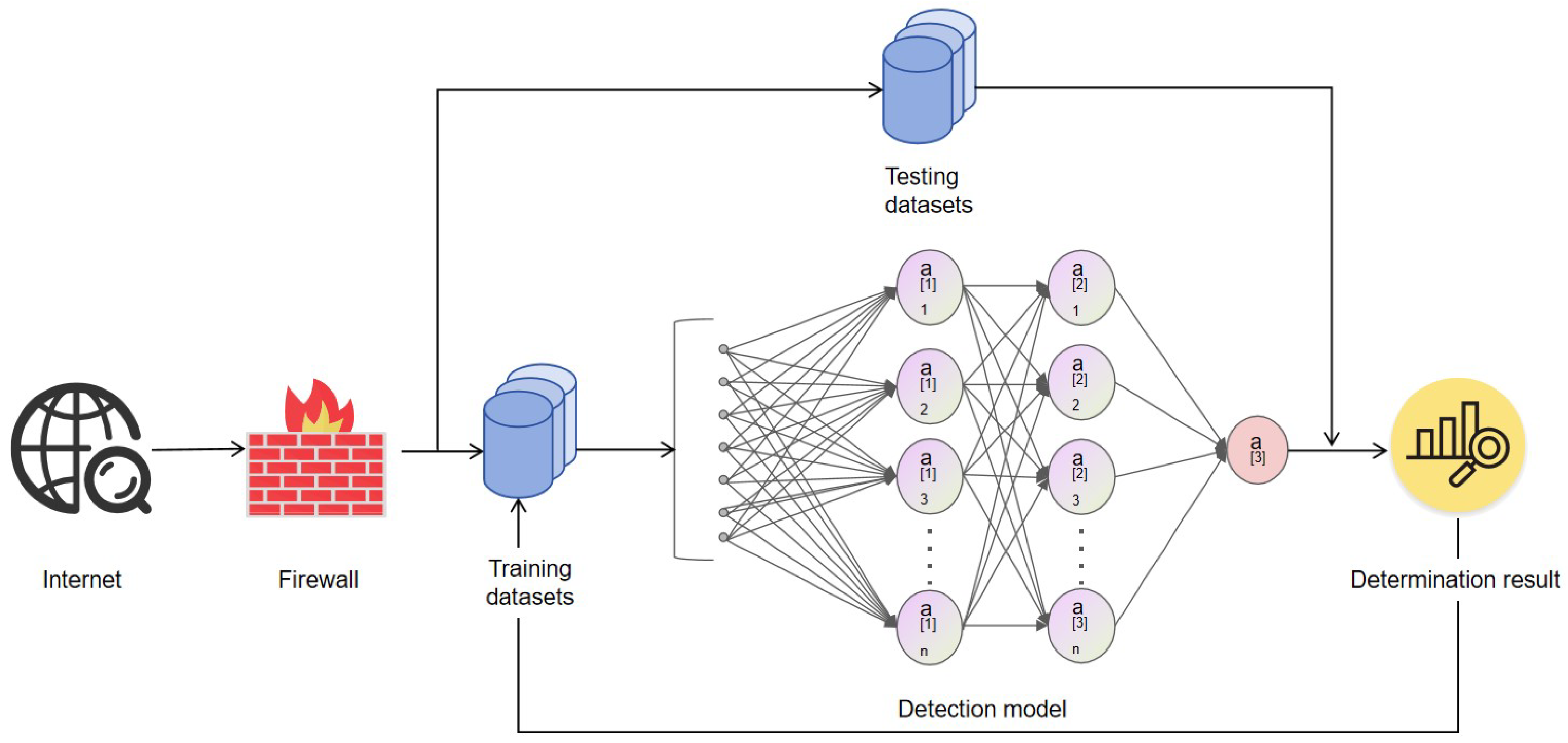
3.1. The Overall Framework
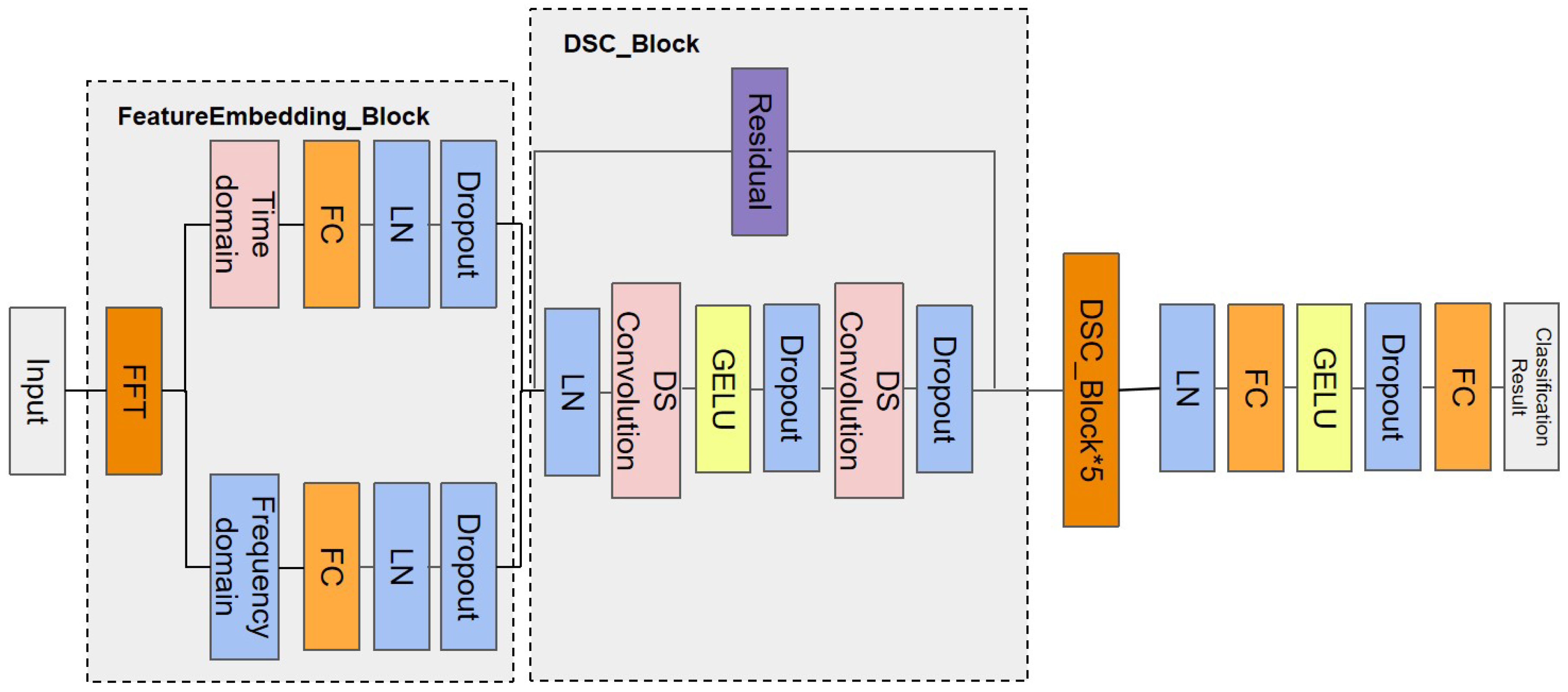
3.2. The Feature Embedding Module
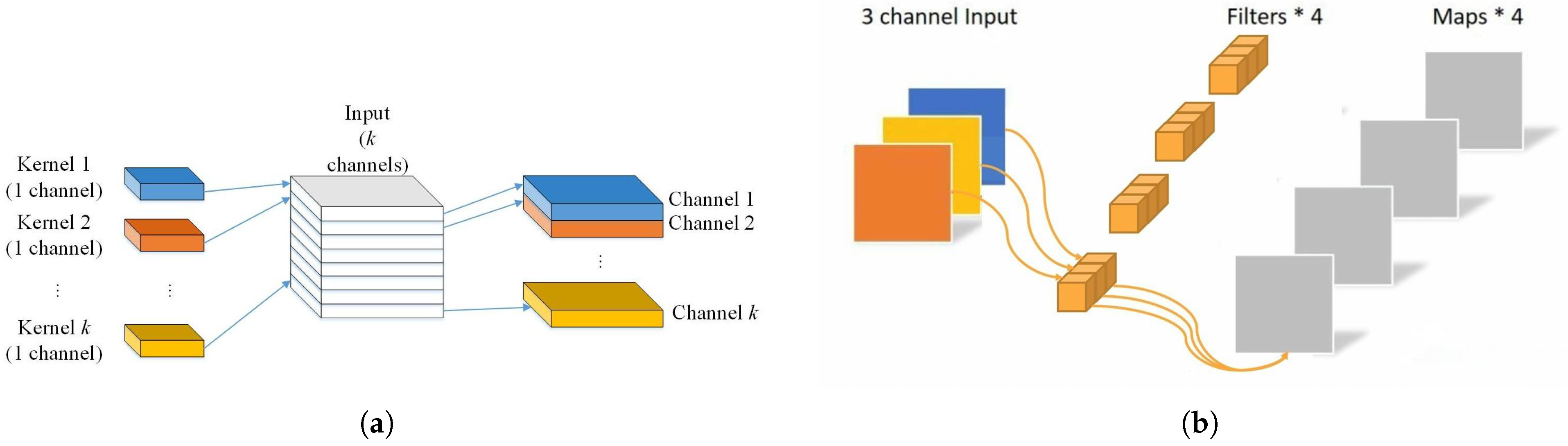
3.3. The Depthwise Separable Convolution Block
3.4. Basic Blocks
3.5. Calculation of the Model Calculations and Parameter Quantities
3.5.1. The Feature Embedding Module Complexity Calculation
3.5.2. Depthwise Separable Convolution Block Complexity Calculation
3.5.3. An Analysis of the Model’s Complexity
4. Experiments
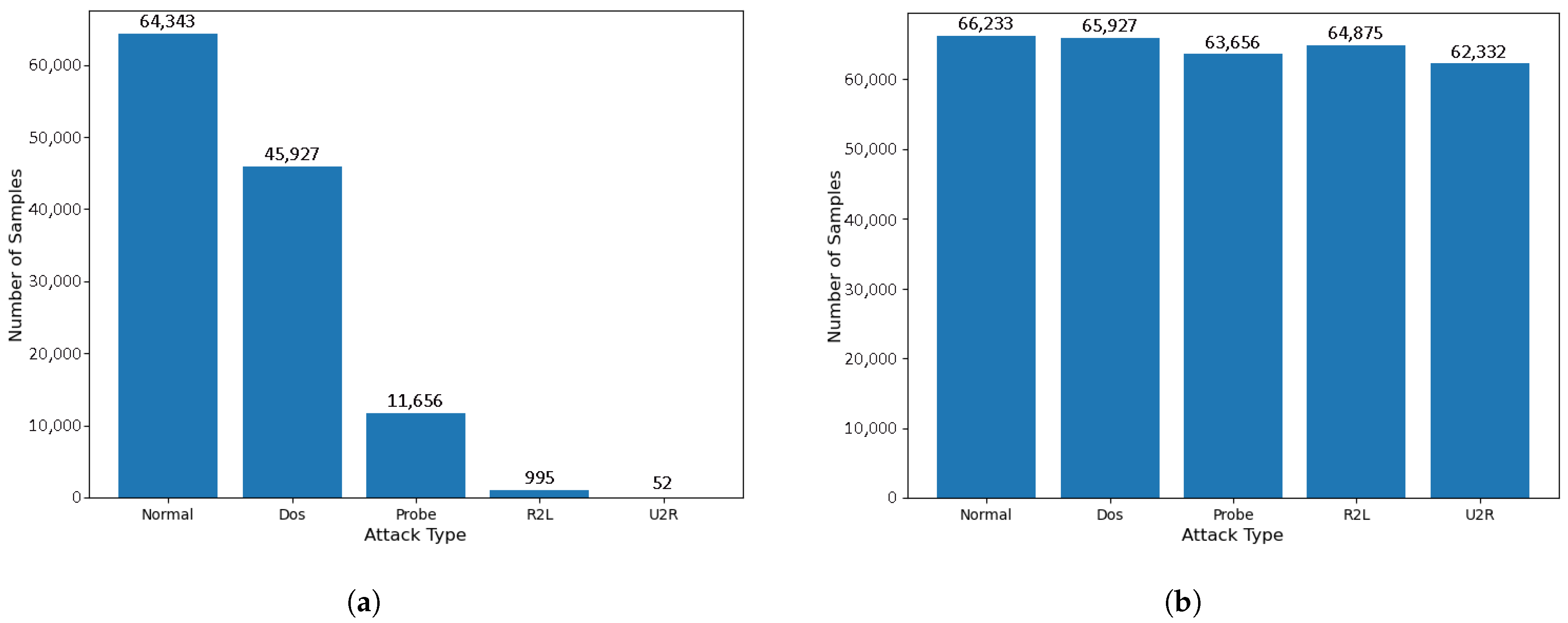
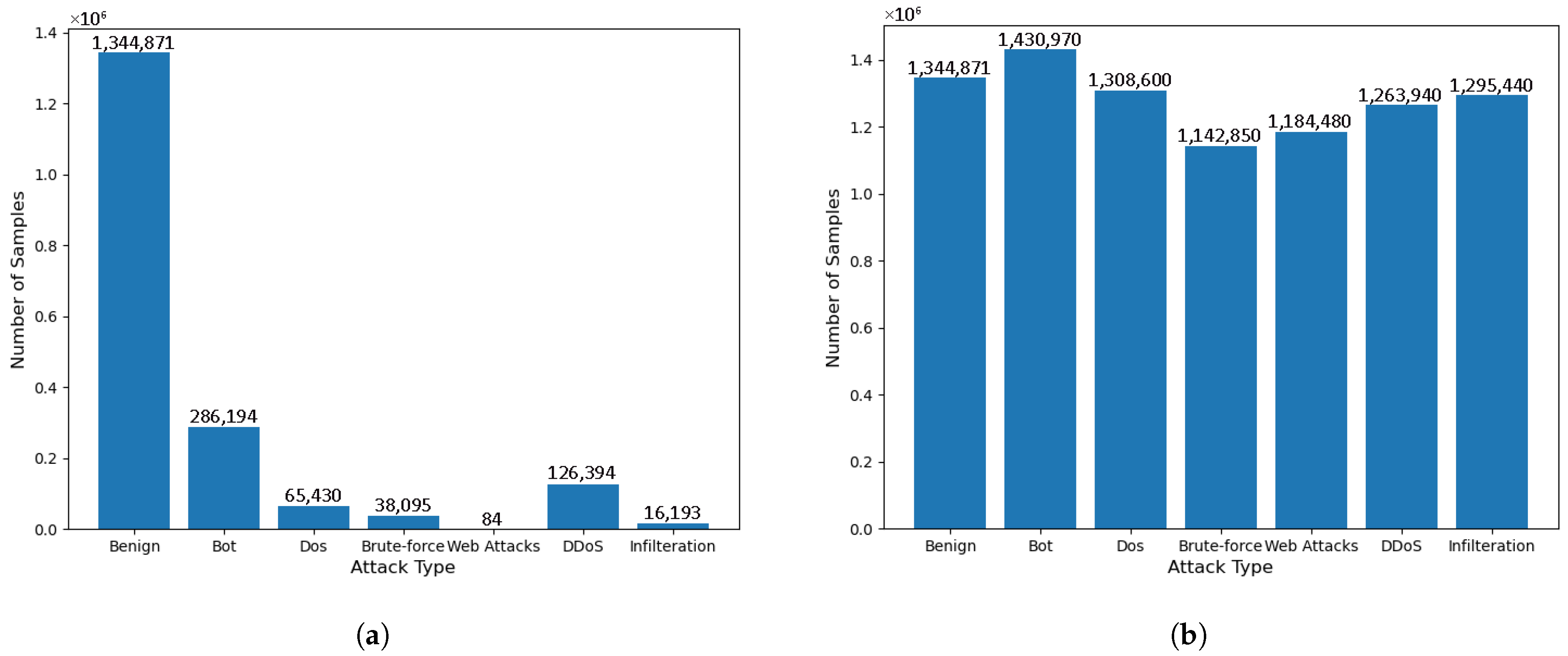
4.1. The Datasets
4.2. Data Processing
4.3. The Selection of Mixed Sampling Methods
4.4. Selection of the Experimental Hyperparameters and Assessment Indicators
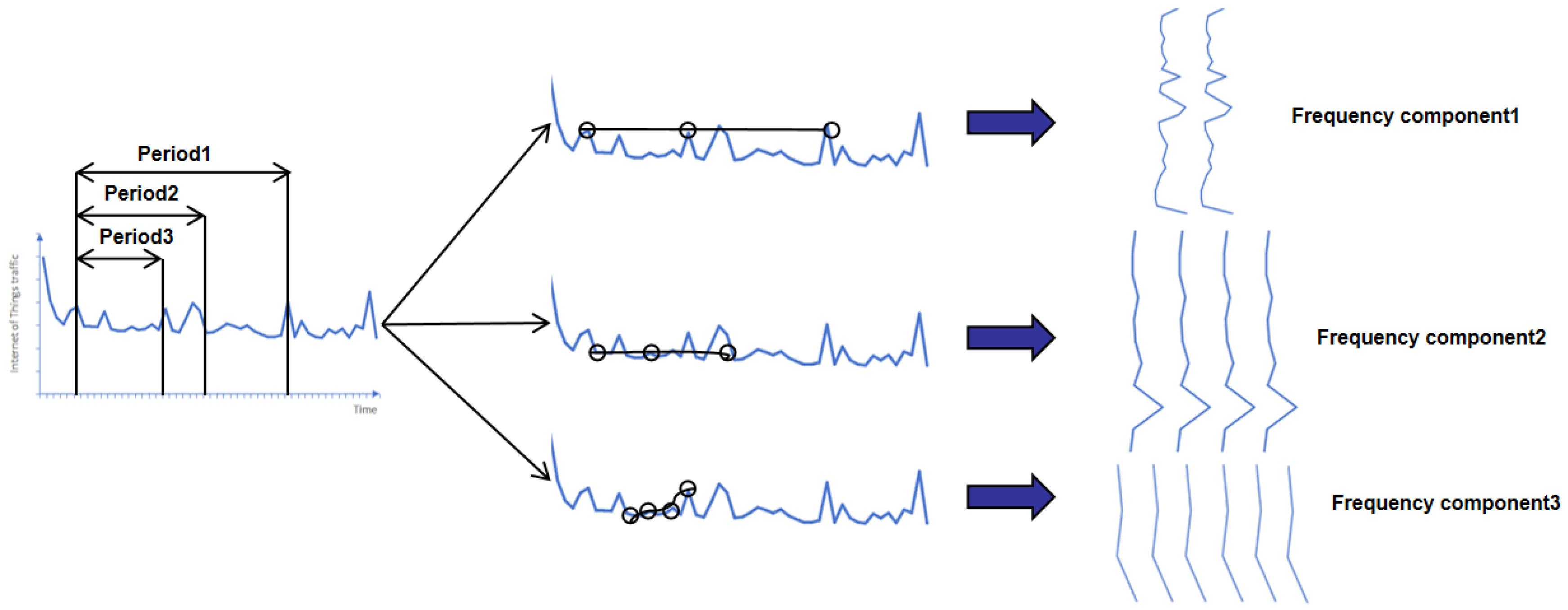
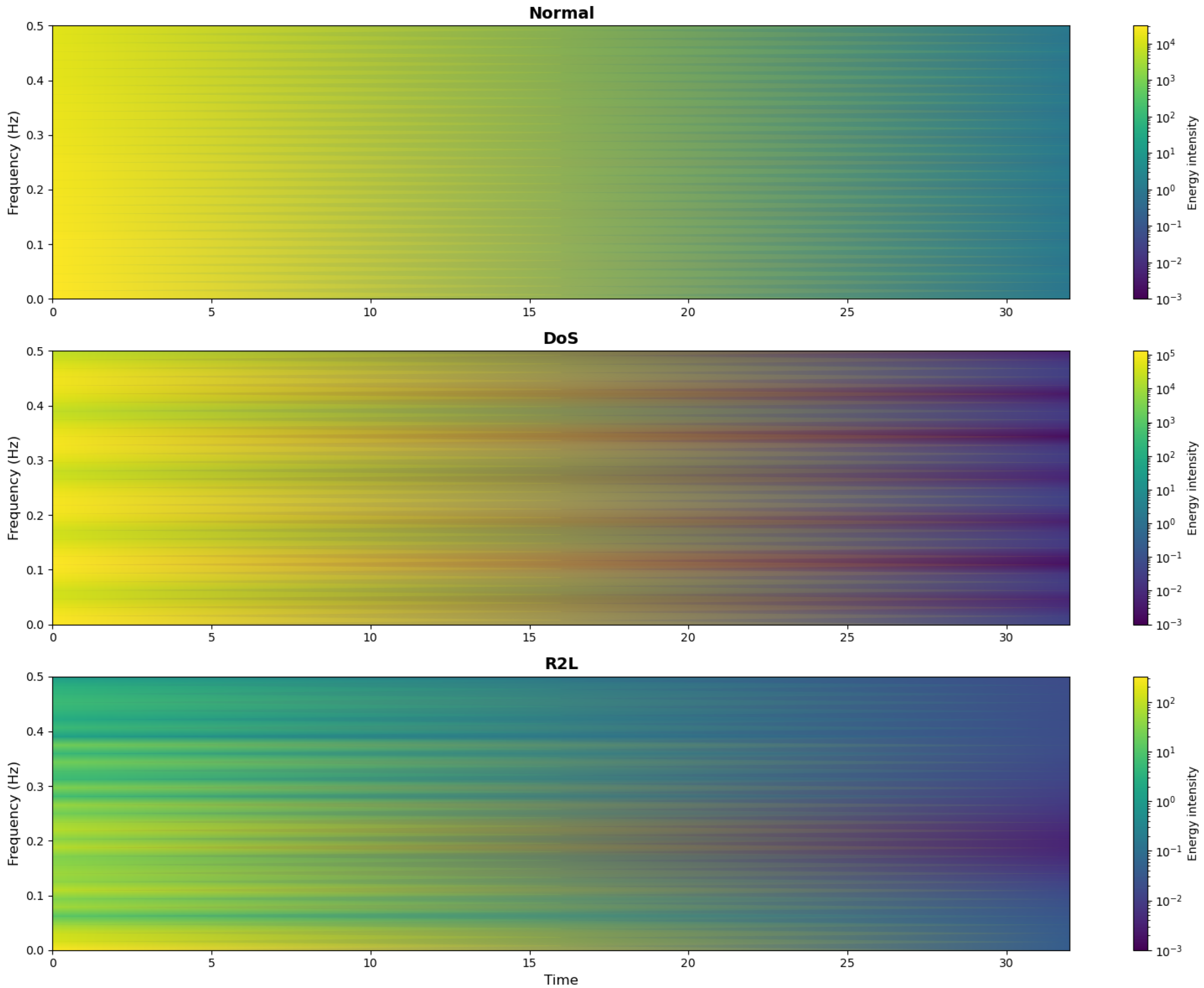
4.5. A Visualization Analysis of Time–Frequency Characteristics
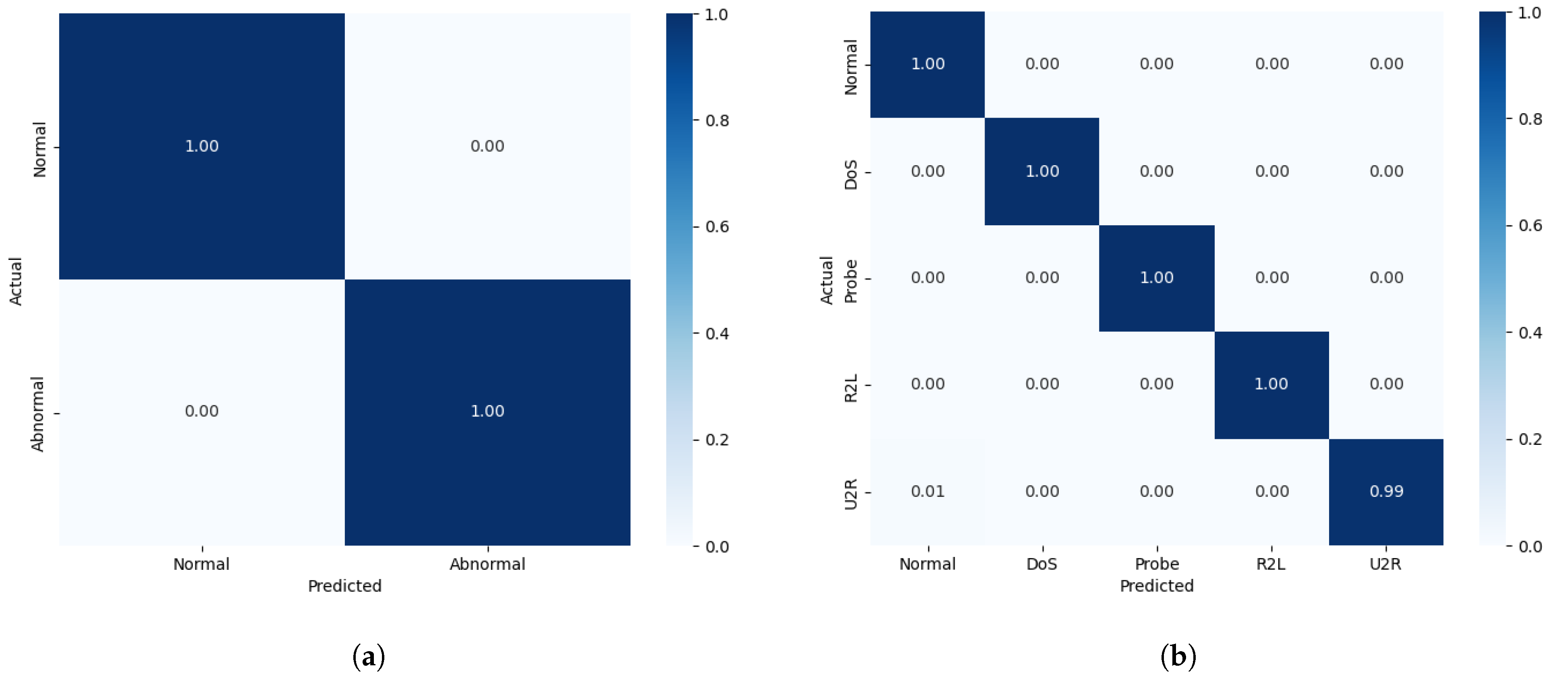
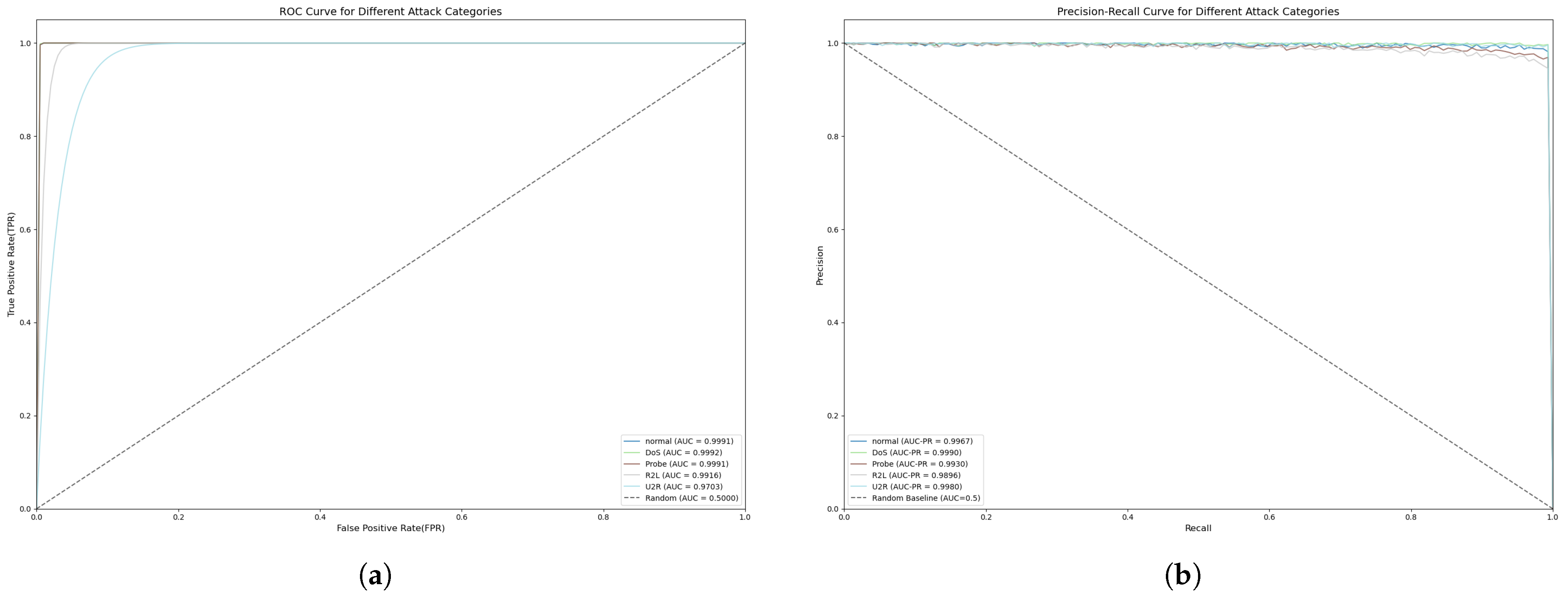
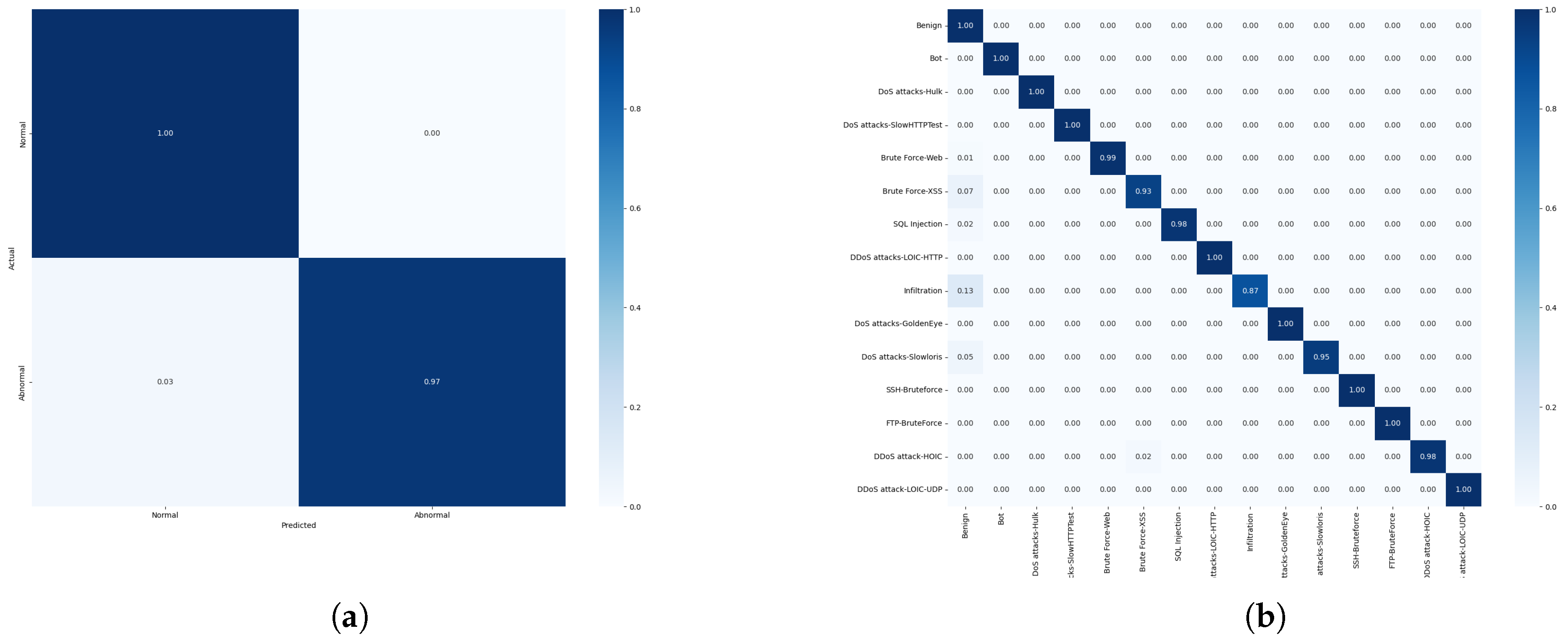
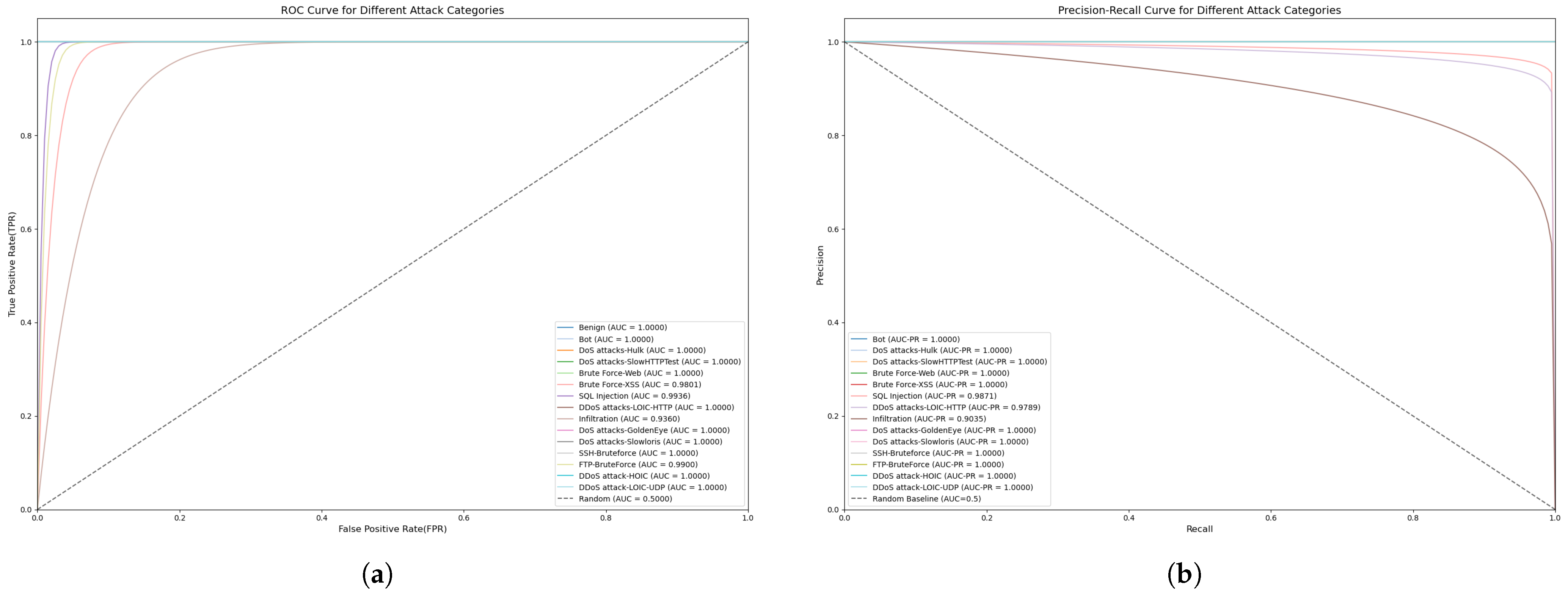
4.6. Experimental Results
4.7. Ablation Experiments
4.8. Edge Deployment Feasibility Validation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Karantzas, G.; Patsakis, C. An empirical assessment of endpoint detection and response systems against advanced persistent threats attack vectors. J. Cybersecur. Priv. 2021, 1, 387–421. [Google Scholar] [CrossRef]
- Devalla, V.; Raghavan, S.S.; Maste, S.; Kotian, J.D.; Annapurna, D. Murli: A tool for detection of malicious urls and injection attacks. Procedia Comput. Sci. 2022, 215, 662–676. [Google Scholar] [CrossRef]
- Husnoo, M.A.; Anwar, A.; Chakrabortty, R.K.; Doss, R.; Ryan, M.J. Differential privacy for IoT-enabled critical infrastructure: A comprehensive survey. IEEE Access 2021, 9, 153276–153304. [Google Scholar] [CrossRef]
- Liao, H.J.; Lin, C.H.R.; Lin, Y.C.; Tung, K.Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A deep learning approach for network intrusion detection system. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies (Formerly BIONETICS), New York, NY, USA, 3–5 December 2015; pp. 21–26. [Google Scholar]
- Park, Y.H.; Wood, G.; Kastner, D.L.; Chae, J.J. Pyrin inflammasome activation and RhoA signaling in the autoinflammatory diseases FMF and HIDS. Nat. Immunol. 2016, 17, 914–921. [Google Scholar] [CrossRef] [PubMed]
- Peng, T.; Leckie, C.; Ramamohanarao, K. Survey of network-based defense mechanisms countering the DoS and DDoS problems. ACM Comput. Surv. (CSUR) 2007, 39, 3-es. [Google Scholar] [CrossRef]
- Cui, A.; Costello, M.; Stolfo, S.J. When Firmware Modifications Attack: A Case Study of Embedded Exploitation. In Proceedings of the NDSS, San Diego, CA, USA, 24–27 February 2013; Volume 1, pp. 1–13. [Google Scholar]
- Galtier, F.; Cayre, R.; Auriol, G.; Kaâniche, M.; Nicomette, V. A PSD-based fingerprinting approach to detect IoT device spoofing. In Proceedings of the 2020 IEEE 25th Pacific Rim International Symposium on Dependable Computing (PRDC), Perth, Australia, 1–4 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 40–49. [Google Scholar]
- Kaul, V.; Yezzi, A.; Tsai, Y. Detecting curves with unknown endpoints and arbitrary topology using minimal paths. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1952–1965. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar] [PubMed]
- Joachims, T. Making Large-Scale SVM Learning Practical; Technical Report; Technical University Dortmund: Dortmund, Germany, 1998. [Google Scholar]
- Tang, J.; Liu, J.; Zhang, M.; Mei, Q. Visualizing large-scale and high-dimensional data. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 287–297. [Google Scholar]
- Yan, B.; Han, G. Effective feature extraction via stacked sparse autoencoder to improve intrusion detection system. IEEE Access 2018, 6, 41238–41248. [Google Scholar] [CrossRef]
- Kuncheva, L.I. Change detection in streaming multivariate data using likelihood detectors. IEEE Trans. Knowl. Data Eng. 2011, 25, 1175–1180. [Google Scholar] [CrossRef]
- Sun, P.; Liu, P.; Li, Q.; Liu, C.; Lu, X.; Hao, R.; Chen, J. DL-IDS: Extracting Features Using CNN-LSTM Hybrid Network for Intrusion Detection System. Secur. Commun. Netw. 2020, 2020, 8890306. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The performance of LSTM and BiLSTM in forecasting time series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3285–3292. [Google Scholar]
- Seo, E.; Song, H.M.; Kim, H.K. GIDS: GAN based intrusion detection system for in-vehicle network. In Proceedings of the 2018 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, Ireland, 28–30 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Zhou, X.; Liang, W.; Li, W.; Yan, K.; Shimizu, S.; Wang, K.I.K. Hierarchical adversarial attacks against graph-neural-network-based IoT network intrusion detection system. IEEE Internet Things J. 2021, 9, 9310–9319. [Google Scholar] [CrossRef]
- Pham, T.N.D.; Yeo, C.K.; Yanai, N.; Fujiwara, T. Detecting flooding attack and accommodating burst traffic in delay-tolerant networks. IEEE Trans. Veh. Technol. 2017, 67, 795–808. [Google Scholar] [CrossRef]
- Abdulganiyu, O.H.; Ait Tchakoucht, T.; Saheed, Y.K. A systematic literature review for network intrusion detection system (IDS). Int. J. Inf. Secur. 2023, 22, 1125–1162. [Google Scholar] [CrossRef]
- Gharaee, H.; Hosseinvand, H. A new feature selection IDS based on genetic algorithm and SVM. In Proceedings of the 2016 8th International Symposium on Telecommunications (IST), Tehran, Iran, 27–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 139–144. [Google Scholar]
- Bilge, L.; Dumitraş, T. Before we knew it: An empirical study of zero-day attacks in the real world. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 833–844. [Google Scholar]
- Balla, A.; Habaebi, M.H.; Elsheikh, E.A.; Islam, M.R.; Suliman, F. The effect of dataset imbalance on the performance of SCADA intrusion detection systems. Sensors 2023, 23, 758. [Google Scholar] [CrossRef] [PubMed]
- Bagui, S.; Li, K. Resampling imbalanced data for network intrusion detection datasets. J. Big Data 2021, 8, 6. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Lin, W.C.; Tsai, C.F.; Hu, Y.H.; Jhang, J.S. Clustering-based undersampling in class-imbalanced data. Inf. Sci. 2017, 409, 17–26. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1322–1328. [Google Scholar]
- Vinayakumar, R.; Soman, K.; Poornachandran, P. Applying convolutional neural network for network intrusion detection. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1222–1228. [Google Scholar]
- Laghrissi, F.; Douzi, S.; Douzi, K.; Hssina, B. Intrusion detection systems using long short-term memory (LSTM). J. Big Data 2021, 8, 65. [Google Scholar] [CrossRef]
- Liu, W.; Liu, X.; Di, X.; Qi, H. A novel network intrusion detection algorithm based on Fast Fourier Transformation. In Proceedings of the 2019 1st International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 23–27 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Sinha, J.; Manollas, M. Efficient deep CNN-BiLSTM model for network intrusion detection. In Proceedings of the 2020 3rd International Conference on Artificial Intelligence and Pattern Recognition, Xiamen, China, 26–28 June 2020; pp. 223–231. [Google Scholar]
- Sun, H.; Chen, M.; Weng, J.; Liu, Z.; Geng, G. Anomaly detection for in-vehicle network using CNN-LSTM with attention mechanism. IEEE Trans. Veh. Technol. 2021, 70, 10880–10893. [Google Scholar] [CrossRef]
- Ullah, F.; Ullah, S.; Srivastava, G.; Lin, J.C.W. IDS-INT: Intrusion detection system using transformer-based transfer learning for imbalanced network traffic. Digit. Commun. Netw. 2024, 10, 190–204. [Google Scholar] [CrossRef]
- Sana, L.; Nazir, M.M.; Yang, J.; Hussain, L.; Chen, Y.L.; Ku, C.S.; Alatiyyah, M.; Alateyah, S.A.; Por, L.Y. Securing the IoT cyber environment: Enhancing intrusion anomaly detection with vision transformers. IEEE Access 2024, 12, 82443–82468. [Google Scholar] [CrossRef]
- Wan, J.; Yin, L.; Wu, Y. Return and volatility connectedness across global ESG stock indexes: Evidence from the time-frequency domain analysis. Int. Rev. Econ. Financ. 2024, 89, 397–428. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Peng, H.; Wu, C.; Xiao, Y. CBF-IDS: Addressing class imbalance using CNN-BiLSTM with focal loss in network intrusion detection system. Appl. Sci. 2023, 13, 11629. [Google Scholar] [CrossRef]
- Zhou, Z.; Huang, H.; Fang, B. Application of weighted cross-entropy loss function in intrusion detection. J. Comput. Commun. 2021, 9, 1–21. [Google Scholar] [CrossRef]
- Huang, L.; Qin, J.; Zhou, Y.; Zhu, F.; Liu, L.; Shao, L. Normalization techniques in training dnns: Methodology, analysis and application. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10173–10196. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Islam, M.R.; Sahlabadi, M.; Kim, K.; Kim, Y.; Yim, K. CF-AIDS: Comprehensive frequency-agnostic intrusion detection system on in-vehicle network. IEEE Access 2023, 12, 13971–13985. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Cui, J.; Zong, L.; Xie, J.; Tang, M. A novel multi-module integrated intrusion detection system for high-dimensional imbalanced data. Appl. Intell. 2023, 53, 272–288. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, A.; Sinha, D.; Kumar, V. WCGAN-GP based synthetic attack data generation with GA based feature selection for IDS. Comput. Secur. 2023, 134, 103432. [Google Scholar] [CrossRef]
- Wang, S.; Xu, W.; Liu, Y. Res-TranBiLSTM: An intelligent approach for intrusion detection in the Internet of Things. Comput. Netw. 2023, 235, 109982. [Google Scholar] [CrossRef]
- Akuthota, U.C.; Bhargava, L. Transformer Based Intrusion Detection for IoT Networks. IEEE Internet Things J. 2025, 12, 6062–6067. [Google Scholar] [CrossRef]
- Jablaoui, R.; Liouane, N. An effective deep CNN-LSTM based intrusion detection system for network security. In Proceedings of the 2024 International Conference on Control, Automation and Diagnosis (ICCAD), Paris, France, 15–17 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Mezina, A.; Burget, R.; Travieso-González, C.M. Network anomaly detection with temporal convolutional network and U-Net model. IEEE Access 2021, 9, 143608–143622. [Google Scholar] [CrossRef]
- Kunang, Y.N.; Nurmaini, S.; Stiawan, D.; Suprapto, B.Y. Attack classification of an intrusion detection system using deep learning and hyperparameter optimization. J. Inf. Secur. Appl. 2021, 58, 102804. [Google Scholar] [CrossRef]
- Selvam, R.; Velliangiri, S. An improving intrusion detection model based on novel CNN technique using recent CIC-IDS datasets. In Proceedings of the 2024 International Conference on Distributed Computing and Optimization Techniques (ICDCOT), Bengaluru, India, 15–16 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Qazi, E.U.H.; Faheem, M.H.; Zia, T. HDLNIDS: Hybrid deep-learning-based network intrusion detection system. Appl. Sci. 2023, 13, 4921. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Methods | Datasets | Balancing Methods | Feature Dimension | Parameter Quantity | Limitations |
|---|---|---|---|---|---|---|
| 2017 | CNN-based | KDDcup99, NSL-KDD | – | 1D | 500 K–1 M | Limited sequential modeling, poor handling of temporal dynamics |
| 2019 | FFT-based | NSL-KDD | – | 1D (only frequency domain) | 200–300 K | Limited to the frequency domain |
| 2022 | BiLSTM | NSL-KDD | – | 1D (only time domain) | 1–2 M | Limited to the time domain, limited to NSL-KDD |
| 2023 | CBF-IDS [40] | UNSW-NB15 CIC-IDS2017 NSL-KDD | Focal loss | 2D | 1.8–2.2 M | Long training time Poor interpretability |
| 2024 | IDS-INT | UNSW-NB15 CIC-IDS2017 NSL-KDD | SMOTE | 1D | 3–5 M | High computational cost, large data requirements, overfitting risk |
| 2024 | CNN-BiLSTM | UNSW-NB15 | Weighted loss | 2D (time and space dimensions) | 1.8–2.2 M | Sensitive to long sequences |
| 2024 | ViT models | NSL-KDD | Bayesian optimization | 2D (two-dimensional images) | 50–80 M | Long training time |
| 2025 | ours | NSL-KDD CIC-IDS2018 | ADASYN and Tomeklinkes | 2D (time–frequency domain) | 350–500 K | The size of the FFT window needs to be preset |
| Dataset | Quantity and Proportion | Normal | DoS | Probe | R2L | U2R |
|---|---|---|---|---|---|---|
| KDDTrain+ | Number scale | 67,343 53.46% | 45,927 36.46% | 11,656 9.25% | 995 0.79% | 52 0.04% |
| KDDTest+ | Number scale | 9711 43.08% | 7458 33.08% | 2421 11.77% | 2654 0.89% | 200 0.89% |
| Category | Total Size | Total Rate | Train Size | Test Size |
|---|---|---|---|---|
| Benign | 13,448,708 | 83.07% | 1,344,871 | 267,762 |
| Bot | 286,191 | 1.76% | 286,194 | 5705 |
| DoS attacks-Hulk | 461,912 | 2.85% | 46,191 | 9205 |
| DoS attacks-SlowHTTPTest | 139,890 | 0.86% | 13,989 | 2795 |
| Brute Force-Web | 611 | 0.004% | 61 | 13 |
| Brute Force-XSS | 230 | 0.001% | 23 | 6 |
| SQL Injection | 87 | 0.001% | 9 | 2 |
| DDoS attacks-LOIC-HTTP | 576,192 | 3.55% | 57,619 | 11,578 |
| Infiltration | 161,934 | 1% | 16,193 | 3190 |
| DoS attacks-GoldenEye | 41,508 | 0.26% | 4151 | 827 |
| DoS attacks-Slowloris | 10,990 | 0.07% | 1099 | 223 |
| SSH-Bruteforce | 187,589 | 1.16% | 18,759 | 3755 |
| FTP-Bruteforce | 193,360 | 1.19% | 19,336 | 3889 |
| DDoS attacks-HOIC | 686,023 | 4.23% | 68,602 | 13,753 |
| DDoS attacks-LOIC-UDP | 1730 | 0.01% | 173 | 38 |
| Confusion Matrix | Predicted Value | ||
|---|---|---|---|
| Normal | Attack | ||
| True value | Normal | TN | FP |
| Attack | FN | TP | |
| Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|
| GMM-WGAN [47] | ||||
| XGB [48] | ||||
| IDS-INT | ||||
| Res-TranBiLSTM [49] | ||||
| Transformer-based [50] | ||||
| Ours |
| Ours | IDS-INT | Transformer-Based | |
|---|---|---|---|
| DoS | |||
| Probe | |||
| R2L | |||
| U2R |
| Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|
| CNN+LSTM [51] | ||||
| U-net [52] | ||||
| HPO+DNN [53] | ||||
| Novel CNN [54] | ||||
| HDLNIDS [55] | ||||
| Ours |
| Ours | HDLNIDS | U-Net | |
|---|---|---|---|
| Bot | |||
| DDoS | |||
| Infiltration | |||
| DoS | |||
| Web Attacks | |||
| Brute Force |
| Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|
| IDS-INT | ||||
| FFT+depthwise separable convolution | ||||
| Depthwise separable convolution+ResNet | ||||
| FFT+CNN+ResNet | ||||
| Ours |
| Module Combination | Accuracy | Parameter Quantity |
|---|---|---|
| Four Basic Blocks | 300 K | |
| Six Basic Blocks | 500 K | |
| Eight Basic Blocks | 800 K |
| Module | Latency (ms) | Peak RAM (MB) | Model Size (MB) |
|---|---|---|---|
| FFT-RDNet | 1.1 | ||
| ViT | 48.7 | ||
| CNN-BiLSTM | 8.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, B.; Zheng, R.; Zhang, K.; Li, C.; Zheng, J. FFT-RDNet: A Time–Frequency-Domain-Based Intrusion Detection Model for IoT Security. Sensors 2025, 25, 4584. https://doi.org/10.3390/s25154584
Xiang B, Zheng R, Zhang K, Li C, Zheng J. FFT-RDNet: A Time–Frequency-Domain-Based Intrusion Detection Model for IoT Security. Sensors. 2025; 25(15):4584. https://doi.org/10.3390/s25154584
Chicago/Turabian StyleXiang, Bingjie, Renguang Zheng, Kunsan Zhang, Chaopeng Li, and Jiachun Zheng. 2025. "FFT-RDNet: A Time–Frequency-Domain-Based Intrusion Detection Model for IoT Security" Sensors 25, no. 15: 4584. https://doi.org/10.3390/s25154584
APA StyleXiang, B., Zheng, R., Zhang, K., Li, C., & Zheng, J. (2025). FFT-RDNet: A Time–Frequency-Domain-Based Intrusion Detection Model for IoT Security. Sensors, 25(15), 4584. https://doi.org/10.3390/s25154584