
UAV-DETR: An Enhanced RT-DETR Architecture for Efficient Small Object Detection in UAV Imagery

Abstract
1. Introduction
- A lightweight and efficient backbone is developed by introducing the Channel-Aware Sensing (CAS) module, which replaces conventional convolutional blocks with a spatial-channel attention mechanism. This architecture not only enhances small-target detection capability but also substantially decreases parameter volume and computational demands. Experiments show that, compared with the original ResNet-18 backbone, CAS achieves better detection accuracy with lower GFLOPs and fewer parameters.
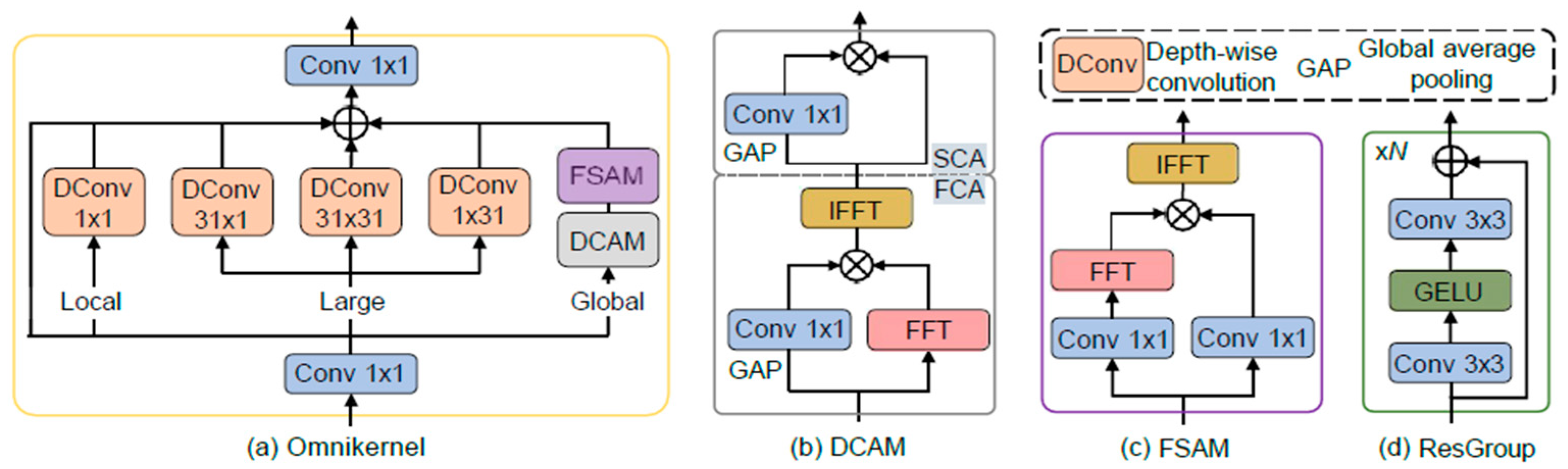
- The Scale-Optimized Enhancement Pyramid (SOEP) is a proposed model that incorporates a small-object detection layer into the original multi-scale feature fusion network. It introduces the concept of Cross Stage Partial (CSP) and OmniKernel network and designs the CSP-OmniKernel module for feature fusion to enhance efficiency in feature representation learning. The CSP-OmniKernel module is engineered to facilitate feature fusion for enhanced detection performance of small targets, ranging from global to local perspectives.
- A unified Context-Spatial Alignment Module (CSAM) is introduced, integrating Contextual Fusion and Calibration (CFC) and Spatial Feature Calibration (SFC) to jointly address semantic inconsistency and spatial misalignment in cross-scale feature fusion.
- Extensive experiments on the VisDrone2019 dataset demonstrate that the proposed UAV-DETR achieves an mAP@0.5 of 51.6%, outperforming the baseline RT-DETR by 3.5%, while maintaining low computational complexity suitable for real-time UAV-based applications.
2. Related Work
2.1. CNN-Based Object Detection
2.2. Transformer-Based Object Detection
2.3. UAV-Specific Detection Methods
2.4. RT-DETR Model
3. Methodology
3.1. UAV-DETR Model
3.2. CasNet
3.3. SOEP Module
3.3.1. SPDConv
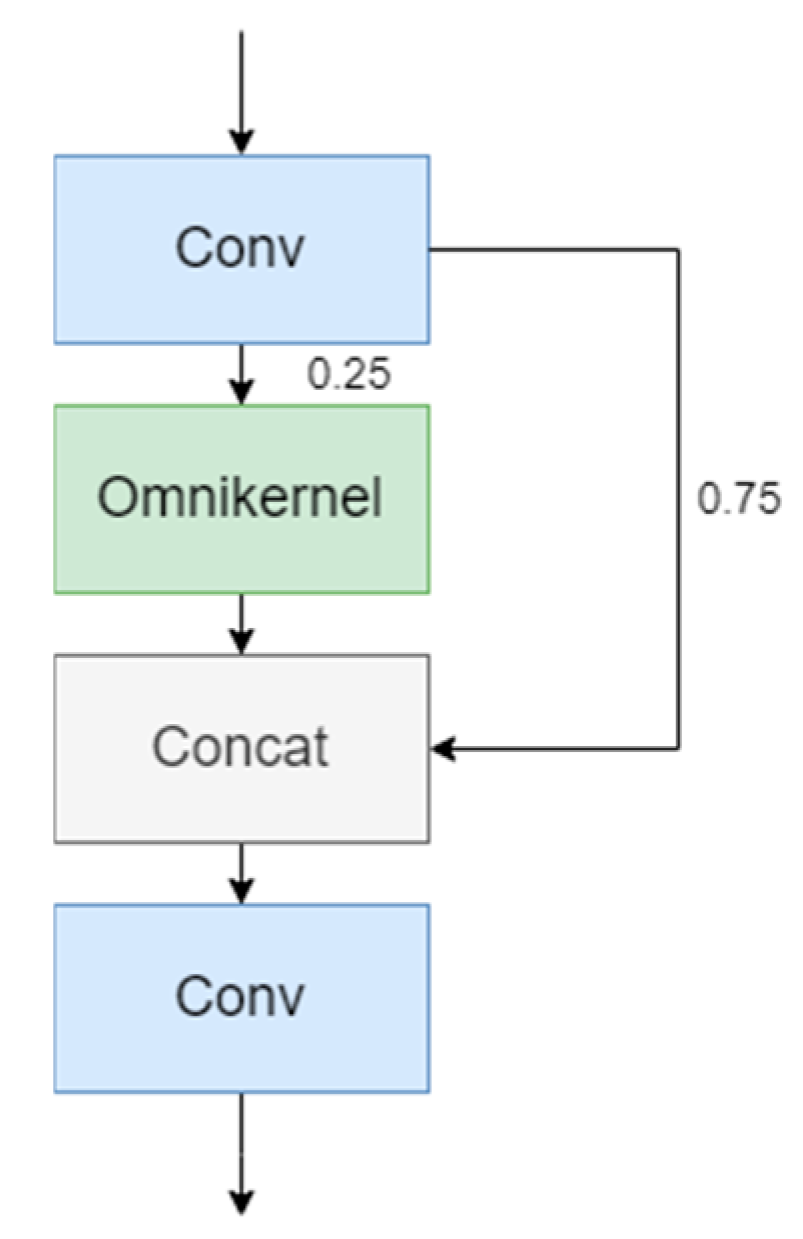
3.3.2. CSP-OmniKernel Module
3.4. CSAM Module
3.4.1. CFC Module
3.4.2. SFC Module
4. Results and Analysis
4.1. Experimental Dataset and Experimental Setup
4.1.1. Experimental Dataset
4.1.2. Experimental Setup
4.2. Evaluation Metrics
4.3. Results and Comparsion
4.3.1. Ablation Study
4.3.2. Comparative Experiment
4.3.3. Generalization Experiments
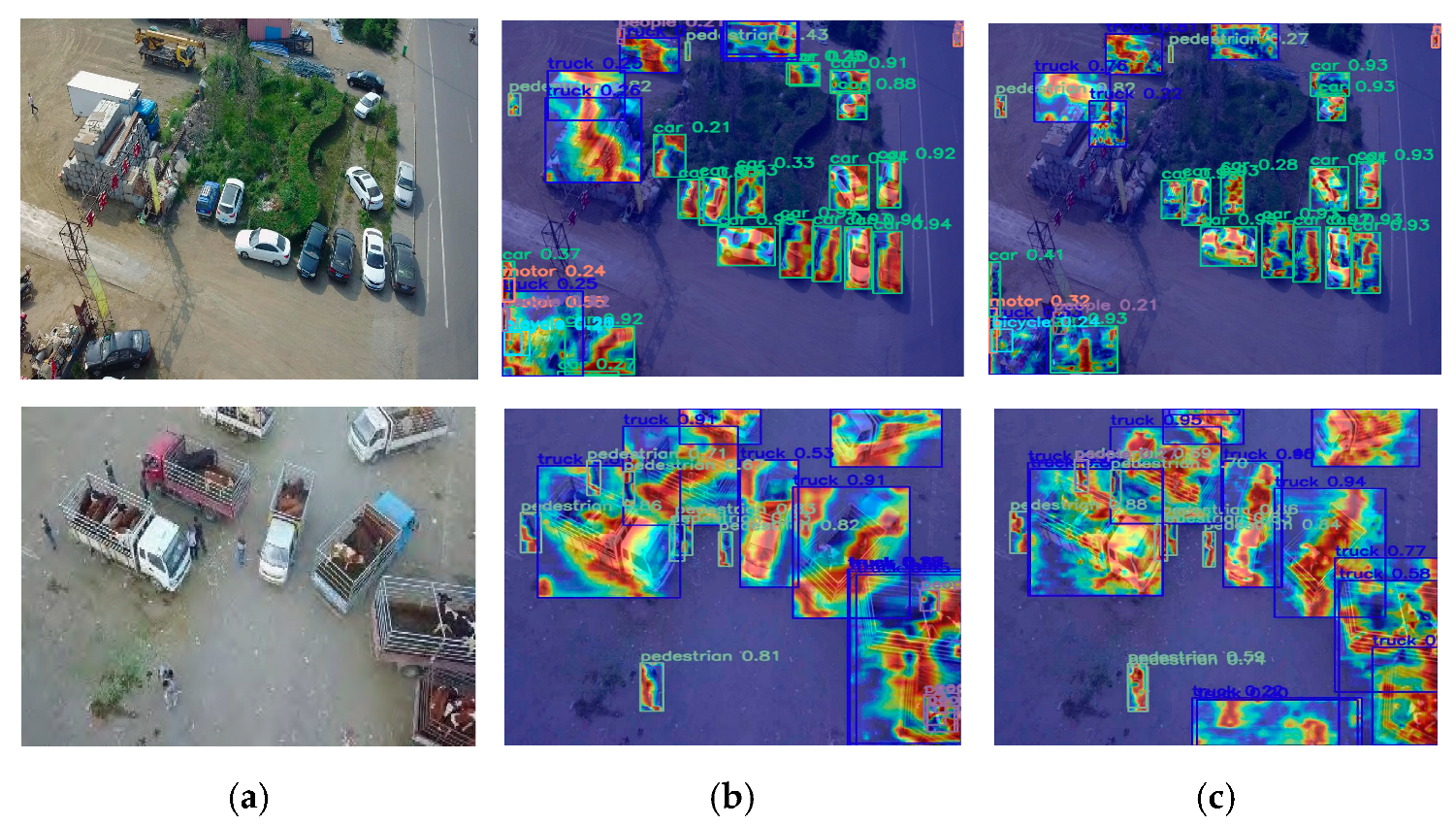
4.3.4. Feature Fusion Visualization Comparison Experiment
4.3.5. Comparison of Detection Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Sahin, O.; Ozer, S. Yolodrone: Improved YOLO architecture for object detection in drone images. In Proceedings of the 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Budapest, Hungary, 15–17 July 2021; pp. 361–365. [Google Scholar]
- Tan, L.; Lv, X.; Lian, X.; Wang, G. YOLOv4_Drone: UAV image target detection based on an improved YOLOv4 algorithm. Comput. Electr. Eng. 2021, 93, 107261. [Google Scholar] [CrossRef]
- Bujagouni, G.K.; Pradhan, S. Transformer-based deep learning hybrid architecture for phase unwrapping. Phys. Scr. 2024, 99, 7. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Roh, B.; Shin, J.; Shin, W.; Kim, S. Sparse DETR: Efficient End-to-End Object Detection with Learnable Sparsity. In Proceedings of the 10th International Conference on Learning Representations (ICLR), Virtual Event, 25–29 April 2022. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. DN-DETR: Accelerate DETR training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–23 June 2022; pp. 13619–13627. [Google Scholar]
- Li, F.; Zhang, H.; Xu, H.; Liu, S.; Zhang, L.; Ni, L.M.; Shum, H.Y. Mask DINO: Towards a unified transformer-based framework for object detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–23 June 2023; pp. 3041–3050. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–22 June 2024; pp. 16965–16974. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; HE, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional DETR for Fast Training Convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 August 2021; pp. 3631–3640. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2022, 20, 2238. [Google Scholar] [CrossRef]
- Chen, S.; Cheng, T.; Fang, J.; Zhang, Q.; Li, Y.; Liu, W.; Wang, X. TinyDet: Accurate Small Object Detection in Lightweight Generic Detectors. arXiv 2023, arXiv:2304.03428. [Google Scholar]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision Meets Drones: A Challenge. arXiv 2022, arXiv:1804.07437. [Google Scholar]
- Yu, H.; Li, G.; Zhang, W.; Huang, Q.; Du, D.; Tian, Q.; Sebe, N. The Unmanned Aerial Vehicle Benchmark: Object Detection, Tracking and Baseline. Int. J. Comput. Vis. 2020, 128, 1141–1159. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Han, J.; Lu, X. Object Detection in Optical Remote Sensing Images: A Survey and a New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Du, Z.; Hu, Z.; Zhao, G.; Jin, Y.; Ma, H. Cross-Layer Feature Pyramid Transformer for Small Object Detection in Aerial Images. arXiv 2024, arXiv:2407.19696. [Google Scholar] [CrossRef]
- Chen, Z. LGI-DETR: Local-Global Interaction for UAV Object Detection. arXiv 2025. [Google Scholar] [CrossRef]
- Zhao, D.; Shao, F.; Yang, L.; Luo, X.; Liu, Q.; Zhang, H.; Zhang, Z. Object Detection Based on an Improved YOLOv7 Model for Unmanned Aerial-Vehicle Patrol Tasks in Controlled Areas. Electronics 2023, 12, 4887. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, K.; Wu, F.; Lv, H. YOLO-PEL: The Efficient and Lightweight Vehicle Detection Method Based on YOLO Algorithm. Sensors 2025, 25, 1959. [Google Scholar] [CrossRef]
- Wei, X.; Yin, L.; Zhang, L.; Wu, F. DV-DETR: Improved UAV Aerial Small Target Detection Algorithm Based on RT-DETR. Sensors 2024, 24, 7376. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W. RFAG-YOLO: A Receptive Field Attention-Guided YOLO Network for Small-Object Detection in UAV Images. Sensors 2025, 25, 2193. [Google Scholar] [CrossRef]
- Wu, S.; Lu, X.; Guo, C.; Guo, H. Accurate UAV Small Object Detection Based on HRFPN and EfficentVMamba. Sensors 2024, 24, 4966. [Google Scholar] [CrossRef]
- Kong, Y.; Shang, X.; Jia, S. Drone-DETR: Efficient Small Object Detection for Remote Sensing Image Using Enhanced RT-DETR Model. Sensors 2024, 24, 5496. [Google Scholar] [CrossRef] [PubMed]
- Baidya, R.; Jeong, H. YOLOv5 with ConvMixer Prediction Heads for Precise Object Detection in Drone Imagery. Sensors 2022, 22, 8424. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Li, L.; Zhou, Y.; Liu, W.; Qian, C.; Hwang, J.N.; Ji, X. Cas-ViT: Convolutional Additive Self-Attention Vision Transformers for Efficient Mobile Applications. arXiv 2024, arXiv:2408.03703. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Cui, Y.; Ren, W.; Knoll, A. Omni-Kernel Network for Image Restoration. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; AAAI Press: Palo Alto, CA, USA, 2024; Volume 38, pp. 1426–1434. [Google Scholar]
- Sunkara, R.; Luo, T. No More Strided Convolutions or Pooling: A New CNN Building Block for Low Resolution Images and Small Objects. In Proceedings of the 22nd Joint European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD 2022), Grenoble, France, 19–23 September 2022; pp. 443–459. [Google Scholar]
- Li, K.; Geng, Q.; Wan, M.; Zhou, Z. Context and Spatial Feature Calibration for Real-Time Semantic Segmentation. IEEE Trans. Image Process. 2023, 32, 5465–5477. [Google Scholar] [CrossRef]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Lin, G.; Millan, A.; Shen, C.; Reid, I. RefineNet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 1925–1934. [Google Scholar]
- Li, X.; Hu, X.; Yang, J. Spatial group-wise enhance: Improving semantic feature learning in convolutional networks. arXiv 2019, arXiv:1905.09646. [Google Scholar]
- Huang, Z.; Wei, Y.; Wang, X.; Liu, W.; Huang, T.S.; Shi, H. Alignseg:Feature-aligned segmentation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 550–557. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Wen, L.; Bian, X.; Lin, H.; Hu, Q. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF international conference on computer vision workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 213–226. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12023–12031. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configurations | Parameters |
|---|---|
| OS | Windows 11 |
| CPU | Intel(R) Core(TM) i9-10920X@3.50 GHz |
| GPU | NVIDIA GeForce RTX 3080 Ti 28 GB |
| CUDA Version | CUDA 12.1 |
| Memory | 32 GB |
| Deep Learning Framework | PyTorch 2.0.0 |
| Name | Parameters |
|---|---|
| Epoch | 500 |
| Batch Size | 4 |
| Input Size | 640 × 640 |
| Initial Learning Rate | 0.0001 |
| Weight Decay Coefficient | 0.0001 |
| Optimizer | AdamW |
| Patience | 30 |
| Number | Models | P | R | mAP@0.5 | mAP@0.5:0.95 | GFLOPs | FPS | Params/106 |
|---|---|---|---|---|---|---|---|---|
| Exp1 | RT-DETR (Baseline) | 61.8 | 47.0 | 48.1 | 29.5 | 57.0 | 45.8 | 19.8 |
| Exp2 | +CasNet | 62.9 | 47.5 | 49.2 | 30.3 | 49.9 | 31.8 | 14.9 |
| Exp3 | +CasNet + SOEP Module | 62.8 | 49.0 | 50.7 | 31.5 | 67.6 | 32.5 | 15.8 |
| Exp4 | +CasNet + SOEP Module + CSAM-Module | 63.2 | 50.5 | 51.6 | 32.1 | 71.4 | 33.0 | 16.8 |
| Backbone | mAP@0.5 | GFLOPs/G |
|---|---|---|
| ResNet18 | 48.1 | 57.0 |
| EfficientViT | 47.9 | 52.6 |
| FasterNet | 47.6 | 54.9 |
| CasNet | 49.2 | 49.9 |
| Model | mAP@0.5 | Params/M | GFLOPs |
|---|---|---|---|
| Faster RCNN | 39.7 | 41.4 | 212.9 |
| YOLOv5l | 38.8 | 46.1 | 107.8 |
| YOLOv6m | 37.2 | 34.8 | 85.6 |
| YOLOv7 | 48.0 | 36.5 | 103.3 |
| YOLOv8m | 43.2 | 25.8 | 78.7 |
| Enhanced YOLOv7 [26] | 52.3 | 35.8 | - |
| CFPT [24] | 50.0 | 51.3 | 297.6 |
| LGI-DETR [25] | 46.0 | 21.1 | 65.0 |
| DV-DETR [28] | 50.2 | 19.5 | 84.6 |
| Drone-DETR [31] | 53.9 | 28.7 | 128.3 |
| RT-DETR (Baseline) | 48.1 | 19.8 | 57.0 |
| UAV-DETR | 51.6 | 16.8 | 71.4 |
| Model | mAP@0.5 | Params/(M) | GFLOPs/G |
|---|---|---|---|
| Faster R-CNN | 67.3 | 136.9 | 804.8 |
| YOLOv7 | 74.5 | 36.6 | 103.4 |
| RT-DETR | 72.2 | 20.1 | 57.0 |
| UAV-DETR | 74.3 | 16.8 | 71.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Wei, Y. UAV-DETR: An Enhanced RT-DETR Architecture for Efficient Small Object Detection in UAV Imagery. Sensors 2025, 25, 4582. https://doi.org/10.3390/s25154582
Zhou Y, Wei Y. UAV-DETR: An Enhanced RT-DETR Architecture for Efficient Small Object Detection in UAV Imagery. Sensors. 2025; 25(15):4582. https://doi.org/10.3390/s25154582
Chicago/Turabian StyleZhou, Yu, and Yan Wei. 2025. "UAV-DETR: An Enhanced RT-DETR Architecture for Efficient Small Object Detection in UAV Imagery" Sensors 25, no. 15: 4582. https://doi.org/10.3390/s25154582
APA StyleZhou, Y., & Wei, Y. (2025). UAV-DETR: An Enhanced RT-DETR Architecture for Efficient Small Object Detection in UAV Imagery. Sensors, 25(15), 4582. https://doi.org/10.3390/s25154582