1. Introduction
The retina, a vital structure located at the back of the eye, plays a fundamental role in vision by converting light signals into electrical impulses through photoreceptor cells, forming the basis of human visual perception. Owing to its delicate nature, the retina is particularly susceptible to a range of ocular diseases, including Diabetic Retinopathy (DR), Age-related Macular Degeneration (AMD), Diabetic Macular Edema (DME), drusen, Central Serous Retinopathy (CSR), and Macular Hole (MH). These conditions can progressively impair vision and severely affect a person’s quality of life if not detected and managed early.
According to the latest World Health Organization (WHO) report published in 2023, an estimated 2.2 billion people worldwide suffer from near- or distant-vision impairment. Among these, 94 million cases are due to cataracts, 7.7 million to glaucoma, 88.4 million to refractive errors, 3.9 million to Diabetic Retinopathy, and 8 million to Age-related Macular Degeneration [
1]. The early and accurate diagnosis of retinal diseases is therefore crucial to preventing severe visual impairment and blindness.
In recent years, Artificial Intelligence (AI) has emerged as a transformative tool in the field of medical imaging (e.g., [
2,
3]), offering the potential to automate the analysis of different imaging modalities such as fundus photography and Optical Coherence Tomography (OCT). These AI-driven systems have proven capable of supporting ophthalmologists in accurately diagnosing retinal conditions, reducing diagnostic workload, and improving screening efficiency. Numerous studies have employed advanced deep learning and machine learning models for disease detection, achieving high diagnostic accuracy and, in many cases, surpassing traditional manual methods [
1,
4,
5,
6,
7].
However, while much of the existing research focuses on classifying and detecting ocular diseases using medical imaging alone, limited work has addressed multi-label disease prediction or incorporated clinical risk factors and textual patient data. Furthermore, predictive models capable of forecasting the progression of these diseases over time remain underexplored. Developing such predictive frameworks could significantly improve early intervention strategies and personalized treatment planning, ultimately reducing the risk of vision loss.
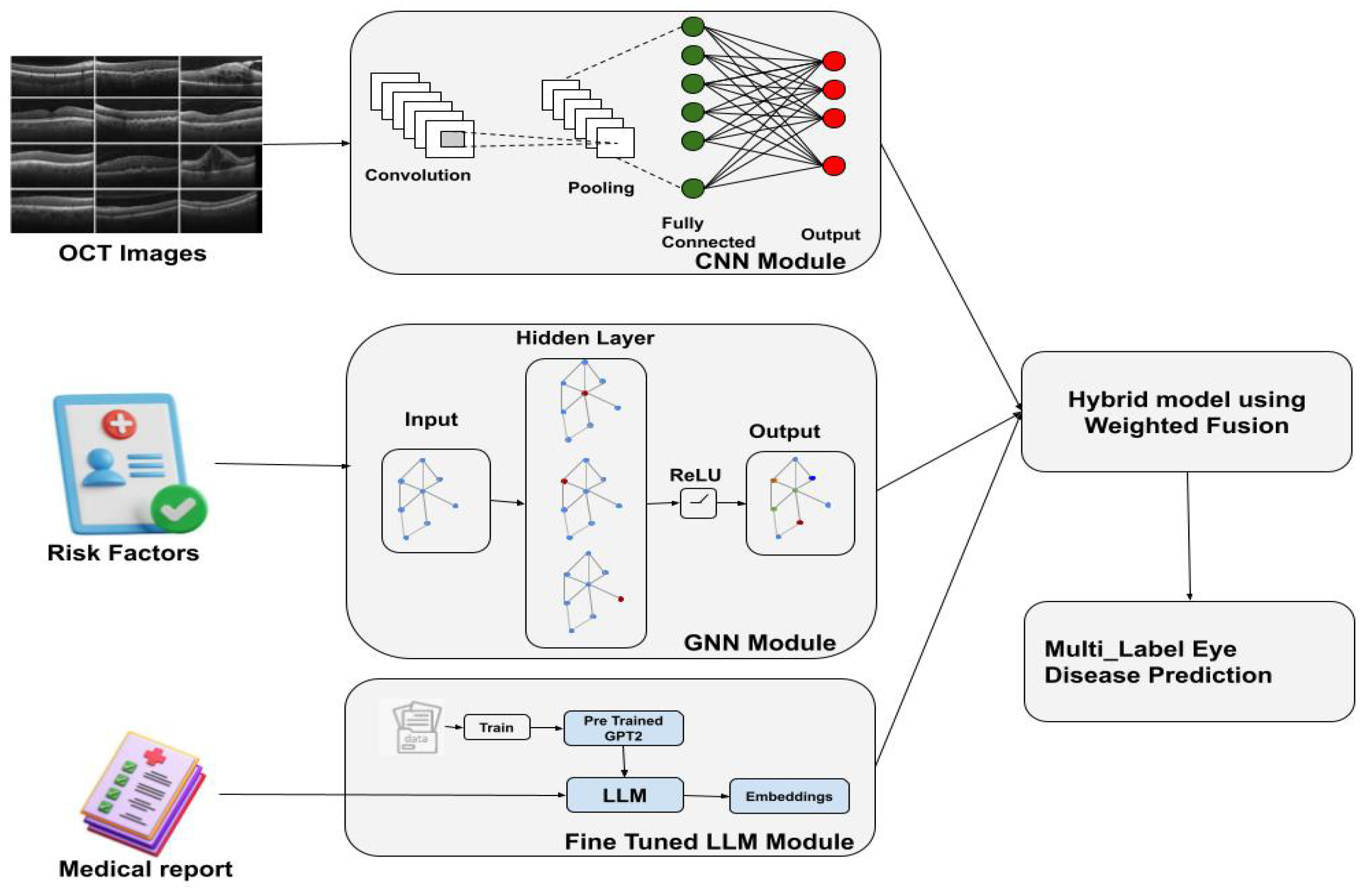
To address this gap, this study proposes VisionTrack, a novel multi-modal AI framework designed for multi-label ocular disease prediction. VisionTrack integrates a Convolutional Neural Network (CNN) to extract discriminative features from retinal images, a Graph Convolutional Network (GCN) to capture complex interrelations among key clinical risk factors such as age, diabetes status, hypertension, and disease duration, and a Large Language Model (LLM) to analyze unstructured textual data from patient medical reports. By effectively combining these heterogeneous data sources, VisionTrack improves predictive accuracy, enables the simultaneous prediction of multiple ocular conditions, and provides a more holistic and personalized assessment of retinal health.
The remainder of this paper is organized as follows:
Section 2 reviews the related work on retinal diseases, including dedicated subsections for Age-related Macular Degeneration (
Section 2.1), Diabetic Retinopathy (
Section 2.2), Diabetic Macular Edema (
Section 2.3), drusen (
Section 2.4), Central Serous Retinopathy (
Section 2.5), and Macular Hole (
Section 2.6).
Section 3 presents the proposed multi-modal AI framework, while
Section 4 describes the experimental setup and the datasets used and discusses the performance of the proposed method in comparison with state-of-the-art techniques. Finally,
Section 5 concludes the paper and outlines future research directions.
2. Background
We provide a comprehensive review of existing approaches for disease prediction using medical images and the application of advanced AI techniques for six major retinal diseases: Diabetic Retinopathy (DR), Age-related Macular Degeneration (AMD), Diabetic Macular Edema (DME), drusen, Central Serous Retinopathy (CSR), and Macular Hole (MH).
2.1. Age-Related Macular Degeneration
Age-related Macular Degeneration (AMD) is a major cause of vision loss worldwide, necessitating early and precise diagnosis. Advances in Artificial Intelligence (AI), particularly deep learning and machine learning, have led to substantial improvements in AMD detection using fundus images and Optical Coherence Tomography (OCT). This paper summarizes key studies that employ AI methodologies for diagnosing AMD, analyzing their objectives, datasets, and outcomes. The reviewed studies utilize Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), and hybrid AI models to enhance classification accuracy and interpretability. The results demonstrate promising performance, achieving high sensitivity, specificity, and accuracy, underscoring AI’s potential in ophthalmology.
Several studies have explored AI-driven approaches for AMD detection. El-Sharkawy et al. [
8] developed an explainable AI system for AMD grading using OCT images, achieving 90.82% accuracy in a multi-way classification task. Abd El-Khalek et al. [
9] introduced a novel ML-based classification framework for AMD diagnosis from fundus images, achieving 96.85% accuracy. Yang et al. [
10] proposed an ensemble deep learning model integrating multiple CNN architectures for dry AMD classification, significantly improving accuracy. Le et al. [
11] designed ViT-AMD, a Vision Transformer-based model for AMD diagnosis, achieving superior performance compared to CNN-based models. Chen et al. [
12] developed a deep learning model to generate ICGA images from fundus photographs using GANs, enhancing AMD classification accuracy.
Table 1 summarizes the related work introduced in this section.
2.2. Diabetic Retinopathy
Diabetic Retinopathy (DR) is a leading cause of vision impairment globally, necessitating early and precise diagnosis. Advances in Artificial Intelligence (AI), particularly deep learning and machine learning, have significantly improved DR detection using fundus images and Optical Coherence Tomography (OCT). This paper summarizes key studies that employ AI methodologies for diagnosing DR, analyzing their objectives, datasets, and outcomes. The reviewed studies utilize Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), Graph Neural Networks (GNNs), and hybrid AI models to enhance classification accuracy and interpretability. The results demonstrate promising performance, achieving high sensitivity, specificity, and accuracy, underscoring AI’s potential in ophthalmology.
Several studies have explored AI-driven approaches for DR detection. Akram et al. [
13] developed a Bayesian deep learning model integrating Monte Carlo Dropout and Variational Inference to enhance uncertainty estimation, achieving 97.68% accuracy on the APTOS 2019 and DDR datasets. Liu et al. [
14] introduced a Vision Transformer model incorporating softmax-pooling operators, outperforming CNN-based models in DR grading. Wong et al. [
15] proposed a transfer learning approach combining ShuffleNet and ResNet-18 with an ECOC ensemble, reaching 96% accuracy in binary classification. Maaliw et al. [
16] presented a segmentation-based DR detection system using DR-UNet and an attention-aware CNN, achieving a high accuracy of 99.2% on DiaretDB0 and DiaretDB1 datasets. In a recent study, Zedadra et al. [
17] demonstrated the value of using complementary data alongside images to improve classification performance. Specifically, they introduced a risk factor: the duration of diabetes. By employing a model that combines a Convolutional Neural Network (CNN) with a Graph Neural Network (GNN), they achieved very promising results. Sumod and Sumathy [
18] developed a graph-based AI model for DR grading using fundus images, achieving superior performance in feature extraction. Poranki and Rao [
19] introduced an XGBoost-based classification framework for DR diagnosis, attaining 99.6% accuracy. Zhang et al. [
20] proposed a multi-model domain adaptation approach for unsupervised DR classification, showing improved generalizability. Feng et al. [
21] designed a GNN-CNN hybrid model for DR grading, significantly enhancing feature relationship capture. Shamrat et al. [
22] developed DRNet13, a CNN-based model that outperformed traditional architectures with 97% accuracy. Dhinakaran et al. [
23] introduced a semi-supervised graph learning method to handle imbalanced datasets, improving DR risk prediction.
Table 2 summarizes the related work introduced in this section.
2.3. Diabetic Macular Edema
The early detection of DME is essential, as it can prevent over 95% of vision loss associated with the condition or at least slow its progression through timely interventions. DME is marked by various abnormalities in the retinal vasculature, such as retinal edema, hard exudates, retinal hemorrhages, and intraretinal microvascular anomalies [
24].
Several studies have explored AI-driven approaches for Diabetic Macular Edema (DME) detection. Fu [
24] introduced the Multi-feature Decomposition Fusion Attention Network (MDFANet) for DME classification in multicolor imaging. The model integrates a Lite Transformer and an Invertible Neural Network to capture multi-frequency features, improving detection accuracy. Zhang et al. [
25] developed a deep learning model using ultra-widefield fundus imaging for referable DR and DME detection. Their approach, based on EfficientNet and ResNet, demonstrated robust performance in large-scale automated screening.
Wu et al. [
26] designed a deep learning framework to detect morphological patterns of DME from OCT images. Their model achieved high accuracy in identifying diffused retinal thickening, cystoid macular edema, and serous retinal detachment. Saidi et al. [
27] implemented a CNN-based model for the automatic detection of AMD and DME, obtaining over 99% accuracy on the Duke dataset. Tripathi et al. [
28] proposed a GAN-based model to generate synthetic OCT B-Scan images for DME detection. By leveraging StyleGAN and CycleGAN, they improved the robustness of automated diagnostic models. Thanikachalam et al. [
29] developed an optimized deep CNN for DR and DME classification, incorporating adaptive Gabor filters and Random Forest-based feature selection. Their method achieved 97.91% accuracy on benchmark datasets. Nazir et al. [
30] introduced a CenterNet-based deep learning model for DME detection from retinal images. By using DenseNet-100 for feature extraction, their system outperformed traditional CNN architectures.
Table 3 summarizes the related work introduced in this section.
2.4. Drusen
Recent advances in AI-based drusen detection have focused on segmentation, classification, and the grading of drusen patterns in retinal images. Goyanes et al. [
31] introduced a fully automatic 3D deep learning-based segmentation method for detecting drusen in OCT images, significantly improving diagnostic workflows. Omar et al. [
32] introduced a classification approach using bagged color vector angles for exudate and drusen differentiation. Ilyasova et al. [
33] focused on the recognition of drusen subtypes in OCT images for diagnosing Age-related Macular Degeneration (AMD). The authors proposed a segmentation-based method to extract drusen from images and classify them based on reflectivity features. Nowomiejska et al. [
34] proposed a Residual Attention Network to distinguish optic disc drusen from healthy optic discs.
Table 4 summarizes the related work introduced in this section.
2.5. Central Serous Retinopathy
Central Serous Retinopathy (CSR), also known as Central Serous Chorioretinopathy (CSC), is a serious eye condition that affects millions of people globally, often leading to vision loss or even blindness. It occurs due to the buildup of fluid beneath the retina. Early detection is crucial, as it enables timely intervention to prevent lasting damage to vision. While traditional manual diagnostic methods have been used, they often lack accuracy and reliability. As a result, advancements in Artificial Intelligence have paved the way for more effective and automated approaches to CSR detection and treatment Hassan et al. [
35].
Recent advances in the AI-based detection of CSR have focused on automated diagnosis using fundus and OCT images and distinguishing between acute and chronic CSC subtypes. Zhen [
36] proposed a deep learning method based on the InceptionV3 model for classifying CSC from color fundus photographs. Their system outperformed human ophthalmologists in terms of accuracy and agreement scores. Yoon et al. [
37] introduced a deep learning system trained on spectral-domain Optical Coherence Tomography (SD-OCT) images to diagnose CSC and differentiate between acute and chronic forms. The model showed high diagnostic accuracy and performance comparable to or superior to that of expert clinicians. Hassan et al. [
38] presented a comprehensive framework using modified DenseNet and DarkNet classifiers trained on OCT and fundus images, achieving state-of-the-art performance in CSR detection. The work in [
39] proposed a deep learning approach using ResNet50 CNNs on multiple OCT modalities to predict the 6-month persistence of CSC, achieving up to 95.2% accuracy by combining B-scan and retinal thickness images.
Table 5 summarizes these AI-based approaches.
2.6. Macular Hole
Macular Hole (MH) is a serious retinal disorder that compromises central vision and requires timely, accurate diagnosis for effective treatment. With an estimated prevalence of 7 per 100,000 individuals globally, the need for reliable diagnostic tools is critical. This study aims to develop an AI model capable of accurately differentiating MH from normal cases using Optical Coherence Tomography (OCT) scans. The goal is to provide ophthalmologists with a fast, precise diagnostic aid that facilitates early detection and enhances clinical decision-making and patient outcomes Bolanos et al. [
39].
Recent advances in the AI-based detection of Macular Hole (MH) have explored both segmentation and classification techniques using Optical Coherence Tomography (OCT) images. Shahalinejad [
40] proposed a hybrid method combining multilevel thresholding and derivation-based edge detection for MH diagnosis from OCT images. Their technique demonstrated improved sensitivity and accuracy over conventional image processing methods. More recently, Ko [
41] introduced a deep learning-based multi-image classification model for assessing central serous chorioretinopathy (CSC), achieving expert-level performance in distinguishing acute, chronic, and normal cases from multiple SD-OCT images. While their focus was CSC, the multi-scan ensemble architecture has direct implications for future AI-based MH detection systems.
Table 6 summarizes these AI-based approaches.
3. Hybrid Multi-Modal Eye Disease Prediction System
The proposed approach is a hybrid multi-modal model designed to predict multiple eye diseases simultaneously (
Figure 1). It focuses on six common conditions:
Diabetic Macular Edema (DME), Diabetic Retinopathy (DR), Age-related Macular Degeneration (AMD), Central Serous Retinopathy (CSR), Macular Hole (MH), and drusen. The system integrates information from three sources:
A Convolutional Neural Network (CNN) for feature extraction from retinal images.
A Graph Neural Network (GNN) for processing patient metadata and risk factors.
A Large Language Model (LLM) for analyzing unstructured clinical text from medical reports.
3.1. Data Preprocessing
The proposed approach, as the first step, involves some data preprocessing, which has to be carried out in order to optimize input sequences to the proposed hybrid model. In particular, this involves the following:
Retinal Images: These images are preprocessed through a series of steps to normalize and augment the data. The transformations include resizing the images to a standard size, normalization based on mean and standard deviation values (such as ; ), and data augmentation techniques like random horizontal flipping, rotation, and brightness adjustments to increase data diversity and reduce overfitting.
Risk Factor Metadata: Clinical features such as age, hypertension (HTA), diabetes (diabetic status, duration), smoking, and dyslipidemia are preprocessed by normalizing the values into numerical vectors. Each clinical feature
is normalized as follows:
where
and
are the mean and standard deviation of the feature
in the dataset.
Medical Reports: The unstructured text data from medical reports is preprocessed using natural language processing (NLP) techniques, including tokenization, stopword removal, and vectorization (e.g., using word embeddings or transformers) to convert the text into numerical features that can be used by the model.
3.2. Model Architecture
The model consists of three main components, each processing different modalities:
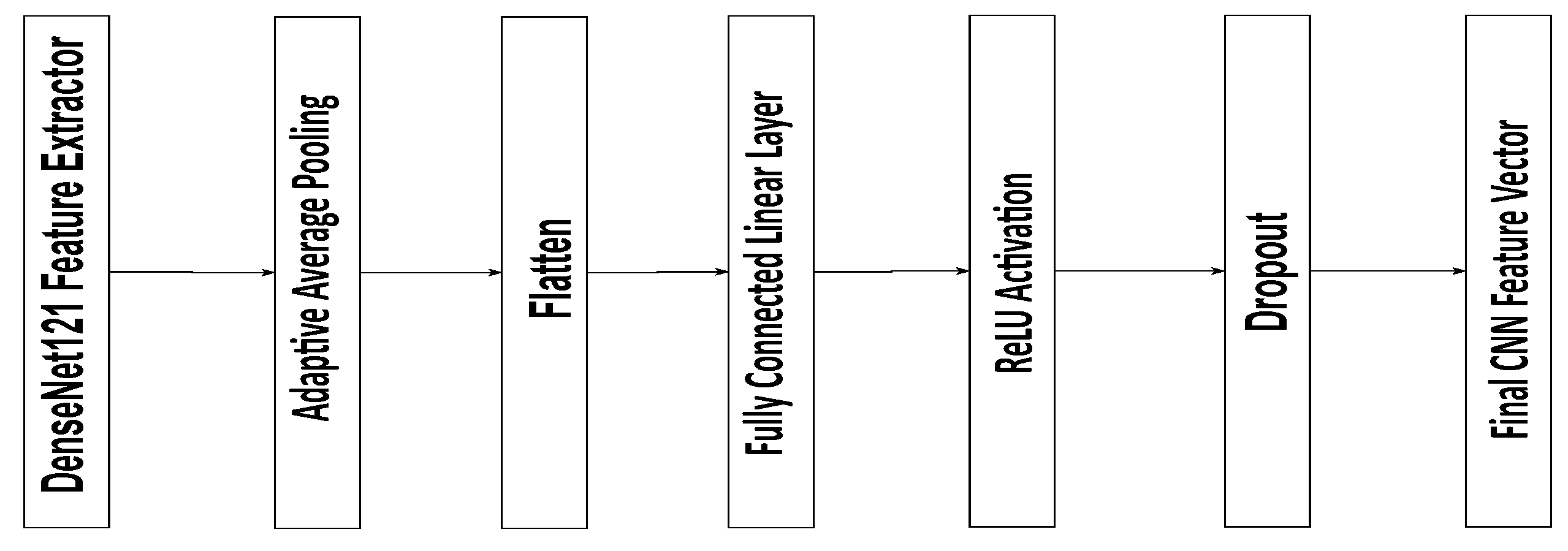
Convolutional Neural Network (CNN) for Retinal Image Feature Extraction: The CNN extracts features from retinal images, typically using a pre-trained backbone such as DenseNet or ResNet. The input image
I is passed through several convolutional layers to obtain a high-level representation
:
The output of the CNN is then passed through fully connected layers to obtain a final feature vector, , representing the image’s characteristics.
The CNN module in the proposed model is based on a pre-trained DenseNet121 architecture used for feature extraction from retinal images. The extracted feature maps are first processed through an Adaptive Average Pooling layer, reducing their spatial dimensions to a single value per channel. The resulting pooled features are then flattened into a one-dimensional vector of the size 1024. This vector passes through a fully connected linear layer that preserves the 1024 feature dimensions, followed by a ReLU activation to introduce non-linearity and a Dropout layer with a 0.5 probability to prevent overfitting. The final output is a 1024-dimensional feature vector representing the high-level image features, which is subsequently used for disease classification and integrated into the multi-modal fusion process of the model (
Figure 2).
Graph Neural Network (GNN) for Clinical Data Integration: The clinical features, including risk factors like age, hypertension, and smoking, are encoded as node features in a graph. Each patient is represented as a node, and edges are created based on relationships between patients, such as shared disease history or similar demographics. The node features are updated through graph convolutions. The graph convolution operation is given by
where
is the normalized adjacency matrix of the graph,
is the feature matrix in layer
l,
is the learned weight matrix, and
is the activation function (e.g., ReLU or SiLU).
The final output from the GNN is a feature representation of the clinical data, which is combined with the retinal image features.
The GNN module receives input node features formed by concatenating the 1024-dimensional CNN feature vectors, four binary clinical variables, and embedded continuous features for age and diabetes duration. These combined features are passed through a first GCNConv layer that projects them to 256 dimensions, followed by Batch Normalization, ReLU activation, and Dropout for regularization. A second GCNConv layer then expands the feature dimension to 1024. Finally, a global mean pooling operation aggregates the node-level features into a single 1024-dimensional vector, representing the integrated image-clinical profile for disease prediction.
Large Language Model (LLM) for Medical Report Analysis: The LLM processes the unstructured clinical text data (e.g., physicians’ reports) to extract contextual information relevant to the eye disease prediction. The text data is tokenized and passed through the model to generate embeddings that capture the semantic meaning of the reports. These embeddings are represented as
:
These embeddings are integrated with the retinal and clinical features in the final decision-making stage.
3.3. Fusion and Prediction
The features obtained from the three modalities—retinal images, clinical metadata, and medical reports—are fused together into a single representation,
:
This fused representation is passed through a series of fully connected layers to output a prediction vector:
where
W is the weight matrix,
b is the bias, and
is the sigmoid activation function. The final prediction
gives the probability of each of the diseases in the multi-class setting.
3.4. Medical Rule Application
To enhance the clinical validity of the prediction system, a set of expert-defined clinical rules was applied as a postprocessing step. These rules were established in collaboration with an experienced ophthalmologist based on current clinical practice guidelines and epidemiological evidence. The rules adjust the raw multi-label prediction vector based on patient-specific metadata (e.g., age, diabetes status, hypertension) to eliminate medically implausible predictions and improve clinical coherence.
The adjusted predictions are computed as follows:
where
R is a rule-based binary mask vector derived from patient clinical metadata and the expert clinical rules listed below.
Each element of R is set to 0 if the corresponding disease prediction should be suppressed based on the clinical context and 1 otherwise.
This adjustment step ensures that the final model outputs remain consistent with medical knowledge and real-world clinical expectations.
The following clinical rules were defined and validated by an ophthalmologist for use in this study:
If Diabetes = No, set Diabetic Retinopathy (DR) and Diabetic Macular Edema (DME) predictions to 0.
If Age < 50, set Age-related Macular Degeneration (AMD) prediction to 0.
If Hypertension = No, reduce the risk prediction for Retinal Vein Occlusion (RVO)-related diseases.
If Smoking History = No, reduce the risk prediction for AMD and Central Serous Retinopathy (CSR).
If Duration of Diabetes < 5 years, suppress severe DR grade predictions.
4. Experiments
4.1. Dataset
We utilized two distinct datasets: the RFMiD and the Retinal OCT dataset. The former comprises fundus images, while the latter includes both fundus and OCT images, providing diverse modalities for comprehensive retinal disease analysis. Furthermore, we selected a subset of seven categories (DME, DR, AMD, CSR, MH, drusen, and normal) from both the RFMID and Retinal OCT dataset to address potential class imbalance issues and focus on the most prevalent and clinically significant retinal conditions.
4.1.1. RFMID Dataset
The Retinal Fundus Multi-disease Image Dataset (RFMiD) comprises 3200 fundus images acquired using three distinct fundus cameras. Each image is annotated with one or more of 46 retinal conditions, based on the adjudicated consensus of two experienced retinal specialists [
42]. The dataset is split into three subsets as suggested by the dataset creators: 60% (1920 images) for training, 20% (640 images) for evaluation, and 20% (640 images) for testing. The fundus images were captured using non-invasive fundus cameras while the patient was seated upright. The distance between the lenses and the examined eye was maintained at 39 mm for the Kowa VX-10 (Kowa Company, Ltd., Nagoya, Japan) and 40.7 mm for the TOPCON 3D OCT-2000 and TOPCON TRC-NW300 devices (Topcon Positioning Systems, Inc., Tokyo, Japan). The dataset includes images acquired with three camera models: the Nikon D7000 (Nikon Corporation, Tokyo, Janpan) digital camera (used with the TOPCON 3D OCT-2000), the Nikon D70s digital camera (used with the Kowa VX-10
), and an integrated digital CCD camera (used with the TOPCON TRC-NW300). The corresponding image resolutions are 2144 × 1424 pixels for TOPCON 3D OCT-2000, 4288 × 2848 pixels for Kowa VX-10
, and 2048 × 1536 pixels for TOPCON TRC-NW300. The field of view (FOV) ranges from 45° to 50°, and both high-quality and low-quality images are deliberately included to increase the dataset’s complexity and reflect real-world variability.
4.1.2. Retinal OCT Dataset
The Retinal OCT-8 Classes dataset comprises 24,000 Optical Coherence Tomography (OCT) images, each labeled across eight distinct retinal disease categories. It is designed to support research and model training in retinal disease classification using machine learning and deep learning techniques [
43]. The dataset is also split according to the recommendations of its creators: 75% for training (18,400 images), 15% for validation (2800 images), and 15% for testing (2800 images). The images in the OCT dataset are of varying sizes but are consistently provided in JPEG format.
4.2. Evaluation Settings
Through extensive experimentation, we carefully tuned the hyperparameters to achieve optimal performance, balancing convergence speed, stability, and generalization while minimizing overfitting. We employed a systematic validation process, including k-fold cross-validation (with k = 5) and Bayesian optimization (via Optuna), to identify the best hyperparameters for our models.
For both the RFMiD (fundus images) and Retinal OCT (OCT images) dataset, we explored a range of learning rates, including 0.0005, 0.0002, 0.0001, 0.005, 0.002, 0.001, and 0.01. After extensive testing, a learning rate of 0.0001 was selected, as it provided the most favorable balance between convergence speed, training stability, and generalization. The number of training epochs was systematically evaluated within a range from 1 to 100, and we determined that 30 epochs achieved optimal performance without signs of overfitting. In addition, batch sizes of 16, 32, and 64 were tested, with 32 being chosen as the ideal value for balancing model generalization, training efficiency, and memory usage.
The hyperparameters explored and the selected values are summarized in
Table 7.
4.3. Results
To evaluate the performance of the model, we use four metrics, including the following:
Accuracy: The proportion of correctly predicted labels out of all predictions.
where
is the indicator function that equals 1 when the predicted label is correct.
Precision, Recall, and F1-Score: These metrics are calculated for each disease class and averaged to provide an overall performance measure. The precision, recall, and F1-score for each class are computed as follows:
where TP, FP, and FN represent the true positives, false positives, and false negatives, respectively.
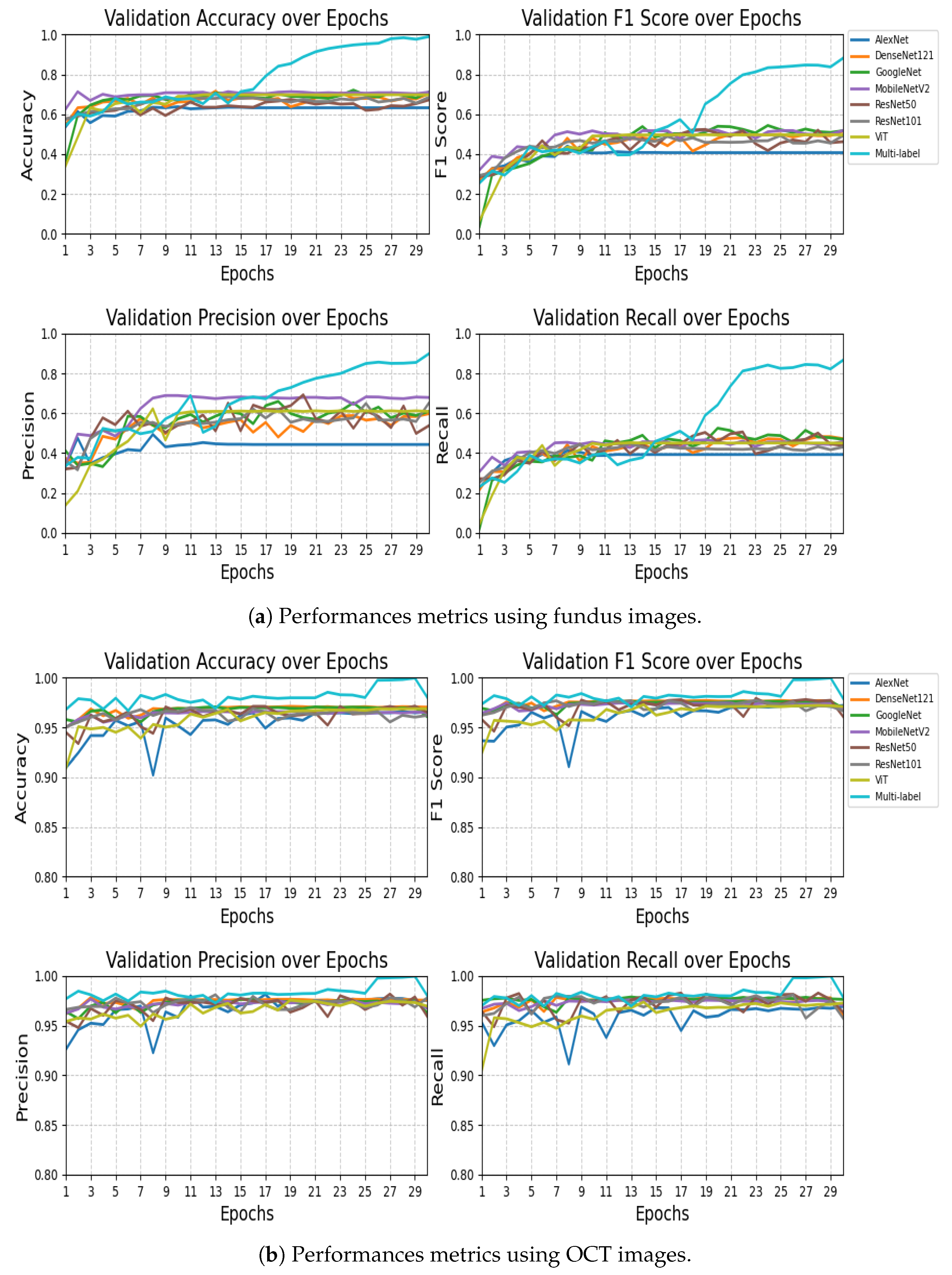
4.3.1. Comparison with the Baseline Models
The performance comparison results presented in
Table 8 and
Table 9 highlight the effectiveness of the proposed VisionTrack model relative to a range of established baseline models. On the RFMiD dataset (
Table 8), VisionTrack significantly outperformed all other models across every evaluation metric. While the best baseline models, MobileNet and GoogleNet, achieved an accuracy of 0.710 and F1-scores of approximately 0.518 and 0.517, respectively, VisionTrack obtained a markedly higher accuracy of 0.989 and an F1-score of 0.881. Similarly, VisionTrack recorded superior precision (0.897) and recall (0.866), exceeding the highest baseline precision (0.679 with MobileNet) and recall (0.472 with DenseNet121).
On the Retinal OCT dataset (
Table 9), although the baseline models performed relatively well, with accuracies ranging from 0.960 to 0.970 and F1-scores between 0.960 and 0.972, VisionTrack still demonstrated the highest performance across all metrics. Specifically, VisionTrack achieved an accuracy of 0.980, a precision of 0.979, a recall of 0.978, and an F1-score of 0.979. Notably, DenseNet121 was the strongest baseline with an accuracy of 0.970 and an F1-score of 0.967, yet it remained slightly behind VisionTrack. These consistent improvements across two diverse ophthalmic datasets confirm the robustness, reliability, and generalizability of the VisionTrack architecture in comparison to conventional CNN and Transformer-based models.
4.3.2. Comparison with Other State-of-the-Art Methods
Table 10 compares the VisionTrack with other methods from the state of the art.
4.3.3. Discussion
The experimental results presented in
Table 10 demonstrate the clear superiority of VisionTrack over existing state-of-the-art methods across both the RFMiD and Retinal OCT dataset. Firstly, VisionTrack consistently outperformed other approaches in terms of
accuracy, achieving
on the RFMiD and
on the Retinal OCT dataset. This performance indicates its strong capability to correctly classify a wide range of ocular diseases, surpassing previous leading models such as DFex-BeeHive [
44] and DSAN-PL [
46]. In addition to accuracy, VisionTrack exhibited superior
specificity, notably reaching
on the RFMiD and
on the Retinal OCT dataset. High specificity is crucial in medical diagnosis, as it minimizes false positive rates, reducing the likelihood of healthy individuals being incorrectly diagnosed with eye diseases. This performance illustrates VisionTrack’s capacity to reliably exclude non-diseased cases, enhancing clinical trust in its predictions. Moreover, the framework achieved an
F1-score of
on the RFMiD and
on the Retinal OCT dataset, outperforming competing methods. The F1-score, which balances precision and recall, confirms VisionTrack’s ability to maintain both a high true positive rate and precision, ensuring both sensitivity to actual disease cases and robustness against over-predicting positive results. A key factor contributing to these outcomes is the
multi-modal architecture of VisionTrack, which integrates CNN-based image analysis, the GNN-based relational modeling of patient clinical data, and the LLM-driven interpretation of diagnostic reports. This combination allows the system to capture complementary patterns from heterogeneous data sources, providing a richer and more contextualized understanding of each patient case compared to unimodal models.
This study is limited by the use of the Retinal OCT-8 dataset, which is of low quality, with very little known about its provenance, particularly regarding image augmentation and the potential risk of data leakage between training and test sets.
4.4. Statistical Tests
To evaluate whether the performance differences between the proposed VisionTrack model and the baseline models were statistically significant, we conducted appropriate statistical tests. Specifically, we compared model performance across multiple runs using paired t-tests on key metrics: accuracy, F1-score, recall, and precision.
4.4.1. Statistical Tests for Multi-Label Fundus Model
Table 11 presents the paired
t-test results comparing Multi-label Fundus against other models.
The statistical analysis reveals that Multi-label Fundus significantly outperformed all baseline models across every metric, with extreme significance values ranging from to . The performance advantage was particularly notable in accuracy (26.81% to 65.37% improvement) and F1-score (34.38% to 62.63% improvement), demonstrating the framework’s superior classification capabilities. While MobileNetV2 achieved the highest precision among baseline models (0.6889), it still fell substantially short of Multi-label Fundus’s 0.8976 precision (). The consistently extreme significance values (21/28 tests showing ) provide overwhelming evidence that Multi-label Fundus represents a major advancement over conventional architectures for this task. These results validate the exceptional effectiveness of the Multi-label Fundus approach, which maintained robust performance across all evaluation metrics while traditional models exhibited limitations in either precision or recall.
4.4.2. Statistical Tests for Multi-Label OCT Model
Table 12 presents the paired
t-test results comparing Multi-label OCT against other models.
The statistical analysis demonstrates that Multi-label OCT achieved significantly superior performance compared to all baseline models, with extreme significance values () across all metrics. The performance gap was most dramatic in the final epochs, where Multi-label OCT reached near-perfect accuracy (0.9997) compared to the best baseline (DenseNet121 at 0.9709). This represents an absolute improvement of 2.88% in accuracy and 2.23% in F1-score over the strongest conventional architecture. The precision advantage was particularly noteworthy, with Multi-label OCT achieving 0.9997 precision versus 0.9811 for ResNet101 (). All 28 statistical tests showed p-values below 1 × 10−13, with 24/28 below 1 × 10−15, providing overwhelming evidence for the superiority of the Multi-label OCT approach. The model’s exceptional performance is consistent across all metrics, avoiding the precision-recall tradeoffs observed in baseline models (e.g., Vision Transformer’s 2.15% lower recall compared to its precision). These results validate Multi-label OCT as a substantial advancement in ophthalmic image analysis, particularly in its ability to maintain robust performance throughout all training epochs while conventional models plateau earlier.
5. Conclusions and Future Work
Retinal diseases remain among the leading causes of vision loss worldwide, with many patients presenting multiple co-occurring conditions in real-world clinical practice. Although existing computer-aided diagnostic systems have shown promising results, most are limited to detecting individual diseases such as Diabetic Retinopathy (DR) or Age-Related Macular Degeneration (AMD). Moreover, challenges such as the long-tailed distribution of disease cases and frequent label co-occurrence complicate accurate and reliable diagnosis [
25].
To address these limitations, this study proposed a multi-modal AI framework that integrates a Convolutional Neural Network (CNN) for OCT image feature extraction, a Graph Neural Network (GNN) for modeling complex relationships among clinical risk factors (including hypertension, diabetes duration, dyslipidemia, smoking status, and age), and a Large Language Models (LLM) for analyzing patient medical reports. This hybrid system facilitates multi-label prediction of retinal diseases such as DME, DR, AMD, drusen, CSR and MH, offering a more comprehensive and accurate assessment of retinal health.
Experimental evaluations demonstrated that the proposed framework outperformed existing methods, achieving high accuracy, F1-scores, recall, precision, and specificity across two public datasets. These results confirm the robustness and clinical applicability of the approach, providing an interpretable and effective solution for early detection and personalized ophthalmic care.
Looking ahead, future work will aim to enhance model performance by incorporating larger and more diverse datasets, conducting real-time clinical validation, and further optimizing the system’s ability to predict disease progression over time. Additionally, we envisage extending this approach to integrate multi-modal imaging data, combining both fundus photographs and OCT images, to improve diagnostic precision and capture complementary disease-related information. These advancements could pave the way for more effective early intervention strategies and precision medicine in ophthalmology. Also, we plan to integrate VisionTrack into clinical workflows by enabling real-time analysis directly from retinography devices that provide fundus/OCT images and clinical data, with results presented through automatically generated medical reports to support timely and informed decision-making.
Author Contributions
Conceptualization, A.Z., M.Y.S.-S. and O.Z.; methodology, A.Z., M.Y.S.-S. and O.Z.; software, A.Z.; validation, A.Z. and M.Y.S.-S.; formal analysis, A.Z. and O.Z.; investigation, A.Z. and O.Z.; data curation, A.Z. and O.Z.; writing—original draft preparation, A.Z. and M.Y.S.-S.; writing—review and editing, A.Z., O.Z. and A.G.; supervision, A.Z., O.Z., and A.G.; project administration, O.Z. and A.G.; funding acquisition, A.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been partially supported by the European Union NextGenerationEU National Recovery and Resilience Plan (Piano Nazionale di Ripresa e Resilienza, PNRR)—Project: “SoBigData.it—Strengthening the Italian RI for Social Mining and Big Data Analytics”—Prot. IR0000013-Avviso n. 3264 del 28/12/2021.
Data Availability Statement
Restrictions apply to the availability of these data. Data was obtained from third party and are available from the authorswith the permission of third party [
42,
43].
Conflicts of Interest
The authors declare no conflict of interest.
Nomenclature
| Diabetic Retinopathy |
| Age-related Macular Degeneration |
| Diabetic Macular Edema |
| Central Serous Retinopathy |
| Macular Hole |
| Convolutional Neural Network |
| Graph Neural Network |
| Large Language Model |
| Artificial Intelligence |
| Retinal Fundus Multi-Disease Image Dataset |
| Optical Coherence Tomography |
| World Health Organization |
| Vision Transformers |
| Light Gradient Boosting Machine |
| Histogram-based Gradient Boosting |
| Extreme Gradient Boosting |
| Random Forest |
| Multi-Layer Perceptron |
| Decision Tree |
| Logistic Regression |
| Support Vector Machine |
| K-Nearest Neighbor |
| Generative Adversarial Network |
| Deep Graph Correlation Network |
| Semi-Supervised Graph Learning |
| Bayesian Convolutional Neural Network |
| Color Fundus Photography |
| Multifeature Decomposition Fusion Attention Network |
| Indocyanine Green Angiography |
| Multicolor Imags |
| Ultra-Widefield Fundus Imaging |
References
- Khan, S.D.; Basalamah, S.; Lbath, A. A Novel Deep Learning Framework for Retinal Disease Detection Leveraging Contextual and Local Feature Cues from Retinal Images. Med. Biol. Eng. Comput. 2025, 63, 2029–2046. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Yu, C.; Zhang, H.; Gao, Z. Embedding Tasks into the Latent Space: Cross-Space Consistency for Multi-Dimensional Analysis in Echocardiography. IEEE Trans. Med. Imaging 2024, 43, 2215–2228. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Xu, L.; Ohorodnyk, P.; Roth, M.; Chen, B.; Li, S. Contrast Agent-Free Synthesis and Segmentation of Ischemic Heart Disease Images Using Progressive Sequential Causal GANs. Med. Image Anal. 2020, 62, 101668. [Google Scholar] [CrossRef] [PubMed]
- Karule, P.T.; Bhele, S.B.; Palsodkar, P.; Agarkar, P.T.; Hajare, H.R.; Patil, P.R. Detection of Multi-Class Multi-Label Ophthalmological Diseases in Retinal Fundus Images Using Machine Learning. In Proceedings of the 2024 International Conference on Innovations and Challenges in Emerging Technologies (ICICET), Nagpur, India, 7–8 June 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Li, T.; Sheng, B. MSCE-LT: Multi-Label Supervised Contrastive Enhancement for Long-Tailed Retinal Diseases Recognition. In Proceedings of the 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Lisbon, Portugal, 3–6 December 2024; pp. 2128–2133. [Google Scholar] [CrossRef]
- Chandran, A.; Arathy, S.; Gowri, R.; Valsaraj, S.; Jeena, R.S. Real Time Diagnosis of Ocular Diseases using AI. In Proceedings of the 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kamand, India, 24–28 June 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Hassan, B.; Raja, H.; Hassan, T.; Akram, M.U.; Raja, H.; Abd-alrazaq, A.A.; Yousefi, S.; Werghi, N. A Comprehensive Review of Artificial Intelligence Models for Screening Major Retinal Diseases. Artif. Intell. Rev. 2024, 57, 111. [Google Scholar] [CrossRef]
- El-Sharkawy, M.; Ahmed, A.; Nassar, M.; Farag, A. A Clinically Explainable AI-Based Grading System for Age-Related Macular Degeneration Using Optical Coherence Tomography. Sci. Rep. 2024, 14, 2434. [Google Scholar] [CrossRef]
- Abd El-Khalek, A.A.; Balaha, H.M.; Sewelam, A.; Ghazal, M.; Khalil, A.T.; Abo-Elsoud, M.E.A.; El-Baz, A. A Comprehensive Review of AI Diagnosis Strategies for Age-Related Macular Degeneration (AMD). Bioengineering 2024, 11, 711. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Liu, X.; Zhao, W.; Chen, Q. Dry Age-Related Macular Degeneration Classification from Optical Coherence Tomography Images Based on Ensemble Deep Learning Architecture. Front. Med. 2024, 11, 1438768. [Google Scholar] [CrossRef] [PubMed]
- Le, N.T.; Truong, T.L.; Deelertpaiboon, S.; Srisiri, W.; Pongsachareonnont, P.F.; Suwajanakorn, D.; Mavichak, A.; Itthipanichpong, R.; Asdornwised, W.; Benjapolakul, W.; et al. ViT-AMD: A New Deep Learning Model for Age-Related Macular Degeneration Diagnosis From Fundus Images. Int. J. Intell. Syst. 2024, 2024, 3026500. [Google Scholar] [CrossRef]
- Chen, R.; Zhang, W.; Song, F.; Yu, H.; Cao, D.; Zheng, Y.; He, M.; Shi, D. Translating Color Fundus Photography to Indocyanine Green Angiography Using Deep Learning for Age-Related Macular Degeneration Screening. NPJ Digit. Med. 2024, 7, 34. [Google Scholar] [CrossRef] [PubMed]
- Akram, M.; Adnan, M.; Ali, S.F.; Ahmad, J.; Yousef, A.; Alshalali, T.A.N.; Shaikh, Z.A. Uncertainty-aware diabetic retinopathy detection using deep learning enhanced by Bayesian approaches. Sci. Rep. 2025, 15, 1342. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Wang, W.; Lian, J.; Jiao, W. Lesion classification and diabetic retinopathy grading by integrating softmax and pooling operators into vision transformer. Front. Public Health 2025, 12, 1442114. [Google Scholar] [CrossRef] [PubMed]
- Wong, W.K.; Juwono, F.H.; Apriono, C. Diabetic Retinopathy Detection and Grading: A Transfer Learning Approach Using Simultaneous Parameter Optimization and Feature-Weighted ECOC Ensemble. IEEE Access 2023, 11, 3301618. [Google Scholar] [CrossRef]
- Maaliw, R.R.; Lagman, A.C.; Mabunga, Z.P.; Garcia, M.B.; De Veluz, M.R.D.; Lacatan, L.L.; Alon, A.S.; Dellosa, R.M. An Enhanced Segmentation and Deep Learning Architecture for Early Diabetic Retinopathy Detection. IEEE CCWC 2023, 13, 10099069. [Google Scholar] [CrossRef]
- Zedadra, A.; Zedadra, O.; Salah-Salah, M.Y.; Guerrieri, A. Graph-Aware Multimodal Deep Learning for Classification of Diabetic Retinopathy Images. IEEE Access 2025. [Google Scholar] [CrossRef]
- Sumod, S.; Sumathy, S. Classification of Diabetic Retinopathy Disease Levels by Extracting Topological Features Using Graph Neural Networks. IEEE Access 2023, 11, 51435–51450. [Google Scholar] [CrossRef]
- Poranki, V.K.R.; Rao, B.S. DRG-Net: Diabetic Retinopathy Grading Network Using Graph Learning with Extreme Gradient Boosting Classifier. Informatica 2024, 48, 171–184. [Google Scholar] [CrossRef]
- Zhang, G.; Sun, B.; Zhang, Z.; Pan, J.; Yang, W.; Liu, Y. Multi-Model Domain Adaptation for Diabetic Retinopathy Classification. Front. Physiol. 2022, 13, 918929. [Google Scholar] [CrossRef] [PubMed]
- Feng, M.; Wang, J.; Wen, K.; Sun, J. Grading of Diabetic Retinopathy Images Based on Graph Neural Network. IEEE Access 2023, 11, 98391–98402. [Google Scholar] [CrossRef]
- Shamrat, F.M.J.M.; Shakil, R.; Sharmin, S.; Hoque Ovy, N.; Akter, B.; Ahmed, M.Z.; Ahmed, K.; Bui, F.M.; Moni, M.A. An Advanced Deep Neural Network for Fundus Image Analysis and Enhancing Diabetic Retinopathy Detection. Healthc. Anal. 2024, 5, 100303. [Google Scholar] [CrossRef]
- Dhinakaran, D.; Srinivasan, L.; Selvaraj, D.; Sankar, S.M.U. Leveraging Semi-Supervised Graph Learning for Enhanced Diabetic Retinopathy Detection. SSRG Int. J. Electron. Commun. Eng. 2023, 10, 9–21. [Google Scholar] [CrossRef]
- Fu, C. Enhanced Diabetic Macular Edema Detection in Multicolor Imaging through a Multi-Feature Decomposition Fusion Attention Network. J. Radiat. Res. Appl. Sci. 2025, 18, 101210. [Google Scholar] [CrossRef]
- Zhang, P.; Conze, P.H.; Lamard, M.; Cochener, B.; Quellec, G.; El Habib Daho, M. Deep Learning-Based Detection of Referable Diabetic Retinopathy and Macular Edema Using Ultra-Widefield Fundus Imaging. In Proceedings of the MICCAI Challenge on Ultra-Widefield Fundus Imaging for Diabetic Retinopathy; Springer: Cham, Switzerland, 2025; pp. 88–100. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, B.; Hu, Y.; Liu, B.; Cao, D.; Yang, D.; Peng, Q.; Zhong, P.; Zeng, X.; Xiao, Y.; et al. Detection of Morphologic Patterns of Diabetic Macular Edema Using a Deep Learning Approach Based on Optical Coherence Tomography Images. Retina 2021, 41, 1110–1117. [Google Scholar] [CrossRef] [PubMed]
- Saidi, L.; Jomaa, H.; Zainab, H.; Zgolli, H.; Mabrouk, S.; Sidibé, D.; Tabia, H.; Khlifa, N. Automatic Detection of AMD and DME Retinal Pathologies Using Deep Learning. Int. J. Biomed. Imaging 2023, 2023, 9966107. [Google Scholar] [CrossRef] [PubMed]
- Tripathi, A.; Kumar, P.; Mayya, V.; Tulsani, A. Generating OCT B-Scan DME Images Using Optimized Generative Adversarial Networks (GANs). Heliyon 2023, 9, e18773. [Google Scholar] [CrossRef] [PubMed]
- Thanikachalam, V.; Kabilan, K.; Erramchetty, S. Optimized Deep CNN for Detection and Classification of Diabetic Retinopathy and Diabetic Macular Edema. BMC Med. Imaging 2024, 24, 227. [Google Scholar] [CrossRef] [PubMed]
- Nazir, T.; Nawaz, M.; Rashid, J. Detection of Diabetic Eye Disease from Retinal Images Using a Deep Learning-Based CenterNet Model. Sensors 2021, 21, 5283. [Google Scholar] [CrossRef] [PubMed]
- Goyanes, E.; Leyva, S.; Herrero, P.; de Moura, J.; Novo, J.; Ortega, M. Fully-Automatic End-to-End Approaches for 3D Drusen Segmentation in Optical Coherence Tomography Images. Procedia Comput. Sci. 2024, 246, 1100–1109. [Google Scholar] [CrossRef]
- Ilyasova, N.Y.; Demin, N.S.; Kuritsyn, N.S. Recognition of Drusen Subtypes on OCT Data for the Diagnosis of Age-Related Macular Degeneration. J. Biomed. Photonics Eng. 2024, 10, 030307. [Google Scholar] [CrossRef]
- Omar, M.A.; Khelifi, F.; Tahir, M.A. Exudate and Drusen Classification in Retinal Images Using Bagged Colour Vector Angles and Inter Colour Local Binary Patterns. Multimed. Tools Appl. 2024, 83, 51809–51833. [Google Scholar] [CrossRef]
- Nowomiejska, K.; Powroźnik, P.; Skublewska-Paszkowska, M.; Adamczyk, K.; Concilio, M.; Sereikaite, L.; Rejdak, R. Residual Attention Network for Distinction Between Visible Optic Disc Drusen and Healthy Optic Discs. Opt. Lasers Eng. 2024, 176, 108056. [Google Scholar] [CrossRef]
- Hassan, S.A.; Akbar, S.; Rehman, A.; Saba, T.; Kolivand, H.; Bahaj, S.A. Recent Developments in Detection of Central Serous Retinopathy through Imaging and Artificial Intelligence Techniques—A Review. IEEE Access 2021, 9, 168731–168748. [Google Scholar] [CrossRef]
- Zhen, Y.; Chen, H.; Zhang, X.; Liu, M.; Meng, X.; Zhang, J.; Pu, J. Assessment of Central Serous Chorioretinopathy (CSC) Depicted on Color Fundus Photographs Using Deep Learning. arXiv 2020, arXiv:1901.04540. [Google Scholar] [CrossRef]
- Yoon, J.; Han, J.; Park, J.I.; Hwang, J.S.; Han, J.M.; Sohn, J.; Park, K.H.; Hwang, D.D.J. Optical Coherence Tomography-Based Deep-Learning Model for Detecting Central Serous Chorioretinopathy. Sci. Rep. 2020, 10, 18852. [Google Scholar] [CrossRef] [PubMed]
- Hassan, S.A.; Akbar, S.; Khan, H.U. Detection of Central Serous Retinopathy Using Deep Learning Through Retinal Images. Multimed. Tools Appl. 2024, 83, 21369–21396. [Google Scholar] [CrossRef]
- Bolanos, A.; Reddy, A.; Tak, N.; Nawathey, N.; Esfahani, P.R.; Aval, H.; Garcia, A.; San Lwin, S.; Nguyen, M.; Martel, J. AI-Driven Macular Hole Detection in OCT Scans: Efficient Training, Robust Performance, and Global Significance. Investig. Ophthalmol. Vis. Sci. 2024, 65, 2358. [Google Scholar]
- Shahalinejad, S.; Majdar, R.S. Macular Hole Detection Using a New Hybrid Method: Using Multilevel Thresholding and Derivation on Optical Coherence Tomographic Images. Comput. Intell. Neurosci. 2021, 2021, 6904217. [Google Scholar] [CrossRef] [PubMed]
- Ko, J.; Han, J.; Yoon, J.; Park, J.I.; Hwang, J.S.; Han, J.M.; Park, K.H.; Hwang, D.D.J. Assessing Central Serous Chorioretinopathy with Deep Learning and Multiple Optical Coherence Tomography Images. Sci. Rep. 2022, 12, 1831. [Google Scholar] [CrossRef] [PubMed]
- Pachade, S.; Porwal, P.; Thulkar, D.; Kokare, M.; Deshmukh, G.; Sahasrabuddhe, V.; Meriaudeau, F. Retinal Fundus Multi-Disease Image Dataset (RFMiD): A Dataset for Multi-Disease Detection Research. Data 2021, 6, 14. [Google Scholar] [CrossRef]
- Naren, O.S. Retinal OCT Image Classification-C8 Dataset; Kaggle. 2021. Available online: https://www.kaggle.com/datasets/obulisainaren/retinal-oct-c8/versions/2 (accessed on 11 June 2025).
- Bali, A.; Mansotra, V. Multiclass Multilabel Ophthalmological Fundus Image Classification Based on Optimised Deep Feature Space Evolutionary Model. Multimed. Tools Appl. 2024, 83, 49813–49843. [Google Scholar] [CrossRef]
- Jiang, X.F.; Ken-Cheng, Z.D.L. Retinal OCT Image Classification Based on CNN-RNN Unified Neural Networks. J. Comput. 2024, 35, 255–266. [Google Scholar] [CrossRef]
- Tan, Z.; Zhang, Q.; Lan, G.; Xu, J.; Ou, C.; An, L.; Qin, J.; Huang, Y. OCT Retinopathy Classification via a Semi-Supervised Pseudo-Label Sub-Domain Adaptation and Fine-Tuning Method. Mathematics 2024, 12, 347. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).

 ,
, 

{kind=link}
{kind=link}
{kind=link}