1. Introduction
Despite the continuous rise in global electricity demand, the environmental concerns associated with fossil fuel consumption are becoming increasingly critical [
1]. This has driven a growing global interest in sustainable energy alternatives, including solar, wind, hydro, and tidal power, collectively termed renewable energy sources (RESs) [
2,
3]. Among these, solar energy stands out due to its widespread availability and suitability for deployment in urban environments [
4]. Recent technological advances have significantly improved the conversion efficiency of photovoltaics (PV), positioning solar energy as one of the most rapidly adopted RES options [
5,
6].
As a result, solar power generation (SPG) has maintained its status as the fastest-growing electricity source for the 18th consecutive year, with a 24% increase in capacity compared to 2021, reaching approximately 861 GW globally [
7]. However, the inherently variable nature of solar energy presents unique challenges for the integration of the power system [
8]. SPG output is highly sensitive to meteorological conditions, leading to significant fluctuations in electricity production. Consequently, accurate solar power forecasting is essential to reduce uncertainty, improve economic viability, and ensure reliable power grid operation through efficient integration of renewable sources [
9].
Forecasting in SPG is essential for effective grid integration and is commonly categorized into four primary approaches: physical, statistical, machine learning (ML), and hybrid or ensemble methods [
10,
11]. In addition to methodological classification, forecasts are also distinguished by their temporal horizon—typically divided into short-term (1 h to 1 week), medium-term (1 week to 1 month), and long-term (beyond 1 month) predictions [
12]. However, it is important to note that these definitions are not universally standardized. For instance, some studies propose a four-tier classification: very short-term (up to 1 day), short-term (up to 2 weeks), medium-term (up to 3 years), and long-term (up to 30 years) [
13,
14]. This variation highlights the lack of consensus in the literature regarding forecasting horizon definitions.
Physical models rely on mathematical modeling and Numerical Weather Prediction (NWP) systems to simulate the physical processes affecting solar irradiance. These models incorporate variables such as temperature, atmospheric pressure, solar angles, and cloud cover [
15,
16]. They are particularly effective for long-term and large-scale forecasting but require high-resolution environmental data and significant computational resources. Representative examples include radiative transfer models, the P-persistent model, and satellite-based forecasting systems [
17,
18,
19,
20]. Despite their accuracy, physical models often face challenges related to calibration, spatial resolution, and model complexity [
21].
Statistical approaches use historical data to identify patterns and trends in solar power output [
22]. Common techniques include autoregressive (AR) and moving average (MA) techniques, and their extensions such as ARIMA and SARIMA, which address non-stationarity through differencing [
23,
24,
25,
26]. While these models are computationally efficient and relatively easy to implement, they are fundamentally limited by their reliance on linear assumptions and their inability to adapt to rapidly changing environmental conditions.
In the context of SPG, where input variables such as irradiance, temperature, and cloud cover exhibit strong non-linear and non-stationary behavior, statistical models often fail to capture the underlying dynamics accurately [
27,
28]. Moreover, traditional statistical models are typically static in nature, i.e., they do not incorporate mechanisms for dynamically adjusting to new data patterns or site-specific characteristics. This rigidity makes them unsuitable for distributed solar power systems, where forecast conditions can vary significantly between locations.
Recent advancements in power systems and the exponential growth of data availability have positioned ML and deep learning (DL) as powerful tools for addressing the non-linearity inherent in the environmental variables affecting SPG forecasting [
29,
30]. Regression-based, tree-based, and ensemble models have demonstrated strong performance across various locations and forecasting horizons [
31,
32,
33].
DL models, particularly neural networks such as Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), have shown promising results in time series forecasting tasks [
34,
35]. RNNs are well-suited for sequential data, while CNNs are effective in capturing long-term dependencies [
36]. However, the performance of these models is highly dependent on the quality and characteristics of the training data [
37]. Variability in forecast accuracy often arises when models are applied across datasets from different PV plants, due to differences in module characteristics, data resolution, and environmental conditions [
38].
To overcome the limitations of individual models, hybrid or ensembling approaches that integrate physical, statistical, ML, and DL methods have gained prominence in SPG prediction and forecasting [
39,
40,
41]. These methods often employ ensemble techniques such as boosting [
42], bagging [
43], and stacked generalization (meta-learning) [
44] to combine the strengths of diverse models and reduce prediction uncertainty [
45,
46]. Boosting and bagging improve performance by reweighting or aggregating predictions from multiple models. Meta-learning in particular trains a meta-model on the outputs of several base models, leveraging their complementary strengths while reducing bias and variance [
47,
48]. Stacking uses cross-validation (CV) to generate meta-features, while blending relies on a hold-out validation set. Though similar in principle, their key distinction lies in how training data are allocated.
Nevertheless, the incorrect model selection can significantly compromise SPG forecasting accuracy due to the unique sensitivities of each algorithm, making it crucial to use a model that best fits the given data. Thus, numerous hybrid models have been proposed in this field. For instance, a day-ahead forecasting model combining wavelet transformation, support vector machines (SVM), and particle swarm optimization (PSO) has shown improved accuracy [
49]. Other examples include multi-model ensembles that integrate statistical models with artificial neural networks (ANN) using numerical weather data [
50], and advanced ML-only hybrids such as ANN-XGBoost-Ridge regression ensembles or the Transformer-LUBE-GRU framework for deterministic day-ahead forecasting [
51,
52].
Recent studies have continued to refine deep learning architectures for solar forecasting. Transformer-based models in particular have shown strong performance in capturing long-term dependencies in environmental time series [
53,
54]. Graph neural networks (GNNs) have also emerged as a promising approach for modeling spatial–temporal relationships across multiple power plants or sensor locations [
55]. In parallel, optimization techniques such as evolutionary algorithms and attention-based adaptive ensembling have been explored to further improve hybrid model performance [
56].
Despite their advantages, hybrid models are not without limitations. They may inherit the weaknesses of their constituent models, particularly when less accurate models are included in the ensemble [
33]. Moreover, hybrid systems often rely on pre-tested base models, reducing flexibility and adaptability [
57]. Even when individual models perform well, their combination does not guarantee improved results, necessitating careful evaluation of the ensemble’s overall performance [
58].
These limitations are particularly pronounced in the context of SPG forecasting. One of the key advantages of solar power plants is their geographical flexibility, as they can be deployed in a wide range of environments—including urban, rural, and remote areas—without the spatial and scale constraints typically associated with other energy sources [
4]. However, this flexibility introduces significant forecasting challenges due to the resulting heterogeneity in environmental conditions and solar exposure.
Each solar power plant operates under distinct meteorological and operational contexts, which leads to variability in the availability, resolution, and quality of the input data. For example, the types and frequency of weather measurements—such as solar irradiance, temperature, humidity, and cloud cover—can differ substantially depending on the location and the instrumentation used [
59]. Additionally, the data collection methods and infrastructure (e.g., ground-based sensors vs. satellite data) vary across sites, influencing both the selection and performance of forecasting models.
This distributed and heterogeneous nature of SPG systems demands forecasting models that are both highly adaptable and context-aware. Fixed-output or static models often fail to generalize across different sites as they are typically optimized for specific data distributions and environmental conditions. As a result, a hybrid ensemble model that performs well for one solar power plant may not achieve the same level of accuracy when applied to another, even if the underlying modeling framework remains unchanged [
60]. These challenges underscore the need for flexible ensemble frameworks capable of dynamically adapting to local data characteristics and operational constraints rather than relying on a one-size-fits-all approach.
An approach that can be tailored to the specific attributes of each site is essential to overcome the challenge of developing a universally effective forecasting solution. The heterogeneity of environmental conditions, data availability, and system configurations across solar power plants makes it difficult for conventional models to generalize effectively. This underscores the need for a flexible and adaptive forecasting framework capable of dynamically adjusting to site-specific characteristics.
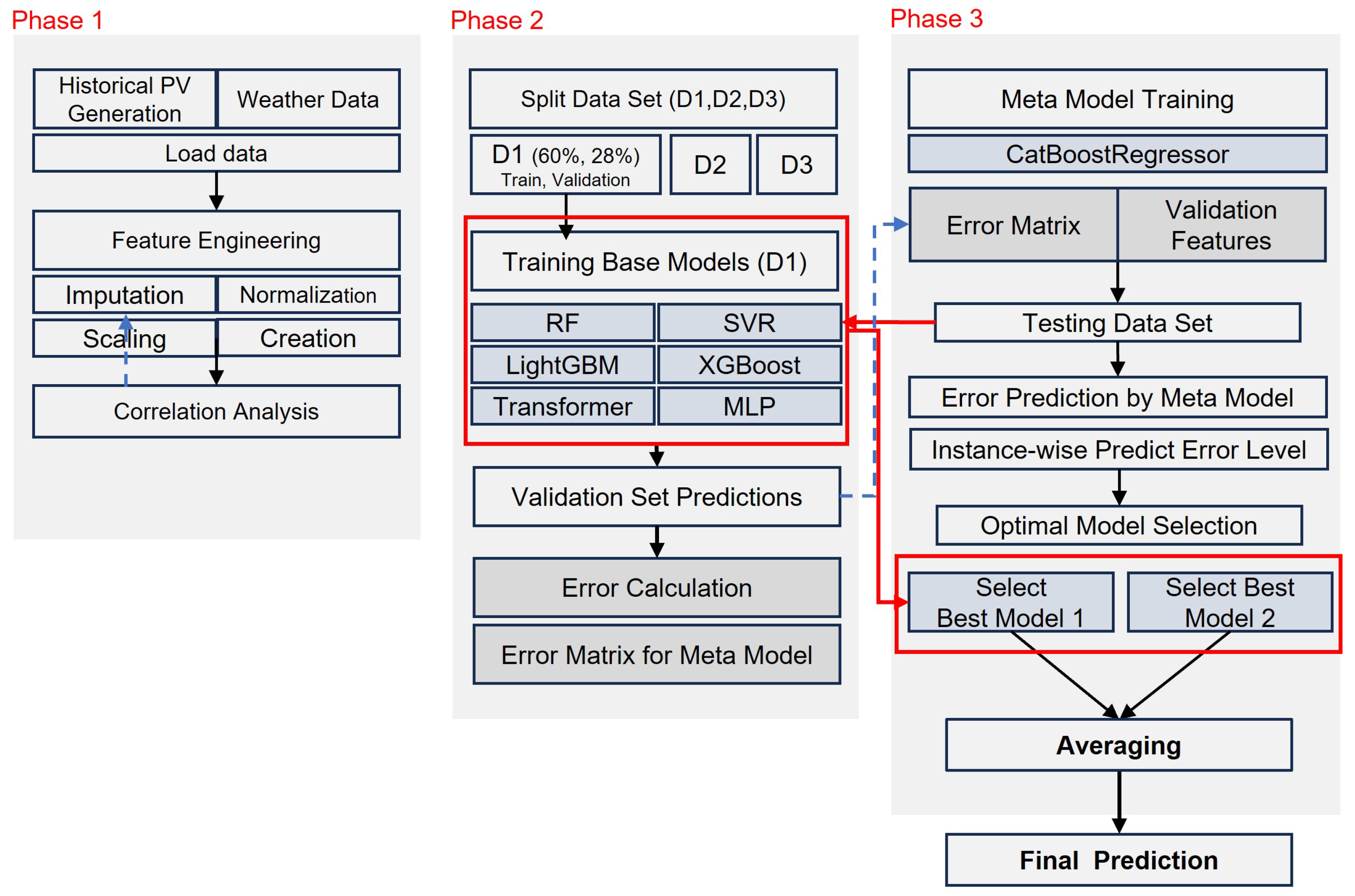
To address these challenges, this study proposes a flexible hybrid ensemble (FHE) framework designed to overcome the limitations of traditional hybrid ensemble methods. It reduces reliance on pre-tested model combinations, increases robustness to data variability across different sites, and enables the inclusion of diverse models without compromising overall performance. Furthermore, it adapts dynamically to local environmental and operational conditions, making it particularly well-suited for distributed solar power systems. Key innovations and contributions include the following:
Selective Model Utilization: The FHE framework avoids the common pitfall of performance degradation caused by underperforming models by not mandatorily integrating all base models into the final prediction. Instead, it selectively includes only those models that are expected to contribute positively to forecasting accuracy. This eliminates the need for exhaustive pre-testing of individual models and enhances the framework’s adaptability across different sites.
Error-Based Meta-Modeling: A central innovation of the FHE framework is its use of an error-informed meta-model. Unlike traditional meta-models that rely solely on base model outputs, the FHE meta-model incorporates both historical prediction errors and environmental variables to estimate the expected performance of each base model under specific conditions. This allows the system to dynamically assess and select the most suitable models for each forecasting instance.
Dynamic Base Model Selection: The framework predicts the expected error of each base model for a given input and selects the subset of models most likely to yield accurate predictions. This instance-specific selection enables the ensemble to adapt its configuration in real time, leveraging even models that may perform poorly on average but excel under certain conditions.
The remainder of this paper is organized as follows:
Section 2 describes the research design, including the characteristics of the data and the preprocessing steps undertaken, and also details of the development and implementation of the FHE framework, with particular emphasis on the methodology through which the meta-model dynamically selects the optimal base models.
Section 3 presents the experimental results and performance evaluation. Finally,
Section 4 concludes the study and discusses future research directions.
3. Results and Discussion
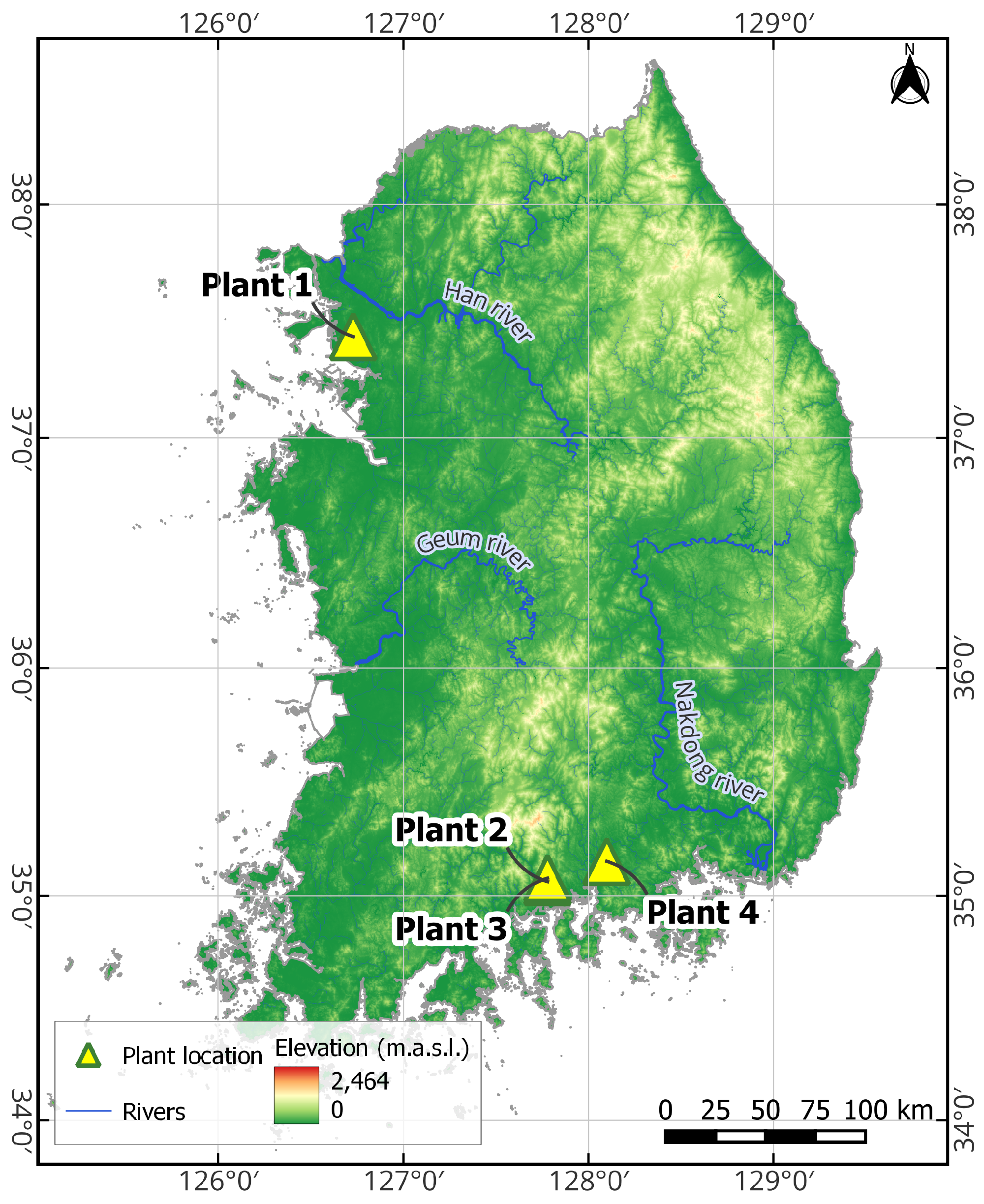
This section evaluates the performance of the proposed FHE framework across four PV plants with capacities ranging from 48.3 kW to 998 kW. The results are reported as the average of 10 independent runs (epochs). Performance comparisons are made against standard models and ensemble baselines using multiple error metrics.
3.1. Effect of Feature Engineering on Base Model Accuracy
The impact of engineered features on forecasting accuracy was assessed by comparing four feature scenarios across six base models (RF, SVR, LGBM, XGB, Transformer, and MLP) and four PV plants with varying capacities. The results, averaged over 10 runs, are summarized in
Table 3 using the error metrics MSE, NMAE, and
. The assessment included four input configurations, each combining the meteorological data with a different subset of features:
Scenario 1: Meteorological + Radiation + Engineered Features;
Scenario 2: Meteorological + Engineered Features (No Irradiance);
Scenario 3: Meteorological (No Irradiance, No Engineered Features);
Scenario 4: Meteorological + Irradiance (No Engineered Features).
Across all plants and models, the combination with meteorological data, irradiance, and engineered features (Scenario 1) consistently delivered the best performance. This suggests that the inclusion of solar position (azimuth, elevation) and temporal encodings (hour, month) effectively enhances the model’s ability to capture diurnal and seasonal variability. For instance, the Random Forest achieved an above 0.86 at all plants, with particularly strong performance at Plants 2 and 4 ( = 0.897 and 0.898, respectively). Among all models, the LGBM slightly outperformed the others on average, showing a lower MSE and NMAE at most plants.
When direct irradiance measurements were unavailable (Scenario 2), engineered features still contributed significantly to preserving model accuracy. For instance, RF performance was only slightly degraded compared to in Scenario 1, with the dropping by 1–3 percentage points at most plants. This suggests that the engineered features can partially compensate for the absence of irradiance by implicitly capturing solar geometry and temporal dynamics. Interestingly, at Plant 4, the MLP outperformed all other models with an = 0.860, highlighting its robustness when dealing with incomplete input modalities.
Scenario 3 presented a clear degradation in performance, confirming the critical role of both irradiance and engineered features. All models experienced substantial increases in MSE and NMAE, with values dropping dramatically. For example, the for RF at Plant 1 fell from 0.869 (Scenario 1) to 0.255. This trend was consistent across all models and plants, underscoring that meteorological data alone are insufficient for accurate power prediction, especially when solar geometry is not explicitly encoded.
In Scenario 4, the removal of engineered features led to moderate performance loss compared to Scenario 1, yet the models still performed better than in Scenario 2 in most cases due to the presence of irradiance data. The RF model showed a noticeable drop in at Plant 1 (from 0.869 to 0.833), but maintained reasonable accuracy overall. These results indicate that, while irradiance is a strong predictor, engineered features provide an additional signal that boosts model generalization, especially in edge cases (e.g., early mornings or cloudy days).
To assess the role of irradiance and engineered features, we compared four feature configurations across all models and plants. Comparing Scenario 1 (all features) to Scenario 2 (engineered features only) revealed only a slight drop in performance, indicating that engineered features can effectively compensate for missing irradiance. For example, the MLP model at Plant 1 maintained nearly identical values (0.853 vs. 0.852), suggesting these features successfully capture relevant solar geometry and temporal patterns. A more dramatic change appeared between Scenario 2 and Scenario 3 (neither irradiance nor engineered features), where performance degraded substantially. The RF model at Plant 1, for instance, dropped from 0.848 to 0.255, confirming that engineered features are critical when irradiance is unavailable.
Comparing Scenario 3 to Scenario 4 (irradiance only), we found that irradiance improved performance but not as much as engineered features. For instance, SVR at Plant 2 improved from 0.198 to 0.852, yet similar or better performance is often achieved with engineered features alone. The comparison between Scenario 1 and Scenario 4 shows that, even when irradiance is available, engineered features still offer additional predictive value. Ensemble models like LGBM and XGB benefited the most, with consistent performance gains across plants.
Finally, engineered features are essential for maintaining accuracy in the absence of irradiance and remain beneficial even when irradiance is present, underscoring their value in robust solar energy forecasting.
3.2. Comprehensive Performance Analysis of the FHE Framework
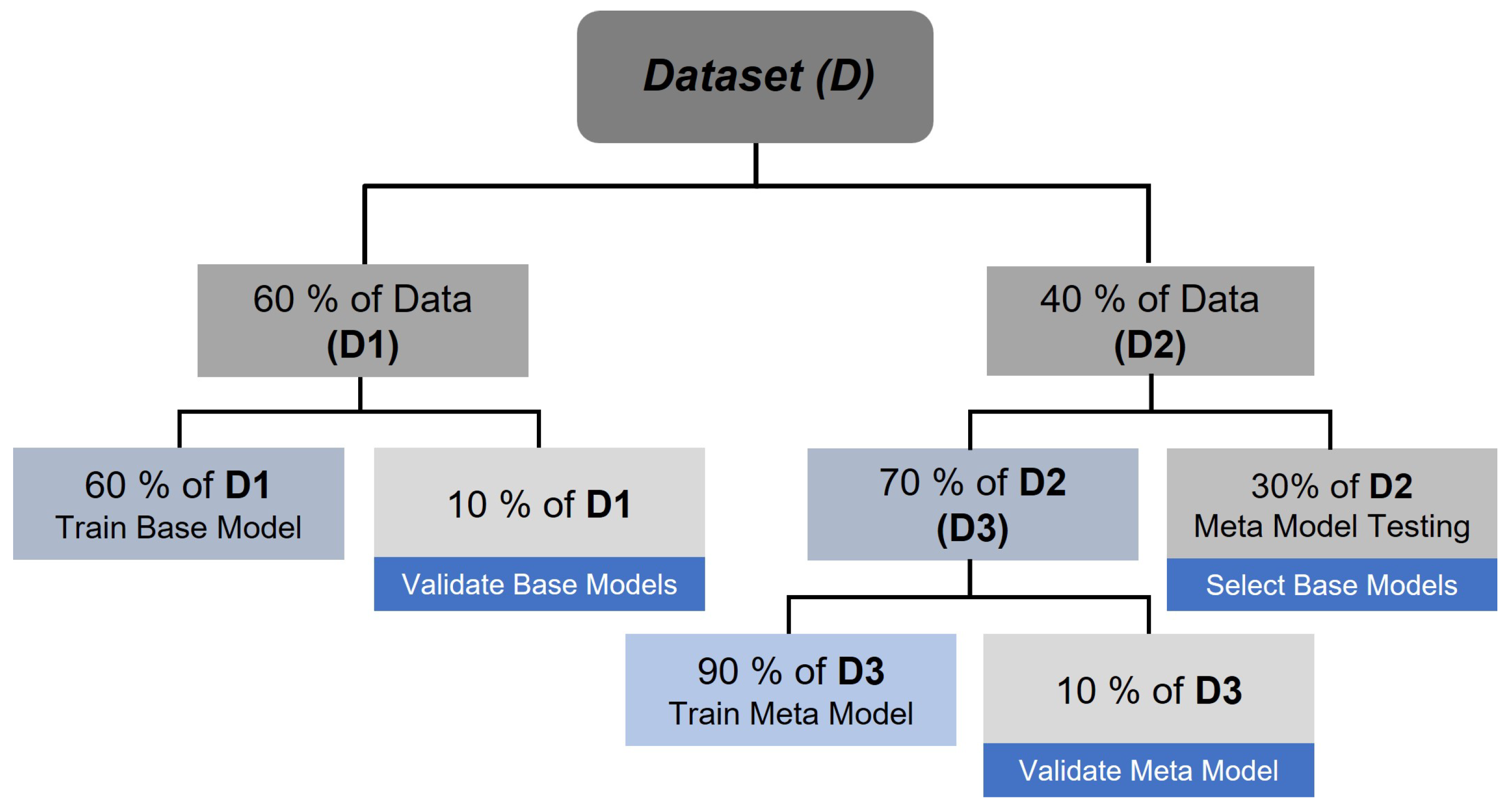
The proposed FHE framework was evaluated using real operational data from PV plants to assess its forecasting accuracy. The analysis focused on the framework’s ability to dynamically select and integrate forecasts from multiple base models based on real-time weather conditions, thereby enhancing prediction reliability. Three baseline settings were considered:
Baseline 1: Each base model was evaluated independently within the FHE framework, providing a reference for standalone performance.
Baseline 2: Conventional hybrid ensemble strategies were applied, including meta-modeling and bagging, which combine forecasts from all base models.
Baseline 3 (FHE): The proposed FHE approach selectively integrates forecasts from the best-performing model for specific conditions, optimizing prediction dynamically.
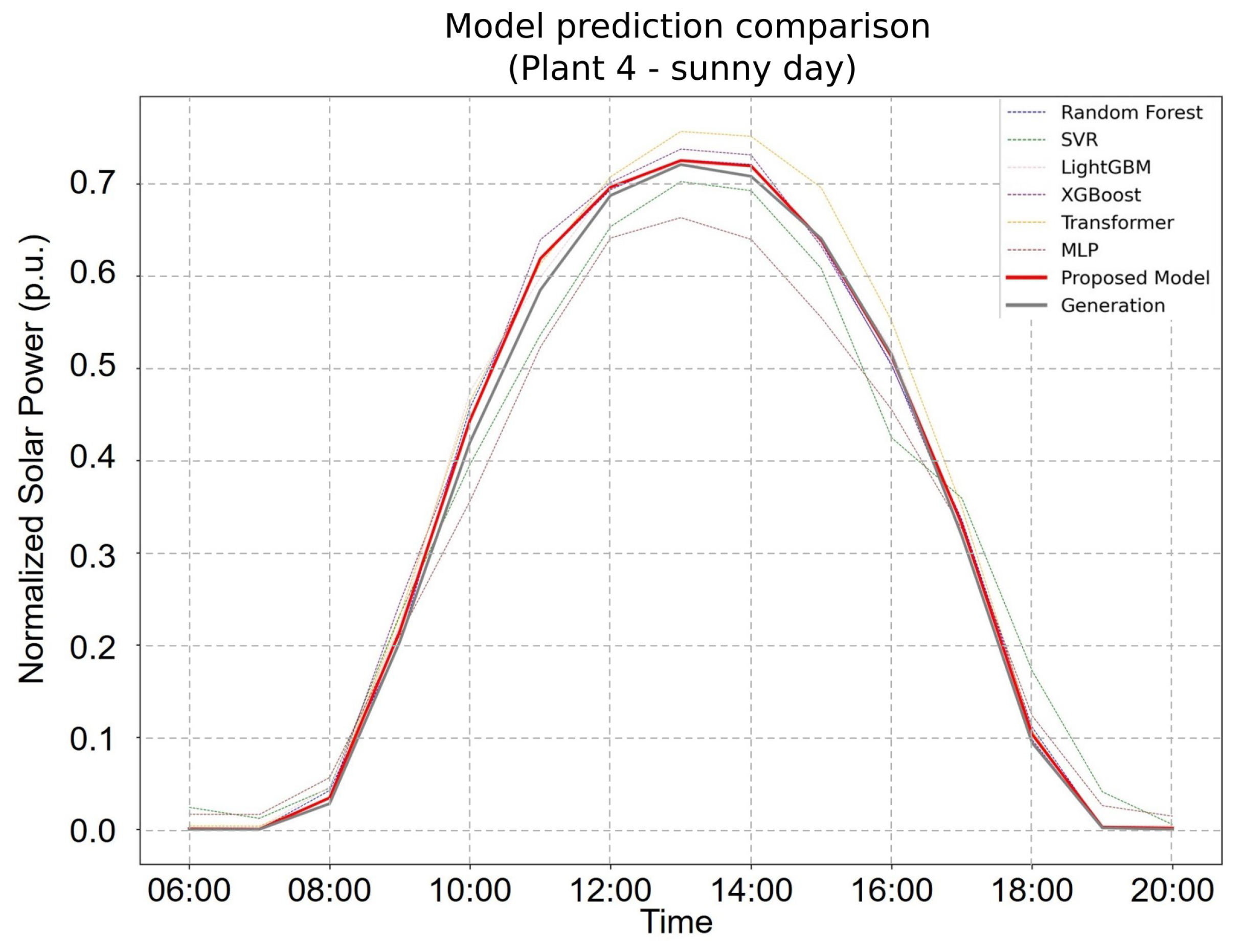
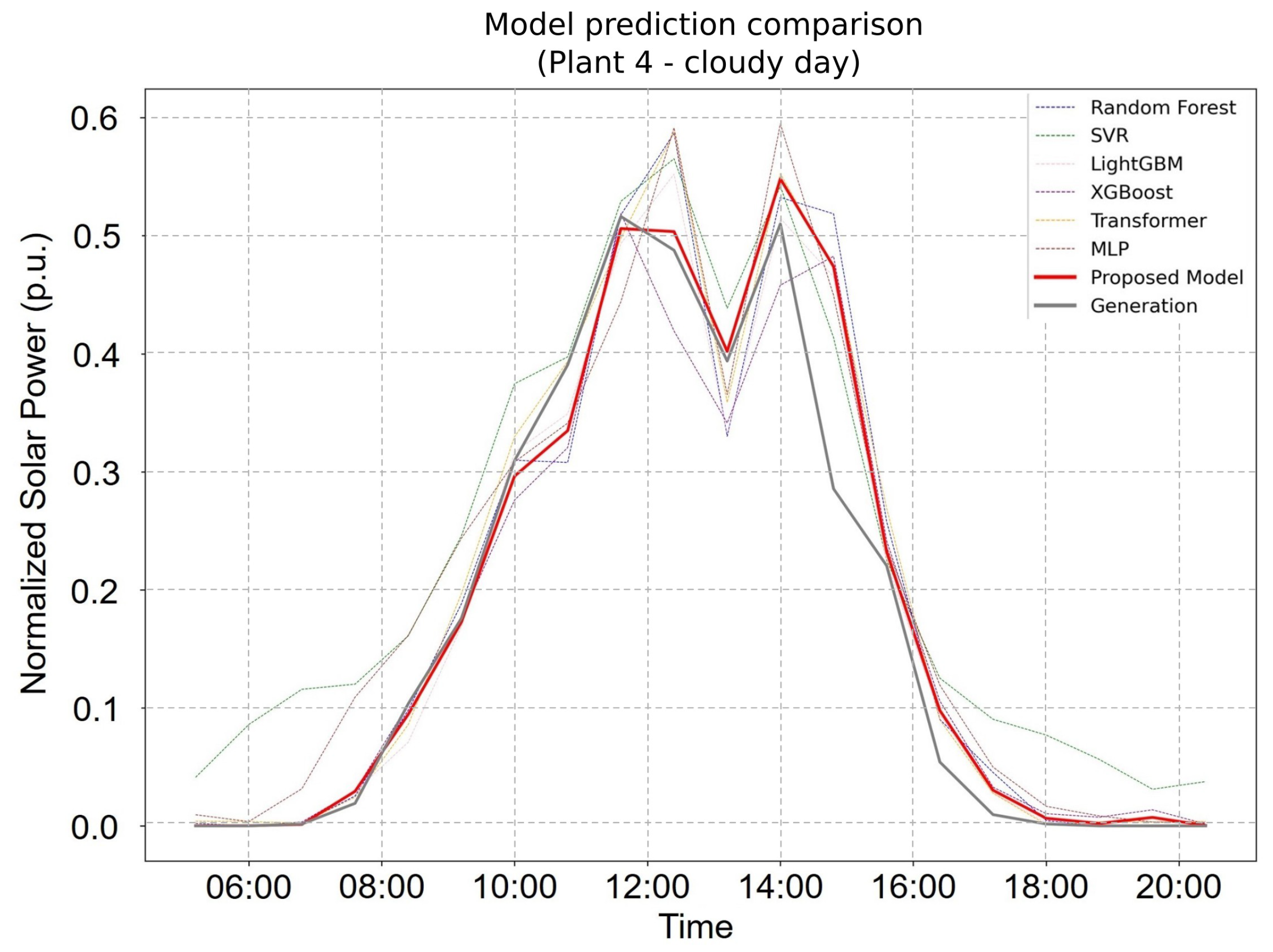
Figure 4 and
Figure 5 further illustrate the FHE framework’s forecasting capability. On clear days (
Figure 4), the proposed model not only achieved the highest overall accuracy but also captured peak solar production values with superior precision. Under cloudy conditions (
Figure 4), it continued to perform reliably, closely tracking the fluctuations in actual power generation. These findings underscore the FHE framework’s adaptability and robustness across diverse environmental conditions, with it consistently outperforming individual models and conventional ensembles in both stable and volatile weather scenarios.
Table 4 presents a comprehensive evaluation of the proposed FHE model against individual base models and traditional ensemble approaches (bagging and meta-modeling) across four PV plants with varying capacities and operational contexts.
Across all plants and performance metrics, the proposed FHE consistently outperformed all baseline and ensemble methods. Notably, for Plant 1, the FHE achieved the lowest RMSE (65.785 kW), MAE (43.470%), and MAPE (12.923%) while also yielding the highest (0.864), indicating superior fit and error minimization. A similar pattern was observed for Plant 2, where the FHE attained an of 0.906 and an MAPE of just 12.332%, outperforming even the most competitive baselines such as the RF and LGBM. The performance gains were especially remarkable at Plant 4, a large-scale system with complex dynamics. The FHE achieved a significant reduction in RMSE (55.568 kW vs. >59 kW for all others), along with a notably lower MAE (36.535%) and the highest (0.902), highlighting its robustness in high-capacity scenarios. At Plant 3, although the magnitude of errors was smaller due to the lower capacity of the plant, the FHE still achieved the best overall scores, indicating its scalability across plant sizes.
Interestingly, while tree-based models such as RF and LGBM performed competitively, especially at Plants 1 and 2, and bagging provided modest gains, neither traditional ensemble approach matched the adaptive advantage of the FHE. Transformer and MLP models generally lag in performance, particularly in overcast or highly variable conditions, as is evident from their higher RMSE and MAPE values. These results affirm that the selective and condition-aware nature of the FHE model enables it to leverage the strengths of different base learners under varying conditions, thereby achieving more accurate and reliable short-term solar power forecasts across heterogeneous PV plants.
3.3. Evaluation of the Robustness of the FHE Framework
To rigorously evaluate the robustness and generalizability of the proposed FHE framework, two complementary experiments were designed: (1) variation of the test set ratios, and (2) time series CV analysis. Initially, a test set ratio of 12% was adopted to capture sufficient temporal variability while maximizing the training data available for the meta-model. To assess the sensitivity of the FHE’s performance to this choice, additional experiments were conducted with increased test set ratios of 16% and 20%. The results of this analysis are summarized in
Table 5.
Across all plants, there was a general trend of increasing error as the test set ratio increased. This was expected, as increasing the size of the test set reduces the number of data available for training, which can impair model generalization. However, the extent of performance degradation varied by model, suggesting differences in robustness. The proposed FHE framework consistently achieved the lowest MAPE and NMAE scores across all plants and test set configurations, highlighting its superior generalization and robustness. For instance, at Plant 1, the MAPE increased only modestly from 12.923% (12%) to 15.079% (20%), which is a smaller increment than observed in other models such as the SVR (from 17.328% to 19.786%) or Transformer (from 18.934% to 21.158%).
We considered the results individually for each plant. At Plant 1 (998 kW), the FHE achieved the best MAPE and NMAE scores at all test set sizes, with a strong lead over both individual models and ensemble baselines. Notably, even compared to strong competitors like the LGBM and RF, the FHE provided a relative error reduction of 12–18% in MAPE. At Plant 2 (369.85 kW), again, the FHE outperformed all other models. Interestingly, the gap between the FHE and the others was slightly larger at this plant, with MAPE improvements of up to 20% compared to the SVR or XGB at the 20% test ratio.
In the situation with a low-capacity plant, Plant 3 (48.3 kW) exhibited generally higher errors across all models, likely due to the higher variability in small-scale energy production. However, the FHE remained the top performer, maintaining MAPE scores 1.5–3 points lower than those of other models, which is particularly notable given the plant’s challenging characteristics. Finally, at Plant 4 (905 kW), the FHE once again dominated in terms of performance. Its MAPE remained under 12.8% even at the highest test ratio, while all other models reported MAPE values above 14%, indicating better resilience to reduced training data.
Traditional ensemble methods like bagging and meta-ensembles provide improved robustness over single learners (e.g., RF, SVR), but they are consistently outperformed by the FHE framework. This suggests that the design of the FHE offers a more flexible and effective mechanism for combining base learners under data variability, presumably leveraging adaptive weighting or dynamic ensemble construction. For example, at Plant 4 at the 20% test ratio, the Bagging Ensemble had a 14.255% MAPE, the Meta-Ensemble a 14.978% MAPE, and the FHE a 12.771% MAPE. This performance gap underlines the FHE’s ability to better adapt to structural variations and uncertainties in the input data.
Furthermore, to assess the FHE’s robustness to sequence-dependent biases and its ability to generalize across different temporal segments, a time series split-based CV was performed. Unlike random splits, this approach preserves the temporal order of observations, thereby providing a more realistic simulation of forecasting in unseen future conditions [
79]. In this setup, four CV groups were executed, each using a chronologically expanding training window and a test set comprising the most recent 12% of the data. The iterations were defined as follows and the results are presented in
Table 6:
CV 1: Training from 1 January 2019 to 13 September 2019;
CV 2: Training from 1 January 2019 to 25 May 2020;
CV 3: Training from 1 January 2019 to 5 February 2021;
CV 4: Training from 1 January 2019 to 18 October 2021.
In CV 1, the FHE outperformed all the models across all four plants. It achieved the lowest MAPE and NMAE, and the highest scores, with particularly strong results for Plant 4 (MAPE: 16.565%, : 0.869), indicating a highly accurate and robust forecast even with a limited training history. Notably, classical machine learning models like the LGBM and RF performed competitively, but consistently lagged behind the FHE in both magnitude of error and explained variance. As the training set increased in CV 2, all models improved in performance, benefiting from more diverse and comprehensive temporal data. However, the margin by which the FHE outperformed others widened. It achieved substantial improvements in accuracy metrics, with Plant 1 showing a remarkable reduction in MAPE to 15.059% and an increase in to 0.874. The Bagging Ensemble and Meta-Ensemble provided competitive baselines, demonstrating the effectiveness of aggregation techniques, yet the FHE still maintained an edge, particularly in reducing the systematic under/over-estimation captured by the NMAE.
In CV 3, the gap between the models narrowed somewhat, as more historical variation was captured by the models. Despite this, the FHE continued to lead in all metrics across the board. For instance, at Plant 3, the FHE obtained the best combination of MAPE: 19.743%, NMAE: 6.044%, and : 0.827, reflecting its resilience in small-capacity scenarios where noise and data imbalance are more pronounced. The Transformer and MLP models showed more volatile performance, suggesting that deep architectures without tailored inductive biases or ensemble mechanisms may overfit or underperform in limited-training contexts.
By the final iteration, CV 4, where the models had the most extensive training data, performances converged, but the FHE retained its leadership. For instance, at Plant 4, the FHE reported an MAPE of 12.976% and an of 0.919, exceeding even ensemble models. Interestingly, the RF and LGBM remained consistently strong contenders across all iterations, especially in the early phases, highlighting their robustness and data efficiency. However, their relative gains diminished as the data complexity increased. The SVR and MLP consistently underperformed, particularly in larger-capacity plants, likely due to their limited ability to capture non-linearities or contextual dependencies across temporal segments.
4. Conclusions
This study conducted a comprehensive comparative analysis of the proposed FHE model against a wide range of baseline methods for short-term PV power forecasting. The evaluation spanned four real-world PV plants of varying capacities and employed a robust shuffle-based cross-validation strategy across different temporal windows. The results demonstrate that the FHE model consistently outperformed all baseline models, including traditional regressors (RF, SVR, LightGBM, XGBoost), DL architectures (MLP, Transformer), and ensemble methods (Bagging Ensemble and Meta-Ensemble), across all evaluation metrics.
Notably, the FHE model exhibited a superior forecasting accuracy, reflected by the lowest MAPE and NMAE values across all plants and cross-validation splits; a high explanatory power, achieving the highest scores consistently, indicating a strong ability to capture the underlying data variance; and robust generalization, with stable performance across different time splits and plant sizes, including challenging cases such as small-scale PV installations with higher noise and variability. While ensemble methods such as the Bagging Ensemble and Meta-Ensemble improved upon individual traditional models, they were still outperformed by the FHE, underscoring the effectiveness of its hybrid design. Furthermore, DL models underperformed relative to both ensemble and tree-based methods, suggesting that their complexity may not be fully leveraged in this context, potentially due to data limitations or architecture mismatch.
Another important observation is that forecasting performance tends to degrade for smaller plants, likely due to increased stochasticity in their power generation profiles. Nevertheless, the FHE model maintained its lead even under these more difficult conditions, further reinforcing its versatility and robustness. In conclusion, the FHE model emerges as a reliable, accurate, and scalable solution for PV power forecasting across diverse operating conditions. These promising results suggest its strong potential for deployment in operational settings, where accurate and generalizable energy forecasts are critical for grid stability and energy management.
Interesting directions for future research are the application of transfer learning between plants with similar characteristics and the use of federated learning frameworks to allow collaborative model training without centralized data aggregation. Also, we aim to explore other sequential-based architectures, such as Recurrent Neural Networks (RNNs), which are specifically designed for long-term time series forecasting. Additionally, another research path is to investigate the impact of selecting different numbers of base models in the final ensemble. While this study fixed the number to two for simplicity and interpretability, alternative strategies such as adaptive top-k selection or error-weighted combinations may offer additional improvements in robustness and accuracy.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}