Abstract
Radio frequency fingerprint identification (RFFI) leverages the unique characteristics of radio signals resulting from inherent hardware imperfections for identification, making it essential for applications in telecommunications, cybersecurity, and surveillance. Despite the advancements brought by deep learning in enhancing RFFI accuracy, challenges persist in model deployment, particularly when transferring RFFI models across different receivers. Variations in receiver hardware can lead to significant performance declines due to shifts in data distribution. This paper introduces the source-free cross-receiver RFFI (SCRFFI) problem, which centers on adapting pre-trained RF fingerprinting models to new receivers without needing access to original training data from other devices, addressing concerns of data privacy and transmission limitations. We propose a novel approach called contrastive source-free cross-receiver network (CSCNet), which employs contrastive learning to facilitate model adaptation using only unlabeled data from the deployed receiver. By incorporating a three-pronged loss function strategy—minimizing information entropy loss, implementing pseudo-label self-supervised loss, and leveraging contrastive learning loss—CSCNet effectively captures the relationships between signal samples, enhancing recognition accuracy and robustness, thereby directly mitigating the impact of receiver variations and the absence of source data. Our theoretical analysis provides a solid foundation for the generalization performance of SCRFFI, which is corroborated by extensive experiments on real-world datasets, where under realistic noise and channel conditions, that CSCNet significantly improves recognition accuracy and robustness, achieving an average improvement of at least 13% over existing methods and, notably, a 47% increase in specific challenging cross-receiver adaptation tasks.
1. Introduction
Radio frequency fingerprint identification (RFFI) is an emerging technology that leverages the unique characteristics of radio signals emitted by devices for identification purposes. It is based on the concept that every electronic device, due to hardware imperfections introduced during the manufacturing process, emits a unique and repeatable RF signal, often referred to as a radio frequency fingerprint [1]. These unique signatures are crucial for applications in secure communication systems, device authentication, and surveillance. The integration of deep learning (DL) has significantly improved the accuracy of RFFI systems, which typically consist of RF signal acquisition, feature extraction, and emitter identification stages, as illustrated in Figure 1. Despite these advancements, a critical challenge for practical deployment remains: The performance of a DL-based model degrades significantly when it is transferred from the receiver on which it was trained to a new one. This is known as the Cross-receiver RFFI problem, caused by data distribution shifts arising from variations in receiver hardware characteristics [2,3].
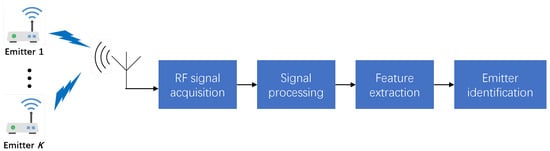
Figure 1.
The block diagram of the RFFI system outlines the following sequence: The process begins with the emission of signals from multiple sources. These signals are captured by a receiver, after which they undergo signal processing. This step typically includes operations such as filtering, amplification, and the conversion of the signals from analog to digital form. Once processed, the system proceeds to the feature extraction and identification phase, where distinctive characteristics or “fingerprints” of the signals are identified.
While existing methods have made progress in improving cross-receiver generalization, they almost universally assume that data from the source domain are available during the adaptation phase. However, in many practical applications, this requirement is challenging to meet. Privacy concerns, security protocols, and the logistical difficulties of transmitting large volumes of raw RF data often make accessing original training data from other receivers impractical. Therefore, a more feasible and secure approach is to adapt an RFFI model to a new receiver without accessing the original training data, relying only on the pre-trained model itself. Our research is driven by the need to address this gap. This paper defines and tackles this new, more stringent problem, which we term source-free cross-receiver RFFI (SCRFFI). This framework sets our work apart from existing methods that depend on source data [2,3,4,5,6,7,8,9,10,11,12].
The cross-receiver RFFI problem has been extensively studied from a domain adaptation perspective. Researchers have explored various paradigms, such as training with data from multiple receivers to enhance generalization [2], or developing calibration procedures to align signals from new receivers [2]. Other prominent approaches include adversarial training to learn receiver-agnostic features [3,9,12], and feature disentanglement to separate transmitter characteristics from receiver-induced effects [5,11]. More recent works have advanced these ideas using dynamic distribution alignment with maximum mean discrepancy (MMD) [8], prototypical contrastive domain adaptation learning (PCDAL) [10], and hybrid strategies for specific applications like UAV RFFI [12]. Nonetheless, all these techniques necessitate access to source domain data, making them unsuitable for the SCRFFI scenario we address.
To solve the challenging SCRFFI problem, where source data is inaccessible, we propose a novel method called the contrastive source-free cross-receiver network (CSCNet). Our approach begins by introducing pseudo-labeling and providing a theoretical analysis of its generalization performance on the new receiver. CSCNet employs contrastive learning alongside a three-pronged loss function—combining information entropy minimization, a pseudo-label self-supervised loss, and a contrastive learning loss—to effectively adapt the model to the new receiver’s characteristics using only its unlabeled data. This comprehensive approach directly addresses the performance degradation due to receiver hardware variations by learning robust, domain-invariant features and inherently overcomes the limitation of requiring access to original source training data.
The main contributions of this paper are summarized as follows:
- We define and address the SCRFFI problem, which centers on adapting a trained RF fingerprinting model to new receivers without requiring access to the original labeled data from other receivers. This approach is particularly suited for real-world applications where data privacy and transmission constraints are critical concerns.
- We introduce the concept of pseudo-labeling and formulate a novel learning problem specific to SCRFFI. Through rigorous analysis, we derive an upper bound on the generalization performance of the proposed solution, establishing a solid theoretical foundation for our approach.
- To address the SCRFFI problem, we propose CSCNet, an innovative method that incorporates contrastive learning. CSCNet employs a three-pronged loss function strategy, allowing the model to emphasize the relationships between signal samples and effectively adapt to the characteristics of new receivers using only unlabeled test data.
- Experiments on two real-world datasets demonstrate that CSCNet outperforms existing methods in terms of recognition accuracy and robustness.
The remainder of the paper is organized as follows. Section 2 introduces the system model and defines the SCRFFI problem; Section 3 performs a theoretical analysis on the SCRFFI problem; Section 4 presents the design of the proposed CSCNet; Section 5 evaluates the performance of CSCNet on HackRF and Wisig datasets; and Section 6 concludes the paper.
Notation 1.
denotes norm; represents the inner product, denotes the k-th entry of the vector , is an indicator function whose value equals one if , and 0 otherwise; denotes the -dimension probability simplex, i.e., ; denotes the convolution operator; denotes the expectation.
2. System Model and Problem Formulation
2.1. System Model
During the i-th time interval, the RF signal received, denoted as , is modeled by the equation
for . In this model, signifies noise, T is the duration of the interval, is the carrier frequency, is a random modulating signal, and represents the channel response. The function accounts for nonlinear distortions caused by the emitter’s hardware, while addresses the nonlinear reception characteristics inherent to the receiver’s hardware. It is important to note that each receiver generally has a unique .
In the above model, the nonlinear distortion function is essential for capturing the unique RF fingerprint of an emitter. This function reflects the hardware imperfections inherent to the emitting device, which arise from various sources during signal generation and transmission, such as amplifiers and mixers. For instance, power amplifiers often exhibit nonlinear behavior when driven beyond their linear operating range, resulting in the following relationship:
Here, is the output signal, is the input signal, and are the coefficients that characterize the degree of nonlinearity. When significantly exceeds , the output exhibits notable distortion, which can manifest as harmonic generation or intermodulation effects. Such distortions introduce unwanted harmonic frequency components, affecting signal integrity and contributing to the emitter’s unique fingerprint. Additionally, the specific design of the transmitter’s circuitry can introduce further nonlinear effects. Components such as filters, oscillators, and even the layout of the circuit board can influence how the signal is processed and distorted. Given the various sources of distortion contributing to the emitter’s RF fingerprint, accurately modeling it with a simple function is challenging. However, leveraging the powerful modeling capabilities of deep neural networks allows us to adopt a data-driven approach to automatically capture the distinct distortions among emitters.
For simplicity, we define as the i-th processed signal sample and as the corresponding emitter label, where K denotes the number of emitters and the subscript s indicates the source domain for Rx-1. Thus, the labeled training dataset for Rx-1 is represented concisely as , with being the dataset size. In a similar fashion, the dataset from a new receiver, denoted by Rx-2, is represented as , where the subscript t denotes the target domain associated with Rx-2. Notice that the target dataset has no label information. We should mention that the subsequent developed approach does not hinge on the number of source receivers. Thus, for ease of exposition, we consider one source receiver; extension to multiple source receivers is straightforward.
2.2. Source-Free Cross-Receiver RFFI
The problem of SCRFFI can be described as follows: Let denote the model trained on labeled data from the source domain . With known and utilizing unlabeled data from the target domain , our objective is to develop an RFFI model that minimizes the classification error on . Specifically, our goal is to minimize
where represents the unknown true label function for the target domain. Here, and denote the expected risk and empirical risk, respectively, when applying a classification model h to the target domain. The hypothesis space encompasses all potential models mapping from to . The specific form and capacity of are dictated by the architecture and size of the neural network employed. The efficacy of the classification model is closely tied to the complexity of , often characterized by metrics such as the Vapnik–Chervonenkis (VC) dimension [13]. This will be further discussed in the subsequent section.
3. Theoretical Analysis
To gain insights into our proposed design, we begin with a theoretical analysis of the SCRFFI problem. Directly minimizing problem (1) is not possible due to the lack of information about . Therefore, we turn to the pseudo-label technique and define a pseudo-label function for the target domain. An example of such a function could be the original source model . The next section will detail how to improve using and . For the purpose of this analysis, we assume that an is already available for model adaptation. To simplify our discussion, we focus on the case where . Now, let us consider the following learning problem in the target domain:
where is a small number close to zero, and
with being the k-th entry of the vector h.
The problem in (2) serves as a manageable approximation for the problem in (1), aiming to minimize empirical risk relative to while incorporating additional constraints. Because is generally imprecise (i.e. ), merely minimizing is inadequate for enhancing the model’s performance. However, as the following theorem demonstrates, constraint (2b) plays a crucial role in facilitating effective model learning on the target domain.
Theorem 1.
Let be an optimal solution of problem (2). Suppose that the hypothesis space has a VC dimension d. Then, for any , with probability at least , the following inequality holds:
where .
Proof of Theorem 1.
First, we show that the ground-truth label function is a feasible solution to problem (2). By the definition of , we know is a one-hot vector for all . By substituting into (3), we have , which satisfies the constraint (2b). Therefore, is a feasible solution of problem (2).
Next, according to the VC theory [13], the expected loss can be bounded by its empirical estimate . Specifically, if is an -sized i.i.d. sample, then, with probability exceeding ,
Therefore, we have
Then, it follows from the triangle inequality [14], i.e.,
that the right-hand side of (5) can be further bounded as
Combining (5) and (6) yields
Since is an optimal solution of problem (2), we have
which, together with (7), implies
Finally, applying the VC theory [13] again to , we get
Substituting the above inequality into (8) yields
This completes the proof. □
The inequality presented in (4) highlights that the expected classification error probability for on the target domain is constrained by a certain constant. This constant is influenced by the number of samples , the capacity d of the hypothesis space , and the precision of the pseudo-label function . Notably, is typically a fixed value that does not depend on the learning method used. Consequently, enhancing the accuracy of the pseudo-label function is crucial for minimizing this upper bound. If perfectly matches , then approaches zero.
4. Proposed Method
The CSCNet, as depicted in Figure 2, is structured to address the adaptation challenge. The model integrates a feature extractor and a classifier , formulated as . Here, denotes the signal space, d represents the dimensionality of the feature space, and and are the respective parameters governing the feature extractor and classifier.
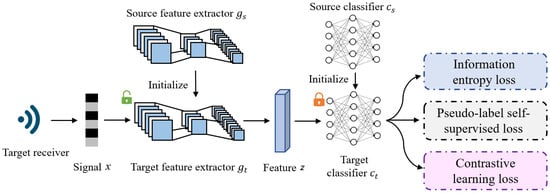
Figure 2.
The overview of proposed method CSCNet. The model comprises two primary components: the feature extractor (g) and the classifier (C). The role of the feature extractor g is to extract emitter’s fingerprint from the received signal, while the classifier C maps the feature to the corresponding class. Our method involves loading the source model and , which are pre-trained on the source domain . Then, we freeze the parameters of and update the feature extractor g to adapt the target domain . Three kinds of losses are considered, namely, information entropy loss, pseudo-label self-supervised loss, and contrastive learning loss.
At its core, the CSCNet model is composed of two primary, interconnected components: a feature extractor (g) and a classifier (C). The feature extractor’s crucial role is to meticulously extract the unique radio frequency fingerprints from the received signals. These fingerprints, which are subtle characteristics stemming from inherent hardware imperfections, are then passed to the classifier. The classifier’s function is to accurately map these extracted features to their corresponding emitter class, thereby identifying the transmitting device. Our method involves loading the source model and , which are pre-trained on the source domain . Subsequently, we freeze the parameters of and update the feature extractor g to adapt to the target domain .
The adaptation strategy of CSCNet involves leveraging a trained source model , which has been trained using supervised learning on the labeled source domain to minimize cross-entropy loss. In the adaptation phase to the target domain , the classifier’s parameters remain fixed, while the feature extractor’s parameters are re-optimized to better align with the characteristics of . According to Theorem 1, solving problem (2) is theoretically beneficial for achieving domain adaptation. However, due to the inherent constraints in problem (2), we explore an alternative approach by minimizing its penalized form:
where denotes the empirical risk with respect to the pseudo-label function . Here, represents a regularization term to promote generalization, controlled by the hyperparameter .
Specifically, CSCNet integrates a three-pronged loss function strategy to achieve robust model adaptation. This strategy includes minimizing information entropy loss to encourage confident predictions, implementing pseudo-label self-supervised loss to leverage self-generated labels for training, and crucially, incorporating contrastive learning loss to capture the intricate relationships between signal samples effectively. This multi-faceted approach allows the model to learn powerful representations solely from unlabeled data on the deployed receiver, significantly enhancing recognition accuracy and robustness in cross-receiver RFFI scenarios.
The optimization of problem (9) is intricately linked to the pseudo-label function , and vice versa. However, jointly optimizing and can be challenging. To address this, an alternating optimization strategy is proposed:
- 1.
- Initialization: Begin with initialized using the source-trained model .
- 2.
- Pseudo-Label Generation: Utilize to generate pseudo-labels for all samples .
- 3.
- Feature Extractor Update: Formulate and solve problem (9) using the generated pseudo-labels to update .
- 4.
- Pseudo-Label Update: Update the pseudo-label function with the latest network parameters: .
- 5.
- Iteration: Repeat steps (2)–(4) iteratively until convergence criteria are met.
These iterative steps are crucial for progressively refining the feature extractor g to better capture domain-specific characteristics while continuously updating the pseudo-label function to improve model adaptation. Subsequent subsections will delve deeper into each of these steps, providing comprehensive insights and experimental validations to support the proposed approach.
4.1. Pseudo-Label Generation
The source-trained model provides an initial basis for generating pseudo-labels in the target domain . For each target data point , the pseudo-label is determined as
where denotes the k-th element of the output vector , representing the model’s confidence that belongs to class k.
However, due to the domain shift between and , these initial pseudo-labels are often not accurate and can be sensitive to domain discrepancies. To improve their accuracy, we propose a clustering-based pseudo-labeling strategy:
- 1.
- Initialization: Start with , where denotes the output of the source-trained model for signal x.
- 2.
- Initial Weighted Center Calculation: Compute the initial weighted center for each class k using the feature vectors extracted by the feature extractor :Here, denotes the k-th component of .
- 3.
- Pseudo-Label Assignment: Assign pseudo-labels to each target data point based on cosine similarity with the class centers :This step ensures that is assigned to the class whose centroid is most similar to .
- 4.
- Update of Target Feature Centers: Update the class centers using k-means clustering with the updated pseudo-labels :This step adjusts by averaging the feature vectors of data points assigned to class k, ensuring the centers reflect the current distribution of the target domain.
- 5.
- Iteration: Iterate steps (3) and (4) until convergence criteria are met for the k-means algorithm. Convergence indicates stability in the assignment of pseudo-labels and the centroids .
By iteratively refining the pseudo-labels based on clustering with the feature vectors and updating the class centers accordingly, this approach progressively improves the alignment of the model h with the target domain . This method effectively mitigates the domain shift between and , enhancing the adaptation process of the model for accurate classification on the target domain.
4.2. Feature Extractor Update
Given the pseudo-label assigned to each target data point , we utilize standard supervised learning techniques to update the parameters of the feature extractor. Instead of using the empirical risk defined in Equation (9), we adopt the cross-entropy loss, which measures the discrepancy between predicted probabilities and the pseudo-labels:
where denotes the output probability vector of the classifier C with parameters .
To further enhance the utilization of pseudo-label information, we employ contrastive learning techniques, inspired by recent advancements in representation learning [15]. Contrastive learning aims to improve the feature representation by encouraging similar data points to be closer together and dissimilar ones to be farther apart in the feature space. The contrastive learning loss function is designed to maximize the agreement between the feature representations of instances sharing the same pseudo-label and differentiate those from different classes. It is defined as
where is a temperature hyper-parameter controlling the sharpness of the softmax function, and represents the cosine similarity between the feature vector and a learnable vector associated with the k-th class:
Here, corresponds to the parameters of the fully connected layer in the classifier C. It should be noted that since the classifier C is frozen, the is fixed and not updated during adaptation.
In summary, the parameter of the feature extractor is updated by minimizing the combined loss:
where and are hyper-parameters controlling the contributions of contrastive learning and entropy regularization, respectively. The update of using gradient descent is performed iteratively:
where denotes the learning rate.
This approach integrates supervised learning with cross-entropy loss and unsupervised contrastive learning to adapt the feature representation to the target domain . By leveraging pseudo-labels and contrastive learning, the model effectively learns a discriminative feature space that mitigates domain shift challenges, enhancing its performance in target domain tasks.
5. Experiment
5.1. Setups
In this section, we will evaluate the performance of our model using two real-world datasets: HackRF and Wisig [16]. The HackRF dataset comprises data received from multiple HackRF hardware devices. On the other hand, Wisig is a large-scale WiFi dataset, and for our experiment, we use a subset of Wisig, called “ManySig”. The datasets consist of signals received by multiple receivers, from which we can choose two. One receiver is designated as the source receiver, and the other is the target receiver. In the following subsections, we provide a brief overview of the datasets and describe the implementation of our method.
5.1.1. Dataset
HackRF, a cost-effective open-source software radio platform, is used to generate and collect the HackRF dataset, which includes signal data. Data collection involved four HackRFs as transmitting terminal devices and three HackRFs (referred to as HackRF 1, 2, and 3) as receivers. Signals were generated using Matlab and modulated using BFSK with a 2 MHz sampling rate. To introduce randomness, amplitude and frequency noise were uniformly added to the signals. This process ensures the dataset simulates realistic communication environments where signal quality can be degraded, thereby providing a basis for evaluating the model’s robustness against noise. The transmitted signals passed through a relatively fixed channel and were moved to the intermediate frequency (IF) before being received by the receiving device. The collected signals were transformed into signal time-domain samples using data frames, with each time-domain sample containing 28,000 sampling points. By performing short-time Fourier transform (STFT) on each time-domain signal sample, the corresponding spectrogram is obtained. The time-domain signal and its spectrum are illustrated in Figure 3.
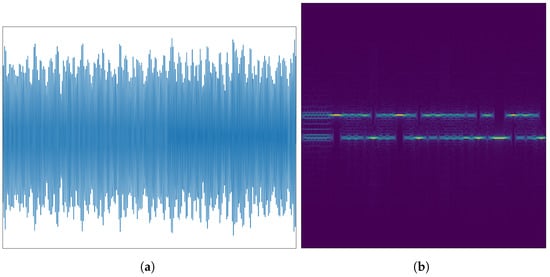
Figure 3.
Signals of HackRF dataset: (a) waveform of HackRF; (b) spectrogram of HackRF.
The Wisig dataset [16] is a large-scale WiFi dataset containing 10 million packets obtained from 174 off-the-shelf WiFi transmitters (Tx) and 41 USRP receivers (Rx) across four captures over a month. The Tx and Rx are deployed on nodes arranged in a grid. The 2D-coordinate scattergram of Tx and Rx is shown in Figure 4a,b, respectively. For our experiment, we used the ManySig subset provided by the dataset, comprising 1000 equalized signals from all Tx-Rx pairs, including 6 Tx and 12 Rx, spanning over four days. As a large-scale dataset captured in a real-world environment, its signals inherently encompass a range of channel effects and authentic signal-to-noise ratios, offering a practical benchmark for the model’s performance under non-ideal conditions. The time-domain signal and its spectrum of Wisig dataset are illustrated in Figure 4c,d. Each signal contains two channels and 256 sample points. During the cross-receiver test, the dataset is divided into 12 parts, each corresponding to a receiver with capturing time spanning over four days. The time-domain signal and its spectrum of Wisig dataset are illustrated in Figure 4c,d.
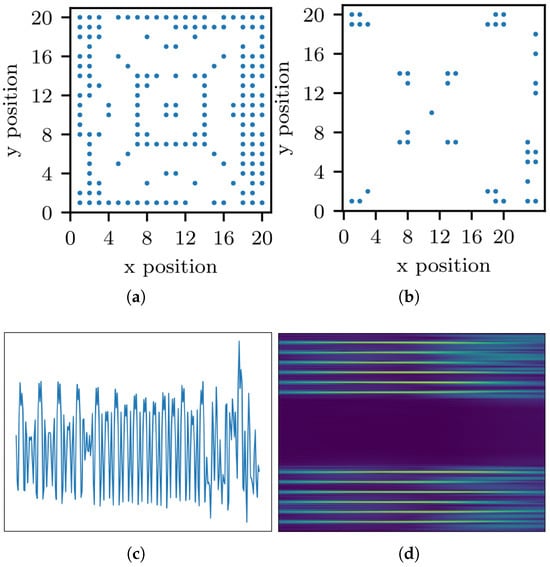
Figure 4.
Scenario description of Wisig dataset [16]: (a) positions of Tx; (b) positions of Rx; (c) waveform of Wisig; (d) spectrogram of Wisig.
5.1.2. Implementation Details
The feature extractor for HackRF employs ResNet50 [17], while for Wisig, ResNet18-1D is utilized. To adapt to one-dimensional time series signals, ResNet18-1D is derived from ResNet18 by substituting the 2D-convolution with 1D-convolution. Additionally, the classifier networks are implemented using a four-layer fully connected network. For data preprocessing, we applied min-max normalization to scale the RF samples to the range of . This normalization aids in the convergence of the neural network training. The formula used for this normalization is
where z represents the input data, is the normalized output, and and are the minimum and maximum values of z, respectively. No additional data augmentation or filtering methods were applied to the raw RF signals beyond this normalization.
The initial learning rate is set as . The hyperparameters and are set to 0.2 and 0.5, respectively. The temperature coefficient , and the total number of training epochs is set to 50. As for the final results, we calculate the classification accuracies of the models on the test dataset for the last five epochs of each experiment.
5.2. Comparison with the Source-Only Method
To assess the effectiveness of our network model, we conducted a comparison with source-only methods. The source-only method utilizes only cross-entropy loss as the loss function and trains the network solely on data from the source receiver, without employing any other algorithms for adaptation.
Table 1 presents the performance comparison between the traditional method and our proposed approach when using different datasets. In the HackRF dataset, the i-th receiver is called “HackRF i”, while “” denotes adaptation from receiver HackRF i to HackRF j. We designate HackRF i as the source receiver, while HackRF j serves as the target receiver. For the Wisig dataset, to uniquely represent transmitters (Tx) and receivers (Rx) on a 2D grid, we assign them two-dimensional (2D) coordinates, denoted as “” for receiver located at . The notation “” signifies adaptation from data collected at receiver “” to that of “”. Similar to the HackRF dataset, we designate the receiver “” as the source receiver, and the receiver “” as the target receiver.

Table 1.
Classification accuracies (%) comparison with source-only method.
Upon testing, when the same receiver is applied for training and testing, the recognition accuracies of the source-only model attained 93.77% and 99.99% for the HackRF dataset and the Wisig dataset, respectively. Therefore, for the within-receiver test, the source-only model already works very well. However, as shown in Table 1, when the training and test data come from different receivers, the source-only model’s recognition accuracy dramatically drops to around 50% to 60%, indicating the significant impact of the receiver’s fingerprint on the results. In contrast, our proposed CSCNet model achieves significantly improved recognition accuracy, with an improvement of at least 13%. Notably, in the “1-19 → 7-7” task, the recognition accuracy improved by 47%. These results conclusively demonstrate the effectiveness of the CSCNet model in addressing the receiving impact.
5.3. Comparison with Other Domain Adaptation Methods
We conducted a comparison of our proposed method with other domain adaptive methods on the Wisig dataset, including DANN [18], MCD [19], and SHOT [20].
As presented in Table 2, our CSCNet method outperforms the other domain-adaptive methods significantly. In comparison with the best-performing method, CSCNet demonstrates a remarkable improvement in recognition accuracy across different tasks. For the task “1-1 → 1-19”, CSCNet achieves an accuracy of 92.64%, which is significantly higher than the best alternative method, MCD, which has an accuracy of 79.64%. For the task “1-1 → 8-8”, although DANN shows a slightly higher accuracy of 96.52%, CSCNet still performs competitively with an accuracy of 95.72%. In the task “7-7 → 8-8”, CSCNet achieves the highest accuracy of 88.00%, surpassing all other methods. This demonstrates the robustness and effectiveness of CSCNet in various domain adaptation scenarios.
Table 2.
Classification accuracies (%) comparison with other UDA methods.
5.4. Ablation Experiment
We conducted a series of ablation experiments to evaluate the components of our proposed method, specifically focusing on two key elements: the information entropy loss (IEL) and the contrastive learning loss (CLL). To isolate the effects of each component, we designed four configurations: a baseline with no losses, serving as a control to measure the performance impact of each loss; a setup incorporating only the IEL; another configuration employing only the CLL; and a final setup combining both losses to explore their synergistic effects on model performance. Extensive experiments were carried out across multiple cross-domain tasks, with the results summarized in Table 3, demonstrating the individual and combined contributions of each component to the overall effectiveness of the method.
Table 3.
Ablation accuracies (%).
As shown in Table 3, the baseline configuration, which does not include any specific loss functions, achieves accuracies of 59.14%, 62.42%, and 44.50% for the tasks “1-1 → 1-19”, “1-1 → 8-8”, and “7-7 → 8-8”, respectively. When only the information entropy loss (IEL) is applied, the performance improves significantly, with accuracies reaching 74.61%, 88.73%, and 74.73% for the same tasks. On the other hand, the configuration using only the contrastive learning loss (CLL) shows a decline in performance, achieving accuracies of 49.38%, 49.15%, and 39.81%. The most notable improvement is observed when both IEL and CLL are combined, resulting in the highest accuracies of 92.64%, 95.72%, and 88.00%, indicating a strong synergistic effect between these two components.
5.5. Effect of SNR on Model Accuracy
To address the practical deployment of the model and evaluate its robustness, we investigated the effect of the signal-to-noise ratio (SNR) on the accuracy of CSCNet. We simulated various noise conditions by adding additive white Gaussian noise (AWGN) to the test signals of both the HackRF and Wisig datasets to achieve SNR levels of 0 dB, 5 dB, 10 dB, 15 dB, and 20 dB. The results are presented for several cross-receiver adaptation tasks in Figure 5.
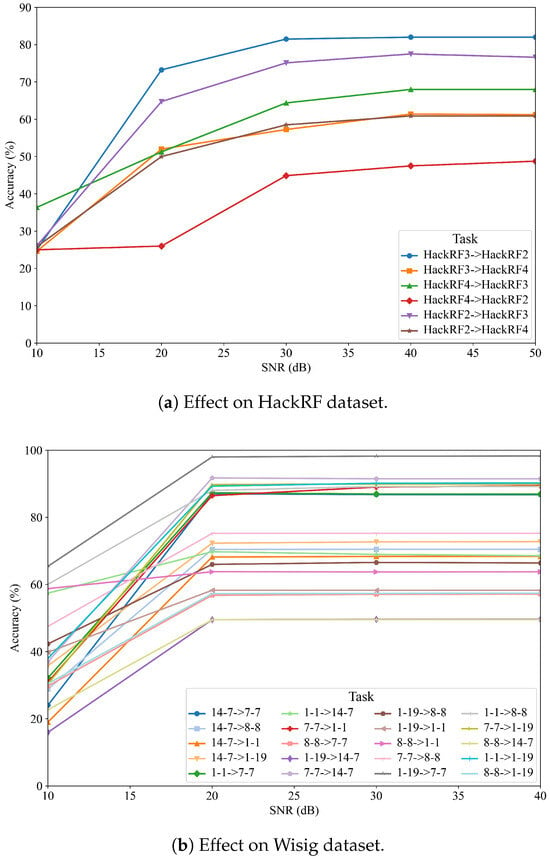
Figure 5.
Effect of SNR on the accuracy of CSCNet for various cross-receiver tasks on the (a) HackRF and (b) Wisig datasets.
Figure 5a illustrates the performance of CSCNet on the HackRF dataset under different SNR conditions. As expected, the model’s accuracy is significantly impacted by noise. At a low SNR of 0 dB, the performance is generally poor across all tasks, with accuracies ranging from 25% to 36%. However, as the SNR increases to 5 dB and 10 dB, there is a substantial improvement in accuracy. For instance, in the ‘h2 → h3’ task, the accuracy jumps from 26.12% at 0 dB to 75.12% at 10 dB. For most tasks, the performance tends to saturate or plateau when the SNR is 10 dB or higher, indicating that the model performs robustly in moderately noisy environments.
Similarly, Figure 5b shows the results for the Wisig dataset. The trend is consistent, where higher SNR leads to better performance. The influence of noise is particularly evident in challenging adaptation tasks. For example, in the ‘1-19 → 14-7’ task, the accuracy is only 15.96% at 0 dB but climbs to nearly 50% at 10 dB. In contrast, for tasks where the model adapts well, such as ‘1-19 → 7-7’, the accuracy starts at a respectable 65.42% at 0 dB and quickly reaches over 98% at higher SNRs. This analysis confirms that while CSCNet’s performance is dependent on signal quality, it demonstrates strong robustness and achieves high accuracy under realistic noise conditions (SNR ≥ 10 dB), which is crucial for real-world applications. These results also underscore that some cross-receiver pairs are inherently more challenging to adapt to, regardless of the noise level.
5.6. t-SNE Visualization
To provide compelling qualitative validation for our method, we employed t-SNE to visualize the learned high-dimensional feature representations, with the results depicted in Figure 6. This visualization offers a clear narrative of the problem and our solution’s efficacy. Initially, for the in-domain scenario, the source-trained model demonstrates its full potential by mapping source data into a well-structured feature space, characterized by high intra-class compactness and clear inter-class separation (Figure 6a). This ideal clustering signifies that the learned features are highly discriminative. However, this finely-tuned feature structure proves fragile when confronted with the cross-receiver domain shift. When the model is applied to target domain data, the feature space integrity collapses into a chaotic and non-discriminative manifold where features from different classes become severely entangled (Figure 6b). This visual evidence explains why traditional classifiers fail: No simple decision boundary can effectively partition such an overlapped space. This is the critical challenge CSCNet addresses. Through its source-free adaptation strategy—which uniquely combines information entropy minimization with pseudo-label-guided contrastive learning—CSCNet actively remodels the target feature space. It learns to disentangle the mixed representations by pulling samples with the same pseudo-label closer together while pushing others apart. The result is a remarkable restoration of order, as seen in Figure 6c, where distinct, albeit not as perfect as the source-domain baseline, clusters re-emerge. This visual journey from a well-ordered space, through a chaotic collapse, to a successfully restructured state powerfully demonstrates CSCNet’s ability to learn domain-agnostic features. It serves as strong corroborating evidence for the quantitative accuracy gains, confirming that the performance improvement stems from a fundamental enhancement of the feature representation itself.
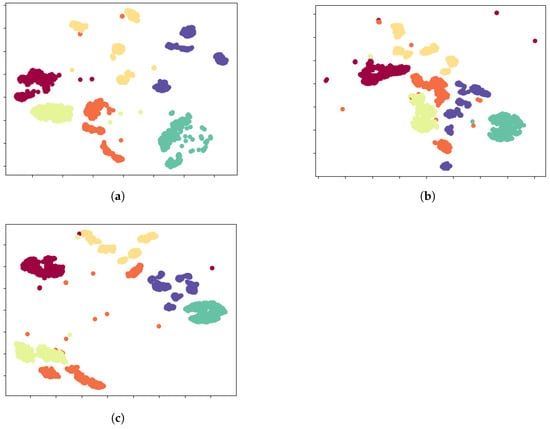
Figure 6.
t-SNE visualization of the learned feature representations, providing a qualitative assessment of the model’s effectiveness. In all subplots, different colors are used to distinguish signals from different transmitter classes. The clustering of same-colored points and the separation between different-colored clusters visually represent the model’s classification capability. (a) Features from the source domain data, extracted by the source-trained model, show clear and well-separated class clusters, representing the ideal performance baseline. (b) When the source model is applied directly to the target domain data, the feature representations of different classes (colors) become heavily overlapped and indistinguishable, visually demonstrating the severe impact of the domain shift problem. (c) Features from the target domain data, extracted by our proposed CSCNet model, show that the class-specific clusters (colors) are reformed and become significantly more separable, which powerfully demonstrates the effectiveness of our source-free adaptation method.
6. Conclusions
This paper introduced the source-free cross-receiver rf fingerprinting (SCRFFI) problem, tackling the crucial challenge of adapting pre-trained RF fingerprinting models to new receivers without accessing original training data, a vital aspect for data privacy and deployment. Our theoretical analysis provided an upper bound on generalization performance, emphasizing the role of pseudo-label accuracy. To address this, we proposed CSCNet, a novel approach leveraging information entropy loss, pseudo-label self-supervised loss, and contrastive learning loss. Experimental results on HackRF and Wisig datasets demonstrated CSCNet’s significant effectiveness. It consistently outperformed the source-only method, with recognition accuracy improvements of at least 13% and, notably, a 47% gain in the “1-19→7-7” task on Wisig (from 50.88% to 98.12%). CSCNet also surpassed other domain adaptation methods like DANN, MCD, and SHOT. Ablation studies confirmed the synergistic contribution of information entropy and contrastive learning losses. These achievements highlight CSCNet’s robustness in mitigating receiver variations and its practical value for RFFI deployment.
Author Contributions
Conceptualization, J.Y. and Q.L.; methodology, J.Y. and S.Z.; validation, S.Z. and Z. Wen; formal analysis, J.Y. and Q.L.; writing—original draft preparation, J.Y., S.Z. and Z.W.; writing—review and editing, Q.L.; supervision, Q.L.; funding acquisition, Q.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by National Natural Science Foundation of China under Grant 62171110.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Xie, L.; Peng, L.; Zhang, J.; Hu, A. Radio frequency fingerprint identification for Internet of Things: A survey. Secur. Saf. 2024, 3, 2023022. [Google Scholar] [CrossRef]
- Merchant, K.; Nousain, B. Toward receiver-agnostic RF fingerprint verification. In Proceedings of the 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Shen, G.; Zhang, J.; Marshall, A.; Woods, R.; Cavallaro, J.; Chen, L. Towards receiver-agnostic and collaborative radio frequency fingerprint identification. IEEE Trans. Mob. Comput. 2024, 23, 7618–7634. [Google Scholar] [CrossRef]
- Zhao, T.; Sarkar, S.; Krijestorac, E.; Cabric, D. GAN-RXA: A practical scalable solution to receiver-agnostic transmitter fingerprinting. IEEE Trans. Cogn. Commun. Netw. 2024, 10, 403–416. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, S.; Yang, L.; Li, Q.; Lin, J. Receiver-agnostic radio frequency fingerprint identification via feature disentanglement. In Proceedings of the 2023 IEEE 24th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Shanghai, China, 25–28 September 2023; pp. 46–50. [Google Scholar]
- Zhu, W.; Li, J.; Wang, Z.; Li, Q.; Lin, J.; Xiaoxiao, S. Radio frequency fingerprints identification based on GAN networks. In Proceedings of the 2023 IEEE 24th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Shanghai, China, 25–28 September 2023; pp. 51–55. [Google Scholar]
- Yang, L.; Li, Q.; Ren, X.; Fang, Y.; Wang, S. Mitigating receiver impact on radio frequency fingerprint identification via domain adaptation. IEEE Internet Things J. 2024, 11, 24024–24034. [Google Scholar] [CrossRef]
- Feng, J.; Fang, S.; Fan, Y. Cross-Receiver Radio Frequency Fingerprint Identification Based on Domain Adaptation With Dynamic Distribution Alignment. IEEE Internet Things J. 2025; early access. [Google Scholar]
- Li, K.; Bao, J.; Xie, X.; Hong, J.; Hua, C. Receiver-Agnostic Radio Frequency Fingerprint Identification for Zero-Trust Wireless Networks. IEEE J. Sel. Areas Commun. 2025, 43, 1981–1990. [Google Scholar] [CrossRef]
- Li, W.; Wang, J.; Liu, T.; Xu, G. Receiver-Agnostic Radio Frequency Fingerprinting Using a Prototypical Contrastive Domain Adaptation Method. IEEE Signal Process. Lett. 2025, 32, 1910–1914. [Google Scholar] [CrossRef]
- Zhou, F.; Qiao, X.; Wu, H.; Zhang, J. Receiver-Agnostic Radio Frequency Fingerprint Identification Based on Disentangled Feature Cross Combination. IEEE Wirel. Commun. Lett. 2025; early access. [Google Scholar]
- Cai, Z.; Lu, G.; Wang, Y.; Gui, G.; Sha, J. Robust Cross-Domain UAV RFFI Method Using Domain-Invariant Adversarial Learning and Manifold Regularization. IEEE Trans. Cogn. Commun. Netw. 2025; early access. [Google Scholar]
- Vapnik, V. Statistical Learning Theory; John Wiley: New York, NY, USA, 1998. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef]
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Hanna, S.; Karunaratne, S.; Cabric, D. Wisig: A large-scale WiFi signal dataset for receiver and channel agnostic RF fingerprinting. IEEE Access 2022, 10, 22808–22818. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3723–3732. [Google Scholar]
- Liang, J.; Hu, D.; Feng, J. Do we really need to access the source data? Source hypothesis transfer for unsupervised domain adaptation. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 6028–6039. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).