1. Introduction
Special vehicle target detection, as an important research direction in computer vision, has extensive application prospects and significant practical value in traffic monitoring, industrial inspection, reconnaissance, disaster rescue, and other domains [
1,
2]. Unlike ordinary vehicles, special vehicles typically possess complex structural features, diverse appearance forms, and specific functional components, making their detection and recognition face greater challenges [
3]. Accurate and efficient special vehicle detection systems can not only improve traffic management efficiency and enhance industrial safety monitoring capabilities but also provide critical technical support for emergency rescue and equipment maintenance [
4].
In this paper, special vehicles refer to specialized military and civilian vehicles including but not limited to main battle tanks, armored personnel carriers, self-propelled artillery, mobile radar systems, fire trucks, ambulances, and engineering vehicles. These vehicles are characterized by unique structural features such as armored hulls, rotating turrets, specialized equipment mountings, and distinctive geometric configurations that differentiate them from conventional civilian vehicles. The detection of such vehicles presents unique challenges including complex geometric structures, camouflage patterns, partial occlusion by terrain features, varying scales in aerial imagery, and the need to identify specific components like turrets and sensor arrays that are crucial for vehicle classification and threat assessment.
Traditional special vehicle target detection methods primarily rely on hand-crafted feature extractors and classifiers, such as the Histogram of Oriented Gradients (HOG), Scale-Invariant Feature Transform (SIFT), and Support Vector Machines (SVMs) [
5]. Dalal and Triggs [
6] proposed a vehicle detection method based on the HOG and SVMs, improving detection accuracy by constructing multi-scale feature pyramids. Zheng et al. [
7] combined geometric and texture features of special vehicles to design a vehicle detection algorithm for high-resolution remote sensing images.
With the rapid development of Convolutional Neural Networks (CNNs), special vehicle target detection methods based on deep learning have achieved significant progress. With the rapid development of Convolutional Neural Networks (CNNs), special vehicle target detection methods based on deep learning have achieved significant progress [
8]. Wang et al. [
9] proposed a multi-scale feature fusion method based on deep residual networks, significantly improving vehicle detection accuracy. Liu et al. [
10] designed an attention-enhanced feature extraction network, effectively improving special vehicle detection performance under complex backgrounds. Chen et al. [
11] proposed a domain adaptation method for multi-view special vehicle detection, addressing cross-scene detection challenges. Ma and Xue [
5] conducted a comprehensive review of deep learning-based vehicle detection methods, highlighting the widespread application of two-stage and single-stage detectors in intelligent transportation systems. With the introduction of self-attention mechanisms and Transformer architectures, detection performance has been further enhanced.
In recent years, general object detection frameworks have demonstrated good performance and strong practicality in the special vehicle detection domain. These methods are typically categorized into two types: single-stage detectors (such as YOLO series [
12,
13], SSD [
14]) and two-stage detectors (such as Faster R-CNN [
15], Mask R-CNN [
16]). Single-stage detectors directly predict target locations and categories with high inference speed; two-stage detectors first generate candidate regions and then perform classification and refinement, typically achieving higher detection accuracy. The YOLO series, with its excellent speed-accuracy balance, has been widely adopted in real-time special vehicle detection applications. Zaidi et al. [
17] reviewed recent deep learning object detection models, analyzing the application effects of various models in different scenarios. Improved versions such as YOLOv5 [
18] and YOLOv7 [
19] further enhanced feature extraction and multi-scale target detection capabilities.
Recently, Transformer-based detectors have become research hotspots due to their powerful global modeling capabilities. Carion et al. [
20] proposed DETR, which first successfully applied Transformers to object detection, eliminating hand-crafted components in traditional detectors (such as anchors and non-maximum suppression), but with slow inference speed. To address this issue, Zhao et al. [
21] proposed RT-DETR (Real-Time Detection Transformer), achieving efficient real-time inference through hybrid encoders and lightweight decoders. RT-DETR employs efficient hybrid encoders to process multi-scale features, achieving significant inference speed improvements while maintaining high accuracy through decoupled intra-scale interaction and cross-scale fusion [
22].
Zhang et al. [
23] proposed DINO (DETR with improved denoising anchor boxes), significantly improving DETR model performance and efficiency through contrastive denoising training, hybrid query selection methods for query initialization, and look-forward-twice box prediction schemes. Li et al. [
24] explored vehicle logo recognition methods based on Swin Transformers, utilizing their efficient computation and global feature modeling capabilities to enhance key feature extraction for special vehicles. Wang et al. [
25] designed a dynamic graph learning method based on content-guided spatial-frequency relationship reasoning. Although applied to DeepFake detection, its spatial-frequency hybrid attention mechanism provides new insights for enhancing feature expression capabilities, which can be transferred to vehicle key component recognition tasks. While recent works like Hyper-YOLO [
26] have explored ε-ball semantic space hyperedges for general object detection, our approach specifically designs geometry-driven hypergraph structures tailored for special vehicle detection challenges. Unlike ε-ball semantic hyperedges that rely on feature similarity in embedding space, our geometric neighborhood-based hyperedges capture spatial relationships and structural patterns specific to armored vehicles and their components, enabling the more precise detection of rigid geometric structures such as turrets.
Despite significant progress in target detection technology in the special vehicle recognition domain, the following key challenges remain: insufficient feature extraction, where existing backbone networks struggle to capture subtle differences between targets and backgrounds and hierarchical relationships between components when processing high-resolution special vehicle images; inadequate multi-scale feature fusion, where traditional fusion networks fail to establish effective correlations between different scale features, leading to low detection accuracy for small components and difficulty distinguishing similar structures; unbalanced attention allocation, where existing encoders have uneven attention allocation for targets under complex backgrounds, limited long-range dependency modeling capabilities, and insufficient frequency-domain information processing, affecting model robustness; information loss during upsampling, where traditional upsampling methods suffer from feature accuracy loss, limited detail recovery capabilities, and insufficient inter-channel information interaction, resulting in blurred boundaries and inaccurate fine structure recognition.
Addressing the above challenges, this paper proposes HSF-DETR (Hypergraph Spatial Feature DETR), a special vehicle detection algorithm based on hypergraph spatial features and bipolar attention. The main contributions are as follows:
A Cascaded Spatial Feature Network (CSFNet) backbone is proposed, based on Cross-Efficient Convolutional Gating (CECG) feature extraction modules. By combining hybrid state-space modeling with convolutional gating mixing units, it enhances the network’s detection capability for long-range special vehicles and their key components while improving model robustness under adverse conditions such as occlusion, lighting variations, and complex backgrounds.
A Hypergraph-enhanced Spatial Feature Modulation (HyperSFM) feature fusion network is designed. This network models high-order feature correlations through hypergraph structures and combines Spatial Feature Modulation (SFM) to achieve efficient fusion and adaptive modulation between different scale features, significantly improving the system’s detection capability for vehicle key components.
A Dual-Domain Feature Encoder (DDFE) is proposed, combining Bipolar Efficient Attention (BEA) and a Frequency-Enhanced Feed-Forward Network (FEFFN). Through innovative bipolar representation and frequency-domain enhancement mechanisms, it achieves more precise feature weight allocation and richer detail feature extraction, improving system detection accuracy and robustness under complex environments.
A Spatial-Channel Fusion Upsampling Block (SCFUB) is developed. This module combines depth-wise separable convolution with channel shift mixing techniques, significantly enhancing feature fidelity and spatial consistency during upsampling while maintaining computational efficiency, effectively addressing fine recognition issues of special vehicle key components.
By integrating the above four innovative modules, HSF-DETR forms an end-to-end detection framework, achieving a balance between accuracy and efficiency in special vehicle detection tasks.
2. Related Work
2.1. Dataset Construction and Annotation Strategy
Special vehicle detection is a key technology in modern intelligent surveillance, emergency rescue, and reconnaissance domains. However, existing public datasets mainly focus on conventional civilian vehicles, lacking specialized datasets for special vehicles and their key components under complex environments, severely constraining the performance optimization of related detection algorithms in special scenarios. To address this issue, this research constructs a high-quality complex environment special vehicle detection dataset containing 2388 meticulously annotated images, divided into a training set (1671 images), validation set (239 images), and test set (478 images) at a 7:1:2 ratio. All images are precisely annotated by professional equipment identification experts to ensure data quality and annotation accuracy.
As shown in
Figure 1, the dataset covers various typical complex environment scenarios: (a) multi-target detection scenes in barren desert terrain; (b) concealed target recognition in mountainous and hilly environments; (c) long-range surveillance scenes in open plain areas; (d) occluded target detection under dense forest vegetation coverage; (e) low-visibility detection under smoke interference conditions; (f) camouflaged target recognition in complex vegetation terrain. Data collection primarily employs unmanned aerial vehicle bird’s-eye view imaging, supplemented by ground-level perspectives, comprehensively simulating diverse visual challenges in real-world applications. The dataset defines two core detection categories, tank (vehicle body) and turret (turret component), where the turret serves as a key identification feature of special vehicles. Its precise detection is crucial for vehicle type discrimination and intelligent decision making, providing important data support for algorithm research and engineering applications in related domains.
2.2. RT-DETR Baseline Framework Model and Comparative Analysis
RT-DETR (Real-Time Detection Transformer) is an end-to-end real-time object detection model proposed by Baidu [
21]. It mainly consists of three core components: backbone network, encoder, and decoder.
The backbone network includes ResNet and HGNetv2 series. Unlike traditional DETR, RT-DETR extracts multi-scale features from the last three stages (S3, S4, S5) of the backbone network, providing rich multi-scale information for subsequent encoders.
The encoder consists of two key modules: the Attention-based Intra-scale Feature Interaction (AIFI) module and the CNN-based Cross-scale Feature Fusion (CCFF) module. The AIFI module utilizes self-attention mechanisms to process feature interactions within the same scale, enhancing feature expression capabilities, while the CCFF module is responsible for fusion between different scale features, comprehensively utilizing multi-scale information.
The decoder adopts a Transformer structure with auxiliary prediction heads. Based on encoder outputs, RT-DETR introduces an innovative IoU-aware Query Selection mechanism for selecting high-quality initial target queries. The decoder iteratively optimizes these target queries to generate final bounding boxes and confidence scores.
RT-DETR (Real-Time Detection Transformer) demonstrates superior performance compared to the YOLO series in real-time scenarios due to its efficient hybrid encoder design and end-to-end detection paradigm without post-processing requirements like NMS. RT-DETR-R50 achieves 53.1% AP at 108 FPS on the COCO dataset, outperforming YOLOv8 in both speed and accuracy while eliminating inference delays caused by non-maximum suppression.
Recent advances have also explored hypergraph structures for object detection. The Hyper-YOLO series [
26] introduces hypergraph computation-empowered semantic collecting and scattering frameworks, demonstrating the potential of hypergraph structures in capturing complex feature relationships. These methods utilize ε-ball semantic space hyperedges to model high-order dependencies between features through semantic similarity in embedding space.
2.3. Feature Fusion Networks
The Feature Pyramid Network (FPN) is a key technology in object detection, aimed at addressing multi-scale object detection problems [
27]. Since Lin et al. proposed the FPN in 2017, this technology has become a standard component of many object detectors [
28]. In recent years, researchers have proposed various improved FPN variants to enhance feature representation capabilities.
Ghiasi et al. proposed the NAS-FPN, discovering better feature pyramid structures through neural architecture search [
29]. To better handle small target detection, Deng et al. proposed the Extended Feature Pyramid Network, enhancing the FPN’s sensitivity to small-scale targets [
30]. Addressing information loss during feature fusion, Zhu et al. proposed an improved Feature Pyramid Network (ImFPN), which includes segmentation attention modules and similarity-based fusion modules, better adapting to instances of different scales [
31]. Additionally, some researchers have explored multi-path attention mechanisms to enhance FPN’s representation capabilities, such as MAFPNs (Multi-scale Attention-based Feature Pyramid Networks), which can simultaneously consider scale, spatial, and channel information, more comprehensively processing multi-scale inputs [
32].
The research progress of these Feature Pyramid Networks provides a theoretical foundation for the proposed hypergraph spatial features and bipolar attention mechanisms in this paper. We will build upon these cutting-edge works, combined with the special requirements of special vehicle detection, to propose more effective feature extraction and fusion strategies.
3. Method
This paper proposes HSF-DETR, consisting of four key modules. First, the Cascaded Spatial Feature Network (CSFNet) extracts multi-scale features, followed by the Dual-Domain Feature Encoder (DDFE) combining bipolar directional attention and frequency-domain modulation encoders. Input to the Hypergraph-enhanced Spatial Feature Modulation (HyperSFM) feature fusion network utilizes hypergraph structures to model high-order feature correlations. The Spatial-Channel Fusion Upsampling Block (SCFUB) enhances upsampling quality through channel shift mixing. These four modules work collaboratively to form an end-to-end detection framework, significantly improving detection accuracy and robustness for special vehicles and their key components under complex environments while maintaining high computational efficiency. The overall framework of HSF-DETR is shown in
Figure 2. The following subsections will detail each component module of HSF-DETR and its working principles.
3.1. Cascaded Spatial Feature Network (CSFNet)
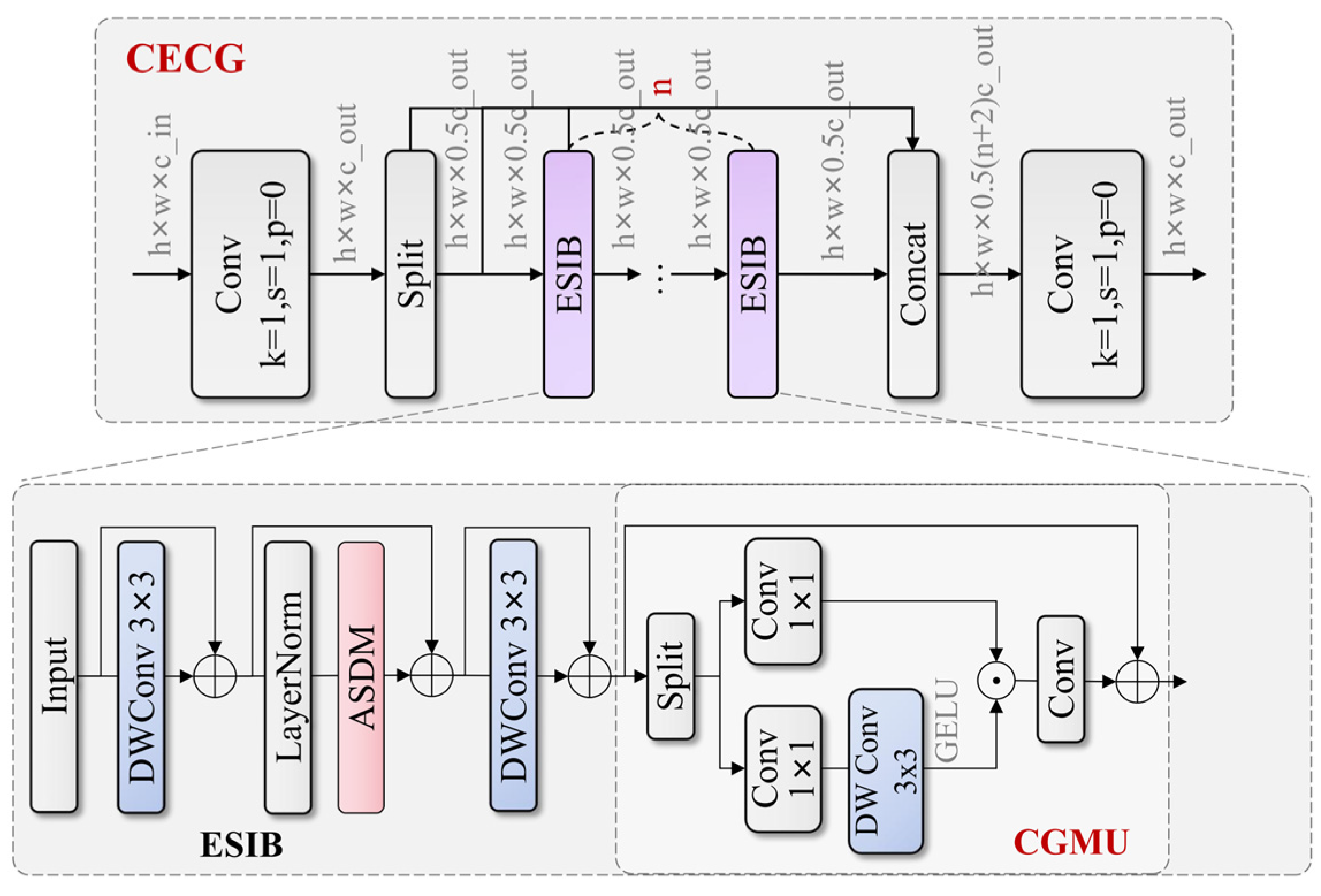
Traditional ResNet backbone networks face issues of insufficient feature extraction, limited representation capabilities, and parameter redundancy when processing high-resolution special vehicle images. Particularly when recognizing large armored vehicles and their rotating observation chambers and other key components in complex terrain, networks struggle to capture subtle differences between targets and backgrounds and hierarchical relationships between components. To address these problems, we propose a Cascaded Spatial Feature Network (CSFNet) backbone based on Cross-Efficient Convolutional Gating (CECG) modules, with the overall structure of CECG shown in
Figure 3. This network enhances the network’s detection capability for long-range special vehicles and their key components by combining hybrid state-space modeling with convolutional gating linear units while improving model robustness under adverse conditions such as occlusion, lighting variations, and complex backgrounds. CSFNet demonstrates significant advantages in application scenarios such as industrial equipment monitoring, traffic management, and disaster rescue vehicle identification.
Our hypergraph topology was dynamically constructed based on geometric neighborhood relationships rather than being fixed or purely learned. Specifically, hyperedges are defined by grouping 3–8 feature nodes within a local spatial window of size 7 × 7. The connectivity criterion was based on spatial distance threshold τ combined with feature similarity. For each potential hyperedge, we computed the geometric centroid of candidate nodes and included nodes that satisfy both spatial proximity (distance < τ × receptive_field_size) and feature similarity (cosine similarity > 0.6). The threshold τ was empirically set to 0.4 based on validation experiments. Each hyperedge typically connects 4–6 nodes representing spatially coherent feature regions, enabling the capture of local geometric patterns while maintaining computational efficiency.
The CECG module achieves feature enhancement through improved Cross-Stage Partial [
33] connections and efficient visual hybrid state-space modeling. The overall mathematical expression of this module can be formalized as follows:
where
and
represent two convolutional layers, respectively,
represents the i-th Efficient Spatial Interaction Block (ESIB) module, and
represents feature concatenation operation. The workflow first maps input features
to hidden space through
and divides them into two parts, where one part is directly transmitted and the other part is processed through cascaded ESIB modules, finally fusing all features through
.
The ESIB module adopts residual adaptive learning mechanisms and convolutional gating linear units, effectively improving the network’s representation capabilities. Its mathematical expression is as follows:
where
are learnable adaptive parameters,
and
are depth-wise separable convolutions,
is the Adaptive State Decomposition Module (ASDM), and
is a feed-forward network based on Convolutional Gating Mixing Unit (CGMU). The computation process of CGMU can be expressed as follows:
where
and
are two parts of input
after projection through
,
represents depth convolution, and
represents element-wise multiplication. This design enables the module to more effectively process vehicle contour and key component detail features, improving model recognition capabilities under different viewing angles and partial occlusion conditions.
Gating mechanism was chosen over traditional activation functions like ReLU or SE-blocks for several specific reasons relevant to special vehicle detection. Unlike ReLU, which applies element-wise thresholding, gating enables selective information flow based on learned importance weights, which is crucial for distinguishing between vehicle components and background clutter. Compared to SE blocks that focus on channel-wise attention, our convolutional gating mechanism preserves spatial relationships essential for geometric structure recognition in armored vehicles. The multiplicative gating operation () allows fine-grained control over feature activation based on local context, enabling the model to adaptively emphasize vehicle contours, turret boundaries, and other distinctive geometric features while suppressing irrelevant background information.
The ASDM is key for the network to capture long-range dependency relationships, with its structure shown in
Figure 4. It first decomposes input features into state parameters through projection:
Then, the computation process for state interaction and feature enhancement is as follows:
where
is a learnable initial state parameter,
and
are projection transformations, and
is an activation function. This module effectively captures spatial relationships and structural features between various components of armored vehicles through selective state decomposition and hybrid state interaction.
Based on the CECG feature extraction module, the CSFNet backbone network has achieved significant success in recognition tasks for special vehicles and their key components. Compared to traditional backbone networks, CSFNet demonstrates stronger feature expression capabilities and environmental adaptability, accurately recognizing large armored vehicles and their functional components under challenging conditions such as complex backgrounds, lighting variations, and partial occlusion. This network optimizes the balance between computational efficiency and accuracy, ensuring both real-time performance and detection quality.
3.2. Hypergraph-Enhanced Spatial Feature Modulation (HyperSFM)
Traditional feature fusion networks like CCFM (Conventional Cross-Feature Fusion Mechanism) face issues of limited feature expression capabilities, insufficient semantic information transmission, and poor scale variation adaptability when processing multi-scale special vehicle images. Traditional fusion methods struggle to establish effective correlations between different scale features, leading to low detection accuracy for small components, difficulty distinguishing similar structures, and high false detection rates under complex backgrounds. Addressing these challenges, we propose the Hypergraph-enhanced Spatial Feature Modulation (HyperSFM) feature fusion network, with its structure shown in
Figure 5. This network achieves high-order correlation modeling and adaptive feature fusion between features through hypergraph structures and multi-scale feature modulation mechanisms, significantly improving system performance in applications such as traffic monitoring, industrial equipment monitoring, and rescue vehicle identification, particularly the detection capability for vehicle observation systems and other fine components.
HyperSFM combines hypergraph theory with feature modulation mechanisms. It collects hierarchical features through the semantic collecting module; then, it employs Hypergraph Relational Aggregator (HRA) to establish high-order dependency relationships between feature points, surpassing the limitation of traditional graph structures where edges can only connect two nodes; finally, it designs Spatial Feature Modulation (SFM) to achieve adaptive feature fusion.
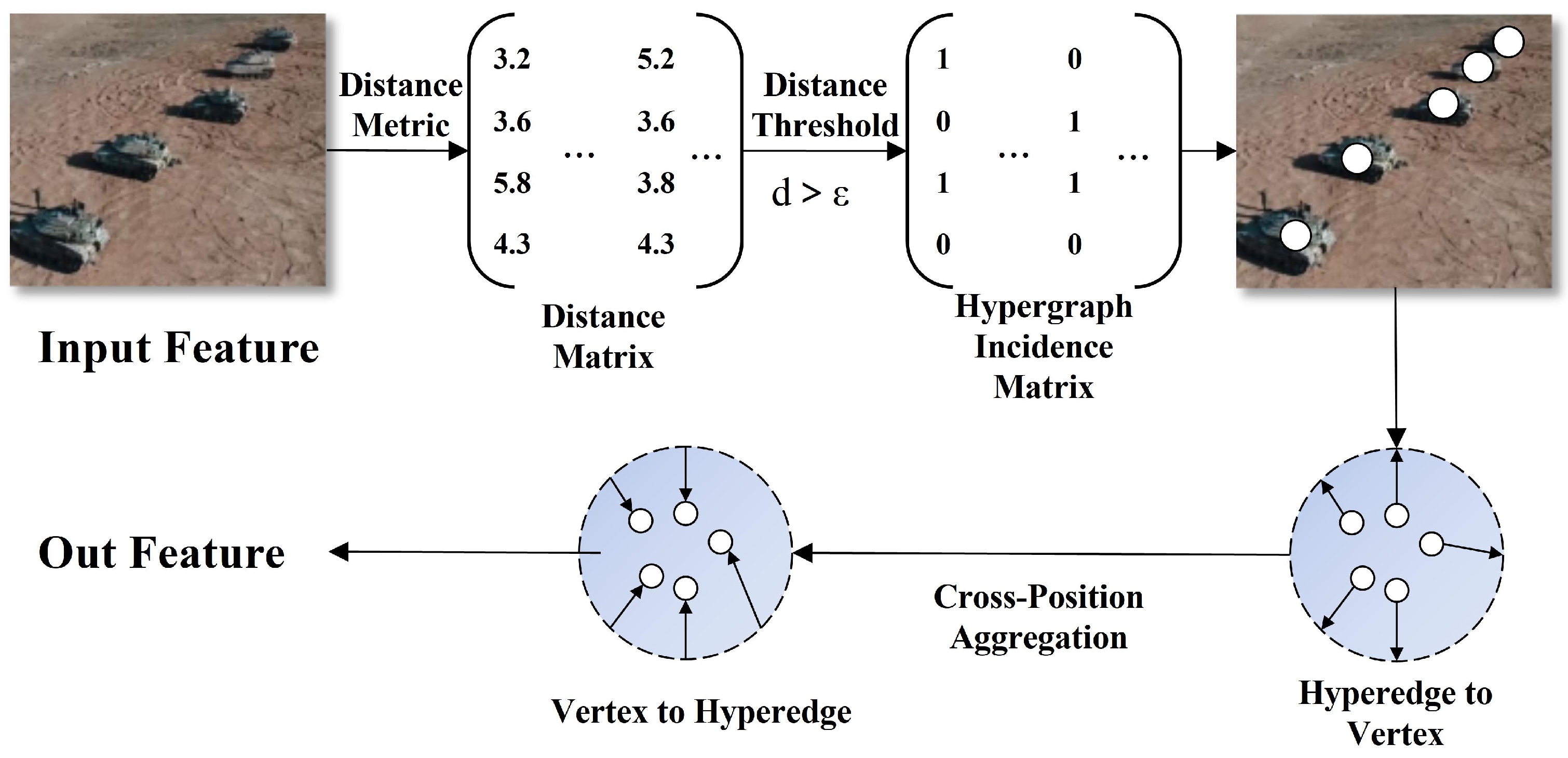
HRA primarily establishes high-order correlations between feature points through hypergraph convolution operations, with its structure shown in
Figure 5. Our hypergraph construction differs from existing semantic-based approaches by utilizing geometric neighborhood criteria. We define hyperedges based on spatial proximity and geometric relationships between feature points, which is particularly beneficial for capturing the rigid geometric structures and spatial arrangements of special vehicle components such as turrets.
Our hypergraph topology was dynamically constructed based on geometric neighborhood relationships rather than being fixed or purely learned. Specifically, hyperedges were defined by grouping 3–8 feature nodes within a local spatial window of size 7 × 7. The connectivity criterion was based on spatial distance threshold τ combined with feature similarity. For each potential hyperedge, we computed the geometric centroid of candidate nodes and included nodes that satisfy both spatial proximity and feature similarity. The threshold τ was empirically set to 4 based on validation experiments. Each hyperedge typically connects 4–6 nodes representing spatially coherent feature regions, enabling the capture of local geometric patterns while maintaining computational efficiency.
Its workflow first constructed feature hypergraphs and then performed bidirectional message passing and updates based on the hypergraph. The overall mathematical expression is as follows:
where
represents the reshaped feature matrix,
represents the hypergraph adjacency tensor constructed based on threshold
,
represents hypergraph convolution operations,
is batch normalization, and
is an activation function. The mathematical expression for hypergraph convolution
is as follows:
where
is a learnable linear transformation,
and
represent message aggregation operations from nodes to hyperedges and from hyperedges to nodes, respectively. This module can capture complex spatial relationships between key structural components of special vehicles through hyperedge connections of multiple nodes, providing powerful high-order feature representations for subsequent precise positioning and component recognition, effectively addressing challenges such as partial occlusion and complex backgrounds.
Modeling higher-order relationships through hypergraph structures enables generalization across diverse scene types by capturing complex spatial interdependencies that extend beyond pairwise relationships. In urban environments, hyperedges can simultaneously connect road surfaces, building facades, and vehicle positions to understand contextual relationships. For rural or battlefield scenarios, the same hypergraph mechanism captures relationships between terrain features, vegetation patterns, and vehicle camouflage effectiveness. This approach generalizes across different lighting conditions by modeling illumination-invariant geometric relationships rather than relying solely on appearance features.
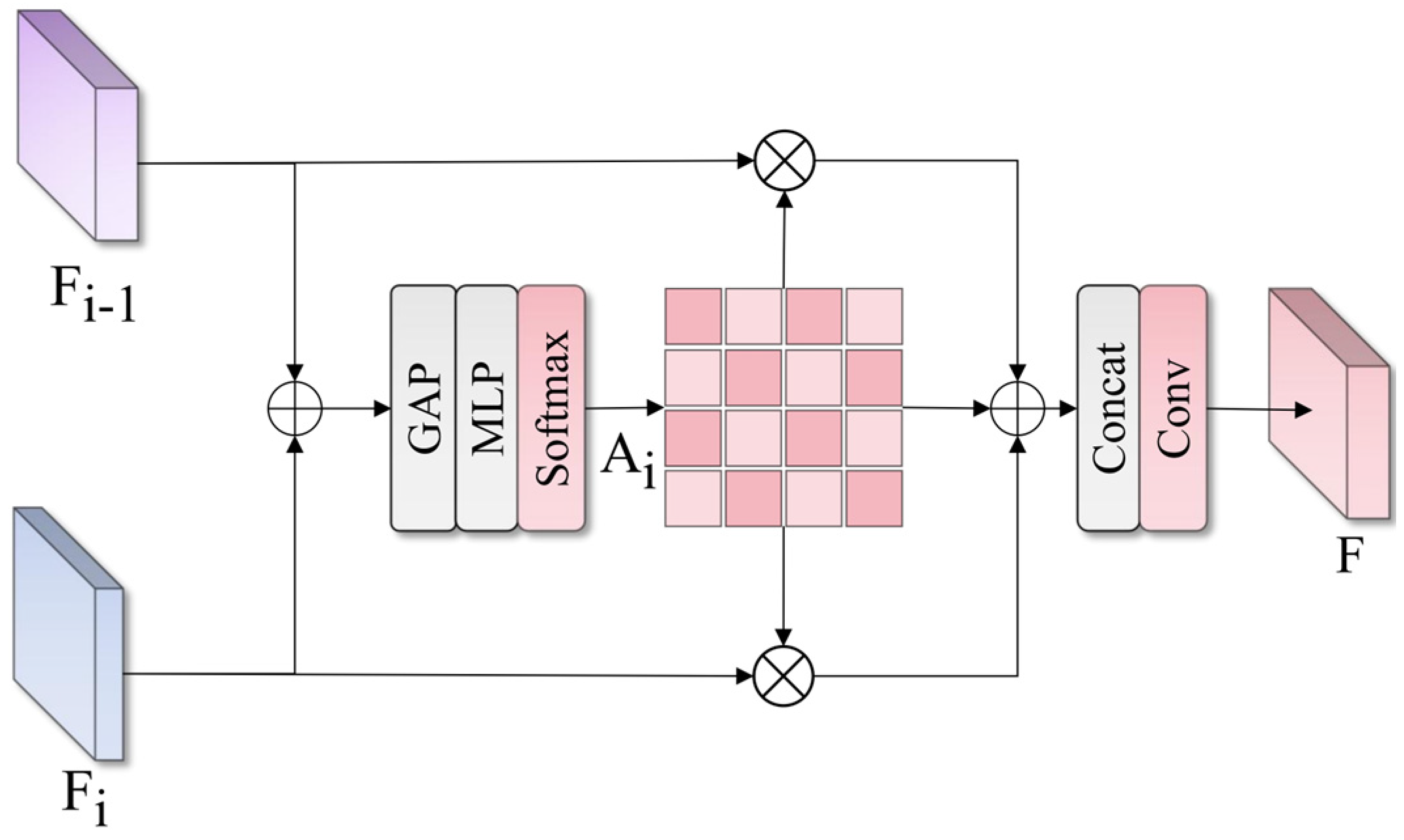
The SFM module’s structure is shown in
Figure 6. Its working principle is to adaptively adjust the contribution weights of each scale feature based on feature importance, with the overall mathematical expression as follows:
where
represents the i-th input feature (after scale alignment),
represents the corresponding attention weight,
is the number of input features, and
represents element-wise multiplication. The computation process for attention weights is as follows:
where
represents global average pooling operation,
and
are MLP layer weights, and
is a nonlinear activation function. SFM achieves more refined and adaptive feature fusion by learning the importance of different scale features, dynamically adjusting weights of each scale feature based on specific content of input images, effectively improving system detection accuracy for different sizes and states of special vehicle components, enabling the model to achieve high-performance recognition in complex monitoring and detection scenarios.
The HyperSFM feature fusion network successfully addresses multi-scale feature fusion challenges in special vehicle and key component detection through hierarchical perception, hypergraph modeling, and adaptive fusion design concepts. Compared to traditional methods, this network achieves richer feature correlation modeling through hypergraph structures, effectively capturing complex dependency relationships between various vehicle components. The overall network architecture optimization design enables the system to maintain high accuracy while preserving computational efficiency.
3.3. Dual-Domain Feature Encoder (DDFE)
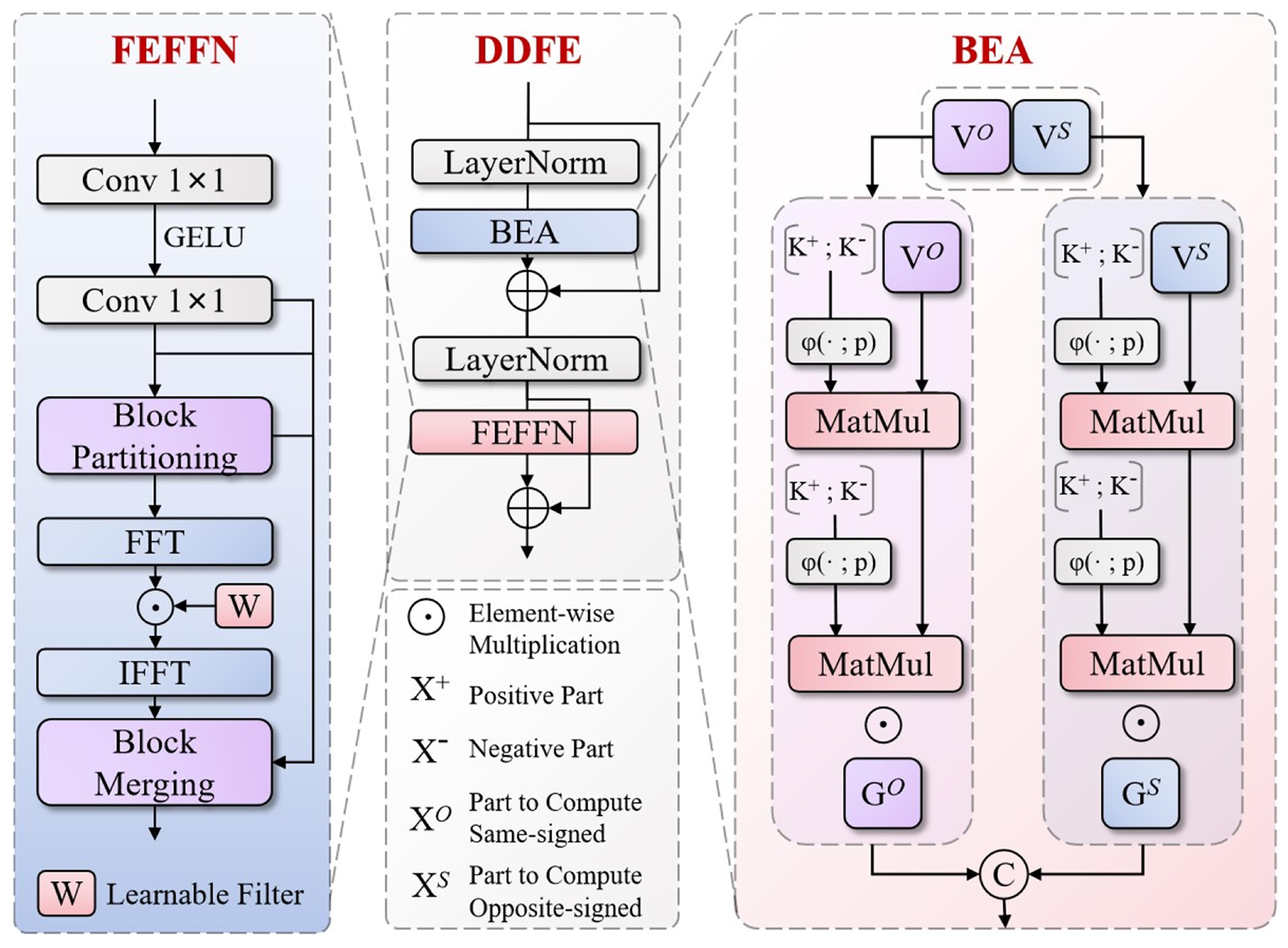
Traditional AIFI (Attention-based Intra-Feature Interaction) encoders face numerous limitations when processing special vehicle image features, mainly manifested as unbalanced attention allocation for targets under complex backgrounds, limited long-range dependency modeling capabilities, and insufficient frequency-domain information processing, leading to inadequate accuracy and robustness when recognizing special vehicles and their key components (such as observation chambers, communication equipment, etc.). Addressing these challenges, we propose the Dual-Domain Feature Encoder (DDFE), with its structure shown in
Figure 7. This encoder combines Bipolar Efficient Attention (BEA) and Frequency-Enhanced Feed-Forward Network (FEFFN), significantly enhancing the system’s recognition capabilities for special vehicles under various environmental conditions.
The DDFE adopts a dual-stage design approach, achieving comprehensive extraction and refined modulation of feature information. Its overall workflow can be summarized through the following mathematical expression:
where
represents input features,
represents bipolar linear attention operations,
represents frequency-domain modulation feed-forward networks,
and
represent dropout operations, and
and
represent layer normalization. The encoder first achieved adaptive weight allocation for features through BEA, focusing on feature representation and structural relationships of large armored vehicles; then, it modulated and enhanced features in the frequency domain through FEFFN, capturing more detail information; finally, it maintained information flow stability through residual connections and normalization.
BEA achieves efficient computation and precise feature extraction through innovative bipolar representation and linear attention mechanisms. Its attention computation process can be expressed through the following key formulas:
where
and
represent query and key matrices, respectively,
is a learnable scale parameter,
is a learnable polarity power parameter,
represents ReLU activation function, and
represents feature concatenation operation. Through this positive–negative polarity decomposition, the network can simultaneously capture complementary representations of features, enhancing expression capabilities for vehicle details. BEA’s computation adopts an efficient linear form:
where
and
represent similar and opposite polarity query representations, respectively,
and
are two sub-parts of the value matrix,
represents the average representation of keys,
is the number of keys, and
is a stability factor. The final attention output was modulated through gating mechanisms and position enhancement:
where
is the gating factor,
represents element-wise multiplication, and
represents depth-wise separable convolution operations.
Frequency-Enhanced Feed-Forward Network (FEFFN) achieves effective extraction of special vehicle detail features through selective enhancement of features in the frequency domain space. The overall mathematical expression of FEFFN is as follows:
where
and
represent weights of two convolutional layers, respectively,
represents nonlinear activation function, and
represents frequency-domain modulation operations. The core mathematical expression of the frequency-domain modulation module Window Frequency Modulation is
where
represents window rearrangement operations, reorganizing features into local windows;
and
represent two-dimensional fast Fourier transform and its inverse transform, respectively;
is a learnable complex weight parameter; and
represents complex multiplication. Through selective modulation of features in the frequency domain, FEFFN can enhance texture, edge, and structural detail features of special vehicles while suppressing background noise and interference, making the network more robust to environmental variations.
The DDFE, through innovative design of bipolar linear attention and frequency-domain modulation, demonstrates significant advantages compared to traditional AIFI encoders. The bipolar linear attention mechanism achieves more precise feature weight allocation, significantly improving positioning accuracy for vehicle key components; frequency-domain modulation technology enhances the model’s capability to capture feature details, enabling the system to better recognize vehicle observation chambers, communication equipment, and other key components; the high-efficiency computational characteristics of linear attention significantly reduce computational complexity, enabling the model to maintain high accuracy while possessing stronger real-time performance; finally, the overall design of the encoder improves adaptability to complex environmental factors, enabling the system to maintain stable performance under various lighting conditions, partial occlusion, and complex backgrounds.
3.4. Spatial-Channel Fusion Upsampling Block (SCFUB)
Traditional convolutional downsampling and nearest neighbor interpolation upsampling face obvious limitations when processing multi-scale features of special vehicles, mainly manifested as the following: severe feature accuracy loss during upsampling, limited detail recovery capabilities, insufficient information interaction between different channels, and difficulty maintaining feature spatial consistency. These deficiencies are particularly prominent when recognizing observation chambers, sensor devices, and other key components of large armored vehicles, leading to blurred boundaries, missing small targets, and inaccurate fine structure recognition. Addressing these challenges, we propose the Spatial-Channel Fusion Upsampling Block (SCFUB), with its structure shown in
Figure 8. This module significantly enhances feature fidelity and spatial consistency during upsampling while maintaining computational efficiency through combining depth-wise separable convolution with channel shift mixing techniques, effectively addressing fine recognition issues of special vehicles in complex environments.
The SCFUB upsampling module achieves efficient and refined feature upsampling through a three-stage workflow of “scale expansion—channel reorganization—feature mixing”. Its overall mathematical expression can be formalized as follows:
where
and
represent input and output feature maps, respectively,
represents scale expansion operations,
represents depth convolution operations,
represents depth convolution kernels,
represents channel reorganization function,
represents Cross-Spatial Channel Mixer (CSCM),
represents pointwise convolution, and
represents the number of groups. The workflow first achieved feature map scale expansion through nearest neighbor interpolation and then used depth-wise separable convolution for feature enhancement, during which channel reorganization and shift mixing operations were employed to enhance cross-channel interaction.
CSCM achieves feature enhancement and mixing through efficient channel segmentation and spatial shift operations. Its mathematical expression can be succinctly represented as follows:
where
represents features equally divided along the channel dimension,
,
,
, and
represent positive and negative direction circular shift operations in height and width dimensions, respectively,
represents shift size, and
represents channel concatenation. This operation first divided the feature map into four sub-blocks along the channel dimension and then applied circular shifts in different directions to different spatial dimensions for these sub-blocks, finally recombining them to form mixed features. This design enables different channels to perceive different spatial position information, effectively enhancing feature expression capabilities and spatial perception while maintaining extremely low computational overhead.
5. Conclusions
This paper addresses key challenges in special vehicle detection under complex environments, including insufficient feature extraction, inadequate multi-scale fusion, unbalanced attention allocation, and upsampling information loss, and it proposes the HSF-DETR detection framework. Through the collaborative design of four innovative modules, the framework achieves the high-precision detection of special vehicles and their key components: CSFNet backbone network enhances long-range dependency modeling capabilities through CECG modules; HyperSFM feature fusion network utilizes hypergraph structures to achieve high-order feature correlation modeling; DDFE improves feature expression capabilities through bipolar attention and frequency-domain modulation; SCFUB upsampling module effectively maintains feature fidelity.
Experimental results demonstrate that HSF-DETR achieved significant performance improvements in special vehicle detection tasks, with mAP50 and mAP50-95 reaching 96.6% and 70.6%, respectively, improving by 3.1% and 4.6% compared to baseline methods. In terms of computational efficiency, this method requires only 59.7 GFLOPs and 18.07 M parameters, achieving a good balance between accuracy and efficiency. Generalization experiments demonstrate the method’s adaptability and robustness in different application scenarios.
Future work will focus on the following directions: (1) further optimizing model structure to improve real-time performance; (2) expanding dataset scale and scene diversity; (3) exploring multi-modal fusion technologies to enhance detection capabilities under complex environments; and (4) applying the method to broader military and civilian special vehicle detection scenarios.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}