
Anomaly Detection in Nuclear Power Production Based on Neural Normal Stochastic Process

Abstract
1. Introduction
- Serialization embedding of incomplete samples: We design a framework that transforms incomplete sensor data into ordered sequence matrices and incorporates timestamp information through an independent input stream. This enables the model to extract temporal dependencies even in the presence of missing values.
- Neural Normal Stochastic Process representation: In the latent space, we construct a neural representation of a normal stochastic process that continuously interpolates incomplete series, allowing the decoder to operate seamlessly across missing regions.
- Decoder guided by future information: The decoder receives inputs sampled from the future distribution of the latent process, which implicitly forces the model to reconstruct forward-looking patterns and thus improves the timeliness of anomaly detection.
- The remainder of this paper is organized as follows. Section 2 reviews the related work on anomaly detection for time series with missing data. Section 3 introduces the proposed Neural Normal Stochastic Process (NNSP), detailing its encoder–decoder architecture and how it handles incomplete input. Section 4 presents experimental evaluations conducted on real-world nuclear monitoring datasets, including baseline comparisons, ablation studies, and parameter analysis. Section 5 concludes the study with a summary of contributions and potential directions for future work.
2. Related Work
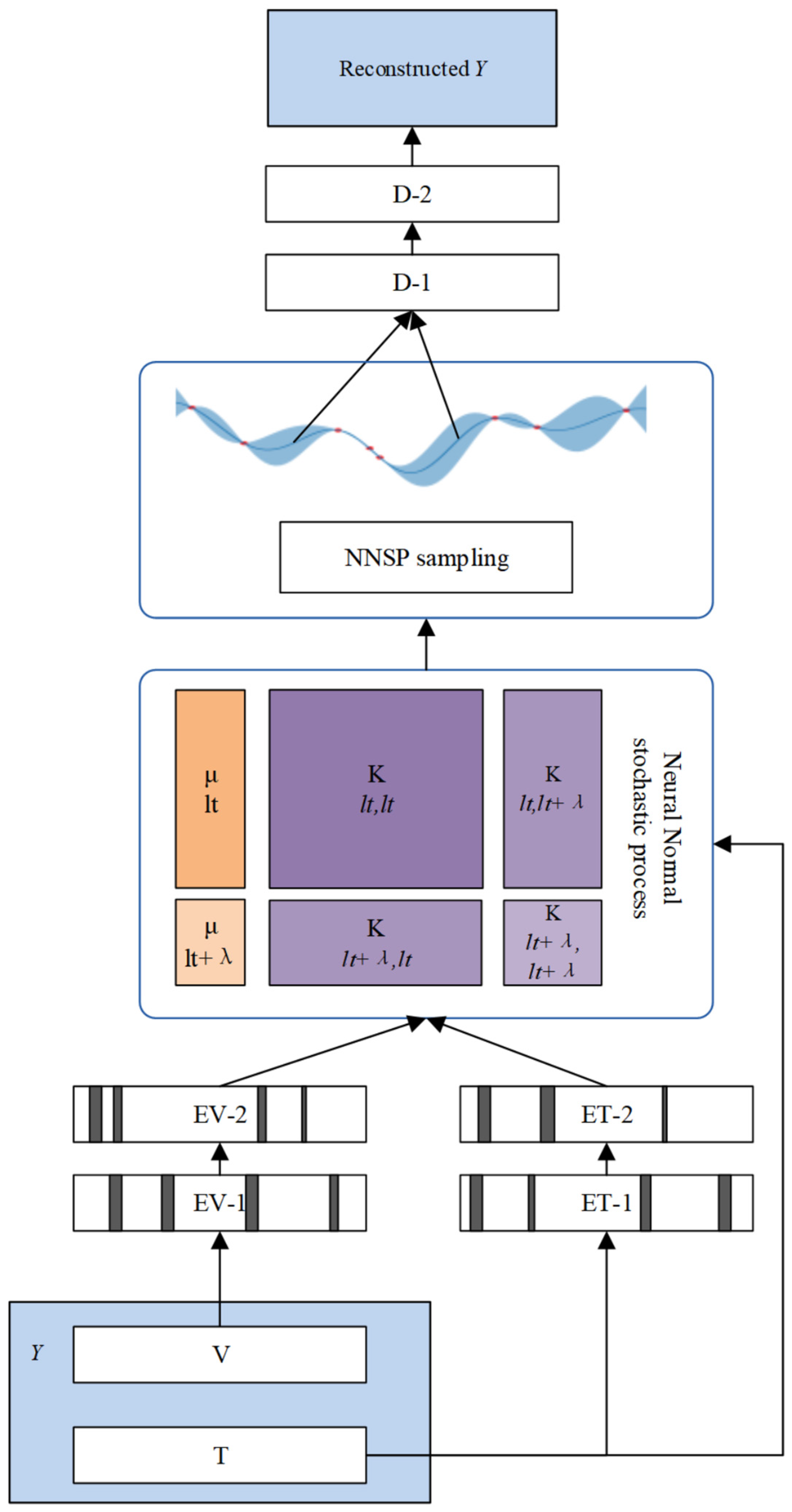
3. Proposed Methods
3.1. Sequentialization of Nuclear Power Monitoring Data
3.2. The Framework of Neural Normal Stochastic Process
3.3. Encoding
3.4. Normal Stochastic Process Sampling
3.5. Anomaly Detection
4. Experiments and Discussion
4.1. Experimental Settings
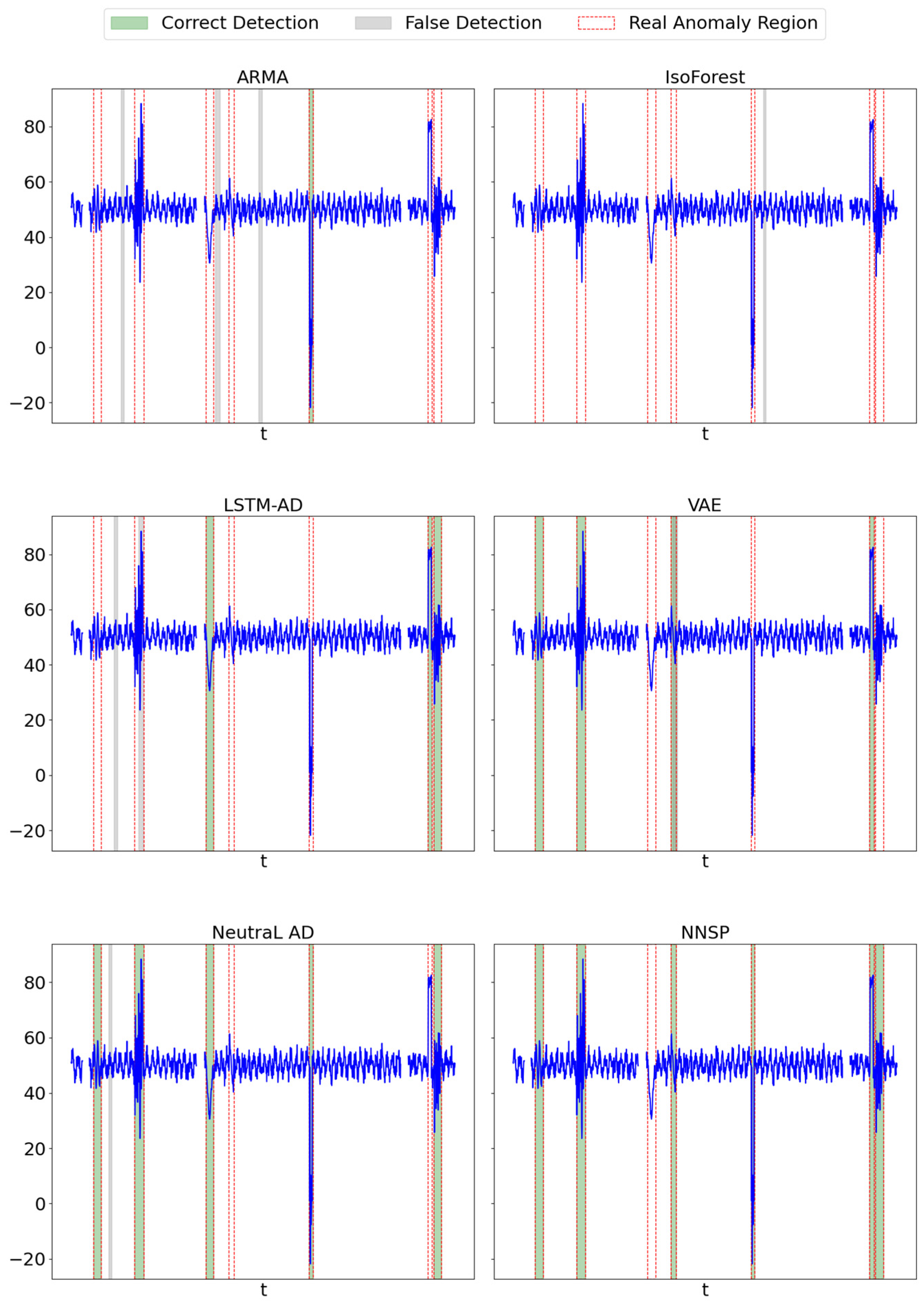
4.2. Result Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, X.; Kim, J.; Warns, K.; Wang, X.; Ramuhalli, P.; Cetiner, S.; Kang, H.G.; Golay, M. Prognostics and health management in nuclear power plants: An updated method-centric review with special focus on data-driven methods. Front. Energy Res. 2021, 9, 696785. [Google Scholar] [CrossRef]
- Gursel, E.; Reddy, B.; Khojandi, A.; Madadi, M.; Coble, J.B.; Agarwal, V.; Boring, R.L. Using artificial intelligence to detect human errors in nuclear power plants: A case in operation and maintenance. Nucl. Eng. Technol. 2023, 55, 603–622. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, Y.; Cai, J.; Fan, J. Deep orthogonal hypersphere compression for anomaly detection. In Proceedings of the 12th International Conference on Learning Representations, Virtual, Austria, 7–11 May 2024; Available online: https://openreview.net/forum?id=cJs4oE4m9Q (accessed on 15 October 2024).
- Fu, D.; Zhang, Z.; Fan, J. Dense projection for anomaly detection. In Proceedings of the 38th AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 8398–8408. [Google Scholar]
- Xiao, F.; Zhou, J.; Han, K.; Hu, H.; Fan, J. Unsupervised anomaly detection using inverse generative adversarial networks. Inf. Sci. 2025, 689, 121435. [Google Scholar] [CrossRef]
- Griffiths, F.; Ooi, M. The fourth industrial revolution-Industry 4.0 and IoT [Trends in Future I&M]. IEEE Instrum. Meas. Mag. 2018, 21, 29–43. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, Y.; Udell, M. Polynomial matrix completion for missing data imputation and transductive learning. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3842–3849. [Google Scholar]
- Muzellec, B.; Josse, J.; Boyer, C.; Cuturi, M. Missing data imputation using optimal transport. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 7130–7140. [Google Scholar]
- Sarda, K.; Yerudkar, A.; Del Vecchio, C. Unsupervised anomaly detection for multivariate incomplete data using gan-based data imputation: A comparative study. In Proceedings of the 2023 31st Mediterranean Conference on Control and Automation, Limassol, Cyprus, 26–29 June 2023; pp. 55–60. [Google Scholar] [CrossRef]
- Lin, S.; Clark, R.; Birke, R. Anomaly detection for time series using vae-lstm hybrid model. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 4322–4326. [Google Scholar]
- Dubey, A.K.; Kumar, A.; García-Díaz, V.; Sharma, A.K.; Kanhaiya, K. Study and analysis of SARIMA and LSTM in forecasting time series data. Sustain. Energy Technol. Assess. 2021, 47, 101474. [Google Scholar] [CrossRef]
- Yoo, Y.-H.; Kim, U.-H.; Kim, J.-H. Recurrent reconstructive network for sequential anomaly detection. IEEE Trans. Cybern. 2019, 51, 1704–1715. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; You, Z.; Zhang, N. UTRAD: Anomaly detection and localization with U-transformer. Neural Netw. 2022, 147, 53–62. [Google Scholar] [CrossRef] [PubMed]
- Du, J.; Hu, M.; Zhang, W. Missing data problem in the monitoring system: A review. IEEE Sens. J. 2020, 20, 13984–13998. [Google Scholar] [CrossRef]
- Liu, F.; Li, H.; Yang, Z. Estimation method based on deep neural network for consecutively missing sensor data. Radioelectron. Commun. Syst. 2018, 61, 258–266. [Google Scholar] [CrossRef]
- Donders, A.R.T.; Van Der Heijden, G.J.M.G.; Stijnen, T.; Moons, K.G.M. A gentle introduction to imputation of missing values. J. Clin. Epidemiol. 2006, 59, 1087–1091. [Google Scholar] [CrossRef] [PubMed]
- Shahbazi, H.; Karimi, S.; Hosseini, V. A novel regression imputation framework for Tehran air pollution monitoring network using outputs from WRF and CAMx models. Atmos. Environ. 2018, 187, 24–33. [Google Scholar] [CrossRef]
- Zhang, S. Nearest neighbor selection for iteratively kNN imputation. J. Syst. Softw. 2012, 85, 2541–2552. [Google Scholar] [CrossRef]
- Park, D.; Hoshi, Y.; Kemp, C.C. A multimodal anomaly detector for robot-assisted feeding using an LSTM-based variational autoencoder. IEEE Robot. Autom. Lett. 2018, 3, 1544–1551. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Han, J. Multivariate time series anomaly detection and interpretation using hierarchical inter-metric and temporal embedding. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 3220–3230. [Google Scholar] [CrossRef]
- Su, Y.; Zhao, Y.; Niu, C. Robust anomaly detection for multivariate time series through stochastic recurrent neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2828–2837. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Pincombe, B. Anomaly detection in time series of graphs using ARMA processes. Asor Bull. 2005, 24, 2. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long short term memory networks for anomaly detection in time series. In Proceedings of the 23rd European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, 22–24 April 2015; p. 89. [Google Scholar]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Qiu, C.; Pfrommer, T.; Kloft, M.; Mandt, S.; Rudolph, M. Neural transformation learning for deep anomaly detection beyond images. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8703–8714. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Strategy | PGS | PTS | PDS | TSS | EAL |
|---|---|---|---|---|---|
| Missing Rate | 13.21% | 11.17% | 10.72% | 9.66% | 14.28% |
| Anomaly Rate | 9.77% | 14.02% | 6.51% | 12.41% | 12.73% |
| Length | 1695.25 K | 712.33 K | 37,286.04 K | 1442.93 K | 26,782.61 K |
| Frequency | 1/30 s | 1/60 s | 1/s | 1/30 s | 1/1 s |
| Dataset | PGS | PTS | PDS | TSS | EAL | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 |
| ARMA | 58.42 | 54.13 | 56.19 | 64.29 | 57.80 | 60.87 | 60.64 | 50.44 | 55.07 | 55.75 | 53.39 | 54.55 | 62.94 | 52.10 | 57.12 |
| IsoForest | 65.49 | 67.89 | 66.67 | 67.50 | 74.31 | 70.74 | 66.36 | 62.83 | 64.55 | 66.06 | 61.02 | 63.44 | 57.26 | 64.11 | 60.51 |
| LSTM-AD | 73.12 | 62.39 | 67.33 | 75.45 | 76.15 | 75.80 | 73.87 | 72.57 | 73.21 | 71.43 | 67.80 | 69.47 | 68.32 | 63.59 | 65.90 |
| VAE | 77.32 | 68.81 | 72.82 | 75.26 | 66.97 | 70.87 | 69.37 | 68.14 | 68.75 | 71.68 | 68.64 | 70.13 | 70.74 | 65.16 | 67.86 |
| NeutraL AD | 84.16 | 77.98 | 80.95 | 79.21 | 73.39 | 76.19 | 78.07 | 78.76 | 78.41 | 82.35 | 71.19 | 76.36 | 80.53 | 74.27 | 77.27 |
| NNSP | 84.91 | 82.57 | 83.72 | 83.33 | 81.67 | 82.49 | 84.26 | 80.53 | 82.35 | 85.19 | 77.97 | 81.42 | 83.70 | 79.94 | 81.78 |
| Strategy | PGS | PTS | PDS | TSS | EAL |
|---|---|---|---|---|---|
| SIS− HGP− GPS− | 57.29 | 56.21 | 59.43 | 56.31 | 57.52 |
| SIS+ HGP− GPS− | 65.72 | 64.32 | 67.11 | 65.49 | 66.09 |
| SIS+ HGP+ GPS− | 69.23 | 68.97 | 67.87 | 66.15 | 67.49 |
| SIS− HGP+ GPS− | 65.85 | 62.71 | 63.34 | 65.92 | 62.24 |
| SIS− HGP+ GPS+ | 77.97 | 76.47 | 69.83 | 70.20 | 73.76 |
| SIS− HGP− GS+ | 72.82 | 70.87 | 68.75 | 70.13 | 68.18 |
| SIS+ HGP− GS+ | 75.90 | 74.14 | 71.28 | 69.81 | 71.55 |
| SIS+ HGP+ GPS+ | 83.72 | 82.49 | 82.35 | 81.42 | 81.78 |
| Hyperparameters | F1 | |||
|---|---|---|---|---|
| λ = 0.1 | λ = 1 | λ = 10 | λ = 50 | |
| l = 1.0, σ = 1.0 | 84.29 | 82.61 | 80.28 | 76.73 |
| l = 1.0, σ = 2.0 | 81.67 | 79.72 | 77.42 | 74.13 |
| l = 0.5, σ = 1.0 | 79.96 | 78.38 | 75.02 | 73.29 |
| l = 1.2, σ = 0.8 | 83.20 | 82.05 | 79.74 | 76.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Liu, S.; He, S.; Xu, K.; Lan, Y.; Fang, H. Anomaly Detection in Nuclear Power Production Based on Neural Normal Stochastic Process. Sensors 2025, 25, 4358. https://doi.org/10.3390/s25144358
Liu L, Liu S, He S, Xu K, Lan Y, Fang H. Anomaly Detection in Nuclear Power Production Based on Neural Normal Stochastic Process. Sensors. 2025; 25(14):4358. https://doi.org/10.3390/s25144358
Chicago/Turabian StyleLiu, Linyu, Shiqiao Liu, Shuan He, Kui Xu, Yang Lan, and Huajian Fang. 2025. "Anomaly Detection in Nuclear Power Production Based on Neural Normal Stochastic Process" Sensors 25, no. 14: 4358. https://doi.org/10.3390/s25144358
APA StyleLiu, L., Liu, S., He, S., Xu, K., Lan, Y., & Fang, H. (2025). Anomaly Detection in Nuclear Power Production Based on Neural Normal Stochastic Process. Sensors, 25(14), 4358. https://doi.org/10.3390/s25144358