1. Introduction
Research on robotic manipulators was advanced steadily with the development of automation and intelligent systems [
1,
2,
3,
4]. With the advancement of research, numerous control methods for robotic manipulator system were proposed [
5,
6,
7,
8]. These methods have enabled robotic manipulators to achieve reliable task execution in complex and uncertain environments.
So far, the zeroing neural network (ZNN) has been regarded as an algorithm characterized by convergence properties [
9,
10,
11]. The ZNN was able to avoid the errors commonly encountered in conventional gradient neural networks and has gained attention over the past two decades. Moreover, the ZNN was recently applied to various control tasks aimed at eliminating uncertainties [
12,
13,
14]. By designing a nonlinear activation function and introducing an integral term, a noise-tolerant ZNN with finite-time convergence was proposed for trajectory tracking [
14]. Simulation results confirmed that this noise-tolerant ZNN achieved stable solutions within finite time under uncertainties. Additionally, a novel ZNN, referred to as ST-ZNN, was developed by incorporating the super-twisting (ST) algorithm to handle external disturbances while ensuring finite-time convergence [
15]. The ST-ZNN demonstrated improvements in finite-time trajectory-tracking accuracy and disturbance rejection capabilities for parallel robotic manipulator systems. Furthermore, two robust finite-time ZNN (RFTZNN) variants based on stationary and non-stationary parameters with sign-bi-power activation functions were designed to eliminate uncertainties [
16]. Thus, the core of the ZNN was to construct an error function that asymptotically approached zero.
The robotic manipulators were widely employed to perform repetitive tasks [
17,
18]. The iterative learning control (ILC) was aimed at enhancing the performance of a controlled system by leveraging information from previous executions, which enabled the system to improve progressively with each iteration [
19,
20]. For tracking control of robotic manipulators, a novel proportional-derivative iterative second-order neural network learning control (PDISN) method was proposed [
21]. The tracking errors of joints l and 2 were recorded to be approximately
rad and
rad, respectively. In addition, an ILC approach was developed to jointly learn model parameters based on the interoceptive sensors [
22]. The ILC outperformed the baseline by achieving a threefold reduction in residual vibration. Thus, the ILC was demonstrated to be particularly effective in trajectory tracking for robotic manipulators. Numerous studies on ILC were conducted under the assumption of identical initial conditions. These approaches were typically dependent on the desired state and input, which were not always available beforehand, thereby limiting their practical applicability. Notably, traditional ILC frameworks required the system to start each iteration from the same initial condition. Unlike repetitive control, which reused the terminal condition of the previous cycle as the initial condition of the current one, some ILC algorithms removed the requirement for identical initial conditions. For varying initial states, an ILC framework was proposed to learn from a virtual cycle constructed based on historical data [
23]. Furthermore, the ILC was designed with distributed initial-state learning, which eliminated the need to fix the initial value at the start of each iteration [
24]. Therefore, the limitations imposed by initial conditions were eliminated through the implementation of the ILC algorithm without resetting conditions.
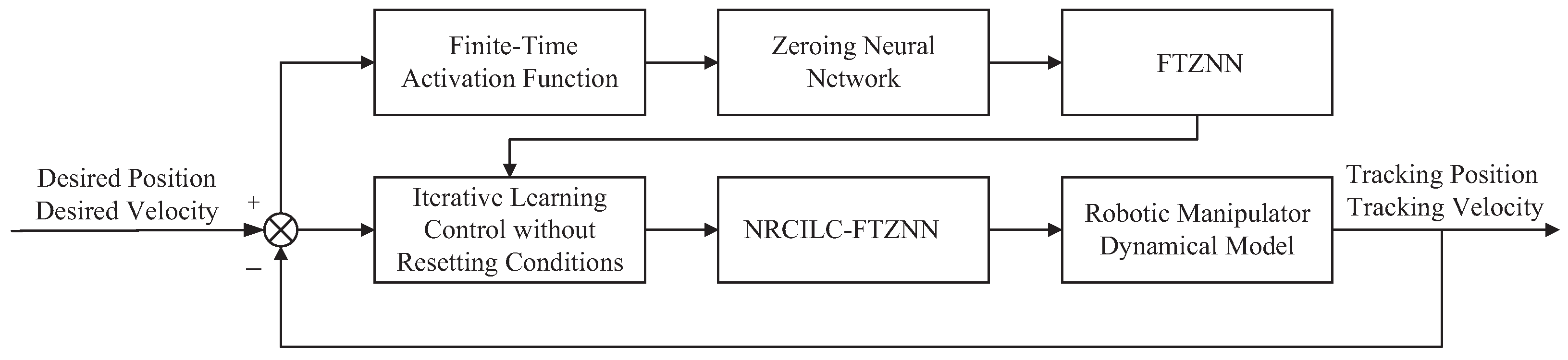
Building upon the considerations outlined above, an innovative finite-time activation function of the zeroing neural network (FTZNN) is developed in this paper. An ILC without resetting conditions based on the FTZNN (NRCILC-FTZNN) is proposed for a robotic manipulator under external disturbances. The proposed NRCILC-FTZNN is introduced as a novel framework that enhances convergence in repetitive tracking tasks. The main contributions of this paper are summarized as follows:
A novel FTZNN is introduced to reduce external disturbances and enhance the convergence of the system.
An ILC without resetting conditions is proposed, which automatically provides the initial state value in each iteration, thereby eliminating the need for reset conditions.
The convergence of the system is theoretically proven. Moreover, trajectory-tracking simulations further confirm that the proposed NRCILC-FTZNN achieves rapid convergence compared to other schemes and reduces external disturbances.
This paper is organized as follows:
Section 2 presents the dynamic model of robotic manipulator.
Section 3 introduces the design of the proposed tracking control strategy. In
Section 4, the convergence of the NRCILC-FTZNN sheme is theoretically analyzed.
Section 5 evaluates the effectiveness of the proposed algorithm through simulation results. Finally,
Section 6 summarizes the achievements and predicts the future work.
2. Dynamical Model
In this paper, the dynamic model of robotic manipulator (
1) is assumed to be known and used as part of the control design framework. The focus of this paper is not on modeling or analyzing the dynamics themselves, but rather on developing the NRCILC-FTZNN.
The robotic manipulator composed of serially connected rigid links is considered. The motion of the
n-links manipulator is described by the following dynamic equation:
where
k is the iteration number;
t is the time;
,
, and
denote link position, velocity, and acceleration vectors, respectively;
,
, and
are the manipulator inertia matrix, centripetal and Coriolis matrix, and gravitational torque, respectively;
is the disturbance torque, for example, it can be measurement noises and friction compensation in control; and
is the torque input vector.
In addition,
,
, and
denote the desired link position, velocity, and acceleration vectors, respectively. To monitor the tracking process, the tracking error
and its time-derivative
are defined as follows:
with
.
The following modeling assumptions are used in the development and analysis of the proposed controller.
Modeling Assumptions 1. For the purpose of controller synthesis and theoretical analysis, the robotic manipulator is modeled as a rigid serial-link mechanism with n degrees of freedom, where joint flexibility, mechanical backlash, and structural compliance are neglected.
Modeling Assumptions 2. The systems are assumed to be fully known, with the manipulator inertia matrix, centripetal and Coriolis matrix, and gravitational torque regarded as smooth and continuously differentiable functions of their arguments.
Modeling Assumptions 3. Frictional effects, sensor noise, and other higher-order uncertainties are not explicitly modeled; instead, they are encompassed within a bounded disturbance term , which accounts for both internal and external unmodeled effects.
Modeling Assumptions 4. It is presumed that accurate measurements of joint positions and velocities are available throughout the control.
Although certain aspects of practical robotic systems are idealized by these assumptions, they are widely adopted in model-based and ILC studies to facilitate analytical tractability while preserving dominant characteristics of system.
The following properties, lemmas, and assumptions are used in the development and analysis of the proposed controller.
Property 1. Thematrices and are bounded and Lipschitz continuous with respect to their arguments, as described below:where , , g, , and are positive constant. Property 2. The is bounded as follows:where c is positive constant. Property 3. The i-th element of is equal to , where is symmetric and continuously differentiable, satisfying the following condition:where . Lemma 1 ([
25]).
The possesses the following property: Lemma 2 ([
27]).
The norm of a function (*) over the is defined as follows: In addition, let
be defined. Then,
Assumption 1. The norms of and are bounded by the positive constants and , respectively.
5. Simulation and Discussion
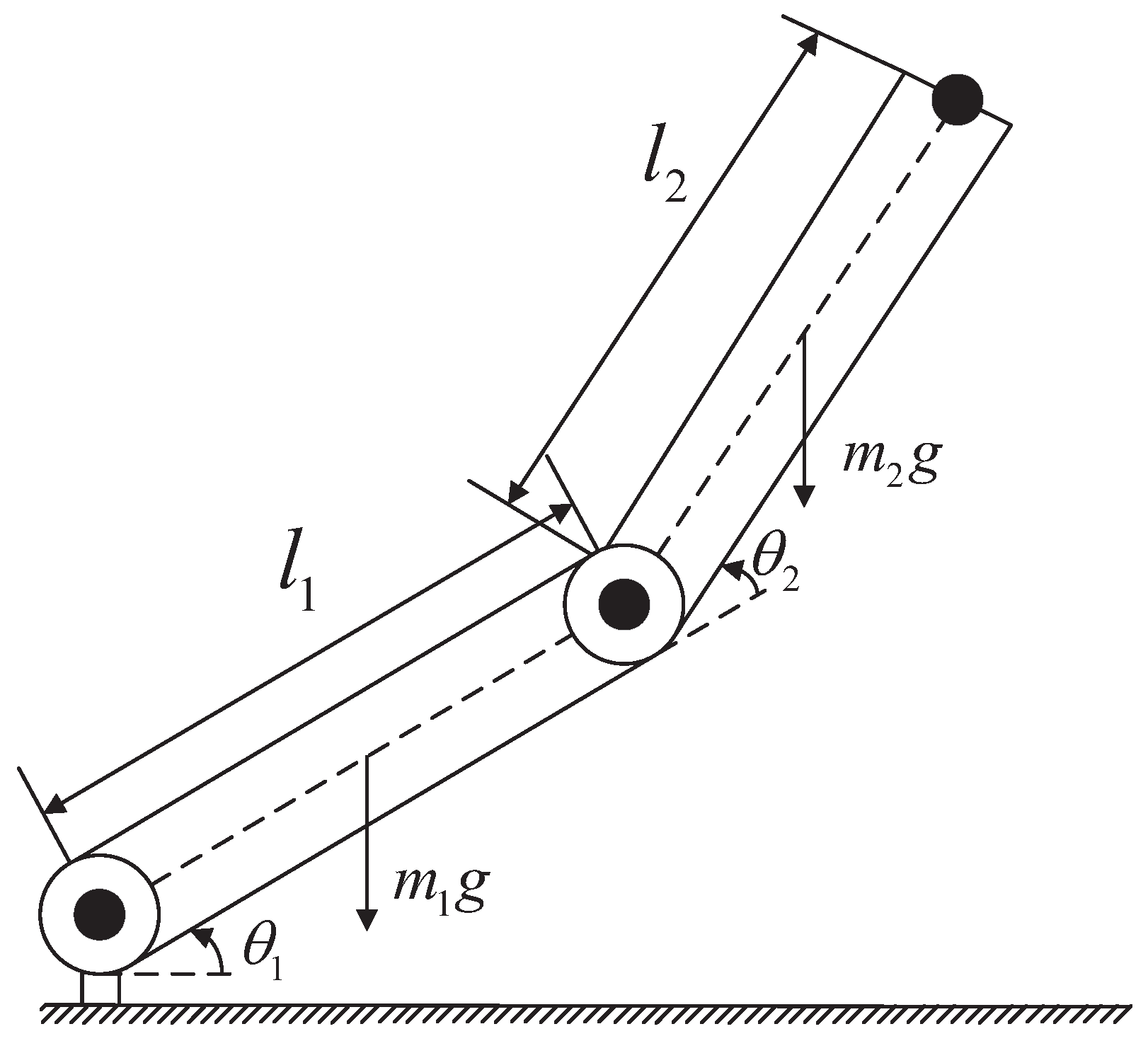
The NRCILC-FTZNN algorithm is implemented in MATLAB. Moreover, three illustrative examples are provided to validate the characteristics and effectiveness of the NRCILC-FTZNN in trajectory tracking. The robotic manipulator is depicted in
Figure 2. Moreover, the manipulator link weight is set to 2 kg and the link length to 0.6 m [
30,
31]. The model (
1) with the elements of
,
, and
are given by the following:
where
and
are masses,
and
are lengths,
and
are the distance between the center of mass of the joint and the corresponding link,
and
are moment of inertia, and
g is gravitational acceleration. The robot parameters are set as
kg,
m,
m,
, and
.
This section focuses on investigating the simulation and effectiveness of the NRCILC-FTZNN applied to robotic manipulator. To establish a rigorous and quantitative evaluation framework, the root mean square error (RMSE), mean absolute error (MAE), and standard deviation (SD) are utilized. These metrics are defined as follows:
where
X is number of data; and
,
, and
are the true value, observation value, and average of observation value, respectively.
5.1. Comparative Simulation with Robust Adaptive Proportional-Derivative Control
This section compares the NRCILC-FTZNN framework with robust adaptive proportional-derivative (RAPD) control. Additionally, the tracking controller of RAPD is defined as follows:
where
,
.
Moreover, the parameter estimation law for
is chosen as follows:
where
,
,
is a positive, definite, and symmetric matrix.
The parameters are set as , , , , , , .
As shown in
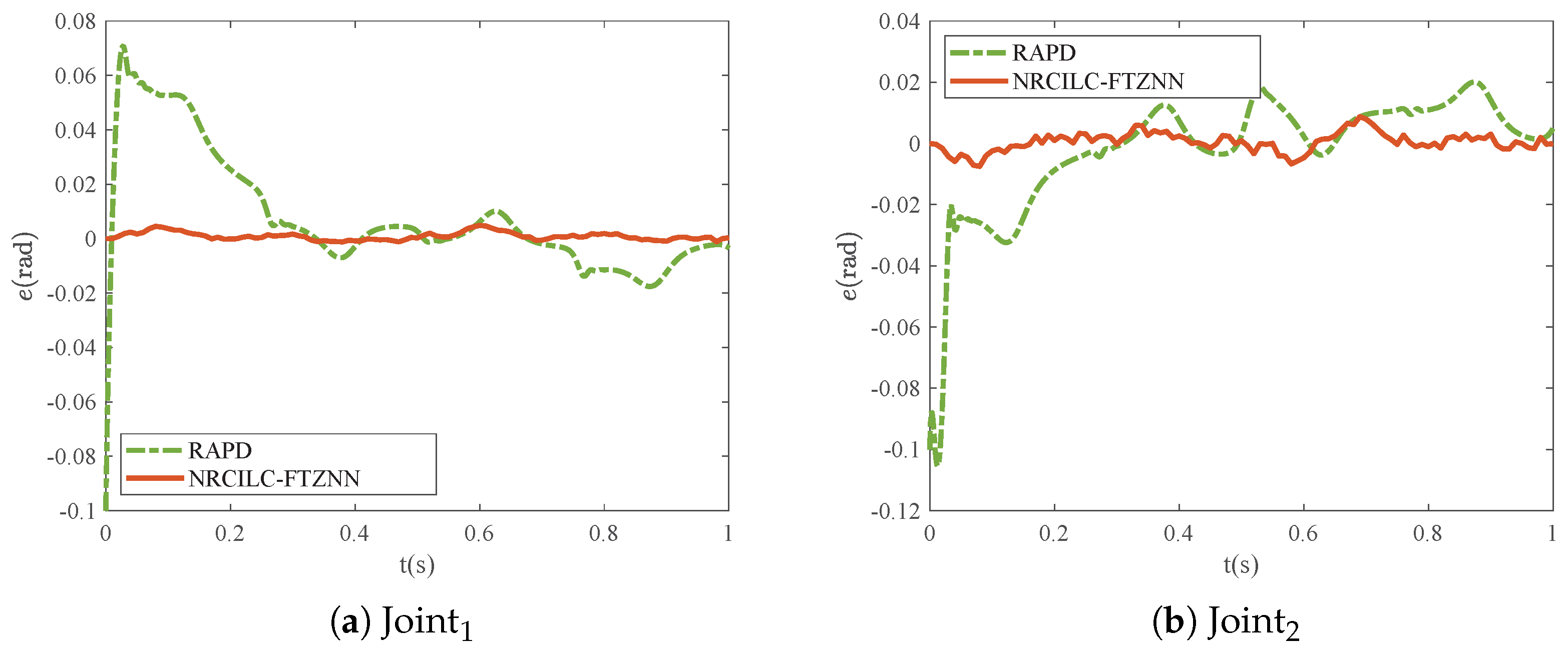
Figure 3, the tracking trajectories generated by the RAPD and NRCILC-FTZNN are illustrated. Both methods exhibit convergence of tracking trajectories to the desired trajectories. Furthermore, the comparison of the tracking errors of the RAPD and NRCILC-FTZNN is shown in
Figure 4. The tracking error of the NRCILC-FTZNN is smaller than those of the RAPD, which indicates superior tracking performance.
The comparisons of the RMSE, MAE, and SD of the RAPD and NRCILC-FTZNN are shown in
Table 1 and
Figure 5. The RMSE values of the NRCILC-FTZNN are 0.0017 and 0.0031, both smaller than those of RAPD. A smaller RMSE indicates that the NRCILC-FTZNN achieves higher tracking accuracy. Additionally, The average trajectory-tracking error of
and
, measured by MAE, is reduced by 82.94% compared to RAPD. The MAE and SD of the NRCILC-FTZNN are smaller than RAPD. The smaller MAE demonstrates that the NRCILC-FTZNN maintains stable tracking performance. The lower SD indicates reduced error fluctuations, further confirming excellent stability.
5.2. System Simulation with Different Schemes
In this section, various activation functions of ZNN are introduced to highlight the advantages of the NRCILC-FTZNN framework, including the linear activation function (NRCILC-LZNN) and power activation function (NRCILC-PZNN). Additionally, the element form of activation functions for the NRCILC-LZNN and NRCILC-PZNN are defined as follows:
Additionally, the relevant parameters are set as , , , and .
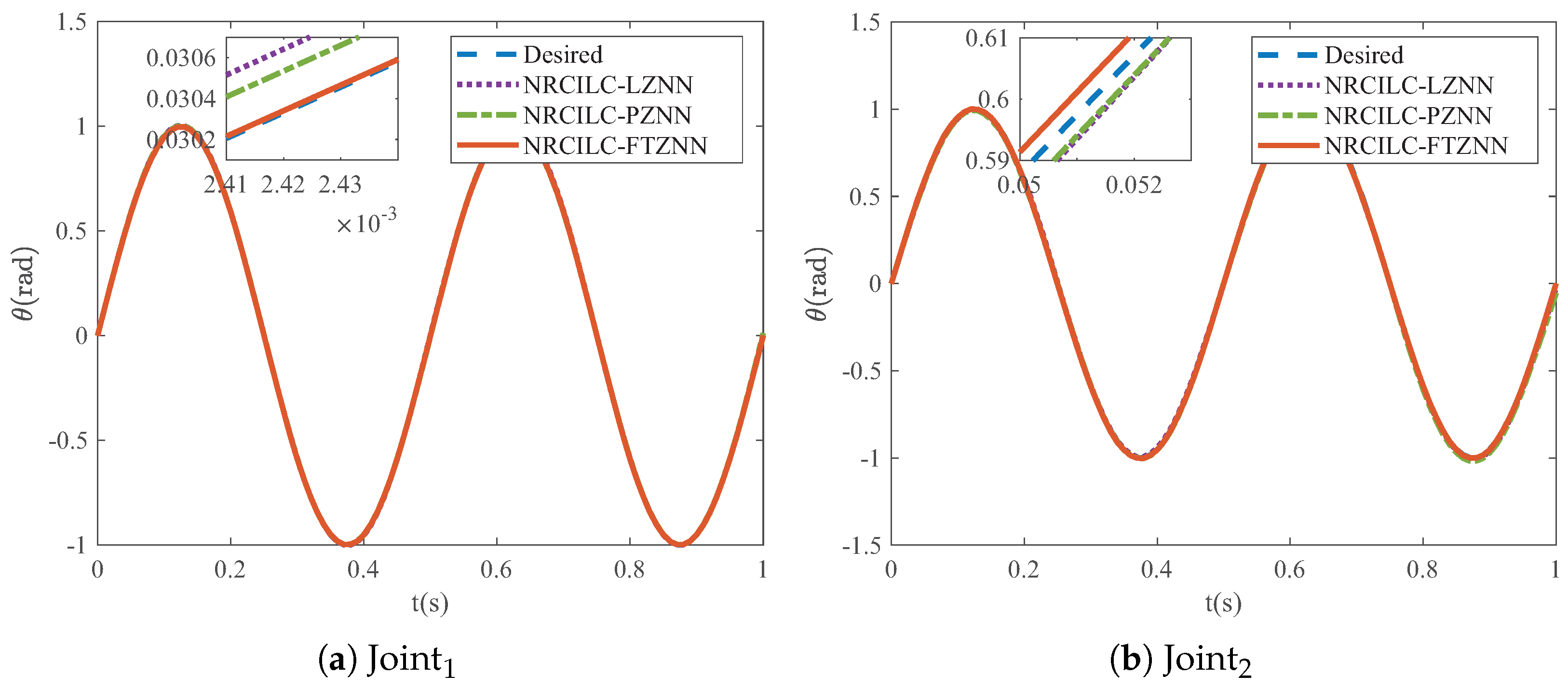
As shown in
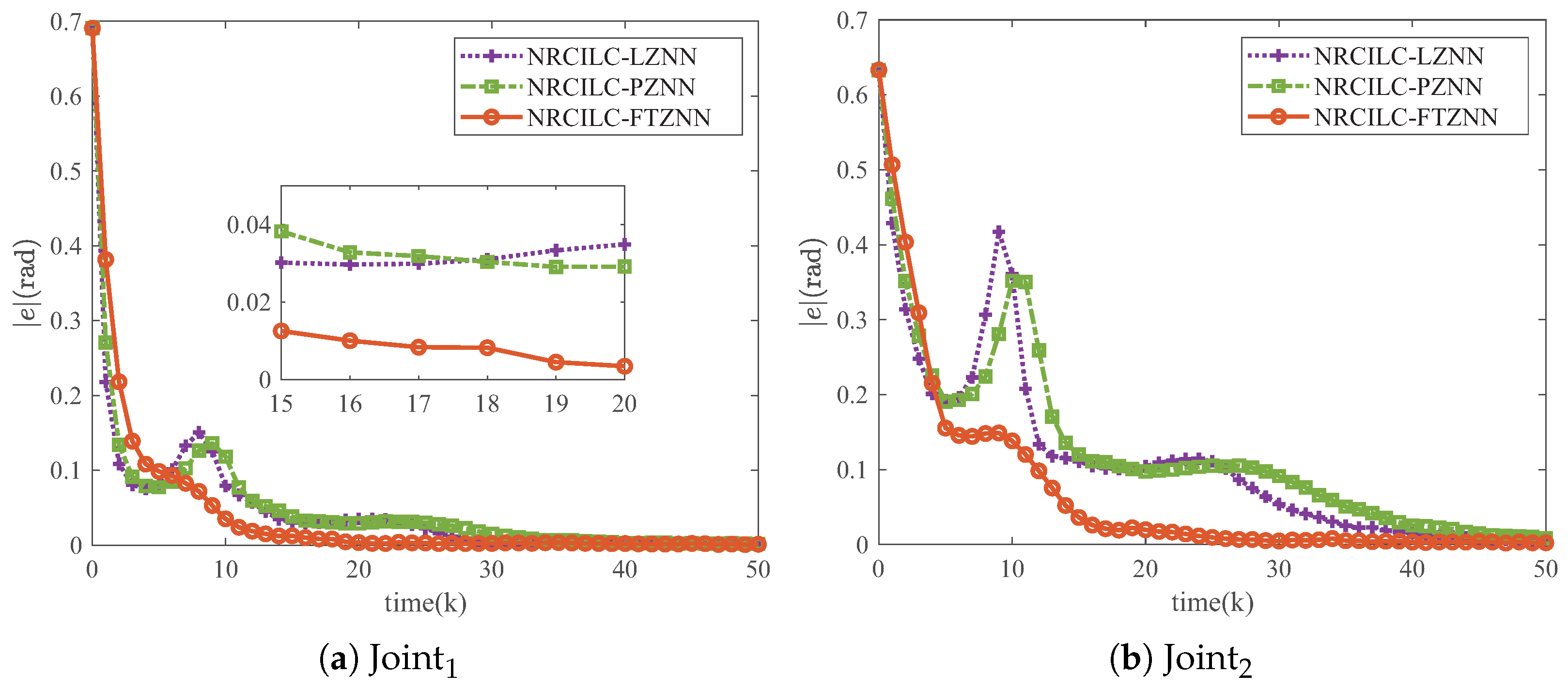
Figure 6, the tracking trajectories generated by the three schemes are illustrated, with the blue dashed lines representing the desired trajectories. It can be observed that the tracking trajectories of the three schemes converge to the desired trajectories. Furthermore,
Figure 7 illustrates the mean absolute tracking error per iteration for the three schemes. The tracking errors of the NRCILC-FTZNN converge to zero in fewer iterations compared to the other schemes, which demonstrates the rapid convergence.
The tracking error of NRCILC-FTZNN converges to zero with 10 fewer iterations compared to other schemes, which proves its fast convergence.
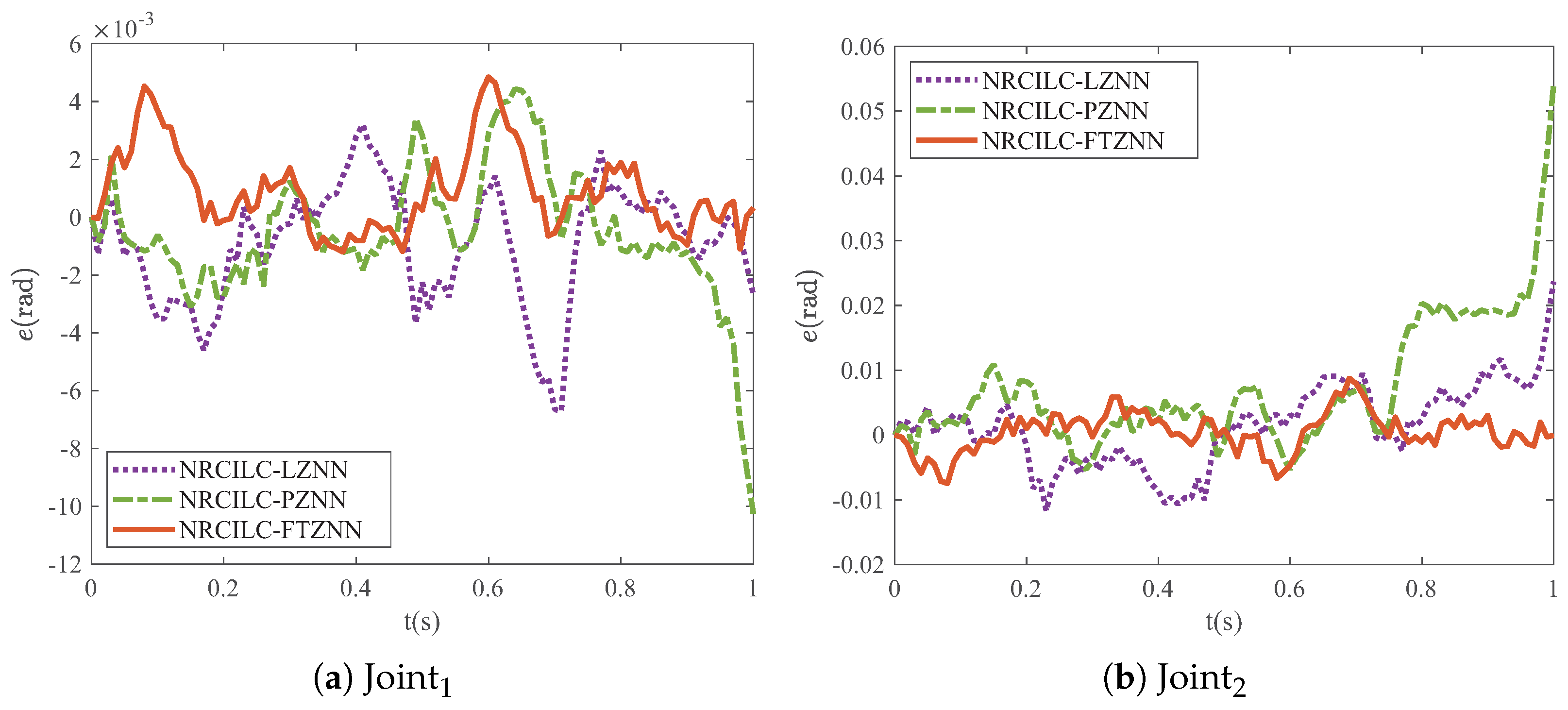
A comparison of the final tracking errors of different schemes is shown in
Figure 8. The tracking error of the NRCILC-FTZNN is smaller than those of the other schemes, which indicates superior tracking performance. The tracking errors of the NRCILC-FTZNN remain consistently within
rad and
rad. Furthermore, the error magnitude is 0.005 rad smaller than other schemes, which demonstrates the asymptotic stability of the NRCILC-FTZNN.
As shown in
Table 2, under the conditions
,
, and
, the RMSE of the NRCILC-FTZNN scheme are 0.0017 and 0.0031, which are the lowest among the three schemes. It demonstrates that the higher accuracy of the proposed tracking control scheme in trajectory tracking.
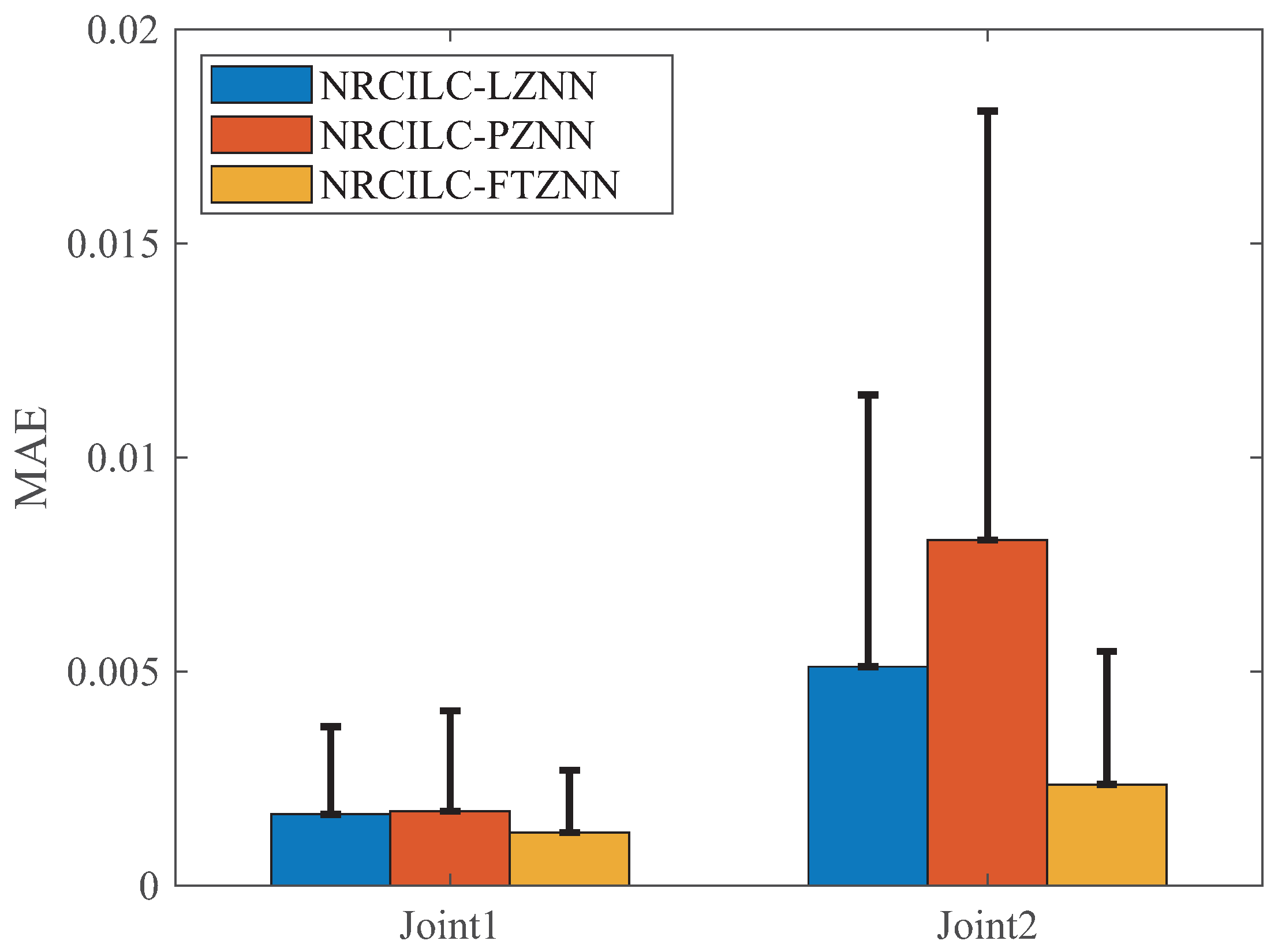
The comparison of MAE and SD for the three schemes is shown in
Figure 9. The MAE evaluates the average deviation between the tracking and desired trajectories, while the SD measures the stability of the trajectory tracking. As shown in the figure, both the MAE and SD of the NRCILC-FTZNN are smaller than those of the other schemes. The average trajectory-tracking error of
and
, calculated by MAE, are reduced by 46.89% and 63.29% compared to other methods, respectively. A smaller MAE value indicates higher accuracy in trajectory tracking, while a smaller SD value suggests reduced trajectory fluctuation and improved stability.
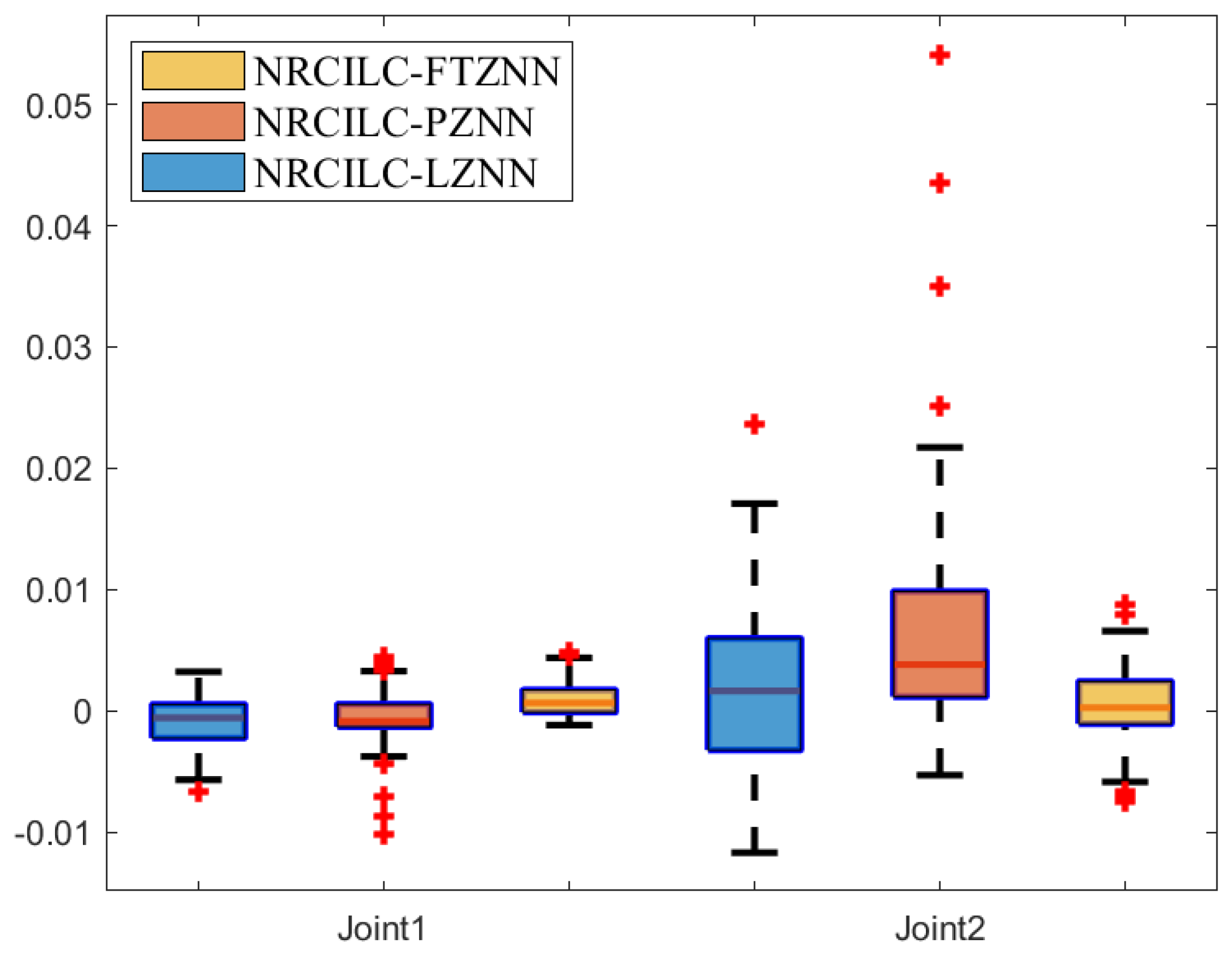
The box plot, a powerful tool for data visualization, is used to reflect the central tendency, dispersion, and outliers of the error data in
Figure 10. Specifically, the median tracking error of the NRCILC-FTZNN is close to zero, which demonstrates the effectiveness in centering the tracking error around zero. Furthermore, the interquartile range as indicated by the length of the box is narrower than that of the other schemes, which reflects the reduced tracking error dispersion. Thus, the NRCILC-FTZNN provides more stable tracking performance.Moreover, the shorter whiskers indicate fewer extreme values. Therefore, the tracking error is centered around zero with low dispersion and a concentrated data distribution. The proposed scheme demonstrates excellent performance in trajectory tracking.
5.3. System Simulation with Different Disturbances
This section demonstrates that the NRCILC-FTZNN effectively performs trajectory tracking under different disturbances, including constant disturbance , linear disturbance , random disturbance , and mixed disturbance . Additionally, the parameters are set as , , and .
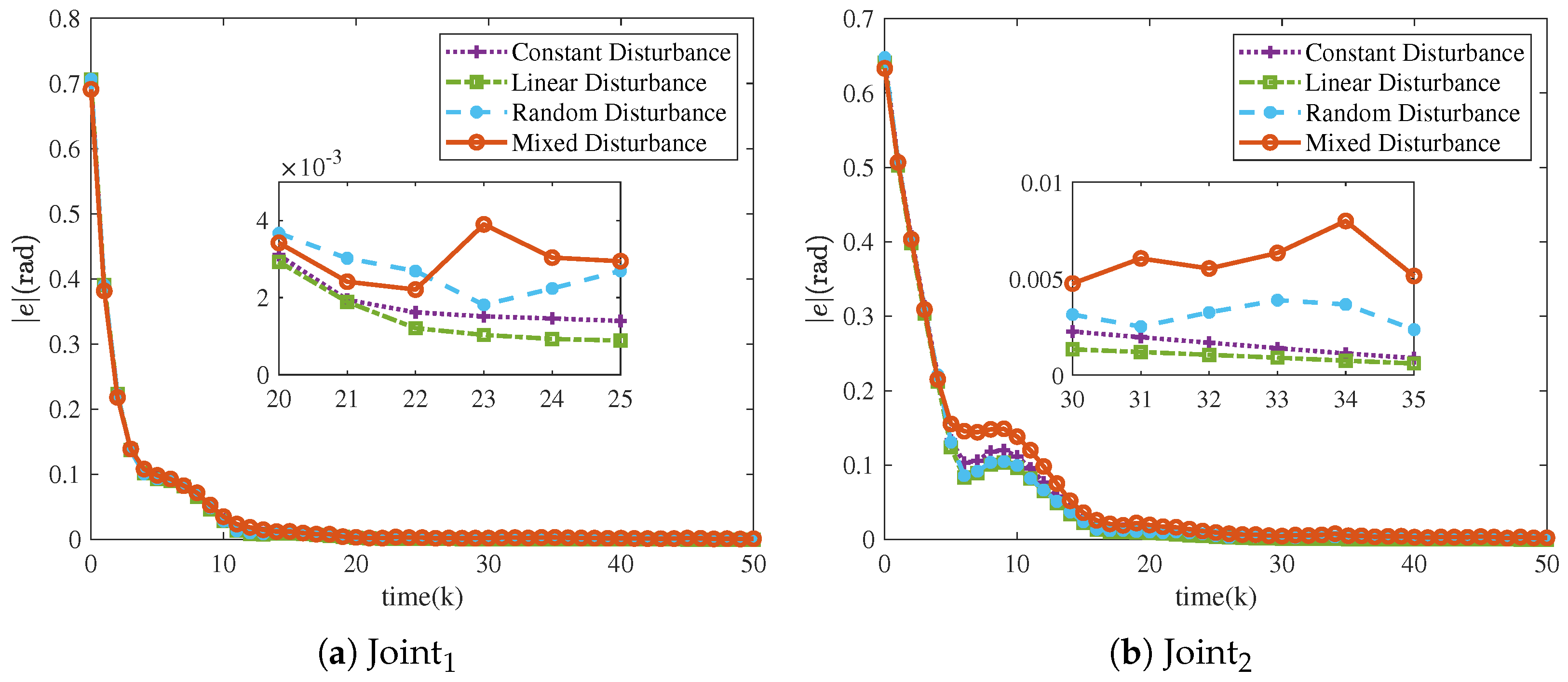
The trajectory tracking under four different types of disturbances is illustrated in
Figure 11. The NRCILC-FTZNN is observed to maintain stable tracking performance under various disturbances. Moreover,
Figure 12 illustrates the mean absolute error over iterations under different disturbances. The tracking errors converge within 0.005 rad and 0.01 rad, which eliminates external disturbances. The simulation results demonstrate that the NRCILC-FTZNN effectively suppresses disturbances and maintains high tracking accuracy.
A comparison of the final tracking errors of the NRCILC-FTZNN with different disturbances is shown in
Figure 13. The error magnitude of
and
under constant and linear disturbances are 0.006 rad and 0.015 rad smaller than random and mixed disturbances. The system exhibits better performance under constant and linear disturbance compared to random and mixed disturbance, as the models for constant and linear disturbance are relatively simple and more easily compensated for.
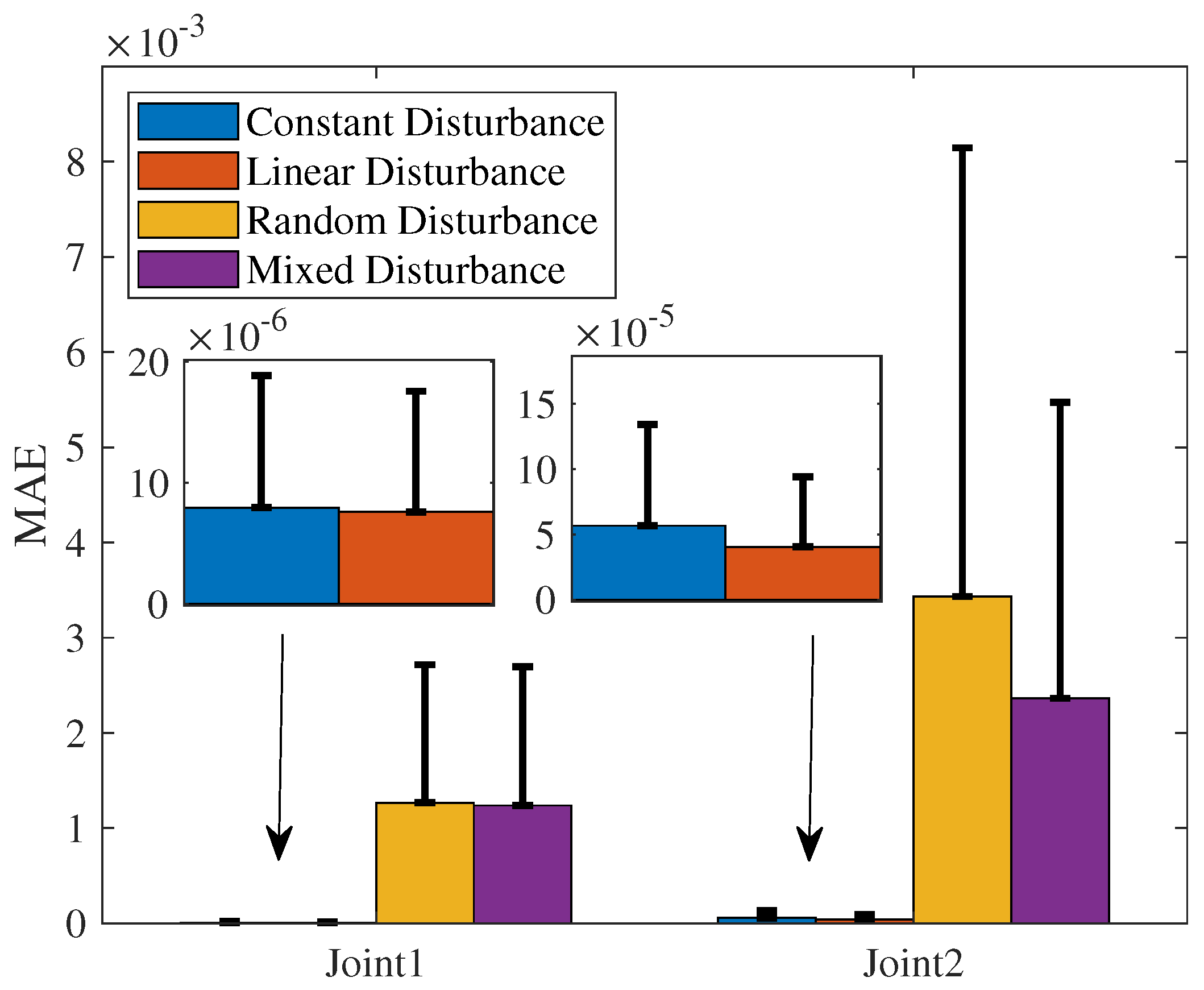
The comparisons of the RMSE, MAE, and SD of the NRCILC-FTZNN under four different disturbances are shown in
Table 2 and
Figure 14. It is evident that the RMSE of constant and linear disturbances ranges from 0.0001 to 0.0009, which is smaller than that of random and mixed disturbances. A smaller RMSE indicates that the NRCILC-FTZNN achieves higher tracking accuracy under constant and linear disturbances with a reduced frequency of large errors. Additionally, the MAE and SD of constant and linear disturbances are smaller than those of random and mixed disturbances. The smaller MAE demonstrates that the NRCILC-FTZNN maintains stability in tracking under constant and linear disturbances. The smaller SD suggests a narrower range of error fluctuations, which further confirms the excellent stability.
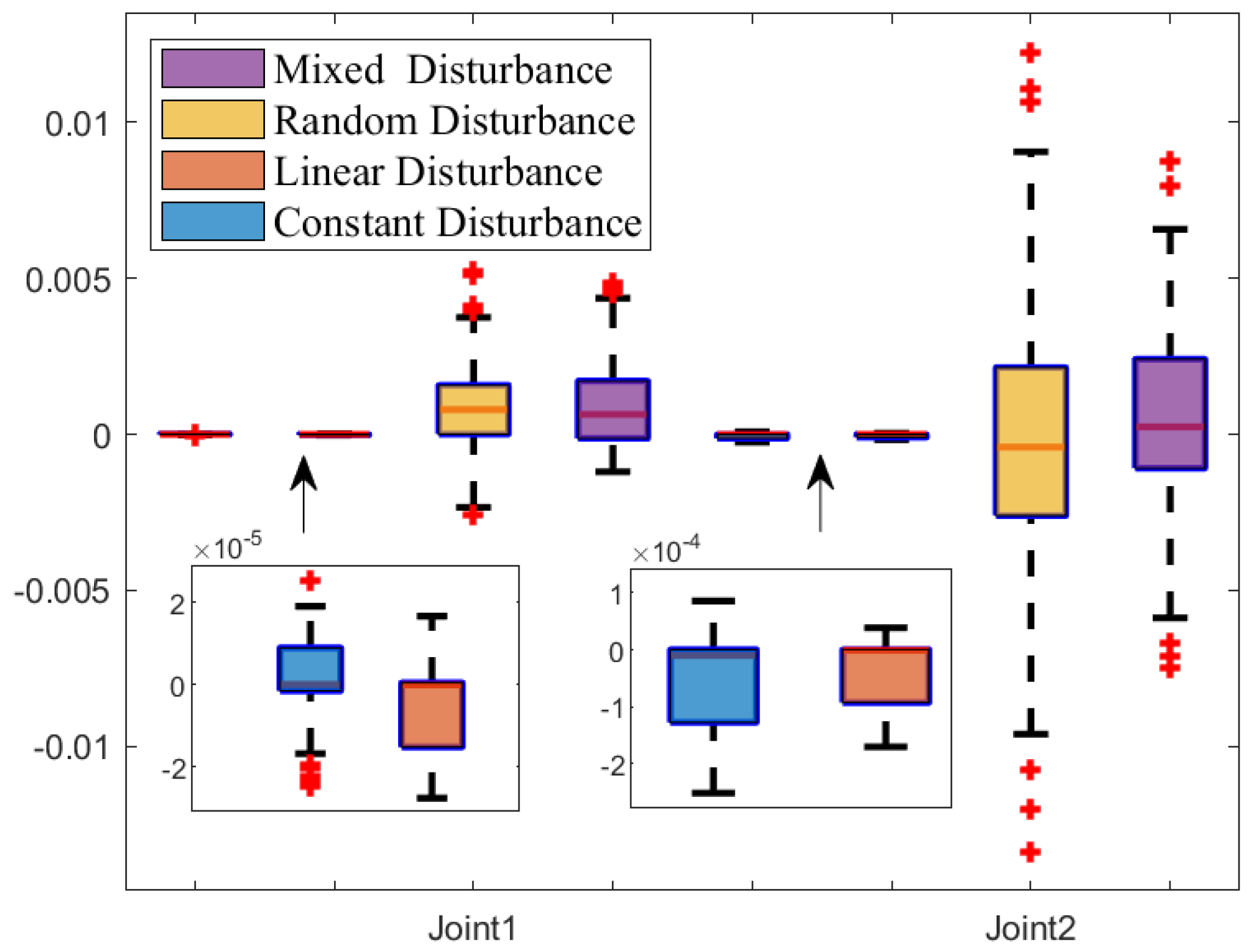
Figure 15 shows the tracking error box plot under different disturbances. Specifically under constant and linear disturbances, the median error is close to zero, which indicates that tracking errors are concentrated around zero. Additionally, the interquartile range under constant and linear disturbances is narrower than that of other disturbances, which suggests a lower degree of error dispersion. Therefore, constant and linear disturbances provide more stable and reliable trajectory tracking. Furthermore, shorter whisker lines under constant and linear disturbances indicate a reduction in extreme values, and fewer outliers are observed. Therefore, the distribution of tracking error data is more concentrated under constant and linear disturbances. In summary, constant and linear disturbances are characterized by tracking errors concentrated near zero, low dispersion, a concentrated data distribution, and fewer outliers.
5.4. System Simulation with Different Parameters
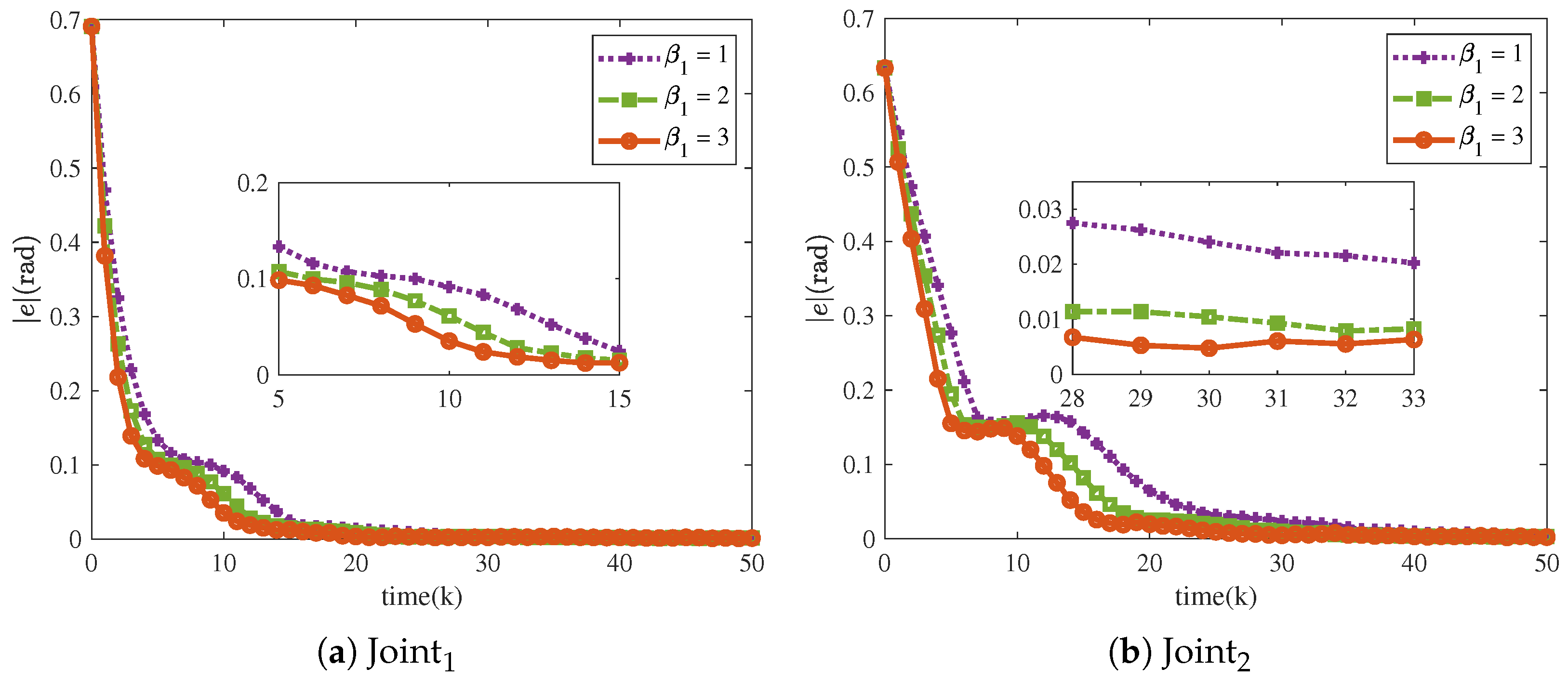
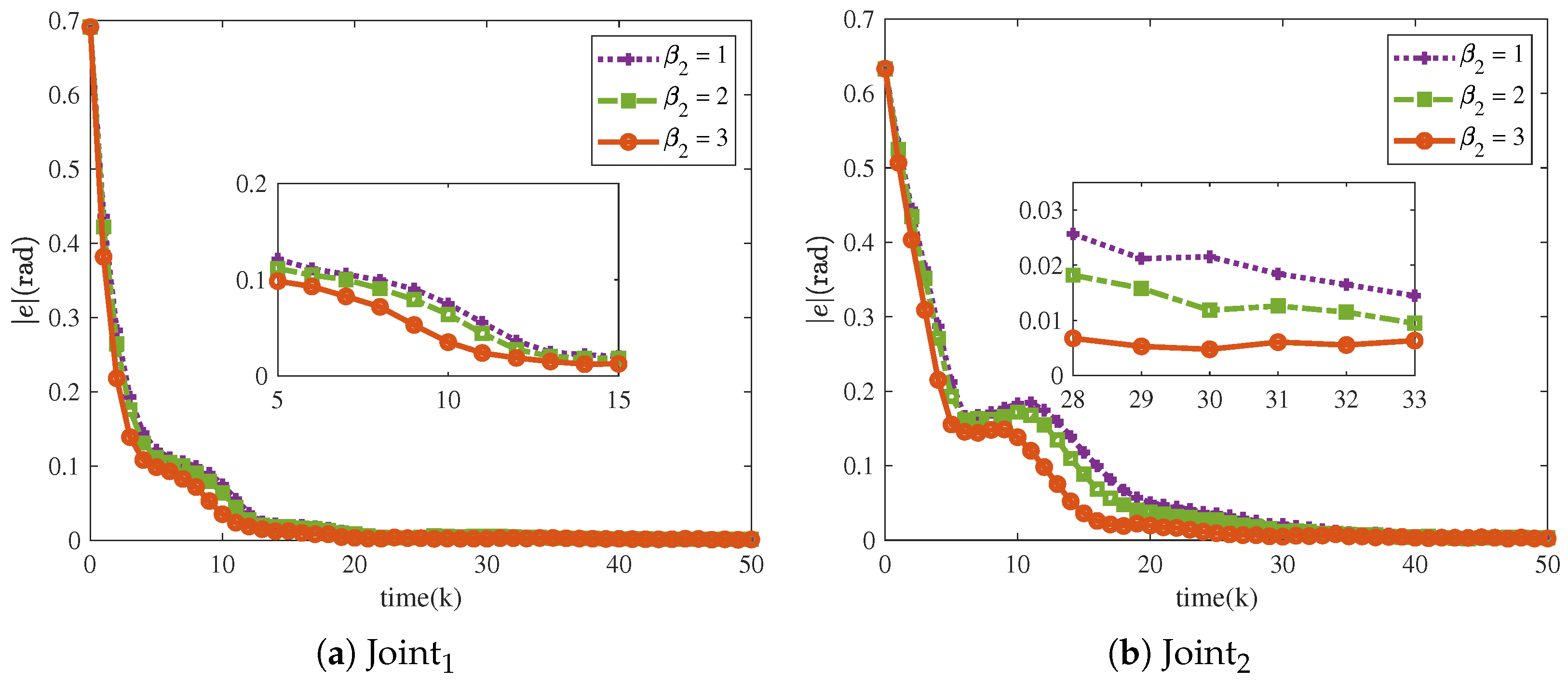
The tracking performance of the proposed scheme depends on various parameters, which makes a sensitivity analysis of these parameters essential. The NRCILC-FTZNN is evaluated for various and , as well as various and various are considered. Additionally, the relevant parameters are set as , and .
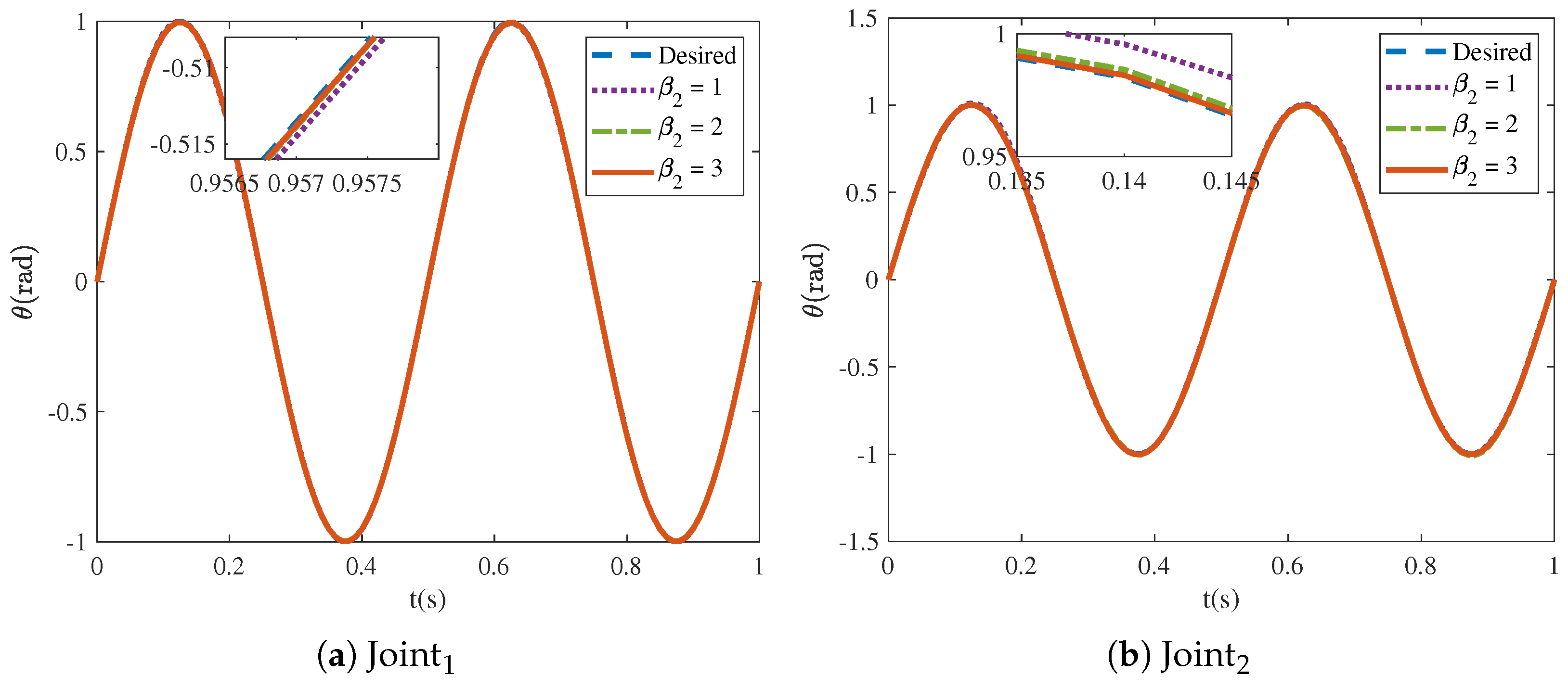
Figure 16 and
Figure 17 show that the tracking trajectories of the NRCILC-FTZNN with various
and various
converge to the desired trajectories. Tracking errors of the NRCILC-FTZNN with various
and various
in iterations are shown in
Figure 18 and
Figure 19, respectively. As shown in
Figure 18, the convergence speed of the tracking error increases with the growth of
. The weight of the linear term in the control law determines the convergence speed under large errors, and a larger
accelerates convergence under these conditions. Furthermore, as shown in
Figure 19, the convergence speed of the tracking error increases with the growth of
. The weight of the nonlinear term in the control law governs the convergence speed under small errors, and a larger
accelerates convergence under these conditions.
The comparisons of the RMSE are shown in
Table 3 and
Table 4. It is clearly observed that the RMSE of
and
based on the NRCILC-FTZNN with
and
are 0.0017rad and 0.0031rad smaller than that under other parameter conditions. A smaller RMSE indicates that higher tracking accuracy is achieved by the NRCILC-FTZNN with larger
and
.
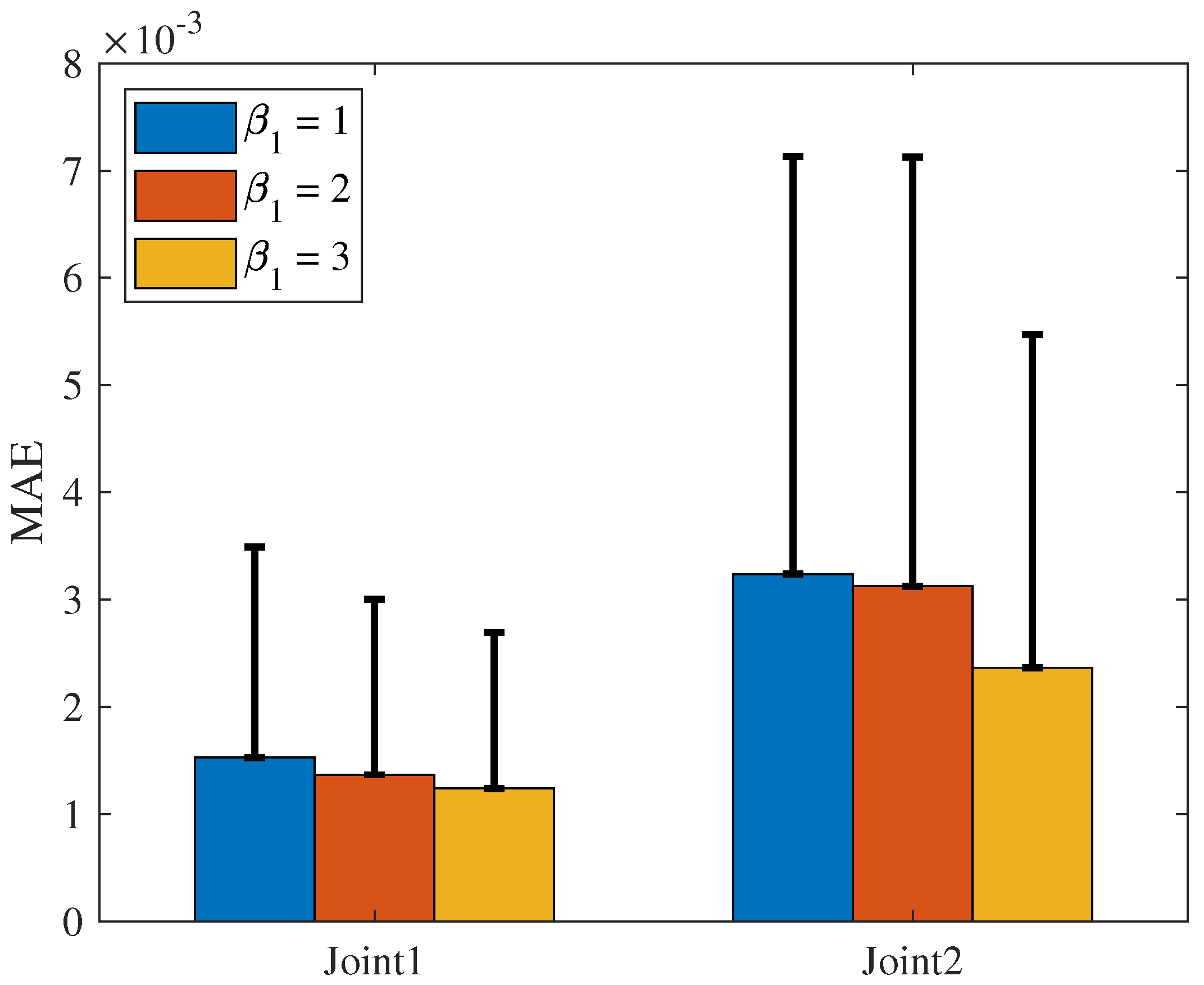
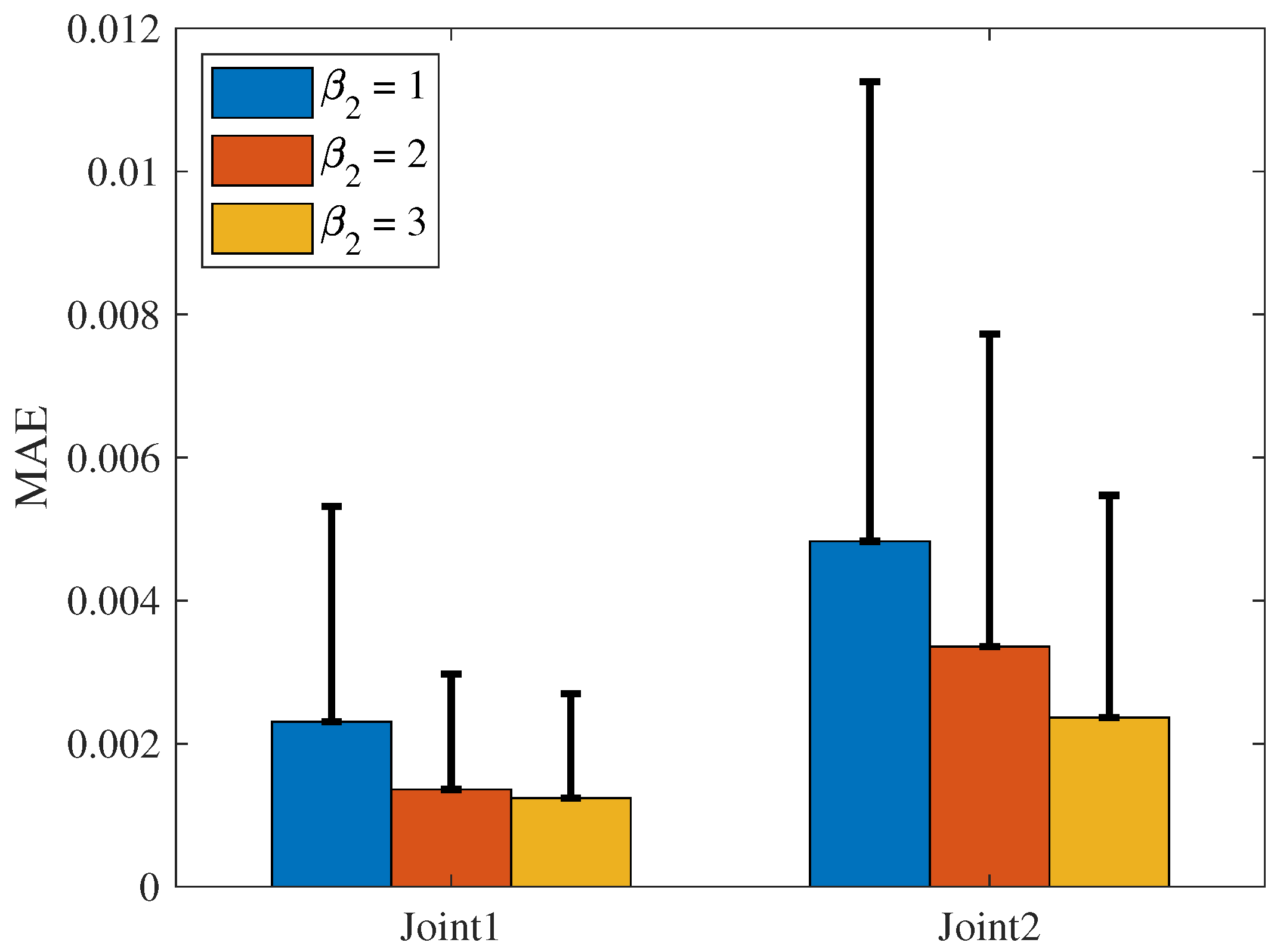
The MAE and SD of the NRCILC-FTZNN with various
and various
are shown in
Figure 20 and
Figure 21. From
Figure 20, the average trajectory-tracking error of
and
with
, calculated by MAE, are reduced by 24.38% and 19.8% compared to the NRCILC-FTZNN with
and
, respectively. Moreover, from
Figure 21, the average trajectory-tracking error of
and
with
, calculated by MAE, are reduced by 49.51% and 23.56% compared to the NRCILC-FTZNN with
and
, respectively. The MAE and SD are observed to be smaller with
and
. The smaller MAE and SD indicate that the stability of trajectory tracking improves as
and
increase.
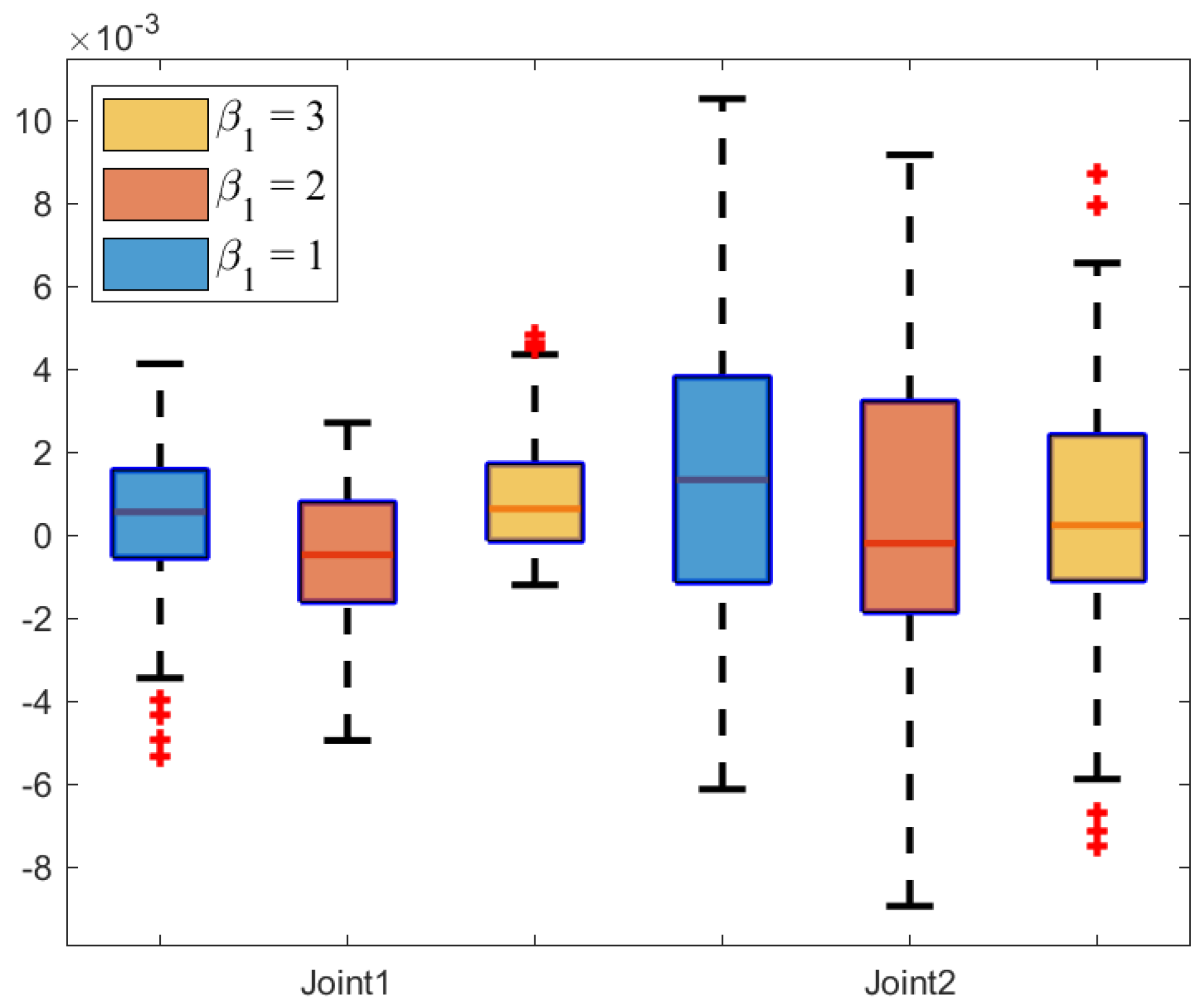
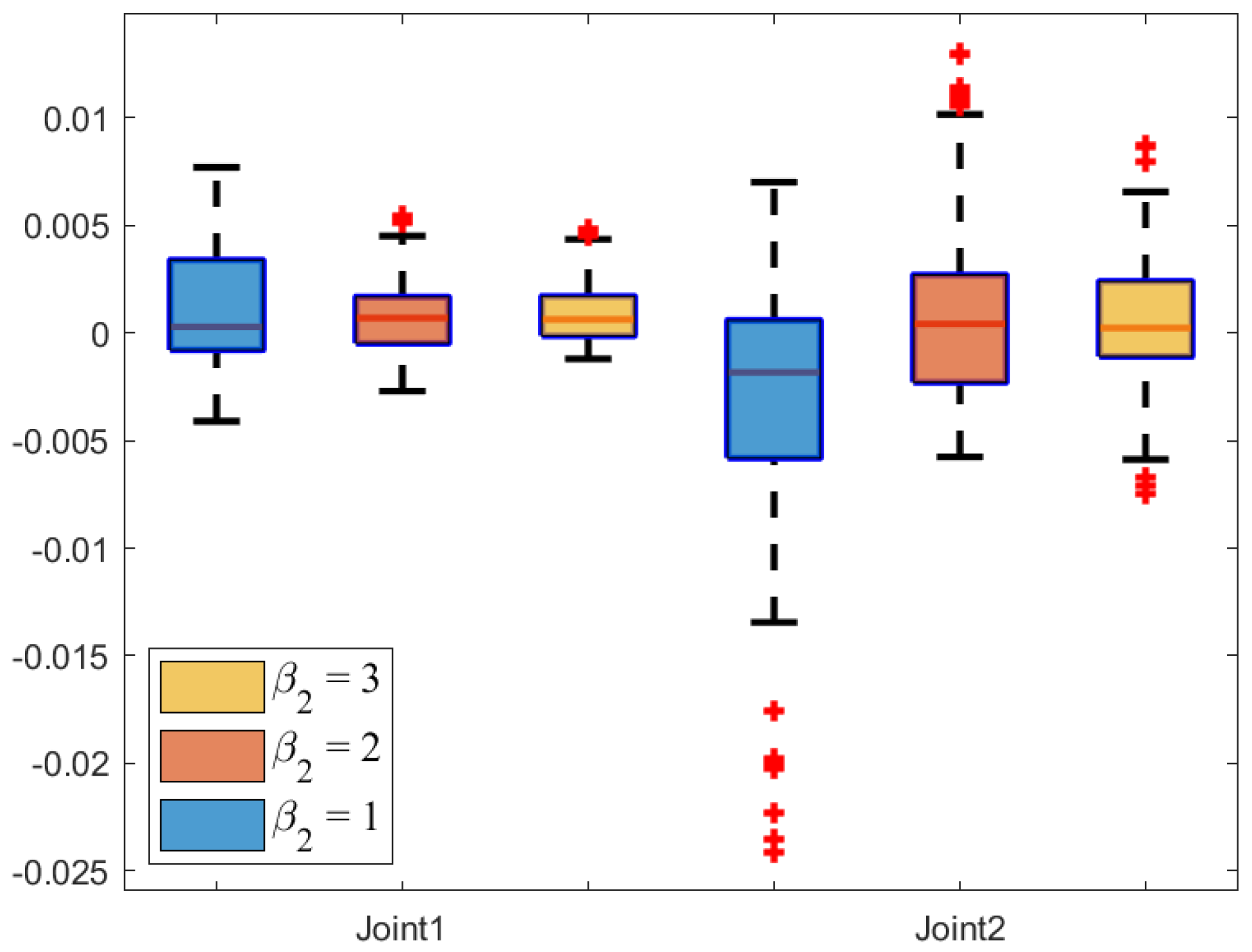
Figure 22 and
Figure 23 illustrate the tracking error box plot for different parameter sets. When
and
, the median error approaches zero, which indicates that the tracking errors are more concentrated near zero. Additionally, the interquartile range under
and
is narrower compared to other parameter conditions, which suggests a lower degree of error dispersion. Therefore, parameters set as
and
provide more stable and reliable trajectory tracking. Furthermore, shorter whisker lines under
and
indicate a reduction in extreme values. In summary, the characteristics of
and
include tracking errors concentrated near zero, low dispersion, and a concentrated data distribution.
5.5. Exploration of Experimental Implementation
To validate the practical applicability of the proposed NRCILC-FTZNN, a feasible implementation and testing plan for real hardware is outlined as follows:
- (1)
To explore the practical feasibility of the proposed NRCILC-FTZNN algorithm, a potential implementation plan is considered on a self-developed two-degree-of-freedom (2-DOF) planar robotic manipulator. The manipulator can be constructed using lightweight aluminum alloy to ensure both structural rigidity. Each joint is actuated by a servo motor equipped with a dedicated closed-loop driver for precise motion control. High-resolution encoders are installed at each joint to provide accurate real-time angular feedback. The control algorithm is implemented on an upper-level computer using MATLAB R2022a, which communicates with a lower-level controller, such as Arduino, and STM32, via CAN communication.
- (2)
The robotic manipulator is tasked with tracking a planar sinusoidal trajectory in a repetitive motion scenario. The proposed ILC without resetting conditions eliminates the need for state resetting, thereby making the control process more consistent with practical robotic operations. The control input is updated after each trial based on the tracking error using the ZNN-based learning mechanism.
- (3)
To simulate real-world conditions, uncertainties such as load changes and sensor noise could be introduced. For instance, small payloads may be added to the end-effector to simulate variations in system, and Gaussian noise can be injected into encoder readings to emulate measurement disturbances. These settings facilitate evaluation of the robustness and adaptability of the controller. Control performance in such a setup can be quantitatively evaluated using metrics such as RMSE, MAE, and SD of the tracking error. The indicators would include convergence speed, steady-state accuracy, and robustness under disturbances.
- (4)
To ensure safe execution, protective strategies such as joint limiters, control signal saturation logic, and emergency stop mechanisms should be integrated into the system. Control parameters can be conservatively tuned initially and gradually optimized once stable performance is achieved.
In summary, although physical experiments have not yet been conducted, the proposed NRCILC-FTZNN algorithm demonstrates promising potential for implementation on a self-developed 2-DOF robotic manipulator. This framework may be extended in the future to more complex platforms with higher degrees of freedom or environments involving visual feedback, compliant joints, and multi-modal sensing. Furthermore, it can be integrated with data-driven strategies such as reinforcement learning to enhance adaptability to uncertain environments.
5.6. Extended Controller Design
For the impact of unmodeled effects, the finite-time convergence property of the ZNN inherently enhances the ability of system to suppress transient disturbances and mitigate certain unmodeled effects. Additionally, adaptive learning mechanisms, such as iteration-based gain tuning, can be integrated into the ILC framework to accommodate nonlinear characteristics. Moreover, data-driven model estimation approaches, such as neural networks, and Gaussian processes, offer a promising means of capturing complex system that are difficult to model explicitly.
Future research will focus on these directions to extend the applicability of the NRCILC-FTZNN algorithm to more realistic robotic environments characterized by strong nonlinearities and significant uncertainties.
6. Conclusions
The ILC with resetting conditions based on FTZNN has been proposed for trajectory tracking of robotic manipulator under disturbances in this paper. The framework has combined a finite-time activation function of ZNN and an ILC algorithm with resetting conditions, and theoretically proved the convergence of proposed scheme. Moreover, through trajectory-tracking simulation experiments and error analysis, the superiority of the NRCILC-FTZNN in convergence has been demonstrated. Specifically, convergence analysis has shown that the NRCILC-FTZNN scheme has exhibited a rapid convergence speed. The eliminating disturbances analysis has indicated that the NRCILC-FTZNN has strong resistance to various external disturbances. Quantitative analysis has shown the superiority of the finite-time activation function of ZNN. The above error analysis has further demonstrated that the NRCILC-FTZNN has high tracking accuracy and stability.
In the future, the activation functions of the ZNN, such as the fixed-time and predetermined-time activation functions, can be replaced or optimized to address diverse applications of robotic manipulator.To further improve trajectory-tracking accuracy, advanced sensor technologies can be integrated into the control scheme. Additionally, combining the proposed approach with intelligent control algorithms, such as reinforcement learning and deep learning, can enhance the autonomous learning and adaptive capabilities of robotic manipulator. Another promising direction is applying the ILC algorithm to control robotic manipulator in real time, enabling more precise and efficient performance in practical implementations. These advancements can significantly expand the functionality and applicability of robotic manipulator systems.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}