Incremental Multi-Step Learning MLP Model for Online Soft Sensor Modeling


Abstract
1. Introduction
2. Proposed Methodology
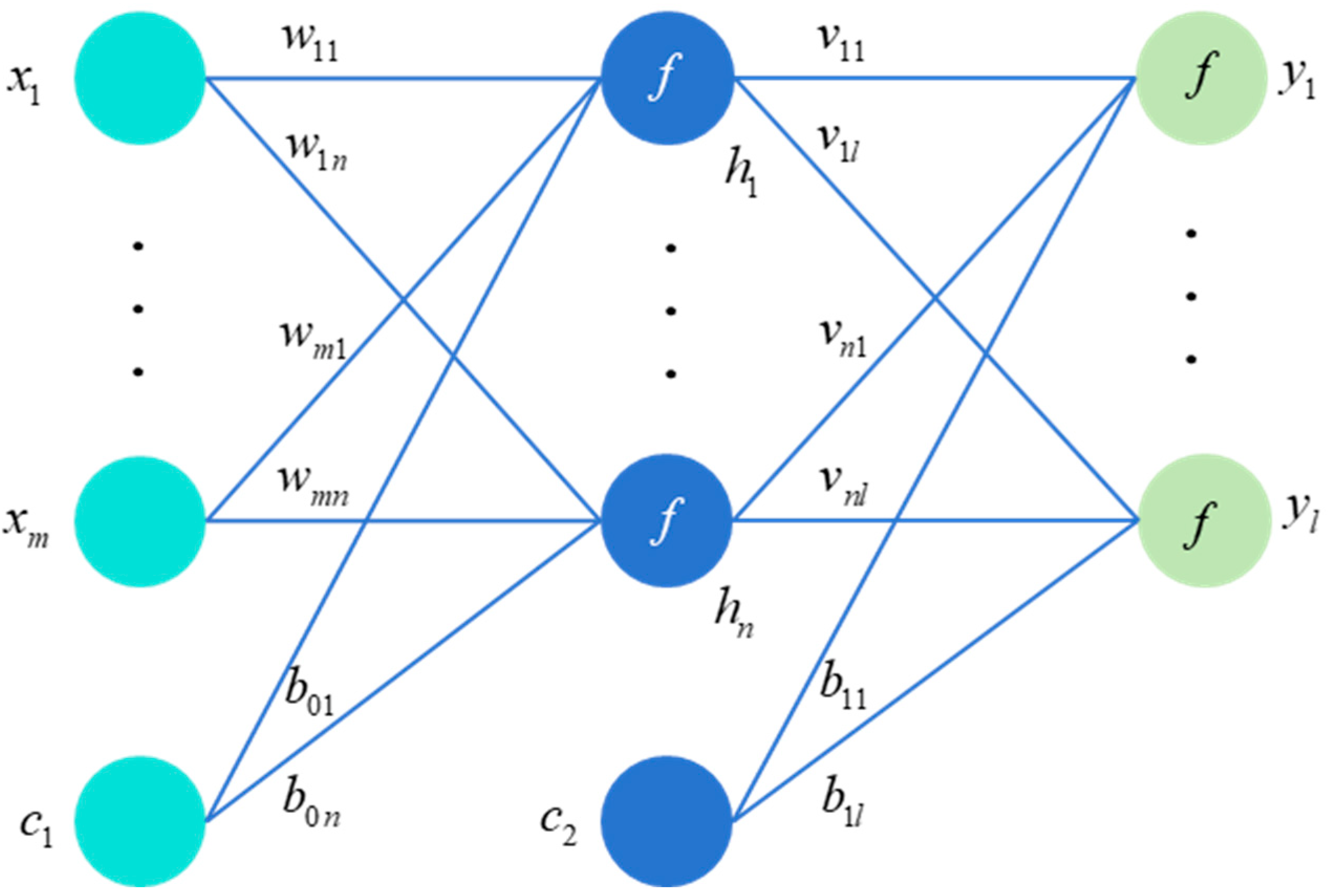
2.1. MLP Model and Algorithm
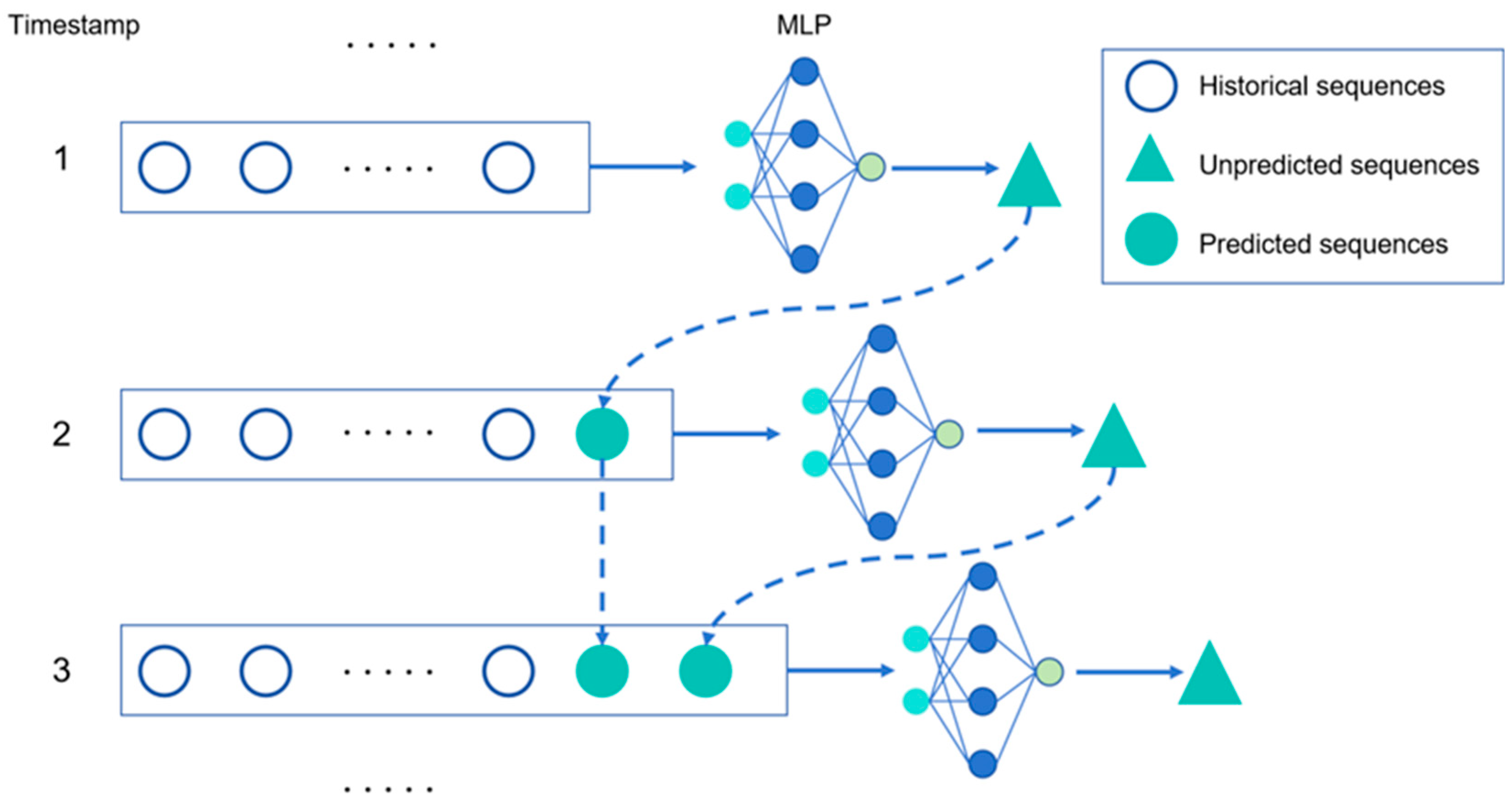
2.2. MVMS-MLP
3. Incremental MVMS-MLP
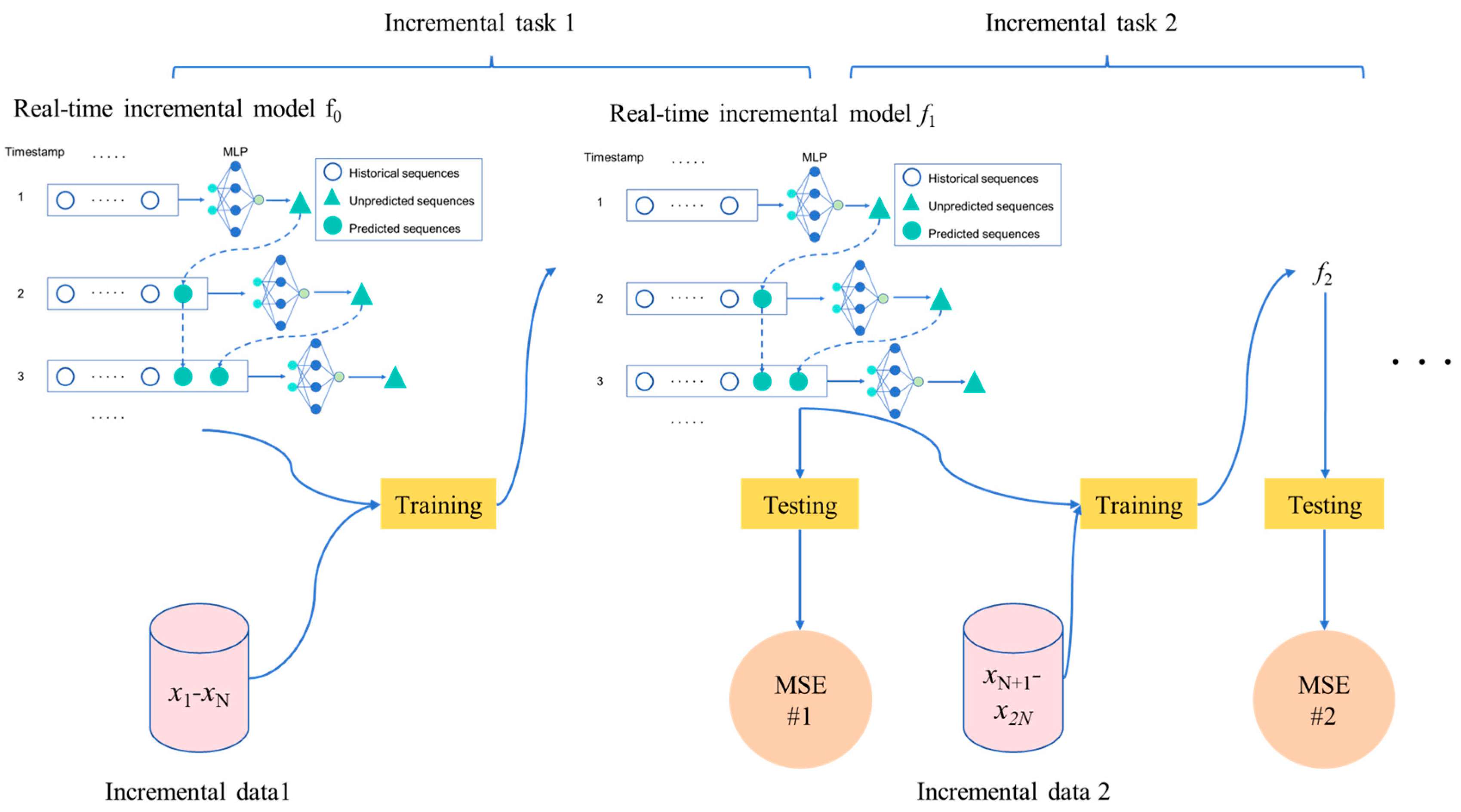
3.1. Incremental Learning
3.2. Procedure of Incremental MVMS-MLP
4. Applications
4.1. Benchmark Dataset
4.2. MAPD Soft Sensor Development
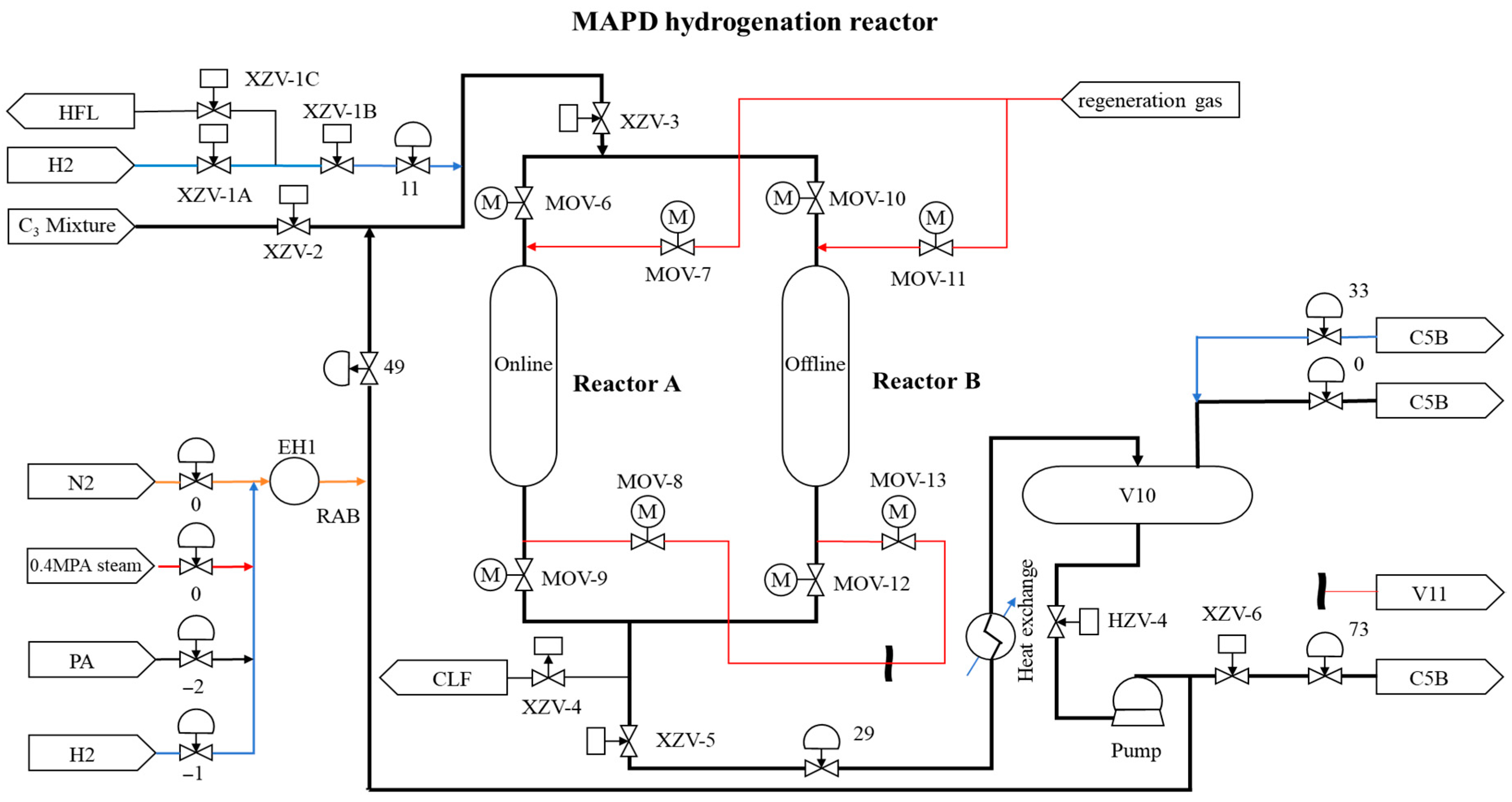
4.2.1. MAPD Hydrogenation Reactor Process
4.2.2. Auxiliary Variable Selection
4.2.3. Model Architecture
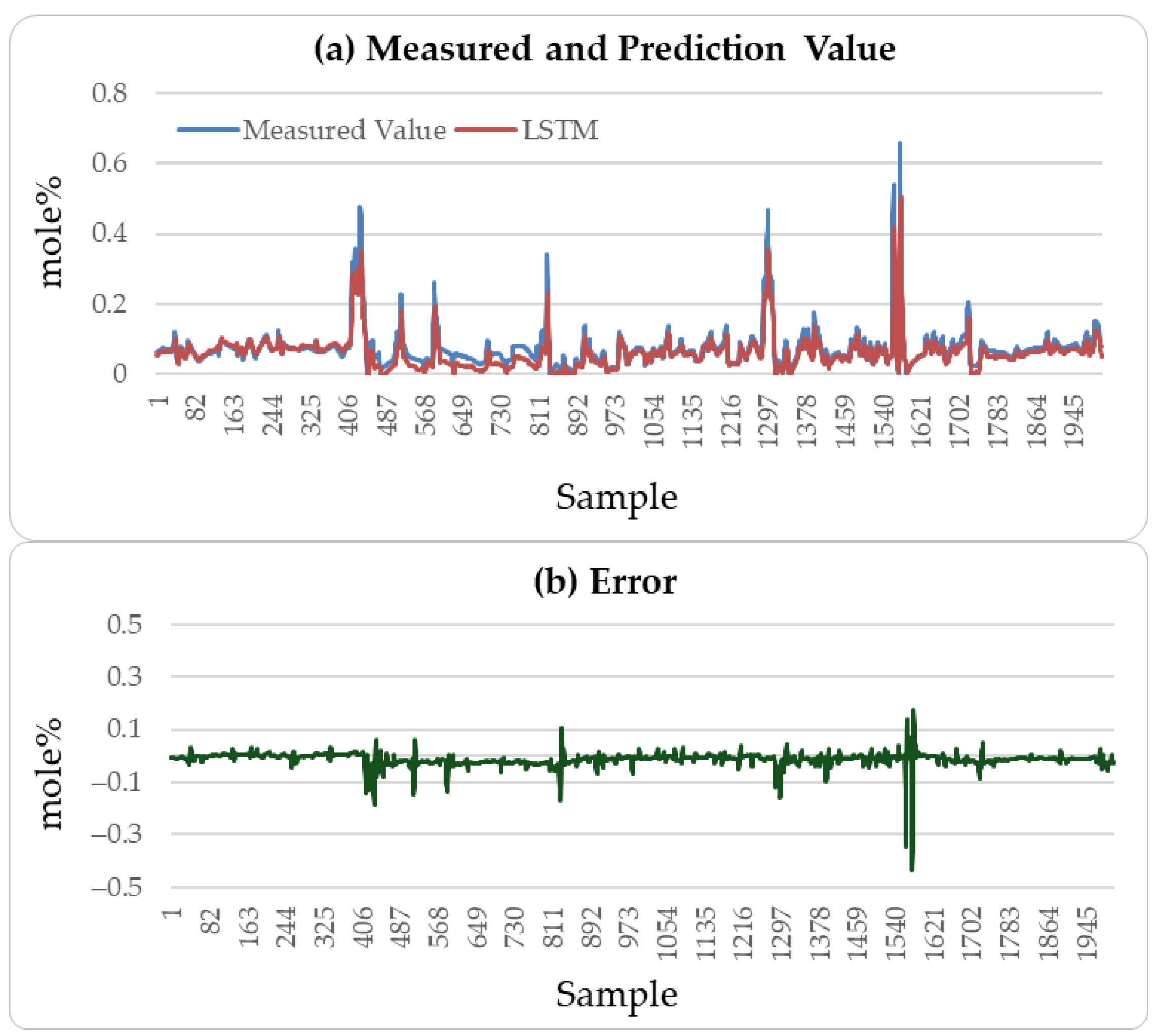
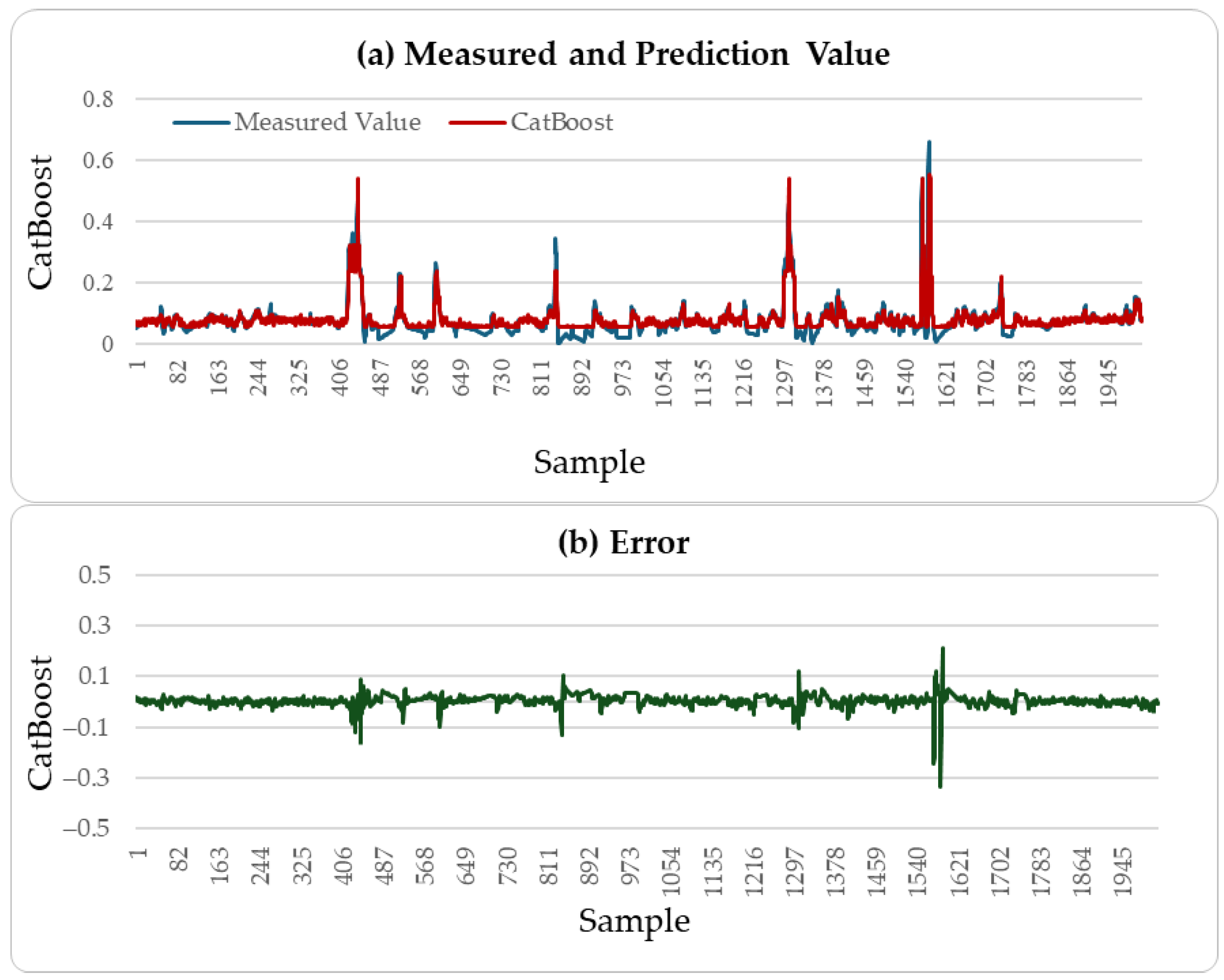
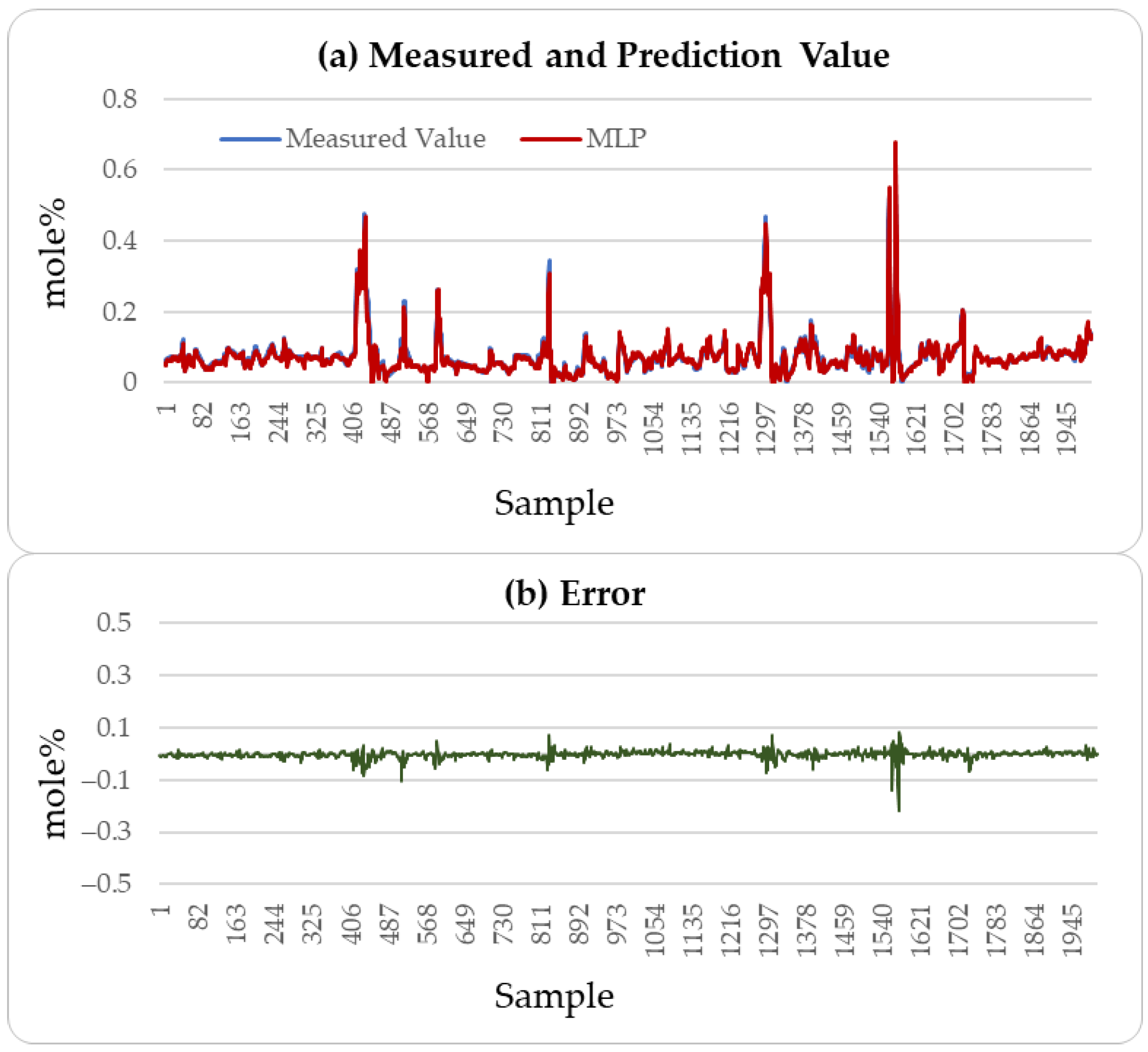
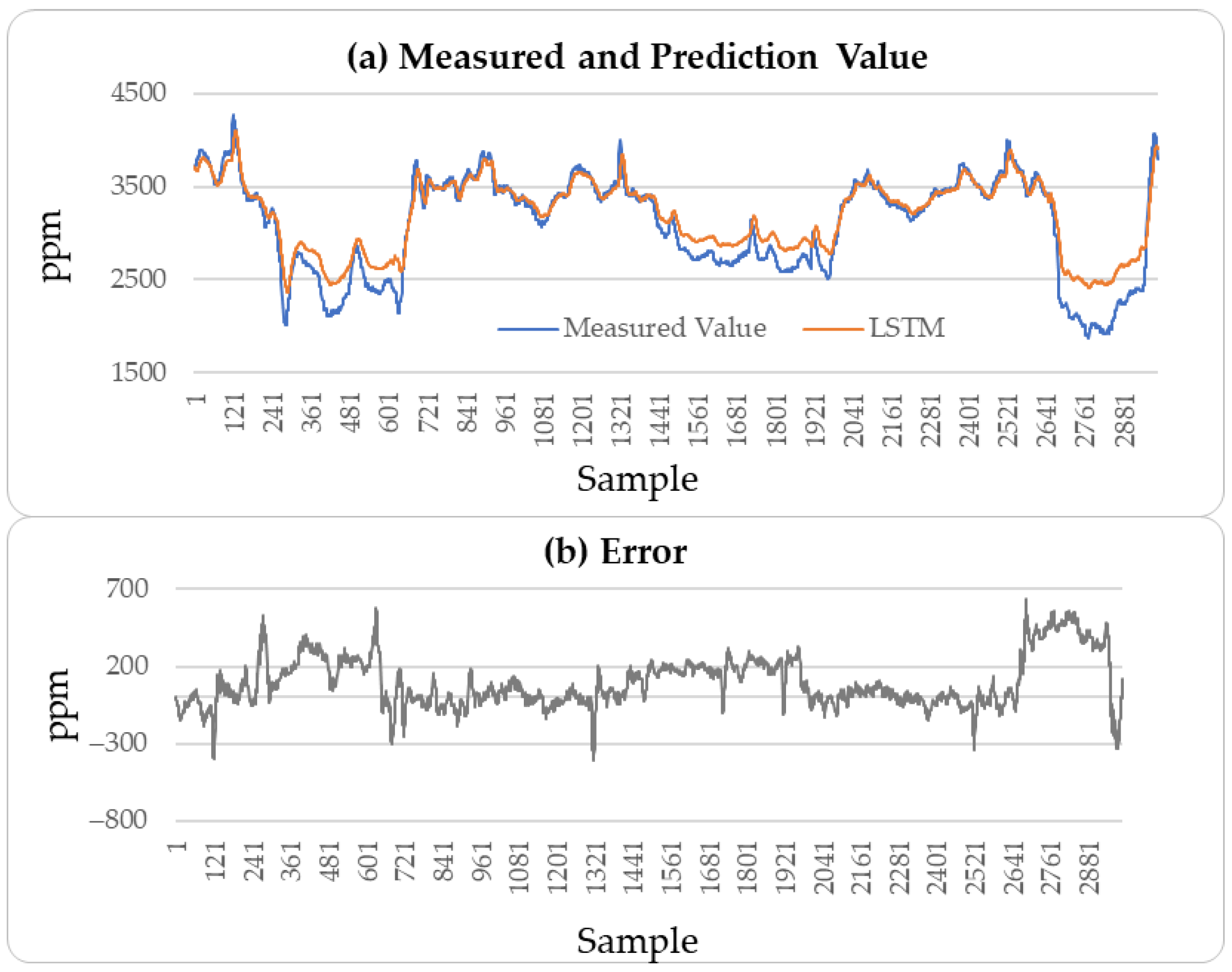
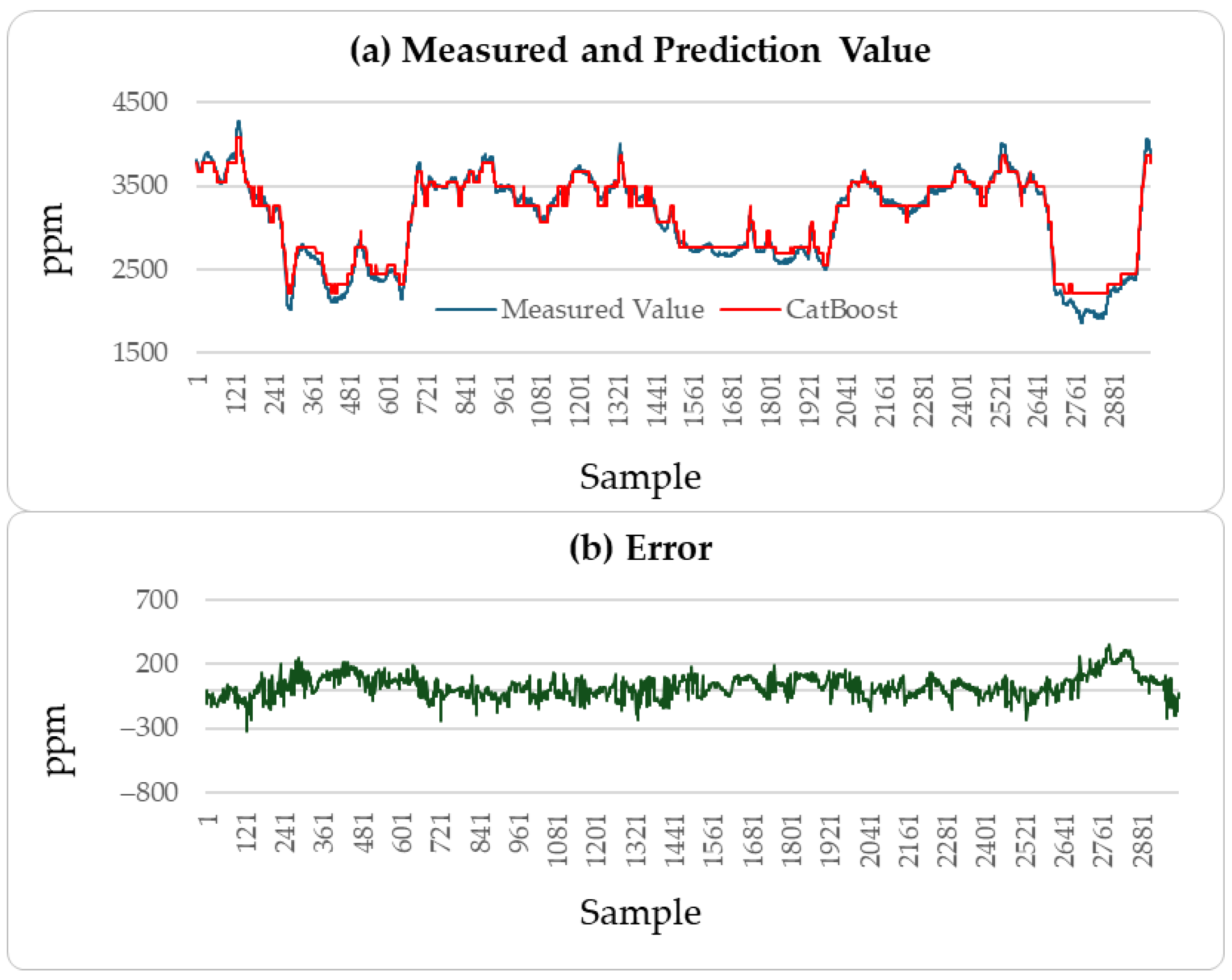
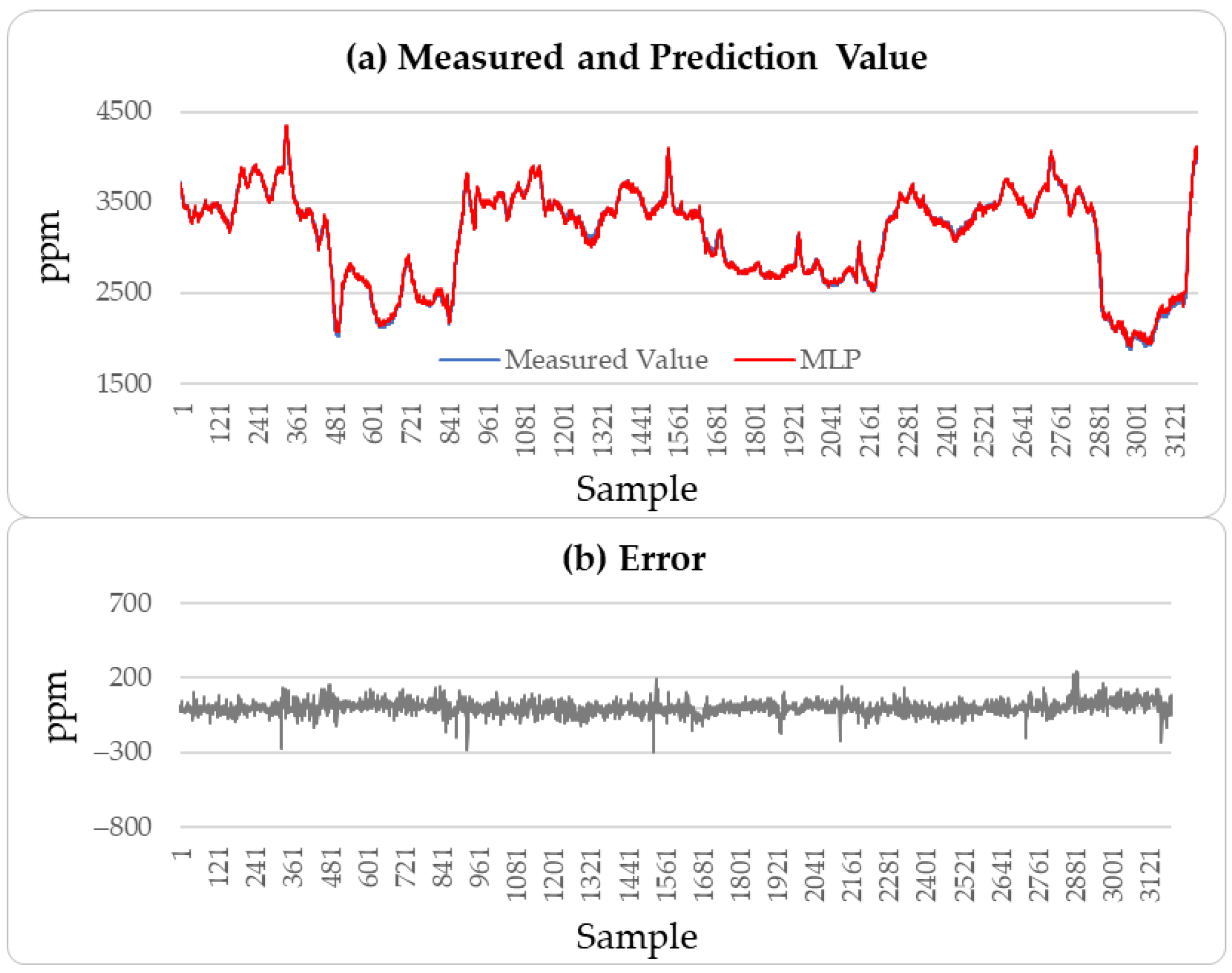
4.2.4. Result Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MVMS-MLP | Multivariate Multi-Step Multilayer Perceptron |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| SRU | Sulfur Recovery Unit |
| MAPD | Methylacetylene–Propadiene |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| ReLU | Rectified Linear Unit |
| Adam | A Stochastic Gradient Descent Optimization Algorithm |
| H2S | Hydrogen Sulfide |
| C3 | Propylene Fraction |
References
- Zhou, J.-y.; Yang, C.-h.; Wang, X.-l.; Cao, S.-y. A soft sensor modeling framework embedded with domain knowledge based on spatio-temporal deep LSTM for process industry. Eng. Appl. Artif. Intell. 2023, 126, 106847. [Google Scholar] [CrossRef]
- Xie, S.; Yu, J.; Xie, Y.; Jiang, Z.; Gui, W. A two-layer optimization and control strategy for zinc hydrometallurgy process based on RBF neural network soft-sensor. In Proceedings of the 2019 1st International Conference on Industrial Artificial Intelligence (IAI), Online, 23–27 July 2019; pp. 1–6. [Google Scholar]
- Tian, Z.; Li, S.; Wang, Y.; Wang, X. A multi-model fusion soft sensor modelling method and its application in rotary kiln calcination zone temperature prediction. Trans. Inst. Meas. Control 2016, 38, 110–124. [Google Scholar]
- Thuruthel, T.G.; Shih, B.; Laschi, C.; Tolley, M.T. Soft robot perception using embedded soft sensors and recurrent neural networks. Sci. Rob. 2019, 4, eaav1488. [Google Scholar]
- Yuan, X.; Li, L.; Shardt, Y.A.; Wang, Y.; Yang, C. Deep learning with spatiotemporal attention-based LSTM for industrial soft sensor model development. IEEE Trans. Ind. Electron. 2020, 68, 4404–4414. [Google Scholar] [CrossRef]
- Ma, L.; Zhao, Y.; Wang, B.; Shen, F. A multistep sequence-to-sequence model with attention LSTM neural networks for industrial soft sensor application. IEEE Sens. J. 2023, 23, 10801–10813. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, X.; Song, Z.; Kano, M. Multivariate Deep Reconstruction Neural Network for Multi-step-ahead Prediction of Industrial Process Quality Variables. IFAC-Pap. Online 2023, 56, 2852–2857. [Google Scholar] [CrossRef]
- Ou, C.; Zhu, H.; Shardt, Y.A.; Ye, L.; Yuan, X.; Wang, Y.; Yang, C. Quality-driven regularization for deep learning networks and its application to industrial soft sensors. IEEE Trans. Neural Netw. Learn. Syst. 2022, 36, 3943–3953. [Google Scholar] [CrossRef]
- Ke, W.; Huang, D.; Yang, F.; Jiang, Y. Soft sensor development and applications based on LSTM in deep neural networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–6. [Google Scholar]
- Yuan, X.; Huang, B.; Wang, Y.; Yang, C.; Gui, W. Deep learning-based feature representation and its application for soft sensor modeling with variable-wise weighted SAE. IEEE Trans. Ind. Inf. 2018, 14, 3235–3243. [Google Scholar] [CrossRef]
- Jia, M.; Yao, Y.; Liu, Y. Review on Graph Neural Networks for Process Soft Sensor Development, Fault Diagnosis, and Process Monitoring. Ind. Eng. Chem. Res. 2025, 64, 8543–8564. [Google Scholar] [CrossRef]
- Li, Z.; Xue, K.; Chen, J.; Peng, X. A quality-driven multi-attribute channel hybrid neural network for soft sensing in refining processes. Measurement 2025, 250, 117061. [Google Scholar] [CrossRef]
- Jin, H.; Dong, X.; Qian, B.; Wang, B.; Yang, B.; Chen, X. Soft sensor modeling using deep learning with maximum relevance and minimum redundancy for quality prediction of industrial processes. ISA Trans. 2025, 146, 351–363. [Google Scholar] [CrossRef] [PubMed]
- Van de Ven, G.M.; Tuytelaars, T.; Tolias, A.S. Three types of incremental learning. Nat. Mach. Intell. 2022, 4, 1185–1197. [Google Scholar] [CrossRef] [PubMed]
- Feng, F.; Chan, R.H.; Shi, X.; Zhang, Y.; She, Q. Challenges in task incremental learning for assistive robotics. IEEE Access 2019, 8, 3434–3441. [Google Scholar] [CrossRef]
- Mozaffari, A.; Vajedi, M.; Azad, N.L. A robust safety-oriented autonomous cruise control scheme for electric vehicles based on model predictive control and online sequential extreme learning machine with a hyper-level fault tolerance-based supervisor. Neurocomputing 2015, 151, 845–856. [Google Scholar] [CrossRef]
- Khannoussi, A.; Olteanu, A.-L.; Labreuche, C.; Narayan, P.; Dezan, C.; Diguet, J.-P.; Petit-Frère, J.; Meyer, P. Integrating operators’ preferences into decisions of unmanned aerial vehicles: Multi-layer decision engine and incremental preference elicitation. In Algorithmic Decision Theory, Proceedings of the 6th International Conference, ADT 2019, Durham, NC, USA, 25–27 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 49–64. [Google Scholar]
- Yan, S.; Xie, J.; He, X. Der: Dynamically expandable representation for class incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3014–3023. [Google Scholar]
- Chi, Z.; Gu, L.; Liu, H.; Wang, Y.; Yu, Y.; Tang, J. Metafscil: A meta-learning approach for few-shot class incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Louisiana, NO, USA, 18–24 June 2022; pp. 14166–14175. [Google Scholar]
- Castro, F.M.; Marín-Jiménez, M.J.; Guil, N.; Schmid, C.; Alahari, K. End-to-end incremental learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 233–248. [Google Scholar]
- Masana, M.; Liu, X.; Twardowski, B.; Menta, M.; Bagdanov, A.D.; Van De Weijer, J. Class-incremental learning: Survey and performance evaluation on image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5513–5533. [Google Scholar] [CrossRef]
- Tao, X.; Hong, X.; Chang, X.; Dong, S.; Wei, X.; Gong, Y. Few-shot class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12183–12192. [Google Scholar]
- Liu, Y.; Schiele, B.; Sun, Q. Adaptive aggregation networks for class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2544–2553. [Google Scholar]
- Wang, Y.; Zhou, L.; He, S.; Wu, Y. Multi-rate Autoregressive Dynamic Latent Variable Model for Soft Sensing in Dynamic Processes. IEEE Trans. Instrum. Meas. 2025, 74, 1008110. [Google Scholar]
- Yanchuk, S.; Giacomelli, G. Spatio-temporal phenomena in complex systems with time delays. J. Phys. A: Math. Theor. 2017, 50, 103001. [Google Scholar] [CrossRef]
- Yang, X.; Lam, J.; Ho, D.W.; Feng, Z. Fixed-time synchronization of complex networks with impulsive effects via nonchattering control. IEEE Trans. Autom. Control 2017, 62, 5511–5521. [Google Scholar] [CrossRef]
- Ding, S.; Wang, Z.; Xie, X. Periodic event-triggered synchronization for discrete-time complex dynamical networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 3622–3633. [Google Scholar] [CrossRef]
- Truong, H.T.; Ta, B.P.; Le, Q.A.; Nguyen, D.M.; Le, C.T.; Nguyen, H.X.; Do, H.T.; Nguyen, H.T.; Tran, K.P. Light-weight federated learning-based anomaly detection for time-series data in industrial control systems. Comput. Ind. 2022, 140, 103692. [Google Scholar] [CrossRef]
- Shen, B.; Jiang, X.; Yao, L.; Zeng, J. Gaussian mixture TimeVAE for industrial soft sensing with deep time series decomposition and generation. J. Process Control. 2025, 147, 103355. [Google Scholar] [CrossRef]
- Cao, L.; Wang, J.; Su, J.; Luo, Y.; Cao, Y.; Braatz, R.D.; Gopaluni, B. Comprehensive analysis on machine learning approaches for interpretable and stable soft sensors. IEEE Trans. Instrum. Meas. 2025, 74, 9517217. [Google Scholar] [CrossRef]
- Jia, M.; Jiang, L.; Guo, B.; Liu, Y.; Chen, T. Physical-anchored graph learning for process key indicator prediction. Control Eng. Pract. 2025, 154, 106167. [Google Scholar] [CrossRef]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Karlik, B.; Olgac, A.V. Performance analysis of various activation functions in generalized MLP architectures of neural networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Yilmaz, I.; Kaynar, O. Multiple regression. ANN (RBF, MLP) and ANFIS models for prediction of swell potential of clayey soils. Expert Syst. Appl. 2011, 38, 5958–5966. [Google Scholar] [CrossRef]
- Heidari, E.; Sobati, M.A.; Movahedirad, S. Accurate prediction of nanofluid viscosity using a multilayer perceptron artificial neural network (MLP-ANN). Chemom. Intell. Lab. Syst. 2016, 155, 73–85. [Google Scholar] [CrossRef]
- Zare, M.; Pourghasemi, H.R.; Vafakhah, M.; Pradhan, B. Landslide susceptibility mapping at Vaz Watershed (Iran) using an artificial neural network model: A comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arab. J. Geosci. 2013, 6, 2873–2888. [Google Scholar] [CrossRef]
- Bai, Y.; Zhao, J. A novel transformer-based multi-variable multi-step prediction method for chemical process fault prognosis. Process Saf. Environ. Prot. 2023, 169, 937–947. [Google Scholar] [CrossRef]
- He, X.; Shi, S.; Geng, X.; Yu, J.; Xu, L. Multi-step forecasting of multivariate time series using multi-attention collaborative network. Expert Syst. Appl. 2023, 211, 118516. [Google Scholar] [CrossRef]
- Fortuna, L.; Rizzo, A.; Sinatra, M.; Xibilia, M.G. Soft analyzers for a sulfur recovery unit. Control Eng. Pract. 2003, 11, 1491–1500. [Google Scholar] [CrossRef]
- Qian, X.; Jia, S.; Luo, Y.; Yuan, X.; Yu, K.-T. Selective hydrogenation and separation of C3 stream by thermally coupled reactive distillation. Chem. Eng. Res. Des. 2015, 99, 176–184. [Google Scholar] [CrossRef]
- Chen, M.; Yan, K.; Cao, Y.; Li, Y.; Ge, X.; Zhang, J.; Gong, X.; Qian, G.; Zhou, X.; Duan, X. Thermodynamics insights into the selective hydrogenation of alkynes in C2 and C3 streams. Ind. Eng. Chem. Res. 2021, 60, 16969–16980. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Auxiliary Variables | Dominant Variable | ||||
|---|---|---|---|---|---|
| MEA GAS (Nm3/h) | AIR MEA1 (Nm3/h) | AIR MEA 2 (Nm3/h) | AIR SWS (Nm3/h) | SWS GAS (Nm3/h) | H2S (mol%) |
| Single Incremental Sample | Incremental Learning Times | Total Incremental Samples | Incremental Learning Rate | H2S MAE | H2S MSE | |
|---|---|---|---|---|---|---|
| Original paper model | 0.0008 | |||||
| LSTM | 4000 | 0.015 | 0.00065 | |||
| CatBoost | 4000 | 0.0144 | 0.0006 | |||
| GRU | 4000 | 0.0154 | 0.00079 | |||
| MVMS-MLP | 4000 | 0.02 | 0.001 | |||
| Incremental MVMS-MLP | 250 | 12 | 3000 | 0.001 | 0.0187 | 0.00085 |
| 250 | 12 | 3000 | 0.0015 | 0.0183 | 0.000849 | |
| 250 | 12 | 3000 | 0.002 | 0.0179 | 0.00084 | |
| 500 | 6 | 3000 | 0.001 | 0.014 | 0.00049 | |
| 500 | 6 | 3000 | 0.0015 | 0.0126 | 0.000469 | |
| 500 | 6 | 3000 | 0.002 | 0.011 | 0.00045 | |
| 1000 | 3 | 3000 | 0.001 | 0.02 | 0.00075 | |
| 1000 | 3 | 3000 | 0.0015 | 0.017 | 0.00059 | |
| 1000 | 3 | 3000 | 0.002 | 0.016 | 0.0005 | |
| 1500 | 2 | 3000 | 0.001 | 0.0117 | 0.000277 | |
| 1500 | 2 | 3000 | 0.002 | 0.012 | 0.000266 | |
| 1500 | 2 | 3000 | 0.005 | 0.011 | 0.000257 |
| Tag Description | Unit |
|---|---|
| Fresh C3 | t/h |
| Cycle C3 | t/h |
| Hydrogen flowrate | kg/h |
| Outlet temperature | °C |
| Outlet pressure | MPa |
| Cycle C3 temperature | °C |
| Outlet online analysis of hydrogen concentration | ppm |
| Outlet online analysis of propylene | % |
| Outlet online analysis of MA | ppm |
| Outlet online analysis of PD | ppm |
| Inlet online analysis of propylene | % |
| Inlet online analysis of MA | % |
| Inlet online analysis of PD | % |
| Auxiliary Variables | Dominant Variable | ||
|---|---|---|---|
| Pearson coefficient | Fresh C3 (t/h) | Hydrogen (kg/h) | Outlet MAPD (ppm) |
| Fresh C3 (t/h) | 1.000000 | 0.692936 | 0.389205 |
| Hydrogen (kg/h) | 0.692936 | 1.000000 | 0.215326 |
| Outlet MAPD (ppm) | 0.389205 | 0.215326 | 1.000000 |
| Single Incremental Samples | Incremental Learning Sessions | Total Incremental Samples | Incremental Learning Rate | Outlet MAPD MAE | Outlet MAPD MSE | |
|---|---|---|---|---|---|---|
| MVMS-LSTM | 6000 | 54.17 | 6587 | |||
| MVMS-CatBoost | 6000 | 71.75 | 8395 | |||
| MVMS-GRU | 6000 | 59.5 | 6047 | |||
| MVMS-MLP | 6000 | 52 | 6448 | |||
| Incremental MVMS-MLP | 500 | 12 | 6000 | 0.002 | 50.75 | 4961 |
| 500 | 12 | 6000 | 0.005 | 45.2 | 3511 | |
| 500 | 12 | 6000 | 0.01 | 44.7 | 3434 | |
| 1000 | 6 | 6000 | 0.001 | 49.9 | 4606 | |
| 1000 | 6 | 6000 | 0.002 | 51.9 | 4589 | |
| 1000 | 6 | 6000 | 0.003 | 47.25 | 4485 | |
| 1500 | 4 | 6000 | 0.002 | 55.7 | 5589 | |
| 1500 | 4 | 6000 | 0.005 | 51.8 | 4890 | |
| 1500 | 4 | 6000 | 0.01 | 46.7 | 3844 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Tao, J.; Zhao, L. Incremental Multi-Step Learning MLP Model for Online Soft Sensor Modeling. Sensors 2025, 25, 4303. https://doi.org/10.3390/s25144303
Wang Y, Tao J, Zhao L. Incremental Multi-Step Learning MLP Model for Online Soft Sensor Modeling. Sensors. 2025; 25(14):4303. https://doi.org/10.3390/s25144303
Chicago/Turabian StyleWang, Yihan, Jiahao Tao, and Liang Zhao. 2025. "Incremental Multi-Step Learning MLP Model for Online Soft Sensor Modeling" Sensors 25, no. 14: 4303. https://doi.org/10.3390/s25144303
APA StyleWang, Y., Tao, J., & Zhao, L. (2025). Incremental Multi-Step Learning MLP Model for Online Soft Sensor Modeling. Sensors, 25(14), 4303. https://doi.org/10.3390/s25144303